A neurális hálózatok alapjai
|
|
|
- Kristóf Balog
- 6 évvel ezelőtt
- Látták:
Átírás
1 A neurális hálózatok alapjai Modern Tudományos Programozás Wigner FK 20 November 2018
2 Bevezető példa Egyenes illesztés: Sok minden demonstrálható rajta, de tudjuk, van intuíciónk róla, hogyan működik
3 Egyenes illesztés Feladat: Adott N darab {x i, y i } pont pár (az adatok). Szeretnénk jellemezni őket egy modellel, pl. egyenes: y = M ab x = ax + b Választottunk egy költség függvényt az eltérés mérésére L z0 (z) = z 0 z 2 Kérdés: Hogyan illesszük a modellt az adatokra?
4 Egyenes illesztés Azt mondjuk, hogy a modell akkor illik az adatokra, ha a költségfüggvény minimális: min a,b i L yi (M ab (x i ) ) Minimumban a paraméterek szerinti deriváltak nullák: 0 = d da L yi (M ab (x i ) ) i 0 = d db i L yi (M ab (x i ) )
5 Egyenes illesztés Ismert, hogy komponált függvények deriváltja a lánc szabály szerint: d dx f g x = f g x g (x) Így átírhatjuk a minimum feltételt: 0 = d da i 0 = d db i L yi (M ab (x i ) ) = L yi (M ab (x i ) ) = i i L yi (M ab (x i ) ) d da M ab x i L yi (M ab (x i ) ) d db M ab x i
6 Egyenes illesztés Esetünkben speciálisan: M ab x = ax + b, d da M ab x i = x i, d db M ab x i = 1 így 0 = i 0 = i L z0 z = z 0 z 2, L z0 z = 2(z 0 z) L yi (M ab (x i ) ) d da M ab x i L y i M ab x i d db M ab x i = i 2(y i ax i b) x i = 2 y i ax i b 1 i
7 Egyenes illesztés 0 = (y i ax i b)x i i 0 = y i ax i b i Ez egy lineáris egyenletrendszer {a, b}-re, ezért meg tudjuk oldani, zárt alakban. Másképp fogalmazva: a minimalizálandó függvényünknek egyértelmű minimuma van!
8 Modell illesztés Foglaljuk össze, hogy mit használtunk fel: Volt egy modellünk M, aminek voltak hangolható paraméterei Volt egy költségfüggvényünk L A kettőt összekomponáltuk L M = L M, majd kerestük a paraméterek szerinti minimumát A minimumban a paraméterek szerinti deriváltak nullák Tehát deriváltat kellett számolnunk, de ez a kompozícióra a lánc szabály segítségével könnyen ment (szorzat alak) A deriváltak ismeretében egy egyenletrendszert kaptunk, amit meg kellett oldani.
9 Mi lenne ha...?
10 Mi lenne ha...? A modellünk nem csak lineáris lenne, hanem valamilyen általánosabb függvényosztály
11 Mi lenne ha...? A modellünk nem csak lineáris lenne, hanem valamilyen általánosabb függvényosztály És ha mondjuk nem csak két paramétere lenne, hanem mondjuk 1 millió...

12 Mi lenne ha...? A modellünk nem csak lineáris lenne, hanem valamilyen általánosabb függvényosztály És ha mondjuk nem csak két paramétere lenne, hanem mondjuk 1 millió...
13 Problémák Néhány a problémák közül: Ha sok paraméterünk van, a szimbolikus deriválás és megoldás nem működik Az egyenletrendszer, amit meg kell oldanunk általában nem lineáris Következés képpen a minimum nem egyértelmű és sok van belőle (valószínűleg)
14 Deriválás A deriváltakat több féle módszerrel számolhatunk: Szimbolikusan Numerikusan Automatikusan
15 Deriválás A deriváltakat több féle módszerrel számolhatunk: Szimbolikusan Numerikusan Mi a különbség? Automatikusan
16 Deriválás A deriváltakat több féle módszerrel számolhatunk: Szimbolikusan f x = x 2, f x = 2x Numerikusan f 1.00 = ൠ f 1.01 = f = 2.01 Automatikusan f x = x 2 f 1 = 1 1 f 1 + ε = 1 + ε 1 + ε = 1 + 2ε Tehát: f 1 = 1 és f 1 = 2
17 Automatikus differenciálás A módszer felfogható úgy, hogy a számokat kiterjesztjük egy infinitezimális iránnyal: x x + x ε ahol ε egy infinitezimális szám, és ε 2 = 0 x reprezentálja a függvény értékét x a derivált értéke az adott függvényérték mellett
18 Automatikus differenciálás A deriválási szabályok ekkor egyszerűen reprezentálhatóak: x + x ε + y + y ε = (x + y) + x + y ε x + x ε y + y ε = (xy) + x y + xy ε sin x + x ε = sin(x) + x cos(x) ε Általában tehát: f x + x ε = f x + f x x ε
19 Automatikus differenciálás Általában tehát: f x + x ε = f x + f x x ε Ezt viszont értjük, hiszen ez csak a lánc szabály!
20 Automatikus differenciálás f x + x ε = f x + f x x ε Konstansok: c = c + 0ε
21 Automatikus differenciálás f x + x ε = f x + f x x ε Ha van egy függvényem, hogy számolom ki a deriváltját egy adott x 0 pontban? Ha csak x + 0ε -t rakunk bele, akkor a fenti képlet szerint 0 lesz a deriváltat jellemző tag. f(x) + 0ε
22 Automatikus differenciálás f x + x ε = f x + f x x ε Ha van egy függvényem, hogy számolom ki a deriváltját egy adott x 0 pontban? Megoldás: x + 1ε Ekkor ugyanis az eredmény: (f x + f x ε)
23 Automatikus differenciálás Összefoglalva: Konstans: (c + 0ε) Változó: (x + 1ε) Lánc szabály: f x + x ε = f x + f x x ε Tovább komponálva: f g x + x ε = f g(x) + f g(x) g (x)x ε Még tovább: f g(h x + x ε) = f g(h(x)) + f g h x g (h x )h (x)x ε
24 Automatikus differenciálás Mi van több változó esetén? f x + x ε, y + y ε = f x, y + df dx x, y x + df dy x, y y ε Hasonlóan általánosítható, ha komponálunk: f g(x + x ε), h y + y ε = f g(x), h(y) + df dg g(x), h y g (x)x + df dh g(x), h y h (y)y ε
25 Automatikus differenciálás Menjünk vissza ehhez a képlethez: f g(h x + x ε) = f g(h(x)) + f g h x g (h x )h (x)x ε Ezt felrajzolhatjuk így is: f g h x
26 Automatikus differenciálás Menjünk vissza ehhez a képlethez: f g(h x + x ε) = f g(h(x)) + f g h x g (h x )h (x)x ε Ezt felrajzolhatjuk így is: Ha deriválni akarok, akkor (x 0 + 1ε)-t teszünk be alul: x 0 + 1ε f g h x
27 Automatikus differenciálás Menjünk vissza ehhez a képlethez: f g(h x + x ε) = f g(h(x)) + f g h x g (h x )h (x)x ε Ezt felrajzolhatjuk így is: f Ha deriválni akarok, akkor (x 0 + 1ε)-t teszünk be alul: h x 0 + h (x 0 )1ε g h És terjesztjük felfelé! x 0 + 1ε x
28 Automatikus differenciálás Menjünk vissza ehhez a képlethez: f g(h x + x ε) = f g(h(x)) + f g h x g (h x )h (x)x ε Ezt felrajzolhatjuk így is: Ha deriválni akarok, akkor (x 0 + 1ε)-t teszünk be alul: És terjesztjük felfelé! g(h x 0 ) + g h x 0 h (x 0 )1ε h x 0 + h (x 0 )1ε x 0 + 1ε f g h x
29 Automatikus differenciálás Menjünk vissza ehhez a képlethez: f g(h x + x ε) = f g(h(x)) + f g h x g (h x )h (x)x ε Ezt felrajzolhatjuk így is: f g(h(x)) + f g h x g (h x )h (x)x ε f Ha deriválni akarok, akkor (x 0 + 1ε)-t teszünk be alul: És terjesztjük felfelé! g(h x 0 ) + g h x 0 h (x 0 )1ε h x 0 + h (x 0 )1ε x 0 + 1ε g h x
30 Automatikus differenciálás Menjünk vissza ehhez a képlethez: f g(h x + x ε) = f g(h(x)) + f g h x g (h x )h (x)x ε Lényegében a derivált szorzatát jobbról zárójelezve halmozzuk fel f g h x
31 ҧ Automatikus differenciálás Tegyük fel, hogy egyszer kiszámoltuk az összes függvény értéket és letároltuk minden pontban: x = x h x = തh g h x = gҧ f g(h x + x ε) = f g(h(x)) + f g h x g h x h x x ε = ҧ f + f gҧ g തh h xҧ x ε f g h x fҧ gҧ തh xҧ
32 Automatikus differenciálás A deriváltban levő szorzatot ekkor felülről lefelé így is számolhatjuk: f g(h x + x ε) = f ҧ + f gҧ g തh h xҧ x ε f szintjén a derivált f a gҧ helyen g szintjén hozzájön szorzónak g deriváltja a തh helyen. h szintjén hozzájön szorzónak h deriváltja a xҧ helyen. x szintjén, hozzájön szorzónak x deriváltja, de az 1. f g h x fҧ gҧ തh xҧ
33 Automatikus differenciálás Mi van, ha elágazás van? f g(x + x ε), h y + y ε = f g, ҧ തh + df dg g, ҧ തh g ( x)x ҧ + df dh g, ҧ തh h (തy)y ε Összegezni kell az ágakra! f-nek két argumentuma van, lesz egy két tagú összeg df + df dg dh A g tagban jön szorzónak dg a x ҧ helyen. dx A h tagban jön szorzónak dh dy x-nél a szorzó 1. az തy helyen. g x gҧ xҧ f fҧ h തh y തy y-nál a szorzó 1.
34 Automatikus differenciálás Lényegében az, hogy a gráfban alulról felfelé, vagy felülről lefelé számolunk, ugyan azt az eredményt adja, mert csak átzárójelezzük a lánc szabály szorzatát df dg dg dp dp dx + df dh dh dq dq dy = f Alulról indulva Felülről indulva df dg df dg dg dp dp dg dp dx + df dh dp dx + df dh dh dq dh dq dq dy = dq dy g p x h q y
35 Automatikus differenciálás A költségek viszont egészen mások tudnak lenni (hányszor kell egy rész-függvény deriváltját előállítani) g f h Ha redukáló jellegű a kifejezés (sok tagból lesz kevés eredmény), akkor felülről célszerű indulni p x q y Fordítva (kevés adatból állítunk elő sok eredményt), akkor alulról célszerű indulni p q r s g h x
36 Automatikus differenciálás Ha nem valamelyik szélsőséges esetben vagyunk, akkor baj van: Kezdhetjük a szorzat építést akármelyik pontból és két irányban haladhatunk, de: A minimális költségű kiértékelési módszer megtalálása NP nehéz probléma... f g p h q x y p q r s g h x
37 Differenciálás Összefoglalva: Ha sok változó szerint kell deriválnunk, akkor az automatikus differenciálás módszere minimális költséggel megadja egy számítási gráf eredményeinek deriváltjait a paraméterek szerint. g p x f h q y p q r s g h x
38 Mihez kezdünk a deriváltakkal? Ezek numerikus értékek, elvileg fel tudunk írni belőlük egy egyenletrendszert, de nem tudjuk zárt eljárással megoldani (abban sem lehetünk biztosak, hogy létezik-e megoldás)
39 Mihez kezdünk a deriváltakkal? Ezek numerikus értékek, elvileg fel tudunk írni belőlük egy egyenletrendszert, de nem tudjuk zárt eljárással megoldani (abban sem lehetünk biztosak, hogy létezik-e megoldás) De iterálni mindig lehet...
40 Iteratív megoldás Emlékeztető: gradiens módszer 0 α 1 tanulási ráta w n+1 = w n α df dw w n f(w) df dw α df dw
41 Iteratív megoldás Emlékeztető: gradiens módszer Mi kell hozzá? w n+1 = w n α df dw w n Kezdő érték w 0 A derivált (ezt már megoldottuk) Megállási feltétel f(w) α df dw df dw
42 Gradiens módszer Problémák: Ha rosszul indítjuk el a módszert, nem talál megoldást Ha nem figyelünk a konvergenciára, nem mindig megy bele a minimumba Beragadhat lokális minimumba A minimum közelében nagyon lecsökkenhet a konvergencia sebessége (lapos minimum) Ha valahol nagy ugrás van a deriváltban (nem analitikus viselkedés), az nagyon elronthatja a konvergenciát... f(w) α df dw df dw
43 Gradiens módszer Hogy néz ez ki több változóra (w W, f F)? W n+1 = W n α df dw W n Azonban ne felejtsük el a kontextust: az F függvényünk lehet egy kompozíció, a végén egy költség függvénnyel, ami pl. egy összegzett eltérést fejez ki megfigyelt {X i, Y i } adatpontoktól: F = L Yi (M W (X i )) i
44 Gradiens módszer W n+1 = W n α N dlyi (M Wn (X i )) i dw Ez viszont azt jelenti, hogy ha N nagy, akkor nagyon költséges kiszámolni a teljes σ i d dw -t...
45 Gradiens módszer W n+1 = W n α N dlyi (M Wn (X i )) i dw Sőt, a helyzet rosszabb, sokszor a véges numerikus ábrázolás miatt a sokféle gradiens összegzésekor elveszik az az információ, hogy merre is a legjobb lépni a paraméterekkel.
46 Sztochasztikus gradiens módszer W n+1 = W n α n dlyi (M Wn (X i )) i dw A teljes felösszegzés helyett egy kisebb mintával közelíthetjük a deriváltat: n < N (batch) Ekkor a derivált csak egy sztochasztikus becslése lesz az igazi deriváltnak: Sztochasztikus Gradiens Módszer A továbbiakban ezt mindig odaértjük, ahol deriváltat írunk!
47 Momentum Gradiens módszer Egy másik változata a módszernek, amikor az előző változtatás nagyságát is figyelembe vesszük valamilyen súllyal: W n+1 = α n dl Yi M Wn X i i dw + β W n W n+1 = W n + W n
48 AdaGrad A jó konvergenciát sokszor segíti egy prekondícionáló használata, de ezt költséges lehet megkonstruálni. Az AdaGrad megpróbál becsülni egyet: df W n+1 = W n αq 1 dw W n Ahol Q = diag n t=0 df dw t df dw t Ez lényegében skálázza α-t a korábbi deriváltak nagysága szerint. További olvasnivaló: link, link
49 Root Mean Square Propagation Egy másik fajta prekondícionálás az alábbi: W n+1 = W n α df Q n,wn dw W n Q n,wn = βq n 1,Wn + 1 β df dw n 2 Minden egyes súlyra léptetünk egy skálázási faktort, ami csak 1 β faktorral változik a gradiens négyzetével arányosan.
50 Adam Az előzőek ötvözése: W n+1 = W n α Q n,wn P n,wn P n,wn = 1 1 β 1 β 1 P n 1,Wn + 1 β 1 df dw n Korábbi gradiensek átlaga Q n,wn = 1 2 df β 1 β 2 Q n 1,Wn + 1 β 2 2 dw n Korábbi gradiensek szórása Minden egyes súlyra léptetjük a korábbi gradiensek átlagának és szórásának egy becslését, és a szórást használjuk prekondícionálásra. Link
51 Gradiens módszerek Sok féle gradiens módszer változat létezik, nem könnyű előre megmondani, hogy adott problémára melyik lesz a legjobb Érdemes többet is kipróbálni, illetve a paramétereikkel játszani Egy részletesebb lista többféle módszerről: link
52 Függvény osztályok Mi legyen a modell függvényünk?
53 Függvény osztályok Az előző módszerekkel tehát tudunk optimalizálni függvény kompozíciókat. Vegyük azonban észre, ha a függvények mind lineárisak, akkor a teljes kompozíció is egy lineáris függvény lesz... f x = cx + d g x = ax + b f g(x) = ca x + (cb + d)
54 Függvény osztályok Tehát ahhoz, hogy nem lineáris függvényeket is le tudjunk írni, szükség van arra, hogy a kompozícióban legyen nemlinearitás is.
55 Függvény osztályok Tehát ahhoz, hogy nem lineáris függvényeket is le tudjunk írni, szükség van arra, hogy a kompozícióban legyen nemlinearitás is. Milyen nemlinearitás legyen?
56 Nemlinearitások Sok féle nemlinearitást ki lehet próbálni, néhány példa: Tanh: σ x = tanh(x) Szigmoid: σ x = 1 1+e x RELU: σ x = ቊ 0, x < 0 x, x 0 Továbbiak: link
57 Nemlinearitások Néhány szempont, ami számít: Folytonos, folytonosan differenciálható vagy sem 0 közelében lineáris-e, vagy sem Monotonitás a függvényre és a deriváltjára Olcsó legyen kiszámolni
58 Nemlinearis kompozíciók Érdekesebb azonban az Univerzális Approximációs tulajdonság: N f(x) i c i σ(a i x + b i ) < ε, x Azaz, pl. az előző nemlinearitások szuperpozíciójaként minden folytonos f(x) függvény tetszőlegesen pontosan közelíthető. Vö.: tavaly: Ortogonális függvényrendszerek Pl.: Cybenko, G. (1989) link
59 Nemlinearis kompozíciók A valóságban azonban azt tapasztaljuk, hogy minél több nemlinearitást komponálunk: N i x = σ i a i x + b i N 1 N 2 annál jobban működik a rendszer, azaz annál jobban tudja közelíteni a célfüggvényt. Ennek az elméleti magyarázata még nyitott kérdés.
60 Nemlinearis kompozíciók Miért lehet mégis hasznos? Egy illusztráció: Ha a sokparaméteres hálózatot úgy fogjuk fel, hogy egy magas dimenziós térben beágyazza az adatot, akkor több nemlinearitással több lehetősége van határfelületeket találni pl. klasszifikációhoz. Forrás: link
61 Neurális hálózatok
62 Neurális hálózatok Az előzőeket összerakva: A neurális háló egy differenciálható függvény kompozíció, ami nemlinearitásokat tartalmaz. A nemlinearitás azért fontos, hogy jól közelíthessünk általános függvényosztályokat. A differenciálhatóság azért fontos, hogy automatikus deriválással előállíthassuk a gradiens módszerhez szükséges deriváltakat és a módszer konvergáljon. Igazából ennél kevesebb is elég: nekünk csak egy eljárás kell minden elemhez a kompozícióban, hogy milyen járulékot írjunk a lánc szabály szorzatába.
 és a kimenet is (output layer) a belső rétegekre a rejtett (hidden layer) elnevezést szokás")
63 Rétegek A neurális hálók kompozícióinak elemeit általában rétegeknek nevezik: Viszont a bemenet is réteg (input layer) és a kimenet is (output layer) a belső rétegekre a rejtett (hidden layer) elnevezést szokás használni
64 Rétegek A legáltalánosabb réteg a teljesen összefüggő (fully connected) réteg: f x = Ax + b Ahol A egy sűrű mátrix, b meg egy megfelelő méretű vektor. Ennek a hálózatnak a legnagyobb a kifejező ereje, de az N 2 paraméter nagyon költséges.
65 Rétegek Ha kevesebb paramétert akarunk és/vagy tudjuk, hogy valamilyen eltolás invariancia van a problémánkban, akkor célszerű konvolúciót használni: f x n = i w i x n+i + b Ahol w és b is vektor, w kevesebb elemű (tipikusan néhány), mint x, és f (és b) elemszáma x w. Az ehhez tartozó deriváltakat megfelelő index eltolással kell számolni: f x n x i = w i n f x i w i = x n+i
, illetve elősegíti a méret-függetlenség kifejezését Maximum esetén a deriváltat a következő képpen")
66 Rétegek Pooling (subsampling): Valamilyen módon összevonja a szomszédos adatokat, például maximum, átlag, medián, stb segítségével. A szerepe az, hogy csökkenti az utána jövő rétegek méretét (paraméter számát), illetve elősegíti a méret-függetlenség kifejezését Maximum esetén a deriváltat a következő képpen számolhatjuk: f f x = max x i, = ቊ 1, x j = max(x i ) x j 0, egyébként
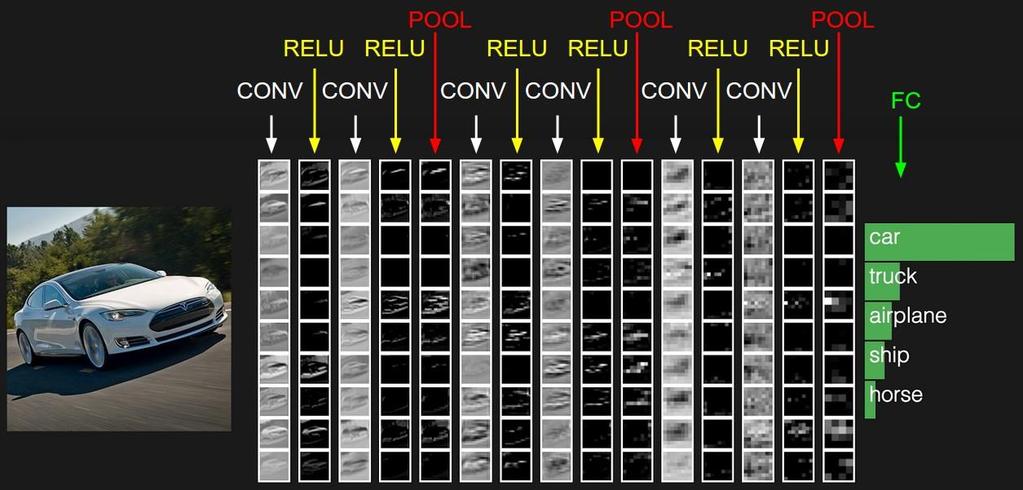
67 Rétegek
68 Költségfüggvények Az utolsó réteg egy hálózatban a költségfüggvény, ami valahogy skálázza az eltéréseket az elvárt adatokhoz képest. Ennek nagy szerepe van. Egyszerű esetekben általában négyzet-összeget, vagy abszolút eltérést használhatunk, esetleg logaritmikus súlyozást használhatunk. De célfeladatokra vannak jól bevált költség függvények...
69 Költségfüggvények Ha a feladat klasszifikáció, azaz besorolás nem átfedő csoportokba, akkor a softmax-ot célszerű használni: Softmax R n R n f x 1,, x n i = ex i σ k e x k Ez egy normalizált összeg, ahol a végén σ i f i = 1, így lehet akár valószínűségi értelmezést is adni.
70 Költségfüggvények Ha egymástól független, de normált értékeket kell előállítani, akkor használatos a Cross-entropy: C = 1 N x Y ln y + 1 Y ln 1 y itt Y az ismert érték, y a háló kimenete, az összegzés a kimenetek számára (N) történik.
71 Feed forward networks Az eddigi hálózati elemek szűrő jellegűek: (feed forward network) A belső állapotot a paraméterek (W) jellemzik Ezek csak a tanítás során változnak, amikor használjuk a hálózatot, már nem, ezért a teljes rendszer egy szokványos tiszta függvényként tekinthető Másképp fogalmazva: nincs visszacsatolás a hálózatban, nincs hurok a számítási gráfban

72 Feed forward networks Ezek a hálózatok tipikusan a képfeldolgozási eljárásokban használatosak, ahol az adatokban nincs időszerűség
73 Rekurrens neurális hálózatok (RNN) Sokszor azonban fontos az időszerűség, pl. jósolni szeretnénk korábbi eseményekből a következőt. Ezek a hálózatok már tartalmaznak visszacsatolást és belső állapotot. A visszacsatolás miatt a számítási gráf már ciklikus Az időszerűség mellett nagy előnyük, hogy változó hosszúságú kimenetet is elő tudnak állítani.

74 Rekurrens neurális hálózatok (RNN) A rekurrens hálózatok leginkább az írott és beszélt szöveg feldolgozásban, fordításban, idősor jóslásban, vezérléstechnikában használatosak
75 Long short-term memory Az egyik legegyszerűbb építőelem a Long short-term memory (LSTM): Itt x a bemenet, h az előző kimenet, c a memória, σ a nemlineáris függvény C t = σ W f h t 1, x t + b f C t 1 + σ W i h t 1, x t + b i tanh W C h t 1, x t + b C h t = σ W o h t 1, x t + b o tanh(c t ) Olvasnivaló: link
76 Long short-term memory Az egyik legegyszerűbb építőelem a Long short-term memory (LSTM): Ez a rész azt szabályozza, hogy a régi kimenet és az új input mennyire változtassa meg a régi állapotot (mennyire felejtődjön el a korábbi memória). C t = σ W f h t 1, x t + b f C t 1 + σ W i h t 1, x t + b i tanh W C h t 1, x t + b C h t = σ W o h t 1, x t + b o tanh(c t ) Olvasnivaló: link
77 Long short-term memory Az egyik legegyszerűbb építőelem a Long short-term memory (LSTM): A másik vonalon az új memóriába írandó érték és annak a súlya állítódik be C t = σ W f h t 1, x t + b f C t 1 + σ W i h t 1, x t + b i tanh W C h t 1, x t + b C h t = σ W o h t 1, x t + b o tanh(c t ) Olvasnivaló: link
")
78 Long short-term memory Az egyik legegyszerűbb építőelem a Long short-term memory (LSTM): Végül a módosított memória és a beérkezett adatok függvényében előállítjuk az új kimenetet C t = σ W f h t 1, x t + b f C t 1 + σ W i h t 1, x t + b i tanh W C h t 1, x t + b C h t = σ W o h t 1, x t + b o tanh(c t ) Olvasnivaló: link

79 Long short-term memory Az LSTM, és általában a rekurrens hálók tanítása nem könnyű. Nem szeretnek tanulni: nehéz rávenni őket, hogy értékeket írjanak a belső állapotba, és gyakran ragaszkodnak ahhoz, hogy identitás függvényként viselkedjenek... A rekurrens hálózatokat általában kitekerik időben N lépésig, és így számolják a gradienseket és a tanítást.

80 Rekurzív hálók Egy másik érdekes struktúra a rekurzív neurális hálózat: Itt valamilyen gráfon ugyan azokkal a súlyokkal, de más léptékben történik ugyan az a művelet Ez akkor hasznos, ha fontosak a hierarchikus, ismétlődő struktúrák, a kompozícionalitás Például: Mondatelemzés, parafrázis detektálás Kép értelmezése, cimkézése
81 Tanítási módszerek Több féle tanítási metodológia létezik, amelyek általában más feladatokra működnek jól, vagy más célokat próbálnak elérni
82 Tanítási módszerek Három féle tanítási paradigmát szoktak megkülönböztetni Supervised learning (felügyelt tanítás, ebből indultunk ki) Adott sok bemenet kimenet pár, és ezzel tanítunk egy hálózatot, hogy közelítse a kívánt leképezést (függvényt) Reinforcement learning (megerősítéses tanítás) Nincs adat, a háló (ágens) állapot átmenetek közül választhat, és az egyetlen visszajelzés az, hogy jutalmat/büntetést kap, ha jó átmenetet választott, vagy elért egy kívánt állapotot (hibánál büntetést nem kap, a jutalom akár nagyon ritkán is jöhet). Unsupervised learning Nincs felcimkézett adat, nem lehet mérni a hibát, az optimalizáció a statisztikai momentumok hasonlóságán alapul
83 Reinforcement Learning technikák Monte-Carlo Tree Search Tipikusan játékok döntési sorozatának bejárása (pl. táblajátékok: go, vagy video játékok: PacMan) Q-learning Egy Q State Action Reward függvényt tanul meg, iterációval: Q n+1 = 1 α Q n s n, a n + α r n + γ max a Q n+1 s n+1, a A Google Deep Mind ezzel játszik Atari játékokat Előző állapot Pillanatnyi jutalom Következő állapot becslése Várható jutalom ellensúlya 83
 Variációs AE (adott eloszlás tanulása Bayes módszerrel) Pl.")
84 Unsupervised learning technikák Autoencoder-decoder hálózat A háló először betömöríti a bemenetét, majd vissza kell alakítania a kimenetén a bemenetet, a közbülső rétegben ekkor előáll a tömörített forma, ami kicsatolható. Backprop-al tanítható Sparse AE (jutalom a ritkaságért) Variációs AE (adott eloszlás tanulása Bayes módszerrel) Pl. ha középen csak két változó van, akkor az egy 2D-s beágyazást állít elő: 84
, az egyiknek elő kell állítania egy adatot, a")


85 Unsupervised learning technikák Generative Adversarial hálózatok Két háló verseng (zero sum game), az egyiknek elő kell állítania egy adatot, a másiknak egy ilyen, és egy adott valódi adathalmazból jövő random mintáról meg kell mondania, hogy valódi, vagy generált. Ha elég okos tud lenni a felismerő fél, akkor nagyon jó generátort lehet tanítani, relatíve kicsi adathalmazzal. Példák: 3D rekonstrukció 2D képből, viselkedés jóslás Egy generált festmény: 85

86 Unsupervised learning technikák Generative Adversarial hálózatok További példák 86
87 Nehézségek Annak ellenére, hogy számos alkalmazásban nagyon jól teljesítenek a bemutatott hálózatok, vannak problémák, amikbe könnyű belefutni
88 Nehézségek Súlyok inicializálása: Részben az előző problémának a továbbvetülése, mert több esetben sikerült megmutatni, hogy a megfelelő inicializációval sokkal gyorsabb tud lenni a konvergencia, elkerülhető a gradiensek eltűnése. Érdemes adott probléma, vagy hálózat architektúra esetén megnézni, hogy van-e ajánlott inicializálási módszer.
89 Nehézségek Súlyok inicializálása: Például, a lineáris transzformációban résztvevő súlyokat célszerű a Xavier módszerrel inicializálni, azaz olyan Gauss eloszlású értékekkel, amelyek átlaga nulla, szórása pedig: vagy Var W = 1 n in Var W = 2 n in + n out Olvasnivaló: link, link ahol n in a bejövő értékek, n out a kimenő értékek száma.


90 Nehézségek Gradiensek eltűnése: Ha elég sok réteget rakunk egymás után, akkor a nemlinearitások halmozódása gondot jelenthet, főleg akkor, ha szigmoid alakúak: A lánc szabályban felhalmozódó deriváltak nagyon kicsik, ha több rétegben is a szigmoid széle felé kerül az aktuális érték. Ez sok réteg esetén azt eredményezheti, hogy nagyon belassul a tanítás, esetleg teljesen meg is áll. A RELU esetén ez nem probléma, de nem minden feladathoz jó a RELU, mert negatív értékekre nem terjeszt vissza hibát
91 Nehézségek Tanítás problémái: A rendszer nem tanul pl. véletlenül rosszul sikerült az inicializáció, beragadt az optimizer,... A rendszer túltanul (overfitting) akkor szokott lenni, ha a hálónak sokkal több szabadsági foka van, mint a tanító adathalmaz és a háló elkezd a tanítóhalmaz sajátosságaira specializálódni
92 Nehézségek Tanítás problémái: A rendszer látszólag jól tanul (csökken a költség fv), de mégsem jó az eredmény Tipikusan 3 halmazzal szokás dolgozni, amelyek diszjunktak: Az első a tanítóhalmaz, ami alapján optimalizáljuk a súlyokat A második a validációs halmaz, ahol ellenőrizzük, hogy tud-e a háló általánosítani a tanítóhalmazon kívülre, és nem történt-e túltanulás A harmadik halmaz a teszt halmaz, ahol valójában mérünk metrikákat, hogy mennyire jól teljesít a hálózat
93 Nehézségek Tanítás problémái: Túltanulás: A tanítóhalmazon (kék) csökken a költségfüggvény, de a validációs halmazon (piros) nő! A rendszer nem általánosít, csak megjegyzi a tanítóhalmazt.

94 Tanítás Egy jól működő tanítás, kb. így fest: A tanító és a teszt halmazon is csökken a hiba, és kb. azonos nagyságrendűek.
95 Tanítás után Betanítottunk sikeresen egy hálót 1 millió paraméterrel. De vajon mindre szükség van? Példák Pruning: A hálók paramétereinek nagy része nagyon kicsi, közel nulla. Szisztematikus explicit kinullázással és újratanítással akár 75-90%-a a paramétereknek kiküszöbölhető jelentős minőségi romlás nélkül.

96 Tanítás után Mennyire megbízható a háló? Nem tudni... Rosszindulatú támadások: A tanítóhalmaz és a háló ismeretében könnyen konstruálható olyan bemenet, ami Az ember számára teljesen megkülönböztethetetlen a tanítóhalmaz egy elemétől, de a háló nagyon magabiztosan félreklasszifikálja Vagy olyan elemeket tartalmaz, amit az ember zajnak ítél, de a háló számára kulcsfontosságú azonosító elem. Forrás
97 Szoftveres rendszerek Ha valaki el akar kezdeni neurális hálókkal ismerkedni, számos nagy keretrendszer érhető el, amelyek magas szintű, technikai részletektől mentesen teszik elérhetővé ezeket a módszereket. Néhány példa: Tensorflow PyTorch MxNet Theano, Caffe (elavultak, nem fejlesztik tovább)
Neurális Hálók. és a Funkcionális Programozás. Berényi Dániel Wigner GPU Labor
 Neurális Hálók és a Funkcionális Programozás Berényi Dániel Wigner GPU Labor Alapvető építőkövek Függvény kompozíció Automatikus Differenciálás (AD) 2 Neurális Háló, mint kompozíció Bemenetek Súlyok w
Neurális Hálók és a Funkcionális Programozás Berényi Dániel Wigner GPU Labor Alapvető építőkövek Függvény kompozíció Automatikus Differenciálás (AD) 2 Neurális Háló, mint kompozíció Bemenetek Súlyok w
Gépi tanulás a gyakorlatban. Lineáris regresszió
 Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Számítógépes képelemzés 7. előadás. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Keresés képi jellemzők alapján. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Konvolúciós neurális hálózatok (CNN)
") Konvolúciós neurális hálózatok (CNN) Konvolúció Jelfeldolgozásban: Diszkrét jelek esetén diszkrét konvolúció: Képfeldolgozásban 2D konvolúció (szűrők): Konvolúciós neurális hálózat Konvolúciós réteg Kép,
Konvolúciós neurális hálózatok (CNN) Konvolúció Jelfeldolgozásban: Diszkrét jelek esetén diszkrét konvolúció: Képfeldolgozásban 2D konvolúció (szűrők): Konvolúciós neurális hálózat Konvolúciós réteg Kép,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
Tanulás az idegrendszerben. Structure Dynamics Implementation Algorithm Computation - Function
 Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék. Neurális hálók. Pataki Béla
 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók Előadó: Előadás anyaga: Hullám Gábor Pataki Béla Dobrowiecki Tadeusz BME I.E. 414, 463-26-79
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók Előadó: Előadás anyaga: Hullám Gábor Pataki Béla Dobrowiecki Tadeusz BME I.E. 414, 463-26-79
Matematika A1a Analízis
 B U D A P E S T I M Ű S Z A K I M A T E M A T I K A É S G A Z D A S Á G T U D O M Á N Y I I N T É Z E T E G Y E T E M Matematika A1a Analízis BMETE90AX00 Differenciálhatóság H607, EIC 2019-03-14 Wettl
B U D A P E S T I M Ű S Z A K I M A T E M A T I K A É S G A Z D A S Á G T U D O M Á N Y I I N T É Z E T E G Y E T E M Matematika A1a Analízis BMETE90AX00 Differenciálhatóság H607, EIC 2019-03-14 Wettl
Matematika A1a Analízis
 B U D A P E S T I M Ű S Z A K I M A T E M A T I K A É S G A Z D A S Á G T U D O M Á N Y I I N T É Z E T E G Y E T E M Matematika A1a Analízis BMETE90AX00 A derivált alkalmazásai H607, EIC 2019-04-03 Wettl
B U D A P E S T I M Ű S Z A K I M A T E M A T I K A É S G A Z D A S Á G T U D O M Á N Y I I N T É Z E T E G Y E T E M Matematika A1a Analízis BMETE90AX00 A derivált alkalmazásai H607, EIC 2019-04-03 Wettl
Visszacsatolt (mély) neurális hálózatok
 neurális hálózatok") Visszacsatolt (mély) neurális hálózatok Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Sima előrecsatolt neurális hálózat Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Pl.: kép feliratozás,
Visszacsatolt (mély) neurális hálózatok Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Sima előrecsatolt neurális hálózat Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Pl.: kép feliratozás,
Alap-ötlet: Karl Friedrich Gauss ( ) valószínűségszámítási háttér: Andrej Markov ( )
 valószínűségszámítási háttér: Andrej Markov ( )") Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Regresszió. Csorba János. Nagyméretű adathalmazok kezelése március 31.
 Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
A L Hospital-szabály, elaszticitás, monotonitás, konvexitás
 A L Hospital-szabály, elaszticitás, monotonitás, konvexitás 9. előadás Farkas István DE ATC Gazdaságelemzési és Statisztikai Tanszék A L Hospital-szabály, elaszticitás, monotonitás, konvexitás p. / A L
A L Hospital-szabály, elaszticitás, monotonitás, konvexitás 9. előadás Farkas István DE ATC Gazdaságelemzési és Statisztikai Tanszék A L Hospital-szabály, elaszticitás, monotonitás, konvexitás p. / A L
Adatbányászati szemelvények MapReduce környezetben
 Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes [email protected] 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes [email protected] 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Line aris f uggv enyilleszt es m arcius 19.
 Lineáris függvényillesztés 2018. március 19. Illesztett paraméterek hibája Eddig azt néztük, hogy a mérési hiba hogyan propagál az illesztett paraméterekbe, ha van egy konkrét függvényünk. a hibaterjedés
Lineáris függvényillesztés 2018. március 19. Illesztett paraméterek hibája Eddig azt néztük, hogy a mérési hiba hogyan propagál az illesztett paraméterekbe, ha van egy konkrét függvényünk. a hibaterjedés
Lineáris leképezések. Wettl Ferenc március 9. Wettl Ferenc Lineáris leképezések március 9. 1 / 31
 Lineáris leképezések Wettl Ferenc 2015. március 9. Wettl Ferenc Lineáris leképezések 2015. március 9. 1 / 31 Tartalom 1 Mátrixleképezés, lineáris leképezés 2 Alkalmazás: dierenciálhatóság 3 2- és 3-dimenziós
Lineáris leképezések Wettl Ferenc 2015. március 9. Wettl Ferenc Lineáris leképezések 2015. március 9. 1 / 31 Tartalom 1 Mátrixleképezés, lineáris leképezés 2 Alkalmazás: dierenciálhatóság 3 2- és 3-dimenziós
Irányításelmélet és technika II.
 Irányításelmélet és technika II. Legkisebb négyzetek módszere Magyar Attila Pannon Egyetem Műszaki Informatikai Kar Villamosmérnöki és Információs Rendszerek Tanszék [email protected] 200 november
Irányításelmélet és technika II. Legkisebb négyzetek módszere Magyar Attila Pannon Egyetem Műszaki Informatikai Kar Villamosmérnöki és Információs Rendszerek Tanszék [email protected] 200 november
Intelligens orvosi műszerek VIMIA023
 Intelligens orvosi műszerek VIMIA023 Neurális hálók (Dobrowiecki Tadeusz anyagának átdolgozásával) 2017 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla [email protected] (463-)2679 A
Intelligens orvosi műszerek VIMIA023 Neurális hálók (Dobrowiecki Tadeusz anyagának átdolgozásával) 2017 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla [email protected] (463-)2679 A
3. Lineáris differenciálegyenletek
 3. Lineáris differenciálegyenletek A közönséges differenciálegyenletek két nagy csoportba oszthatók lineáris és nemlineáris egyenletek csoportjába. Ez a felbontás kicsit önkényesnek tűnhet, a megoldásra
3. Lineáris differenciálegyenletek A közönséges differenciálegyenletek két nagy csoportba oszthatók lineáris és nemlineáris egyenletek csoportjába. Ez a felbontás kicsit önkényesnek tűnhet, a megoldásra
Feladatok a Gazdasági matematika II. tárgy gyakorlataihoz
 Debreceni Egyetem Közgazdaságtudományi Kar Feladatok a Gazdasági matematika II tárgy gyakorlataihoz a megoldásra ajánlott feladatokat jelöli e feladatokat a félév végére megoldottnak tekintjük a nehezebb
Debreceni Egyetem Közgazdaságtudományi Kar Feladatok a Gazdasági matematika II tárgy gyakorlataihoz a megoldásra ajánlott feladatokat jelöli e feladatokat a félév végére megoldottnak tekintjük a nehezebb
"Flat" rendszerek. definíciók, példák, alkalmazások
 "Flat" rendszerek definíciók, példák, alkalmazások Hangos Katalin, Szederkényi Gábor [email protected], [email protected] 2006. október 18. flatness - p. 1/26 FLAT RENDSZEREK: Elméleti alapok 2006.
"Flat" rendszerek definíciók, példák, alkalmazások Hangos Katalin, Szederkényi Gábor [email protected], [email protected] 2006. október 18. flatness - p. 1/26 FLAT RENDSZEREK: Elméleti alapok 2006.
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék. Neurális hálók 2. Pataki Béla
 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók 2. Előadó: Hullám Gábor Pataki Béla BME I.E. 414, 463-26-79 [email protected], http://www.mit.bme.hu/general/staff/pataki
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók 2. Előadó: Hullám Gábor Pataki Béla BME I.E. 414, 463-26-79 [email protected], http://www.mit.bme.hu/general/staff/pataki
1. Házi feladat. Határidő: I. Legyen f : R R, f(x) = x 2, valamint. d : R + 0 R+ 0
 = x 2, valamint. d : R + 0 R+ 0") I. Legyen f : R R, f(x) = 1 1 + x 2, valamint 1. Házi feladat d : R + 0 R+ 0 R (x, y) f(x) f(y). 1. Igazoljuk, hogy (R + 0, d) metrikus tér. 2. Adjuk meg az x {0, 3} pontok és r {1, 2} esetén a B r (x)
I. Legyen f : R R, f(x) = 1 1 + x 2, valamint 1. Házi feladat d : R + 0 R+ 0 R (x, y) f(x) f(y). 1. Igazoljuk, hogy (R + 0, d) metrikus tér. 2. Adjuk meg az x {0, 3} pontok és r {1, 2} esetén a B r (x)
Gépi tanulás a gyakorlatban. Kiértékelés és Klaszterezés
 Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Differenciálszámítás. 8. előadás. Farkas István. DE ATC Gazdaságelemzési és Statisztikai Tanszék. Differenciálszámítás p. 1/1
 Differenciálszámítás 8. előadás Farkas István DE ATC Gazdaságelemzési és Statisztikai Tanszék Differenciálszámítás p. 1/1 Egyenes meredeksége Egyenes meredekségén az egyenes és az X-tengely pozitív iránya
Differenciálszámítás 8. előadás Farkas István DE ATC Gazdaságelemzési és Statisztikai Tanszék Differenciálszámítás p. 1/1 Egyenes meredeksége Egyenes meredekségén az egyenes és az X-tengely pozitív iránya
Konjugált gradiens módszer
 Közelítő és szimbolikus számítások 12. gyakorlat Konjugált gradiens módszer Készítette: Gelle Kitti Csendes Tibor Vinkó Tamás Faragó István Horváth Róbert jegyzetei alapján 1 LINEÁRIS EGYENLETRENDSZEREK
Közelítő és szimbolikus számítások 12. gyakorlat Konjugált gradiens módszer Készítette: Gelle Kitti Csendes Tibor Vinkó Tamás Faragó István Horváth Róbert jegyzetei alapján 1 LINEÁRIS EGYENLETRENDSZEREK
Neurális hálózatok elméleti alapjai TULICS MIKLÓS GÁBRIEL
 Neurális hálózatok elméleti alapjai TULICS MIKLÓS GÁBRIEL [email protected] Példa X (tanult órák száma, aludt órák száma) y (dolgozaton elért pontszám) (5, 8) 80 (3, 5) 78 (5, 1) 82 (10, 2) 93 (4, 4)
Neurális hálózatok elméleti alapjai TULICS MIKLÓS GÁBRIEL [email protected] Példa X (tanult órák száma, aludt órák száma) y (dolgozaton elért pontszám) (5, 8) 80 (3, 5) 78 (5, 1) 82 (10, 2) 93 (4, 4)
Biomatematika 12. Szent István Egyetem Állatorvos-tudományi Kar. Fodor János
 Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c [email protected] Last Revision
Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c [email protected] Last Revision
Intelligens Rendszerek Elmélete. Versengéses és önszervező tanulás neurális hálózatokban
 Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Lineáris regressziós modellek 1
 Lineáris regressziós modellek 1 Ispány Márton és Jeszenszky Péter 2016. szeptember 19. 1 Az ábrák C.M. Bishop: Pattern Recognition and Machine Learning c. könyvéből származnak. Tartalom Bevezető példák
Lineáris regressziós modellek 1 Ispány Márton és Jeszenszky Péter 2016. szeptember 19. 1 Az ábrák C.M. Bishop: Pattern Recognition and Machine Learning c. könyvéből származnak. Tartalom Bevezető példák
VIK A1 Matematika BOSCH, Hatvan, 5. Gyakorlati anyag
 VIK A1 Matematika BOSCH, Hatvan, 5. Gyakorlati anyag 2018/19 1. félév Függvények határértéke 1. Bizonyítsuk be definíció alapján a következőket! (a) lim x 2 3x+1 5x+4 = 1 2 (b) lim x 4 x 16 x 2 4x = 2
VIK A1 Matematika BOSCH, Hatvan, 5. Gyakorlati anyag 2018/19 1. félév Függvények határértéke 1. Bizonyítsuk be definíció alapján a következőket! (a) lim x 2 3x+1 5x+4 = 1 2 (b) lim x 4 x 16 x 2 4x = 2
Megoldott feladatok november 30. n+3 szigorúan monoton csökken, 5. n+3. lim a n = lim. n+3 = 2n+3 n+4 2n+1
 Megoldott feladatok 00. november 0.. Feladat: Vizsgáljuk az a n = n+ n+ sorozat monotonitását, korlátosságát és konvergenciáját. Konvergencia esetén számítsuk ki a határértéket! : a n = n+ n+ = n+ n+ =
Megoldott feladatok 00. november 0.. Feladat: Vizsgáljuk az a n = n+ n+ sorozat monotonitását, korlátosságát és konvergenciáját. Konvergencia esetén számítsuk ki a határértéket! : a n = n+ n+ = n+ n+ =
1. feladatsor: Vektorterek, lineáris kombináció, mátrixok, determináns (megoldás)
") Matematika A2c gyakorlat Vegyészmérnöki, Biomérnöki, Környezetmérnöki szakok, 2017/18 ősz 1. feladatsor: Vektorterek, lineáris kombináció, mátrixok, determináns (megoldás) 1. Valós vektorterek-e a következő
Matematika A2c gyakorlat Vegyészmérnöki, Biomérnöki, Környezetmérnöki szakok, 2017/18 ősz 1. feladatsor: Vektorterek, lineáris kombináció, mátrixok, determináns (megoldás) 1. Valós vektorterek-e a következő
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017.
 Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Haladó lineáris algebra
 B U D A P E S T I M Ű S Z A K I M A T E M A T I K A É S G A Z D A S Á G T U D O M Á N Y I I N T É Z E T E G Y E T E M Haladó lineáris algebra BMETE90MX54 Lineáris leképezések 2017-02-21 IB026 Wettl Ferenc
B U D A P E S T I M Ű S Z A K I M A T E M A T I K A É S G A Z D A S Á G T U D O M Á N Y I I N T É Z E T E G Y E T E M Haladó lineáris algebra BMETE90MX54 Lineáris leképezések 2017-02-21 IB026 Wettl Ferenc
Szélsőérték-számítás
 Szélsőérték-számítás Jelölések A következő jelölések mind az f függvény x szerinti parciális deriváltját jelentik: Ugyanígy az f függvény y szerinti parciális deriváltja: f x = xf = f x f y = yf = f y
Szélsőérték-számítás Jelölések A következő jelölések mind az f függvény x szerinti parciális deriváltját jelentik: Ugyanígy az f függvény y szerinti parciális deriváltja: f x = xf = f x f y = yf = f y
Bevezetés a programozásba I 3. gyakorlat. PLanG: Programozási tételek. Programozási tételek Algoritmusok
 Pázmány Péter Katolikus Egyetem Információs Technológiai Kar Bevezetés a programozásba I 3. gyakorlat PLanG: 2011.09.27. Giachetta Roberto [email protected] http://people.inf.elte.hu/groberto Algoritmusok
Pázmány Péter Katolikus Egyetem Információs Technológiai Kar Bevezetés a programozásba I 3. gyakorlat PLanG: 2011.09.27. Giachetta Roberto [email protected] http://people.inf.elte.hu/groberto Algoritmusok
Kalkulus 2., Matematika BSc 1. Házi feladat
 . Házi feladat Beadási határidő: 07.0.. Jelölések x = (x,..., x n, y = (y,..., y n, z = (z,..., z n R n esetén. x, y = n i= x iy i, skalárszorzat R n -ben. d(x, y = x y = n i= (x i y i, metrika R n -ben
. Házi feladat Beadási határidő: 07.0.. Jelölések x = (x,..., x n, y = (y,..., y n, z = (z,..., z n R n esetén. x, y = n i= x iy i, skalárszorzat R n -ben. d(x, y = x y = n i= (x i y i, metrika R n -ben
Nemlineáris programozás 2.
 Optimumszámítás Nemlineáris programozás 2. Többváltozós optimalizálás feltételek mellett. Lagrange-feladatok. Nemlineáris programozás. A Kuhn-Tucker feltételek. Konvex programozás. Sydsaeter-Hammond: 18.1-5,
Optimumszámítás Nemlineáris programozás 2. Többváltozós optimalizálás feltételek mellett. Lagrange-feladatok. Nemlineáris programozás. A Kuhn-Tucker feltételek. Konvex programozás. Sydsaeter-Hammond: 18.1-5,
Matematika I. NÉV:... FELADATOK: 2. Határozzuk meg az f(x) = 2x 3 + 2x 2 2x + 1 függvény szélsőértékeit a [ 2, 2] halmazon.
![Matematika I. NÉV:... FELADATOK: 2. Határozzuk meg az f(x) = 2x 3 + 2x 2 2x + 1 függvény szélsőértékeit a [ 2, 2] halmazon.](/thumbs/102/154127337.jpg "Matematika I. NÉV:... FELADATOK: 2. Határozzuk meg az f(x) = 2x 3 + 2x 2 2x + 1 függvény szélsőértékeit a [ 2, 2] halmazon.") 215.12.8. Matematika I. NÉV:... 1. Lineáris transzformációk segítségével ábrázoljuk az f(x) = ln(2 3x) függvényt. 7pt 2. Határozzuk meg az f(x) = 2x 3 + 2x 2 2x + 1 függvény szélsőértékeit a [ 2, 2] halmazon.
215.12.8. Matematika I. NÉV:... 1. Lineáris transzformációk segítségével ábrázoljuk az f(x) = ln(2 3x) függvényt. 7pt 2. Határozzuk meg az f(x) = 2x 3 + 2x 2 2x + 1 függvény szélsőértékeit a [ 2, 2] halmazon.
Statisztika - bevezetés Méréselmélet PE MIK MI_BSc VI_BSc 1
 Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Gazdasági matematika II. vizsgadolgozat megoldása, június 10
 Gazdasági matematika II. vizsgadolgozat megoldása, 204. június 0 A dolgozatírásnál íróeszközön kívül más segédeszköz nem használható. A dolgozat időtartama: 90 perc. Ha a dolgozat első részéből szerzett
Gazdasági matematika II. vizsgadolgozat megoldása, 204. június 0 A dolgozatírásnál íróeszközön kívül más segédeszköz nem használható. A dolgozat időtartama: 90 perc. Ha a dolgozat első részéből szerzett
A fontosabb definíciók
 A legfontosabb definíciókat jelöli. A fontosabb definíciók [Descartes szorzat] Az A és B halmazok Descartes szorzatán az A és B elemeiből képezett összes (a, b) a A, b B rendezett párok halmazát értjük,
A legfontosabb definíciókat jelöli. A fontosabb definíciók [Descartes szorzat] Az A és B halmazok Descartes szorzatán az A és B elemeiből képezett összes (a, b) a A, b B rendezett párok halmazát értjük,
Numerikus módszerek I. zárthelyi dolgozat (2017/18. I., A. csoport) Megoldások
 Megoldások") Numerikus módszerek I. zárthelyi dolgozat (2017/18. I., A. csoport) Megoldások 1. Feladat. (6p) Jelöljön. egy tetszőleges vektornormát, ill. a hozzá tartozó indukált mátrixnormát! Igazoljuk, hogy ha A
Numerikus módszerek I. zárthelyi dolgozat (2017/18. I., A. csoport) Megoldások 1. Feladat. (6p) Jelöljön. egy tetszőleges vektornormát, ill. a hozzá tartozó indukált mátrixnormát! Igazoljuk, hogy ha A
I. LABOR -Mesterséges neuron
 I. LABOR -Mesterséges neuron A GYAKORLAT CÉLJA: A mesterséges neuron struktúrájának az ismertetése, neuronhálókkal kapcsolatos elemek, alapfogalmak bemutatása, aktivációs függvénytípusok szemléltetése,
I. LABOR -Mesterséges neuron A GYAKORLAT CÉLJA: A mesterséges neuron struktúrájának az ismertetése, neuronhálókkal kapcsolatos elemek, alapfogalmak bemutatása, aktivációs függvénytípusok szemléltetése,
Statisztikai módszerek a skálafüggetlen hálózatok
 Statisztikai módszerek a skálafüggetlen hálózatok vizsgálatára Gyenge Ádám1 1 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Számítástudományi és Információelméleti
Statisztikai módszerek a skálafüggetlen hálózatok vizsgálatára Gyenge Ádám1 1 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Számítástudományi és Információelméleti
2 (j) f(x) dx = 1 arcsin(3x 2) + C. (d) A x + Bx + C 5x (2x 2 + 7) + Hx + I. 2 2x F x + G. x
 f(x) dx = 1 arcsin(3x 2) + C. (d) A x + Bx + C 5x (2x 2 + 7) + Hx + I. 2 2x F x + G. x") I feladatsor Határozza meg az alábbi függvények határozatlan integrálját: a fx dx = x arctg + C b fx dx = arctgx + C c fx dx = 5/x 4 arctg 5 x + C d fx dx = arctg + C 5/ e fx dx = x + arctg + C f fx dx
I feladatsor Határozza meg az alábbi függvények határozatlan integrálját: a fx dx = x arctg + C b fx dx = arctgx + C c fx dx = 5/x 4 arctg 5 x + C d fx dx = arctg + C 5/ e fx dx = x + arctg + C f fx dx
n n (n n ), lim ln(2 + 3e x ) x 3 + 2x 2e x e x + 1, sin x 1 cos x, lim e x2 1 + x 2 lim sin x 1 )
, lim ln(2 + 3e x ) x 3 + 2x 2e x e x + 1, sin x 1 cos x, lim e x2 1 + x 2 lim sin x 1 )") Matek szigorlat Komplex számok Sorozat határérték., a legnagyobb taggal egyszerűsítünk n n 3 3n 2 + 2 3n 2 n n + 2 25 n 3 9 n 2 + + 3) 2n 8 n 3 2n 3,, n n5 + n 2 n 2 5 2n + 2 3n 2) n+ 2. e-ados: + a )
Matek szigorlat Komplex számok Sorozat határérték., a legnagyobb taggal egyszerűsítünk n n 3 3n 2 + 2 3n 2 n n + 2 25 n 3 9 n 2 + + 3) 2n 8 n 3 2n 3,, n n5 + n 2 n 2 5 2n + 2 3n 2) n+ 2. e-ados: + a )
1/1. Házi feladat. 1. Legyen p és q igaz vagy hamis matematikai kifejezés. Mutassuk meg, hogy
 /. Házi feladat. Legyen p és q igaz vagy hamis matematikai kifejezés. Mutassuk meg, hogy mindig igaz. (p (( p) q)) (( p) ( q)). Igazoljuk, hogy minden A, B és C halmazra A \ (B C) = (A \ B) (A \ C) teljesül.
/. Házi feladat. Legyen p és q igaz vagy hamis matematikai kifejezés. Mutassuk meg, hogy mindig igaz. (p (( p) q)) (( p) ( q)). Igazoljuk, hogy minden A, B és C halmazra A \ (B C) = (A \ B) (A \ C) teljesül.
MATEMATIKA 2. dolgozat megoldása (A csoport)
") MATEMATIKA. dolgozat megoldása (A csoport). Definiálja az alábbi fogalmakat: (egyváltozós) függvény folytonossága, differenciálhatósága, (többváltozós függvény) iránymenti deriváltja. (3x8 pont). Az f
MATEMATIKA. dolgozat megoldása (A csoport). Definiálja az alábbi fogalmakat: (egyváltozós) függvény folytonossága, differenciálhatósága, (többváltozós függvény) iránymenti deriváltja. (3x8 pont). Az f
Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok
 Zrínyi Miklós Gimnázium Művészet és tudomány napja Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok 10/9/2009 Dr. Viharos Zsolt János Elsősorban volt Zrínyis diák Tudományos főmunkatárs
Zrínyi Miklós Gimnázium Művészet és tudomány napja Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok 10/9/2009 Dr. Viharos Zsolt János Elsősorban volt Zrínyis diák Tudományos főmunkatárs
Legkisebb négyzetek módszere, Spline interpoláció
 Közelítő és szimbolikus számítások 10. gyakorlat Legkisebb négyzetek módszere, Spline interpoláció Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor Vinkó Tamás London András Deák Gábor jegyzetei alapján
Közelítő és szimbolikus számítások 10. gyakorlat Legkisebb négyzetek módszere, Spline interpoláció Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor Vinkó Tamás London András Deák Gábor jegyzetei alapján
Általánosan, bármilyen mérés annyit jelent, mint meghatározni, hányszor van meg
 LMeasurement.tex, March, 00 Mérés Általánosan, bármilyen mérés annyit jelent, mint meghatározni, hányszor van meg a mérendő mennyiségben egy másik, a mérendővel egynemű, önkényesen egységnek választott
LMeasurement.tex, March, 00 Mérés Általánosan, bármilyen mérés annyit jelent, mint meghatározni, hányszor van meg a mérendő mennyiségben egy másik, a mérendővel egynemű, önkényesen egységnek választott
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
Intelligens Rendszerek Gyakorlata. Neurális hálózatok I.
 : Intelligens Rendszerek Gyakorlata Neurális hálózatok I. dr. Kutor László http://mobil.nik.bmf.hu/tantargyak/ir2.html IRG 3/1 Trend osztályozás Pnndemo.exe IRG 3/2 Hangulat azonosítás Happy.exe IRG 3/3
: Intelligens Rendszerek Gyakorlata Neurális hálózatok I. dr. Kutor László http://mobil.nik.bmf.hu/tantargyak/ir2.html IRG 3/1 Trend osztályozás Pnndemo.exe IRG 3/2 Hangulat azonosítás Happy.exe IRG 3/3
First Prev Next Last Go Back Full Screen Close Quit. (Derivált)
") Valós függvények (3) (Derivált) . Legyen a belső pontja D f -nek. Ha létezik és véges a f(x) f(a) x a x a = f (a) () határérték, akkor f differenciálható a-ban. Az f (a) szám az f a-beli differenciálhányadosa.
Valós függvények (3) (Derivált) . Legyen a belső pontja D f -nek. Ha létezik és véges a f(x) f(a) x a x a = f (a) () határérték, akkor f differenciálható a-ban. Az f (a) szám az f a-beli differenciálhányadosa.
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
Az egyenlőtlenség mindkét oldalát szorozzuk meg 4 16-al:
 Bevezető matematika kémikusoknak., 04. ősz. feladatlap. Ábrázoljuk számegyenesen a következő egyenlőtlenségek megoldáshalmazát! (a) x 5 < 3 5 x < 3 x 5 < (d) 5 x
Bevezető matematika kémikusoknak., 04. ősz. feladatlap. Ábrázoljuk számegyenesen a következő egyenlőtlenségek megoldáshalmazát! (a) x 5 < 3 5 x < 3 x 5 < (d) 5 x
0-49 pont: elégtelen, pont: elégséges, pont: közepes, pont: jó, pont: jeles
 Matematika szigorlat, Mérnök informatikus szak I. 2013. jan. 10. Név: Neptun kód: Idő: 180 perc Elm.: 1. f. 2. f. 3. f. 4. f. 5. f. Fel. össz.: Össz.: Oszt.: Az elérhető pontszám 40 (elmélet) + 60 (feladatok)
Matematika szigorlat, Mérnök informatikus szak I. 2013. jan. 10. Név: Neptun kód: Idő: 180 perc Elm.: 1. f. 2. f. 3. f. 4. f. 5. f. Fel. össz.: Össz.: Oszt.: Az elérhető pontszám 40 (elmélet) + 60 (feladatok)
A lineáris programozás alapjai
 A lineáris programozás alapjai A konvex analízis alapjai: konvexitás, konvex kombináció, hipersíkok, félterek, extrém pontok, Poliéderek, a Minkowski-Weyl tétel (a poliéderek reprezentációs tétele) Lineáris
A lineáris programozás alapjai A konvex analízis alapjai: konvexitás, konvex kombináció, hipersíkok, félterek, extrém pontok, Poliéderek, a Minkowski-Weyl tétel (a poliéderek reprezentációs tétele) Lineáris
Mátrixok 2017 Mátrixok
 2017 számtáblázatok" : számok rendezett halmaza, melyben a számok helye két paraméterrel van meghatározva. Például lineáris egyenletrendszer együtthatómátrixa 2 x 1 + 4 x 2 = 8 1 x 1 + 3 x 2 = 1 ( 2 4
2017 számtáblázatok" : számok rendezett halmaza, melyben a számok helye két paraméterrel van meghatározva. Például lineáris egyenletrendszer együtthatómátrixa 2 x 1 + 4 x 2 = 8 1 x 1 + 3 x 2 = 1 ( 2 4
Megerősítéses tanulás 7. előadás
 Megerősítéses tanulás 7. előadás 1 Ismétlés: TD becslés s t -ben stratégia szerint lépek! a t, r t, s t+1 TD becslés: tulajdonképpen ezt mintavételezzük: 2 Akcióértékelő függvény számolása TD-vel még mindig
Megerősítéses tanulás 7. előadás 1 Ismétlés: TD becslés s t -ben stratégia szerint lépek! a t, r t, s t+1 TD becslés: tulajdonképpen ezt mintavételezzük: 2 Akcióértékelő függvény számolása TD-vel még mindig
1. Generátorrendszer. Házi feladat (fizikából tudjuk) Ha v és w nem párhuzamos síkvektorok, akkor generátorrendszert alkotnak a sík vektorainak
 Ha v és w nem párhuzamos síkvektorok, akkor generátorrendszert alkotnak a sík vektorainak") 1. Generátorrendszer Generátorrendszer. Tétel (Freud, 4.3.4. Tétel) Legyen V vektortér a T test fölött és v 1,v 2,...,v m V. Ekkor a λ 1 v 1 + λ 2 v 2 +... + λ m v m alakú vektorok, ahol λ 1,λ 2,...,λ
1. Generátorrendszer Generátorrendszer. Tétel (Freud, 4.3.4. Tétel) Legyen V vektortér a T test fölött és v 1,v 2,...,v m V. Ekkor a λ 1 v 1 + λ 2 v 2 +... + λ m v m alakú vektorok, ahol λ 1,λ 2,...,λ
Statisztika I. 12. előadás. Előadó: Dr. Ertsey Imre
 Statisztika I. 1. előadás Előadó: Dr. Ertsey Imre Regresszió analízis A korrelációs együttható megmutatja a kapcsolat irányát és szorosságát. A kapcsolat vizsgálata során a gyakorlatban ennél messzebb
Statisztika I. 1. előadás Előadó: Dr. Ertsey Imre Regresszió analízis A korrelációs együttható megmutatja a kapcsolat irányát és szorosságát. A kapcsolat vizsgálata során a gyakorlatban ennél messzebb
Véletlen jelenség: okok rendszere hozza létre - nem ismerhetjük mind, ezért sztochasztikus.
 Valószín ségelméleti és matematikai statisztikai alapfogalmak összefoglalása (Kemény Sándor - Deák András: Mérések tervezése és eredményeik értékelése, kivonat) Véletlen jelenség: okok rendszere hozza
Valószín ségelméleti és matematikai statisztikai alapfogalmak összefoglalása (Kemény Sándor - Deák András: Mérések tervezése és eredményeik értékelése, kivonat) Véletlen jelenség: okok rendszere hozza
Matematika I. NÉV:... FELADATOK:
 24.2.9. Matematika I. NÉV:... FELADATOK:. A tanult módon vizsgáljuk az a = 3, a n = 3a n 2 (n > ) rekurzív sorozatot. pt 2n 2 + e 2. Definíció szerint és formálisan is igazoljuk, hogy lim =. pt n 3 + n
24.2.9. Matematika I. NÉV:... FELADATOK:. A tanult módon vizsgáljuk az a = 3, a n = 3a n 2 (n > ) rekurzív sorozatot. pt 2n 2 + e 2. Definíció szerint és formálisan is igazoljuk, hogy lim =. pt n 3 + n
Kétváltozós függvények differenciálszámítása
 Kétváltozós függvények differenciálszámítása 13. előadás Farkas István DE ATC Gazdaságelemzési és Statisztikai Tanszék Kétváltozós függvények p. 1/1 Definíció, szemléltetés Definíció. Az f : R R R függvényt
Kétváltozós függvények differenciálszámítása 13. előadás Farkas István DE ATC Gazdaságelemzési és Statisztikai Tanszék Kétváltozós függvények p. 1/1 Definíció, szemléltetés Definíció. Az f : R R R függvényt
1. Oldja meg a z 3 (5 + 3j) (8 + 2j) 2. Adottak az A(1,4,3), B(3,1, 1), C( 5,2,4) pontok a térben.
 (8 + 2j) 2. Adottak az A(1,4,3), B(3,1, 1), C( 5,2,4) pontok a térben.") Szak: Műszaki menedzser I. Dátum: 006. június. MEGOLDÓKULCS Tárgy: Matematika szigorlat Idő: 0 perc Neptun kód: Előadó: Berta Gábor szig 06 06 0 Pontszám: /00p. Oldja meg a z (5 + j (8 + j + = (+5j (7
Szak: Műszaki menedzser I. Dátum: 006. június. MEGOLDÓKULCS Tárgy: Matematika szigorlat Idő: 0 perc Neptun kód: Előadó: Berta Gábor szig 06 06 0 Pontszám: /00p. Oldja meg a z (5 + j (8 + j + = (+5j (7
3D számítógépes geometria 2
 3D számítógépes geometria Numerikus analízis alapok ujjgyakorlat megoldások Várady Tamás, Salvi Péter / BME October, 18 Ujjgyakorlat 1 Feladat: 1 cos(x) dx kiszámítása trapéz-módszerrel Ujjgyakorlat 1
3D számítógépes geometria Numerikus analízis alapok ujjgyakorlat megoldások Várady Tamás, Salvi Péter / BME October, 18 Ujjgyakorlat 1 Feladat: 1 cos(x) dx kiszámítása trapéz-módszerrel Ujjgyakorlat 1
Függvények július 13. f(x) = 1 x+x 2 f() = 1 ()+() 2 f(f(x)) = 1 (1 x+x 2 )+(1 x+x 2 ) 2 Rendezés után kapjuk, hogy:
 = 1 x+x 2 f() = 1 ()+() 2 f(f(x)) = 1 (1 x+x 2 )+(1 x+x 2 ) 2 Rendezés után kapjuk, hogy:") Függvények 015. július 1. 1. Feladat: Határozza meg a következ összetett függvényeket! f(x) = cos x + x g(x) = x f(g(x)) =? g(f(x)) =? Megoldás: Összetett függvény el állításához a küls függvényben a független
Függvények 015. július 1. 1. Feladat: Határozza meg a következ összetett függvényeket! f(x) = cos x + x g(x) = x f(g(x)) =? g(f(x)) =? Megoldás: Összetett függvény el állításához a küls függvényben a független
Matematika III előadás
 Matematika III. - 2. előadás Vinczéné Varga Adrienn Debreceni Egyetem Műszaki Kar, Műszaki Alaptárgyi Tanszék Előadáskövető fóliák Vinczéné Varga Adrienn (DE-MK) Matematika III. 2016/2017/I 1 / 23 paramétervonalak,
Matematika III. - 2. előadás Vinczéné Varga Adrienn Debreceni Egyetem Műszaki Kar, Műszaki Alaptárgyi Tanszék Előadáskövető fóliák Vinczéné Varga Adrienn (DE-MK) Matematika III. 2016/2017/I 1 / 23 paramétervonalak,
Funkcionálanalízis. n=1. n=1. x n y n. n=1
 Funkcionálanalízis 2011/12 tavaszi félév - 2. előadás 1.4. Lényeges alap-terek, példák Sorozat terek (Folytatás.) C: konvergens sorozatok tere. A tér pontjai sorozatok: x = (x n ). Ezen belül C 0 a nullsorozatok
Funkcionálanalízis 2011/12 tavaszi félév - 2. előadás 1.4. Lényeges alap-terek, példák Sorozat terek (Folytatás.) C: konvergens sorozatok tere. A tér pontjai sorozatok: x = (x n ). Ezen belül C 0 a nullsorozatok
Bevezetés a programozásba. 5. Előadás: Tömbök
 Bevezetés a programozásba 5. Előadás: Tömbök ISMÉTLÉS Specifikáció Előfeltétel: milyen körülmények között követelünk helyes működést Utófeltétel: mit várunk a kimenettől, mi az összefüggés a kimenet és
Bevezetés a programozásba 5. Előadás: Tömbök ISMÉTLÉS Specifikáció Előfeltétel: milyen körülmények között követelünk helyes működést Utófeltétel: mit várunk a kimenettől, mi az összefüggés a kimenet és
Deep Learning a gyakorlatban Python és LUA alapon Tanítás: alap tippek és trükkök
 Gyires-Tóth Bálint Deep Learning a gyakorlatban Python és LUA alapon Tanítás: alap tippek és trükkök http://smartlab.tmit.bme.hu Deep Learning Híradó Hírek az elmúlt 168 órából Deep Learning Híradó Google
Gyires-Tóth Bálint Deep Learning a gyakorlatban Python és LUA alapon Tanítás: alap tippek és trükkök http://smartlab.tmit.bme.hu Deep Learning Híradó Hírek az elmúlt 168 órából Deep Learning Híradó Google
FELÜGYELT ÉS MEGERŐSÍTÉSES TANULÓ RENDSZEREK FEJLESZTÉSE
 FELÜGYELT ÉS MEGERŐSÍTÉSES TANULÓ RENDSZEREK FEJLESZTÉSE Dr. Aradi Szilárd, Fehér Árpád Mesterséges intelligencia kialakulása 1956 Dartmouth-i konferencián egy maroknyi tudós megalapította a MI területét
FELÜGYELT ÉS MEGERŐSÍTÉSES TANULÓ RENDSZEREK FEJLESZTÉSE Dr. Aradi Szilárd, Fehér Árpád Mesterséges intelligencia kialakulása 1956 Dartmouth-i konferencián egy maroknyi tudós megalapította a MI területét
Megerősítéses tanulás 9. előadás
 Megerősítéses tanulás 9. előadás 1 Backgammon (vagy Ostábla) 2 3 TD-Gammon 0.0 TD() tanulás (azaz időbeli differencia-módszer felelősségnyomokkal) függvényapproximátor: neuronháló 40 rejtett (belső) neuron
Megerősítéses tanulás 9. előadás 1 Backgammon (vagy Ostábla) 2 3 TD-Gammon 0.0 TD() tanulás (azaz időbeli differencia-módszer felelősségnyomokkal) függvényapproximátor: neuronháló 40 rejtett (belső) neuron
x, x R, x rögzített esetén esemény. : ( ) x Valószínűségi Változó: Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel:
 x Valószínűségi Változó: Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel:") Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel: Valószínűségi változó általános fogalma: A : R leképezést valószínűségi változónak nevezzük, ha : ( ) x, x R, x rögzített esetén esemény.
Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel: Valószínűségi változó általános fogalma: A : R leképezést valószínűségi változónak nevezzük, ha : ( ) x, x R, x rögzített esetén esemény.
KÖZELÍTŐ INFERENCIA II.
 STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
Mérési struktúrák
 Mérési struktúrák 2007.02.19. 1 Mérési struktúrák A mérés művelete: a mérendő jellemző és a szimbólum halmaz közötti leképezés megvalósítása jel- és rendszerelméleti aspektus mérési folyamat: a leképezést
Mérési struktúrák 2007.02.19. 1 Mérési struktúrák A mérés művelete: a mérendő jellemző és a szimbólum halmaz közötti leképezés megvalósítása jel- és rendszerelméleti aspektus mérési folyamat: a leképezést
Numerikus matematika. Irodalom: Stoyan Gisbert, Numerikus matematika mérnököknek és programozóknak, Typotex, Lebegőpontos számok
 Numerikus matematika Irodalom: Stoyan Gisbert, Numerikus matematika mérnököknek és programozóknak, Typotex, 2007 Lebegőpontos számok Normák, kondíciószámok Lineáris egyenletrendszerek Legkisebb négyzetes
Numerikus matematika Irodalom: Stoyan Gisbert, Numerikus matematika mérnököknek és programozóknak, Typotex, 2007 Lebegőpontos számok Normák, kondíciószámok Lineáris egyenletrendszerek Legkisebb négyzetes
A maximum likelihood becslésről
 A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
Figyelem, próbálja önállóan megoldani, csak ellenőrzésre használja a következő oldalak megoldásait!
 Elméleti kérdések: Második zárthelyi dolgozat biomatematikából * (Minta, megoldásokkal) E. Mit értünk hatványfüggvényen? Adjon példát nem invertálható hatványfüggvényre. Adjon példát mindenütt konkáv hatványfüggvényre.
Elméleti kérdések: Második zárthelyi dolgozat biomatematikából * (Minta, megoldásokkal) E. Mit értünk hatványfüggvényen? Adjon példát nem invertálható hatványfüggvényre. Adjon példát mindenütt konkáv hatványfüggvényre.
(Independence, dependence, random variables)
") Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
Megerősítéses tanulás
 Megerősítéses tanulás elméleti kognitív neurális Introduction Knowledge representation Probabilistic models Bayesian behaviour Approximate inference I (computer lab) Vision I Approximate inference II:
Megerősítéses tanulás elméleti kognitív neurális Introduction Knowledge representation Probabilistic models Bayesian behaviour Approximate inference I (computer lab) Vision I Approximate inference II:
Tanulás az idegrendszerben
 Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Funkcióvezérelt modellezés Abból indulunk ki, hogy milyen feladatot valósít meg a rendszer Horace Barlow: "A
Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Funkcióvezérelt modellezés Abból indulunk ki, hogy milyen feladatot valósít meg a rendszer Horace Barlow: "A
Stratégiák tanulása az agyban
 Statisztikai tanulás az idegrendszerben, 2019. Stratégiák tanulása az agyban Bányai Mihály [email protected] http://golab.wigner.mta.hu/people/mihaly-banyai/ Kortárs MI thispersondoesnotexist.com
Statisztikai tanulás az idegrendszerben, 2019. Stratégiák tanulása az agyban Bányai Mihály [email protected] http://golab.wigner.mta.hu/people/mihaly-banyai/ Kortárs MI thispersondoesnotexist.com
Modern műszeres analitika szeminárium Néhány egyszerű statisztikai teszt
 Modern műszeres analitika szeminárium Néhány egyszerű statisztikai teszt Galbács Gábor KIUGRÓ ADATOK KISZŰRÉSE STATISZTIKAI TESZTEKKEL Dixon Q-tesztje Gyakori feladat az analitikai kémiában, hogy kiugrónak
Modern műszeres analitika szeminárium Néhány egyszerű statisztikai teszt Galbács Gábor KIUGRÓ ADATOK KISZŰRÉSE STATISZTIKAI TESZTEKKEL Dixon Q-tesztje Gyakori feladat az analitikai kémiában, hogy kiugrónak
Függvény differenciálás összefoglalás
 Függvény differenciálás összefoglalás Differenciálszámítás: Def: Differenciahányados: f() f(a + ) f(a) függvényérték változása független változó megváltozása Ha egyre kisebb, vagyis tart -hoz, akkor a
Függvény differenciálás összefoglalás Differenciálszámítás: Def: Differenciahányados: f() f(a + ) f(a) függvényérték változása független változó megváltozása Ha egyre kisebb, vagyis tart -hoz, akkor a
Közösség detektálás gráfokban
 Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
KÖZELÍTŐ INFERENCIA II.
 STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
Hidden Markov Model. March 12, 2013
 Hidden Markov Model Göbölös-Szabó Julianna March 12, 2013 Outline 1 Egy példa 2 Feladat formalizálása 3 Forward-algoritmus 4 Backward-algoritmus 5 Baum-Welch algoritmus 6 Skálázás 7 Egyéb apróságok 8 Alkalmazás
Hidden Markov Model Göbölös-Szabó Julianna March 12, 2013 Outline 1 Egy példa 2 Feladat formalizálása 3 Forward-algoritmus 4 Backward-algoritmus 5 Baum-Welch algoritmus 6 Skálázás 7 Egyéb apróságok 8 Alkalmazás
Least Squares becslés
 Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Gyakorló feladatok az II. konzultáció anyagához
 Gyakorló feladatok az II. konzultáció anyagához 003/004 tanév, I. félév 1. Vizsgáljuk meg a következő sorozatokat korlátosság és monotonitás szempontjából! a n = 5n+1, b n = n + n! 3n 8, c n = 1 ( 1)n
Gyakorló feladatok az II. konzultáció anyagához 003/004 tanév, I. félév 1. Vizsgáljuk meg a következő sorozatokat korlátosság és monotonitás szempontjából! a n = 5n+1, b n = n + n! 3n 8, c n = 1 ( 1)n
Numerikus integrálás
 Közelítő és szimbolikus számítások 11. gyakorlat Numerikus integrálás Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor Vinkó Tamás London András Deák Gábor jegyzetei alapján 1. Határozatlan integrál
Közelítő és szimbolikus számítások 11. gyakorlat Numerikus integrálás Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor Vinkó Tamás London András Deák Gábor jegyzetei alapján 1. Határozatlan integrál
Egyenletek, egyenlőtlenségek V.
 Egyenletek, egyenlőtlenségek V. DEFINÍCIÓ: (Másodfokú egyenlet) Az ax + bx + c = 0 alakban felírható egyenletet (a, b, c R; a 0), ahol x a változó, másodfokú egyenletnek nevezzük. TÉTEL: Az ax + bx + c
Egyenletek, egyenlőtlenségek V. DEFINÍCIÓ: (Másodfokú egyenlet) Az ax + bx + c = 0 alakban felírható egyenletet (a, b, c R; a 0), ahol x a változó, másodfokú egyenletnek nevezzük. TÉTEL: Az ax + bx + c
A mérési eredmény megadása
 A mérési eredmény megadása A mérés során kapott értékek eltérnek a mérendő fizikai mennyiség valódi értékétől. Alapvetően kétféle mérési hibát különböztetünk meg: a determinisztikus és a véletlenszerű
A mérési eredmény megadása A mérés során kapott értékek eltérnek a mérendő fizikai mennyiség valódi értékétől. Alapvetően kétféle mérési hibát különböztetünk meg: a determinisztikus és a véletlenszerű
Gauss-Jordan módszer Legkisebb négyzetek módszere, egyenes LNM, polinom LNM, függvény. Lineáris algebra numerikus módszerei
 A Gauss-Jordan elimináció, mátrixinvertálás Gauss-Jordan módszer Ugyanazzal a technikával, mint ahogy a k-adik oszlopban az a kk alatti elemeket kinulláztuk, a fölötte lévő elemeket is zérussá lehet tenni.
A Gauss-Jordan elimináció, mátrixinvertálás Gauss-Jordan módszer Ugyanazzal a technikával, mint ahogy a k-adik oszlopban az a kk alatti elemeket kinulláztuk, a fölötte lévő elemeket is zérussá lehet tenni.