Standardizálás, transzformációk
|
|
|
- Judit Balázs
- 5 évvel ezelőtt
- Látták:
Átírás
1 Standardizálás, transzformációk A transzformációk ugynúgy mennek, mint egyváltozós esetben. Itt még fontosabbak a linearitás miatt. Standardizálás átskálázás. Centrálás: kivonjuk minden változó átlagát, így az átlag 0 lesz. (Spektrál felbontás esetén tulajdonképpen a centrált adatok kovariancia mátrixával dolgozunk.) Standardizálás: korrelációs mátrix standardizált adatok kovariancia mátrixa. Relatív értékek (arányok): legnagyobb értékkel osztjuk az összeset. Megfigyelési egységeket is lehet standardizálni. Abundancia adatoknál fontos, ha a megfigyelési egységek mérete különböző. (arányok) 0,-é is lehet konvertálni. Sokszor hasznos lehet különböző módokon standardizálni és összehasonlítani az eredményeket: eredeti standardizált 0, eredeti: legnagyobb abundanciájú mit befolyásol 0, : prezencia, abszenciától mi függ. Asszociációs mértékek implicit módon standardizáltak.
2 Az, hogy a kovariancia vagy korrelációs mátrixot használjuk attól függ, hogy a varianciák különbsége fontos-e biológiai szempontból.
3 Hiányzó adatok MCAR-missing completely at random: független mind a megfigyelt adatoktól, mind a többi hiányzótól. Random részhalmaza az adatoknak. MAR lehet, hogy függ a csoporttól, hogy hiányzik-e. Mit tegyünk a hiányzó adatokkal?. Objektum törlése (deletion): legjobb megoldás, ha kevesebb, mint 5% hiányzik és MCAR Információ vesztés (complete.obs) esetén. Ha az analízis páronkénti (pairwise) asszociációkon alapul (kovariancia, korreláció), akkor paiwise.complete.obs. Csak akkor töröljük, ha éppen azokkal a változókkal dolgozunk, amelyiknél hiányzik a megfigyelés. Imputáció Helyettesítés becsléssel. Módszerek:. átlaggal (változó értékeiből számolt\na) A varianciát alulbecsüli.. Regressziós modellel. Más változókkal becsüljük, pl. a legjobban korrelált változót vagy változókat választjuk prediktornak.) 3. Hot-deck: Hasonló objektum értékével helyettesítjük. Problémák: függetlenség sérül; varianciát alulbecsli.
4 Maximum likelihood (ML) és EM becslés ML : paraméter becslés a megfigyelt, nem teljes adatokból, majd a modellből becsüljük a hiányzó adatokat. Felhasználja a megfigyelt adatok eloszlását és a hiányzó adatok mintázatát. Iteratív imputáció + ML : Expectation Maximization ML paraméter becslés hiányzó adatok ML paraméterbecslés hiányzó adatok..., amíg nem konvergál. ML és EM feltétele a MAR.
5 Adatredukció (Ordináció) Főkomponens analízis (PCA) Felfedező adatelemzésben használatos. Adathalmaz kényelmesebb és informatívabb ábrázolása, dimenziószám csökkentése, fontos változók beazonosítása. Cél: Van p változónk:,,..., p és keressük ezeknek olyan,,..., kombinációit (főkomponensek), amelyek p nem korreláltak. A korrelálatlanság azt jelenti, hogy az új változók az adatok különböző dimenzióit mérik.... p Remény: a legtöbb főkomponens szórása olyan kicsi, hogy elhanyagolhatók, így az adatokban meglévő változatosság néhány főkomponenssel jól leírható. Ha az eredeti változók egyáltalán nem korreláltak, az analízis semmit nem csinál. Legjobb eredmény: nagyon korrelált változók esetén. Adatok: Egyed... p x x... x p x x... x p n x n x n x np
6 A főkomponensek: a a a i i i... ip p a a... a i i ip és p.... A főkomponensek varianciái az adatok kovariancia mátrixának sajátértékei ( i ), az együtthatói pedig a megfelelő sajátértékhez tartozó sajátvektor együtthatói. Ha a kovarianciamátrix: c c... c c c... c C c c c p p pp p p, akkor... c c... c... p pp p Célszerű az adatokat standardizálni az analízis előtt. Ekkor a kovariancia mátrix megegyezik korrelációs mátrixszal. Feltételek: Normalitás nem feltétel, de a nagyon ferde eloszlás ronthatja az eredményt. A normalitás csak tesztek esetén szükséges. Linearitás. Ne legyenek outlierek.
7 Azt mutatja meg, hogy a főkomponensek mennyit magyaráznak az egyes változókból. A korrelációs/kovariancia mátrix s.é.-ei, és a megfelelő variancia hányadok.
8 A s.é.-kek a komponens sorszám függvényében.
9 > pca=princomp(vereb[,:6],cor=t) > summary(pca,loadings=true) Importance of components: Comp. Comp. Comp.3 Standard deviation Proportion of Variance Cumulative Proportion Comp.4 Comp.5 Standard deviation Proportion of Variance Cumulative Proportion Loadings: Comp. Comp. Comp.3 Comp.4 Comp >par(pty="s") >plot(pca$scores[,],pca$scores[,], >ylim=range(pca$scores[,]), >xlab="pc",ylab="pc",type="n",lwd=) >text(pca$scores[,],pca$scores[,], >labels=row.names(vereb),cex=0.7,lwd=)
10 > pca$scores Ezekkel a szkórokkal tudjuk kiszámolni a komponensek értékeit az egyes esetekre. (Ezek az a ij együtthatók.) >biplot(pca) > cor(data.frame(pca$scores[,],vereb[,:6]))[,] pca.scores... pca.scores
11 Faktoranalízis Nagyszámú változó korrelációinak elemzése. Változók faktorokba csoportosítása. Az egy faktorba csoportosított változók korreláltsága nagyobb egymással, mint a csoporton kívüliekkel. A faktorok interpretálása (látens változók) a változók alapján. Sok változó összesítése néhány faktorba. i a F a F... i i a im F m e i aij - faktorsúlyok (loadings), i -k a standardizált változók. F j : korrelálatlan közös faktorok 0 várható értékkel és szórással. e i - egyedi faktor, várható értéke 0, F j -kel nem korrelált. Nem korrelált a többi j, j i változóval sem. i ai F... aim Fm ei a... a e i im i a a - kommunalitás, - egyediség (uniqueness). i... im ( e i )
12 i és j m l a a il jl - az és korrelációs együtthatója. (Csak akkor lehet két változó nagyon korrelált, ha nagy súllyal szereplenek ugyanabban a faktorban.) Számítás menete:. Korrelációs vagy kovarinacia mátrix kiszámítása.. Faktorsúlyok becslése (faktor extrakció). Pl. főkomponens analízisből megtartjuk az -nél nagyobb sajátértékű főkomponenseket (Főkomponens faktoranalízis). Főkomponensek: p b b b p b b b p... b p... b p... b Mátrix egyenlet formában: pp =B B - = B T = Mivel a B mártix ortonormált. Így: b p b b p b b b p... b... b p p... b pp p p p p p p
13 Mivel Faktor analízis esetén m < p számú faktorral dolgozunk, ezért: p b b b p b b b p... b... b m m... b mp m m e m e e Mostmár csak át kell skálázni az eredeti főkomponenseket úgy, hogy legyen a varianciájuk. Ehhez a i ket osztani kell a szórásukkal, ami éppen i. Így: p F i i / i. 3. Faktor rotációt végzünk azért, hogy a faktorok interpretálhatóbbak legyenek. A súlyok minden faktor esetén vagy nagyok vagy nagyon kicsik legyenek. 4. Faktor értékek kiszámítása a mintaegyedekre. További analízisek. Rotációs módszerek: Ortogonális: Varimax, Quartimax, Equamax Varimax: úgy forgat, hogy az együtthatók vagy -hez vagy 0-hoz közeliek legyenek. Quartimax: minimalizálja a változók magyarázásához szükséges faktorok számát Equamax: Az előző kettő kompromisszuma. A rotált faktorok nem korreláltak.
14 Ferde (Oblique): Direct Oblimin, Promax Nagyobb sajátértékeket eredményeznek. A Promax nagyon nagy táblázatok esetén használatos. Korrelált faktorok. Maximum-likelihood faktor analízis Leginkább elfogadott módszer. Szükséges faktorszám tesztelhető. Fakt > fa<-factanal(vereb[,:6],factors=,scores="regression",correlation=t) > fa Call: factanal(x = vereb[, :6], factors =, scores = "regression", correlation = T) Uniquenesses: Loadings: Factor Factor Factor Factor SS loadings Proportion Var Cumulative Var Test of the hypothesis that factors are sufficient. The chi square statistic is 0.7 on degree of freedom. The p-value is 0.603
15 Ha nem szign., akkor jó. > fa<-factanal(vereb[,:6],factors=,rotation="promax") > fa Call: factanal(x = vereb[, :6], factors =, rotation = "promax") Uniquenesses: Loadings: Factor Factor Factor Factor SS loadings Proportion Var Cumulative Var Test of the hypothesis that factors are sufficient. The chi square statistic is 0.7 on degree of freedom. The p-value is > par(pty="s") > plot(fa$scores[,],fa$scores[,], + ylim=range(fa$scores[,]), + xlab="fa",ylab="fa",type="n",lwd=) > text(fa$scores[,],fa$scores[,], + labels=row.names(vereb),cex=0.7,lwd=)
16
17 Klaszter analízis n egyedből álló minta, amelynek minden egyedén p számú változó értékét mérjük. Csoportosítási séma, amely a hasonló objektumokat egy csoportba sorolja. A csoportok száma nem ismert (általában). Algoritmusok két típusa: Hierarhikus technikák. Dendrogramot produkálnak.. Egyedek egymástól való távolságának kiszámítása.. Csoportok létrehozása vagy összevonással, vagy felosztással. Az összevonás esetén először minden objektumot külön csoportba sorolunk és azután a legközelebbieket fokozatosan egyesítjük. A felosztó módszerek esetén, először egy csoportba soroljuk az összes objektumot, majd először ketté osztjuk, majd a ketté osztottakat is tovább osztjuk egészen addíg, amíg minden egyed külön csoportot alkot. Másik típusa esetén az egyedek be is kerülhetnek egy csoportba és ki is kerülhetnek onnan (k-means clustering). Előre meg kell határozni, hogy hány csoportunk legyen.
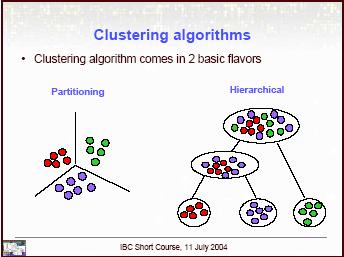
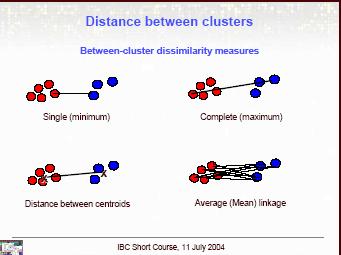
18 Összevonási technikák (linkage methods):
19 Egyszerű lánc módszer (nearest neighbor): Két csoport távolságát az egymáshoz legközelebb eső, de nem egy csoportba tartozó elemeik távolságaként határozzuk meg. Ha a csoportok közt nincs éles elválás, akkor nem működik jól, viszont ha élesen elhatárolódnak, akkor nagyon effektív. Hosszú giliszták jönnek létre. hclust: method = single Teljes lánc módszer (furthest neighbor): Két csoport távolságát legtávolabbi elemeik távolsága adja meg. Jól működik nem elhatárolódó, de erős kohéziójú csoportok esetén. Kompakt kupacokat eredményez. hclust: method = single
20 Csoportátlag módszer (group average clustering): Az előző két módszer közötti átmenet. A két csoport távolsága elemeik páronkénti távolságainak átlaga osztva a két csoport elemszámával. Jól működik akkor is, ha azt várjuk, hogy a csoportok elemszáma nagyon különböző lesz. hclust: method = average Centroid módszer (centroid clustering): Két csoport távolságát a súlypontjaik távolsága adja meg. Csoportok összevonásakor az új súlypont a régiek csoportmérettel súlyozott átlaga. A kis klasztert felfalja a nagy. hclust: method = centroid Medián módszer (median clustering): Két csoport távolságát a súlypontjaik távolsága adja meg. Csoportok összevonásakor az új súlypont a régiek egyszerű számtani átlaga. Ha várhatóan nagyok az elemszámokban a különbségek, akkor az előzőhöz képest ezt célszerű használni. hclust: method = median
21 Ward módszer (Ward s method): A csoportokon belüli varianciát minimalizálja. Nagyon effektív, de kis elemszámú csoportok létrehozására hajlamos módszer. hclust: method = ward
22 pl: Az emlősállatoknak négyféle foguk van: metszőfog, szemfog, kiszápfog és zápfog. Az adattáblázat 3 állatfaj egyik oldali állkapcsában alul illetve felül található különböző fogainak számát tartalmazza.
23 Modell alapú klaszterezés (Model based clustering) A populáció valahány részpopulációból (= klaszterek) áll. Csilpcsalp füzikék szárnyhossz eloszlása
24 Paraméterek $pro (mixing proportions, keverékek aránya) [] $mean (komponensek várható értéke) $variance $variance$modelname [] "V" (variable variances, lehetnek különbözők a varianciák) $variance$d (az adatok dimenziója, most csak a szárnyhosszt nézzük, ezért ) [] $variance$g (komponensek száma a keverékfelbontásban) [] $variance$sigmasq (ebben a paraméterezésben a két variancia becslése) [] $variance$scale (ebben a paraméterezésben a két variancia becslése) []
25
Standardizálás, transzformációk
 Standardizálás, transzformációk A transzformációk ugynúgy mennek, mint egyváltozós esetben. Itt még fontosabbak a linearitás miatt. Standardizálás átskálázás. Centrálás: kivonjuk minden változó átlagát,
Standardizálás, transzformációk A transzformációk ugynúgy mennek, mint egyváltozós esetben. Itt még fontosabbak a linearitás miatt. Standardizálás átskálázás. Centrálás: kivonjuk minden változó átlagát,
Faktoranalízis az SPSS-ben
 Faktoranalízis az SPSS-ben Kvantitatív statisztikai módszerek Petrovics Petra Feladat Megnyitás: faktor.sav Fogyasztók materialista vonásai (Richins-skála) Forrás: Sajtos-Mitev, 250.oldal Faktoranalízis
Faktoranalízis az SPSS-ben Kvantitatív statisztikai módszerek Petrovics Petra Feladat Megnyitás: faktor.sav Fogyasztók materialista vonásai (Richins-skála) Forrás: Sajtos-Mitev, 250.oldal Faktoranalízis
Faktoranalízis az SPSS-ben
 Faktoranalízis az SPSS-ben = Adatredukciós módszer Petrovics Petra Doktorandusz Feladat Megnyitás: faktoradat_msc.sav Forrás: Sajtos-Mitev 250.oldal Fogyasztók materialista vonásai (Richins-skála) Faktoranalízis
Faktoranalízis az SPSS-ben = Adatredukciós módszer Petrovics Petra Doktorandusz Feladat Megnyitás: faktoradat_msc.sav Forrás: Sajtos-Mitev 250.oldal Fogyasztók materialista vonásai (Richins-skála) Faktoranalízis
Principal Component Analysis
 Principal Component Analysis Principal Component Analysis Principal Component Analysis Definíció Ortogonális transzformáció, amely az adatokat egy új koordinátarendszerbe transzformálja úgy, hogy a koordináták
Principal Component Analysis Principal Component Analysis Principal Component Analysis Definíció Ortogonális transzformáció, amely az adatokat egy új koordinátarendszerbe transzformálja úgy, hogy a koordináták
Több mint egy változót jegyzünk fel a megfigyelési egységekről (objektumok).
.") Többváltozós problémák Több mint egy változót jegyzünk fel a megfigyelési egységekről (objektumok). Volt: Több magyarázó változó: többszörös regresszió, több faktoros ANOVA, ANCOVA. Most: több független
Többváltozós problémák Több mint egy változót jegyzünk fel a megfigyelési egységekről (objektumok). Volt: Több magyarázó változó: többszörös regresszió, több faktoros ANOVA, ANCOVA. Most: több független
Miskolci Egyetem Gazdaságtudományi Kar Üzleti Információgazdálkodási és Módszertani Intézet
 Klaszteranalízis Hasonló dolgok csoportosítását jelenti, gyakorlatilag az osztályozás szinonimájaként értelmezhetjük. A klaszteranalízis célja A klaszteranalízis alapvető célja, hogy a megfigyelési egységeket
Klaszteranalízis Hasonló dolgok csoportosítását jelenti, gyakorlatilag az osztályozás szinonimájaként értelmezhetjük. A klaszteranalízis célja A klaszteranalízis alapvető célja, hogy a megfigyelési egységeket
Főkomponens és Faktor analízis
 Főkomponens és Faktor analízis Márkus László 2017. december 5. Márkus László Főkomponens és Faktor analízis 2017. december 5. 1 / 35 Bevezetés - Főkomponens és Faktoranalízis A főkomponens és faktor analízis
Főkomponens és Faktor analízis Márkus László 2017. december 5. Márkus László Főkomponens és Faktor analízis 2017. december 5. 1 / 35 Bevezetés - Főkomponens és Faktoranalízis A főkomponens és faktor analízis
Gazdaságtudományi Kar. Gazdaságelméleti és Módszertani Intézet. Faktoranalízis előadás. Kvantitatív statisztikai módszerek
 Faktoranalízis 6.-7. előadás Kvantitatív statisztikai módszerek Faktoranalízis Olyan többváltozós statisztikai módszer, amely adattömörítésre, a változók számának csökkentésére, az adatstruktúra feltárására
Faktoranalízis 6.-7. előadás Kvantitatív statisztikai módszerek Faktoranalízis Olyan többváltozós statisztikai módszer, amely adattömörítésre, a változók számának csökkentésére, az adatstruktúra feltárására
Főkomponens és Faktor analízis
 Főkomponens és Faktor analízis Márkus László 2014. december 4. Márkus László Főkomponens és Faktor analízis 2014. december 4. 1 / 34 Bevezetés - Főkomponens és Faktoranalízis A főkomponens és faktor analízis
Főkomponens és Faktor analízis Márkus László 2014. december 4. Márkus László Főkomponens és Faktor analízis 2014. december 4. 1 / 34 Bevezetés - Főkomponens és Faktoranalízis A főkomponens és faktor analízis
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
Adatok statisztikai értékelésének főbb lehetőségei
 Adatok statisztikai értékelésének főbb lehetőségei 1. a. Egy- vagy kétváltozós eset b. Többváltozós eset 2. a. Becslési problémák, hipotézis vizsgálat b. Mintázatelemzés 3. Szint: a. Egyedi b. Populáció
Adatok statisztikai értékelésének főbb lehetőségei 1. a. Egy- vagy kétváltozós eset b. Többváltozós eset 2. a. Becslési problémák, hipotézis vizsgálat b. Mintázatelemzés 3. Szint: a. Egyedi b. Populáció
Diszkriminancia-analízis
 Diszkriminancia-analízis az SPSS-ben Petrovics Petra Doktorandusz Diszkriminancia-analízis folyamata Feladat Megnyitás: Employee_data.sav Milyen tényezőktől függ a dolgozók beosztása? Nem metrikus Független
Diszkriminancia-analízis az SPSS-ben Petrovics Petra Doktorandusz Diszkriminancia-analízis folyamata Feladat Megnyitás: Employee_data.sav Milyen tényezőktől függ a dolgozók beosztása? Nem metrikus Független
Nagy-György Judit. Szegedi Tudományegyetem, Bolyai Intézet
 Többváltozós statisztika Szegedi Tudományegyetem, Bolyai Intézet Többváltozós módszerek Ezek a módszerek több változó együttes vizsgálatára vonatkoznak. Alapvető típusaik: többdimenziós eloszlásokra vonatkozó
Többváltozós statisztika Szegedi Tudományegyetem, Bolyai Intézet Többváltozós módszerek Ezek a módszerek több változó együttes vizsgálatára vonatkoznak. Alapvető típusaik: többdimenziós eloszlásokra vonatkozó
Több mint egy változót jegyzünk fel a megfigyelési egységekről (objektumok).
.") Többváltozós roblémák Több mint egy változót jegyzünk fel a megfigyelési egységekről (objektumok). Volt: Több magyarázó változó: többszörös regresszió, több faktoros ANOVA, ANCOVA. Most: több független
Többváltozós roblémák Több mint egy változót jegyzünk fel a megfigyelési egységekről (objektumok). Volt: Több magyarázó változó: többszörös regresszió, több faktoros ANOVA, ANCOVA. Most: több független
Fogalom STATISZTIKA. Alkalmazhatósági feltételek. A standard lineáris modell. Projekciós mátrix, P
 Fogalom STATISZTIKA 8 Előadás Többszörös lineáris regresszió Egy jelenség vizsgálata során általában az adott jelenséget több tényező befolyásolja, vagyis többnyire nem elegendő a kétváltozós modell elemzése
Fogalom STATISZTIKA 8 Előadás Többszörös lineáris regresszió Egy jelenség vizsgálata során általában az adott jelenséget több tényező befolyásolja, vagyis többnyire nem elegendő a kétváltozós modell elemzése
STATISZTIKA. Fogalom. A standard lineáris regressziós modell mátrixalgebrai jelölése. A standard lineáris modell. Eredménytáblázat
 Fogalom STATISZTIKA 8 Előadás Többszörös lineáris regresszió Egy jelenség vizsgálata során általában az adott jelenséget több tényező befolyásolja, vagyis többnyire nem elegendő a kétváltozós modell elemzése
Fogalom STATISZTIKA 8 Előadás Többszörös lineáris regresszió Egy jelenség vizsgálata során általában az adott jelenséget több tényező befolyásolja, vagyis többnyire nem elegendő a kétváltozós modell elemzése
Miskolci Egyetem Gazdaságtudományi Kar Üzleti Információgazdálkodási és Módszertani Intézet
 Fkt Faktoranalízis líi Olyan többváltozós statisztikai módszer, amely adattömörítésre, a változók számának csökkentésére, az adatstruktúra feltárására szolgál. A kiinduló változók számát úgynevezett faktorváltozókba
Fkt Faktoranalízis líi Olyan többváltozós statisztikai módszer, amely adattömörítésre, a változók számának csökkentésére, az adatstruktúra feltárására szolgál. A kiinduló változók számát úgynevezett faktorváltozókba
Tárgy- és névmutató. C Cox & Snell R négyzet 357 Cramer-V 139, , 151, 155, 159 csoportok közötti korrelációs mátrix 342 csúcsosság 93 95, 102
 Tárgy- és névmutató A a priori kontraszt 174 175 a priori kritérium 259, 264, 276 adatbevitel 43, 47, 49 52 adatbeviteli nézet (data view) 45 adat-elôkészítés 12, 37, 62 adatgyûjtés 12, 15, 19, 20, 23,
Tárgy- és névmutató A a priori kontraszt 174 175 a priori kritérium 259, 264, 276 adatbevitel 43, 47, 49 52 adatbeviteli nézet (data view) 45 adat-elôkészítés 12, 37, 62 adatgyûjtés 12, 15, 19, 20, 23,
STATISZTIKA. A maradék független a kezelés és blokk hatástól. Maradékok leíró statisztikája. 4. A modell érvényességének ellenőrzése
 4. A modell érvényességének ellenőrzése STATISZTIKA 4. Előadás Variancia-analízis Lineáris modellek 1. Függetlenség 2. Normális eloszlás 3. Azonos varianciák A maradék független a kezelés és blokk hatástól
4. A modell érvényességének ellenőrzése STATISZTIKA 4. Előadás Variancia-analízis Lineáris modellek 1. Függetlenség 2. Normális eloszlás 3. Azonos varianciák A maradék független a kezelés és blokk hatástól
Többváltozós lineáris regressziós modell feltételeinek tesztelése I.
 Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Kvantitatív statisztikai módszerek Petrovics Petra Többváltozós lineáris regressziós
Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Kvantitatív statisztikai módszerek Petrovics Petra Többváltozós lineáris regressziós
Klaszterezés, 2. rész
 Klaszterezés, 2. rész Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 208. április 6. Csima Judit Klaszterezés, 2. rész / 29 Hierarchikus klaszterezés egymásba ágyazott klasztereket
Klaszterezés, 2. rész Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 208. április 6. Csima Judit Klaszterezés, 2. rész / 29 Hierarchikus klaszterezés egymásba ágyazott klasztereket
STATISZTIKA. Egymintás u-próba. H 0 : Kefir zsírtartalma 3% Próbafüggvény, alfa=0,05. Egymintás u-próba vagy z-próba
 Egymintás u-próba STATISZTIKA 2. Előadás Középérték-összehasonlító tesztek Tesztelhetjük, hogy a valószínűségi változónk értéke megegyezik-e egy konkrét értékkel. Megválaszthatjuk a konfidencia intervallum
Egymintás u-próba STATISZTIKA 2. Előadás Középérték-összehasonlító tesztek Tesztelhetjük, hogy a valószínűségi változónk értéke megegyezik-e egy konkrét értékkel. Megválaszthatjuk a konfidencia intervallum
c adatpontok és az ismeretlen pont közötti kovariancia vektora
 1. MELLÉKLET: Alkalmazott jelölések A mintaterület kiterjedése, területe c adatpontok és az ismeretlen pont közötti kovariancia vektora C(0) reziduális komponens varianciája C R (h) C R Cov{} d( u, X )
1. MELLÉKLET: Alkalmazott jelölések A mintaterület kiterjedése, területe c adatpontok és az ismeretlen pont közötti kovariancia vektora C(0) reziduális komponens varianciája C R (h) C R Cov{} d( u, X )
y ij = µ + α i + e ij
 Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai
Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai
Matematikai geodéziai számítások 6.
 Matematikai geodéziai számítások 6. Lineáris regresszió számítás elektronikus távmérőkre Dr. Bácsatyai, László Matematikai geodéziai számítások 6.: Lineáris regresszió számítás elektronikus távmérőkre
Matematikai geodéziai számítások 6. Lineáris regresszió számítás elektronikus távmérőkre Dr. Bácsatyai, László Matematikai geodéziai számítások 6.: Lineáris regresszió számítás elektronikus távmérőkre
Diverzifikáció Markowitz-modell MAD modell CAPM modell 2017/ Szegedi Tudományegyetem Informatikai Intézet
 Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 11. Előadás Portfólió probléma Portfólió probléma Portfólió probléma Adott részvények (kötvények,tevékenységek,
Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 11. Előadás Portfólió probléma Portfólió probléma Portfólió probléma Adott részvények (kötvények,tevékenységek,
Közösség detektálás gráfokban
 Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
Hipotézis vizsgálatok
 Hipotézis vizsgálatok Hipotézisvizsgálat Hipotézis: az alapsokaság paramétereire vagy az alapsokaság eloszlására vonatkozó feltevés. Hipotézis ellenőrzés: az a statisztikai módszer, amelynek segítségével
Hipotézis vizsgálatok Hipotézisvizsgálat Hipotézis: az alapsokaság paramétereire vagy az alapsokaság eloszlására vonatkozó feltevés. Hipotézis ellenőrzés: az a statisztikai módszer, amelynek segítségével
Segítség az outputok értelmezéséhez
 Tanulni: 10.1-10.3, 10.5, 11.10. Hf: A honlapra feltett falco_exp.zip-ben lévő exploratív elemzések áttanulmányozása, érdekességek, észrevételek kigyűjtése. Segítség az outputok értelmezéséhez Leiro: Leíró
Tanulni: 10.1-10.3, 10.5, 11.10. Hf: A honlapra feltett falco_exp.zip-ben lévő exploratív elemzések áttanulmányozása, érdekességek, észrevételek kigyűjtése. Segítség az outputok értelmezéséhez Leiro: Leíró
A leíró statisztikák
 A leíró statisztikák A leíró statisztikák fogalma, haszna Gyakori igény az, hogy egy adathalmazt elemei egyenkénti felsorolása helyett néhány jellemző tulajdonságának megadásával jellemezzünk. Ezeket az
A leíró statisztikák A leíró statisztikák fogalma, haszna Gyakori igény az, hogy egy adathalmazt elemei egyenkénti felsorolása helyett néhány jellemző tulajdonságának megadásával jellemezzünk. Ezeket az
Többváltozós lineáris regressziós modell feltételeinek
 Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Petrovics Petra Doktorandusz Többváltozós lineáris regressziós modell x 1, x 2,, x p
Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Petrovics Petra Doktorandusz Többváltozós lineáris regressziós modell x 1, x 2,, x p
Bevezetés a Korreláció &
 Bevezetés a Korreláció & Regressziószámításba Petrovics Petra Doktorandusz Statisztikai kapcsolatok Asszociáció 2 minőségi/területi ismérv között Vegyes kapcsolat minőségi/területi és egy mennyiségi ismérv
Bevezetés a Korreláció & Regressziószámításba Petrovics Petra Doktorandusz Statisztikai kapcsolatok Asszociáció 2 minőségi/területi ismérv között Vegyes kapcsolat minőségi/területi és egy mennyiségi ismérv
Statisztikai következtetések Nemlineáris regresszió Feladatok Vége
 [GVMGS11MNC] Gazdaságstatisztika 10. előadás: 9. Regressziószámítás II. Kóczy Á. László koczy.laszlo@kgk.uni-obuda.hu Keleti Károly Gazdasági Kar Vállalkozásmenedzsment Intézet A standard lineáris modell
[GVMGS11MNC] Gazdaságstatisztika 10. előadás: 9. Regressziószámítás II. Kóczy Á. László koczy.laszlo@kgk.uni-obuda.hu Keleti Károly Gazdasági Kar Vállalkozásmenedzsment Intézet A standard lineáris modell
ANOVA,MANOVA. Márkus László március 30. Márkus László ANOVA,MANOVA március / 26
 ANOVA,MANOVA Márkus László 2013. március 30. Márkus László ANOVA,MANOVA 2013. március 30. 1 / 26 ANOVA / MANOVA One-Way ANOVA (Egyszeres ) Analysis of Variance (ANOVA) = szóráselemzés A szórásokat elemezzük,
ANOVA,MANOVA Márkus László 2013. március 30. Márkus László ANOVA,MANOVA 2013. március 30. 1 / 26 ANOVA / MANOVA One-Way ANOVA (Egyszeres ) Analysis of Variance (ANOVA) = szóráselemzés A szórásokat elemezzük,
Biomatematika 12. Szent István Egyetem Állatorvos-tudományi Kar. Fodor János
 Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
III. Kvantitatív változók kapcsolata (korreláció, regresszió)
") III. Kvantitatív változók kapcsolata (korreláció, regresszió) Tartalom Változók kapcsolata Kétdimenziós minta (pontdiagram) Regressziós előrejelzés (predikció) Korreláció Tanuló Kétdimenziós minta Tanulással
III. Kvantitatív változók kapcsolata (korreláció, regresszió) Tartalom Változók kapcsolata Kétdimenziós minta (pontdiagram) Regressziós előrejelzés (predikció) Korreláció Tanuló Kétdimenziós minta Tanulással
Faktor- és fıkomponens analízis
 Faktor- és fıkomponens analízis Informatikai Tudományok Doktori Iskola Adatredukció Olyan statisztikai módszerek tartoznak ide, melyek lehetıvé teszik, hogy az adatmátrix méretét csökkentve kisebb költséggel
Faktor- és fıkomponens analízis Informatikai Tudományok Doktori Iskola Adatredukció Olyan statisztikai módszerek tartoznak ide, melyek lehetıvé teszik, hogy az adatmátrix méretét csökkentve kisebb költséggel
STATISZTIKA ELŐADÁS ÁTTEKINTÉSE. Matematikai statisztika. Mi a modell? Binomiális eloszlás sűrűségfüggvény. Binomiális eloszlás
 ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 9. Előadás Binomiális eloszlás Egyenletes eloszlás Háromszög eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell 2/62 Matematikai statisztika
ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 9. Előadás Binomiális eloszlás Egyenletes eloszlás Háromszög eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell 2/62 Matematikai statisztika
Matematikai geodéziai számítások 6.
 Nyugat-magyarországi Egyetem Geoinformatikai Kara Dr. Bácsatyai László Matematikai geodéziai számítások 6. MGS6 modul Lineáris regresszió számítás elektronikus távmérőkre SZÉKESFEHÉRVÁR 2010 Jelen szellemi
Nyugat-magyarországi Egyetem Geoinformatikai Kara Dr. Bácsatyai László Matematikai geodéziai számítások 6. MGS6 modul Lineáris regresszió számítás elektronikus távmérőkre SZÉKESFEHÉRVÁR 2010 Jelen szellemi
Varianciaanalízis 4/24/12
 1. Feladat Egy póker kártya keverő gép a kártyákat random módon választja ki. A vizsgálatban 1600 választott kártya színei az alábbi gyakorisággal fordultak elő. Vizsgáljuk meg, hogy a kártyák kiválasztása
1. Feladat Egy póker kártya keverő gép a kártyákat random módon választja ki. A vizsgálatban 1600 választott kártya színei az alábbi gyakorisággal fordultak elő. Vizsgáljuk meg, hogy a kártyák kiválasztása
STATISZTIKA ELŐADÁS ÁTTEKINTÉSE. Mi a modell? Matematikai statisztika. 300 dobás. sűrűségfüggvénye. Egyenletes eloszlás
 ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 7. Előadás Egyenletes eloszlás Binomiális eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell /56 Matematikai statisztika Reprezentatív mintavétel
ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 7. Előadás Egyenletes eloszlás Binomiális eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell /56 Matematikai statisztika Reprezentatív mintavétel
Regressziós vizsgálatok
 Regressziós vizsgálatok Regresszió (regression) Általános jelentése: visszaesés, hanyatlás, visszafelé mozgás, visszavezetés. Orvosi területen: visszafejlődés, involúció. A betegség tünetei, vagy maga
Regressziós vizsgálatok Regresszió (regression) Általános jelentése: visszaesés, hanyatlás, visszafelé mozgás, visszavezetés. Orvosi területen: visszafejlődés, involúció. A betegség tünetei, vagy maga
Klaszterelemzés az SPSS-ben
 Klaszterelemzés az SPSS-ben Kvantitatív statisztikai módszerek Petrovics Petra Klaszteranalízis Olyan dimenziócsökkentő eljárás, amellyel adattömböket megfigyelési egységeket tudunk viszonylag homogén
Klaszterelemzés az SPSS-ben Kvantitatív statisztikai módszerek Petrovics Petra Klaszteranalízis Olyan dimenziócsökkentő eljárás, amellyel adattömböket megfigyelési egységeket tudunk viszonylag homogén
Virág Katalin. Szegedi Tudományegyetem, Bolyai Intézet
 Függetleségvizsgálat Virág Katali Szegedi Tudomáyegyetem, Bolyai Itézet Függetleség Függetleség Két változó függetle, ha az egyik változó megfigyelése a másik változóra ézve em szolgáltat iformációt; azaz
Függetleségvizsgálat Virág Katali Szegedi Tudomáyegyetem, Bolyai Itézet Függetleség Függetleség Két változó függetle, ha az egyik változó megfigyelése a másik változóra ézve em szolgáltat iformációt; azaz
Többváltozós lineáris regresszió 3.
 Többváltozós lineáris regresszió 3. Orlovits Zsanett 2018. október 10. Alapok Kérdés: hogyan szerepeltethetünk egy minőségi (nominális) tulajdonságot (pl. férfi/nő, egészséges/beteg, szezonális hatások,
Többváltozós lineáris regresszió 3. Orlovits Zsanett 2018. október 10. Alapok Kérdés: hogyan szerepeltethetünk egy minőségi (nominális) tulajdonságot (pl. férfi/nő, egészséges/beteg, szezonális hatások,
Hipotézis STATISZTIKA. Kétmintás hipotézisek. Munkahipotézis (H a ) Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok
 Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok") STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
Miskolci Egyetem Gazdaságtudományi Kar Üzleti Információgazdálkodási és Módszertani Intézet Factor Analysis
 Factor Analysis Factor analysis is a multiple statistical method, which analyzes the correlation relation between data, and it is for data reduction, dimension reduction and to explore the structure. Aim
Factor Analysis Factor analysis is a multiple statistical method, which analyzes the correlation relation between data, and it is for data reduction, dimension reduction and to explore the structure. Aim
Geokémia gyakorlat. 1. Geokémiai adatok értelmezése: egyszerű statisztikai módszerek. Geológus szakirány (BSc) Dr. Lukács Réka
 Dr. Lukács Réka") Geokémia gyakorlat 1. Geokémiai adatok értelmezése: egyszerű statisztikai módszerek Geológus szakirány (BSc) Dr. Lukács Réka MTA-ELTE Vulkanológiai Kutatócsoport e-mail: reka.harangi@gmail.com ALAPFOGALMAK:
Geokémia gyakorlat 1. Geokémiai adatok értelmezése: egyszerű statisztikai módszerek Geológus szakirány (BSc) Dr. Lukács Réka MTA-ELTE Vulkanológiai Kutatócsoport e-mail: reka.harangi@gmail.com ALAPFOGALMAK:
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
Hátrányok: A MANOVA elvégzésének lépései:
 MANOVA Tulajdonságok: Hasonló az ANOVÁ-hoz Több függő változó A függő változók korreláltak és a lineáris kombinációnak értelme van. Azt teszteli, hogy k populációban a függő változók egy lineáris kombinációjának
MANOVA Tulajdonságok: Hasonló az ANOVÁ-hoz Több függő változó A függő változók korreláltak és a lineáris kombinációnak értelme van. Azt teszteli, hogy k populációban a függő változók egy lineáris kombinációjának
Biometria az orvosi gyakorlatban. Korrelációszámítás, regresszió
 SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
Matematikai alapok és valószínőségszámítás. Középértékek és szóródási mutatók
 Matematikai alapok és valószínőségszámítás Középértékek és szóródási mutatók Középértékek A leíró statisztikák talán leggyakrabban használt csoportját a középértékek jelentik. Legkönnyebben mint az adathalmaz
Matematikai alapok és valószínőségszámítás Középértékek és szóródási mutatók Középértékek A leíró statisztikák talán leggyakrabban használt csoportját a középértékek jelentik. Legkönnyebben mint az adathalmaz
Statisztikai szoftverek esszé
 Statisztikai szoftverek esszé Dávid Nikolett Szeged 2011 1 1. Helyzetfelmérés Adott egy kölcsön.txt nevű adatfájl, amely információkkal rendelkezik az ügyfelek életkoráról, családi állapotáról, munkaviszonyáról,
Statisztikai szoftverek esszé Dávid Nikolett Szeged 2011 1 1. Helyzetfelmérés Adott egy kölcsön.txt nevű adatfájl, amely információkkal rendelkezik az ügyfelek életkoráról, családi állapotáról, munkaviszonyáról,
Matematikai statisztika Gazdaságinformatikus MSc október 8. lineáris regresszió. Adatredukció: Faktor- és főkomponensanaĺızis.
 i Matematikai statisztika Gazdaságinformatikus MSc 6. előadás 2018. október 8. 1/52 - Hol tartottunk? Modell. Y i = β 0 + β 1 X 1,i + β 2 X 2,i +... + β k X k,i + u i i minden t = 1,..., n esetén. X i
i Matematikai statisztika Gazdaságinformatikus MSc 6. előadás 2018. október 8. 1/52 - Hol tartottunk? Modell. Y i = β 0 + β 1 X 1,i + β 2 X 2,i +... + β k X k,i + u i i minden t = 1,..., n esetén. X i
y ij = µ + α i + e ij STATISZTIKA Sir Ronald Aylmer Fisher Példa Elmélet A variancia-analízis alkalmazásának feltételei Lineáris modell
 Példa STATISZTIKA Egy gazdálkodó k kukorica hibrid termesztése között választhat. Jelöljük a fajtákat A, B, C, D-vel. Döntsük el, hogy a hibridek termesztése esetén azonos terméseredményre számíthatunk-e.
Példa STATISZTIKA Egy gazdálkodó k kukorica hibrid termesztése között választhat. Jelöljük a fajtákat A, B, C, D-vel. Döntsük el, hogy a hibridek termesztése esetén azonos terméseredményre számíthatunk-e.
Matematikai statisztika Gazdaságinformatikus MSc október 8. lineáris regresszió. Adatredukció: Faktor- és főkomponensanaĺızis.
 i Matematikai statisztika Gazdaságinformatikus MSc 6. előadás 2018. október 8. 1/52 - Hol tartottunk? Modell. Y i = β 0 + β 1 X 1,i + β 2 X 2,i +... + β k X k,i + u i i minden t = 1,..., n esetén. 2/52
i Matematikai statisztika Gazdaságinformatikus MSc 6. előadás 2018. október 8. 1/52 - Hol tartottunk? Modell. Y i = β 0 + β 1 X 1,i + β 2 X 2,i +... + β k X k,i + u i i minden t = 1,..., n esetén. 2/52
(Independence, dependence, random variables)
") Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
Saj at ert ek-probl em ak febru ar 26.
 Sajátérték-problémák 2018. február 26. Az alapfeladat Adott a következő egyenlet: Av = λv, (1) ahol A egy ismert mátrix v ismeretlen, nem zérus vektor λ ismeretlen szám Azok a v, λ kombinációk, amikre
Sajátérték-problémák 2018. február 26. Az alapfeladat Adott a következő egyenlet: Av = λv, (1) ahol A egy ismert mátrix v ismeretlen, nem zérus vektor λ ismeretlen szám Azok a v, λ kombinációk, amikre
STATISZTIKA. András hármas. Éva ötös. Nóri négyes. 5 4,5 4 3,5 3 2,5 2 1,5 ANNA BÉLA CILI 0,5 MAGY. MAT. TÖRT. KÉM.
 STATISZTIKA 5 4,5 4 3,5 3 2,5 2 1,5 1 0,5 0 MAGY. MAT. TÖRT. KÉM. ANNA BÉLA CILI András hármas. Béla Az átlag 3,5! kettes. Éva ötös. Nóri négyes. 1 mérés: dolgokhoz valamely szabály alapján szám rendelése
STATISZTIKA 5 4,5 4 3,5 3 2,5 2 1,5 1 0,5 0 MAGY. MAT. TÖRT. KÉM. ANNA BÉLA CILI András hármas. Béla Az átlag 3,5! kettes. Éva ötös. Nóri négyes. 1 mérés: dolgokhoz valamely szabály alapján szám rendelése
Elemi statisztika fizikusoknak
 1. oldal Elemi statisztika fizikusoknak Pollner Péter Biológiai Fizika Tanszék pollner@elte.hu Az adatok leírása, megismerése és összehasonlítása 2-1 Áttekintés 2-2 Gyakoriság eloszlások 2-3 Az adatok
1. oldal Elemi statisztika fizikusoknak Pollner Péter Biológiai Fizika Tanszék pollner@elte.hu Az adatok leírása, megismerése és összehasonlítása 2-1 Áttekintés 2-2 Gyakoriság eloszlások 2-3 Az adatok
[Biomatematika 2] Orvosi biometria. Visegrády Balázs
![[Biomatematika 2] Orvosi biometria. Visegrády Balázs](/thumbs/93/112272424.jpg "[Biomatematika 2] Orvosi biometria. Visegrády Balázs") [Biomatematika 2] Orvosi biometria Visegrády Balázs 2016. 03. 27. Probléma: Klinikai vizsgálatban három különböző antiaritmiás gyógyszert (ß-blokkoló) alkalmaznak, hogy kipróbálják hatásukat a szívműködés
[Biomatematika 2] Orvosi biometria Visegrády Balázs 2016. 03. 27. Probléma: Klinikai vizsgálatban három különböző antiaritmiás gyógyszert (ß-blokkoló) alkalmaznak, hogy kipróbálják hatásukat a szívműködés
Normális eloszlás tesztje
 Valószínűség, pontbecslés, konfidenciaintervallum Normális eloszlás tesztje Kolmogorov-Szmirnov vagy Wilk-Shapiro próba. R-funkció: shapiro.test(vektor) balra ferde eloszlás jobbra ferde eloszlás balra
Valószínűség, pontbecslés, konfidenciaintervallum Normális eloszlás tesztje Kolmogorov-Szmirnov vagy Wilk-Shapiro próba. R-funkció: shapiro.test(vektor) balra ferde eloszlás jobbra ferde eloszlás balra
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
Egyszempontos variancia analízis. Statisztika I., 5. alkalom
 Statisztika I., 5. alkalom Számos t-próba versus variancia analízis Kreativitás vizsgálata -nık -férfiak ->kétmintás t-próba I. Fajú hiba=α Kreativitás vizsgálata -informatikusok -építészek -színészek
Statisztika I., 5. alkalom Számos t-próba versus variancia analízis Kreativitás vizsgálata -nık -férfiak ->kétmintás t-próba I. Fajú hiba=α Kreativitás vizsgálata -informatikusok -építészek -színészek
Feladatok: pontdiagram és dobozdiagram. Hogyan csináltuk?
 Feladatok: pontdiagram és dobozdiagram Hogyan csináltuk? Alakmutatók: ferdeség, csúcsosság Alakmutatók a ferdeség és csúcsosság mérésére Ez eloszlás centrumát (középérték) és az adatok centrum körüli terpeszkedését
Feladatok: pontdiagram és dobozdiagram Hogyan csináltuk? Alakmutatók: ferdeség, csúcsosság Alakmutatók a ferdeség és csúcsosság mérésére Ez eloszlás centrumát (középérték) és az adatok centrum körüli terpeszkedését
Véletlen jelenség: okok rendszere hozza létre - nem ismerhetjük mind, ezért sztochasztikus.
 Valószín ségelméleti és matematikai statisztikai alapfogalmak összefoglalása (Kemény Sándor - Deák András: Mérések tervezése és eredményeik értékelése, kivonat) Véletlen jelenség: okok rendszere hozza
Valószín ségelméleti és matematikai statisztikai alapfogalmak összefoglalása (Kemény Sándor - Deák András: Mérések tervezése és eredményeik értékelése, kivonat) Véletlen jelenség: okok rendszere hozza
Adatbányászat: Klaszterezés Haladó fogalmak és algoritmusok
 Adatbányászat: Klaszterezés Haladó fogalmak és algoritmusok 9. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Logók és támogatás A tananyag a TÁMOP-4.1.2-08/1/A-2009-0046
Adatbányászat: Klaszterezés Haladó fogalmak és algoritmusok 9. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Logók és támogatás A tananyag a TÁMOP-4.1.2-08/1/A-2009-0046
Elméleti összefoglaló a Sztochasztika alapjai kurzushoz
 Elméleti összefoglaló a Sztochasztika alapjai kurzushoz 1. dolgozat Véletlen kísérletek, események valószín sége Deníció. Egy véletlen kísérlet lehetséges eredményeit kimeneteleknek nevezzük. A kísérlet
Elméleti összefoglaló a Sztochasztika alapjai kurzushoz 1. dolgozat Véletlen kísérletek, események valószín sége Deníció. Egy véletlen kísérlet lehetséges eredményeit kimeneteleknek nevezzük. A kísérlet
Elméleti összefoglaló a Valószín ségszámítás kurzushoz
 Elméleti összefoglaló a Valószín ségszámítás kurzushoz Véletlen kísérletek, események valószín sége Deníció. Egy véletlen kísérlet lehetséges eredményeit kimeneteleknek nevezzük. A kísérlet kimeneteleinek
Elméleti összefoglaló a Valószín ségszámítás kurzushoz Véletlen kísérletek, események valószín sége Deníció. Egy véletlen kísérlet lehetséges eredményeit kimeneteleknek nevezzük. A kísérlet kimeneteleinek
Biometria az orvosi gyakorlatban. Regresszió Túlélésanalízis
 SZDT-09 p. 1/36 Biometria az orvosi gyakorlatban Regresszió Túlélésanalízis Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Logisztikus regresszió
SZDT-09 p. 1/36 Biometria az orvosi gyakorlatban Regresszió Túlélésanalízis Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Logisztikus regresszió
Saj at ert ek-probl em ak febru ar 22.
 Sajátérték-problémák 2016. február 22. Az alapfeladat Adott a következő egyenlet: Av = λv, (1) ahol A egy ismert mátrix v ismeretlen vektor λ ismeretlen szám Azok a v, λ kombinációk, amikre az egyenlet
Sajátérték-problémák 2016. február 22. Az alapfeladat Adott a következő egyenlet: Av = λv, (1) ahol A egy ismert mátrix v ismeretlen vektor λ ismeretlen szám Azok a v, λ kombinációk, amikre az egyenlet
Egymintás próbák. Alapkérdés: populáció <paramétere/tulajdonsága> megegyezik-e egy referencia paraméter értékkel/tulajdonsággal?
 Egymintás próbák σ s μ m Alapkérdés: A populáció egy adott megegyezik-e egy referencia paraméter értékkel/tulajdonsággal? egymintás t-próba Wilcoxon-féle előjeles
Egymintás próbák σ s μ m Alapkérdés: A populáció egy adott megegyezik-e egy referencia paraméter értékkel/tulajdonsággal? egymintás t-próba Wilcoxon-féle előjeles
A maximum likelihood becslésről
 A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
Mérési adatok illesztése, korreláció, regresszió
 Mérési adatok illesztése, korreláció, regresszió Korreláció, regresszió Két változó mennyiség közötti kapcsolatot vizsgálunk. Kérdés: van-e kapcsolat két, ugyanabban az egyénben, állatban, kísérleti mintában,
Mérési adatok illesztése, korreláció, regresszió Korreláció, regresszió Két változó mennyiség közötti kapcsolatot vizsgálunk. Kérdés: van-e kapcsolat két, ugyanabban az egyénben, állatban, kísérleti mintában,
4/24/12. Regresszióanalízis. Legkisebb négyzetek elve. Regresszióanalízis
 1. feladat Regresszióanalízis. Legkisebb négyzetek elve 2. feladat Az iskola egy évfolyamába tartozó diákok átlagéletkora 15,8 év, standard deviációja 0,6 év. A 625 fős évfolyamból hány diák fiatalabb
1. feladat Regresszióanalízis. Legkisebb négyzetek elve 2. feladat Az iskola egy évfolyamába tartozó diákok átlagéletkora 15,8 év, standard deviációja 0,6 év. A 625 fős évfolyamból hány diák fiatalabb
Elemi statisztika. >> =weiszd= << december 20. Szerintem nincs sok szükségünk erre... [visszajelzés esetén azt is belerakom] x x = n
![Elemi statisztika. >> =weiszd= << december 20. Szerintem nincs sok szükségünk erre... [visszajelzés esetén azt is belerakom] x x = n](/thumbs/61/46384531.jpg "Elemi statisztika. >> =weiszd= << december 20. Szerintem nincs sok szükségünk erre... [visszajelzés esetén azt is belerakom] x x = n") Elemi statisztika >> =weiszd=
Elemi statisztika >> =weiszd=
2013 ŐSZ. 1. Mutassa be az egymintás z-próba célját, alkalmazásának feltételeit és módszerét!
 GAZDASÁGSTATISZTIKA KIDOLGOZOTT ELMÉLETI KÉRDÉSEK A 3. ZH-HOZ 2013 ŐSZ Elméleti kérdések összegzése 1. Mutassa be az egymintás z-próba célját, alkalmazásának feltételeit és módszerét! 2. Mutassa be az
GAZDASÁGSTATISZTIKA KIDOLGOZOTT ELMÉLETI KÉRDÉSEK A 3. ZH-HOZ 2013 ŐSZ Elméleti kérdések összegzése 1. Mutassa be az egymintás z-próba célját, alkalmazásának feltételeit és módszerét! 2. Mutassa be az
Izgalmas újdonságok a klaszteranalízisben
 Izgalmas újdonságok a klaszteranalízisben Vargha András KRE és ELTE, Pszichológiai Intézet Vargha András KRE és ELTE, Pszichológiai Intézet Mi a klaszteranalízis (KLA)? Keressük a személyek (vagy bármilyen
Izgalmas újdonságok a klaszteranalízisben Vargha András KRE és ELTE, Pszichológiai Intézet Vargha András KRE és ELTE, Pszichológiai Intézet Mi a klaszteranalízis (KLA)? Keressük a személyek (vagy bármilyen
Leíró és matematikai statisztika el adásnapló Matematika alapszak, matematikai elemz szakirány 2016/2017. tavaszi félév
 Leíró és matematikai statisztika el adásnapló Matematika alapszak, matematikai elemz szakirány 2016/2017. tavaszi félév A pirossal írt anyagrészeket nem fogom közvetlenül számon kérni a vizsgán, azok háttérismeretként,
Leíró és matematikai statisztika el adásnapló Matematika alapszak, matematikai elemz szakirány 2016/2017. tavaszi félév A pirossal írt anyagrészeket nem fogom közvetlenül számon kérni a vizsgán, azok háttérismeretként,
Klaszterelemzés az SPSS-ben
 Klaszterelemzés az SPSS-ben Petrovics Petra Doktorandusz Klaszteranalízis Olyan dimenziócsökkentő eljárás, amellyel adattömböket megfigyelési egységeket tudunk viszonylag homogén csoportokba sorolni, klasszifikálni.
Klaszterelemzés az SPSS-ben Petrovics Petra Doktorandusz Klaszteranalízis Olyan dimenziócsökkentő eljárás, amellyel adattömböket megfigyelési egységeket tudunk viszonylag homogén csoportokba sorolni, klasszifikálni.
IBM SPSS Modeler 18.2 Újdonságok
 IBM SPSS Modeler 18.2 Újdonságok 1 2 Új, modern megjelenés Vizualizáció fejlesztése Újabb algoritmusok (Python, Spark alapú) View Data, t-sne, e-plot GMM, HDBSCAN, KDE, Isotonic-Regression 3 Új, modern
IBM SPSS Modeler 18.2 Újdonságok 1 2 Új, modern megjelenés Vizualizáció fejlesztése Újabb algoritmusok (Python, Spark alapú) View Data, t-sne, e-plot GMM, HDBSCAN, KDE, Isotonic-Regression 3 Új, modern
Blind Source Separation. Kiváltott agyi jelek informatikai feldolgozása
 Blind Source Separation Kiváltott agyi jelek informatikai feldolgozása 1 Bevezetés Az EEG jelek elemzése során egyik fő nehézség a különböző források szuperponálásából kapott többcsatornás jelből az egyes
Blind Source Separation Kiváltott agyi jelek informatikai feldolgozása 1 Bevezetés Az EEG jelek elemzése során egyik fő nehézség a különböző források szuperponálásából kapott többcsatornás jelből az egyes
Adatbányászati szemelvények MapReduce környezetben
 Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
7. Régió alapú szegmentálás
 Digitális képek szegmentálása 7. Régió alapú szegmentálás Kató Zoltán http://www.cab.u-szeged.hu/~kato/segmentation/ Szegmentálási kritériumok Particionáljuk a képet az alábbi kritériumokat kielégítő régiókba
Digitális képek szegmentálása 7. Régió alapú szegmentálás Kató Zoltán http://www.cab.u-szeged.hu/~kato/segmentation/ Szegmentálási kritériumok Particionáljuk a képet az alábbi kritériumokat kielégítő régiókba
Least Squares becslés
 Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Sajátértékek és sajátvektorok. mf1n1a06- mf1n2a06 Csabai István
 Sajátértékek és sajátvektorok A fizika numerikus módszerei I. mf1n1a06- mf1n2a06 Csabai István Lineáris transzformáció Vektorok lineáris transzformációja: általános esetben az x vektor iránya és nagysága
Sajátértékek és sajátvektorok A fizika numerikus módszerei I. mf1n1a06- mf1n2a06 Csabai István Lineáris transzformáció Vektorok lineáris transzformációja: általános esetben az x vektor iránya és nagysága
Gyakorló feladatok adatbányászati technikák tantárgyhoz
 Gyakorló feladatok adatbányászati technikák tantárgyhoz Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Klaszterezés kiértékelése Feladat:
Gyakorló feladatok adatbányászati technikák tantárgyhoz Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Klaszterezés kiértékelése Feladat:
Több valószínűségi változó együttes eloszlása, korreláció
 Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Statisztika I. 11. előadás. Előadó: Dr. Ertsey Imre
 Statisztika I. 11. előadás Előadó: Dr. Ertsey Imre Összefüggés vizsgálatok A társadalmi gazdasági élet jelenségei kölcsönhatásban állnak, összefüggnek egymással. Statisztika alapvető feladata: - tényszerűségek
Statisztika I. 11. előadás Előadó: Dr. Ertsey Imre Összefüggés vizsgálatok A társadalmi gazdasági élet jelenségei kölcsönhatásban állnak, összefüggnek egymással. Statisztika alapvető feladata: - tényszerűségek
Döntési fák. (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART ))
)") Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
Regresszió. Csorba János. Nagyméretű adathalmazok kezelése március 31.
 Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
[Biomatematika 2] Orvosi biometria
![[Biomatematika 2] Orvosi biometria](/thumbs/47/23623719.jpg "[Biomatematika 2] Orvosi biometria") [Biomatematika 2] Orvosi biometria 2016.02.15. Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza) alkotja az eseményteret. Esemény: az eseménytér részhalmazai.
[Biomatematika 2] Orvosi biometria 2016.02.15. Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza) alkotja az eseményteret. Esemény: az eseménytér részhalmazai.
Korrel aci os egy utthat ok febru ar 29.
 Korrelációs együtthatók 2012. február 29. Május 2-án elmarad az óra. Helyette április 10-én, kedden 5 órakor vendégelőadás lesz: Maschine learning with R: decision trees, clustering. Applications: language
Korrelációs együtthatók 2012. február 29. Május 2-án elmarad az óra. Helyette április 10-én, kedden 5 órakor vendégelőadás lesz: Maschine learning with R: decision trees, clustering. Applications: language
Régészeti mintákon végzett neutronaktivációs analízis eredményeinek sokváltozós statisztikai feldolgozása
 Régészeti mintákon végzett neutronaktivációs analízis eredményeinek sokváltozós statisztikai feldolgozása SZAKDOLGOZAT NÉMETH VIKTÓRIA Matematika BSc Matematika tanári szakirány Témavezető: Balázs László,
Régészeti mintákon végzett neutronaktivációs analízis eredményeinek sokváltozós statisztikai feldolgozása SZAKDOLGOZAT NÉMETH VIKTÓRIA Matematika BSc Matematika tanári szakirány Témavezető: Balázs László,
Biomatematika 13. Varianciaanaĺızis (ANOVA)
") Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 13. Varianciaanaĺızis (ANOVA) Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision Date:
Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 13. Varianciaanaĺızis (ANOVA) Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision Date:
Korreláció számítás az SPSSben
 Korreláció számítás az SPSSben Kvantitatív statisztikai módszerek Petrovics Petra Statisztikai kapcsolatok Asszociáció 2 minőségi/területi ismérv között Vegyes kapcsolat minőségi/területi és egy mennyiségi
Korreláció számítás az SPSSben Kvantitatív statisztikai módszerek Petrovics Petra Statisztikai kapcsolatok Asszociáció 2 minőségi/területi ismérv között Vegyes kapcsolat minőségi/területi és egy mennyiségi
Lineáris algebra gyakorlat
 Lineáris algebra gyakorlat 7. gyakorlat Gyakorlatvezet : Bogya Norbert 2012. március 26. Ismétlés Tartalom 1 Ismétlés 2 Koordinátasor 3 Bázistranszformáció és alkalmazásai Vektorrendszer rangja Mátrix
Lineáris algebra gyakorlat 7. gyakorlat Gyakorlatvezet : Bogya Norbert 2012. március 26. Ismétlés Tartalom 1 Ismétlés 2 Koordinátasor 3 Bázistranszformáció és alkalmazásai Vektorrendszer rangja Mátrix
Van-e kapcsolat a változók között? (példák: fizetés-távolság; felvételi pontszám - görgetett átlag)
") , rangkorreláció Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék 1111, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-16-80 Fax: 463-30-91 http://www.vizgep.bme.hu
, rangkorreláció Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék 1111, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-16-80 Fax: 463-30-91 http://www.vizgep.bme.hu
Keresés képi jellemzők alapján. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Biomatematika 2 Orvosi biometria
 Biomatematika 2 Orvosi biometria 2017.02.13. Populáció és minta jellemző adatai Hibaszámítás Valószínűség 1 Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza)
Biomatematika 2 Orvosi biometria 2017.02.13. Populáció és minta jellemző adatai Hibaszámítás Valószínűség 1 Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza)