Tanulás elosztott rendszerekben/3
|
|
|
- Valéria Faragóné
- 5 évvel ezelőtt
- Látták:
Átírás
1 Tanulás elosztott rendszerekben/3
2 MARL Multi Agent Reinforcement Learning Többágenses megerősítéses tanulás Kezdjük egy ágenssel. Legyenek a környezeti állapotai s-ek, cselekvései a-k, az ágens cselekvéseit meghatározó eljárásmód p, ill. ágens cselekvés-érték függvénye Q(s,a). Az állapotok és a cselekvések közötti kapcsolatot az un. Markov döntési folyamat (MDF) írja le, T(s,a,s ) átmenet-valószínűségel. Egyes állapotokban ágens r(s,a,s ) közvetlen megerősítést kap. Ágens célja megállapítani azt az optimális eljárásmódot, ami a diszkont hátralévő jutalmat (az s k állapottól végtelen jövőbe) maximálja, ahol γ a diszkont faktor és r a megerősítés. j Rk E rk j1 j0 Adott eljárásmód mellett az ágens cselekvés-érték függvényt tanul p j Q s, a E rk j1 sk s, ak a, p j0
3 MARL Multi Agent Reinforcement Learning Többágenses megerősítéses tanulás A lehető legjobb eredmény az optimális cselekvés-érték függvény: ami teljesíti az un. Bellman egyenletet:, max p, Q s a Q s a, (,, ) (,, ) max, Q s a T s a s r s a s a Q s a s S Az ágens eljárásmódja mohó: p s arg max, ami optimális, ha Q is optimális. a Q s a p
4 A Bellman-egyenlet ismeretlen r és T mellett az un. Q-tanulással oldható meg (jelen formában időkülönbség Q-tanulással):,, max,, 1 Q s, a r max Q s, a Q s a Q s a r Q s a Q s a k1 k k k k k k k 1 a k k 1 k k k k k k k k k1 a k k 1 Q-tanulás bizonyos feltételek mellett optimális Q-hoz konvergál. A legfontosabb feltétel, hogy a tanuló ágensnek nem nulla valószínűséggel ki kell próbálnia minden létező cselekvését. Nem tud tehát csak mohó lenni, a mohóságát felfedezési igénnyel kell vegyítenie. A mohóság + felfedezés keverékviselkedést biztosítani tudjuk: - ε-mohósággal: az ágens ε valószínűséggel véletlen cselekvést választ, ill. 1-ε valószínűséggel mohó, vagy - Boltzmann-felfedezési modellel, ahol egy a cselekvés megválasztásának valószínűsége egy s állapotban: ahol a T hőmérséklet a két véglet között szabályoz. ha T, akkor a választás tisztán (egyenletesen) véletlen, ha T 0, akkor a választás mohó. p sa, e e a Q( s, a)/ T Q( s, a)/ T
5 Többágenses eset: - (matrix) játék (stage game), hasznossági (payoff) mátrixxal definiált, - ismételt játék (repeated game, iterative game), minden fordulóban ugyanazt a mátrixjátékot játsszák, - sztochasztikus játék (stochastic game, SG), a MDF többágenses kiterjesztése, ahol az állapotátmeneteket és a kapott megerősítést az összes ágens együttes cselekvése határozza meg, és ahol az egyedi ágensek eljárásmódjai mellett beszélünk az együttes eljárásmódról is. Mindegyik állapotban az ágensek új mátrix játékot játszanak, aminek mátrixát a tanult hasznosságok határozzák meg. Megjegyzés: - Egy mátrix játékban mindegyik ágens megerősítése/ hasznossága függ az állapottól és az összes ágens együttes cselekvésétől (joint action, joint learners) - MDF a sztochasztikus játék egyágenses esete - Ismételt játék a sztochasztikus játék egyetlenegy állapotú esete. N, S, A A, T, R, T : S A S [0,1], R : S A kn k k k R( s, a) i
6 Játék lehet modell-alapú. Akkor az ágens először megtanulja az ellenfél stratégiáját, majd talál rá a legjobb választ. Lehet model-nélküli is, amikor az ágens az ellenfelélre jó választ adó stratégiát tanulja meg anélkül, hogy az ellenfél stratégiáját explicite kitanulná. Jelölje egy-egy ágens megerősítését generáló függvényt ρ i. Beszélhetünk akkor - teljesen kooperatív ágensrendszerekről 1... n - teljesen versengő ágensrendszerekről, ill. (két ágens, zérus összegű) 1 2 és ρ 1 + ρ 2 + ρ n = 0, több ágens esetén - vegyes ágensrendszerekről (általános összegű, ahol semmilyen feltétel nem adható) n 0 Minden zérus-összegű mátrix játéknak van NE-ja tiszta stratégiákban. (Neumann) Minden általános összegű mátrix játéknak van NE-ja. (Nash) Minden teljesen versengő sztochasztikus játéknak van NE-ja (Shapley) Minden általános (vegyes) sztochasztikus játéknak van NE-ja. (Fink)
7 Pl. Stackelberg-féle játék Left Right Up 1, 0 3, 2 Down 2, 1 4, 0 Down a sorjátékos domináns stratégiája. Sorjátékos meg fogja játszani a Down -t. Ezt megsejtve az oszlopjátékos Left -tel készül. Eredményben a szociális jólét = 3. A sorjátékos sorozatban játsza meg az Up -ot. Erre a jelzésre az oszlopjátékos Right -tal készül válaszolni. Eredményben a szociális jólét = 5, nemcsak az összegében nagyobb, de egyenként is. Többágenses környezetben nemigen választható szét a tanulás éa a tanítás.
8 Többágenses megerősítéses tanulás problémái: Alapvető problémák: nem stacionárius (l. előbbi előadás) a szokásos (egy ágenses) bizonyítható konvergencia lehetetlen. koordinálás igénye (pl. több NE esetén) Mi legyen a tanulás célja? (1) Stabilitás - Konvergencia stratégiában valamilyen egyensúlyhoz (pl. NE), ha a saját maga ellen játszik (self-play, minden ágens ugyanazt a tanulási algoritmust használja) (2) Adaptivítás - Az ellenfél stratégiájának sikeres megtanulása. (3) Egy bizonyos hasznossági szintet túlhaladó nyerességek megszerzése. Milyen tulajdonságokkal rendelkezzen egy tanulási algoritmus? (1) Biztonságos (Safe) garantáljon legalább a minimax szintű nyerességet. (2) Konzisztens (Consistent) legalább ilyen jó, mint az egyensúlyi esetre számított legjobb válasz (best response). (P1) Konvergencia - Konvergáljon egy stacionárius eljárásmódhoz. (P2) Racionalitás - Ha az ellenfél egy stacionárius stratégiához konvergál, a tanulónak a legjobb válaszhoz kell konvergálnia.
9 Egyensúlyok pro és kontra Pro Egyensúly feltételeket fogalmaz meg, hogy a tanulásnak mikor le kell, le kellene állnia. Egyensúlyban egyszerűbb a játék (kevesebb erőforrás, számítás) Kontra NE nem egy előírás jellegű. Több egyensúly is lehet. Valamilyen konkrét egyensúlyra vonatkozó ötletadás nem lehetséges (vagy csalás) Az ellenfél nem biztos, hogy az egyensúlyra vágyik (és játszik). NE egyensúly számításának komplexitása általános játékok esetén tiltó lehet.
10 Egy ágenstől több ágensig,, max,, Q s a Q s a r Q s a Q s a k 1 k k k k k k k 1 a k k1 k k k Mások cselekvései is, a, a max, a, a Q s Q s r Q s Q s k 1 k k k k k k k 1 a k k1 k k k Valami más, ami a cselekvések baráti, vagy adverz jellegére utal és eszerint számítja ki a várható jövőt., a, a, a Q s Q s r XYZ Q s k1 k k k k k k k1 k k k 1 ágens 2 ágens N ágens
11 Teljes együttműködés Optimális együttes Q értékek parallel tanulása és belőle egyenkénti optimális eljárásmód származtatása Együttműködés ellenére probléma a koordinálás szükségessége. Példa: formáció-mozgás 1... n, a, a max, a, a Q s Q s r Q s Q s k 1 k k k k k k 1 a k k1 k k k s a arg max max Q s, a p i ai a1,..., ai1, ai1,..., an A két optimális helyzet ellenére, koordinálás hiányában ágensek szuboptimális Q( L1, R2) helyzetben végezhetnek. (ha a Q érték közös, mindkét optimális eset egy Nash egyensúly) Q( L, L ) Q( R, R ) 10
12 (e,e) koordinálása, ha nem tökéletes, bűntetésbe visz. Biztonságosabb a szuboptimális (d, *), (*, d).
13 Koordinálás kérdése Koordinálás-mentes pl. Team-Q: optimális együttes cselekvés egyedi jellegét tételezi fel Distributed-Q-Learning: lokális Q és p tanulás, de az egyedi Q frissítése csak akkor, ha növekszik (a közös optimális Q értéket is el fogja kapni). A stratégia frissítése csak akkor, ha a Q érték növekszik., max,, max, Q s a Q s a r Q s a i, k1 k i, k i, k k i, k k1 a i, k k1 i i
14 Koordinálás kérdése Koordinálás-alapú pl. együttes Q dekomponálása kisebb csoportasulások szerint. (koordinációs gráfok) Q( s, a) Q ( s, a ) Q ( s, a, a ) Q ( s, a, a ) Q( s, a) Q ( s, a, a ) Q ( s, a, a ) Q ( s, a )
15 Koordinálás kérdése Indirekt koordinálás pl. tanulva mások (stacionárius probabilisztikus) empirikus modelljét, hogy egyes cselekvéseit milyen gyakorisággal használják: JAL Joint Action Learner C i j (u j ) i-edik ágens hányszor látta, hogy az j-edik ágens egy a j cselekvéséhez i folyamodik, erre a legjobb válasz számítása i ˆ ( a ) ( a ) j j j j i C a A j ( a ) Frequency Maximum Q-value heurisztika: mely cselekvések jók voltak a múltban? r max (a i ) - az a i re eddig kapott max megerősítés, C i max (a i ) ennek a gyakorisága és C i (a i ) az a i cselekvés (önmagában) gyakorisága (az a i -re több megerősítés is jöhetett, szórás csakis a mások cselekvései miatt, determinisztikus probléma). A számított Q értéket a Boltzmann-felfedezés képletében használja (v egy súly). C ( a ) Q a Q a r a Explicit koordinálás pl. társadalmi szabályok pl. ágens 1 < ágens 2 normatívák, törvények L < R < S kommunikáció döntés (L 1, L 2 ) szerepek Intelligens Elosztott... Rendszerek BME-MIT, 2019 i max i i( i) i( i) max ( i) i C ( ai ) C j j j
16 Teljes versengés Minimax Q-tanulás (1. ágens esete, Q = Q 1 = - Q 2 ),,,, Q s a a Q s a a k1 k 1, k 2, k k k 1, k 2, k r m ( Q, s ) Q s, a, a k1 1 k k 1 k k 1, k 2, k m ( Q, s) max min p ( s, a ) Q( s, a, a ) 1 p ( s, ) a a p s, arg m ( Q, s ) 1, k k 1 k k Az 1. ágens minimax haszna Garantált konvergencia (NE) (self-play), de nem racionális.
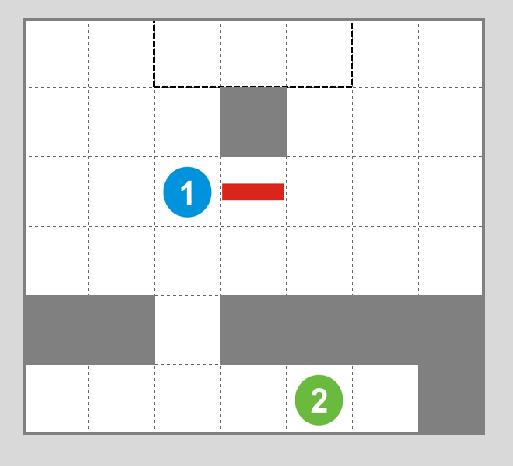
17 Teljes versengés Minimax Q-tanulás, példa 1. ágens szeretne elfoglalni a keresztet és elmenekülni. 2. ágens szeretne elkapni az 1. ágenst. A Q táblázat az 1. ágens perspektíváját mutatja, a 2. ágens Q függvénye ennek (-1)-szerese. A minimax megoldás 1. ágensre: Ha L 1 -et lép, akkor a 2. minimalizálva L 2 -et lép, eredményben 0. Ha R 1 -et lép, akkor a 2. minimalizálva szintén L 2 -et lép, eredményben -10. Az 1. ágensnek tehát L 1 -et kell lépnie, mert így legfeljebb 0-val megússza.
18 Vegyes feladatok Nincsenek feltételek megerősítésekre. Valamilyen egyensúly felé mégis húzni kell. Lehet pl. Nash-egyensúly, de mi van, ha több van ilyen? Egyedi ágens Q-tanulás (a többi implicite a környezeti információban) Ágens-független módszerek (egymástól független, de feltehetően egy közös egyensúly fel), pl. Nash-Q-tanulás., a, a eval (,.), a Q s Q s r Q s Q s i, k1 k k i, k k k i, k1 i., k k1 i, k k k eval p solve s, solve Q ( s,.) i, k i., k k Q., s V s NEQ., s i Q., k ( s,.) NEi Q., k ( s,.) (,.) (, (,.) ) i k i k NE az egyensúly kiszámítása, NE i az i-ik ágens stratégiája az egyensúlyban és V i az ágens várható haszna s-ben az egyensúlyban. Bizonyos feltételekkel NE-hoz konvergál. Mindegyik ágens számon tartja mások Q értékeit is!
19 Vegyes feladatok Nash-Q egyszerübben: FoF Friend-or-Foe tanulás Fel kell ismerni, hogy az ellenfél kooperál, vagy ellenünk dolgozik. Kooperál esetében: JAL megoldás, a Q közös maximumára való törekvés Ellenünk van: minimax-q játék. Nash ( s, Q, Q ) max Q ( s, a, a ) a, a Nash ( s, Q, Q ) max min p ( s, a ) Q ( s, a, a ) p ( s, ) a a Ellenséges egyensúly (EE): ha mások tőle eltérnek, az ágensünk helyzete változatlan lesz, vagy javul. Kooperatív egyensúly (KE): ahol az ágensek maximális haszonhoz jutnak (a jóléti megoldás). Ha a játéknak van EE egysúlya, FOE-Q tanulás ezt megtanulja. Ha a jatéknak van KE egyensúlya, FRIEND-Q tanulás ezt megtanulja.

20 Vegyes feladatok Problémák egyensúlyi helyzetek koordinálásával itt is, pl.: Két porszívóágens feladata a két szobából álló lakás kitakarítása. Mindegyik jobban szeretne a bal szobát megkapni, mert ez kisebb. ( L, R ), ( R, L ) Két Nash-egyensúly van: de ha a két ágens között nincs koordináció (nincs megegyezés melyik NE-re játszanak, akkor mindketten ugyanabban a szobában végeznek, kisebb hasznossággal. Q ( L, L ) Q ( R, R ) Q ( L, L ) Q ( R, R )
21 Vegyes feladatok Ágens-követő, ágens-tudatos módszerek (más ágensek modellezése, a modell használata tanulásban: - érzékelés + stratégia-váltás) AWESOME (Adapt When Everyone is Stationary, Otherwise Move to Equilibrium) Induláskor p i egyensúlyi stratégiát játszik (az i-ik ágens) és mások cselekvéseit követi. Minden N-ik kör végére a megfigyelt gyakoriságokból kiszámítja az s j -t, az j-ik ágens (feltehetően vegyes) stratégia becslését. Ha s j minden j-ik játékos stratégiája egyensúlyi, akkor i folytatja az egyensúlyi stratégiájának bevetését. Különben az i-ik ágens megjátsza az s j stratégiára kiszámított legjobb válasz stratégiáját (best response). Ha minden játékos AWESOME játékos, akkor a közös tanulás az egyensúlyi helyzethez konvergál és nem fog tőle eltérni.
22 Vegyes feladatok IGA (Infinitensimal Gradient Ascent) ágensek cselekvéseinek a valószínűsége az, amit az ágensek tanulnak (2 ágens, 2 cselekvés), α az 1. ágens 1. cselekvésének a valószínűsége és β a 2. ágens 1. cselekvésének a valószínűsége: k 1 k 1, k k 1 k 2, k E r 1 2, E r, 1, k 2, k
23 Vegyes feladatok WoLF-IGA (Win-or-Learn-Fast) - győztes helyzetben ágens óvatos, kis δ-val lassan tanul, nehogy az előnyös pozícióját elveszítse, - vesztes esetben viszont nagyobb δ-val gyorsan igyekszik kikerülni a jelen helyzetből. k 1 k 1, k k 1 k 2, k E r 1 2, Hogyan látszik meg melyik a győzelem, melyik a vesztes állapot? E r, WoLF-elv: Ha a várható hasznom, ahogy játszom és ahogy az ellenfél játszik, jobb, mintha a jelen játéka mellett én az egyensúlyi stratégiámot játszanám, akkor győzelemre állok. Ha rosszabbul állok az egyensúlyi stratégiámhoz képest (az ellenfél adott játéka mellett), akkor vesztésre állok. Lucian Busoniu, Robert Babuska, and Bart De Schutter, A Comprehensive Survey of Multiagent Reinforcement Learning, IEEE Trans. on Systems, Man, and Cybernetics Part C: Applications and Reviews, Vol. 38, No. 2, March 2008,, 0 1, k 2, k min max
, ellenfelek cs., szövetségesek cs., saját magam cs. : 4 x H x H.")
24 Többágenses mély megerősítéses tanulás, a, a max, a, a,, a θ Q s Q s r a Q s Q s Q s a θi a a θi a θi L min L s, r max Q s, Q s, θ θ θ θ i1 i i Környezet 2 dim, 2 ágens tipus, diszkrét tér/idő. Konvolúciós NN csatornák: háttér cs. (akadályok), ellenfelek cs., szövetségesek cs., saját magam cs. : 4 x H x H. 2
25 Többágenses mély megerősítéses tanulás Tanulás: egyszerre 1 ágens, a többinek stratégiája fix, a megtanult stratégia kiosztása a saját tipusú ágensekre.


26 Többágenses mély megerősítéses tanulás Szimulációk startuprl.m alg_gui.m rrgwdemo.m
Tanulás elosztott rendszerekben/2. Intelligens Elosztott Rendszerek BME-MIT, 2018
 Tanulás elosztott rendszerekben/2 Rétegezett tanulás (Layered Learning) Közvetlen bemeneti adat kimenet függvény tanulása nem megy - hierarchiadekompozíció, taszk feltörése rétegekre, - más-más koncepció
Tanulás elosztott rendszerekben/2 Rétegezett tanulás (Layered Learning) Közvetlen bemeneti adat kimenet függvény tanulása nem megy - hierarchiadekompozíció, taszk feltörése rétegekre, - más-más koncepció
Megerősítéses tanulási módszerek és alkalmazásaik
 MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Megerősítéses tanulási módszerek és alkalmazásaik Tompa Tamás tanársegéd Általános Informatikai Intézeti Tanszék Miskolc, 2017. szeptember 15. Tartalom
MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Megerősítéses tanulási módszerek és alkalmazásaik Tompa Tamás tanársegéd Általános Informatikai Intézeti Tanszék Miskolc, 2017. szeptember 15. Tartalom
Megerősítéses tanulás
 Gépi tanulás (Szekvenciális döntési probléma) Megerősítéses tanulás Pataki Béla BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Az egész világot nem tudjuk modellezni,
Gépi tanulás (Szekvenciális döntési probléma) Megerősítéses tanulás Pataki Béla BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Az egész világot nem tudjuk modellezni,
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Keresés ellenséges környezetben Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Ellenség
Mesterséges Intelligencia MI Keresés ellenséges környezetben Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Ellenség
Kooperáció és intelligencia
 Kooperáció és intelligencia Tanulás többágenses szervezetekben/3 MARL Multi Agent Reinforcement Learning Többágenses megerősítéses tanulás: áttekintés Kezdjük 1 db ágenssel. Legyenek a környezet állapotai
Kooperáció és intelligencia Tanulás többágenses szervezetekben/3 MARL Multi Agent Reinforcement Learning Többágenses megerősítéses tanulás: áttekintés Kezdjük 1 db ágenssel. Legyenek a környezet állapotai
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Megerősítéses tanulás Pataki Béla BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Ágens tudása: Induláskor: vagy ismeri már a környezetet
Mesterséges Intelligencia MI Megerősítéses tanulás Pataki Béla BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Ágens tudása: Induláskor: vagy ismeri már a környezetet
Döntési rendszerek I.
 Döntési rendszerek I. SZTE Informatikai Intézet Számítógépes Optimalizálás Tanszék Készítette: London András 8 Gyakorlat Alapfogalmak A terület alapfogalmai megtalálhatók Pluhár András Döntési rendszerek
Döntési rendszerek I. SZTE Informatikai Intézet Számítógépes Optimalizálás Tanszék Készítette: London András 8 Gyakorlat Alapfogalmak A terület alapfogalmai megtalálhatók Pluhár András Döntési rendszerek
Monoton Engedmény Protokoll N-M multilaterális tárgyalás
 Tárgyalások/2 Monoton Engedmény Protokoll N-M multilaterális tárgyalás Fordulók 1. Minden ágens előáll a javaslatával k. Mindegyik ágens vagy ragaszkodik a javaslatához, vagy engedményt tesz. Ismétlés
Tárgyalások/2 Monoton Engedmény Protokoll N-M multilaterális tárgyalás Fordulók 1. Minden ágens előáll a javaslatával k. Mindegyik ágens vagy ragaszkodik a javaslatához, vagy engedményt tesz. Ismétlés
Rasmusen, Eric: Games and Information (Third Edition, Blackwell, 2001)
") Játékelmélet szociológusoknak J-1 Bevezetés a játékelméletbe szociológusok számára Ajánlott irodalom: Mészáros József: Játékelmélet (Gondolat, 2003) Filep László: Játékelmélet (Filum, 2001) Csontos László
Játékelmélet szociológusoknak J-1 Bevezetés a játékelméletbe szociológusok számára Ajánlott irodalom: Mészáros József: Játékelmélet (Gondolat, 2003) Filep László: Játékelmélet (Filum, 2001) Csontos László
13. Tanulás elosztott rendszerekben/1. Intelligens Elosztott Rendszerek BME-MIT, 2017
 13. Tanulás elosztott rendszerekben/1 (Egyedi ágens) tanulásáról röviden Célja: javulás (feladavégzésben), adaptalódás, robusztusság (környezet), kompenzálás, hibatürés (ismerethiány, meghibasodás) Miből:
13. Tanulás elosztott rendszerekben/1 (Egyedi ágens) tanulásáról röviden Célja: javulás (feladavégzésben), adaptalódás, robusztusság (környezet), kompenzálás, hibatürés (ismerethiány, meghibasodás) Miből:
Korszerű információs technológiák
 MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Korszerű információs technológiák Megerősítéses tanulási módszerek és alkalmazásaik Tompa Tamás tanársegéd Általános Informatikai Intézeti Tanszék Miskolc,
MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Korszerű információs technológiák Megerősítéses tanulási módszerek és alkalmazásaik Tompa Tamás tanársegéd Általános Informatikai Intézeti Tanszék Miskolc,
Megerősítéses tanulás 2. előadás
 Megerősítéses tanulás 2. előadás 1 Technikai dolgok Email szityu@eotvoscollegium.hu Annai levlista http://nipglab04.inf.elte.hu/cgi-bin/mailman/listinfo/annai/ Olvasnivaló: Sutton, Barto: Reinforcement
Megerősítéses tanulás 2. előadás 1 Technikai dolgok Email szityu@eotvoscollegium.hu Annai levlista http://nipglab04.inf.elte.hu/cgi-bin/mailman/listinfo/annai/ Olvasnivaló: Sutton, Barto: Reinforcement
Megerősítéses tanulás 7. előadás
 Megerősítéses tanulás 7. előadás 1 Ismétlés: TD becslés s t -ben stratégia szerint lépek! a t, r t, s t+1 TD becslés: tulajdonképpen ezt mintavételezzük: 2 Akcióértékelő függvény számolása TD-vel még mindig
Megerősítéses tanulás 7. előadás 1 Ismétlés: TD becslés s t -ben stratégia szerint lépek! a t, r t, s t+1 TD becslés: tulajdonképpen ezt mintavételezzük: 2 Akcióértékelő függvény számolása TD-vel még mindig
Adaptív menetrendezés ADP algoritmus alkalmazásával
 Adaptív menetrendezés ADP algoritmus alkalmazásával Alcím III. Mechwart András Ifjúsági Találkozó Mátraháza, 2013. szeptember 10. Divényi Dániel Villamos Energetika Tanszék Villamos Művek és Környezet
Adaptív menetrendezés ADP algoritmus alkalmazásával Alcím III. Mechwart András Ifjúsági Találkozó Mátraháza, 2013. szeptember 10. Divényi Dániel Villamos Energetika Tanszék Villamos Művek és Környezet
Kétszemélyes játékok Gregorics Tibor Mesterséges intelligencia
 Kétszemélyes játékok Kétszemélyes, teljes információjú, véges, determinisztikus,zéró összegű játékok Két játékos lép felváltva adott szabályok szerint, amíg a játszma véget nem ér. Mindkét játékos ismeri
Kétszemélyes játékok Kétszemélyes, teljes információjú, véges, determinisztikus,zéró összegű játékok Két játékos lép felváltva adott szabályok szerint, amíg a játszma véget nem ér. Mindkét játékos ismeri
Nem-kooperatív játékok
 Nem-kooperatív játékok Versengő ágensek konfliktusai játékelmélet Cselekvéseivel mások cselekvéseinek hatását befolyásolják. Ettől a cselekvések (mind) várható haszna meg fog változni. A változás az én
Nem-kooperatív játékok Versengő ágensek konfliktusai játékelmélet Cselekvéseivel mások cselekvéseinek hatását befolyásolják. Ettől a cselekvések (mind) várható haszna meg fog változni. A változás az én
Bonyolult jelenség, aminek nincs jó modellje, sok empirikus adat, intelligens (ember)ágens képessége, hogy ilyen problémákkal mégis megbirkozzék.
ágens képessége, hogy ilyen problémákkal mégis megbirkozzék.") Vizsga, 2015. dec. 22. B cs. B1. Hogyan jellemezhetők a tanulást igénylő feladatok? (vendégelőadás) Bonyolult jelenség, aminek nincs jó modellje, sok empirikus adat, intelligens (ember)ágens képessége,
Vizsga, 2015. dec. 22. B cs. B1. Hogyan jellemezhetők a tanulást igénylő feladatok? (vendégelőadás) Bonyolult jelenség, aminek nincs jó modellje, sok empirikus adat, intelligens (ember)ágens képessége,
Mátrixjátékok tiszta nyeregponttal
 1 Mátrixjátékok tiszta nyeregponttal 1. Példa. Két játékos Aladár és Bendegúz rendelkeznek egy-egy tetraéderrel, melyek lapjaira rendre az 1, 2, 3, 4 számokat írták. Egy megadott jelre egyszerre felmutatják
1 Mátrixjátékok tiszta nyeregponttal 1. Példa. Két játékos Aladár és Bendegúz rendelkeznek egy-egy tetraéderrel, melyek lapjaira rendre az 1, 2, 3, 4 számokat írták. Egy megadott jelre egyszerre felmutatják
12. előadás - Markov-láncok I.
 12. előadás - Markov-láncok I. 2016. november 21. 12. előadás 1 / 15 Markov-lánc - definíció Az X n, n N valószínűségi változók sorozatát diszkrét idejű sztochasztikus folyamatnak nevezzük. Legyen S R
12. előadás - Markov-láncok I. 2016. november 21. 12. előadás 1 / 15 Markov-lánc - definíció Az X n, n N valószínűségi változók sorozatát diszkrét idejű sztochasztikus folyamatnak nevezzük. Legyen S R
Stratégiák tanulása az agyban
 Statisztikai tanulás az idegrendszerben, 2019. Stratégiák tanulása az agyban Bányai Mihály banyai.mihaly@wigner.mta.hu http://golab.wigner.mta.hu/people/mihaly-banyai/ Kortárs MI thispersondoesnotexist.com
Statisztikai tanulás az idegrendszerben, 2019. Stratégiák tanulása az agyban Bányai Mihály banyai.mihaly@wigner.mta.hu http://golab.wigner.mta.hu/people/mihaly-banyai/ Kortárs MI thispersondoesnotexist.com
Diverzifikáció Markowitz-modell MAD modell CAPM modell 2017/ Szegedi Tudományegyetem Informatikai Intézet
 Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 11. Előadás Portfólió probléma Portfólió probléma Portfólió probléma Adott részvények (kötvények,tevékenységek,
Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 11. Előadás Portfólió probléma Portfólió probléma Portfólió probléma Adott részvények (kötvények,tevékenységek,
1. feladat Az egyensúly algoritmus viselkedése: Tekintsük a kétdimenziós Euklideszi teret, mint metrikus teret. A pontok
 1. feladat Az egyensúly algoritmus viselkedése: Tekintsük a kétdimenziós Euklideszi teret, mint metrikus teret. A pontok (x, y) valós számpárokból állnak, két (a, b) és (c, d) pontnak a távolsága (a c)
1. feladat Az egyensúly algoritmus viselkedése: Tekintsük a kétdimenziós Euklideszi teret, mint metrikus teret. A pontok (x, y) valós számpárokból állnak, két (a, b) és (c, d) pontnak a távolsága (a c)
Mikroökonómia I. B. ELTE TáTK Közgazdaságtudományi Tanszék. 12. hét STRATÉGIAI VISELKEDÉS ELEMZÉSE JÁTÉKELMÉLET
 MIKROÖKONÓMIA I. B ELTE TáTK Közgazdaságtudományi Tanszék Mikroökonómia I. B STRATÉGIAI VISELKEDÉS ELEMZÉSE JÁTÉKELMÉLET K hegyi Gergely, Horn Dániel, Major Klára Szakmai felel s: K hegyi Gergely 2010.
MIKROÖKONÓMIA I. B ELTE TáTK Közgazdaságtudományi Tanszék Mikroökonómia I. B STRATÉGIAI VISELKEDÉS ELEMZÉSE JÁTÉKELMÉLET K hegyi Gergely, Horn Dániel, Major Klára Szakmai felel s: K hegyi Gergely 2010.
DIFFERENCIAEGYENLETEK
 DIFFERENCIAEGYENLETEK Példa: elsőrendű állandó e.h. lineáris differenciaegyenlet Ennek megoldása: Kezdeti feltétellel: Kezdeti feltétel nélkül ha 1 és a végtelen összeg (abszolút) konvergens: / 1 Minden
DIFFERENCIAEGYENLETEK Példa: elsőrendű állandó e.h. lineáris differenciaegyenlet Ennek megoldása: Kezdeti feltétellel: Kezdeti feltétel nélkül ha 1 és a végtelen összeg (abszolút) konvergens: / 1 Minden
Markov-láncok stacionárius eloszlása
 Markov-láncok stacionárius eloszlása Adatbányászat és Keresés Csoport, MTA SZTAKI dms.sztaki.hu Kiss Tamás 2013. április 11. Tartalom Markov láncok definíciója, jellemzése Visszatérési idők Stacionárius
Markov-láncok stacionárius eloszlása Adatbányászat és Keresés Csoport, MTA SZTAKI dms.sztaki.hu Kiss Tamás 2013. április 11. Tartalom Markov láncok definíciója, jellemzése Visszatérési idők Stacionárius
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FELÜGYELT ÉS MEGERŐSÍTÉSES TANULÓ RENDSZEREK FEJLESZTÉSE
 FELÜGYELT ÉS MEGERŐSÍTÉSES TANULÓ RENDSZEREK FEJLESZTÉSE Dr. Aradi Szilárd, Fehér Árpád Mesterséges intelligencia kialakulása 1956 Dartmouth-i konferencián egy maroknyi tudós megalapította a MI területét
FELÜGYELT ÉS MEGERŐSÍTÉSES TANULÓ RENDSZEREK FEJLESZTÉSE Dr. Aradi Szilárd, Fehér Árpád Mesterséges intelligencia kialakulása 1956 Dartmouth-i konferencián egy maroknyi tudós megalapította a MI területét
Megerősítéses tanulás
 Megerősítéses tanulás elméleti kognitív neurális Introduction Knowledge representation Probabilistic models Bayesian behaviour Approximate inference I (computer lab) Vision I Approximate inference II:
Megerősítéses tanulás elméleti kognitív neurális Introduction Knowledge representation Probabilistic models Bayesian behaviour Approximate inference I (computer lab) Vision I Approximate inference II:
PIACI JÁTSZMÁK. Bevezető Közgazdaságtan Tanszék
 PIACI JÁTSZMÁK Bevezető 2018. 09. 03 Közgazdaságtan Tanszék banhidiz@kgt.bme.hu Általános információk Piaci játszmák (BMEGT30V200) Oktatók és témakörök: Bánhidi Zoltán (banhidiz@kgt.bme.hu) Bevezető témakörök
PIACI JÁTSZMÁK Bevezető 2018. 09. 03 Közgazdaságtan Tanszék banhidiz@kgt.bme.hu Általános információk Piaci játszmák (BMEGT30V200) Oktatók és témakörök: Bánhidi Zoltán (banhidiz@kgt.bme.hu) Bevezető témakörök
Diszkrét idejű felújítási paradoxon
 Magda Gábor Szaller Dávid Tóvári Endre 2009. 11. 18. X 1, X 2,... független és X-szel azonos eloszlású, pozitív egész értékeket felvevő valószínűségi változó (felújítási idők) P(X M) = 1 valamilyen M N
Magda Gábor Szaller Dávid Tóvári Endre 2009. 11. 18. X 1, X 2,... független és X-szel azonos eloszlású, pozitív egész értékeket felvevő valószínűségi változó (felújítási idők) P(X M) = 1 valamilyen M N
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Racionalitás: a hasznosság és a döntés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade
Mesterséges Intelligencia MI Racionalitás: a hasznosság és a döntés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade
Hidden Markov Model. March 12, 2013
 Hidden Markov Model Göbölös-Szabó Julianna March 12, 2013 Outline 1 Egy példa 2 Feladat formalizálása 3 Forward-algoritmus 4 Backward-algoritmus 5 Baum-Welch algoritmus 6 Skálázás 7 Egyéb apróságok 8 Alkalmazás
Hidden Markov Model Göbölös-Szabó Julianna March 12, 2013 Outline 1 Egy példa 2 Feladat formalizálása 3 Forward-algoritmus 4 Backward-algoritmus 5 Baum-Welch algoritmus 6 Skálázás 7 Egyéb apróságok 8 Alkalmazás
V. Kétszemélyes játékok
 Teljes információjú, véges, zéró összegű kétszemélyes játékok V. Kétszemélyes játékok Két játékos lép felváltva adott szabályok szerint. Mindkét játékos ismeri a maga és az ellenfele összes választási
Teljes információjú, véges, zéró összegű kétszemélyes játékok V. Kétszemélyes játékok Két játékos lép felváltva adott szabályok szerint. Mindkét játékos ismeri a maga és az ellenfele összes választási
JÁTÉKELMÉLETTEL KAPCSOLATOS FELADATOK
 1.Feladat JÁTÉKELMÉLETTEL KAPCSOLATOS FELADATOK Az alábbi kifizetőmátrixok három különböző kétszemélyes konstans összegű játék sorjátékosának eredményeit mutatják: 2 1 0 2 2 4 2 3 2 4 0 0 1 0 1 5 3 4 3
1.Feladat JÁTÉKELMÉLETTEL KAPCSOLATOS FELADATOK Az alábbi kifizetőmátrixok három különböző kétszemélyes konstans összegű játék sorjátékosának eredményeit mutatják: 2 1 0 2 2 4 2 3 2 4 0 0 1 0 1 5 3 4 3
Problémamegoldás kereséssel. Mesterséges intelligencia március 7.
 Problémamegoldás kereséssel Mesterséges intelligencia 2014. március 7. Bevezetés Problémamegoldó ágens Kívánt állapotba vezető cselekvéseket keres Probléma megfogalmazása Megoldás megfogalmazása Keresési
Problémamegoldás kereséssel Mesterséges intelligencia 2014. március 7. Bevezetés Problémamegoldó ágens Kívánt állapotba vezető cselekvéseket keres Probléma megfogalmazása Megoldás megfogalmazása Keresési
Navigáci. stervezés. Algoritmusok és alkalmazásaik. Osváth Róbert Sorbán Sámuel
 Navigáci ció és s mozgástervez stervezés Algoritmusok és alkalmazásaik Osváth Róbert Sorbán Sámuel Feladat Adottak: pálya (C), játékos, játékos ismerethalmaza, kezdőpont, célpont. Pálya szerkezete: akadályokkal
Navigáci ció és s mozgástervez stervezés Algoritmusok és alkalmazásaik Osváth Róbert Sorbán Sámuel Feladat Adottak: pálya (C), játékos, játékos ismerethalmaza, kezdőpont, célpont. Pálya szerkezete: akadályokkal
Markov modellek 2015.03.19.
 Markov modellek 2015.03.19. Markov-láncok Markov-tulajdonság: egy folyamat korábbi állapotai a későbbiekre csak a jelen állapoton keresztül gyakorolnak befolyást. Semmi, ami a múltban történt, nem ad előrejelzést
Markov modellek 2015.03.19. Markov-láncok Markov-tulajdonság: egy folyamat korábbi állapotai a későbbiekre csak a jelen állapoton keresztül gyakorolnak befolyást. Semmi, ami a múltban történt, nem ad előrejelzést
Megerősítéses tanulás 9. előadás
 Megerősítéses tanulás 9. előadás 1 Backgammon (vagy Ostábla) 2 3 TD-Gammon 0.0 TD() tanulás (azaz időbeli differencia-módszer felelősségnyomokkal) függvényapproximátor: neuronháló 40 rejtett (belső) neuron
Megerősítéses tanulás 9. előadás 1 Backgammon (vagy Ostábla) 2 3 TD-Gammon 0.0 TD() tanulás (azaz időbeli differencia-módszer felelősségnyomokkal) függvényapproximátor: neuronháló 40 rejtett (belső) neuron
Döntési rendszerek I.
 Döntési rendszerek I. SZTE Informatikai Intézet Számítógépes Optimalizálás Tanszék Készítette: London András 7. Gyakorlat Alapfogalmak A terület alapfogalmai megtalálhatók Pluhár András Döntési rendszerek
Döntési rendszerek I. SZTE Informatikai Intézet Számítógépes Optimalizálás Tanszék Készítette: London András 7. Gyakorlat Alapfogalmak A terület alapfogalmai megtalálhatók Pluhár András Döntési rendszerek
Sapientia - Erdélyi Magyar TudományEgyetem (EMTE) Csíkszereda IRT- 4. kurzus. 3. Előadás: A mohó algoritmus
 Csíkszereda IRT- 4. kurzus. 3. Előadás: A mohó algoritmus") Csíkszereda IRT-. kurzus 3. Előadás: A mohó algoritmus 1 Csíkszereda IRT. kurzus Bevezetés Az eddig tanult algoritmus tipúsok nem alkalmazhatók: A valós problémák nem tiszta klasszikus problémák A problémák
Csíkszereda IRT-. kurzus 3. Előadás: A mohó algoritmus 1 Csíkszereda IRT. kurzus Bevezetés Az eddig tanult algoritmus tipúsok nem alkalmazhatók: A valós problémák nem tiszta klasszikus problémák A problémák
Ismételt játékok: véges és végtelenszer. Kovács Norbert SZE GT. Példa. Kiindulás: Cournot-duopólium játék Inverz keresleti görbe: P=150-Q, ahol
 9. elõaás Ismételt játékok: véges és végtelenszer történõ smétlés Kovács Norbert SZE GT Az elõaás menete Ismételt játékok Véges sokszor smételt játékok Végtelenszer smételt játékok Péla Knulás: ournot-uopólum
9. elõaás Ismételt játékok: véges és végtelenszer történõ smétlés Kovács Norbert SZE GT Az elõaás menete Ismételt játékok Véges sokszor smételt játékok Végtelenszer smételt játékok Péla Knulás: ournot-uopólum
Universität M Mis is k k olol ci c, F Eg a y kultä etem t, für Wi Gazda rts ságcha tudft o sw máis n s yen i scha Kar, ften,
 6. Előadás Piaci stratégiai cselekvések leírása játékelméleti modellek segítségével 1994: Neumann János és Oskar Morgenstern Theory of Games and Economic Behavior. A játékelmélet segítségével egzakt matematikai
6. Előadás Piaci stratégiai cselekvések leírása játékelméleti modellek segítségével 1994: Neumann János és Oskar Morgenstern Theory of Games and Economic Behavior. A játékelmélet segítségével egzakt matematikai
Megoldott feladatok november 30. n+3 szigorúan monoton csökken, 5. n+3. lim a n = lim. n+3 = 2n+3 n+4 2n+1
 Megoldott feladatok 00. november 0.. Feladat: Vizsgáljuk az a n = n+ n+ sorozat monotonitását, korlátosságát és konvergenciáját. Konvergencia esetén számítsuk ki a határértéket! : a n = n+ n+ = n+ n+ =
Megoldott feladatok 00. november 0.. Feladat: Vizsgáljuk az a n = n+ n+ sorozat monotonitását, korlátosságát és konvergenciáját. Konvergencia esetén számítsuk ki a határértéket! : a n = n+ n+ = n+ n+ =
KÖZGAZDASÁGTAN I. Készítette: Bíró Anikó, K hegyi Gergely, Major Klára. Szakmai felel s: K hegyi Gergely. 2010. június
 KÖZGAZDASÁGTAN I. Készült a TÁMOP-4.1.2-08/2/a/KMR-2009-0041 pályázati projekt keretében Tartalomfejlesztés az ELTE TáTK Közgazdaságtudományi Tanszékén az ELTE Közgazdaságtudományi Tanszék az MTA Közgazdaságtudományi
KÖZGAZDASÁGTAN I. Készült a TÁMOP-4.1.2-08/2/a/KMR-2009-0041 pályázati projekt keretében Tartalomfejlesztés az ELTE TáTK Közgazdaságtudományi Tanszékén az ELTE Közgazdaságtudományi Tanszék az MTA Közgazdaságtudományi
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Problémamegoldás kereséssel - csak lokális információra alapozva Pataki Béla BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Lokálisan
Mesterséges Intelligencia MI Problémamegoldás kereséssel - csak lokális információra alapozva Pataki Béla BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Lokálisan
Intelligens ágensek. Mesterséges intelligencia február 28.
 Intelligens ágensek Mesterséges intelligencia 2014. február 28. Ágens = cselekvő Bevezetés Érzékelői segítségével érzékeli a környezetet Beavatkozói/akciói segítségével megváltoztatja azt Érzékelési sorozat:
Intelligens ágensek Mesterséges intelligencia 2014. február 28. Ágens = cselekvő Bevezetés Érzékelői segítségével érzékeli a környezetet Beavatkozói/akciói segítségével megváltoztatja azt Érzékelési sorozat:
Statisztika elméleti összefoglaló
 1 Statisztika elméleti összefoglaló Tel.: 0/453-91-78 1. Tartalomjegyzék 1. Tartalomjegyzék.... Becsléselmélet... 3 3. Intervallumbecslések... 5 4. Hipotézisvizsgálat... 8 5. Regresszió-számítás... 11
1 Statisztika elméleti összefoglaló Tel.: 0/453-91-78 1. Tartalomjegyzék 1. Tartalomjegyzék.... Becsléselmélet... 3 3. Intervallumbecslések... 5 4. Hipotézisvizsgálat... 8 5. Regresszió-számítás... 11
További forgalomirányítási és szervezési játékok. 1. Nematomi forgalomirányítási játék
 További forgalomirányítási és szervezési játékok 1. Nematomi forgalomirányítási játék A forgalomirányítási játékban adott egy hálózat, ami egy irányított G = (V, E) gráf. A gráfban megengedjük, hogy két
További forgalomirányítási és szervezési játékok 1. Nematomi forgalomirányítási játék A forgalomirányítási játékban adott egy hálózat, ami egy irányított G = (V, E) gráf. A gráfban megengedjük, hogy két
Teljesen elosztott adatbányászat pletyka algoritmusokkal. Jelasity Márk Ormándi Róbert, Hegedűs István
 Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Szokol Patricia szeptember 19.
 a Haladó módszertani ismeretek című tárgyhoz 2017. szeptember 19. Legyen f : N R R adott függvény, ekkor a x n = f (n, x n 1 ), n = 1, 2,... egyenletet elsőrendű differenciaegyenletnek nevezzük. Ha még
a Haladó módszertani ismeretek című tárgyhoz 2017. szeptember 19. Legyen f : N R R adott függvény, ekkor a x n = f (n, x n 1 ), n = 1, 2,... egyenletet elsőrendű differenciaegyenletnek nevezzük. Ha még
Ambiens szabályozás problémája Kontroll és tanulás-1
 Ambiens szabályozás problémája Kontroll és tanulás-1 Ambiens (fizikai) tér Ambiens Intelligencia szenzorok beavatkozók Ágens szervezet AmI - megfigyelés, elemzés - tervezés, megtanulás AmI - statikus -
Ambiens szabályozás problémája Kontroll és tanulás-1 Ambiens (fizikai) tér Ambiens Intelligencia szenzorok beavatkozók Ágens szervezet AmI - megfigyelés, elemzés - tervezés, megtanulás AmI - statikus -
Monte Carlo módszerek a statisztikus fizikában. Az Ising modell. 8. előadás
 Monte Carlo módszerek a statisztikus fizikában. Az Ising modell. 8. előadás Démon algoritmus az ideális gázra időátlag fizikai mennyiségek átlagértéke sokaságátlag E, V, N pl. molekuláris dinamika Monte
Monte Carlo módszerek a statisztikus fizikában. Az Ising modell. 8. előadás Démon algoritmus az ideális gázra időátlag fizikai mennyiségek átlagértéke sokaságátlag E, V, N pl. molekuláris dinamika Monte
PIACI JÁTSZMÁK. Fiú. Színház. Színház (4 ; 2) (0 ; 0) A38 (0 ; 0) (2 ; 4) Lány
 (0 ; 0) A38 (0 ; 0) (2 ; 4) Lány") PIACI JÁTSZMÁK Bevezető Mindenki saját sorsának kovácsa tartja a közmondás. Ez azonban csak részben igaz; saját választásaink és cselekedeteink eredményét rendszerint más szereplők döntései is befolyásolják.
PIACI JÁTSZMÁK Bevezető Mindenki saját sorsának kovácsa tartja a közmondás. Ez azonban csak részben igaz; saját választásaink és cselekedeteink eredményét rendszerint más szereplők döntései is befolyásolják.
(Diszkrét idejű Markov-láncok állapotainak
 (Diszkrét idejű Markov-láncok állapotainak osztályozása) March 21, 2019 Markov-láncok A Markov-láncok anaĺızise főként a folyamat lehetséges realizációi valószínűségeinek kiszámolásával foglalkozik. Ezekben
(Diszkrét idejű Markov-láncok állapotainak osztályozása) March 21, 2019 Markov-láncok A Markov-láncok anaĺızise főként a folyamat lehetséges realizációi valószínűségeinek kiszámolásával foglalkozik. Ezekben
Véletlenszám generátorok és tesztelésük HORVÁTH BÁLINT
 Véletlenszám generátorok és tesztelésük HORVÁTH BÁLINT Mi a véletlen? Determinisztikus vs. Véletlen esemény? Véletlenszám: számok sorozata, ahol véletlenszerűen követik egymást az elemek Pszeudo-véletlenszám
Véletlenszám generátorok és tesztelésük HORVÁTH BÁLINT Mi a véletlen? Determinisztikus vs. Véletlen esemény? Véletlenszám: számok sorozata, ahol véletlenszerűen követik egymást az elemek Pszeudo-véletlenszám
Dunaújvárosi Főiskola Informatikai Intézet. Intelligens ágensek. Dr. Seebauer Márta. főiskolai tanár
 Dunaújvárosi Főiskola Informatikai Intézet Intelligens ágensek Dr. Seebauer Márta főiskolai tanár seebauer.marta@szgti.bmf.hu Ágens Ágens (agent) bármi lehet, amit úgy tekinthetünk, hogy érzékelők (sensors)
Dunaújvárosi Főiskola Informatikai Intézet Intelligens ágensek Dr. Seebauer Márta főiskolai tanár seebauer.marta@szgti.bmf.hu Ágens Ágens (agent) bármi lehet, amit úgy tekinthetünk, hogy érzékelők (sensors)
Számításelmélet. Második előadás
 Számításelmélet Második előadás Többszalagos Turing-gép Turing-gép k (konstans) számú szalaggal A szalagok mindegyike rendelkezik egy független író / olvasó fejjel A bemenet az első szalagra kerül, a többi
Számításelmélet Második előadás Többszalagos Turing-gép Turing-gép k (konstans) számú szalaggal A szalagok mindegyike rendelkezik egy független író / olvasó fejjel A bemenet az első szalagra kerül, a többi
Hipotézis STATISZTIKA. Kétmintás hipotézisek. Munkahipotézis (H a ) Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok
 Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok") STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
Felső végükön egymásra támaszkodó szarugerendák egyensúlya
 1 Felső végükön egymásra támaszkodó szarugerendák egyensúlya Az [ 1 ] példatárban találtunk egy érdekes feladatot, melynek egy változatát vizsgáljuk meg itt. A feladat Ehhez tekintsük az 1. ábrát! 1. ábra
1 Felső végükön egymásra támaszkodó szarugerendák egyensúlya Az [ 1 ] példatárban találtunk egy érdekes feladatot, melynek egy változatát vizsgáljuk meg itt. A feladat Ehhez tekintsük az 1. ábrát! 1. ábra
Fraktálok. Hausdorff távolság. Czirbusz Sándor ELTE IK, Komputeralgebra Tanszék március 14.
 Fraktálok Hausdorff távolság Czirbusz Sándor ELTE IK, Komputeralgebra Tanszék 2015. március 14. TARTALOMJEGYZÉK 1 of 36 Halmazok távolsága ELSŐ MEGKÖZELÍTÉS Legyen (S, ρ) egy metrikus tér, A, B S, valamint
Fraktálok Hausdorff távolság Czirbusz Sándor ELTE IK, Komputeralgebra Tanszék 2015. március 14. TARTALOMJEGYZÉK 1 of 36 Halmazok távolsága ELSŐ MEGKÖZELÍTÉS Legyen (S, ρ) egy metrikus tér, A, B S, valamint
Autoregresszív és mozgóátlag folyamatok. Géczi-Papp Renáta
 Autoregresszív és mozgóátlag folyamatok Géczi-Papp Renáta Autoregresszív folyamat Az Y t diszkrét paraméterű sztochasztikus folyamatok k-ad rendű autoregresszív folyamatnak nevezzük, ha Y t = α 1 Y t 1
Autoregresszív és mozgóátlag folyamatok Géczi-Papp Renáta Autoregresszív folyamat Az Y t diszkrét paraméterű sztochasztikus folyamatok k-ad rendű autoregresszív folyamatnak nevezzük, ha Y t = α 1 Y t 1
Függvények növekedési korlátainak jellemzése
 17 Függvények növekedési korlátainak jellemzése A jellemzés jól bevált eszközei az Ω, O, Θ, o és ω jelölések. Mivel az igények általában nemnegatívak, ezért az alábbi meghatározásokban mindenütt feltesszük,
17 Függvények növekedési korlátainak jellemzése A jellemzés jól bevált eszközei az Ω, O, Θ, o és ω jelölések. Mivel az igények általában nemnegatívak, ezért az alábbi meghatározásokban mindenütt feltesszük,
A megerősítéses tanulás alkalmazása az Othello játékban
 Debreceni Egyetem Informatikai Kar A megerősítéses tanulás alkalmazása az Othello játékban Témavezető: Dr. Várterész Magda Egyetemi docens Készítette: Andorkó Gábor Programtervező informatikus (B.Sc.)
Debreceni Egyetem Informatikai Kar A megerősítéses tanulás alkalmazása az Othello játékban Témavezető: Dr. Várterész Magda Egyetemi docens Készítette: Andorkó Gábor Programtervező informatikus (B.Sc.)
Autoregresszív és mozgóátlag folyamatok
 Géczi-Papp Renáta Autoregresszív és mozgóátlag folyamatok Autoregresszív folyamat Az Y t diszkrét paraméterű sztochasztikus folyamatok k-ad rendű autoregresszív folyamatnak nevezzük, ha Y t = α 1 Y t 1
Géczi-Papp Renáta Autoregresszív és mozgóátlag folyamatok Autoregresszív folyamat Az Y t diszkrét paraméterű sztochasztikus folyamatok k-ad rendű autoregresszív folyamatnak nevezzük, ha Y t = α 1 Y t 1
1000 forintos adósságunkat, de csak 600 forintunk van. Egyetlen lehetőségünk, hogy a
 A merész játékok stratégiája A következő problémával foglalkozunk: Tegyük fel, hogy feltétlenül ki kell fizetnünk 000 forintos adósságunkat, de csak 600 forintunk van. Egyetlen lehetőségünk, hogy a még
A merész játékok stratégiája A következő problémával foglalkozunk: Tegyük fel, hogy feltétlenül ki kell fizetnünk 000 forintos adósságunkat, de csak 600 forintunk van. Egyetlen lehetőségünk, hogy a még
 Á Á É ú Í Í í í ű ú í ú ú íí í ű Í Í Í í ü í í í í í Á í ü ü í í ü í í í ű í ú í ű í ű ú Í í ú ű ű í í í ű í í í í í Í ü ü í í í Á Á Á Á Á ú í í í ü ü í í í í í í í í ú Í Í í í ü í ü í í í ú í Á í ú í
Á Á É ú Í Í í í ű ú í ú ú íí í ű Í Í Í í ü í í í í í Á í ü ü í í ü í í í ű í ú í ű í ű ú Í í ú ű ű í í í ű í í í í í Í ü ü í í í Á Á Á Á Á ú í í í ü ü í í í í í í í í ú Í Í í í ü í ü í í í ú í Á í ú í
Alap-ötlet: Karl Friedrich Gauss ( ) valószínűségszámítási háttér: Andrej Markov ( )
 valószínűségszámítási háttér: Andrej Markov ( )") Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Gépi tanulás. Hány tanítómintára van szükség? VKH. Pataki Béla (Bolgár Bence)
") Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
Optimalizálás alapfeladata Legmeredekebb lejtő Lagrange függvény Log-barrier módszer Büntetőfüggvény módszer 2017/
 Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 9. Előadás Az optimalizálás alapfeladata Keressük f függvény maximumát ahol f : R n R és
Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 9. Előadás Az optimalizálás alapfeladata Keressük f függvény maximumát ahol f : R n R és
N-személyes játékok. Bársony Alex
 N-személyes játékok Bársony Alex Előszó Neumann János és Oskar Morgenstern Racionális osztozkodás törvényeinek tanulmányozása Játékosok egy tetszőleges csoportjának ereje Nem 3 személyes sakk Definíció
N-személyes játékok Bársony Alex Előszó Neumann János és Oskar Morgenstern Racionális osztozkodás törvényeinek tanulmányozása Játékosok egy tetszőleges csoportjának ereje Nem 3 személyes sakk Definíció
Új típusú döntési fa építés és annak alkalmazása többtényezős döntés területén
 Új típusú döntési fa építés és annak alkalmazása többtényezős döntés területén Dombi József Szegedi Tudományegyetem Bevezetés - ID3 (Iterative Dichotomiser 3) Az ID algoritmusok egy elemhalmaz felhasználásával
Új típusú döntési fa építés és annak alkalmazása többtényezős döntés területén Dombi József Szegedi Tudományegyetem Bevezetés - ID3 (Iterative Dichotomiser 3) Az ID algoritmusok egy elemhalmaz felhasználásával
c adatpontok és az ismeretlen pont közötti kovariancia vektora
 1. MELLÉKLET: Alkalmazott jelölések A mintaterület kiterjedése, területe c adatpontok és az ismeretlen pont közötti kovariancia vektora C(0) reziduális komponens varianciája C R (h) C R Cov{} d( u, X )
1. MELLÉKLET: Alkalmazott jelölések A mintaterület kiterjedése, területe c adatpontok és az ismeretlen pont közötti kovariancia vektora C(0) reziduális komponens varianciája C R (h) C R Cov{} d( u, X )
Kétszemélyes játékok
 Mesterséges Intelligencia alapjai, gyakorlat Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék 2010 / udapest Kétszemélyes teljes információjú játékok két
Mesterséges Intelligencia alapjai, gyakorlat Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék 2010 / udapest Kétszemélyes teljes információjú játékok két
1. Lineáris differenciaegyenletek
 Lineáris differenciaegyenletek Tekintsük az alábbi egyenletet: f(n) af(n ) + bf(n + ), (K < n < N) f(k) d, f(n) d Keressük a megoldást f(n) α n alakban Így kajuk a következőket: α n aα n + bα n+ α a +
Lineáris differenciaegyenletek Tekintsük az alábbi egyenletet: f(n) af(n ) + bf(n + ), (K < n < N) f(k) d, f(n) d Keressük a megoldást f(n) α n alakban Így kajuk a következőket: α n aα n + bα n+ α a +
Nagyságrendek. Kiegészítő anyag az Algoritmuselmélet tárgyhoz. Friedl Katalin BME SZIT február 1.
 Nagyságrendek Kiegészítő anyag az Algoritmuselmélet tárgyhoz (a Rónyai Ivanyos Szabó: Algoritmusok könyv mellé) Friedl Katalin BME SZIT friedl@cs.bme.hu 018. február 1. Az O, Ω, Θ jelölések Az algoritmusok
Nagyságrendek Kiegészítő anyag az Algoritmuselmélet tárgyhoz (a Rónyai Ivanyos Szabó: Algoritmusok könyv mellé) Friedl Katalin BME SZIT friedl@cs.bme.hu 018. február 1. Az O, Ω, Θ jelölések Az algoritmusok
Közgazdaságtan I. 11. alkalom
 Közgazdaságtan I. 11. alkalom 2018-2019/II. 2019. Április 24. Tóth-Bozó Brigitta Tóth-Bozó Brigitta Általános információk Fogadóóra szerda 13-14, előzetes bejelentkezés szükséges e-mailben! QA218-as szoba
Közgazdaságtan I. 11. alkalom 2018-2019/II. 2019. Április 24. Tóth-Bozó Brigitta Tóth-Bozó Brigitta Általános információk Fogadóóra szerda 13-14, előzetes bejelentkezés szükséges e-mailben! QA218-as szoba
1.1. Vektorok és operátorok mátrix formában
 1. Reprezentáció elmélet 1.1. Vektorok és operátorok mátrix formában A vektorok és az operátorok mátrixok formájában is felírhatók. A végtelen dimenziós ket vektoroknak végtelen sok sort tartalmazó oszlopmátrix
1. Reprezentáció elmélet 1.1. Vektorok és operátorok mátrix formában A vektorok és az operátorok mátrixok formájában is felírhatók. A végtelen dimenziós ket vektoroknak végtelen sok sort tartalmazó oszlopmátrix
Teljesen elosztott adatbányászat alprojekt
 Teljesen elosztott adatbányászat alprojekt Hegedűs István, Ormándi Róbert, Jelasity Márk Big Data jelenség Big Data jelenség Exponenciális növekedés a(z): okos eszközök használatában, és a szenzor- és
Teljesen elosztott adatbányászat alprojekt Hegedűs István, Ormándi Róbert, Jelasity Márk Big Data jelenség Big Data jelenség Exponenciális növekedés a(z): okos eszközök használatában, és a szenzor- és
Problémás regressziók
 Universitas Eotvos Nominata 74 203-4 - II Problémás regressziók A közönséges (OLS) és a súlyozott (WLS) legkisebb négyzetes lineáris regresszió egy p- változós lineáris egyenletrendszer megoldása. Az egyenletrendszer
Universitas Eotvos Nominata 74 203-4 - II Problémás regressziók A közönséges (OLS) és a súlyozott (WLS) legkisebb négyzetes lineáris regresszió egy p- változós lineáris egyenletrendszer megoldása. Az egyenletrendszer
Játékelmélet és stratégiai gondolkodás
 Nyomtatás Játékelmélet és stratégiai gondolkodás Budapesti Műszaki és Gazdaságtudományi Egyetem Gazdaság- és Társadalomtudományi Kar Szociológia és Kommunikáció Tanszék TANTÁRGYI ADATLAP 0 I. Tantárgyleírás
Nyomtatás Játékelmélet és stratégiai gondolkodás Budapesti Műszaki és Gazdaságtudományi Egyetem Gazdaság- és Társadalomtudományi Kar Szociológia és Kommunikáció Tanszék TANTÁRGYI ADATLAP 0 I. Tantárgyleírás
Kollektív tanulás milliós hálózatokban. Jelasity Márk
 Kollektív tanulás milliós hálózatokban Jelasity Márk 2 3 Motiváció Okostelefon platform robbanásszerű terjedése és Szenzorok és gazdag kontextus jelenléte, ami Kollaboratív adatbányászati alkalmazások
Kollektív tanulás milliós hálózatokban Jelasity Márk 2 3 Motiváció Okostelefon platform robbanásszerű terjedése és Szenzorok és gazdag kontextus jelenléte, ami Kollaboratív adatbányászati alkalmazások
f(x) vagy f(x) a (x x 0 )-t használjuk. lim melyekre Mivel itt ɛ > 0 tetszőlegesen kicsi, így a a = 0, a = a, ami ellentmondás, bizonyítva
 vagy f(x) a (x x 0 )-t használjuk. lim melyekre Mivel itt ɛ > 0 tetszőlegesen kicsi, így a a = 0, a = a, ami ellentmondás, bizonyítva") 6. FÜGGVÉNYEK HATÁRÉRTÉKE ÉS FOLYTONOSSÁGA 6.1 Függvény határértéke Egy D R halmaz torlódási pontjainak halmazát D -vel fogjuk jelölni. Definíció. Legyen f : D R R és legyen x 0 D (a D halmaz torlódási
6. FÜGGVÉNYEK HATÁRÉRTÉKE ÉS FOLYTONOSSÁGA 6.1 Függvény határértéke Egy D R halmaz torlódási pontjainak halmazát D -vel fogjuk jelölni. Definíció. Legyen f : D R R és legyen x 0 D (a D halmaz torlódási
A Termelésmenedzsment alapjai tárgy gyakorló feladatainak megoldása
 azdaság- és Társadalomtudományi Kar Ipari Menedzsment és Vállakozásgazdaságtan Tanszék A Termelésmenedzsment alapjai tárgy gyakorló feladatainak megoldása Készítette: dr. Koltai Tamás egyetemi tanár Budapest,.
azdaság- és Társadalomtudományi Kar Ipari Menedzsment és Vállakozásgazdaságtan Tanszék A Termelésmenedzsment alapjai tárgy gyakorló feladatainak megoldása Készítette: dr. Koltai Tamás egyetemi tanár Budapest,.
Mátrixhatvány-vektor szorzatok hatékony számítása
 Mátrixhatvány-vektor szorzatok hatékony számítása Izsák Ferenc ELTE TTK, Alkalmazott Analízis és Számításmatematikai Tanszék & ELTE-MTA NumNet Kutatócsoport munkatárs: Szekeres Béla János Alkalmazott Analízis
Mátrixhatvány-vektor szorzatok hatékony számítása Izsák Ferenc ELTE TTK, Alkalmazott Analízis és Számításmatematikai Tanszék & ELTE-MTA NumNet Kutatócsoport munkatárs: Szekeres Béla János Alkalmazott Analízis
Explicit hibabecslés Maxwell-egyenletek numerikus megoldásához
 Explicit hibabecslés Maxwell-egyenletek numerikus megoldásához Izsák Ferenc 2007. szeptember 17. Explicit hibabecslés Maxwell-egyenletek numerikus megoldásához 1 Vázlat Bevezetés: a vizsgált egyenlet,
Explicit hibabecslés Maxwell-egyenletek numerikus megoldásához Izsák Ferenc 2007. szeptember 17. Explicit hibabecslés Maxwell-egyenletek numerikus megoldásához 1 Vázlat Bevezetés: a vizsgált egyenlet,
Van-e kapcsolat a változók között? (példák: fizetés-távolság; felvételi pontszám - görgetett átlag)
") , rangkorreláció Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék 1111, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-16-80 Fax: 463-30-91 http://www.vizgep.bme.hu
, rangkorreláció Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék 1111, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-16-80 Fax: 463-30-91 http://www.vizgep.bme.hu
Intelligens Elosztott Rendszerek. Dobrowiecki Tadeusz és Eredics Péter, Gönczy László, Pataki Béla és Strausz György közreműködésével
 Intelligens Elosztott Rendszerek Dobrowiecki Tadeusz és Eredics Péter, Gönczy László, Pataki Béla és Strausz György közreműködésével A mai előadás tartalma Mi is egy rendszer? Mit jelent elosztottnak lenni?
Intelligens Elosztott Rendszerek Dobrowiecki Tadeusz és Eredics Péter, Gönczy László, Pataki Béla és Strausz György közreműködésével A mai előadás tartalma Mi is egy rendszer? Mit jelent elosztottnak lenni?
Tanulás Boltzmann gépekkel. Reiz Andrea
 Tanulás Boltzmann gépekkel Reiz Andrea Tanulás Boltzmann gépekkel Boltzmann gép Boltzmann gép felépítése Boltzmann gép energiája Energia minimalizálás Szimulált kifűtés Tanulás Boltzmann gép Tanulóalgoritmus
Tanulás Boltzmann gépekkel Reiz Andrea Tanulás Boltzmann gépekkel Boltzmann gép Boltzmann gép felépítése Boltzmann gép energiája Energia minimalizálás Szimulált kifűtés Tanulás Boltzmann gép Tanulóalgoritmus
Mesterséges Intelligencia (MI)
") Mesterséges Intelligencia (MI) Intelligens ágensek Dobrowiecki Tadeusz Antal Péter, Bolgár Bence, Engedy István, Eredics Péter, Strausz György és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade
Mesterséges Intelligencia (MI) Intelligens ágensek Dobrowiecki Tadeusz Antal Péter, Bolgár Bence, Engedy István, Eredics Péter, Strausz György és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
A stratégiák összes kombinációján (X) adjunk meg egy eloszlást (z) Az eloszlás (z) szerint egy megfigyelő választ egy x X-et, ami alapján mindkét
 adjunk meg egy eloszlást (z) Az eloszlás (z) szerint egy megfigyelő választ egy x X-et, ami alapján mindkét") Készítette: Jánki Zoltán Richárd Robert Aumann (1930) Izraeli-amerikai matematikus 1974-ben általánosította a Nash-egyensúlyt 2005-ben közgazdasági Nobel-díjat kapott (kooperatív és nem-kooperatív játékok)
Készítette: Jánki Zoltán Richárd Robert Aumann (1930) Izraeli-amerikai matematikus 1974-ben általánosította a Nash-egyensúlyt 2005-ben közgazdasági Nobel-díjat kapott (kooperatív és nem-kooperatív játékok)
Játékelméleti alapvetés - I
 Játékelméleti alapvetés - I Fáth Gábor (SZFKI) ELTE 2005. június 1. Alkalmazások pszichológia biológia nyelvészet közgazdaságtan számítástudomány Játékelmélet filozófia politika tudomány etika kulturális
Játékelméleti alapvetés - I Fáth Gábor (SZFKI) ELTE 2005. június 1. Alkalmazások pszichológia biológia nyelvészet közgazdaságtan számítástudomány Játékelmélet filozófia politika tudomány etika kulturális
Q 1 D Q 2 (D x) 2 (1.1)
 2 (1.1)") . Gyakorlat 4B-9 Két pontszerű töltés az x tengelyen a következőképpen helyezkedik el: egy 3 µc töltés az origóban, és egy + µc töltés az x =, 5 m koordinátájú pontban van. Keressük meg azt a helyet, ahol
. Gyakorlat 4B-9 Két pontszerű töltés az x tengelyen a következőképpen helyezkedik el: egy 3 µc töltés az origóban, és egy + µc töltés az x =, 5 m koordinátájú pontban van. Keressük meg azt a helyet, ahol
KÖZGAZDASÁGTAN. Játékelmélet Szalai László
 KÖZGAZDASÁGTAN Játékelmélet 2017. 10. 09. Szalai László Játékelméleti problémák Racionális, haszonmaximalizáló játékosok Döntéselmélet vs. játékelmélet Döntések közötti interakciók A játékosok által élérhető
KÖZGAZDASÁGTAN Játékelmélet 2017. 10. 09. Szalai László Játékelméleti problémák Racionális, haszonmaximalizáló játékosok Döntéselmélet vs. játékelmélet Döntések közötti interakciók A játékosok által élérhető
Intelligens Rendszerek Elmélete. Versengéses és önszervező tanulás neurális hálózatokban
 Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Osztott algoritmusok
 Osztott algoritmusok A benzinkutas példa szimulációja Müller Csaba 2010. december 4. 1. Bevezetés Első lépésben talán kezdjük a probléma ismertetésével. Adott két n hosszúságú bináris sorozat (s 1, s 2
Osztott algoritmusok A benzinkutas példa szimulációja Müller Csaba 2010. december 4. 1. Bevezetés Első lépésben talán kezdjük a probléma ismertetésével. Adott két n hosszúságú bináris sorozat (s 1, s 2
Koordinálás és feladatkiosztás aukciókkal 3.rész. Kooperáció és intelligencia, Dobrowiecki, BME-MIT
 Koordinálás és feladatkiosztás aukciókkal 3.rész Komplex feladatok kezelése Elemi feladat nem dekomponálható Dekomponálható egyszerű feladat elemi, v. dekomponálható elemi feladatokra, de egyetlen egy
Koordinálás és feladatkiosztás aukciókkal 3.rész Komplex feladatok kezelése Elemi feladat nem dekomponálható Dekomponálható egyszerű feladat elemi, v. dekomponálható elemi feladatokra, de egyetlen egy
Least Squares becslés
 Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Kooperáció és intelligencia kis HF-ok/ Kooperáció és intelligencia, Dobrowiecki T., BME-MIT 1
 Kooperáció és intelligencia kis HF-ok/ 2015 Kooperáció és intelligencia, Dobrowiecki T., BME-MIT 1 Kis HF-1: Elosztott következtetés (modell-keresés) 3 db. logikailag következtető (KA1..3) ágens dolgozik
Kooperáció és intelligencia kis HF-ok/ 2015 Kooperáció és intelligencia, Dobrowiecki T., BME-MIT 1 Kis HF-1: Elosztott következtetés (modell-keresés) 3 db. logikailag következtető (KA1..3) ágens dolgozik
1. feladatsor: Vektorterek, lineáris kombináció, mátrixok, determináns (megoldás)
") Matematika A2c gyakorlat Vegyészmérnöki, Biomérnöki, Környezetmérnöki szakok, 2017/18 ősz 1. feladatsor: Vektorterek, lineáris kombináció, mátrixok, determináns (megoldás) 1. Valós vektorterek-e a következő
Matematika A2c gyakorlat Vegyészmérnöki, Biomérnöki, Környezetmérnöki szakok, 2017/18 ősz 1. feladatsor: Vektorterek, lineáris kombináció, mátrixok, determináns (megoldás) 1. Valós vektorterek-e a következő