Algoritmikus modellek és tanulóalgoritmusok a statisztikában
|
|
|
- Gizella Fehérné
- 6 évvel ezelőtt
- Látták:
Átírás
1 Algoritmikus modellek és tanulóalgoritmusok a statisztikában Bolla Marianna, Csicsman József
2 Előszó Jegyzetünk azoknak a hallgatóknak készült, akik matematikai statisztika és többváltozós statisztika tanulmányaik után szeretnék megismerni a modern statisztikai modelleket és módszereket is. A klasszikus statisztika fogalomrendszere és legtöbb tétele a XX. század első felében lett kidolgozva, elsősorban valószínűségszámítási alapokon. Ebben jelentős szerepet játszott az angolszász, orosz és indiai iskola. Érdekes, hogy olyan kulcsfontosságú eredmények, mint a Cramér Rao egyenlőtlenség, Rao Blackwellizálás, és a Wald-féle szekvenciális döntési eljárás a II. Világháború idején születtek meg, utóbbi töltények gazdaságos minőségellenőrzésére. A XX. század közepére kifejlesztették a többváltozós statisztikai eljárásokat is, amelyek széleskörű alkalmazásának azonban csak a nagy teljesítményű számítógépek elterjedése nyitott utat a XX. század második felében (BMDP, SPSS programcsomagok), hiszen ezek a módszerek nagyméretű adatmátrixok és kovarianciamátrixok szinguláris- és spektrális felbontásán alapulnak. Nagyjából ezeket az ismereteket foglalja össze a BME matematikus képzés BSc és MSc statisztika anyagának gerincét képező Bolla Krámli, Statisztikai következtetések elmélete (Typotex, 2005 és 2012) könyv. Az as években azonban már ez a tényanyag sem bizonyult elégségesnek. Valós életbeli (biolológiai, pszichológiai, szociológiai) adatrendszerekkel foglalkozva azt találtuk, hogy a klasszikus módszerek nem alkalamazhatók mindig közvetlenül, illetve a probémák sokszor túlmutattak a tanult (elsősorban többváltozós normális eloszlású mintákra kifejlesztett) módszerek alkalmazhatósági körén (diszkrét, nem-paraméteres szituációk, időben is változó megfigyelések). L. Breiman, Statistical modeling: the two cultures (Statist. Sci. 16) 2001-es cikkében szintén rámutat arra, hogy gyakorlati problémákkal szembesülve a klasszikus apparátus néha csődöt mond. Az ún. második kultúra egy algoritmikus szemléletet visz a klasszikusba, ami azonban nem a numerikus módszerek automatikus alkalmazását jelenti, hanem olyan elméleti algoritmusok kifejlesztését, melyek az információelmélet, a Hilbert-terek, sőt akár a gráfelmélet eszköztárát használják magas színvonalon. Ebbe az eszköztárba szeretnénk betekintést nyújtani. Ilyen módon a tankönyv egy, a modern statisztikai módszerek iránt érdeklődő hallgatók számára a BME-n kétévente tartott kurzus anyaga, de használható témalabor vagy diplomamunka készítéséhez is, illetve az elméleti részek kihagyásával a leírt algoritmusok nagyméretű adatrendszerek adatbányászatával foglalkozó szakemberek számára is hasznosak lehetnek. Az algoritmikus modellek köre egyre terjed, itt csak a legfontosabbakat foglaltuk össze, de utalunk egyéb, hasonló célú eljárásokra, illetve bőséges szakirodalmat közlünk a részletek iránt érdeklődőknek. Az elméleti részek tanulmányozása pedig az arra fogékony olvasók kezébe ötleteket és eszközöket adhat hasonló szituációk kezelésére. Bolla Marianna, Csicsman József Budapest, július 5. 1
3 Tartalomjegyzék 1. Bevezetés 4 2. Az EM-algoritmus hiányos adatrendszerekre Egy konkrét példa Elméleti megfontolások Alkalmazások EM-algoritmus normális eloszlások keverékfelbontására EM-algoritmus polinomiális eloszlások keverékfelbontására EM-algoritmus gráfok klaszterezésére Irodalomjegyzék Az ACE-algoritmus általánosított regresszióra Elméleti megfontolások ACE-algoritmus egymásba ágyazott ciklusokkal ACE-algoritmus adatmátrixra simításokkal Az ACE-algoritmus outputja Alkalmazások Irodalomjegyzék Reprodukáló magú Hilbert-terek Elméleti háttér Példák Empirikus kernel Szemléletes példák Irodalomjegyzék Spektrális klaszterezés Gráfok és hipergráfok reprezentációja Egyszerű és súlyozott gráfok
4 Hipergráfok Normált Laplace mátrix Modularitás mátrix Nevezetes gráfok spektruma Minimális vágások, maximális modularitás Arányos és kiegyensúlyoztott vágások Általánosított véletlen gráfok Felfújt zajos mátrixok Reguláris partíciók Algoritmusok gráfok és hipergráfok klaszterezésére Súlyozott gráfok Hipergráfok kétszempontú klaszterezése Irodalom jegyzék Irodalomjegyzék Dinamikus faktoranalízis Előzmények és célkitűzések A modell A paraméterek becslése Szimmetrikus mátrixok kompromisszuma Alkalmazás Irodalomjegyzék A varianciaanalízis általános modelljei Többváltozós varianciaanalízis (MANOVA) Nemparaméteres varianciaanalízis Irodalomjegyzék 104 3
5 1. fejezet Bevezetés Hat fő téma köré csoportosítottuk a tananyagot, mindegyiket külön fejezetben tárgyaljuk, egységes jelölésmóddal és elnevezésekkel. A témák látszólag függetlenek, azonban eszközeikben, tárgyalásmódjukban igyekeztünk a bennük rejlő hasonlóságokat is felfedni. Az első fejezet az ún. EM (Expectation-Maximization) algoritmussal foglalkozik, mely hiányos adatrendszerből képes becsülni maximum likelihood módszerrel a paramétereket. A likelihood függvény maximumhelyének megkeresése még teljes adatrendszerből is sokszor bonyolult feladat, néha hiányosak is az adatok. Az algoritmus mintegy kihasználva ezt a körülményt, rekonstruálja az adatokat (feltételes várható érték képzéssel, ez az E-lépés), miközben a paramétert a kiegśzített adatrendszerből becsli klasszikus maximalizálással (M-lépés). Tárgyaljuk az E- és M-lépések alternálásával kialakított iteráció konvergenciáját, illetve a módszer alkalmazhatóságát keverékek felbontására. Utóbbi esetben nem feltétlenül a paraméter, hanem egy látens változó értékei hiányoznak, melyek a mintaelemek osztálybatartozását adják meg. Tárgyalásunkban az 1977-ben megjelent Dempster Laird Rubin alapcikket követjük, de beszélünk az azóta elterjedt ún. collaborative filterigről is. A második fejezet az ACE (Alternating Conditional Expectation) algoritmust ismerteti általánosított regresszióra, mikor nemcsak a függő és független változók közti függvénykapcsolat jellege ismeretlen, hanem a változók vegyes (diszkrét és folytonos) tipusúak is lehetnek. Az ismertetett iteráció az adatrendszer simításával szemléletes képet nyújt a változók optimális linearizáló transzformációiról. A Breiman Friedman 1985-ös alapcikket követjük, és a Hilbert-terek lineáris transzformációit vizsgáló elmélet mellett kitérünk a feltételes várható érték képzésnek simításokkal történő gyakorlati megvalósítására sokváltozós adatrendszereken. A harmadik fejezet speciális Hilbert-terekkel foglalkozik, melyeket egy pozitív definit magfüggvény generál. Az ún. kernel-trükk amit elsősorban az adatokban levő nem-linearitások kezelésére használnak abban áll, hogy adatainkat nem feltétlenül kell az ún. Reprodukáló Magú Hilbert Térbe (RMHT) leképezni, elég csak a páronkénti kovarianciákat a magfüggvénnyel kiszámolni, legalábbis olyan módszereknél, melyek a 4
6 kovarianciamátrixot használják inputként (a főkomponens- és faktoranalízis pl. ilyen). Rámutatunk, hogy a módszer mögött meghúzódó elmélet a Riesz Fréchet Reprezentációs Tétel, melynek értelmében egy Hilbert-tér és duálisa (az azon értelmezett lineáris funkcionálok) izometrikusan izomorfak. Nagyon vázlatosan, a nem-lineáris funkcionálok már egy bonyolultabb Hilbert-tér elemeinek feleltethetők meg (ez az RMHT). Bemutatjuk, hogyan lehet a szokásos klaszterező eljárásokkal nem szétválasztható, de szemmel láthatóan különböző (nem lineárisan szeparált) klasztereket megtalálni. A negyedik fejezet élsúlyozott gráfok és hipergráfok klaszterezéséről szól spektrális módszerekkel. Az ún. spektrális klaszterezés lényege, hogy először a csúcsokat (a köztük levő hasonlóságok, azaz a súlyozott élek) alapján egy véges dimenziós térbe képezzük le, a többváltozós statisztikai módszereknél használt spektrálfelbontási technikákkal. Ezután a reprezentánsok metrikus klaszterezésével polinomiális időben vagyunk képesek megkeresni minimális többszempontú vágásokat vagy maximalizálni az ún. Newman Girvan modularitást. A minimális vágások és maximális modularitások olyan csúcspartíciókat keresnek, melyeken belül nagy az élsűrűség. Az összes partíción való optimalizálás azonban nagy csúcsszám esetén nem kivitelezhető (exponenciális idejű), ezért használjuk a fenti ún. spektrális relaxációt. Ilyen módon a csúcsklaszterekre csak közelítő megoldást kapunk, azonban a közelítés jóságát a spektrumbeli résekkel becsülni tudjuk, és az osztályok számát úgy választjuk meg, hogy jó közelítést kapjunk. Foglalkozunk még kis diszkrepanciájú ún. reguláris vágásokkal, általánosított véletlen gráfokkal, és adatpontok spektrális klaszterezésével. Utóbbi esetben egy hasonlósági gráfot építünk, például RMHT technikákat használva. Az ötödik fejezetbeli Dinamikus Faktoranalízis többváltozós idősorok komponenseiből választ le független faktorokat, melyek időbeli lefutása a sok összefüggő komponenst tartalmazó idősor fő tendenciáit mutatja. A faktorfolyamatok autoregresszív modellt követnek. Ennek együthatói és a faktorsúlyok a modell paraméterei, ezek becslésére adunk egy mátrixfelbontásokon alapuló iterációs eljárást. Az algoritmus tárgyalásán túl egy alkalmazást is bemutatunk makroökológiai idősorokra. A hatodik fejezet a varianciaanalízis (ANOVA) általános modelljeit tárgyalja. A többváltozós varianciaanalízis (MANOVA) a szórások felbontása helyett a kovarianciamátrixok felbontásán alapul, és többdimenziós normális sokaságból vett minta esetén hasonlóan műkódik az ANOVA-hoz. A másik módszer újszerűbb, rangstatisztikákon alapul, és tetszőleges, akár vegyes eloszlású változókra is alkalmazható. A Brunner Puri alapcikk felhasználásával írjuk le a módszert, majd a kapott becslők konzisztenciájára, aszimptotikus normalitására idézzük az ott bizonyított tételeket. A fejezetek elvileg tetszőleges sorrendben olvashatók, külön irodalomjegyzékkel rendelkeznek, mégis ezt a sorrendet javasoljuk tanulmányozásukra, a néha egymásra épülő jelölések és kereszthivatkozások miatt. 5
7 2. fejezet Az EM-algoritmus hiányos adatrendszerekre Süvítenek napjaink, a forró sortüzek valamit minden nap elmulasztunk. Robotolunk lélekszakadva, jóttevőn, s valamit minden tettben elmulasztunk... (Váci Mihály: Valami nincs sehol) december 8-án Londonban, a Királyi Statisztikai Társaság ülésén érdekes előadás hangzott el. Egy olyan algoritmust ismertettek, amelyet különböző formákban a paraméterek maximum likelihood becslésére már régóta használtak, azonban ilyen általános formában még soha nem fogalmazták meg. Az algoritmus eredeti leírása konvergenciabizonyítással és példákkal [5]-ben található. Az ún. EM-algoritmus célja az, hogy becslést adjon a háttéreloszlás valamely θ paraméterére hiányos adatokból. A paraméter maximum likelihood becslése még teljes adatrendszerből is bonyolult, sokszor nem is adható explicit megoldás. Gyakran hiányos is az adatrendszer. Az ismertetendő algoritmus kihasználva ezt a körülményt, megpróbálja rekonstruálni a hiányzó adatokat, miközben a paraméterre is egyre jobb becslést ad. Ez a kétféle törekvés egy iteráció következő két alaplépésében valósul meg: 1. E-lépés: a paraméter korábbi becslése alapján rekonstruáljuk a hiányzó adatokat feltételes várható érték képzéssel (E: Expectation ); 2. M-lépés: az ilyen módon kiegészített teljes adatrendszerből meghatározzuk a likelihoodfv. maximumhelyét θ-ban (M: Maximization ). A paraméter így nyert közelítésével újra kezdjük az E-lépést. Tág feltételek mellett Dempster, Laird és Rubin [5] bebizonyították az algoritmus konvergenciáját. Az algoritmus nem csupán akkor alkalmazható, amikor bizonyos változók mérései nem állnak 6
8 rendelkezésünkre, hanem cenzorát adatok vagy keverékfelbontás esetén is. Még általánosabban, az adatrendszert úgy is tekinthetjük hiányosnak, hogy látens változók vagy egy rejtett modell húzódik meg mögötte (pl. Baum Welch algoritmus rejtett Markovmodellekre). Ilyenkor a modell paramétereinek becslése a feladat. Néha csupán technikai okokból egészítjük ki adatrendszerünket, mert a kiegészítettben könnyebben végre tudjuk hajtani az ML-becslést (l. a következő példa). Tételek viszont garantálják, hogy az iteráció az eredeti (hiányos) likelihoodot maximalizálja. A hivatkozott cikk jelöléseivel: legyen X a teljes, Y pedig a hiányos mintatér, amelyek között tehát létezik egy X Y, x y(x) megfeleltetés. Jelölje f(x θ) ill. g(y θ) a megfelelő eloszlások együttes sűrűség- ill. vsz.- függvényét, azaz a likelihood-függvényt, amely a θ akár többdimenziós paramétertől függ (itt az abszolút folytonos esetet tekintjük). Közöttük a g(y θ) = f(x θ) dx (2.1) X (y) összefüggés közvetít (diszkrét eloszlásoknál az helyett értendő), ahol X (y) = {x : y(x) = y}. Célunk a g(y θ) hiányos likelihood függvény maximalizálása θ-ban az y megfigyelés alapján Egy konkrét példa Tekintsünk egy genetikai példát (l. Rao [9], 5.5.g. fejezet)! (AB ab) genotípusú hímek és ugyanilyen genotípusú nőstények keresztezéséből származó 197 utód fenotípusa négyféle lehet: AB, Ab, ab és ab. A modell szerint az utódok polinomiális eloszlás szerint 1 tartoznak a négy fenotípus valamelyikéhez, az osztályok valószínűségei rendre: + 1π, π, 1 1π és 1π; itt π a modell paramétere (Rao példájában π = ( θ)2, ahol θ az ún. rekombinációs hányados). A megfigyelt (hiányos) adatok: y = (y 1, y 2, y 3, y 4 ) = (125, 18, 20, 34). Itt y tulajdonképpen egy 4 alternatívájú indikátorváltozó összegstatisztikája, mely polinomiális eloszlást követ. A likelihood függvény tehát g(y π) = (y 1 + y 2 + y 3 + y 4 )! ( 1 y 1!y 2!y 3!y 4! π)y 1 ( π)y 2 ( π)y 3 ( 1 4 π)y 4. 7
9 A feladat g maximalizása π-ben. Ecélból egy olyan algebrai egyenletet kell megoldani, aminek számos gyöke van, közülük csak kettőt lehet explicit módon megadni. A feladat természetesen numerikusan viszonylag egyszerűen megoldható, az alábbiakban ismertetett eljárás az EM-algoritmus egy jól követhető illusztrációja. A fenti adatrendszert technikai okokból hiányosnak tekintjük, amely a valódi, 5 csoportból álló adatrendszerből úgy keletkezett, hogy az első 2 csoport összevonódott. A teljes adatrendszer tehát: x = (x 1, x 2, x 3, x 4, x 5 ), ahol y 1 = x 1 + x 2, y 2 = x 3, y 3 = x 4, y 4 = x 5. x nem más, mint egy 5 alternatívájú indikátorváltozó összegstatisztikája, melyre felírt polinomiális likelihood: ahol f(x π) = (x 1 + x 2 + x 3 + x 4 + x 5 )! p x 1 1 p x 2 2 p x 3 3 p x 4 4 p x 5 5, x 1!x 2!x 3!x 4!x 5! p 1 = 1 2, p 2 = 1 4 π, p 3 = p 4 = π, p 5 = 1 4 π. Az (2.1)-beli integrálnak diszkrétben megfelelő összeg: g(y π) = f(x π). x 1 +x 2 =y 1, x 1 0, x 2 0 egész, x 3 =y 2, x 4 =y 3, x 5 =y 4 Ezután kezdődjék az iteráció valamely π (0) kezdőértékkel! Tegyük fel, hogy az m-edik lépés után már megvan a π (m) közelítés. Az m + 1-edik lépés a következő két lépésből fog állni: 1. E-lépés: az y megfigyelés alapján rekonstruáljuk az x adatrendszert azaz meghatározzuk x 1 és x 2 y 1 = 125 és π = π (m) feltételek melletti feltételes várható értékeit. Mivel x 1, illetve ( x 2 a) fenti feltételek( mellett ) x 3, x 4 és x 5 értékétől 1 2 π függetlenül Bin illetve Bin (m) π(m) 1 eloszlású, ezért π(m) x (m) 1 = és x (m) 2 4 π(m) 2 = π(m) π(m) 2. M-lépés: az ilyen módon kiegészített (x (m) 1, x (m) 2, 18, 20, 34) teljes adatrendszerből meghatározzuk π maximum likelihood becslését, és ezt π (m+1) -gyel jelöljük. Ecélból vonjuk össze maximalizálandó f(x π) likelihood függvény π (m) -től nem függő tényezőit egyetlen konstansba: f(x π) = const ( ) (m) x 1 4 π ( ) π. 8
10 Ezt a kifejezést 4 x(m) nal megszorozva a a maximalizálandó függvény az alábbi alakot ölti: f(x π) = const (π) x(m) (1 π) 18+20, ami a Bernoulli eloszlás likelihood függvénye, tehát a maximumát a értéken veszi fel. π (m+1) = x (m) x (m) Ezzel a π (m+1) értékkel visszatérünk az E-lépéshez. Az iterációt π (0) = 0.5-el indítva 2-3 lépés után π értéke 0.6 körül stabilizálódott Elméleti megfontolások Legyen statisztikai mezőnk dominált, paraméteres, identifikálható és reguláris (a Cramer Rao egyenlőtlenségnél tanult bederiválhatósági feltételek teljesülnek). Tegyük fel, hogy mintánk exponenciális eloszláscsaládból származik, ahol természetes paraméterezést választunk, azaz a sűrűség/súly-függvény f(x θ) = c(θ) e k j=1 θ jt j (x) h(x) alakú, ahol c(θ) normáló tényező és a θ = (θ 1,..., θ k ) természetes paramétertől való függést feltételként jelöljük (nem ok nélkül, ui. a Bayes módszeréhez hasonló meggondolásokat használunk). Tudjuk, hogy egy X = (X 1,..., X n ) n-elemű minta esetén t(x) = ( n t 1(X i ),..., n t k(x i )) elégséges, sőt amennyiben a k-dimenziós paramétertér konvex és tartalmaz k-dimenziós téglát teljes is, így minimális elégséges statisztika, ami ekvivalencia erejéig egyértelmű. Tehát a realizáltakkal felírt likelihoodfüggvény a következő alakú: f(x θ) = c n (θ) e k j=1 θ j n t j(x i) n h(x i ) = 1 a(θ) eθ tt (x) b(x), (2.2) ahol a vektorok sorvektorok, T a transzponálást jelöli (így az exponensben tulajdonképpen skalárszorzat áll), az utolsó tényező csak a mintától az első pedig csak a paramétertől függ és a normális miatt a(θ) = e θ tt (x) b(x) dx. (2.3) X Jelen esetben az iteráció végigkövethető a t minimális elégséges statisztikán keresztül a következőképpen. Miután Y (a megfigyelt hiányos adatrendszer) az X (a posztulált 9
11 teljes adatrendszer) függvénye, X feltételes sűrűsége x-ben az Y = y feltétel mellett (2.1) és (2.2) figyelembevételével ahol k(x y, θ) = f(x θ) g(y θ) = 1 a(θ y) eθ tt (x) b(x), (2.4) a(θ y) = X (y) e θ tt (x) b(x) dx. (2.5) Azaz a feltétel nélküli és a feltételes likelihood ugyanazzal a természetes paraméterrel és elégséges statisztikával írható fel, a különbség csak az, hogy különböző tereken X -en ill. X (y)-on vannak értelmezve, ami a (2.3) ill. (2.5)-beli súlyfüggvényeken is látszik. Célunk az L(θ) := ln g(y θ) log-likelihood függvény maximalizálása θ-ban adott y mellett. (2.4) miatt L(θ) = ln a(θ) + ln a(θ y). (2.6) A bederiválhatósági feltételek miatt 1 ln a(θ) = θ a(θ) X t(x) e θ tt (x) b(x) dx = E(t θ). (2.7) Hasonlóan 1 ln a(θ y) = t(x) e θ tt (x) b(x) dx = E(t y, θ). θ a(θ y) X (y) (Ez csak tömör jelölés: A vektor szerinti deriválás eredménye a komponensek szerinti parciális deriváltakból álló vektor.) Ezek segítségével (2.6) deriváltja L(θ) = E(t θ) + E(t y, θ) (2.8) θ alakú, aminek zérushelyét keressük. Nézzük most a következő iterációt, melyben már eljutottunk θ m-edik becsléséig. 1. E-lépés: a paraméter θ (m) értéke alapján becsüljük a teljes adatrendszer t elégséges statisztikáját a hiányos adatrendszerből t (m) := E(t y, θ (m) ) (2.9) a feltételes eloszlás alapján (a példában ezek a binomiális eloszlású változók becslései); 10
12 2. M-lépés: meghatározzuk θ (m+1) -et, mint a teljes minta likelihood-egyenletének megoldását, azaz ln f(x θ) = 0. θ Használva az exponenciális eloszláscsalád speciális alakját, ez nem más, mint a egyenlet, azaz (2.7) figyelembevételével az egyenlet megoldása lesz θ (m+1). θ ln a(θ) + t(m) (x) = 0 (2.10) E(t θ) = t (m) (2.11) Amennyiben az iteráció θ -hoz konvergál, elég nagy m-re θ (m) = θ (m+1) = θ, így (2.9) és (2.11) alapján E(t θ ) = E(t y, θ ) teljesül, azaz (2.8) zérushelyét kapjuk. Most még általánosabban belátjuk, hogy az iteráció konvergál. Az általánosság egyrészt azt jelenti, hogy nem csupán exponenciális eloszláscsaládra szorítkozunk, másrészt az M-lépés sem feltétlenül a teljes likelihood maximalizálását jelenti, csak a célfüggvény növelését. Mivel információelméleti fogalmakat használunk, a természetes alapú logaritmus helyett 2 alapút használunk és log-gal jelöljük. Ez nem jelenti az általánosság megszorítását, hiszen a hiányos likelihhoodnak a θ argumentumban való maximalizálása arg max szempontjából ekvivalens a likelihood függvény bármely 1-nél nagyobb alapú logaritmusának a maximalizálásával. Így a továbbiakban L(θ) = log g(y θ) lesz a maximalizálandó log-likelihood függvény. Tetszőleges θ, θ párra vezessük be a Q(θ θ ) = E(log f(x θ) y, θ ) = log f(x θ)k(x y, θ ) dx (2.12) függvényt. Ezzel az iteráció θ (m) θ (m+1) fázisa: 1. E-lépés: kiszámoljuk a Q(θ θ (m) ) függvényt a (2.12)-beli feltételes várható érték képzéssel (exponenciális eloszláscsaládnál elég volt az elégséges statisztika feltételes várható értékét venni); X (y) 2. M-lépés: maximalizáljuk a Q(θ θ (m) ) függvényt θ-ban. Legyen θ (m+1) := arg max Q(θ θ (m) ) és tegyük fel, hogy θ (m+1) Θ. Exponenciális eloszláscsaládnál ez a (2.10) egyenlet megoldását jelenti. 11
13 Most belátjuk, hogy az algoritmus következő relaxációja is konvergál: az M-lépésben Q(θ θ (m) )-et nem feltétlenül maximalizáljuk θ-ban, hanem csak növeljük értékét az előző iterációbelihez képest. Azaz θ (m+1) olyan, hogy Vezessük be a H(θ θ ) = E(log k(x y, θ) y, θ ) = jelölést Lemma Q(θ (m+1) θ (m) ) Q(θ (m) θ (m) ). (2.13) X (y) H(θ θ ) H(θ θ ) log k(x y, θ)k(x y, θ ) dx (2.14) és egyenlőség pontosan akkor áll fenn, ha k(x y, θ) = k(x y, θ ) majdnem biztosan. (Megjegyezzük, hogy H(θ θ) a k(x y, θ) eloszlás entrópiája.) Bizonyítás: Alkalmazzuk a Jensen-egyenlőtlenséget, melynek értelmében tetszőleges h konvex függvényre és első momentummal rendelkező ξ valószínűségi változóra E(h(ξ)) h(e(ξ)). Emiatt az f eloszlás relatív entrópiája a g eloszlásra f log f 0, ui. alkalmazzuk a Jensen-egyenlőtlenséget a h(x) = log(x) konvex függvényre és az f eloszlás g szerinti várható értékre: f log f g = E( log g f ) log(e( g g f )) = log f = log 1 = 0. (2.15) f Mivel H(θ θ ) H(θ θ ) = X (y) log k(x y, θ ) k(x y, θ) k(x y, θ ) dx, nem más, mint a k(x y, θ ) eloszlás relatív entrópiája a k(x y, θ) eloszlásra nézve, így a lemma értelmében nem-negatív. Az integrál pontosan akkor 0, ha a nem-negatív integrandus majdnem biztosan 0, azaz a logaritmálandó hányados majdnem biztosan 1. Ezzel a bizonyítást befejeztük Definíció A θ (m+1) = M(θ (m) ) iteráció általánosított EM-algotitmust (GEM) definiál, ha Q(M(θ) θ) Q(θ θ), θ Θ. Tehát (2.13) fennállásakor GEM algoritmusunk van. 12
14 2.3. Tétel Tetszőleges GEM algoritmusra L(M(θ)) L(θ), θ Θ, ahol egyenlőség pontosan akkor áll fenn, ha k(x y, M(θ)) = k(x y, θ) és Q(M(θ) θ) = Q(θ θ) majdnem biztosan teljesülnek. Bizonyítás: Először is Q(θ θ ) H(θ θ ) = E(log(f(x θ) log(k(x y, θ) y, θ ) = E(log(g(y θ)) y, θ ) (2.16) mivel log(g(y θ)) mérhető y-ra. Ezután = log(g(y θ)) = L(θ), (2.17) L(M(θ)) L(θ) = [Q(M(θ) θ) Q(θ θ)] + [H(θ θ) H(M(θ) θ)] 0, mivel az első Szögletes zárójelben álló mennyiség nem-negatív a GEM definíciója miatt, a másodikban álló pedig a lemma miatt. Ezzel a bizonyítást befejeztük. Ha a likelihood-függvény korlátos, akkor a GEM mivel minden iterációs lépésben növeli (nem csökkenti) a likelihood-függvény értékét konvergál, és exponenciális eloszláscsaládnál láttuk, hogy a fixpont a likelihood-egyenlet megoldását adja. A likelihoodfüggvényre tett további folytonossági és differenciálhatósági feltételek, továbbá a paramétertér konvexitása esetén belátható, hogy az iteráció a likelihood-függvény egy lokális maximumhelyéhez konvergál Θ-ban, ami egyértelműség esetén globális maximumhely is. [5] cikkben mondják ki ehhez a pontos feltételeket. Ha ilyen feltételek nincsenek, [8]-ben példákat mutatnak egyéb eshetőségekre (pl. nyeregpont). A [4] monográfiában Csiszár Imre bebizonyítja, hogy az EM-algeritmus nem más, mint egy alternálva minimalizáló eljárás az I-divergenciára. A P és Q eloszlások I- divergenciája a (2.15)-beli relatív entrópia azzal a különbséggel, hogy itt a két eloszlás ugyanazon a véges tartón értelmezett diszkrét eloszlás: D(P Q) = a P(a) log P(a) Q(a). Az I-divergencia nem szimmetrikus az argumentumaiban, viszont az euklideszi távolsághoz hasonló tulajdonságai vannak. Ezeken alapul az az állítás, hogy az EM-algoritmus során D(P 1 Q 0 ) D(P 1 Q 1 ) D(P 2 Q 1 ) D(P 2 Q 2 )..., ahol a Q 0 felvett kezdeti eloszlásból kiindulva Q 1, Q 2,... rekonstruálja a teljes minta ismeretlen eloszlását, míg P m = E Qm 1 (x y) a teljes minta hiányosra vett feltételes várható értéke, amennyiben a teljes minta eloszlása Q m 1. A [4] jegyzetben a szerzők bebizonyítják, hogy a fenti eljárás konvergál az ismeretlen valódi Q eloszláshoz, mivel a nem-negatív I-divergencia minden lépésben csökken (nem növekszik). (Itt most általánosabban, nem a paramétert becslik, hanem magát az ismeretlen eloszlást, azaz az EM algoritmus nem-paraméteres verzióját kapjuk.) 13
15 2.3. Alkalmazások Gyakori feladat a többdimenziós normális eloszlás paramétereinek becslése hiányos adatokból. Pl. adatrendszerünk pácienseken mért folytonos változók értékeit tartalmazza (pl. testmagasság, testsúly, vérnyomás), de bizonyos páciensek bizonyos mért értékei hiányoznak (nem vették fel vagy elvesztek). 1. E-lépés: a paraméter valamely θ (m) értéke alapján becsüljük a hiányzó adatokat feltételes várható érték képzéssel. 2. M-lépés: az így kiegészített teljes adatrendszerben a jól ismert módon maximum likelihood becslést hajtunk végre a paraméterekre (mintaátlag ill. empirikus kovarianciamátrix). Azonban nem feltétlenül a mérések hiányosak, lehet, hogy valamit meg sem néztünk, pl. elfelejtettük, hogy a páciensek mely betegcsoportból valók, vagy éppenséggel most szeretnénk új diagnosztikai csoportokat definiálni (a látens változó véges értékkészletű). Adatbányászatban nagy mintáknál előfordul, hogy a mintaelemek bár függetlenek, nem azonos eloszlásúak. Ilyenkor gyakran feltesszük, hogy nem homogén mintánk különböző (paraméterű, de azonos típusú) eloszlások keveréke, azaz a sűrűség/súly-függvény véges sok különböző paraméterű sűrűség/súlyfüggvény szuperpoziciója EM-algoritmus normális eloszlások keverékfelbontására Gyakran folytonos sokaságból származó mintánk empirikus sűrűséghisztogramja több kiugró csúccsal rendelkezik; úgy néz ki, mint Gauss-görbék szuperpoziciója. (Pl. folyók vízszintjének tetőzési értékei megfelelhetnek a tavaszi és nyár eleji árhullámnak; vagy a forgalomban levő részvénymennyiség a tőszdén nyitás után és zárás előtt mutat egyegy csúcsot, ezeket szeretnénk sok nap 8-9 órás adatai alapján szétválasztani.) Ilyenkor keressük a komponensek paramétreit és arányát. Az EM-algoritmus szemléltetéséül egy [6]-beli példát ismertetek két komponens szétválasztására. Háttéreloszlásunk változóját jelölje Y, amely az Y 1 és Y 2 Gauss-eloszlású változók keveréke, ahol a keverési arányt a Bernoulli-eloszlású háttérváltozó jelöli. Amennyiben a 0 értéket veszi fel, az első (Y 1 által képviselt), amennyiben az 1 értéket veszi fel, a második (Y 2 által képviselt) Gauss-eloszlás van érvényben. Tehát modellünk a következő: Y = (1 )Y 1 + Y 2, ahol a modell paraméterei: (µ j, σ 2 j ) az j-edik Gauss-eloszlás paraméterei (j = 1, 2) és π a látens Bernoulli-változó paramétere ( az 1 ertéket π valószínűséggel veszi fel, a 0 ertéket pedig 1 π valószínűséggel). Azaz θ = (µ 1, σ 2 1, µ 2, σ 2 2, π). 14
16 Y sűrűségfüggvénye tehát g(y θ) = (1 π)f 1 (y) + πf 2 (y), ahol f j a (µ j, σj 2 ) paraméterű Gauss-sűrűség. Amennyiben n-elemű független mintánk realizáltja az y 1,..., y n mért értékekből áll, a likelihood-függvény n n g(y θ) = g(y i θ) = [(1 π)f 1 (y i ) + πf 2 (y i )] alakú, melyet vagy melynek logaritmusát maximalizálni θ-ban bonyolult feladat. Ezért a következő iterációt hajtjuk végre. (Összhangban az elméleti meggondolásokkal, itt is g a hiányos minta likelihoodja. A teljes minta likelihoodja a két csoport kétféle likelihoodjának a szorzata lenne, de ezt nem tudjuk felírni, mert nem ismerjük az egyes mintaelemek csoportba tartozását.) 0. Inicializálás. A paraméterekhez kezdőértéket rendelünk: θ (0) = (µ (0) 1, σ1 2(0), µ (0) 2, σ 2(0) 2, π (0) ). (Pl. π (0) lehet 1/2, a két várható érték lehet két szélsőséges érték, a szórások mindegyike pedig az empirikus.) Tehát m := 0 és tegyük fel, hogy már eljutottunk a θ (m) = (µ (m) 1, σ1 2(m), µ (m) 2, σ 2(m) 2, π (m) ) iteráltig. A következő lépésben E-M belső ciklus jön: 1. E-lépés: kiszámoljuk az egyes mintaelemek részarányát a kétféle eloszlásban, azaz az E( Y = y i ) feltételes várható értéket, ami Bernoulli-eloszlása miatt a P( = 1 Y = y i ) feltételes valószínűséggel egyezik meg és π (m+1) i -el jelöljük (i = 1,..., n). Mindezt a hiányos adatrendszer és a paraméter kezdeti eloszlása alapján tesszük a Bayestétel folytonos eloszlásokra adaptált verziója segítségével: π (m+1) i = π (m) f (m) 2 (y i ) (1 π (m) )f (m) 1 (y i ) + π (m) f (m) 2 (y i ) (i = 1,..., n), (2.18) ahol f (m) j jelöli a θ (m) paraméter alapján számolt j-edik Gauss-sűrűséget (j = 1, 2): f (m) j (x) = 1 e (m) 2πσ j (x µ(m) ) j 2 2(σ (m) j 2. M-lépés: külön-külön maximalizáljuk a teljes mintát jelentő kétféle Gauss likelihoodot, aminek megoldása jól ismert, csak itt a mintaelemeket részesedésük arányában számítjuk be a kétféle becslésbe: µ (m+1) 1 = n n (1 π(m+1) i )y i (1 π(m+1) i ), 15 ) 2.
17 illetve σ 2 1(m+1) = σ 2 2(m+1) = n (1 π(m+1) i )(y i µ (m+1) 1 ) 2 (1 π(m+1) i ) n µ (m+1) 2 = n π(m+1) i n π(m+1) i y i n π(m+1) i (y i µ (m+1) 2 ) 2 n π(m+1) i, (i = 1,..., n), (i = 1,..., n). A fenti E-M lépés egy iterációs lépést jelentett. Ezután legyen π (m+1) := 1 n n π (m+1) i a Bernoulli-paraméter első iterációs becslése a mintaátlagával, m := m + 1 és ismételjük meg a fenti 1. és 2. lépést. Elég sokszor ismételve az eljárásbeli θ (m) sorozat (m = 1, 2,... ) konvergálni fog, hacsak valami rossz indítás miatt nem ragad le rögtön az elején (pl. a két normális paraméterei megegyeznek és 1/2 1/2 eséllyel választjuk őket). Könnyű elképzelni, hogyan bonthatnánk fel mintánkat kettőnél több, de adott számú normális eloszlás keverékére (általában annyira, ahány púpú az empirikus sűrűséghisztogram). Végezetül a pontok osztályozhatók az algoritmus paraméterei alapján: az i. pontot az első osztályba soroljuk, ha π i < 0.5, és a másodikba, ha π i 0.5, ahol π i a (2.18)-beli érték, amit az utolsó iterációban kapunk (i = 1,..., n). 1. Példa Generálunk véletlen számokból elemű normális eloszlású mintát, melyeknek várható értékei és szórásai rendre: µ 1 = 1, σ 1 = 2, µ 2 = 5, σ 2 = 2. 16
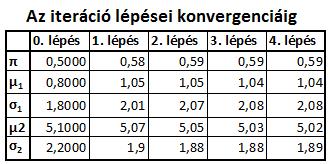
18 17
19 2. Példa Generálunk véletlen számokból elemű normális eloszlású mintát, melyeknek várható értékei és szórásai rendre: µ 1 = 1, σ 1 = 2, µ 2 = 10, σ 2 = 4. 18
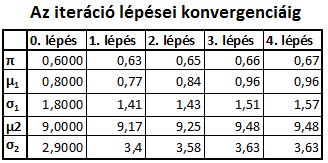
20 19
21 A példák, webes felületen is megtekinthetőek EM-algoritmus polinomiális eloszlások keverékfelbontására Megfigyeléseink itt két véges halmaz elempárjaira vonatkoznak. Kis módosítással a [7]- beli algoritmust ismertetem, melyet ott látens osztályozási modellnek vagy kollaboratív filterezésnek (együttes szűresnek) neveznek. A hiányos mintatér X Y, ahol X = {x 1,..., x n }, Y = {y 1,..., y m } és az x i, y j párokra együttes megfigyeléseink vannak egy n m-es kontingenciatábla formájában, melynek elemei ν(x i, y j ), ezek nem-negatív (nem feltétlenül, de általában) egész számok. Pl. szemszín hajszín esetén ν(x i, y j ) az x i -vel kódolt szem- és y j -vel kódolt hajszínű emberek gyakorisága a mintában; mozibajárók mozifilmek esetén ν(x i, y j ) azt jelöli, hogy x i néző hányszor látta az y j filmet (gyakran 0 vagy 1); internetes adatoknál kulcsszó dokumentum, felhasználó dokumentum; banki adatoknál banki rendszerbe való fizikai belépés id.-je accountra való belépés id.- je; pénzforgalmi adatoknál lehetséges átutalók lehetséges kedvezményezettek. Utóbbi esetben ν(x i, y j ) jelöli az x i által y j -nek átutalt összeg nagyságát (pl. ezer Ft-ban) vagy az x i y j tranzakció gyakoriságát egy adott időszakban. Itt X = Y a bank összes ügyfele, de a kontingenciatábla általában ekkor sem szimmetrikus. Tehát a kontingenciatábla adott, azonban a ν(x i, y j ) számok rendszerét hiányos adatrendszernek tekintjük, mert nem tartalmazza a kapcsolat/tranzakció mögötti szándékot, melyet látens változónak tekintünk. Ez egy diszkrét háttérváltozó a Z = {z 1,..., z k } értékkészlettel, k rögzített és jóval kisebb, mint n vagy m. A szemszín hajszín példában adatrendszerünk lehet különböző típusú országok adatainak keveréke (pl. skandináv, közép-európai, mediterrán); mozibajárók mozifilmek esetén a látens változó a filmnézés ill. filmek különböző fajtáit jelölheti: pl. művész-, dokumentum-, kommersz filmek ill. ilyen filmekre orientált nézők (maguk a nézők ill. filmek sem egységesek, bizonyos arányban tartalmazzák ezeket az orientációkat); a pénzforgalmi példában látens változó lehet az átutalás szándéka (pl. családi, üzleti vagy pénzmosás, ekkor k = 3). Célunk az, hogy 20
22 ezen szándékok szerint szabdaljuk fel az egyes átutalásokat és kiszűrjük a gyanús szándékokhoz leginkább köthető x i, y j párokat. A [7] cikk példájában filmnézési szokásokat vizsgálnak. Modellünk a következő: p(x i, y j ) = k p(x i, y j z l ) π(z l ) = l=1 k p(x i z l ) p(y j z l ) π(z l ), l=1 ahol a pánzforgalmi páldával élve p(x i, y j ) jelöli az x i y j átutalás valószínűségét, π(z l ) a z l szándék a priori valószínűségét, és feltesszük, hogy adott szándék mellett p(x i, y j z l ) = p(x i z l ) p(y j z l ), ami a két irányú pénzforgalom adott szándék melletti feltételes függetlenségét jelenti. A modell paraméterei a π(z l ) valószínűségek (l = 1,..., k) és a p(x i z l ), p(y j z l ) feltételes valószínűségek (i = 1..., n; j = 1,..., m; l = 1,..., k). Ezeket θ-ban fogjuk össze. Célunk a következő hiányos likelihood maximalizálása, mely polinomiális eloszlások keveréke: k n m π(z l ) c l p(x i, y j z l ) ν(x i,y j z l ), l=1 j=1 ahol a feltételes cellavalószínűségek (melyek a modell szerint szorzat alakúak) kitevőjében a cellagyakoriságok adott szándék melletti értéke áll (nem feltétlenül egész számok), c l pedig csak l-től függő konstans (polinomiális együttható, vagy nem egész kitevők esetén Γ-függvényeket tartalmaz). Becsüljük a paramátereket az EM-algoritmus segítségével! 0. Inicializálás. A paraméterekhez kezdőértéket rendelünk: π (0) (z l ), p (0) (x i z l ), p (0) (y j z l ). t:=0, tegyük fel, hogy már kezünkben van a θ (t) iterált. 1. E-lépés: kiszámoljuk a hiányzó szándék feltételes várható értékét a hiányos adatrendszer alapján. Ezt a következő feltételes (a posteriori) valószínűségek rendszere definiálja a Bayes-tétellel: p (t+1) (z l x i, y j ) = p (t) (x i, y j z l ) π (t) (z l ) k l =1 p(t) (x i, y j z l ) π (t) (z l ) = p (t) (x i z l ) p (t) (y j z l ) π (t) (z l ) k l =1 p(t) (x i z l )p (t) (y j z l ) π (t) (z l ). 2. M-lépés: külön-külön maximalizáljuk a k db. polinomiális eloszlás paramétereit, azaz rögzített l esetén keressük a c l n m j=1 ν(x i,y j ) p (t+1) (z l x i,y j ) h p(x i, y j z l ) l függvény maximumát, ahol a feltételes cellavalószínűségek kitevőjében a cellagyakoriságok adott szándék melletti értéke áll (Bayes-tétel a gyakoriságokra), a nevezőben álló h l 21
23 csak l-től függ (a számlálóbeliek i, j-re vett összege). A feltételes függetlenséget kihasználva és átrendezve maximalizálni akarjuk a c l [ n j=1 m {p(x i z l ) p(y j z l )} ν(x i,y j ) p (t+1) (z l x i,y j ) kifejezést a p(x i z l ), p(y j z l ) paraméterekben. Rögzített l-re (l = 1,... k) elég a szögletes zárójelben álló speciális polinomiális likelihood maximumát venni. A specialitás abban áll, hogy a kapcsos zárójelbe foglalt valószínűségek szorzat alakúak és a kitevőbei csonkolt gyakoriságokkal dolgozunk (Bayes-tétel megfelelője a gyakoriságokra). Átrendezve és ismerve a klasszikus polinomiális likelihood maximumát, a paraméterekre a következő becslés adódik minden l = 1,..., k esetén: ] 1 h l p (t+1) (x i z l ) = n i =1 m j=1 ν(x i, y j ) p (t+1) (z l x i, y j ) m j=1 ν(x i, y j) p (t+1) (z l x i, y j ) (i = 1,..., n) illetve p (t+1) (y j z l ) = n n ν(x i, y j ) p (t+1) (z l x i, y j ) m j =1 ν(x i, y j ) p (t+1) (z l x i, y j ) (j = 1,..., m). Ezután legyen π (t+1) (z l ) := n m j=1 p(t+1) (z l x i, y j ) nm (l = 1,..., k) a szándékok valószínűségének következő iterációs becslése, t := t + 1 és újra megtesszük az lépést. Ezt elég sokszor ismételve a θ (t) sorozat konvergálni fog θ -hoz bármely értelmes kezdés esetén. (Értelmetlen kezdás, ha az a priori valószínűségeket egyenlőnek választjuk. Ekkor az első lépésben a marginális valószínűségeket kapjuk, s ezeknél az iteráció le is ragad.) Ezekután pl. a pénzforgalmi példával élve ha valamely l-re π (z l ) kicsi, de a p (x i z l ), p (y j z l ) feltételes valószínűségek közt vannak szignifikánsan nagyok, akkor ezek az x i, y j párok gyanúsak, akárcsak a hozzájuk tartozó z l szándék EM-algoritmus gráfok klaszterezésére Most a statisztikai minta egy n csúcson értelmezett egyszerű gráf n n-es, szimmetrikus szomszédsági mátrixa. Jelölje ezt A = (a ij ), ahol a ij = 1, ha i j (i j) és 0, különben; a ii = 0 (i = 1,..., n). A következő, sztochasztikus blokk-modell paramétereit fogjuk becsülni (a modellt a [1] cikkben vezették be, de ott nem-paraméteres szempontból tárgyalták). A paramétereket most a [2] cikk alapján becsüljük az EM-algoritmus segítségével. 22
24 Adott k egészre (1 < k < n) a csúcsok függetlenül tartoznak a V a klaszterekbe π a valószínűséggel, a = 1,..., k; k a=1 π a = 1. V a és V b csúcsai egymástól függetlenül, P(i j i V a, j V b ) = p ab, 1 a, b k valószínűséggel vannak összekötve. A modell paramétereit a π = (π 1,..., π k ) vektorba és a k k-as, szimmetrikus P = (p ab ) mátrixba foglaljuk össze. A teljes valószínűség tétele értelmében a likelihood függvény: a,b k π a π b i C a,j C b,i j p a ij ab (1 p ab) (1 a ij) = a,b k π a π b p e ab ab (1 p ab) (n ab e ab ), amely binomiális eloszlások keveréke, ahol e ab jelöli a V a és V b klaszterket összekötő élek számát (a b), e aa pedig a tisztán V a -beli élek számának a kétszeresét; továbbá n ab = V a V b ha a b és n aa = V a ( V a 1), a = 1,..., k a lehetséges élek száma. Itt A egy hiányos adatrendszer, mivel a csúcsok klaszterbe tartozását (tagságát) nem ismerjük. Ezért az A adatmátrixot a csúcsok 1,..., n ún. tagsági vektoraival egészítjük ki, melyek független, azonos k-dimenziós P oly(1, π) véletlen vektorok. Még pontosabban, i = ( 1i,..., ki ), ahol ai = 1 ha i V a és 0, különben. Ezért i koordinátáinak összege 1, és P( ai = 1) = π a. Ezzel a fenti likelihood függvény az a,b k i,j: i j π a π b p ai bj a ij ab (1 p ab ) i,j: i j ai bj (1 a ij ) alakot ölti, és ezt maximalizáljuk az EM-algoritmus alternáló E és M lépéseiben. Megjegyezzük, hogy a teljes likelihood a 1 a,b k p e ab ab (1 p ab) (n ab e ab ) = k n a=1 b=1 (2.19) k j: j i [p bja ij ab (1 p ab ) j: j i bj(1 a ij ) ] ai (2.20) kifejezés négyzetgyöke lenne, ami azonban csak ismert tagságok esetén alkalmazható. A kezdő π (0), P (0) paraméterekből és (0) 1,..., (0) n tagsági vektorokból kiindulva, a t-edik iterációs lépés a következő (t = 1, 2,... ). E -lépés: kiszámoljuk i feltételes várható értékét a (t 1)-edik lépésbeli modell paraméterek és tagságok (az M (t 1) -el jelölt körülmények) alapján. A Bayes-tétel értelmében, az i-edik csúcs részaránya az a-adik klaszterben: ai = E( ai M (t 1) ) = P( ai = 1 M (t 1) ) = P(M (t 1) ai = 1) π a (t 1) k l=1 P(M (t 1) li = 1) π (t 1) π (t) 23 l
25 (a = 1,..., k; i = 1,..., n). Látható, hogy minden i-re π (t) ai a számlálóval arányos, ahol P(M (t 1) ai = 1) = k (p (t 1) ab ) j: j i (t 1) bj b=1 a ij (1 p (t 1) ab ) j: j i (t 1) bj (1 a ij ) (2.21) az (2.20) likelihood i-edik csúccsal kapcsolatos része a ai = 1 feltétel mellett. M -lépés: az összes a, b párra külön-külon maximalizáljuk azt a likelihoodot, mely a mintaelemeket a klaszterekben való részarányukban veszi figyelembe: i,j: i j p π(t) ai π(t) bj a ij ab (1 p ab ) i,j: i j π(t) ai π(t) bj (1 a ij) maximumhelye p ab -ben a binomiális likelihood szabálya szerint: p (t) ab = i,j: i j π(t) ai π(t) bj a ij i,j: i j π(t) ai π(t) bj, 1 a b k, ahol az a és b klasztereket összekötő éleket végpontjaik részarányával szorozva vesszük figyelembe. Legyen P (t) = (p (t) ab ) szimmetrikus mátrix. π maximum likelihood becslése a t-edik lépésben a π (t) vektor, melynek koordinátái π a (t) = 1 n n π(t) ai (a = 1,..., k), míg a i tagsági vektor maximum likelihood becslését diszkrét maximalizálással kapjuk: (t) ai = 1, ha π (t) ai = max b {1,...,k} π (t) bi és 0, különben. (Ha nem egyértelmű, akkor a kisebb indexű klasztert választjuk.) π ilyen választása csökkenti (2.19) értékét. Megjegyezzük, hogy elég a tagságokat csak az iteráció végén meghatározni, és (2.21)- ben π (t 1) bj -t helyettesíteni (t 1) bj helyére, ahol π (0) bj = (0) bj. A fenti algoritmus is a [7] cikkbeli ún. kollaboratív filterezés speciális esete, és az EM-algoritmus általános elmélete alapján konvergál, hiszen ismét exponenciális eloszláscsaládban vagyunk. 24
26 Irodalomjegyzék [1] P. J. Bickel, A. Chen, A nonparametric view of network models and Newman-Girvan and other modularities, PNAS 106 (50) (2009), [2] Bolla, M., Parametric and non-parametric approaches to recover regular graph partitions, A 14. ASMDA Konferencia kötetében (szerk. R. Manca és C. H. Skiadas), Universita di Sapienza, Róma (2011), old. [3] Bolla, M., Kramli A., Statisztikai következtetések elmélete. Typotex, Budapest (2005, 2012) [4] Csiszár, I., Shields, P., Information Theory and Statistics: A Tutorial, In: Foundations and Trends in Communications and Information Theory, Vol. 1 Issue 4 (2004), Now Publishers, USA. [5] Dempster, A. P., Laird, N. M., Rubin, D. B., Maximum likelihood from incomplete data via the EM algorithm, J. R. Statist. Soc. B 39 (1977), [6] Hastie, T., Tibshirani, R., Friedman, J., The Elements of Statistical Learning. Data Mining, Inference, and Prediction. Springer, New York (2001). [7] Hofmann, T., Puzicha, J., Latent class models for collaborative filtering. In Proc. 16th International Joint Congress on Artificial Intelligence (IJCAI 99) (ed. Dean T), Vol. 2, (1999) pp Morgan Kaufmann Publications Inc., San Francisco CA. [8] McLachlan, G. J., The EM Algorithm and Extensions. Wiley, New York (1997). [9] Rao, C. R., Linear Statistical Inference and Its Applications. Wiley, New York (1965, 1973). 25
27 3. fejezet Az ACE-algoritmus általánosított regresszióra Akár egy halom hasított fa, hever egymáson a világ, szorítja, nyomja, összefogja egyik dolog a másikát s így mindenik determinált. (József Attila: Eszmélet, IV. ciklus) A Breiman és Friedman által kifejlesztett algoritmus [3] az alábbiakban vázolt általános regressziós feladat numerikus megoldására szolgál igen tág keretek között (kategorikus adatokra, idősorokra ugyanúgy alkalmazható, mint olyan többváltozós adatokra, ahol a változók egy része abszolút folytonos, más része diszkrét; ilyen szituációk gyakran előfordulnak az adatbányászatban). Az Y függő és az X 1,..., X p független változóknak keresendők olyan Ψ, Φ 1,..., Φ p mérhető, nem-konstans valós értékű függvényei (szkórjai), amelyekkel e 2 (Ψ, Φ 1,..., Φ p ) = E [ Ψ(Y ) 2 p Φ j (X j )] /D 2 (Ψ(Y )) minimális adott {(y k, x k1,..., x kp : k = 1,..., n)} adatrendszer alapján. Valójában feltételes minimumot keresünk a D 2 (Ψ(Y )) = 1 feltétel mellett. Lineáris transzformációkkal elérhető, hogy E(Ψ(Y )) = E(Φ 1 (X 1 )) = = E(Φ p (X p )) = 0 D 2 (Ψ(Y )) = 1 legyen. Amennyiben a változók együttes (p + 1)-dimenziós eloszlása ismert, az algoritmus a következő. Legyenek Ψ (0) (Y ), Φ (0) 1 (X 1 ),..., Φ (0) p (X p ) a feltételeknek eleget tevő kezdeti függvények. Az iteráció t)-edik lépése (mindig csak egyik függvényt változtatjuk): j=1 26
28 1. Rögzített Φ (t) 1 (X 1 ),..., Φ (t) p (X p ) esetén Ψ (t+1) (Y ) := E( p j=1 Φ(t) j (X j) Y ) D ( p j=1 Φ(t) j (X j) Y ). 2. Rögzített Ψ (t+1) (Y ), Φ (t+1) 1 (X 1 ),..., Φ (t+1) i 1 (X i 1), Φ (t) i+1 (X i+1),..., Φ (t) p (X p ) esetén Φ (t+1) i (X i ) := E ( i 1 [Ψ (t+1) (Y ) j=1 Φ (t+1) j (X j ) p j=i+1 Φ (t) j (X j)] X i ), i = 1,..., p. Világos az algoritmus elnevezése: ACE=Alternating Conditional Expectation (felváltva történő feltételes várható érték vevés). Ennek az iterációnak a konvergenciája helyett a szerzők ennél egy általánosabb algoritmusnak a konvergenciáját látják be (ún. dupla-ciklus iteráció: az 1. külső iteráció minden lépésében a 2. belső iterációt folytatják konvergenciáig, majd visszatérnek a külső ciklusba, amíg az is nem konvergál). A hagyományos többváltozós regresszió lineáris kapcsolatot tételez fel a változók közt (ez többdimenziós normális háttéreloszlás esetén jogos is), ha pedig tudjuk, hogy a változók közt milyen függvénykapcsolat áll fenn, linearizáló transzformációkat alkalmazunk. Itt magukat a linearizáló transzformációkat is keressük, melyek hatása után a függő és független változók közt közel lineáris függvénykapcsolat alakul ki. Többdimenziós adatsorok esetén az egyik változó lehet maga az idő. Ennek a változónak az optimális transzformációja azt az időtranszformációt adja, mely a leginkább összefügg a többi változó időbeni profiljával. Megjegyezzük még, hogy az ACE-algoritmusbeli sorozatos feltételes várható érték vevés rokonságot mutat a Kálmán Bucy-féle szűrés algoritmusával Elméleti megfontolások A konvergencia bizonyítása egy általános Hilbert-terek kompakt lineáris operátoraira vonatkozó tételen alapul. Legyen (ξ, η) valós értékű valószínűségi változópár egyikük sem konstans 1 valószínűséggel az X Y szorzattér felett W együttes és P, Q marginális eloszlásokkal. Tegyük fel, hogy ξ és η függősége reguláris, azaz W együttes eloszlásuk abszolút folytonos a a P Q szorzatmértékre, és jelölje w a Radon Nikodym deriváltat, ld. [4]. Jelölje H = L 2 (ξ) ill. H = L 2 (η) ξ ill. η 0 várható értékű, véges varianciájú függvényeit a P ill. Q eloszlások szerint. H és H Hilbert-terek a kovarianciával, mint skalárszorzattal és altérként beágyazhatók a szorzattér feletti L 2 -térbe. 27
29 Legyen K : X Y R magfüggvény olyan, hogy K 2 (x, y) P(dy) Q(dx) <. (3.1) X Y Ezzel egy A : H H lineáris operátor (integrál operátor) definiálható a következőképpen: a φ H függvényhez A azt a ψ H függvényt rendeli, melyre ψ(x) = (Aφ)(x) = K(x, y)φ(y) Q(dy), x X. Y A linearitása miatt ψ várható értéke 0, és könnyű látni, hogy varianciája véges, továbbá ψ K φ <, ahol. a megfelelő térbeli L 2 -normát (szórást) jelöli. Ezért A operátornormájára: A = sup Aφ K. (3.2) φ =1 A fenti L 2 -terek szeparábilis Hilbert-terek, és (3.1) miatt A Hilbert Schmidt operátor, így kompakt (teljesen folytonos) is. Ezért létezik a következő szinguláris érték felbontása: A = s i., φ i H ψ i, ahol.,. jelöli a megfelelő Hilbert-térbeli skaláris szorzatot (kovarianciát), s 1 s 2 0 valós szinguláris értékek, melyek egyetlen lehetséges torlódási pontja a 0; a ψ i, φ i függvénypárok pedig megválaszthatók úgy, hogy {ψ i } H és {φ i } H teljes ortonormált rendszer legyen. Ennél kicsit több is igaz: s 2 i = K 2 2 <, ami maga után vonja, hogy lim i s i = 0. A adjungáltja (valósban transzponáltja): A T = s i., ψ i H φ i, és továbbá s 1 A és A T spektrálnormája. Aφ i = s i ψ i, A T ψ i = s i φ i, i = 1, 2,..., 28
30 A szimmetrikus esetben w(x, y) = w(y, x), x X, y Y. Ekkor ξ és η azonos eloszlásúak (de nem függetlenek, hiszen együttes eloszlásuk W), ezért H és H izomorf abban az erősebb értelemben is, hogy tetszőleges ψ H val. változóhoz van olyan ψ H val. változó és megfordítva, hogy ψ és ψ azonos eloszlásúak. A Hilbert Schmidt tétel [5] értelmében a A : H H önadjungált (valósban szimmetrikus) kompakt lineáris operátor spektrálfelbontása A = λ i., ψ i H ψ i valós sajátértékekel, melyek egyetlen lehetséges torlódási pontja 0, és a ψ 1, ψ 2,... sajátfúggvények olyanok, hogy ψ i és ψ i azonos eloszlásúak W együttes eloszlással. (A szinguláris értékei a sajátértékek abszolút értékei, és a Hilbert-Schmidt tulajdonságból a kompaktság következik.) Ha a magfüggvény. maga w, akkor a feltételes várható érték képzés operátorát kapjuk: P X : H H, ψ = P X φ = E(φ ξ), ψ(x) = w(x, y)φ(y) Q(dy) és P Y : H H, φ = P Y ψ = E(ψ η), φ(y) = Nyilván P T X = P Y és megfordítva, hiszen Y X w(x, y)ψ(x) P(dx). P X φ, ψ H = P Y ψ, φ H = Cov W (ψ, φ), (3.3) ahol a Cov W kovarianciafüggvény olyan, hogy Cov W (ψ, φ) = ψ(x)φ(y)w(dx dy) = Tegyük fel, hogy X Y X Y X Y ψ(x)φ(y)w(x, y)q(dy)p(dx). w 2 (x, y)q(dy)p(dx) <. (3.4) Diszkrét {w ij } eloszlás és {p i } (p i = j w ij), {q j } (q j = i w ij) marginálisok esetén (3.4) jelentése: ( ) 2 wij p i q j = wij 2 <, p i q j p i q j i X j Y míg abszolút folytonos eloszlás esetén, ha f(x, y) az együttes, f 1 (x) (f 1 (x) = f(x, y) dy) és f 2 (y) (f 2 (y) = f(x, y) dx) a marginális sűrűségfüggvény, akkor (3.4) jelentése: X Y i X j Y ( ) 2 f(x, y) f 1 (x)f 2 (y) dx dy = f 1 (x)f 2 (y) X Y 29 f 2 (x, y) dx dy <. f 1 (x)f 2 (y)
31 Ilyen feltételek mellett P X és P Y Hilbert Schmidt operátorok, kompaktak, és szinguláris értékfelbontásuk (a továbbiakban SVD): P X = s i., φ i H ψ i, P Y = s i., ψ i H φ i, (3.5) ahol 1 s 1 s 2 0, hiszen P X and P Y megszorított ortogonális vetítések egyik marginálisról (nem az egész térről) a másikra. P X a H -beli konstans 1 valószínűségi változót a H-beli konstans 1-be viszi, de ezeket nem tekintjük függvény párnak 1 szinguláris értékkel, mivel nem 0 várható értékűek. Ezeért 1-et le kell vonni a magból. A [w(x, y) 1] 2 Q(dy)P(dx) = s 2 i < X Y mennyiséget Rényi négyzetes kontingenciának nevezte. Speciálisan, ha W szimmetrikus (H és H izomorf), akkor (3.3) miatt P X = P Y önadjungált: P X : H H spektrálfelbontása: P X φ, ψ H = Cov W (φ, ψ) = Cov W (ψ, φ) = P Y ψ, φ H. P X = λ i., ψ i H ψ i, ahol λ i 1 és P X ψ i = λ i ψ i, ahol ψ i és ψ i azonos eloszlásúak. A Rényi által is vizsgált maximálkorreláció feladata a következő: keresendő ψ H, φ H úgy, hogy korrelációjuk a W egyúttes eloszlás szerint maximális legyen. Kompakt operátorokra vonatkozó szeparációs tételek miatt és eléretik a ψ 1, φ 1 páron. Ekvivalens feladat: max ψ = φ =1 Cov W(ψ, φ) = s 1 min ψ ψ = φ =1 φ 2 = min ψ = φ =1 ( ψ 2 + φ 2 2Cov W (ψ, φ)) = 2(1 s 1 ). Tudjuk, hogy rögzített Ψ H esetén az E(Ψ Φ) 2 együttes eloszlás szerinti várható értéket a Φ H valószínűségi változók körében a Φ = E(Ψ η) feltételes várható érték minimalizálja. Még általánosabban, keressük azt a Ψ H, Φ H változópárt, melyre 30
Principal Component Analysis
 Principal Component Analysis Principal Component Analysis Principal Component Analysis Definíció Ortogonális transzformáció, amely az adatokat egy új koordinátarendszerbe transzformálja úgy, hogy a koordináták
Principal Component Analysis Principal Component Analysis Principal Component Analysis Definíció Ortogonális transzformáció, amely az adatokat egy új koordinátarendszerbe transzformálja úgy, hogy a koordináták
A maximum likelihood becslésről
 A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 3 III. VÉLETLEN VEKTOROK 1. A KÉTDIMENZIÓs VÉLETLEN VEKTOR Definíció: Az leképezést (kétdimenziós) véletlen vektornak nevezzük, ha Definíció:
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 3 III. VÉLETLEN VEKTOROK 1. A KÉTDIMENZIÓs VÉLETLEN VEKTOR Definíció: Az leképezést (kétdimenziós) véletlen vektornak nevezzük, ha Definíció:
Gauss-Jordan módszer Legkisebb négyzetek módszere, egyenes LNM, polinom LNM, függvény. Lineáris algebra numerikus módszerei
 A Gauss-Jordan elimináció, mátrixinvertálás Gauss-Jordan módszer Ugyanazzal a technikával, mint ahogy a k-adik oszlopban az a kk alatti elemeket kinulláztuk, a fölötte lévő elemeket is zérussá lehet tenni.
A Gauss-Jordan elimináció, mátrixinvertálás Gauss-Jordan módszer Ugyanazzal a technikával, mint ahogy a k-adik oszlopban az a kk alatti elemeket kinulláztuk, a fölötte lévő elemeket is zérussá lehet tenni.
Valószínűségi változók. Várható érték és szórás
 Matematikai statisztika gyakorlat Valószínűségi változók. Várható érték és szórás Valószínűségi változók 2016. március 7-11. 1 / 13 Valószínűségi változók Legyen a (Ω, A, P) valószínűségi mező. Egy X :
Matematikai statisztika gyakorlat Valószínűségi változók. Várható érték és szórás Valószínűségi változók 2016. március 7-11. 1 / 13 Valószínűségi változók Legyen a (Ω, A, P) valószínűségi mező. Egy X :
Statisztika - bevezetés Méréselmélet PE MIK MI_BSc VI_BSc 1
 Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Funkcionálanalízis. n=1. n=1. x n y n. n=1
 Funkcionálanalízis 2011/12 tavaszi félév - 2. előadás 1.4. Lényeges alap-terek, példák Sorozat terek (Folytatás.) C: konvergens sorozatok tere. A tér pontjai sorozatok: x = (x n ). Ezen belül C 0 a nullsorozatok
Funkcionálanalízis 2011/12 tavaszi félév - 2. előadás 1.4. Lényeges alap-terek, példák Sorozat terek (Folytatás.) C: konvergens sorozatok tere. A tér pontjai sorozatok: x = (x n ). Ezen belül C 0 a nullsorozatok
Miért fontos számunkra az előző gyakorlaton tárgyalt lineáris algebrai ismeretek
 Az november 23-i szeminárium témája Rövid összefoglaló Miért fontos számunkra az előző gyakorlaton tárgyalt lineáris algebrai ismeretek felfrissítése? Tekintsünk ξ 1,..., ξ k valószínűségi változókat,
Az november 23-i szeminárium témája Rövid összefoglaló Miért fontos számunkra az előző gyakorlaton tárgyalt lineáris algebrai ismeretek felfrissítése? Tekintsünk ξ 1,..., ξ k valószínűségi változókat,
Numerikus módszerek 1.
 Numerikus módszerek 1. 6. előadás: Vektor- és mátrixnormák Lócsi Levente ELTE IK 2013. október 14. Tartalomjegyzék 1 Vektornormák 2 Mátrixnormák 3 Természetes mátrixnormák, avagy indukált normák 4 Mátrixnormák
Numerikus módszerek 1. 6. előadás: Vektor- és mátrixnormák Lócsi Levente ELTE IK 2013. október 14. Tartalomjegyzék 1 Vektornormák 2 Mátrixnormák 3 Természetes mátrixnormák, avagy indukált normák 4 Mátrixnormák
BIOMATEMATIKA ELŐADÁS
 BIOMATEMATIKA ELŐADÁS 9. Együttes eloszlás, kovarianca, nevezetes eloszlások Debreceni Egyetem, 2015 Dr. Bérczes Attila, Bertók Csanád A diasor tartalma 1 Bevezetés, definíciók Együttes eloszlás Függetlenség
BIOMATEMATIKA ELŐADÁS 9. Együttes eloszlás, kovarianca, nevezetes eloszlások Debreceni Egyetem, 2015 Dr. Bérczes Attila, Bertók Csanád A diasor tartalma 1 Bevezetés, definíciók Együttes eloszlás Függetlenség
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
Markov-láncok stacionárius eloszlása
 Markov-láncok stacionárius eloszlása Adatbányászat és Keresés Csoport, MTA SZTAKI dms.sztaki.hu Kiss Tamás 2013. április 11. Tartalom Markov láncok definíciója, jellemzése Visszatérési idők Stacionárius
Markov-láncok stacionárius eloszlása Adatbányászat és Keresés Csoport, MTA SZTAKI dms.sztaki.hu Kiss Tamás 2013. április 11. Tartalom Markov láncok definíciója, jellemzése Visszatérési idők Stacionárius
(Independence, dependence, random variables)
") Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
A következő feladat célja az, hogy egyszerű módon konstruáljunk Poisson folyamatokat.
 Poisson folyamatok, exponenciális eloszlások Azt mondjuk, hogy a ξ valószínűségi változó Poisson eloszlású λ, 0 < λ
Poisson folyamatok, exponenciális eloszlások Azt mondjuk, hogy a ξ valószínűségi változó Poisson eloszlású λ, 0 < λ
Least Squares becslés
 Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Optimalizálás alapfeladata Legmeredekebb lejtő Lagrange függvény Log-barrier módszer Büntetőfüggvény módszer 2017/
 Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 9. Előadás Az optimalizálás alapfeladata Keressük f függvény maximumát ahol f : R n R és
Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 9. Előadás Az optimalizálás alapfeladata Keressük f függvény maximumát ahol f : R n R és
Konjugált gradiens módszer
 Közelítő és szimbolikus számítások 12. gyakorlat Konjugált gradiens módszer Készítette: Gelle Kitti Csendes Tibor Vinkó Tamás Faragó István Horváth Róbert jegyzetei alapján 1 LINEÁRIS EGYENLETRENDSZEREK
Közelítő és szimbolikus számítások 12. gyakorlat Konjugált gradiens módszer Készítette: Gelle Kitti Csendes Tibor Vinkó Tamás Faragó István Horváth Róbert jegyzetei alapján 1 LINEÁRIS EGYENLETRENDSZEREK
Matematika A2 vizsga mgeoldása június 4.
 Matematika A vizsga mgeoldása 03. június.. (a (3 pont Definiálja az f(x, y függvény határértékét az (x 0, y 0 helyen! Megoldás: Legyen D R, f : D R. Legyen az f(x, y függvény értelmezve az (x 0, y 0 pont
Matematika A vizsga mgeoldása 03. június.. (a (3 pont Definiálja az f(x, y függvény határértékét az (x 0, y 0 helyen! Megoldás: Legyen D R, f : D R. Legyen az f(x, y függvény értelmezve az (x 0, y 0 pont
Likelihood, deviancia, Akaike-féle információs kritérium
 Többváltozós statisztika (SZIE ÁOTK, 2011. ősz) 1 Likelihood, deviancia, Akaike-féle információs kritérium Likelihood függvény Az adatokhoz paraméteres modellt illesztünk. A likelihood függvény a megfigyelt
Többváltozós statisztika (SZIE ÁOTK, 2011. ősz) 1 Likelihood, deviancia, Akaike-féle információs kritérium Likelihood függvény Az adatokhoz paraméteres modellt illesztünk. A likelihood függvény a megfigyelt
Alap-ötlet: Karl Friedrich Gauss ( ) valószínűségszámítási háttér: Andrej Markov ( )
 valószínűségszámítási háttér: Andrej Markov ( )") Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Matematikai statisztika c. tárgy oktatásának célja és tematikája
 Matematikai statisztika c. tárgy oktatásának célja és tematikája 2015 Tematika Matematikai statisztika 1. Időkeret: 12 héten keresztül heti 3x50 perc (előadás és szeminárium) 2. Szükséges előismeretek:
Matematikai statisztika c. tárgy oktatásának célja és tematikája 2015 Tematika Matematikai statisztika 1. Időkeret: 12 héten keresztül heti 3x50 perc (előadás és szeminárium) 2. Szükséges előismeretek:
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
0-49 pont: elégtelen, pont: elégséges, pont: közepes, pont: jó, pont: jeles
 Matematika szigorlat, Mérnök informatikus szak I. 2013. jan. 10. Név: Neptun kód: Idő: 180 perc Elm.: 1. f. 2. f. 3. f. 4. f. 5. f. Fel. össz.: Össz.: Oszt.: Az elérhető pontszám 40 (elmélet) + 60 (feladatok)
Matematika szigorlat, Mérnök informatikus szak I. 2013. jan. 10. Név: Neptun kód: Idő: 180 perc Elm.: 1. f. 2. f. 3. f. 4. f. 5. f. Fel. össz.: Össz.: Oszt.: Az elérhető pontszám 40 (elmélet) + 60 (feladatok)
Saj at ert ek-probl em ak febru ar 26.
 Sajátérték-problémák 2018. február 26. Az alapfeladat Adott a következő egyenlet: Av = λv, (1) ahol A egy ismert mátrix v ismeretlen, nem zérus vektor λ ismeretlen szám Azok a v, λ kombinációk, amikre
Sajátérték-problémák 2018. február 26. Az alapfeladat Adott a következő egyenlet: Av = λv, (1) ahol A egy ismert mátrix v ismeretlen, nem zérus vektor λ ismeretlen szám Azok a v, λ kombinációk, amikre
Nagy-György Judit. Szegedi Tudományegyetem, Bolyai Intézet
 Többváltozós statisztika Szegedi Tudományegyetem, Bolyai Intézet Többváltozós módszerek Ezek a módszerek több változó együttes vizsgálatára vonatkoznak. Alapvető típusaik: többdimenziós eloszlásokra vonatkozó
Többváltozós statisztika Szegedi Tudományegyetem, Bolyai Intézet Többváltozós módszerek Ezek a módszerek több változó együttes vizsgálatára vonatkoznak. Alapvető típusaik: többdimenziós eloszlásokra vonatkozó
Sorozatok, sorok, függvények határértéke és folytonossága Leindler Schipp - Analízis I. könyve + jegyzetek, kidolgozások alapján
 Sorozatok, sorok, függvények határértéke és folytonossága Leindler Schipp - Analízis I. könyve + jegyzetek, kidolgozások alapján Számsorozatok, vektorsorozatok konvergenciája Def.: Számsorozatok értelmezése:
Sorozatok, sorok, függvények határértéke és folytonossága Leindler Schipp - Analízis I. könyve + jegyzetek, kidolgozások alapján Számsorozatok, vektorsorozatok konvergenciája Def.: Számsorozatok értelmezése:
Vektorterek. =a gyakorlatokon megoldásra ajánlott
 Vektorterek =a gyakorlatokon megoldásra ajánlott 40. Alteret alkotnak-e a valós R 5 vektortérben a megadott részhalmazok? Ha igen, akkor hány dimenziósak? (a) L = { (x 1, x 2, x 3, x 4, x 5 ) x 1 = x 5,
Vektorterek =a gyakorlatokon megoldásra ajánlott 40. Alteret alkotnak-e a valós R 5 vektortérben a megadott részhalmazok? Ha igen, akkor hány dimenziósak? (a) L = { (x 1, x 2, x 3, x 4, x 5 ) x 1 = x 5,
Gyakorló feladatok I.
 Gyakorló feladatok I. a Matematika Aa Vektorüggvények tárgyhoz (D D5 kurzusok) Összeállította: Szili László Ajánlott irodalmak:. G.B. Thomas, M.D. Weir, J. Hass, F.R. Giordano: Thomas-féle KALKULUS I.,
Gyakorló feladatok I. a Matematika Aa Vektorüggvények tárgyhoz (D D5 kurzusok) Összeállította: Szili László Ajánlott irodalmak:. G.B. Thomas, M.D. Weir, J. Hass, F.R. Giordano: Thomas-féle KALKULUS I.,
Fraktálok. Kontrakciók Affin leképezések. Czirbusz Sándor ELTE IK, Komputeralgebra Tanszék. TARTALOMJEGYZÉK Kontrakciók Affin transzformációk
 Fraktálok Kontrakciók Affin leképezések Czirbusz Sándor ELTE IK, Komputeralgebra Tanszék TARTALOMJEGYZÉK 1 of 71 A Lipschitz tulajdonság ÁTMÉRŐ, PONT ÉS HALMAZ TÁVOLSÁGA Definíció Az (S, ρ) metrikus tér
Fraktálok Kontrakciók Affin leképezések Czirbusz Sándor ELTE IK, Komputeralgebra Tanszék TARTALOMJEGYZÉK 1 of 71 A Lipschitz tulajdonság ÁTMÉRŐ, PONT ÉS HALMAZ TÁVOLSÁGA Definíció Az (S, ρ) metrikus tér
10. Előadás. 1. Feltétel nélküli optimalizálás: Az eljárás alapjai
 Optimalizálási eljárások MSc hallgatók számára 10. Előadás Előadó: Hajnal Péter Jegyzetelő: T. Szabó Tamás 2011. április 20. 1. Feltétel nélküli optimalizálás: Az eljárás alapjai A feltétel nélküli optimalizálásnál
Optimalizálási eljárások MSc hallgatók számára 10. Előadás Előadó: Hajnal Péter Jegyzetelő: T. Szabó Tamás 2011. április 20. 1. Feltétel nélküli optimalizálás: Az eljárás alapjai A feltétel nélküli optimalizálásnál
(1 + (y ) 2 = f(x). Határozzuk meg a rúd alakját, ha a nyomaték eloszlás. (y ) 2 + 2yy = 0,
 2 = f(x). Határozzuk meg a rúd alakját, ha a nyomaték eloszlás. (y ) 2 + 2yy = 0,") Feladatok az 5. hétre. Eredményekkel és kidolgozott megoldásokkal. Oldjuk meg az alábbi másodrend lineáris homogén d.e. - et, tudva, hogy egy megoldása az y = x! x y xy + y = 0.. Oldjuk meg a következ
Feladatok az 5. hétre. Eredményekkel és kidolgozott megoldásokkal. Oldjuk meg az alábbi másodrend lineáris homogén d.e. - et, tudva, hogy egy megoldása az y = x! x y xy + y = 0.. Oldjuk meg a következ
Elméleti összefoglaló a Valószín ségszámítás kurzushoz
 Elméleti összefoglaló a Valószín ségszámítás kurzushoz Véletlen kísérletek, események valószín sége Deníció. Egy véletlen kísérlet lehetséges eredményeit kimeneteleknek nevezzük. A kísérlet kimeneteleinek
Elméleti összefoglaló a Valószín ségszámítás kurzushoz Véletlen kísérletek, események valószín sége Deníció. Egy véletlen kísérlet lehetséges eredményeit kimeneteleknek nevezzük. A kísérlet kimeneteleinek
4. Az A és B események egymást kizáró eseményeknek vagy idegen (diszjunkt)eseményeknek nevezzük, ha AB=O
eseményeknek nevezzük, ha AB=O") 1. Mit nevezünk elemi eseménynek és eseménytérnek? A kísérlet lehetséges kimeneteleit elemi eseményeknek nevezzük. Az adott kísélethez tartozó elemi események halmazát eseménytérnek nevezzük, jele: X 2.
1. Mit nevezünk elemi eseménynek és eseménytérnek? A kísérlet lehetséges kimeneteleit elemi eseményeknek nevezzük. Az adott kísélethez tartozó elemi események halmazát eseménytérnek nevezzük, jele: X 2.
A sorozat fogalma. függvényeket sorozatoknak nevezzük. Amennyiben az értékkészlet. az értékkészlet a komplex számok halmaza, akkor komplex
 A sorozat fogalma Definíció. A természetes számok N halmazán értelmezett függvényeket sorozatoknak nevezzük. Amennyiben az értékkészlet a valós számok halmaza, valós számsorozatról beszélünk, mígha az
A sorozat fogalma Definíció. A természetes számok N halmazán értelmezett függvényeket sorozatoknak nevezzük. Amennyiben az értékkészlet a valós számok halmaza, valós számsorozatról beszélünk, mígha az
Gauss-Seidel iteráció
 Közelítő és szimbolikus számítások 5. gyakorlat Iterációs módszerek: Jacobi és Gauss-Seidel iteráció Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor London András Deák Gábor jegyzetei alapján 1 ITERÁCIÓS
Közelítő és szimbolikus számítások 5. gyakorlat Iterációs módszerek: Jacobi és Gauss-Seidel iteráció Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor London András Deák Gábor jegyzetei alapján 1 ITERÁCIÓS
Véletlen jelenség: okok rendszere hozza létre - nem ismerhetjük mind, ezért sztochasztikus.
 Valószín ségelméleti és matematikai statisztikai alapfogalmak összefoglalása (Kemény Sándor - Deák András: Mérések tervezése és eredményeik értékelése, kivonat) Véletlen jelenség: okok rendszere hozza
Valószín ségelméleti és matematikai statisztikai alapfogalmak összefoglalása (Kemény Sándor - Deák András: Mérések tervezése és eredményeik értékelése, kivonat) Véletlen jelenség: okok rendszere hozza
3. Lineáris differenciálegyenletek
 3. Lineáris differenciálegyenletek A közönséges differenciálegyenletek két nagy csoportba oszthatók lineáris és nemlineáris egyenletek csoportjába. Ez a felbontás kicsit önkényesnek tűnhet, a megoldásra
3. Lineáris differenciálegyenletek A közönséges differenciálegyenletek két nagy csoportba oszthatók lineáris és nemlineáris egyenletek csoportjába. Ez a felbontás kicsit önkényesnek tűnhet, a megoldásra
Készítette: Fegyverneki Sándor
 VALÓSZÍNŰSÉGSZÁMÍTÁS Összefoglaló segédlet Készítette: Fegyverneki Sándor Miskolci Egyetem, 2001. i JELÖLÉSEK: N a természetes számok halmaza (pozitív egészek) R a valós számok halmaza R 2 {(x, y) x, y
VALÓSZÍNŰSÉGSZÁMÍTÁS Összefoglaló segédlet Készítette: Fegyverneki Sándor Miskolci Egyetem, 2001. i JELÖLÉSEK: N a természetes számok halmaza (pozitív egészek) R a valós számok halmaza R 2 {(x, y) x, y
Abszolút folytonos valószín ségi változó (4. el adás)
") Abszolút folytonos valószín ségi változó (4. el adás) Deníció (Abszolút folytonosság és s r ségfüggvény) Az X valószín ségi változó abszolút folytonos, ha van olyan f : R R függvény, melyre P(X t) = t
Abszolút folytonos valószín ségi változó (4. el adás) Deníció (Abszolút folytonosság és s r ségfüggvény) Az X valószín ségi változó abszolút folytonos, ha van olyan f : R R függvény, melyre P(X t) = t
Gyak. vez.: Palincza Richárd ( Gyakorlatok ideje/helye: CS , QBF10
 Intervallumek Matematikai statisztika Gazdaságinformatikus MSc 1. előadás 2018. szeptember 3. 1/53 - Előadó, hely, idő etc. Intervallumek Előadó: Vizer Máté (email: mmvizer@gmail.com) Előadások ideje/helye:
Intervallumek Matematikai statisztika Gazdaságinformatikus MSc 1. előadás 2018. szeptember 3. 1/53 - Előadó, hely, idő etc. Intervallumek Előadó: Vizer Máté (email: mmvizer@gmail.com) Előadások ideje/helye:
Elméleti összefoglaló a Sztochasztika alapjai kurzushoz
 Elméleti összefoglaló a Sztochasztika alapjai kurzushoz 1. dolgozat Véletlen kísérletek, események valószín sége Deníció. Egy véletlen kísérlet lehetséges eredményeit kimeneteleknek nevezzük. A kísérlet
Elméleti összefoglaló a Sztochasztika alapjai kurzushoz 1. dolgozat Véletlen kísérletek, események valószín sége Deníció. Egy véletlen kísérlet lehetséges eredményeit kimeneteleknek nevezzük. A kísérlet
Mesterséges Intelligencia I.
 Mesterséges Intelligencia I. 10. elıadás (2008. november 10.) Készítette: Romhányi Anita (ROANAAT.SZE) - 1 - Statisztikai tanulás (Megfigyelések alapján történı bizonytalan következetésnek tekintjük a
Mesterséges Intelligencia I. 10. elıadás (2008. november 10.) Készítette: Romhányi Anita (ROANAAT.SZE) - 1 - Statisztikai tanulás (Megfigyelések alapján történı bizonytalan következetésnek tekintjük a
Line aris f uggv enyilleszt es m arcius 19.
 Lineáris függvényillesztés 2018. március 19. Illesztett paraméterek hibája Eddig azt néztük, hogy a mérési hiba hogyan propagál az illesztett paraméterekbe, ha van egy konkrét függvényünk. a hibaterjedés
Lineáris függvényillesztés 2018. március 19. Illesztett paraméterek hibája Eddig azt néztük, hogy a mérési hiba hogyan propagál az illesztett paraméterekbe, ha van egy konkrét függvényünk. a hibaterjedés
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
Kvadratikus alakok és euklideszi terek (előadásvázlat, október 5.) Maróti Miklós, Kátai-Urbán Kamilla
 Maróti Miklós, Kátai-Urbán Kamilla") Kvadratikus alakok és euklideszi terek (előadásvázlat, 0. október 5.) Maróti Miklós, Kátai-Urbán Kamilla Az előadáshoz ajánlott jegyzet: Szabó László: Bevezetés a lineáris algebrába, Polygon Kiadó, Szeged,
Kvadratikus alakok és euklideszi terek (előadásvázlat, 0. október 5.) Maróti Miklós, Kátai-Urbán Kamilla Az előadáshoz ajánlott jegyzet: Szabó László: Bevezetés a lineáris algebrába, Polygon Kiadó, Szeged,
Gazdasági matematika II. vizsgadolgozat megoldása, június 10
 Gazdasági matematika II. vizsgadolgozat megoldása, 204. június 0 A dolgozatírásnál íróeszközön kívül más segédeszköz nem használható. A dolgozat időtartama: 90 perc. Ha a dolgozat első részéből szerzett
Gazdasági matematika II. vizsgadolgozat megoldása, 204. június 0 A dolgozatírásnál íróeszközön kívül más segédeszköz nem használható. A dolgozat időtartama: 90 perc. Ha a dolgozat első részéből szerzett
Numerikus módszerek beugró kérdések
 1. Definiálja a gépi számok halmazát (a tanult modellnek megfelelően)! Adja meg a normalizált lebegőpontos szám alakját. (4 pont) Az alakú számot normalizált lebegőpontos számnak nevezik, ha Ahol,,,. Jelöl:
1. Definiálja a gépi számok halmazát (a tanult modellnek megfelelően)! Adja meg a normalizált lebegőpontos szám alakját. (4 pont) Az alakú számot normalizált lebegőpontos számnak nevezik, ha Ahol,,,. Jelöl:
EM-ALGORITMUS HIÁNYOS ADATRENDSZEREKRE
 Süvítenek napjank, a forró sortüzek valamt mnden nap elmulasztunk. Robotolunk lélekszakadva, jóttevőn, s valamt mnden tettben elmulasztunk... (Vác Mhály: Valam nncs sehol) EM-ALGORITMUS HIÁNYOS ADATRENDSZEREKRE
Süvítenek napjank, a forró sortüzek valamt mnden nap elmulasztunk. Robotolunk lélekszakadva, jóttevőn, s valamt mnden tettben elmulasztunk... (Vác Mhály: Valam nncs sehol) EM-ALGORITMUS HIÁNYOS ADATRENDSZEREKRE
1. Példa. A gamma függvény és a Fubini-tétel.
 . Példa. A gamma függvény és a Fubini-tétel.. Az x exp x + t )) függvény az x, t tartományon folytonos, és nem negatív, ezért alkalmazható rá a Fubini-tétel. I x exp x + t )) dxdt + t dt π 4. [ exp x +
. Példa. A gamma függvény és a Fubini-tétel.. Az x exp x + t )) függvény az x, t tartományon folytonos, és nem negatív, ezért alkalmazható rá a Fubini-tétel. I x exp x + t )) dxdt + t dt π 4. [ exp x +
Matematikai alapok és valószínőségszámítás. Statisztikai becslés Statisztikák eloszlása
 Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
A szimplex algoritmus
 A szimplex algoritmus Ismétlés: reprezentációs tétel, az optimális megoldás és az extrém pontok kapcsolata Alapfogalmak: bázisok, bázismegoldások, megengedett bázismegoldások, degenerált bázismegoldás
A szimplex algoritmus Ismétlés: reprezentációs tétel, az optimális megoldás és az extrém pontok kapcsolata Alapfogalmak: bázisok, bázismegoldások, megengedett bázismegoldások, degenerált bázismegoldás
Statisztikai következtetések Nemlineáris regresszió Feladatok Vége
 [GVMGS11MNC] Gazdaságstatisztika 10. előadás: 9. Regressziószámítás II. Kóczy Á. László koczy.laszlo@kgk.uni-obuda.hu Keleti Károly Gazdasági Kar Vállalkozásmenedzsment Intézet A standard lineáris modell
[GVMGS11MNC] Gazdaságstatisztika 10. előadás: 9. Regressziószámítás II. Kóczy Á. László koczy.laszlo@kgk.uni-obuda.hu Keleti Károly Gazdasági Kar Vállalkozásmenedzsment Intézet A standard lineáris modell
1. Generátorrendszer. Házi feladat (fizikából tudjuk) Ha v és w nem párhuzamos síkvektorok, akkor generátorrendszert alkotnak a sík vektorainak
 Ha v és w nem párhuzamos síkvektorok, akkor generátorrendszert alkotnak a sík vektorainak") 1. Generátorrendszer Generátorrendszer. Tétel (Freud, 4.3.4. Tétel) Legyen V vektortér a T test fölött és v 1,v 2,...,v m V. Ekkor a λ 1 v 1 + λ 2 v 2 +... + λ m v m alakú vektorok, ahol λ 1,λ 2,...,λ
1. Generátorrendszer Generátorrendszer. Tétel (Freud, 4.3.4. Tétel) Legyen V vektortér a T test fölött és v 1,v 2,...,v m V. Ekkor a λ 1 v 1 + λ 2 v 2 +... + λ m v m alakú vektorok, ahol λ 1,λ 2,...,λ
x, x R, x rögzített esetén esemény. : ( ) x Valószínűségi Változó: Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel:
 x Valószínűségi Változó: Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel:") Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel: Valószínűségi változó általános fogalma: A : R leképezést valószínűségi változónak nevezzük, ha : ( ) x, x R, x rögzített esetén esemény.
Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel: Valószínűségi változó általános fogalma: A : R leképezést valószínűségi változónak nevezzük, ha : ( ) x, x R, x rögzített esetén esemény.
LINEÁRIS MODELLBEN május. 1. Lineáris modell, legkisebb négyzetek elve
 BECSLÉS ÉS HIPOTÉZISVIZSGÁLAT LINEÁRIS MODELLBEN Móri Tamás ELTE TTK Valószínűségelméleti és Statisztika Tanszék 2008 május Lineáris modell, legkisebb négyzetek elve Tegyük fel, hogy egy bizonyos pl fizikai)
BECSLÉS ÉS HIPOTÉZISVIZSGÁLAT LINEÁRIS MODELLBEN Móri Tamás ELTE TTK Valószínűségelméleti és Statisztika Tanszék 2008 május Lineáris modell, legkisebb négyzetek elve Tegyük fel, hogy egy bizonyos pl fizikai)
Numerikus módszerek 1.
 Numerikus módszerek 1. 10. előadás: Nemlineáris egyenletek numerikus megoldása Lócsi Levente ELTE IK 2013. november 18. Tartalomjegyzék 1 Bolzano-tétel, intervallumfelezés 2 Fixponttételek, egyszerű iterációk
Numerikus módszerek 1. 10. előadás: Nemlineáris egyenletek numerikus megoldása Lócsi Levente ELTE IK 2013. november 18. Tartalomjegyzék 1 Bolzano-tétel, intervallumfelezés 2 Fixponttételek, egyszerű iterációk
LNM folytonos Az interpoláció Lagrange interpoláció. Lineáris algebra numerikus módszerei
 Legkisebb négyzetek módszere, folytonos eset Folytonos eset Legyen f C[a, b]és h(x) = a 1 φ 1 (x) + a 2 φ 2 (x) +... + a n φ n (x). Ekkor tehát az n 2 F (a 1,..., a n ) = f a i φ i = = b a i=1 f (x) 2
Legkisebb négyzetek módszere, folytonos eset Folytonos eset Legyen f C[a, b]és h(x) = a 1 φ 1 (x) + a 2 φ 2 (x) +... + a n φ n (x). Ekkor tehát az n 2 F (a 1,..., a n ) = f a i φ i = = b a i=1 f (x) 2
Megoldások. ξ jelölje az első meghibásodásig eltelt időt. Akkor ξ N(6, 4; 2, 3) normális eloszlású P (ξ
 normális eloszlású P (ξ") Megoldások Harmadik fejezet gyakorlatai 3.. gyakorlat megoldása ξ jelölje az első meghibásodásig eltelt időt. Akkor ξ N(6, 4;, 3 normális eloszlású P (ξ 8 ξ 5 feltételes valószínűségét (.3. alapján számoljuk.
Megoldások Harmadik fejezet gyakorlatai 3.. gyakorlat megoldása ξ jelölje az első meghibásodásig eltelt időt. Akkor ξ N(6, 4;, 3 normális eloszlású P (ξ 8 ξ 5 feltételes valószínűségét (.3. alapján számoljuk.
Lineáris regressziós modellek 1
 Lineáris regressziós modellek 1 Ispány Márton és Jeszenszky Péter 2016. szeptember 19. 1 Az ábrák C.M. Bishop: Pattern Recognition and Machine Learning c. könyvéből származnak. Tartalom Bevezető példák
Lineáris regressziós modellek 1 Ispány Márton és Jeszenszky Péter 2016. szeptember 19. 1 Az ábrák C.M. Bishop: Pattern Recognition and Machine Learning c. könyvéből származnak. Tartalom Bevezető példák
A valószínűségszámítás elemei
 A valószínűségszámítás elemei Kísérletsorozatban az esemény relatív gyakorisága: k/n, ahol k az esemény bekövetkezésének abszolút gyakorisága, n a kísérletek száma. Pl. Jelenség: kockadobás Megfigyelés:
A valószínűségszámítás elemei Kísérletsorozatban az esemény relatív gyakorisága: k/n, ahol k az esemény bekövetkezésének abszolút gyakorisága, n a kísérletek száma. Pl. Jelenség: kockadobás Megfigyelés:
Megoldott feladatok november 30. n+3 szigorúan monoton csökken, 5. n+3. lim a n = lim. n+3 = 2n+3 n+4 2n+1
 Megoldott feladatok 00. november 0.. Feladat: Vizsgáljuk az a n = n+ n+ sorozat monotonitását, korlátosságát és konvergenciáját. Konvergencia esetén számítsuk ki a határértéket! : a n = n+ n+ = n+ n+ =
Megoldott feladatok 00. november 0.. Feladat: Vizsgáljuk az a n = n+ n+ sorozat monotonitását, korlátosságát és konvergenciáját. Konvergencia esetén számítsuk ki a határértéket! : a n = n+ n+ = n+ n+ =
Gazdasági matematika II. tanmenet
 Gazdasági matematika II. tanmenet Mádi-Nagy Gergely A hivatkozásokban az alábbi tankönyvekre utalunk: T: Tóth Irén (szerk.): Operációkutatás I., Nemzeti Tankönyvkiadó 1987. Cs: Csernyák László (szerk.):
Gazdasági matematika II. tanmenet Mádi-Nagy Gergely A hivatkozásokban az alábbi tankönyvekre utalunk: T: Tóth Irén (szerk.): Operációkutatás I., Nemzeti Tankönyvkiadó 1987. Cs: Csernyák László (szerk.):
Matematikai statisztika I. témakör: Valószínűségszámítási ismétlés
 Matematikai statisztika I. témakör: Valószínűségszámítási ismétlés Elek Péter 1. Valószínűségi változók és eloszlások 1.1. Egyváltozós eset Ismétlés: valószínűség fogalma Valószínűségekre vonatkozó axiómák
Matematikai statisztika I. témakör: Valószínűségszámítási ismétlés Elek Péter 1. Valószínűségi változók és eloszlások 1.1. Egyváltozós eset Ismétlés: valószínűség fogalma Valószínűségekre vonatkozó axiómák
17. előadás: Vektorok a térben
 17. előadás: Vektorok a térben Szabó Szilárd A vektor fogalma A mai előadásban n 1 tetszőleges egész szám lehet, de az egyszerűség kedvéért a képletek az n = 2 esetben szerepelnek. Vektorok: rendezett
17. előadás: Vektorok a térben Szabó Szilárd A vektor fogalma A mai előadásban n 1 tetszőleges egész szám lehet, de az egyszerűség kedvéért a képletek az n = 2 esetben szerepelnek. Vektorok: rendezett
Valószínűségszámítás összefoglaló
 Statisztikai módszerek BMEGEVGAT Készítette: Halász Gábor Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel:
Statisztikai módszerek BMEGEVGAT Készítette: Halász Gábor Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel:
Feladatok a Gazdasági matematika II. tárgy gyakorlataihoz
 Debreceni Egyetem Közgazdaságtudományi Kar Feladatok a Gazdasági matematika II tárgy gyakorlataihoz a megoldásra ajánlott feladatokat jelöli e feladatokat a félév végére megoldottnak tekintjük a nehezebb
Debreceni Egyetem Közgazdaságtudományi Kar Feladatok a Gazdasági matematika II tárgy gyakorlataihoz a megoldásra ajánlott feladatokat jelöli e feladatokat a félév végére megoldottnak tekintjük a nehezebb
Matematika (mesterképzés)
") Matematika (mesterképzés) Környezet- és Településmérnököknek Debreceni Egyetem Műszaki Kar, Műszaki Alaptárgyi Tanszék Vinczéné Varga A. Környezet- és Településmérnököknek 2016/2017/I 1 / 29 Lineáris tér,
Matematika (mesterképzés) Környezet- és Településmérnököknek Debreceni Egyetem Műszaki Kar, Műszaki Alaptárgyi Tanszék Vinczéné Varga A. Környezet- és Településmérnököknek 2016/2017/I 1 / 29 Lineáris tér,
1 Lebegőpontos számábrázolás
 Tartalom 1 Lebegőpontos számábrázolás... 2 2 Vektornormák... 4 3 Indukált mátrixnormák és tulajdonságaik... 5 4 A lineáris rendszer jobboldala hibás... 6 5 A kondíciószám és tulajdonságai... 7 6 Perturbációs
Tartalom 1 Lebegőpontos számábrázolás... 2 2 Vektornormák... 4 3 Indukált mátrixnormák és tulajdonságaik... 5 4 A lineáris rendszer jobboldala hibás... 6 5 A kondíciószám és tulajdonságai... 7 6 Perturbációs
e (t µ) 2 f (t) = 1 F (t) = 1 Normális eloszlás negyedik centrális momentuma:
 2 f (t) = 1 F (t) = 1 Normális eloszlás negyedik centrális momentuma:") Normális eloszlás ξ valószínűségi változó normális eloszlású. ξ N ( µ, σ 2) Paraméterei: µ: várható érték, σ 2 : szórásnégyzet (µ tetszőleges, σ 2 tetszőleges pozitív valós szám) Normális eloszlás sűrűségfüggvénye:
Normális eloszlás ξ valószínűségi változó normális eloszlású. ξ N ( µ, σ 2) Paraméterei: µ: várható érték, σ 2 : szórásnégyzet (µ tetszőleges, σ 2 tetszőleges pozitív valós szám) Normális eloszlás sűrűségfüggvénye:
Numerikus módszerek 1.
 Numerikus módszerek 1. 9. előadás: Paraméteres iterációk, relaxációs módszerek Lócsi Levente ELTE IK Tartalomjegyzék 1 A Richardson-iteráció 2 Relaxált Jacobi-iteráció 3 Relaxált Gauss Seidel-iteráció
Numerikus módszerek 1. 9. előadás: Paraméteres iterációk, relaxációs módszerek Lócsi Levente ELTE IK Tartalomjegyzék 1 A Richardson-iteráció 2 Relaxált Jacobi-iteráció 3 Relaxált Gauss Seidel-iteráció
Boros Zoltán február
 Többváltozós függvények differenciál- és integrálszámítása (2 3. előadás) Boros Zoltán 209. február 9 26.. Vektorváltozós függvények differenciálhatósága és iránymenti deriváltjai A továbbiakban D R n
Többváltozós függvények differenciál- és integrálszámítása (2 3. előadás) Boros Zoltán 209. február 9 26.. Vektorváltozós függvények differenciálhatósága és iránymenti deriváltjai A továbbiakban D R n
egyenletesen, és c olyan színű golyót teszünk az urnába, amilyen színűt húztunk. Bizonyítsuk
 Valószínűségszámítás 8. feladatsor 2015. november 26. 1. Bizonyítsuk be, hogy az alábbi folyamatok mindegyike martingál. a S n, Sn 2 n, Y n = t n 1+ 1 t 2 Sn, t Fn = σ S 1,..., S n, 0 < t < 1 rögzített,
Valószínűségszámítás 8. feladatsor 2015. november 26. 1. Bizonyítsuk be, hogy az alábbi folyamatok mindegyike martingál. a S n, Sn 2 n, Y n = t n 1+ 1 t 2 Sn, t Fn = σ S 1,..., S n, 0 < t < 1 rögzített,
Bevezetés az algebrába 2 Vektor- és mátrixnorma
 Bevezetés az algebrába 2 Vektor- és mátrixnorma Wettl Ferenc Algebra Tanszék B U D A P E S T I M Ű S Z A K I M A T E M A T I K A É S G A Z D A S Á G T U D O M Á N Y I I N T É Z E T E G Y E T E M 2016.
Bevezetés az algebrába 2 Vektor- és mátrixnorma Wettl Ferenc Algebra Tanszék B U D A P E S T I M Ű S Z A K I M A T E M A T I K A É S G A Z D A S Á G T U D O M Á N Y I I N T É Z E T E G Y E T E M 2016.
A Statisztika alapjai
 A Statisztika alapjai BME A3c Magyar Róbert 2016.05.12. Mi az a Statisztika? A statisztika a valóság számszerű információinak megfigyelésére, összegzésére, elemzésére és modellezésére irányuló gyakorlati
A Statisztika alapjai BME A3c Magyar Róbert 2016.05.12. Mi az a Statisztika? A statisztika a valóság számszerű információinak megfigyelésére, összegzésére, elemzésére és modellezésére irányuló gyakorlati
Centrális határeloszlás-tétel
 13. fejezet Centrális határeloszlás-tétel A valószínűségszámítás legfontosabb állításai azok, amelyek független valószínűségi változók normalizált összegeire vonatkoznak. A legfontosabb ilyen tételek a
13. fejezet Centrális határeloszlás-tétel A valószínűségszámítás legfontosabb állításai azok, amelyek független valószínűségi változók normalizált összegeire vonatkoznak. A legfontosabb ilyen tételek a
Biomatematika 12. Szent István Egyetem Állatorvos-tudományi Kar. Fodor János
 Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Általánosan, bármilyen mérés annyit jelent, mint meghatározni, hányszor van meg
 LMeasurement.tex, March, 00 Mérés Általánosan, bármilyen mérés annyit jelent, mint meghatározni, hányszor van meg a mérendő mennyiségben egy másik, a mérendővel egynemű, önkényesen egységnek választott
LMeasurement.tex, March, 00 Mérés Általánosan, bármilyen mérés annyit jelent, mint meghatározni, hányszor van meg a mérendő mennyiségben egy másik, a mérendővel egynemű, önkényesen egységnek választott
1. feladatsor: Vektorterek, lineáris kombináció, mátrixok, determináns (megoldás)
") Matematika A2c gyakorlat Vegyészmérnöki, Biomérnöki, Környezetmérnöki szakok, 2017/18 ősz 1. feladatsor: Vektorterek, lineáris kombináció, mátrixok, determináns (megoldás) 1. Valós vektorterek-e a következő
Matematika A2c gyakorlat Vegyészmérnöki, Biomérnöki, Környezetmérnöki szakok, 2017/18 ősz 1. feladatsor: Vektorterek, lineáris kombináció, mátrixok, determináns (megoldás) 1. Valós vektorterek-e a következő
Gazdasági matematika II. vizsgadolgozat, megoldással,
 Gazdasági matematika II. vizsgadolgozat, megoldással, levelező képzés Definiálja az alábbi fogalmakat! 1. Kvadratikus mátrix invertálhatósága és inverze. (4 pont) Egy A kvadratikus mátrixot invertálhatónak
Gazdasági matematika II. vizsgadolgozat, megoldással, levelező képzés Definiálja az alábbi fogalmakat! 1. Kvadratikus mátrix invertálhatósága és inverze. (4 pont) Egy A kvadratikus mátrixot invertálhatónak
CHT& NSZT Hoeffding NET mom. stabilis. 2011. november 9.
 CHT& NSZT Hoeffding NET mom. stabilis Becslések, határeloszlás tételek Székely Balázs 2011. november 9. CHT& NSZT Hoeffding NET mom. stabilis 1 CHT és NSZT 2 Hoeffding-egyenlőtlenség Alkalmazása: Beengedés
CHT& NSZT Hoeffding NET mom. stabilis Becslések, határeloszlás tételek Székely Balázs 2011. november 9. CHT& NSZT Hoeffding NET mom. stabilis 1 CHT és NSZT 2 Hoeffding-egyenlőtlenség Alkalmazása: Beengedés
A fontosabb definíciók
 A legfontosabb definíciókat jelöli. A fontosabb definíciók [Descartes szorzat] Az A és B halmazok Descartes szorzatán az A és B elemeiből képezett összes (a, b) a A, b B rendezett párok halmazát értjük,
A legfontosabb definíciókat jelöli. A fontosabb definíciók [Descartes szorzat] Az A és B halmazok Descartes szorzatán az A és B elemeiből képezett összes (a, b) a A, b B rendezett párok halmazát értjük,
Lineáris algebra numerikus módszerei
 Hermite interpoláció Tegyük fel, hogy az x 0, x 1,..., x k [a, b] különböző alappontok (k n), továbbá m 0, m 1,..., m k N multiplicitások úgy, hogy Legyenek adottak k m i = n + 1. i=0 f (j) (x i ) = y
Hermite interpoláció Tegyük fel, hogy az x 0, x 1,..., x k [a, b] különböző alappontok (k n), továbbá m 0, m 1,..., m k N multiplicitások úgy, hogy Legyenek adottak k m i = n + 1. i=0 f (j) (x i ) = y
6. gyakorlat. Gelle Kitti. Csendes Tibor Somogyi Viktor. London András. jegyzetei alapján
 Közelítő és szimbolikus számítások 6. gyakorlat Sajátérték, Gersgorin körök Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor Vinkó Tamás London András Deák Gábor jegyzetei alapján . Mátrixok sajátértékei
Közelítő és szimbolikus számítások 6. gyakorlat Sajátérték, Gersgorin körök Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor Vinkó Tamás London András Deák Gábor jegyzetei alapján . Mátrixok sajátértékei
Közösség detektálás gráfokban
 Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
Nagy számok törvényei Statisztikai mintavétel Várható érték becslése. Dr. Berta Miklós Fizika és Kémia Tanszék Széchenyi István Egyetem
 agy számok törvényei Statisztikai mintavétel Várható érték becslése Dr. Berta Miklós Fizika és Kémia Tanszék Széchenyi István Egyetem A mérés mint statisztikai mintavétel A méréssel az eloszlásfüggvénnyel
agy számok törvényei Statisztikai mintavétel Várható érték becslése Dr. Berta Miklós Fizika és Kémia Tanszék Széchenyi István Egyetem A mérés mint statisztikai mintavétel A méréssel az eloszlásfüggvénnyel
Nemlineáris programozás 2.
 Optimumszámítás Nemlineáris programozás 2. Többváltozós optimalizálás feltételek mellett. Lagrange-feladatok. Nemlineáris programozás. A Kuhn-Tucker feltételek. Konvex programozás. Sydsaeter-Hammond: 18.1-5,
Optimumszámítás Nemlineáris programozás 2. Többváltozós optimalizálás feltételek mellett. Lagrange-feladatok. Nemlineáris programozás. A Kuhn-Tucker feltételek. Konvex programozás. Sydsaeter-Hammond: 18.1-5,
[Biomatematika 2] Orvosi biometria
![[Biomatematika 2] Orvosi biometria](/thumbs/54/34131233.jpg "[Biomatematika 2] Orvosi biometria") [Biomatematika 2] Orvosi biometria 2016.02.22. Valószínűségi változó Véletlentől függő számértékeket (értékek sokasága) felvevő változókat valószínűségi változóknak nevezzük(jelölés: ξ, η, x). (pl. x =
[Biomatematika 2] Orvosi biometria 2016.02.22. Valószínűségi változó Véletlentől függő számértékeket (értékek sokasága) felvevő változókat valószínűségi változóknak nevezzük(jelölés: ξ, η, x). (pl. x =
Szélsőérték-számítás
 Szélsőérték-számítás Jelölések A következő jelölések mind az f függvény x szerinti parciális deriváltját jelentik: Ugyanígy az f függvény y szerinti parciális deriváltja: f x = xf = f x f y = yf = f y
Szélsőérték-számítás Jelölések A következő jelölések mind az f függvény x szerinti parciális deriváltját jelentik: Ugyanígy az f függvény y szerinti parciális deriváltja: f x = xf = f x f y = yf = f y
3. Fuzzy aritmetika. Gépi intelligencia I. Fodor János NIMGI1MIEM BMF NIK IMRI
 3. Fuzzy aritmetika Gépi intelligencia I. Fodor János BMF NIK IMRI NIMGI1MIEM Tartalomjegyzék I 1 Intervallum-aritmetika 2 Fuzzy intervallumok és fuzzy számok Fuzzy intervallumok LR fuzzy intervallumok
3. Fuzzy aritmetika Gépi intelligencia I. Fodor János BMF NIK IMRI NIMGI1MIEM Tartalomjegyzék I 1 Intervallum-aritmetika 2 Fuzzy intervallumok és fuzzy számok Fuzzy intervallumok LR fuzzy intervallumok
Nemkonvex kvadratikus egyenlőtlenségrendszerek pontos dualitással
 pontos dualitással Imre McMaster University Advanced Optimization Lab ELTE TTK Operációkutatási Tanszék Folytonos optimalizálás szeminárium 2004. július 6. 1 2 3 Kvadratikus egyenlőtlenségrendszerek Primál
pontos dualitással Imre McMaster University Advanced Optimization Lab ELTE TTK Operációkutatási Tanszék Folytonos optimalizálás szeminárium 2004. július 6. 1 2 3 Kvadratikus egyenlőtlenségrendszerek Primál
Eseményalgebra. Esemény: minden amirl a kísérlet elvégzése során eldönthet egyértelmen hogy a kísérlet során bekövetkezett-e vagy sem.
 Eseményalgebra. Esemény: minden amirl a kísérlet elvégzése során eldönthet egyértelmen hogy a kísérlet során bekövetkezett-e vagy sem. Elemi esemény: a kísérlet egyes lehetséges egyes lehetséges kimenetelei.
Eseményalgebra. Esemény: minden amirl a kísérlet elvégzése során eldönthet egyértelmen hogy a kísérlet során bekövetkezett-e vagy sem. Elemi esemény: a kísérlet egyes lehetséges egyes lehetséges kimenetelei.
1.1. Vektorok és operátorok mátrix formában
 1. Reprezentáció elmélet 1.1. Vektorok és operátorok mátrix formában A vektorok és az operátorok mátrixok formájában is felírhatók. A végtelen dimenziós ket vektoroknak végtelen sok sort tartalmazó oszlopmátrix
1. Reprezentáció elmélet 1.1. Vektorok és operátorok mátrix formában A vektorok és az operátorok mátrixok formájában is felírhatók. A végtelen dimenziós ket vektoroknak végtelen sok sort tartalmazó oszlopmátrix
KOVÁCS BÉLA, MATEMATIKA I.
 KOVÁCS BÉLA MATEmATIkA I 6 VI KOmPLEX SZÁmOk 1 A komplex SZÁmOk HALmAZA A komplex számok olyan halmazt alkotnak amelyekben elvégezhető az összeadás és a szorzás azaz két komplex szám összege és szorzata
KOVÁCS BÉLA MATEmATIkA I 6 VI KOmPLEX SZÁmOk 1 A komplex SZÁmOk HALmAZA A komplex számok olyan halmazt alkotnak amelyekben elvégezhető az összeadás és a szorzás azaz két komplex szám összege és szorzata
Regressziós vizsgálatok
 Regressziós vizsgálatok Regresszió (regression) Általános jelentése: visszaesés, hanyatlás, visszafelé mozgás, visszavezetés. Orvosi területen: visszafejlődés, involúció. A betegség tünetei, vagy maga
Regressziós vizsgálatok Regresszió (regression) Általános jelentése: visszaesés, hanyatlás, visszafelé mozgás, visszavezetés. Orvosi területen: visszafejlődés, involúció. A betegség tünetei, vagy maga
Valószínűségelmélet. Pap Gyula. Szegedi Tudományegyetem. Szeged, 2016/2017 tanév, I. félév
 Valószínűségelmélet Pap Gyula Szegedi Tudományegyetem Szeged, 2016/2017 tanév, I. félév Pap Gyula (SZTE) Valószínűségelmélet 2016/2017 tanév, I. félév 1 / 125 Ajánlott irodalom: CSÖRGŐ SÁNDOR Fejezetek
Valószínűségelmélet Pap Gyula Szegedi Tudományegyetem Szeged, 2016/2017 tanév, I. félév Pap Gyula (SZTE) Valószínűségelmélet 2016/2017 tanév, I. félév 1 / 125 Ajánlott irodalom: CSÖRGŐ SÁNDOR Fejezetek
Hadamard-mátrixok Előadó: Hajnal Péter február 23.
 Szimmetrikus kombinatorikus struktúrák MSc hallgatók számára Hadamard-mátrixok Előadó: Hajnal Péter 2012. február 23. 1. Hadamard-mátrixok Ezen az előadáson látásra a blokkrendszerektől független kombinatorikus
Szimmetrikus kombinatorikus struktúrák MSc hallgatók számára Hadamard-mátrixok Előadó: Hajnal Péter 2012. február 23. 1. Hadamard-mátrixok Ezen az előadáson látásra a blokkrendszerektől független kombinatorikus
15. LINEÁRIS EGYENLETRENDSZEREK
 15 LINEÁRIS EGYENLETRENDSZEREK 151 Lineáris egyenletrendszer, Gauss elimináció 1 Definíció Lineáris egyenletrendszernek nevezzük az (1) a 11 x 1 + a 12 x 2 + + a 1n x n = b 1 a 21 x 1 + a 22 x 2 + + a
15 LINEÁRIS EGYENLETRENDSZEREK 151 Lineáris egyenletrendszer, Gauss elimináció 1 Definíció Lineáris egyenletrendszernek nevezzük az (1) a 11 x 1 + a 12 x 2 + + a 1n x n = b 1 a 21 x 1 + a 22 x 2 + + a
azonosságot minden 1 i, l n, 1 j k, indexre teljesítő együtthatókkal, amelyekre érvényes a = c (j) i,l l,i
 i,l l,i") A Cochran Fisher tételről A matematikai statisztika egyik fontos eredménye a Cochran Fisher tétel, amely a variancia analízisben játszik fontos szerepet. Ugyanakkor ez a tétel lényegét tekintve valójában
A Cochran Fisher tételről A matematikai statisztika egyik fontos eredménye a Cochran Fisher tétel, amely a variancia analízisben játszik fontos szerepet. Ugyanakkor ez a tétel lényegét tekintve valójában
Opkut deníciók és tételek
 Opkut deníciók és tételek Készítette: Bán József Deníciók 1. Deníció (Lineáris programozási feladat). Keressük meg adott lineáris, R n értelmezési tartományú függvény, az ún. célfüggvény széls értékét
Opkut deníciók és tételek Készítette: Bán József Deníciók 1. Deníció (Lineáris programozási feladat). Keressük meg adott lineáris, R n értelmezési tartományú függvény, az ún. célfüggvény széls értékét