GPGPU. GPU-k felépítése. Valasek Gábor
|
|
|
- Jenő Fazekas
- 9 évvel ezelőtt
- Látták:
Átírás
1 GPGPU GPU-k felépítése Valasek Gábor
2 Tartalom A mai órán áttekintjük a GPU-k architekturális felépítését A cél elsősorban egy olyan absztrakt hardvermodell bemutatása, ami segít megérteni a GPU-k hardveres felépítéséből adódó sajátosságokat Ezáltal pedig tetszőleges GPGPU API-val hatékonyabb kódot lehessen írni Röviden: a GPGPU-hoz szükséges implicit hardveres tudás átadása a mai óra célja
3 Források Diákban látható ábrák forrásai:
4 Grafikus szerelőszalag
5 Grafikus szerelőszalag A GPU-k eredetileg az inkrementális képszintézist implementálták hardveresen Azaz egy kép (frame) előállításához szükséges lépések sorozatának fázisait huzalozták bele Mert fontos: az inkrementális képszintézis egy pipeline, aminek egyes szakaszai párhuzamosan futnak Nézzük meg először hát ezt
6 Grafikus szerelőszalag Az inkrementális képszintézisben a kirajzolandó geometriákat primitívekkel közelítjük Három fő típus: pont, szakasz, háromszög A primitíveket egyértelműen meghatározzák a csúcspontjainak koordinátái és a primitívtípusra jellemző összekötési szabály Kirajzolási paranccsal valahány primitívet elkezdünk rajzolni
7 Grafikus szerelőszalag 1)A primitívek minden egyes csúcspontját normalizált eszköz-koordinátarendszerbe (NDC) transzformáljuk 2)A transzformált csúcspontokkal képezzük a megfelelő primitíveket 3)Minden egyes primitívet az ablakra vágunk 4)Minden egyes primitívet raszterizáljuk, fragmenteket állítunk elő belülök 5)Minden egyes fragmentre interpoláljuk a csúcspontokban definiált attribútumokat 6)Minden egyes fragment színét meghatározzuk valamilyen árnyalási modell és textúrák segítségével 7)Eldöntjük, hogy a képernyőn meg kell-e jelenjen a fragment, vagy sem, és hogyan
8 Grafikus szerelőszalag 1)A primitívek minden egyes csúcspontját normalizált eszköz-koordinátarendszerbe (NDC) transzformáljuk 2)A transzformált csúcspontokkal képezzük a megfelelő primitíveket 3)Minden egyes primitívet az ablakra vágunk 4)Minden egyes primitívet raszterizáljuk, fragmenteket állítunk elő belülök 5)Minden egyes fragmentre interpoláljuk a csúcspontokban definiált attribútumokat 6)Minden egyes fragment színét meghatározzuk valamilyen árnyalási modell és textúrák segítségével 7)Minden egyes fragmentre eldöntjük, hogy a képernyőn meg kell-e jelenjen vagy sem, és hogyan
9 Raszterizáció
10 Grafikus szerelőszalag
11
12
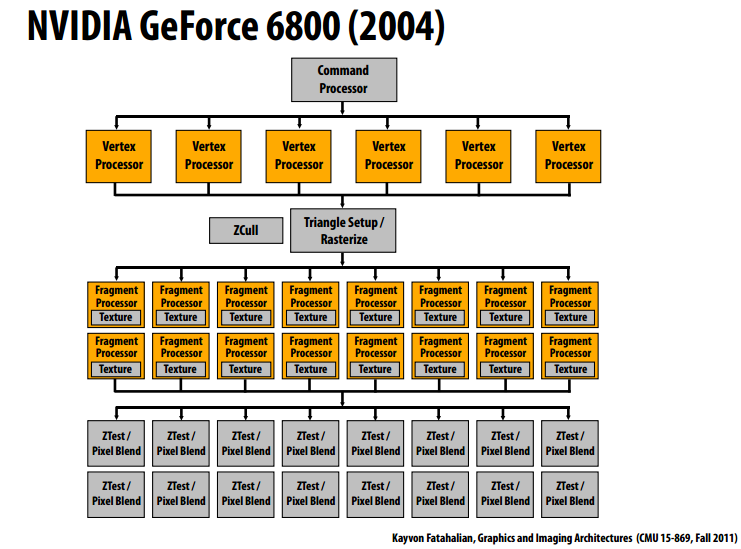
13
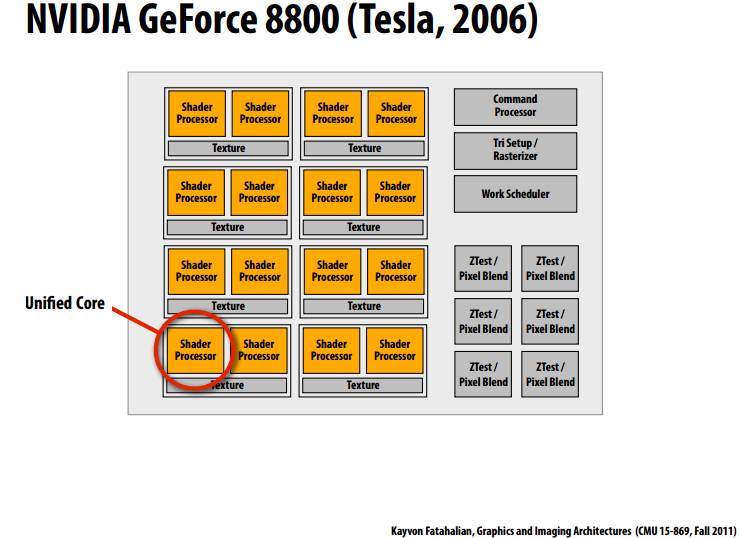
14
15 OpenGL pipeline OpenGL 4.4:
16 Rajzolás grafikus API-val Tipikusan a következőképpen néz ki egy színtér kirajzolása (OpenGL-es szóhasználattal): Parancs típusa Parancs Állapot módosítása Shaderek, textúrák bindolása, uniform változók beállítása Rajzolás Objektum 1 kirajzolása a VAO-jával Állapot módosítása Új uniform értékek átküldése Rajzolás Objektum 2 kirajzolása a VAO-jával Állapot módosítása Új shader bindolása, uniform értékadások Állapot módosítása Blend függvény módosítása Rajzolás Objektum 3 kirajzolása a VAO-jával
17 Rajzolás grafikus API-val Állapotmódosítás lehet shaderek, vertex streamek, textúrák stb. beállítása És figyeljünk: drága az állapotmódosítás Ezért azok hatékony kezelése nagyon fontos De a feladat nehéz: ha minimalizálni akarjuk az állapotváltozások költségét, akkor Utazó Ügynökkel ekvivalens feladatot kapunk Azaz NP-teljeset
18 Rajzolás grafikus API-val Deklaratív (az utasítások olyanok, hogy rajzolj ennyi és ennyi háromszöget, legyen ez az aktív shader stb., nem pedig olyanok, hogy rajzolj kékszemű márvány csillámpónit ) Programozható fázisok vannak (vertex, tesszelációs, geometria és fragment shaderek) Konfigurálható a pipeline Visszacsatolási lehetőségek (feedback loop)
19 Absztrakciók Minden vertexet ugyanúgy dolgozunk fel Függetlenül attól, hogy milyen primitívhez tartozik Minden fragmentet ugyanúgy dolgozunk fel Ismét függetlenül attól, hogy milyen típusú primitívből származik A láthatóságot is primitívtípustól függetlenül oldjuk meg z-bufferrel
20 Grafikus szerelőszalag jellemzői Alacsony szintű absztrakció a hw fölé Megkötések a felépítésén: Adatforgalom a fázisok között korlátozott (előre) Fix funkciójú lépések, amik nem programozhatóak Független adatfeldolgozás (párhuzamosíthatóság) Különböző frekvenciájú műveletek Per vertex, per primitív, per fragment mindent csak a szükséges sebességgel dolgozzunk fel Immediate mode : rajzolási parancs azonnali végrehajtása színtér menedzselést az alkalmazásra hagyja
21 Grafikus szerelőszalag jellemzői Fontos az is, hogy mivel NEM foglalkozik: Nincs olyan benne, hogy anyag, fény, modellezési/nézeti/vetítési transzformációk Nincs olyan, hogy színtér Csak csúcspontok, primitívek, fragmentek, pixelek és állapotok (bufferek és shaderek) vannak! Globális hatásokhoz, mint például árnyékokhoz, tükröződésekhez, trükközni kell Nincs i/o, ablakozás stb.
22 GPU mag
23 GPU mag Egy GPU-s mag másképp néz ki, mint egy CPU Három (és fél) fontos dolog, amivel eljutunk egy GPU maghoz: 1) Egyszerűsítsük egy CPU mag felépítését és tegyünk be sokat belőlük a GPU-ba 2) Az utasításstream-eket osszuk meg magok között 3) A HW szálakat átlapolva osszuk be magokhoz 4) Az 1)-es pontban az egyszerűsítéssel eltüntetett dolgok egy részét tegyük vissza (esetleg más szinten)
24 CPU - Westmere

25 CPU - Westmere
26 CPU - Westmere Execution context: gyors regiszterek szálankénti privát adatok és állapotváltozók értékeinek tárolására Két execution context = Intel hyperthreading Azaz egy mag 2 szálat tud végrehajtani úgy, hogy felváltva ad hozzáférést az ALU-hoz, hozzáférés váltáskor kicserélve az execution context-et
27 GPU Induljunk ki egy CPU magból Első lépésben vegyünk ki mindent, ami csak egyetlen szál (pontosabban utasítás-stream) gyors végrehajtásáért felelős Cache-ek Bedrótozott vezérlési logika Ezekkel megy el egy átlag CPU lapméretének 50%-a
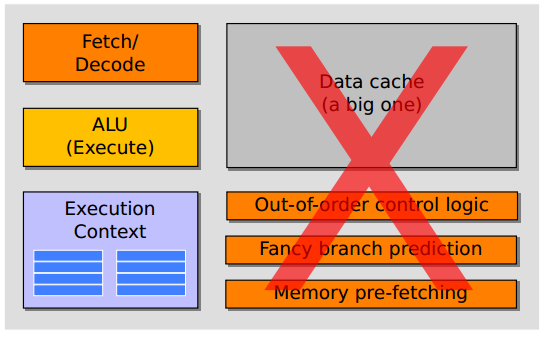
28 1: egyszerűsítés
29 1: egyszerűsítés Az így nyert területet és tranzisztorokat az egyszerűsített mag másolatainak elkészítésére szánjuk Lényegesen több mag van egy GPU-ban, mint egy CPU-ban Ha nem kell várakoznunk valami miatt (például memóriaelérés), így n-szeres sebességet érhetünk el

30 1: egyszerűsítés Két párhuzamos parancs-stream, két magon = két művelet elvégzése egységnyi idő alatt, párhuzamosan

31 1: egyszerűsítés 4 párhuzamos parancs-stream, 4 magon = 4 művelet elvégzése egységnyi idő alatt, párhuzamosan
32 2: SIMD feldolgozás Az inkrementális képszintézisben három fő fázis van: Geometria feldolgozás Raszterizáció Per-fragment árnyalás Ezek maguktól adódóan párhuzamosíthatóak: A geometriai feldolgozásban ugyanazt az affin transzformációt alkalmazzuk a primitívek csúcspontjaira Ugyanazokat a megvilágítási modelleket használjuk egy háromszög fragmentjeire
33 2: SIMD feldolgozás Azaz adat-párhuzamosság van az inkrementális képszintézisben Ennek megfelelően egyszerűsítsük a GPU magokat: osszuk meg több ALU között az utasítás-stream-et Úgyis ugyanazt a shader programot fogják futtatni, csak más-más adatra Ezzel csökkentjük a tranzisztorok számát De egyúttal implikáljuk a folyamatosan memóriahozzáférés szükségességét is optimális működéshez
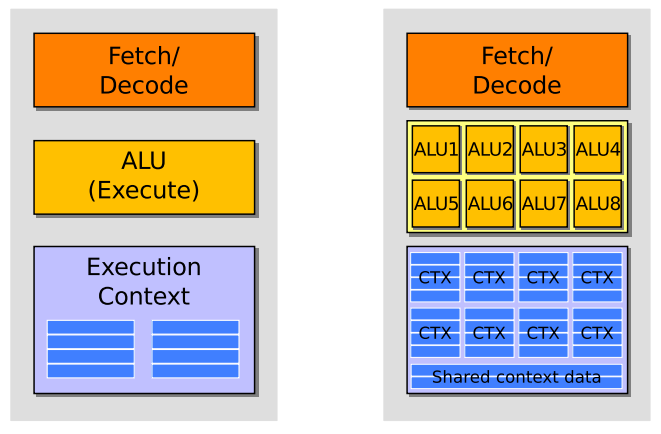
34 2: SIMD feldolgozás

35 2: SIMD feldolgozás Egy 8-széles (8 wide) mag-utasítás 8 különböző adaton végzi el ugyanazt a műveletet

36 2: SIMD feldolgozás 16 darab 8-széles parancs-stream, 16 magon = 128 művelet párhuzamosan
37 SIMD feldolgozás
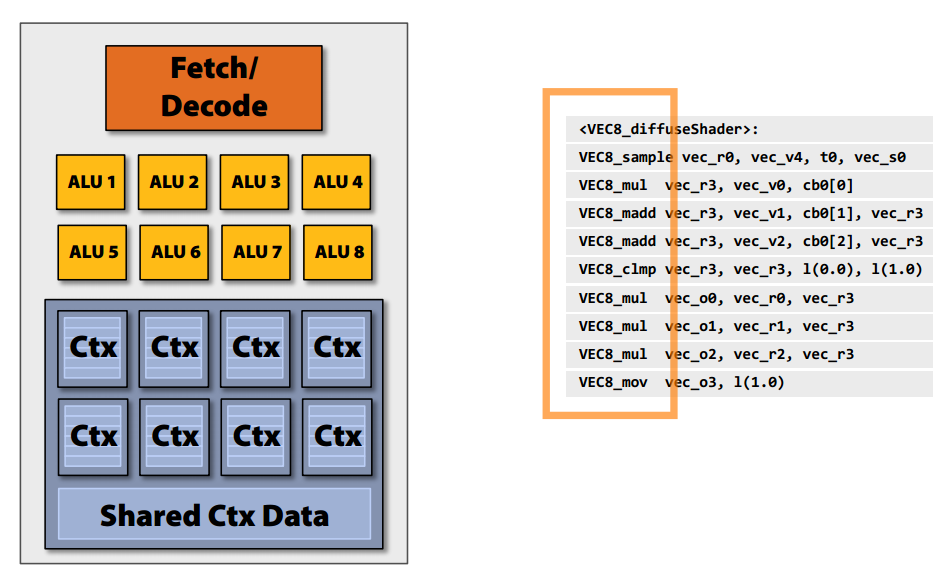
38 SIMD feldolgozás
39 SIMD feldolgozás
40 SIMD problémák Az elágazások divergenciája (azaz amikor az elágazások a különböző adatokra hol a then, hol az else ágra futnak) erősen visszaveti a teljesítményt A then és az else ágak szerializálására van szükség Legrosszabb esetben 1/<ALU-k száma>-ra csökkentve ezzel a teljesítményt egységnyi időben
41 SIMD problémák
42 SIMD feldolgozás Fontos, hogy csak azért, mert SIMD a feldolgozás, nem kell, hogy a programozásban ez explicit megjelenjen: x86 SSE, AVX stb. explicit vektor utasításokkal dolgoznak A GPU-n a vektorizáció implicit, a GPU osztja szét az utasítás stream-eket az ALU-k között (NVIDIA SIMT 32 szálak warp-jait, AMD VLIW 64 szálak wavefront-jait) Emaitt viszont nekünk, programozóknak is több implicit tudásra van szükségünk arról, hogy mi is van a GPU-n!
43 SIMD feldolgozás Tekintsük a következő kódot: float a[n], b[n], c[n];... for (i = 0; i < N; i++) c[i] = a[i] + b[i]; Nézzük meg, hogy miképp néz ki ez SSE-vel és OpenCL kóddal
44 SIMD feldolgozás SSE (explicit vektorutasítások) int a[n], b[n], c[n];... m128i *av, *bv, *cv; av = ( m128i*)a; // assume 16-byte aligned bv = ( m128i*)b; // assume 16-byte aligned cv = ( m128i*)c; // assume 16-byte aligned for (i = 0; i < N/4; i++) cv[i] = _mm_add_epi32(av[i], bv[i]);
45 SIMD feldolgozás OpenCL (implicit, hw vektorizáció) kernel void vector_add( global const int *A, global const int *B, global int *C) { int i = get_global_id(0); C[i] = A[i] + B[i]; }
46 SIMD feldolgozás Így két lehetőség van SIMD feldolgozásnál: Explicit vektorműveletek SSE-k: bit AVX: 512 bit Kézzel, vagy compiler-rel generálva Implicit vektorizáció A hw határozza meg az utasítás-stream megosztást az ALU-k között Ez történik a GPU-n
47 3 késleltetés elrejtése Azaz latency hiding A késleltetés az adatelérésből származik: egy memóriaolvasás akár 1000x annyi időbe is telhet, mint egy aritmetikai művelet elvégzése (tehát egy textúra vagy globális memória elérés ennyivel drágább egy műveletnél!) Ezen segítenek a nagy cache-ek és vezérlőlogika áramkörök amiket az első lépésben kidobtunk :) Csakhogy: a GPU-n rengeteg, független SIMD csoport van
48 3 késleltetés elrejtése Egyetlen magra több SIMD csoportot osszunk be, átlapolva (interleaved) Ha késleltetés történik, akkor átváltunk egy másik SIMD csoport végrehajtására Cserébe több context-et kell tárolni de ezt a GPU vasból megcsinálja nekünk ingyen Így a késleltetést optimális esetben teljesen elrejtjük és maximális áteresztéssel működünk
49 3 késleltetés elrejtése átlapolással
50 3 késleltetés elrejtése átlapolással
51 3 késleltetés elrejtése átlapolással
52 3 késleltetés elrejtése átlapolással; maximális throughput

53 Context-ek tárolása Egy fix méretű területünk van a context-ek tárolására El kell dönteni, hogy ezt hogyan használjuk fel
54 3 átlapolás; sok, kicsi context = maximális latency elfedés

55 3 átlapolás; kevés, nagy context = kicsi latency elfedés
56 Összefoglalva Két egységet különböztethetünk meg tehát: Fizikai magot, ami művetetvégzést végez ( core ) Valahány mag együttesét, amik ugyanahhoz az execution context-hez tartoznak ( functional unit ) A három fő ötlet: Rengeteg, egyszerűsített magot használjunk Ezeket pakoljuk tele ALU-kkal és fussanak mind egy közös utasítás-stream-en A különböző késleltetéseket pedig fedjük el úgy, hogy
57 Architektúrák közelebbről
58 AMD
59
60
61 NVIDIA
62 Nvidia GPUs - Fermi Architecture Instruction Cache GTX Compute 2.0 capability Warp Scheduler Warp Scheduler Dispatch Unit Dispatch Unit Register File x 32bit 15 cores or Streaming Multiprocessors (SMs) LDST LDST Each SM features 32 CUDA processors 480 CUDA processors LDST LDST LDST LDST LDST Global memory with ECC SFU SFU LDST LDST LDST CUDA LDST SFU LDST LDST Dispatch Port Operand Collector Source: NVIDIA s Next Generation CUDA Architecture Whitepaper FP Unit Int Unit Result Queue Perhaad Mistry & Dana Schaa, Northeastern Univ LDST LDST LDST SFU Interconnect Memory L1 Cache / 64kB Shared Memory L2 Cache 62
63 Nvidia GPUs Fermi Architecture SM executes threads in groups of 32 called warps. Instruction Cache Warp Scheduler Warp Scheduler Dispatch Unit Dispatch Unit Two warp issue units per SM Register File x 32bit Concurrent kernel execution Execute multiple kernels simultaneously to improve efficiency LDST LDST LDST LDST LDST LDST LDST SFU CUDA core consists of a single ALU and floating point unit FPU CUDA SFU LDST LDST LDST LDST SFU LDST LDST Dispatch Port Operand Collector Source: NVIDIA s Next Generation CUDA Compute Architecture Whitepaper FP Unit Int Unit Result Queue Perhaad Mistry & Dana Schaa, Northeastern Univ LDST LDST LDST SFU Interconnect Memory L1 Cache / 64kB Shared Memory L2 Cache 63
64 NVIDIA Kepler A teljes Kepler 15 db SMX egységből áll és hat db, 64 bites memóriavezérlőből
65 SMX egység SMX = Streaming Multiprocessor, megnövelt duplapontosságú teljesítménnyel Multiprocesszor: valahány streamprocessor csoportja (Tesla = 8, Fermi = 2x16) Kepler-ben: 192 egyszeres pontosságú CUDA core SFU: special function unit a különleges dolgokhoz (inverse square root, sin, cos, transzcend fv közelítések stb.) Warp: 32 szál
66
67 SIMT Single Instruction, Multiple Thread Step lock-ban mennek az egy csoporthoz tartozó stream processorok, ugyanazt az utasítást hajtják végre, csak más adatokon
68 PowerVR
69 PowerVR Elsősorban mobileszközökhöz, de skálázható eszközök, GPGPU-t is támogatnak (CPU kisegítésére) Universal Scalable Shader Engine mag (és nő) 32x32-es tile-okra osztja a képernyőt Pl.: ipad, iphone, iakármi, Samsung Galaxy S, Tab, Wave I, II... Több infó:
70 Tile alapú rajzolás
71 USSE

72 Tile Accelerator Vágás, vetítés, cull hagyományos szerelőszalagnál a vertex shadert hajtja végre
73 Image Synthesis Processor Tile-onkénti láthatóságvizsgálat (takarás) TSP = Texture and Shading Processor
74 PowerVR SGX Series5XT
75 ARM Mali
76 ARM Mali Nem csak GPU-kat gyártanak és nem csak mobileszközökre Mali 400 MP 1-4 magos Más Mali eszközökkel integrálható Pl.: Samsung Galaxy S2
77 Qualcomm Adreno
78 Qualcomm Adreno Pl.: HTC telefonok (Desire, Evo stb.) Ők is forradalmiak :
79 NVIDIA (megint)
80 Ultra low power GeForce
Haladó Grafika EA. Inkrementális képszintézis GPU-n
 Haladó Grafika EA Inkrementális képszintézis GPU-n Pipeline Az elvégzendő feladatot részfeladatokra bontjuk Mindegyik részfeladatot más-más egység dolgozza fel (ideális esetben) Minden egység inputja,
Haladó Grafika EA Inkrementális képszintézis GPU-n Pipeline Az elvégzendő feladatot részfeladatokra bontjuk Mindegyik részfeladatot más-más egység dolgozza fel (ideális esetben) Minden egység inputja,
GPGPU. Architektúra esettanulmány
 GPGPU Architektúra esettanulmány GeForce 7800 (2006) GeForce 7800 Rengeteg erőforrást fordítottak arra, hogy a throughput-ot maximalizálják Azaz a különböző típusú feldolgozóegységek (vertex és fragment
GPGPU Architektúra esettanulmány GeForce 7800 (2006) GeForce 7800 Rengeteg erőforrást fordítottak arra, hogy a throughput-ot maximalizálják Azaz a különböző típusú feldolgozóegységek (vertex és fragment
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási
 GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
GPGPU alapok. GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai
 GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
Diplomamunka. Miskolci Egyetem. GPGPU technológia kriptográfiai alkalmazása. Készítette: Csikó Richárd VIJFZK mérnök informatikus
 Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
Párhuzamos és Grid rendszerek
 Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
OpenCL - The open standard for parallel programming of heterogeneous systems
 OpenCL - The open standard for parallel programming of heterogeneous systems GPU-k általános számításokhoz GPU Graphics Processing Unit Képalkotás: sok, általában egyszerű és független művelet < 2006:
OpenCL - The open standard for parallel programming of heterogeneous systems GPU-k általános számításokhoz GPU Graphics Processing Unit Képalkotás: sok, általában egyszerű és független művelet < 2006:
Grafikus csővezeték 1 / 44
 Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd.
 1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre
 GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
Nagy adattömbökkel végzett FORRÓ TI BOR tudományos számítások lehetőségei. kisszámítógépes rendszerekben. Kutató Intézet
 Nagy adattömbökkel végzett FORRÓ TI BOR tudományos számítások lehetőségei Kutató Intézet kisszámítógépes rendszerekben Tudományos számításokban gyakran nagy mennyiségű aritmetikai művelet elvégzésére van
Nagy adattömbökkel végzett FORRÓ TI BOR tudományos számítások lehetőségei Kutató Intézet kisszámítógépes rendszerekben Tudományos számításokban gyakran nagy mennyiségű aritmetikai művelet elvégzésére van
Google Summer of Code OpenCL image support for the r600g driver
 Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
Bevitel-Kivitel. Eddig a számítógép agyáról volt szó. Szükség van eszközökre. Processzusok, memória, stb
 Input és Output 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel és kivitel a számitógépből, -be Perifériák 2 Perifériákcsoportosításá,
Input és Output 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel és kivitel a számitógépből, -be Perifériák 2 Perifériákcsoportosításá,
OpenCL Kovács, György
 OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
Heterogén számítási rendszerek
 Heterogén számítási rendszerek GPU-k, GPGPU CUDA, OpenCL Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális koordináta rendszerből
Heterogén számítási rendszerek GPU-k, GPGPU CUDA, OpenCL Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális koordináta rendszerből
Számítógép Architektúrák
 Multiprocesszoros rendszerek Horváth Gábor 2015. május 19. Budapest docens BME Híradástechnikai Tanszék ghorvath@hit.bme.hu Párhuzamosság formái A párhuzamosság milyen formáit ismerjük? Bit szintű párhuzamosság
Multiprocesszoros rendszerek Horváth Gábor 2015. május 19. Budapest docens BME Híradástechnikai Tanszék ghorvath@hit.bme.hu Párhuzamosság formái A párhuzamosság milyen formáit ismerjük? Bit szintű párhuzamosság
Eichhardt Iván GPGPU óra anyagai
 OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos programozás elméleti
OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos programozás elméleti
Memóriák - tárak. Memória. Kapacitás Ár. Sebesség. Háttértár. (felejtő) (nem felejtő)
 (nem felejtő)") Memóriák (felejtő) Memória Kapacitás Ár Sebesség Memóriák - tárak Háttértár (nem felejtő) Memória Vezérlő egység Központi memória Aritmetikai Logikai Egység (ALU) Regiszterek Programok Adatok Ez nélkül
Memóriák (felejtő) Memória Kapacitás Ár Sebesség Memóriák - tárak Háttértár (nem felejtő) Memória Vezérlő egység Központi memória Aritmetikai Logikai Egység (ALU) Regiszterek Programok Adatok Ez nélkül
OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA
 Multidiszciplináris tudományok, 3. kötet. (2013) sz. pp. 259-268. OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA Mileff Péter Adjunktus, Miskolci Egyetem, Informatikai Intézet, Általános
Multidiszciplináris tudományok, 3. kötet. (2013) sz. pp. 259-268. OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA Mileff Péter Adjunktus, Miskolci Egyetem, Informatikai Intézet, Általános
Eichhardt Iván GPGPU óra anyagai
 OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos tervezési minták
OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos tervezési minták
Grafikus processzorok általános célú programozása (GPGPU)
") 2015. szeptember 17. Grafikus processzorok általános célú programozása (GPGPU) Eichhardt I., Hajder L. és V. Gábor eichhardt.ivan@sztaki.mta.hu, hajder.levente@sztaki.mta.hu, valasek@inf.elte.hu Eötvös
2015. szeptember 17. Grafikus processzorok általános célú programozása (GPGPU) Eichhardt I., Hajder L. és V. Gábor eichhardt.ivan@sztaki.mta.hu, hajder.levente@sztaki.mta.hu, valasek@inf.elte.hu Eötvös
8. Fejezet Processzor (CPU) és memória: tervezés, implementáció, modern megoldások
 és memória: tervezés, implementáció, modern megoldások") 8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
2. Generáció (1999-2000) 3. Generáció (2001) NVIDIA TNT2, ATI Rage, 3dfx Voodoo3. Klár Gergely tremere@elte.hu
 3. Generáció (2001) NVIDIA TNT2, ATI Rage, 3dfx Voodoo3. Klár Gergely tremere@elte.hu") 1. Generáció Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. őszi félév NVIDIA TNT2, ATI Rage, 3dfx Voodoo3 A standard 2d-s videokártyák kiegészítése
1. Generáció Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. őszi félév NVIDIA TNT2, ATI Rage, 3dfx Voodoo3 A standard 2d-s videokártyák kiegészítése
FIR SZŰRŐK TELJESÍTMÉNYÉNEK JAVÍTÁSA C/C++-BAN
 Multidiszciplináris tudományok, 4. kötet. (2014) 1. sz. pp. 31-38. FIR SZŰRŐK TELJESÍTMÉNYÉNEK JAVÍTÁSA C/C++-BAN Lajos Sándor Mérnöktanár, Miskolci Egyetem, Matematikai Intézet, Ábrázoló Geometriai Intézeti
Multidiszciplináris tudományok, 4. kötet. (2014) 1. sz. pp. 31-38. FIR SZŰRŐK TELJESÍTMÉNYÉNEK JAVÍTÁSA C/C++-BAN Lajos Sándor Mérnöktanár, Miskolci Egyetem, Matematikai Intézet, Ábrázoló Geometriai Intézeti
VLIW processzorok (Működési elvük, jellemzőik, előnyeik, hátrányaik, kereskedelmi rendszerek)
") SzA35. VLIW processzorok (Működési elvük, jellemzőik, előnyeik, hátrányaik, kereskedelmi rendszerek) Működési elvük: Jellemzőik: -függőségek kezelése statikusan, compiler által -hátránya: a compiler erősen
SzA35. VLIW processzorok (Működési elvük, jellemzőik, előnyeik, hátrányaik, kereskedelmi rendszerek) Működési elvük: Jellemzőik: -függőségek kezelése statikusan, compiler által -hátránya: a compiler erősen
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai Gyakorlat: SSE utasításkészlet Szántó Péter BME MIT, FPGA Laboratórium Vektorizáció Inline assembly Minden fordító támogatja (kivéve VS x64
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai Gyakorlat: SSE utasításkészlet Szántó Péter BME MIT, FPGA Laboratórium Vektorizáció Inline assembly Minden fordító támogatja (kivéve VS x64
8. Fejezet Processzor (CPU) és memória: tervezés, implementáció, modern megoldások
 és memória: tervezés, implementáció, modern megoldások") 8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
ARM processzorok felépítése
 ARM processzorok felépítése Az ARM processzorok több családra bontható közösséget alkotnak. Az Cortex-A sorozatú processzorok, ill. az azokból felépülő mikrokontrollerek a high-end kategóriájú, nagy teljesítményű
ARM processzorok felépítése Az ARM processzorok több családra bontható közösséget alkotnak. Az Cortex-A sorozatú processzorok, ill. az azokból felépülő mikrokontrollerek a high-end kategóriájú, nagy teljesítményű
Négyprocesszoros közvetlen csatolású szerverek architektúrája:
 SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
Számítógép architektúrák I. Várady Géza varadygeza@pmmik.pte.hu
 Számítógép architektúrák I. Várady Géza varadygeza@pmmik.pte.hu 1 Bevezetés - fogalmak Informatika sokrétű Információk Szerzése Feldolgozása Tárolása Továbbítása Információtechnika Informatika a technikai
Számítógép architektúrák I. Várady Géza varadygeza@pmmik.pte.hu 1 Bevezetés - fogalmak Informatika sokrétű Információk Szerzése Feldolgozása Tárolása Továbbítása Információtechnika Informatika a technikai
Számítógépek felépítése, alapfogalmak
 2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd SZE MTK MSZT lovas.szilard@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? Nem reprezentatív felmérés kinek van
2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd SZE MTK MSZT lovas.szilard@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? Nem reprezentatív felmérés kinek van
GPGPU programozás lehetőségei. Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café
 GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15 Fehér
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15 Fehér
ARM Cortex magú mikrovezérlők
 ARM Cortex magú mikrovezérlők 3. Cortex-M0, M4, M7 Scherer Balázs Budapest University of Technology and Economics Department of Measurement and Information Systems BME-MIT 2018 32 bites trendek 2003-2017
ARM Cortex magú mikrovezérlők 3. Cortex-M0, M4, M7 Scherer Balázs Budapest University of Technology and Economics Department of Measurement and Information Systems BME-MIT 2018 32 bites trendek 2003-2017
Magas szintű optimalizálás
 Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
Videókártya - CUDA kompatibilitás: CUDA weboldal: Példaterületek:
 Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
Grafikus kártyák, mint olcsó szuperszámítógépek - I.
 (1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport (2) Vázlat I. Motiváció Beüzemelés C alapok CUDA programozási modell,
(1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport (2) Vázlat I. Motiváció Beüzemelés C alapok CUDA programozási modell,
Számítógépek felépítése
 Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Grafika programozása
 MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Grafika programozása Tárgyi jegyzet (béta változat) KÉSZÍTETTE: DR. MILEFF PÉTER Miskolci Egyetem Általános Informatikai Tanszék 2015. Tartalomjegyzék
MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Grafika programozása Tárgyi jegyzet (béta változat) KÉSZÍTETTE: DR. MILEFF PÉTER Miskolci Egyetem Általános Informatikai Tanszék 2015. Tartalomjegyzék
A CUDA előnyei: - Elszórt memória olvasás (az adatok a memória bármely területéről olvashatóak) PC-Vilag.hu CUDA, a jövő technológiája?!
 PC-Vilag.hu CUDA, a jövő technológiája?!") A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
Grafikus csővezeték 2 / 77
 Bevezetés 1 / 77 Grafikus csővezeték 2 / 77 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve
Bevezetés 1 / 77 Grafikus csővezeték 2 / 77 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA. Dr. Szénási Sándor
 KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15 Fehér
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15 Fehér
SAT probléma kielégíthetőségének vizsgálata. masszív parallel. mesterséges neurális hálózat alkalmazásával
 SAT probléma kielégíthetőségének vizsgálata masszív parallel mesterséges neurális hálózat alkalmazásával Tajti Tibor, Bíró Csaba, Kusper Gábor {gkusper, birocs, tajti}@aries.ektf.hu Eszterházy Károly Főiskola
SAT probléma kielégíthetőségének vizsgálata masszív parallel mesterséges neurális hálózat alkalmazásával Tajti Tibor, Bíró Csaba, Kusper Gábor {gkusper, birocs, tajti}@aries.ektf.hu Eszterházy Károly Főiskola
Dr. Illés Zoltán zoltan.illes@elte.hu
 Dr. Illés Zoltán zoltan.illes@elte.hu Operációs rendszerek kialakulása Op. Rendszer fogalmak, struktúrák Fájlok, könyvtárak, fájlrendszerek Folyamatok Folyamatok kommunikációja Kritikus szekciók, szemaforok.
Dr. Illés Zoltán zoltan.illes@elte.hu Operációs rendszerek kialakulása Op. Rendszer fogalmak, struktúrák Fájlok, könyvtárak, fájlrendszerek Folyamatok Folyamatok kommunikációja Kritikus szekciók, szemaforok.
Digitális Technika I. (VEMIVI1112D)
") Pannon Egyetem Villamosmérnöki és Inf. Rendszerek Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vassányi István vassanyi@almos.vein.hu Feltételek:
Pannon Egyetem Villamosmérnöki és Inf. Rendszerek Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vassányi István vassanyi@almos.vein.hu Feltételek:
Információ megjelenítés Számítógépes ábrázolás. Dr. Iványi Péter
 Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter (adat szerkezet) float x,y,z,w; float r,g,b,a; } vertex; glcolor3f(0, 0.5, 0); glvertex2i(11, 31); glvertex2i(37, 71); glcolor3f(0.5, 0,
Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter (adat szerkezet) float x,y,z,w; float r,g,b,a; } vertex; glcolor3f(0, 0.5, 0); glvertex2i(11, 31); glvertex2i(37, 71); glcolor3f(0.5, 0,
Az INTEL mikroprocesszorok architekturális fejlődésének bemutatása
 MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Automatizálási és Kommunikáció-technológiai Tanszék Az INTEL mikroprocesszorok architekturális SZAKDOLGOZAT Majoros Péter FAXCI3 3530 Miskolc, Rákóczi
MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Automatizálási és Kommunikáció-technológiai Tanszék Az INTEL mikroprocesszorok architekturális SZAKDOLGOZAT Majoros Péter FAXCI3 3530 Miskolc, Rákóczi
Riak. Pronounced REE-ahk. Elosztott adattároló eszköz. Molnár Péter molnarp@ilab.sztaki.hu
 Riak Pronounced REE-ahk Elosztott adattároló eszköz Molnár Péter molnarp@ilab.sztaki.hu Mi a Riak? A Database A Data Store A key/value store A NoSQL database Schemaless and data-type agnostic Written (primarily)
Riak Pronounced REE-ahk Elosztott adattároló eszköz Molnár Péter molnarp@ilab.sztaki.hu Mi a Riak? A Database A Data Store A key/value store A NoSQL database Schemaless and data-type agnostic Written (primarily)
Számítógép Architektúrák
 Számítógép Architektúrák Utasításkészlet architektúrák 2015. április 11. Budapest Horváth Gábor docens BME Hálózati Rendszerek és Szolgáltatások Tsz. ghorvath@hit.bme.hu Számítógép Architektúrák Horváth
Számítógép Architektúrák Utasításkészlet architektúrák 2015. április 11. Budapest Horváth Gábor docens BME Hálózati Rendszerek és Szolgáltatások Tsz. ghorvath@hit.bme.hu Számítógép Architektúrák Horváth
Operációs rendszerek MINB240. Bevitel-Kivitel. 6. előadás Input és Output. Perifériák csoportosításá, használat szerint
 Operációs rendszerek MINB240 6. előadás Input és Output Operációs rendszerek MINB240 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel
Operációs rendszerek MINB240 6. előadás Input és Output Operációs rendszerek MINB240 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel
Számítógép architektúrák
 Számítógép architektúrák Számítógépek felépítése Digitális adatábrázolás Digitális logikai szint Mikroarchitektúra szint Gépi utasítás szint Operációs rendszer szint Assembly nyelvi szint Probléma orientált
Számítógép architektúrák Számítógépek felépítése Digitális adatábrázolás Digitális logikai szint Mikroarchitektúra szint Gépi utasítás szint Operációs rendszer szint Assembly nyelvi szint Probléma orientált
Digitális Technika I. (VEMIVI1112D)
") Pannon Egyetem Villamosmérnöki és Inf. Rendszerek Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vassányi István vassanyi@almos.vein.hu Feltételek:
Pannon Egyetem Villamosmérnöki és Inf. Rendszerek Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vassányi István vassanyi@almos.vein.hu Feltételek:
HLSL programozás. Grafikus játékok fejlesztése Szécsi László t06-hlsl
 HLSL programozás Grafikus játékok fejlesztése Szécsi László 2013.02.16. t06-hlsl RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
HLSL programozás Grafikus játékok fejlesztése Szécsi László 2013.02.16. t06-hlsl RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
CUDA alapok CUDA projektek. CUDA bemutató. Adatbányászat és Webes Keresés Kutatócsoport SZTAKI
 SZTAKI 2010 Tartalom 1 2 Tartalom 1 2 GPU-k és a CUDA El zmények grakus kártyák: nagy párhuzamos számítási kapacitás eredetileg csak grakus m veleteket tudtak végezni GPU-k és a CUDA El zmények grakus
SZTAKI 2010 Tartalom 1 2 Tartalom 1 2 GPU-k és a CUDA El zmények grakus kártyák: nagy párhuzamos számítási kapacitás eredetileg csak grakus m veleteket tudtak végezni GPU-k és a CUDA El zmények grakus
SZÁMÍTÓGÉPES ARCHITEKTÚRÁK
 Misák Sándor SZÁMÍTÓGÉPES ARCHITEKTÚRÁK Nanoelektronikai és Nanotechnológiai Részleg DE TTK v.0.1 (2007.02.13.) 2. előadás A STRUKTURÁLT SZÁMÍTÓGÉP-FELÉPÍTÉS 2. előadás 1. Nyelvek, szintek és virtuális
Misák Sándor SZÁMÍTÓGÉPES ARCHITEKTÚRÁK Nanoelektronikai és Nanotechnológiai Részleg DE TTK v.0.1 (2007.02.13.) 2. előadás A STRUKTURÁLT SZÁMÍTÓGÉP-FELÉPÍTÉS 2. előadás 1. Nyelvek, szintek és virtuális
Bentley új generációs alkalmazásai: ContextCapture, LumenRt és Connect Edition. L - Tér Informatika Kft.
 Bentley új generációs alkalmazásai: ContextCapture, LumenRt és Connect Edition L - Tér Informatika Kft. Bentley alkalmazások műszaki folyamatokban Állapot átvétele Tervezett objektumok illesztése meglévő
Bentley új generációs alkalmazásai: ContextCapture, LumenRt és Connect Edition L - Tér Informatika Kft. Bentley alkalmazások műszaki folyamatokban Állapot átvétele Tervezett objektumok illesztése meglévő
Számítógép Architektúrák I-II-III.
 Kidolgozott államvizsgatételek Számítógép Architektúrák I-II-III. tárgyakhoz 2010. június A sikeres államvizsgához kizárólag ennek a dokumentumnak az ismerete nem elégséges, a témaköröket a Számítógép
Kidolgozott államvizsgatételek Számítógép Architektúrák I-II-III. tárgyakhoz 2010. június A sikeres államvizsgához kizárólag ennek a dokumentumnak az ismerete nem elégséges, a témaköröket a Számítógép
SZÁMÍTÓGÉPES ARCHITEKTÚRÁK A STRUKTURÁLT SZÁMÍTÓGÉP-FELÉPÍTÉS. Misák Sándor. 2. előadás DE TTK
 Misák Sándor SZÁMÍTÓGÉPES ARCHITEKTÚRÁK Nanoelektronikai és Nanotechnológiai Részleg 2. előadás A STRUKTURÁLT SZÁMÍTÓGÉP-FELÉPÍTÉS DE TTK v.0.1 (2007.02.13.) 2. előadás 1. Nyelvek, szintek és virtuális
Misák Sándor SZÁMÍTÓGÉPES ARCHITEKTÚRÁK Nanoelektronikai és Nanotechnológiai Részleg 2. előadás A STRUKTURÁLT SZÁMÍTÓGÉP-FELÉPÍTÉS DE TTK v.0.1 (2007.02.13.) 2. előadás 1. Nyelvek, szintek és virtuális
GPGPU és számítások heterogén rendszereken
 GPGPU és számítások heterogén rendszereken Eichhardt Iván eichhardt.ivan@sztaki.mta.hu ELTE-s GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ Gyors bevezetés a Párhuzamosságról OpenCL API Gyakorlati példák
GPGPU és számítások heterogén rendszereken Eichhardt Iván eichhardt.ivan@sztaki.mta.hu ELTE-s GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ Gyors bevezetés a Párhuzamosságról OpenCL API Gyakorlati példák
Klár Gergely 2010/2011. tavaszi félév
 Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. tavaszi félév Tartalom Generációk Shader Model 3.0 (és korábban) Shader Model 4.0 Shader Model
Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. tavaszi félév Tartalom Generációk Shader Model 3.0 (és korábban) Shader Model 4.0 Shader Model
GPU Lab. 14. fejezet. OpenCL textúra használat. Grafikus Processzorok Tudományos Célú Programozása. Berényi Dániel Nagy-Egri Máté Ferenc
 14. fejezet OpenCL textúra használat Grafikus Processzorok Tudományos Célú Programozása Textúrák A textúrák 1, 2, vagy 3D-s tömbök kifejezetten szín információk tárolására Főbb különbségek a bufferekhez
14. fejezet OpenCL textúra használat Grafikus Processzorok Tudományos Célú Programozása Textúrák A textúrák 1, 2, vagy 3D-s tömbök kifejezetten szín információk tárolására Főbb különbségek a bufferekhez
OpenGL Compute Shader-ek. Valasek Gábor
 OpenGL Compute Shader-ek Valasek Gábor Compute shader OpenGL 4.3 óta része a Core specifikációnak Speciális shaderek, amikben a szokásos GLSL parancsok (és néhány új) segítségével általános számítási feladatokat
OpenGL Compute Shader-ek Valasek Gábor Compute shader OpenGL 4.3 óta része a Core specifikációnak Speciális shaderek, amikben a szokásos GLSL parancsok (és néhány új) segítségével általános számítási feladatokat
Információ megjelenítés Számítógépes ábrázolás. Dr. Iványi Péter
 Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter Raszterizáció OpenGL Mely pixelek vannak a primitíven belül fragment generálása minden ilyen pixelre Attribútumok (pl., szín) hozzárendelése
Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter Raszterizáció OpenGL Mely pixelek vannak a primitíven belül fragment generálása minden ilyen pixelre Attribútumok (pl., szín) hozzárendelése
Heterogén számítási rendszerek gyakorlatok (2017.)
") Heterogén számítási rendszerek gyakorlatok (2017.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 6 2.1 Global
Heterogén számítási rendszerek gyakorlatok (2017.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 6 2.1 Global
1. Az utasítás beolvasása a processzorba
 A MIKROPROCESSZOR A mikroprocesszor olyan nagy bonyolultságú félvezető eszköz, amely a digitális számítógép központi egységének a feladatait végzi el. Dekódolja az uatasításokat, vezérli a műveletek elvégzéséhez
A MIKROPROCESSZOR A mikroprocesszor olyan nagy bonyolultságú félvezető eszköz, amely a digitális számítógép központi egységének a feladatait végzi el. Dekódolja az uatasításokat, vezérli a műveletek elvégzéséhez
Plakátok, részecskerendszerek. Szécsi László
 Plakátok, részecskerendszerek Szécsi László Képalapú festés Montázs: képet képekből 2D grafika jellemző eszköze modell: kép [sprite] 3D 2D képével helyettesítsük a komplex geometriát Image-based rendering
Plakátok, részecskerendszerek Szécsi László Képalapú festés Montázs: képet képekből 2D grafika jellemző eszköze modell: kép [sprite] 3D 2D képével helyettesítsük a komplex geometriát Image-based rendering
Árnyalás, env mapping. Szécsi László 3D Grafikus Rendszerek 3. labor
 Árnyalás, env mapping Szécsi László 3D Grafikus Rendszerek 3. labor Egyszerű árnyaló FS legyen egy fényirány-vektor normálvektor és fényirány közötti szög koszinusza az irradiancia textúrából olvasott
Árnyalás, env mapping Szécsi László 3D Grafikus Rendszerek 3. labor Egyszerű árnyaló FS legyen egy fényirány-vektor normálvektor és fényirány közötti szög koszinusza az irradiancia textúrából olvasott
2D képszintézis. Szirmay-Kalos László
 2D képszintézis Szirmay-Kalos László 2D képszintézis Modell szín (200, 200) Kép Kamera ablak (window) viewport Unit=pixel Saját színnel rajzolás Világ koordinátarendszer Pixel vezérelt megközelítés: Tartalmazás
2D képszintézis Szirmay-Kalos László 2D képszintézis Modell szín (200, 200) Kép Kamera ablak (window) viewport Unit=pixel Saját színnel rajzolás Világ koordinátarendszer Pixel vezérelt megközelítés: Tartalmazás
A mai program OPERÁCIÓS RENDSZEREK. A probléma. Fogalmak. Mit várunk el? Tágítjuk a problémát: ütemezési szintek
 A mai program OPERÁCIÓS RENDSZEREK A CPU ütemezéshez fogalmak, alapok, stratégiák Id kiosztási algoritmusok VAX/VMS, NT, Unix id kiosztás A Context Switch implementáció Ütemezés és a Context Switch Operációs
A mai program OPERÁCIÓS RENDSZEREK A CPU ütemezéshez fogalmak, alapok, stratégiák Id kiosztási algoritmusok VAX/VMS, NT, Unix id kiosztás A Context Switch implementáció Ütemezés és a Context Switch Operációs
Adatfolyam alapú RACER tömbprocesszor és algoritmus implementációs módszerek valamint azok alkalmazásai parallel, heterogén számítási architektúrákra
 Adatfolyam alapú RACER tömbprocesszor és algoritmus implementációs módszerek valamint azok alkalmazásai parallel, heterogén számítási architektúrákra Témavezet : Dr. Cserey György 2014 szeptember 22. Kit
Adatfolyam alapú RACER tömbprocesszor és algoritmus implementációs módszerek valamint azok alkalmazásai parallel, heterogén számítási architektúrákra Témavezet : Dr. Cserey György 2014 szeptember 22. Kit
Ez egy program. De ki tudja végrehajtani?
 Császármorzsa Keverj össze 25 dkg grízt 1 mokkás kanál sóval, 4 evőkanál cukorral és egy csomag vaníliás cukorral! Adj hozzá két evőkanál olajat és két tojást, jól dolgozd el! Folyamatos keverés közben
Császármorzsa Keverj össze 25 dkg grízt 1 mokkás kanál sóval, 4 evőkanál cukorral és egy csomag vaníliás cukorral! Adj hozzá két evőkanál olajat és két tojást, jól dolgozd el! Folyamatos keverés közben
A mikroszámítógép felépítése.
 1. Processzoros rendszerek fő elemei mikroszámítógépek alapja a mikroprocesszor. Elemei a mikroprocesszor, memória, és input/output eszközök. komponenseket valamilyen buszrendszer köti össze, amelyen az
1. Processzoros rendszerek fő elemei mikroszámítógépek alapja a mikroprocesszor. Elemei a mikroprocesszor, memória, és input/output eszközök. komponenseket valamilyen buszrendszer köti össze, amelyen az
Amazon Web Services. Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28.
 Amazon Web Services Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28. Ez nem egy könyváruház? 1994-ben alapította Jeff Bezos Túlélte a dot-com korszakot Eredetileg könyváruház majd az elérhető
Amazon Web Services Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28. Ez nem egy könyváruház? 1994-ben alapította Jeff Bezos Túlélte a dot-com korszakot Eredetileg könyváruház majd az elérhető
2. Gyakorlat Khoros Cantata
 2. Gyakorlat Khoros Cantata Ismerkedés a Khoros Cantata-val: A Khoros Cantata egy képfeldolgozó műveletsorok készítésére szolgáló program. A műveleteket csővezetékszerűen lehet egymás után kötni. A műveleteket
2. Gyakorlat Khoros Cantata Ismerkedés a Khoros Cantata-val: A Khoros Cantata egy képfeldolgozó műveletsorok készítésére szolgáló program. A műveleteket csővezetékszerűen lehet egymás után kötni. A műveleteket
Processzus. Operációs rendszerek MINB240. Memória gazdálkodás. Operációs rendszer néhány célja. 5-6-7. előadás Memóriakezelés
 Processzus Operációs rendszerek MINB40 5-6-7. előadás Memóriakezelés Egy vagy több futtatható szál Futáshoz szükséges erőforrások Memória (RAM) Program kód (text) Adat (data) Különböző bufferek Egyéb Fájlok,
Processzus Operációs rendszerek MINB40 5-6-7. előadás Memóriakezelés Egy vagy több futtatható szál Futáshoz szükséges erőforrások Memória (RAM) Program kód (text) Adat (data) Különböző bufferek Egyéb Fájlok,
Ami az Intel szerint is konvergens architektúra
 Copyright 2012, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners Ami az Intel szerint is konvergens architektúra Gacsal József Business Development
Copyright 2012, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners Ami az Intel szerint is konvergens architektúra Gacsal József Business Development
Analitikai megoldások IBM Power és FlashSystem alapokon. Mosolygó Ferenc - Avnet
 Analitikai megoldások IBM Power és FlashSystem alapokon Mosolygó Ferenc - Avnet Bevezető Legfontosabb elvárásaink az adatbázisokkal szemben Teljesítmény Lekérdezések, riportok és válaszok gyors megjelenítése
Analitikai megoldások IBM Power és FlashSystem alapokon Mosolygó Ferenc - Avnet Bevezető Legfontosabb elvárásaink az adatbázisokkal szemben Teljesítmény Lekérdezések, riportok és válaszok gyors megjelenítése
Budapesti Műszaki- és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar MIT. Nagyteljesítményű mikrovezérlők tantárgy [vimim342]
![Budapesti Műszaki- és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar MIT. Nagyteljesítményű mikrovezérlők tantárgy [vimim342]](/thumbs/39/18932349.jpg "Budapesti Műszaki- és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar MIT. Nagyteljesítményű mikrovezérlők tantárgy [vimim342]") Budapesti Műszaki- és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar MIT Nagyteljesítményű mikrovezérlők tantárgy [vimim342] 8x8x8 LED Cube Készítette: Szikra István URLJRN Tartalomjegyzék
Budapesti Műszaki- és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar MIT Nagyteljesítményű mikrovezérlők tantárgy [vimim342] 8x8x8 LED Cube Készítette: Szikra István URLJRN Tartalomjegyzék
Főbb jellemzők INTELLIO VIDEO SYSTEM 2 ADATLAP
 IVS2 videomenedzsment-szoftver Főbb jellemzők Munkaállomásonként 2 30 kamera monitorozása Szoftverkulcsos és hardverkulcsos működés Intelligens mozgás- és objektumkeresés DPTZ gyors felismerhetőség Microsoft
IVS2 videomenedzsment-szoftver Főbb jellemzők Munkaállomásonként 2 30 kamera monitorozása Szoftverkulcsos és hardverkulcsos működés Intelligens mozgás- és objektumkeresés DPTZ gyors felismerhetőség Microsoft
Máté: Számítógép architektúrák
 Sín műveletek z eddigiek közönséges műveletek voltak. lokkos átvitel (3.4. ábra): kezdő címen kívül az adatre kell tenni a mozgatandó adatok számát. Esetleges várakozó ciklusok után ciklusonként egy adat
Sín műveletek z eddigiek közönséges műveletek voltak. lokkos átvitel (3.4. ábra): kezdő címen kívül az adatre kell tenni a mozgatandó adatok számát. Esetleges várakozó ciklusok után ciklusonként egy adat
Heterogén számítási rendszerek
 Heterogén számítási rendszerek Gyakorlat: SSE utasításkészlet Szántó Péter BME MIT, FPGA Laboratórium SIMD Single Instruction Multiple Data m1 = f1 f2 f3 f4 + + + + + m2 = f5 f6 f7 f8 = = = = = m1+m2 =
Heterogén számítási rendszerek Gyakorlat: SSE utasításkészlet Szántó Péter BME MIT, FPGA Laboratórium SIMD Single Instruction Multiple Data m1 = f1 f2 f3 f4 + + + + + m2 = f5 f6 f7 f8 = = = = = m1+m2 =
Számítógép Architektúrák
 Cache memória Horváth Gábor 2016. március 30. Budapest docens BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu Már megint a memória... Mindenről a memória tehet. Mert lassú. A virtuális
Cache memória Horváth Gábor 2016. március 30. Budapest docens BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu Már megint a memória... Mindenről a memória tehet. Mert lassú. A virtuális
5-6. ea Created by mrjrm & Pogácsa, frissítette: Félix
 2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN
 KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
PÁRHUZAMOS SZÁMÍTÁSTECHNIKA MODUL AZ ÚJ TECHNOLÓGIÁKHOZ KAPCSOLÓDÓ MEGKÖZELÍTÉSBEN
 PÁRHUZAMOS SZÁMÍTÁSTECHNIKA MODUL AZ ÚJ TECHNOLÓGIÁKHOZ KAPCSOLÓDÓ MEGKÖZELÍTÉSBEN PARALLEL COMPUTING MODULE BASED ON THE NEW TECHNOLOGIES Vámossy Zoltán 1, Sima Dezső 2, Szénási Sándor 3, Rövid András
PÁRHUZAMOS SZÁMÍTÁSTECHNIKA MODUL AZ ÚJ TECHNOLÓGIÁKHOZ KAPCSOLÓDÓ MEGKÖZELÍTÉSBEN PARALLEL COMPUTING MODULE BASED ON THE NEW TECHNOLOGIES Vámossy Zoltán 1, Sima Dezső 2, Szénási Sándor 3, Rövid András
Bevezetés az informatikába
 Bevezetés az informatikába 3. előadás Dr. Istenes Zoltán Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék Matematikus BSc - I. félév / 2008 / Budapest Dr.
Bevezetés az informatikába 3. előadás Dr. Istenes Zoltán Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék Matematikus BSc - I. félév / 2008 / Budapest Dr.
Digitális Technika I. (VEMIVI1112D)
") Pannon Egyetem Villamosmérnöki és Információs Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vörösházi Zsolt voroshazi@vision.vein.hu Feltételek:
Pannon Egyetem Villamosmérnöki és Információs Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vörösházi Zsolt voroshazi@vision.vein.hu Feltételek:
14.2. OpenGL 3D: Mozgás a modellben
 14. Fotórealisztikus megjelenítés 1019 14.2. OpenGL 3D: Mozgás a modellben A program az OpenGL technika alkalmazásával gyors lehetőséget biztosít a modellben való mozgásra. A mozgás mellett lehetőség van
14. Fotórealisztikus megjelenítés 1019 14.2. OpenGL 3D: Mozgás a modellben A program az OpenGL technika alkalmazásával gyors lehetőséget biztosít a modellben való mozgásra. A mozgás mellett lehetőség van
KISKER AKCIÓS ÁRLISTA
 KISKER AKCIÓS ÁRLISTA 2015. február 1-tıl visszavonásig, illetve a készlet erejéig érvényes Készülékek** Alcatel OT-2004 C Készülékbiztosítás *3 Alcatel OT-2004C/SL 2G Dualband telefon + akkumulátor +
KISKER AKCIÓS ÁRLISTA 2015. február 1-tıl visszavonásig, illetve a készlet erejéig érvényes Készülékek** Alcatel OT-2004 C Készülékbiztosítás *3 Alcatel OT-2004C/SL 2G Dualband telefon + akkumulátor +
D3D, DXUT primer. Grafikus játékok fejlesztése Szécsi László t01-system
 D3D, DXUT primer Grafikus játékok fejlesztése Szécsi László 2013.02.13. t01-system Háromszögháló reprezentáció Mesh Vertex buffer Index buffer Vertex buffer csúcs-rekordok tömbje pos normal tex pos normal
D3D, DXUT primer Grafikus játékok fejlesztése Szécsi László 2013.02.13. t01-system Háromszögháló reprezentáció Mesh Vertex buffer Index buffer Vertex buffer csúcs-rekordok tömbje pos normal tex pos normal
Virtualizációs Technológiák Bevezetés Kovács Ákos Forrás, BME-VIK Virtualizációs technológiák https://www.vik.bme.hu/kepzes/targyak/vimiav89/
 Virtualizációs Technológiák Bevezetés Kovács Ákos Forrás, BME-VIK Virtualizációs technológiák https://www.vik.bme.hu/kepzes/targyak/vimiav89/ Mi is az a Virtualizáció? Az erőforrások elvonatkoztatása az
Virtualizációs Technológiák Bevezetés Kovács Ákos Forrás, BME-VIK Virtualizációs technológiák https://www.vik.bme.hu/kepzes/targyak/vimiav89/ Mi is az a Virtualizáció? Az erőforrások elvonatkoztatása az
Operációs rendszerek Memóriakezelés 1.1
 Operációs rendszerek Memóriakezelés 1.1 Pere László (pipas@linux.pte.hu) PÉCSI TUDOMÁNYEGYETEM TERMÉSZETTUDOMÁNYI KAR INFORMATIKA ÉS ÁLTALÁNOS TECHNIKA TANSZÉK Operációs rendszerek p. A memóriakezelő A
Operációs rendszerek Memóriakezelés 1.1 Pere László (pipas@linux.pte.hu) PÉCSI TUDOMÁNYEGYETEM TERMÉSZETTUDOMÁNYI KAR INFORMATIKA ÉS ÁLTALÁNOS TECHNIKA TANSZÉK Operációs rendszerek p. A memóriakezelő A
A számítógépes grafika inkrementális képszintézis algoritmusának hardver realizációja Teljesítménykövetelmények:
 Beveetés A sámítógépes grafika inkrementális képsintéis algoritmusának hardver realiációja Teljesítménykövetelmények: Animáció: néhány nsec/ képpont Massívan párhuamos Pipeline(stream processor) Párhuamos
Beveetés A sámítógépes grafika inkrementális képsintéis algoritmusának hardver realiációja Teljesítménykövetelmények: Animáció: néhány nsec/ képpont Massívan párhuamos Pipeline(stream processor) Párhuamos
LowPrice
 LowPrice 2012-2013 1 Under 7 Termék típusa Tablet PC Képernyő méret 7 " Operációs rendszer Támogatott rendszer Android 2.2 operációs rendszer A Windows XP/2000/98SE/ME Processzor típusa / CPU Cortex A9
LowPrice 2012-2013 1 Under 7 Termék típusa Tablet PC Képernyő méret 7 " Operációs rendszer Támogatott rendszer Android 2.2 operációs rendszer A Windows XP/2000/98SE/ME Processzor típusa / CPU Cortex A9
A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem)
") 65-67 A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem) Két fő része: a vezérlőegység, ami a memóriában tárolt program dekódolását és végrehajtását végzi, az
65-67 A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem) Két fő része: a vezérlőegység, ami a memóriában tárolt program dekódolását és végrehajtását végzi, az
OPERÁCIÓS RENDSZEREK 1. ÁTIRÁNYÍTÁSOK, SZŰRŐK
 OPERÁCIÓS RENDSZEREK 1. ÁTIRÁNYÍTÁSOK, SZŰRŐK ÁTIRÁNYÍTÁSOK KIMENET ÁTIRÁNYÍTÁSA A standard output > >> 1> root@ns:/var/tmp# date > datum.txt root@ns:/var/tmp# cat datum.txt 2016. márc. 2., szerda, 07.18.50
OPERÁCIÓS RENDSZEREK 1. ÁTIRÁNYÍTÁSOK, SZŰRŐK ÁTIRÁNYÍTÁSOK KIMENET ÁTIRÁNYÍTÁSA A standard output > >> 1> root@ns:/var/tmp# date > datum.txt root@ns:/var/tmp# cat datum.txt 2016. márc. 2., szerda, 07.18.50
Design and Implementation of High-Performance Computing Algorithms for Wireless MIMO Communications. Supervisors
 Design and Implementation of High-Performance Computing Algorithms for Wireless MIMO Communications Thesis submitted for the degree of Doctor of Philosophy Csaba Máté Józsa, M.Sc. Supervisors Géza Kolumbán,
Design and Implementation of High-Performance Computing Algorithms for Wireless MIMO Communications Thesis submitted for the degree of Doctor of Philosophy Csaba Máté Józsa, M.Sc. Supervisors Géza Kolumbán,