Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés
|
|
|
- Albert Vass
- 10 évvel ezelőtt
- Látták:
Átírás

1 Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés 4. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton



2 Logók és támogatás A tananyag a TÁMOP /1/A számú Kelet-magyarországi Informatika Tananyag Tárház projekt keretében készült. A tananyagfejlesztés az Európai Unió támogatásával és az Európai Szociális Alap társfinanszírozásával valósult meg.

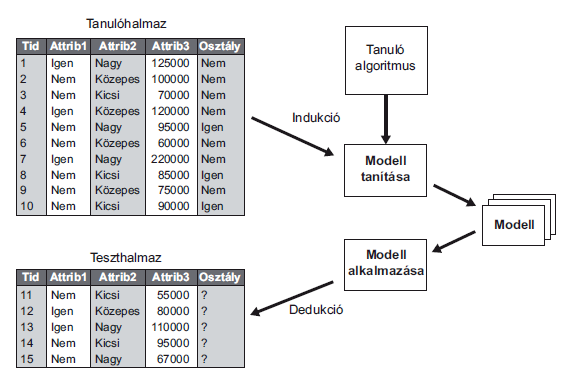
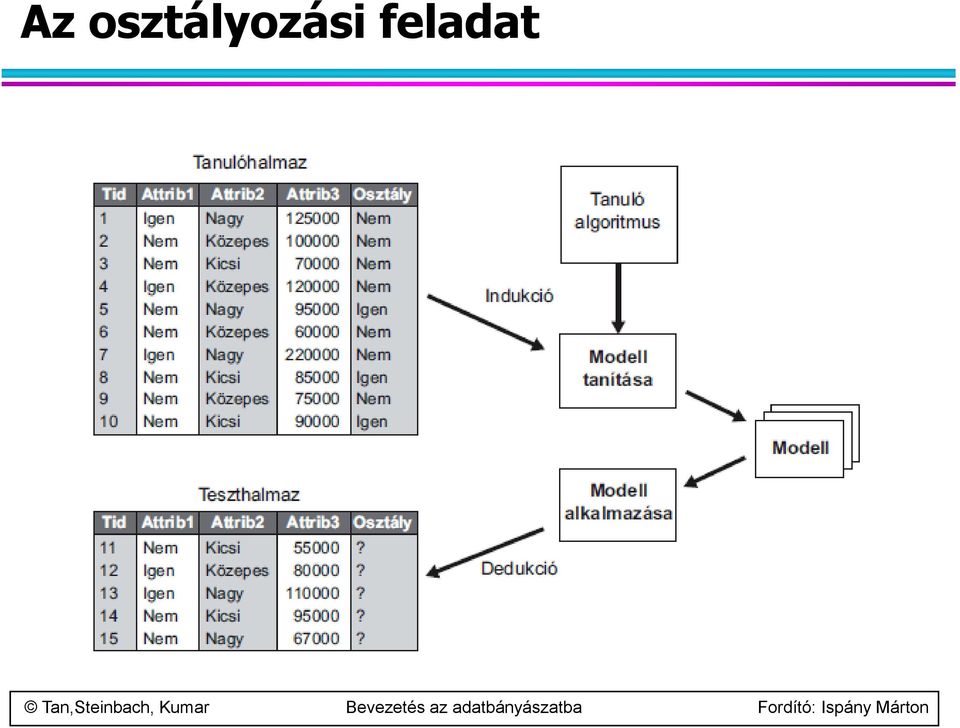
3 Az osztályozás definíciója Adott rekordok egy halmaza (tanító adatállomány) Minden rekord attributumok értékeinek egy halmazából áll, az attributumok egyike az ún. osztályozó vagy cél változó. Találjunk olyan modellt az osztályozó attributumra, amely más attributumok függvényeként állítja elő. Cél: korábban nem ismert rekordokat kell olyan pontosan osztályozni ahogyan csak lehetséges. A teszt adatállomány a modell pontosságának meghatározására szolgál. Általában az adatállományt két részre bontjuk, a tanítón illesztjük a modellt, a tesztelőn pedig validáljuk.

4 Az osztályozási feladat


5 Példák osztályozási feladatra A daganatos sejtek előrejelzése: jó vagy rossz indulatú. Hitelkártya tranzakciók osztályozása: legális vagy csalás. A fehérjék másodlagos szerkezetének osztályozása: alpha-helix, beta-híd, véletlen spirál. Újsághírek kategórizálása: üzlet, időjárás, szórakozás, sport stb.

6 Osztályozási módszerek Döntési fák Szabály alapú módszerek Memória alapú módszerek (legközelebbi k-társ) Logisztikus regresszió Neurális hálók Naív Bayes módszer és Bayes hálók Vektorgépek: SVM

7 10 Példa döntési fára Tid Visszatérítés Családi állapot Adóköteles jövedelem Csalás Vágó attributumok 1 Igen Nőtlen 125K 2 Házas 100K 3 Nőtlen 70K Igen Vissza térítés 4 Igen Házas 120K 5 Elvált 95K Igen 6 Házas 60K 7 Igen Elvált 220K 8 Nőtlen 85K Igen Családi Nőtlen, Elvált Jövedelem < 80K > 80K Házas 9 Házas 75K 10 Nőtlen 90K Igen Igen Tanító adatállomány Model: Döntési fa

8 10 Másik példa döntési fára Tid Visszatérítés Családi állapot Adóköteles jövedelem Csalás 1 Igen Nőtlen 125K 2 Házas 100K 3 Nőtlen 70K 4 Igen Házas 120K 5 Elvált 95K Igen 6 Házas 60K Házas Családi Nőtlen, Elvált Visszatérités Igen Jövedelem < 80K > 80K Igen 7 Igen Elvált 220K 8 Nőtlen 85K Igen 9 Házas 75K Több fa is illeszkedhet ugyanazokra az adatokra! 10 Nőtlen 90K Igen

9 10 10 Osztályozás döntési fával Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K No 2 No Medium 100K No 3 No Small 70K No 4 Yes Medium 120K No 5 No Large 95K Yes 6 No Medium 60K No 7 Yes Large 220K No 8 No Small 85K Yes 9 No Medium 75K No 10 No Small 90K Yes Training Set Tid Attrib1 Attrib2 Attrib3 Class 11 No Small 55K? 12 Yes Medium 80K? 13 Yes Large 110K? 14 No Small 95K? 15 No Large 67K? Test Set Induction Deduction Tree Induction algorithm Learn Model Apply Model Model Decision Tree

10 10 Alkalmazzuk a modellt a teszt adatokra Induljunk a fa gyökerétől. Teszt adatok Visszatérítés Családi állapot Adóköteles jövedelem Csalás Visszatérítés Házas 80K? Igen Nőtlen, Elvált Családi Házas Jövedelem < 80K > 80K Igen

11 10 Alkalmazzuk a modellt a teszt adatokra Teszt adatok Visszatérítés Családi állapot Adóköteles jövedelem Csalás Visszatérítés Házas 80K? Igen Nőtlen, Elvált Családi Házas Jövedelem < 80K > 80K Igen

12 10 Alkalmazzuk a modellt a teszt adatokra Teszt adatok Visszatérítés Családi állapot Adóköteles jövedelem Csalás Visszatérítés Házas 80K? Igen Nőtlen, Elvált Családi Házas Jövedelem < 80K > 80K Igen

13 10 Alkalmazzuk a modellt a teszt adatokra Teszt adatok Visszatérítés Családi állapot Adóköteles jövedelem Csalás Visszatérítés Házas 80K? Igen Nőtlen, Elvált Családi Házas Jövedelem < 80K > 80K Igen

14 10 Alkalmazzuk a modellt a teszt adatokra Teszt adatok Visszatérítés Családi állapot Adóköteles jövedelem Csalás Visszatérítés Házas 80K? Igen Nőtlen, elvált Családi Házas Jövedelem < 80K > 80K Igen

15 10 Alkalmazzuk a modellt a teszt adatokra Teszt adatok Visszatérítés Családi állapot Adóköteles jövedelem Csalás Visszatérítés Házas 80K? Igen Nőtlen, Elvált Családi Házas A Csalás attributumhoz rendeljünk,, -et Jövedelem < 80K > 80K Igen

16 10 10 Osztályozás döntési fával Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K No 2 No Medium 100K No 3 No Small 70K No 4 Yes Medium 120K No 5 No Large 95K Yes 6 No Medium 60K No 7 Yes Large 220K No 8 No Small 85K Yes 9 No Medium 75K No 10 No Small 90K Yes Training Set Tid Attrib1 Attrib2 Attrib3 Class 11 No Small 55K? 12 Yes Medium 80K? 13 Yes Large 110K? 14 No Small 95K? 15 No Large 67K? Test Set Induction Deduction Tree Induction algorithm Learn Model Apply Model Model Decision Tree

17 Döntési fa alapú következtetés Sok algoritmus: Hunt algoritmusa (az egyik legkorábbi) CART (Classification & Regression Trees -- osztályozási és regressziós fák) ID3 (Interaction Detection), C4.5 AID, CHAID (Automatic Interaction Detection, Chi-Square based AID) SLIQ, SPRINT
")
18 10 A Hunt algoritmus általános szerkezete Legyen D t a tanító rekordok halmaza a t csúcspontban. Általános eljárás: Ha D t csak olyan rekordokat tartalmaz, amelyek ugyanahhoz az y t osztályhoz tartoznak, akkor a t csúcspont címkéje legyen y t. Ha D t üres halmaz, akkor a t levél kapja az y d default címkét. Ha D t egynél több osztályból tartalmaz rekordokat, akkor egy attributum szerinti teszt alapján osszuk fel a rekordok halmazát kisebb részhalmazokra. Majd rekurzívan alkalmazzuk az eljárást minden kapott részhalmazra. Tid Visszatérítés Családi állapot Jövedelem Csalás 1 Igen Nőtlen 125K 2 Házas 100K 3 Nőtlen 70K 4 Igen Házas 120K 5 Elvált 95K Igen 6 Házas 60K 7 Igen Elvált 220K 8 Nőtlen 85K Igen 9 Házas 75K 10 Nőtlen 90K Igen? D t

19 10 Hunt algoritmusa csalás csalás Visszatérítés Igen csalás Tid Visszatérítés Családi állapot Jövedelem Csalás 1 Igen Nőtlen 125K 2 Házas 100K 3 Nőtlen 70K 4 Igen Házas 120K Visszatérítés Igen csalás Nőtlen, Elvált Csalás Családi állapot Házas csalás csalás Visszatérítés Igen Nőtlen, Elvált Jövedelem Családi állapot Házas csalás 5 Elvált 95K Igen 6 Házas 60K 7 Igen Elvált 220K 8 Nőtlen 85K Igen 9 Házas 75K 10 Nőtlen 90K Igen Tiszta csomópont < 80K >= 80K csalás Csalás tiszta csomópont

20 Fa alapú következtetés Mohó stratégia. Vágjuk részekre a rekordok halmazát egy attributum szerinti teszt alapján egy alkalmas kritériumot optimalizálva. Szempontok Hogyan vágjuk részekre a rekordokat? Hogyan határozzuk meg az attributumok szerinti teszt feltételeket? Hogyan határozzuk meg a legjobb vágást? Mikor álljunk le a vágással?

21 Fa alapú következtetés Mohó stratégia. Vágjuk részekre a rekordok halmazát egy attributum szerinti teszt alapján egy alkalmas kritériumot optimalizálva. Szempontok Hogyan vágjuk részekre a rekordokat? Hogyan határozzuk meg az attributumok szerinti teszt feltételeket? Hogyan határozzuk meg a legjobb vágást? Mikor álljunk le a vágással?
22 Hogyan határozzuk meg a tesztfeltételt? Függ az attributumok típusától: névleges, sorrendi, folytonos (különbségi, hányados). Függ attól, hogy hány részre vágunk: két részre, ágra (bináris) vágás, több részre, ágra vágás.
23 Vágás névleges attributum alapján Több részre vágás: Annyi részt használjunk amennyi különböző érték van. Családi Autótípus Sport Luxus Bináris vágás: Osszuk az értékeket két részre. Az optimális partíciót találjuk meg. {Sport, Luxus} Autótípus {Családi} vagy {Családi, Luxus} Autótípus {Sport}
24 Vágás sorrendi attributum alapján Több részre vágás : Annyi részt használjunk amennyi különböző érték van. Kicsi Méret Nagy Közepes Bináris vágás: Osszuk az értékeket két részre. Az optimális partíciót találjuk meg. {Kicsi, Közepes} Méret {Nagy} vagy {Közepes, Nagy} Méret {Kicsi} Mi a helyzet ezzel a vágással? {Kicsi, Nagy} Méret {Közepes}
25 Vágás folytonos attributum alapján Többféle módon kezelhető: Diszkretizáció, hogy sorrendi kategórikus attributumot állítsunk elő statikus egyszer, kezdéskor diszkretizálunk, dinamikus a tartományokat kaphatjuk egyenlő hosszú v. egyenlő gyakoriságú intervallumokra való beosztással illetve klaszterosítással. Bináris döntés: (A < v) vagy (A v) Tekintsük az összes lehetséges vágást és találjuk meg a legjobbat. Számításigényes lehet.
26 Vágás folytonos attributum alapján (a) Bináris vágás (b) Többágú vágás
27 Fa alapú következtetés Mohó stratégia. Vágjuk részekre a rekordok halmazát egy attributum szerinti teszt alapján egy alkalmas kritériumot optimalizálva. Szempontok Hogyan vágjuk részekre a rekordokat? Hogyan határozzuk meg az attributumok szerinti teszt feltételeket? Hogyan határozzuk meg a legjobb vágást? Mikor álljunk le a vágással?
28 Mi lesz a legjobb vágás? Vágás előtt: 10 rekord a 0 osztályból, 10 rekord az 1 osztályból Melyik tesztfeltétel a legjobb?
29 Mi lesz a legjobb vágás? Mohó megközelítés: A homogén osztály-eloszlást eredményező csúcspontokat preferáljuk. Szennyezettségi mérőszámra van szükségünk: C0: 5 C1: 5 homogén, nagyon szennyezett C0: 9 C1: 1 Homogén, kicsit szennyezett
30 Szennyezettség mérése Gini index Entrópia Téves osztályozási hiba
31 Mi lesz a legjobb vágás? Vágás előtt: C0 C1 N00 N01 M0 A? B? Igen Igen N1 csúcs N2 csúcs N3 csúcs N4 csúcs C0 N10 C0 N20 C0 N30 C0 N40 C1 N11 C1 N21 C1 N31 C1 N41 M1 M2 M3 M4 M12 M34 Nyereség = M0 M12 vagy M0 M34
32 Szennyezettség mérése: GINI index Gini index egy t csúcspontban: G( t) 1 j [ p( j t)] 2 (p( j t) a j osztály relatív gyakorisága a t csúcspontban). A maximum (1-1/n c ) amikor a rekordok egyenlően oszlanak meg az osztályok között, ahol n c az osztályok száma (legkevésbé hasznos információ). A minimum 0.0 amikor minden rekord ugyanahhoz az osztályhoz tartozik (leghasznosabb információ). C1 0 C2 6 Gini=0.000 C1 1 C2 5 Gini=0.278 C1 2 C2 4 Gini=0.444 C1 3 C2 3 Gini=0.500
33 A Gini index számolása G( t) 1 j [ p( j t)] 2 C1 0 C2 6 P(C1) = 0/6 = 0 P(C2) = 6/6 = 1 Gini = 1 P(C1) 2 P(C2) 2 = = 0 C1 1 C2 5 P(C1) = 1/6 P(C2) = 5/6 Gini = 1 (1/6) 2 (5/6) 2 = C1 2 C2 4 P(C1) = 2/6 P(C2) = 4/6 Gini = 1 (2/6) 2 (4/6) 2 = 0.444
34 Vágás a Gini index alapján A CART, SLIQ, SPRINT algoritmusok használják. Ha a t csúcspontot (szülő) k részre (gyerekek) osztjuk fel, akkor a vágás jóságát az alábbi képlettel számoljuk: G vágás k i1 ni n G( i) ahol n i = rekordok száma az i edik gyereknél, n = rekordok száma a t csomópontban, G(i) = az i-edik gyerek Gini indexe.
35 Gini index bináris attributumokra Két ágra vágás Az ágak súlyozásának hatása: minél nagyobb és tisztább ágakat keresünk. B? Szülő C1 6 Igen C2 6 G(N1) = 1 (5/7) 2 (2/7) 2 = G(N2) = 1 (1/5) 2 (4/5) 2 = 0.32 N1 csúcs N2 csúcs N1 N2 C1 5 1 C2 2 4 Gini=0.333 Gini = G(gyerek) = 7/12 * /12 * 0.32 = 0.371
36 Gini index diszkrét attributumokra Minden különböző vágó értékre határozzuk meg az egyes osztályok előfordulási gyakoriságát az egyes ágakra. Használjuk a gyakorisági mátrixot a döntésnél. Több ágra vágás Bináris vágás (találjuk meg a legjobb partíciót) Autótípus Családi Sport Luxus C C Gini Autótípus {Sport, Luxus} {Családi} C1 3 1 C2 2 4 Gini Autótípus {Sport} {Családi, Luxus} C1 2 2 C2 1 5 Gini 0.419
37 10 Gini index folytonos attributumokra Használjunk egy értéken alapuló bináris döntéseket. Számos lehetséges vágó érték: Lehetséges vágások száma = Különböző értékek száma Mindegyik vágó értékhez tartozik egy gyakorisági mátrix. Az ágak mindegyikében számoljuk össze az A < v és A v osztályok gyakoriságait. Heurisztika a legjobb v megtalálására: Minden v-re fésüljük át az adatbázist a gyakorisági mátrix meghatározására és számoljuk ki a Gini indexet. Numerikusan nem hatékony! (Sok ismétlés) Tid Visszatérítés Családi állapot Jövedelem Csalás 1 Igen Nőtlen 125K 2 Házas 100K 3 Nőtlen 70K 4 Igen Házas 120K 5 Elvált 95K Igen 6 Házas 60K 7 Igen Elvált 220K 8 Nőtlen 85K Igen 9 Házas 75K 10 Nőtlen 90K Igen Taxable Income > 80K? Yes No
38 Gini index folytonos attributumokra Hatékony számolási algoritmus: mindegyik attributumra Rendezzük az attributumot értékei mentén. Lineárisan végigfésülve ezeket az értékeket mindig frissítsük a gyakorisági mátrixot és számoljuk ki a Gini indexet. Válasszuk azt a vágó értéket, amelynek legkisebb a Gini indexe. Csalás Igen Igen Igen Adóköteles jövedelem Rendezett értékek Vágó értékek < = > <= > <= > <= > <= > <= > <= > <= > <= > <= > <= > Igen Gini
39 Entrópia alapú vágási kritérium Entrópia a t csúcsban: E t) p( j t)log p( j t) ( 2 j (ahol p( j t) a j-edik osztály relatív gyakorisága a t csúcsban). Egy csúcs homogenitását méri. Maximuma log 2 n c, amikor a rekordok egyenlően oszlanak meg az osztályok között, ahol n c az osztályok száma (legrosszabb eset). Minimuma 0.0, amikor minden rekord egy osztályba tartozik (legjobb eset). Az entrópia számolása hasonló a Gini index számolásához.
40 Az entrópia számolása E t) p( j t)log p( j t) ( 2 j C1 0 C2 6 P(C1) = 0/6 = 0 P(C2) = 6/6 = 1 Entrópia = 0 log 0 1 log 1 = 0 0 = 0 C1 1 C2 5 P(C1) = 1/6 P(C2) = 5/6 Entrópia = (1/6) log 2 (1/6) (5/6) log 2 (5/6) = 0.65 C1 2 C2 4 P(C1) = 2/6 P(C2) = 4/6 Entrópia = (2/6) log 2 (2/6) (4/6) log 2 (4/6) = 0.92
41 Entrópia alapú vágás Információ nyereség (INY): INY vágás E( p) k i1 ni n E( i) A t szülő csúcsot k ágra bontjuk: n i a rekordok száma az i-edik ágban Az entrópia csökken a vágás miatt. Válasszuk azt a vágást, amelynél a csökkenés a legnagyobb (maximalizáljuk a nyereséget). Az ID3 és C4.5 algoritmusok használják. Hátránya: olyan vágásokat részesít előnyben, amelyek sok kicsi de tiszta ágat hoznak létre.
42 Entrópia alapú vágás Nyereség hányados (NYH): NYH vágás I vágás VE VE k i1 ni n log ni n A p szülő csúcsot k ágra bontjuk: n i a rekordok száma az i-edik ágban Az információ nyereséget módosítja a vágás entrópiájával (VE). A nagy entrópiájú felbontásokat (sok kis partíció) bünteti! A C4.5 algoritmus használja. Az információ nyereség hátrányainak kiküszöbölésére tervezték.
43 Téves osztályozási hiba alapú vágás Osztályozási hiba a t csúcsban : H ( t) 1 max P( i t) i Egy csúcspontbeli téves osztályozás hibáját méri. Maximuma 1-1/n c, amikor a rekordok egyenlően oszlanak meg az osztályok között, ahol n c az osztályok száma (legrosszabb eset). Minimuma 0.0, amikor minden rekord egy osztályba tartozik (legjobb eset).
44 Példa a hiba számolására H( t) 1 max P( i t) i C1 0 C2 6 P(C1) = 0/6 = 0 P(C2) = 6/6 = 1 Hiba = 1 max (0, 1) = 1 1 = 0 C1 1 C2 5 P(C1) = 1/6 P(C2) = 5/6 Hiba = 1 max (1/6, 5/6) = 1 5/6 = 1/6 C1 2 C2 4 P(C1) = 2/6 P(C2) = 4/6 Hiba = 1 max (2/6, 4/6) = 1 4/6 = 1/3
45 Vágási kritériumok összehasonlítása Bináris osztályozási feladat:
46 Téves osztályozás vagy Gini Igen N1 csúcs A? N2 csúcs Szülő C1 7 C2 3 Gini = 0.42 G(N1) = 1 (3/3) 2 (0/3) 2 = 0 G(N2) = 1 (4/7) 2 (3/7) 2 = N1 N2 C1 3 4 C2 0 3 Gini=0.361 G(gyerek) = 3/10 * 0 + 7/10 * = A Gini javít, a másik nem!!
47 Fa alapú következtetés Mohó stratégia. Vágjuk részekre a rekordok halmazát egy attributum szerinti teszt alapján egy alkalmas kritériumot optimalizálva. Szempontok Hogyan vágjuk részekre a rekordokat? Hogyan határozzuk meg az attributumok szerinti teszt feltételeket? Hogyan határozzuk meg a legjobb vágást? Mikor álljunk le a vágással?
48 Megállási szabály döntési fáknál Ne osszunk tovább egy csúcsot ha minden rekord ugyanahhoz az osztályhoz tartozik. Ne osszunk tovább egy csúcsot ha minden rekordnak hasonló attributum értékei vannak. Korai megállás (később tárgyaljuk).
49 Döntési fa alapú osztályozás Előnyök: Kis költséggel állíthatóak elő. Kimagaslóan gyors új rekordok osztályozásánál. A kis méretű fák könnyen interpretálhatóak. Sok egyszerű adatállományra a pontosságuk összemérhető más osztályozási módszerekével.
50 Példa: C4.5 Egyszerű, egy mélységű keresés. Információ nyereséget használ. Minden csúcsnál rendezi a folytonos attributumokat. Az összes adatot a memóriában kezeli. Alkalmatlan nagy adatállományok kezelésére. Memórián kívüli rendezést igényel (lassú). Szoftver letölthető az alábbi címről:
51 Az osztályozás gyakorlati szempontjai Alul- és túlillesztés Hiányzó értékek Az osztályozás költsége
 1 Kék háromszögek: sqrt(x 12 +x 22 ) > 0.")
52 Példa alul- és túlillesztésre 500 piros kör és 500 kék háromszög Piros körök: 0.5 sqrt(x 12 +x 22 ) 1 Kék háromszögek: sqrt(x 12 +x 22 ) > 0.5 or sqrt(x 12 +x 22 ) < 1
53 Alul- és túlillesztés Túlillesztés Alulillesztés: amikor a modell túl egyszerű a tanító és a teszt hiba egyaránt nagy
54 Túlillesztés hiba miatt A döntési határ torzul a zaj miatt
55 Túlillesztés elégtelen minta miatt Nehéz helyesen előrejelezni az ábra alsó felében lévő pontokat mivel azon a területen nincsenek adatok. - Elégtelen számú tanító rekord egy területen azt okozhatja, hogy a döntési fa olyan tanító rekordok alapján prediktál a teszt példákra, amelyek az osztályozási feladat számára irrelevánsak.
56 Túlillesztés: megjegyzések A túlillesztés döntési fák esetén azt eredményezheti, hogy a fa szükségtelenül nagy (összetett) lesz. A tanítás hibája nem ad jó becslést arra hogyan fog működni a fa új rekordokra. A hiba becslésére új módszerek kellenek.
57 Az általánosítási hiba becslése Behelyettesítési hiba: hiba a tanító állományon ( e(t) ) Általánosítási hiba: hiba a teszt állományon ( e (t)) Módszerek az általánosítási hiba becslésére: Optimista megközelítés: e (t) = e(t) Pesszimista megközelítés: Minden levélre: e (t) = (e(t)+0.5) Teljes hiba: e (T) = e(t) + N 0.5 (N: levelek száma) Egy 30 levelű fára 10 tanítási hiba mellett (1000 rekord): Tanítási hiba = 10/1000 = 1% Általánosítási hiba = ( )/1000 = 2.5% Hiba csökkentés tisztítással (REP reduced error pruning): használjunk egy ellenőrző adatállományt az általánosítási hiba becslésére.
58 Occam borotvája Két hasonló általánosítási hibájú modell esetén az egyszerűbbet részesítjük előnyben a bonyolultabbal szemben. Bonyolult modelleknél nagyobb az esélye annak, hogy az csak véletlenül illeszkedik az adatokban lévő hiba miatt. Ezért figyelembe kell venni a modell komplexitását amikor kiértékeljük.
59 Minimális leíró hossz (MDL) X y X 1 1 X 2 0 X 3 0 X 4 1 X n 1 A Yes 0 A? No B? B 1 B 2 C? 1 C 1 C B X y X 1? X 2? X 3? X 4? X n? Költség(Modell,Adat)=Költség(Adat Modell)+Költség(Modell) Költség: a kódoláshoz szükséges bitek száma. A legkisebb költségű modellt keressük. Költség(Adat Modell) a téves osztályozás hibáját kódolja. Költség(Modell) a fát, csúcsokat és leveleket (azok számát) és a vágási feltételeket kódolja.
60 Hogyan kezeljük a túlillesztést Előtisztítás (korai megállási szabály) Állítsuk le az algoritmust mielőtt a fa teljes nem lesz. Jellegzetes megállási szabályok egy csúcsban: Álljunk meg, ha minden rekord ugyanahhoz az osztályhoz tartozik. Álljunk meg, ha az összes attributum értéke egyenként azonos. További megszorító feltételek: Álljunk meg, ha a rekordok száma kisebb egy a felhasználó által meghatározott értéknél. Álljunk meg, ha az osztályok eloszlása a rekordokon független a célváltozótól (használjunk pl. 2 próbát). Álljunk meg, ha az aktuális csúcspont vágása nem javítja a szennyezettség mértékét (pl. a Gini indexet vagy az információ nyereséget).
61 Hogyan kezeljük a túlillesztést Utótisztítás Építsük fel a teljes döntési fát. Metszük a fát alulról felfelé bizonyos csúcspontokban vágva. Ha javul az általánosítási hiba a metszés után, akkor helyettesítsük a levágott részfát egy levéllel. Ennek a levélnek az osztály címkéjét a levágott részfabeli rekordok osztályai alapján többségi elvet alkalmazva kapjuk. Az MDL elvet is használhatjuk utótisztításra.
62 Példa utótisztításra Osztály = Igen 20 Osztály = 10 Hiba = 10/30 A? Tanítási hiba (vágás előtt) = 10/30 Pesszimista hiba (vágás előtt) = ( )/30 = 10.5/30 Tanítási hiba (vágás után) = 9/30 Pesszimista hiba (vágás után) = ( )/30 = 11/30 Messünk! A1 A2 A3 A4 Osztály = Igen 8 Osztály = Igen 3 Osztály = Igen 4 Osztály = Igen 5 Osztály = 4 Osztály = 4 Osztály = 1 Osztály = 1
63 Példa utótisztításra Optimista hiba? 1. eset: Egyik esetben se messünk Pesszimista hiba? C0: 11 C1: 3 C0: 2 C1: 4 Ne messünk az 1. esetben, messünk a 2.-ban Hiba csökkentés tisztítással? Függ az ellenőrző állománytól 2. eset: C0: 14 C1: 3 C0: 2 C1: 2
64 Hiányzó attributum értékek kezelése A hiányzó értékek három különböző módon befolyásolják a döntési fa konstrukcióját: Hogyan számoljuk a szennyezettségi mutatókat? Hogyan oszlanak el a hiányzó értékeket tartalmazó rekordok a gyerek csúcsok között? Hogyan osztályozzuk a hiányzó értékeket tartalmazó teszt rekordokat?
65 10 Szennyezettségi mutató számolása Tid Visszatérítés Családi állapot Jövedelem Csalás 1 Igen Nőtlen 125K 2 Házas 100K 3 Nőtlen 70K 4 Igen Házas 120K 5 Elvált 95K Igen 6 Házas 60K 7 Igen Elvált 220K 8 Nőtlen 85K Igen 9 Házas 75K 10? Nőtlen 90K Igen Hiányzó érték Vágás előtt: Entrópia(Szülő) = -0.3 log(0.3)-(0.7)log(0.7) = Csalás = Igen Csalás = Visszatérítés=Igen 0 3 Visszatérítés= 2 4 Visszatérítés=? 1 0 Vágás Visszatérítés mentén: Entrópia(Visszatérítés=Igen) = 0 Entrópia(Visszatérítés=) = -(2/6)log(2/6) (4/6)log(4/6) = Entrópia(gyerek) = 0.3 (0) (0.9183) = Nyereség = 0.9 ( ) =
66 10 10 Rekordok eloszlása Tid Visszatérítés Családi állapot Jövedelem Csalás 1 Igen Nőtlen 125K 2 Házas 100K 3 Nőtlen 70K 4 Igen Házas 120K 5 Elvált 95K Igen 6 Házas 60K 7 Igen Elvált 220K 8 Nőtlen 85K Igen 9 Házas 75K Igen Csalás=Igen 0 Csalás= 3 Visszatérítés Csalás=Igen 2 Csalás= 4 Tid Visszatérítés Igen Családi állapot Visszatérítés Jövedelem Csalás 10? Nőtlen 90K Igen Csalás=Igen 0 + 3/9 Csalás= 3 Csalás=Igen 2 + 6/9 Csalás= 4 A Visszatérítés=Igen valószínűsége 3/9 A Visszatérítés= valószínűsége 6/9 Rendeljük a rekordot a bal csúcshoz 3/9 súllyal és 6/9 súllyal a jobb csúcshoz.
67 10 Rekordok osztályozása Új rekord: Házas Nőtlen Elvált Összes Tid Visszatérítés Családi állapot Jövedelem Csalás Csalás= ? 85K? Csalás=Igen 6/ Igen Visszatérítés Egyedüli, elvált Jövedelem Családi < 80K > 80K Igen Házas Összes A Családi állapot = Házas valószínűsége 3.67/6.67 A Családi állapot={nőtlen, Elvált} valószínűsége 3/6.67
68 További szempontok Adat-töredezettség Keresési stratégiák Kifejezőképesség Fa ismétlődés
69 Adat-töredezettség A rekordok száma egyre kevesebb lesz ahogy lefelé haladunk a fában. A levelekbe eső rekordok száma túl kevés lehet ahhoz, hogy statisztikailag szignifikáns döntést hozzunk.
70 Keresési stratégiák Az (egy) optimális döntési fa megtalálása NPnehéz feladat. Az eddig bemutatott algoritmusok mohó, fentről lefelé haladó rekurzív partícionáló stratégiák, melyek elfogadható megoldást eredményeznek. Más stratégiák? Lentről felfelé Kétirányú Sztochasztikus
71 Kifejezőképesség A döntési fa kifejező reprezentációt ad diszkrét értékű függvények tanításánál. Azonban nem általánosítható jól bizonyos logikai (Boole) függvények esetén. Példa: paritás függvény Osztály = 1 ha páros számú olyan attributum van, amely igaz Osztály = 0 ha páratlan számú olyan attributum van, amely hamis Pontos modellhez egy teljes fára van szükségünk. elég kifejező folytonos változók modellezésénél. Különösen ha a teszt feltétel egyszerre csak egy attributumot tartalmaz.
72 Döntési határ x < 0.43? 0.7 Yes No 0.6 y 0.5 y < 0.47? y < 0.33? Yes No Yes No : 4 : 0 : 0 : 4 : 0 : 3 : 4 : x Két különböző osztályhoz tartozó szomszédos tartomány közötti határvonalat döntési határnak nevezzük. A döntési határ párhozamos a tengelyekkel mivel a teszt feltétel egy időben csak egy attributumot tartalmaz.

73 Ferde döntési fa x + y < 1 Osztály = + Osztály = A teszt feltétel több attributumot is tartalmazhat. Kifejezőbb reprezentáció Az optimális teszt feltétel megtalálása számítás igényes.
74 Fa ismétlődés P Q R S 0 Q S Ugyanaz a részfa fordul elő több ágban.
75 Modellek kiértékelése Metrikák hatékonyság kiértékelésre Hogyan mérhetjük egy modell hatékonyságát? Módszerek a hatékonyság kiértékelésére Hogyan kaphatunk megbízható becsléseket? Módszerek modellek összehasonlítására Hogyan hasonlíthatjuk össze a versenyző modellek relatív hatékonyságát?
76 Modellek kiértékelése Metrikák hatékonyság kiértékelésre Hogyan mérhetjük egy modell hatékonyságát? Módszerek a hatékonyság kiértékelésére Hogyan kaphatunk megbízható becsléseket? Módszerek modellek összehasonlítására Hogyan hasonlíthatjuk össze a versenyző modellek relatív hatékonyságát?
77 Metrikák hatékonyság kiértékelésre A hangsúly a modellek prediktív képességén van szemben azzal, hogy milyen gyorsan osztályoz vagy épül a modell, skálázható-e stb. Egyetértési mátrix: Előrejelzett osztály Aktuális osztály Osztály= Igen Osztály= Osztály= Igen a c Osztály= b d a: TP (igaz pozitív) b: FN (hamis negatív) c: FP (hamis pozitív) d: TN (igaz negatív)
78 Metrikák hatékonyság kiértékelésre Előrejelzett osztály Osztály= Igen Osztály= Aktuális osztály Osztály= Igen Osztály= a (TP) c (FP) b (FN) d (TN) Leggyakrabban használt metrika: Pontosság a a d b c d TP TN TP TN FP FN
79 A pontosság határai Tekintsünk egy bináris osztályozási feladatot: a 0 osztályba tartozó rekordok száma = 9990, az 1 osztályba tartozó rekordok száma = 10. Ha a modell minden rekordot a 0 osztályba sorol, akkor a pontosság 9990/10000 = 99.9 %. A pontosság félrevezető mivel a modell az 1 osztályból egyetlen rekordot sem vesz figyelembe.
80 Költségmátrix Előrejelzett osztály Aktuális osztály C(i j) Osztály = Igen Osztály = Igen Osztály = C(Igen Igen) Osztály = C( Igen) C(Igen ) C( ) C(i j): a téves osztályozás költsége, a j osztályba eső rekordot az i osztályba soroljuk
81 Osztályozás költségének kiszámolása Költség mátrix Előrejelzett osztály C(i j) + - Aktuális osztály M 1 modell Aktuális osztály Előrejelzett osztály Model M 2 Aktuális osztály Előrejelzett osztály Pontosság = 80% Költség = 3910 Pontosság = 90% Költség = 4255
82 Költség vagy pontosság Darab Aktuális osztály Költség Aktuális osztály Osztály = Igen Osztály = Osztály = Igen Osztály = Előrejelzett osztály Osztály = Igen a c Előrejelzett osztály Osztály = Igen p q Osztály = b d Osztály = q p A pontosság arányos a költséggel ha 1. C(Igen )=C( Igen) = q 2. C(Igen Igen)=C( ) = p N = a + b + c + d Pontosság = (a + d)/n Költség = p (a + d) + q (b + c) = p (a + d) + q (N a d) = q N (q p)(a + d) = N [q (q-p) Pontosság]
83 Költség-érzékeny mutatók Pozitív pontosság Pozitívemlékezet F mutató a p a c a r a b 2rp F r p 2a 2a b c A pozitív pontosság torzított a C(Igen Igen) és C(Igen ) felé A pozitív emlékezet torzított a C(Igen Igen) és C( Igen) felé Az F mutató torzított a C( ) kivételével az összes felé w1a w4d Súlyozott pontosság w a w b w c w d
84 Modellek kiértékelése Metrikák hatékonyság kiértékelésre Hogyan mérhetjük egy modell hatékonyságát? Módszerek a hatékonyság kiértékelésére Hogyan kaphatunk megbízható becsléseket? Módszerek modellek összehasonlítására Hogyan hasonlíthatjuk össze a versenyző modellek relatív hatékonyságát?
85 Módszerek hatékonyság kiértékelésére Hogyan kaphatunk megbízható becslést a hatékonyságra? Egy modell hatékonysága a tanító algoritmus mellett más faktoroktól is függhet: osztályok eloszlása, a téves osztályozás költsége, a tanító és tesz adatállományok mérete.
86 Tanulási görbe A tanulási görbe mutatja hogyan változik a pontosság a mintanagyság függvényében Mintavételi ütemterv szükséges a tanulási görbe elkészítéséhez: Aritmetikai mintavétel (Langley & tsai) Geometriai mintavétel (Provost & tsai) A kis minta hatása: - Torzítás - Variancia
87 Becslési módszerek Felosztás Tartsuk fenn a 2/3 részt tanításra, az 1/3 részt tesztelésre. Véletlen részminták Ismételt felosztás Keresztellenőrzés Osszuk fel az adatállományt k diszjunkt részhalmazra. Tanítsunk k-1 partíción, teszteljünk a fennmaradón. Hagyjunk ki egyet: k=n (diszkriminancia analízis). Rétegzett mintavétel Felül- vagy alulmintavételezés Bootstrap Visszatevéses mintavétel
88 Modellek kiértékelése Metrikák hatékonyság kiértékelésre Hogyan mérhetjükegy modell hatékonyságát? Módszerek a hatékonyság kiértékelésére Hogyan kaphatunk megbízható becsléseket? Módszerek modellek összehasonlítására Hogyan hasonlíthatjuk össze a versenyző modellek relatív hatékonyságát?
89 ROC (Receiver Operating Characteristic) Vevő oldali működési jellemző Az 50-es években fejlesztették ki a jelfeldolgozás számára zajos jelek vizsgálatára. A pozitív találatok és a hamis riasztások közötti kompromisszumot írja le. A ROC görbe a IP (y tengely) eseteket ábrázolja a HP (x tengely) függvényében. Minden osztályozó hatékonysága reprezentálható egy ponttal a ROC görbén. Az algoritmusbeli küszöbértéket megváltoztatva a mintavételi eloszlás vagy a költségmátrix módosítja a pont helyét.
90 ROC görbe Egy dimenziós adatállomány, amely két osztályt tartalmaz (pozitív és negatív). Minden x > t pontot pozitívnak osztályozunk, a többi negatív lesz. A t küszöb értéknél: TP=0.5, FN=0.5, FP=0.12, FN=0.88
91 ROC görbe (IP,HP): (0,0): mindenki a negatív osztályba kerül (1,1): mindenki a pozitív osztályba kerül (1,0): ideális Diagonális vonal: Véletlen találgatás A diagonális vonal alatt: az előrejelzés a valódi osztály ellentéte
92 Modellek összehasonlítása ROC görbével Általában nincs olyan modell, amely következetesen jobb a többinél: M 1 jobb kis HPR esetén, M 2 jobb nagy HPR esetén. A ROC görbe alatti terület: Ideális: Terület = 1 Véletlen találgatás: Terület = 0.5
93 Hogyan szerkesszünk ROC görbét Rekord P(+ A) Igaz osztály Alkalmazzunk egy olyan osztályozót, amely minden rekordra meghatározza a P(+ A) poszterior valószínűséget. Rendezzük a rekordokat P(+ A) szerint csökkenően. Válasszuk küszöbnek minden egyes különböző P(+ A) értéket. Minden küszöb értéknél számoljuk össze: IP, HP, IN, HN. IP ráta, IPR = IP/(IP+HN) HP ráta, HPR = HP/(HP + IN)
94 Hogyan szerkesszünk ROC görbét Osztály P Küszöb >= TP FP TN FN IPR HPR ROC görbe:
95 Szignifikancia vizsgálat Adott két modell: M1 modell: pontosság = 85% 30 rekordon tesztelve M2 modell: pontosság = 75% 5000 rekordon tesztelve Mondhatjuk azt, hogy M1 jobb mint M2? Mekkora megbízhatóságot tulajdoníthatunk az M1 és M2 modellek pontosságának? A hatékonysági mérőszámokbeli különbség a teszt állományokbeli véletlen ingadozásnak köszönhető vagy szisztematikus az eltérés?
96 Konfidencia intervallum a pontosságra Az előrejelzés Bernoulli kísérletnek tekinthető. A Bernoulli kísérletnek 2 lehetséges kimenetele van. Az előrejelzés lehetséges eredménye: helyes vagy hibás. Független Bernoulli kísérletek összege binomiális eloszlású: x Bin(N, p) x: a helyes előrejelzések száma Pl.: Egy szabályos érmét 50-szer feldobva mennyi fejet kapunk? A fejek várt száma = Np = = 25 Adott x (a helyes előrejelzések száma) vagy azok x/n aránya és N (teszt rekordok száma) mellett: Tudjuk-e előrejelezni p-t (a modell pontosságát)?
97 Konfidencia intervallum a pontosságra Nagy mintákra (N > 30), A helyesek aránya normális eloszlású p várható értékkel és p(1-p)/n varianciával. Konfidencia intervallum p-re: 1 ) ) / (1 / ( 2 / 1 2 / Z N p p p N x Z P Terület = 1 - Z /2 Z 1- /2 ) 2( / / / 2 2 / Z N N x x Z Z x p
98 Konfidencia intervallum a pontosságra Tekintsünk egy modellt, amely pontossága 80% volt, amikor 100 teszt rekordon értékeltük ki: N=100, x/n = 0.8 legyen 1- = 0.95 (95% konfidencia) a normális táblázatból Z /2 = Z N p(alsó) p(felső)
99 Két modell összehasonlítása Két modell, M1 és M2, közül melyik a jobb? M1-t a D1-en (n1 rekord) teszteljük, hiba ráta = e 1 M2-t a D2-ön teszteljük (n2 rekord), hiba ráta = e 2 Tegyük fel, hogy D1 és D2 függetlenek Ha n1 és n2 elegendően nagy, akkor Közelítőleg: e e 1 2 ~ ~ ˆ i N N, 1 2 1, e (1 e ) i i n i 2
 e2(1 e2) n1 n2 1 2 Konfidencia intervallum (1-) szinten: d t d Z / 2 ˆ")
100 Két modell összehasonlítása Vizsgáljuk meg, hogy a hiba ráták különbsége szignifikáns-e: d = e1 e2 d ~ N(d t, t ) ahol d t az igazi különbség Mivel D1 és D2 függetlenek a varianciáik összeadódnak: 2 t ˆ 2 ˆ e1(1 e1) e2(1 e2) n1 n2 1 2 Konfidencia intervallum (1-) szinten: d t d Z / 2 ˆ t
Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés
 Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés 4. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Tan,Steinbach, Kumar Bevezetés az
Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés 4. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Tan,Steinbach, Kumar Bevezetés az
Új típusú döntési fa építés és annak alkalmazása többtényezős döntés területén
 Új típusú döntési fa építés és annak alkalmazása többtényezős döntés területén Dombi József Szegedi Tudományegyetem Bevezetés - ID3 (Iterative Dichotomiser 3) Az ID algoritmusok egy elemhalmaz felhasználásával
Új típusú döntési fa építés és annak alkalmazása többtényezős döntés területén Dombi József Szegedi Tudományegyetem Bevezetés - ID3 (Iterative Dichotomiser 3) Az ID algoritmusok egy elemhalmaz felhasználásával
Csima Judit február 19.
 Osztályozás Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2018. február 19. Csima Judit Osztályozás 1 / 53 Osztályozás általában Osztályozás, classification adott egy rekordokból
Osztályozás Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2018. február 19. Csima Judit Osztályozás 1 / 53 Osztályozás általában Osztályozás, classification adott egy rekordokból
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
Eredmények kiértékelése
 Eredmények kiértékelése Nagyméretű adathalmazok kezelése (2010/2011/2) Katus Kristóf, hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi és Információelméleti Tanszék 2011. március
Eredmények kiértékelése Nagyméretű adathalmazok kezelése (2010/2011/2) Katus Kristóf, hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi és Információelméleti Tanszék 2011. március
STATISZTIKA ELŐADÁS ÁTTEKINTÉSE. Matematikai statisztika. Mi a modell? Binomiális eloszlás sűrűségfüggvény. Binomiális eloszlás
 ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 9. Előadás Binomiális eloszlás Egyenletes eloszlás Háromszög eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell 2/62 Matematikai statisztika
ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 9. Előadás Binomiális eloszlás Egyenletes eloszlás Háromszög eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell 2/62 Matematikai statisztika
Statisztika - bevezetés Méréselmélet PE MIK MI_BSc VI_BSc 1
 Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Adatbányászat: Klaszterezés Haladó fogalmak és algoritmusok
 Adatbányászat: Klaszterezés Haladó fogalmak és algoritmusok 9. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Logók és támogatás A tananyag a TÁMOP-4.1.2-08/1/A-2009-0046
Adatbányászat: Klaszterezés Haladó fogalmak és algoritmusok 9. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Logók és támogatás A tananyag a TÁMOP-4.1.2-08/1/A-2009-0046
1. gyakorlat. Mesterséges Intelligencia 2.
 1. gyakorlat Mesterséges Intelligencia. Elérhetőségek web: www.inf.u-szeged.hu/~gulyasg mail: gulyasg@inf.u-szeged.hu Követelmények (nem teljes) gyakorlat látogatása kötelező ZH írása a gyakorlaton elhangzott
1. gyakorlat Mesterséges Intelligencia. Elérhetőségek web: www.inf.u-szeged.hu/~gulyasg mail: gulyasg@inf.u-szeged.hu Követelmények (nem teljes) gyakorlat látogatása kötelező ZH írása a gyakorlaton elhangzott
Gépi tanulás. Hány tanítómintára van szükség? VKH. Pataki Béla (Bolgár Bence)
") Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
Adatbányászati feladatgyűjtemény tehetséges hallgatók számára
 Adatbányászati feladatgyűjtemény tehetséges hallgatók számára Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Tartalomjegyék Modellek kiértékelése...
Adatbányászati feladatgyűjtemény tehetséges hallgatók számára Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Tartalomjegyék Modellek kiértékelése...
Csima Judit február 26.
 Osztályozás Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2014. február 26. Csima Judit Osztályozás 1 / 60 Osztályozás általában Osztályozás, classification adott egy rekordokból
Osztályozás Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2014. február 26. Csima Judit Osztályozás 1 / 60 Osztályozás általában Osztályozás, classification adott egy rekordokból
Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására
 VÉGZŐS KONFERENCIA 2009 2009. május 20, Budapest Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására Hidasi Balázs hidasi@tmit.bme.hu Konzulens: Gáspár-Papanek Csaba Budapesti
VÉGZŐS KONFERENCIA 2009 2009. május 20, Budapest Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására Hidasi Balázs hidasi@tmit.bme.hu Konzulens: Gáspár-Papanek Csaba Budapesti
Több valószínűségi változó együttes eloszlása, korreláció
 Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Statisztika I. 8. előadás. Előadó: Dr. Ertsey Imre
 Statisztika I. 8. előadás Előadó: Dr. Ertsey Imre Minták alapján történő értékelések A statisztika foglalkozik. a tömegjelenségek vizsgálatával Bizonyos esetekben lehetetlen illetve célszerűtlen a teljes
Statisztika I. 8. előadás Előadó: Dr. Ertsey Imre Minták alapján történő értékelések A statisztika foglalkozik. a tömegjelenségek vizsgálatával Bizonyos esetekben lehetetlen illetve célszerűtlen a teljes
[Biomatematika 2] Orvosi biometria
![[Biomatematika 2] Orvosi biometria](/thumbs/54/33134304.jpg "[Biomatematika 2] Orvosi biometria") [Biomatematika 2] Orvosi biometria 2016.02.29. A statisztika típusai Leíró jellegű statisztika: összegzi egy adathalmaz jellemzőit. A középértéket jelemzi (medián, módus, átlag) Az adatok változékonyságát
[Biomatematika 2] Orvosi biometria 2016.02.29. A statisztika típusai Leíró jellegű statisztika: összegzi egy adathalmaz jellemzőit. A középértéket jelemzi (medián, módus, átlag) Az adatok változékonyságát
Regresszió. Csorba János. Nagyméretű adathalmazok kezelése március 31.
 Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Döntési fák. (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART ))
)") Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
Ellenőrző kérdések. 36. Ha t szintű indexet használunk, mennyi a keresési költség blokkműveletek számában mérve? (1 pont) log 2 (B(I (t) )) + t
 log 2 (B(I (t) )) + t") Ellenőrző kérdések 2. Kis dolgozat kérdései 36. Ha t szintű indexet használunk, mennyi a keresési költség blokkműveletek számában mérve? (1 pont) log 2 (B(I (t) )) + t 37. Ha t szintű indexet használunk,
Ellenőrző kérdések 2. Kis dolgozat kérdései 36. Ha t szintű indexet használunk, mennyi a keresési költség blokkműveletek számában mérve? (1 pont) log 2 (B(I (t) )) + t 37. Ha t szintű indexet használunk,
Gépi tanulás a gyakorlatban. Kiértékelés és Klaszterezés
 Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
STATISZTIKA. A maradék független a kezelés és blokk hatástól. Maradékok leíró statisztikája. 4. A modell érvényességének ellenőrzése
 4. A modell érvényességének ellenőrzése STATISZTIKA 4. Előadás Variancia-analízis Lineáris modellek 1. Függetlenség 2. Normális eloszlás 3. Azonos varianciák A maradék független a kezelés és blokk hatástól
4. A modell érvényességének ellenőrzése STATISZTIKA 4. Előadás Variancia-analízis Lineáris modellek 1. Függetlenség 2. Normális eloszlás 3. Azonos varianciák A maradék független a kezelés és blokk hatástól
Biomatematika 2 Orvosi biometria
 Biomatematika 2 Orvosi biometria 2017.02.05. Orvosi biometria (orvosi biostatisztika) Statisztika: tömegjelenségeket számadatokkal leíró tudomány. A statisztika elkészítésének menete: tanulmányok (kísérletek)
Biomatematika 2 Orvosi biometria 2017.02.05. Orvosi biometria (orvosi biostatisztika) Statisztika: tömegjelenségeket számadatokkal leíró tudomány. A statisztika elkészítésének menete: tanulmányok (kísérletek)
Hipotézis STATISZTIKA. Kétmintás hipotézisek. Munkahipotézis (H a ) Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok
 Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok") STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
c adatpontok és az ismeretlen pont közötti kovariancia vektora
 1. MELLÉKLET: Alkalmazott jelölések A mintaterület kiterjedése, területe c adatpontok és az ismeretlen pont közötti kovariancia vektora C(0) reziduális komponens varianciája C R (h) C R Cov{} d( u, X )
1. MELLÉKLET: Alkalmazott jelölések A mintaterület kiterjedése, területe c adatpontok és az ismeretlen pont közötti kovariancia vektora C(0) reziduális komponens varianciája C R (h) C R Cov{} d( u, X )
Kettőnél több csoport vizsgálata. Makara B. Gábor
 Kettőnél több csoport vizsgálata Makara B. Gábor Három gyógytápszer elemzéséből az alábbi energia tartalom adatok származtak (kilokalória/adag egységben) Három gyógytápszer elemzésébô A B C 30 5 00 10
Kettőnél több csoport vizsgálata Makara B. Gábor Három gyógytápszer elemzéséből az alábbi energia tartalom adatok származtak (kilokalória/adag egységben) Három gyógytápszer elemzésébô A B C 30 5 00 10
[Biomatematika 2] Orvosi biometria
![[Biomatematika 2] Orvosi biometria](/thumbs/54/33134285.jpg "[Biomatematika 2] Orvosi biometria") [Biomatematika 2] Orvosi biometria 2016.02.08. Orvosi biometria (orvosi biostatisztika) Statisztika: tömegjelenségeket számadatokkal leíró tudomány. A statisztika elkészítésének menete: tanulmányok (kísérletek)
[Biomatematika 2] Orvosi biometria 2016.02.08. Orvosi biometria (orvosi biostatisztika) Statisztika: tömegjelenségeket számadatokkal leíró tudomány. A statisztika elkészítésének menete: tanulmányok (kísérletek)
y ij = µ + α i + e ij
 Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai
Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai
Least Squares becslés
 Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Mérési hibák 2006.10.04. 1
 Mérési hibák 2006.10.04. 1 Mérés jel- és rendszerelméleti modellje Mérési hibák_labor/2 Mérési hibák mérési hiba: a meghatározandó értékre a mérés során kapott eredmény és ideális értéke közötti különbség
Mérési hibák 2006.10.04. 1 Mérés jel- és rendszerelméleti modellje Mérési hibák_labor/2 Mérési hibák mérési hiba: a meghatározandó értékre a mérés során kapott eredmény és ideális értéke közötti különbség
Gépi tanulás a gyakorlatban. Lineáris regresszió
 Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl sok szelet se legyen.
 KEMOMETRIA VIII-1/27 /2013 ősz CART Classification and Regression Trees Osztályozó fák Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl
KEMOMETRIA VIII-1/27 /2013 ősz CART Classification and Regression Trees Osztályozó fák Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl
Intelligens orvosi műszerek VIMIA023
 Intelligens orvosi műszerek VIMIA023 A mintapéldákból tanuló számítógépes program (egyik lehetőség): döntési fák 2018 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu
Intelligens orvosi műszerek VIMIA023 A mintapéldákból tanuló számítógépes program (egyik lehetőség): döntési fák 2018 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Egyszerű döntés Döntési fák Tanuljuk meg! Metsszük meg! Pataki Béla Bolgár Bence BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Példaprobléma:
Mesterséges Intelligencia MI Egyszerű döntés Döntési fák Tanuljuk meg! Metsszük meg! Pataki Béla Bolgár Bence BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Példaprobléma:
Gépi tanulás Gregorics Tibor Mesterséges intelligencia
 Gépi tanulás Tanulás fogalma Egy algoritmus akkor tanul, ha egy feladat megoldása során olyan változások következnek be a működésében, hogy később ugyanazt a feladatot vagy ahhoz hasonló más feladatokat
Gépi tanulás Tanulás fogalma Egy algoritmus akkor tanul, ha egy feladat megoldása során olyan változások következnek be a működésében, hogy később ugyanazt a feladatot vagy ahhoz hasonló más feladatokat
Matematikai statisztika c. tárgy oktatásának célja és tematikája
 Matematikai statisztika c. tárgy oktatásának célja és tematikája 2015 Tematika Matematikai statisztika 1. Időkeret: 12 héten keresztül heti 3x50 perc (előadás és szeminárium) 2. Szükséges előismeretek:
Matematikai statisztika c. tárgy oktatásának célja és tematikája 2015 Tematika Matematikai statisztika 1. Időkeret: 12 héten keresztül heti 3x50 perc (előadás és szeminárium) 2. Szükséges előismeretek:
Adatszerkezetek 2. Dr. Iványi Péter
 Adatszerkezetek 2. Dr. Iványi Péter 1 Fák Fákat akkor használunk, ha az adatok között valamilyen alá- és fölérendeltség van. Pl. könyvtárszerkezet gyökér (root) Nincsennek hurkok!!! 2 Bináris fák Azokat
Adatszerkezetek 2. Dr. Iványi Péter 1 Fák Fákat akkor használunk, ha az adatok között valamilyen alá- és fölérendeltség van. Pl. könyvtárszerkezet gyökér (root) Nincsennek hurkok!!! 2 Bináris fák Azokat
Populációbecslés és monitoring. Eloszlások és alapstatisztikák
 Populációbecslés és monitoring Eloszlások és alapstatisztikák Eloszlások Az eloszlás megadja, hogy milyen valószínűséggel kapunk egy adott intervallumba tartozó értéket, ha egy olyan populációból veszünk
Populációbecslés és monitoring Eloszlások és alapstatisztikák Eloszlások Az eloszlás megadja, hogy milyen valószínűséggel kapunk egy adott intervallumba tartozó értéket, ha egy olyan populációból veszünk
KÖVETKEZTETŐ STATISZTIKA
 ÁVF GM szak 2010 ősz KÖVETKEZTETŐ STATISZTIKA A MINTAVÉTEL BECSLÉS A sokasági átlag becslése 2010 ősz Utoljára módosítva: 2010-09-07 ÁVF Oktató: Lipécz György 1 A becslés alapfeladata Pl. Hányan láttak
ÁVF GM szak 2010 ősz KÖVETKEZTETŐ STATISZTIKA A MINTAVÉTEL BECSLÉS A sokasági átlag becslése 2010 ősz Utoljára módosítva: 2010-09-07 ÁVF Oktató: Lipécz György 1 A becslés alapfeladata Pl. Hányan láttak
Kabos: Statisztika II. ROC elemzések 10.1. Szenzitivitás és specificitás a jelfeldolgozás. és ilyenkor riaszt. Máskor nem.
 Kabos: Statisztika II. ROC elemzések 10.1 ROC elemzések Szenzitivitás és specificitás a jelfeldolgozás szóhasználatával A riasztóberendezés érzékeli, ha támadás jön, és ilyenkor riaszt. Máskor nem. TruePositiveAlarm:
Kabos: Statisztika II. ROC elemzések 10.1 ROC elemzések Szenzitivitás és specificitás a jelfeldolgozás szóhasználatával A riasztóberendezés érzékeli, ha támadás jön, és ilyenkor riaszt. Máskor nem. TruePositiveAlarm:
Kettőnél több csoport vizsgálata. Makara B. Gábor MTA Kísérleti Orvostudományi Kutatóintézet
 Kettőnél több csoport vizsgálata Makara B. Gábor MTA Kísérleti Orvostudományi Kutatóintézet Gyógytápszerek (kilokalória/adag) Három gyógytápszer A B C 30 5 00 10 05 08 40 45 03 50 35 190 Kérdések: 1. Van-e
Kettőnél több csoport vizsgálata Makara B. Gábor MTA Kísérleti Orvostudományi Kutatóintézet Gyógytápszerek (kilokalória/adag) Három gyógytápszer A B C 30 5 00 10 05 08 40 45 03 50 35 190 Kérdések: 1. Van-e
Véletlenszám generátorok és tesztelésük. Tossenberger Tamás
 Véletlenszám generátorok és tesztelésük Tossenberger Tamás Érdekességek Pénzérme feldobó gép: $0,25-os érme 1/6000 valószínűséggel esik az élére 51% eséllyel érkezik a felfelé mutató oldalára Pörgetésnél
Véletlenszám generátorok és tesztelésük Tossenberger Tamás Érdekességek Pénzérme feldobó gép: $0,25-os érme 1/6000 valószínűséggel esik az élére 51% eséllyel érkezik a felfelé mutató oldalára Pörgetésnél
Keresés képi jellemzők alapján. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
STATISZTIKA I. Változékonyság (szóródás) A szóródás mutatószámai. Terjedelem. Forgalom terjedelem. Excel függvények. Függvénykategória: Statisztikai
 A szóródás mutatószámai. Terjedelem. Forgalom terjedelem. Excel függvények. Függvénykategória: Statisztikai") Változékonyság (szóródás) STATISZTIKA I. 5. Előadás Szóródási mutatók A középértékek a sokaság elemeinek értéknagyságbeli különbségeit eltakarhatják. A változékonyság az azonos tulajdonságú, de eltérő
Változékonyság (szóródás) STATISZTIKA I. 5. Előadás Szóródási mutatók A középértékek a sokaság elemeinek értéknagyságbeli különbségeit eltakarhatják. A változékonyság az azonos tulajdonságú, de eltérő
6. Függvények. Legyen függvény és nem üreshalmaz. A függvényt az f K-ra való kiterjesztésének
 6. Függvények I. Elméleti összefoglaló A függvény fogalma, értelmezési tartomány, képhalmaz, értékkészlet Legyen az A és B halmaz egyike sem üreshalmaz. Ha az A halmaz minden egyes eleméhez hozzárendeljük
6. Függvények I. Elméleti összefoglaló A függvény fogalma, értelmezési tartomány, képhalmaz, értékkészlet Legyen az A és B halmaz egyike sem üreshalmaz. Ha az A halmaz minden egyes eleméhez hozzárendeljük
[1000 ; 0] 7 [1000 ; 3000]
![[1000 ; 0] 7 [1000 ; 3000]](/thumbs/88/116286101.jpg "[1000 ; 0] 7 [1000 ; 3000]") Gépi tanulás (vimim36) Gyakorló feladatok 04 tavaszi félév Ahol lehet, ott konkrét számértékeket várok nem puszta egyenleteket. (Azok egy részét amúgyis megadom.). Egy bináris osztályozási feladatra tanított
Gépi tanulás (vimim36) Gyakorló feladatok 04 tavaszi félév Ahol lehet, ott konkrét számértékeket várok nem puszta egyenleteket. (Azok egy részét amúgyis megadom.). Egy bináris osztályozási feladatra tanított
Biomatematika 2 Orvosi biometria
 Biomatematika 2 Orvosi biometria 2017.02.13. Populáció és minta jellemző adatai Hibaszámítás Valószínűség 1 Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza)
Biomatematika 2 Orvosi biometria 2017.02.13. Populáció és minta jellemző adatai Hibaszámítás Valószínűség 1 Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza)
Adatok statisztikai értékelésének főbb lehetőségei
 Adatok statisztikai értékelésének főbb lehetőségei 1. a. Egy- vagy kétváltozós eset b. Többváltozós eset 2. a. Becslési problémák, hipotézis vizsgálat b. Mintázatelemzés 3. Szint: a. Egyedi b. Populáció
Adatok statisztikai értékelésének főbb lehetőségei 1. a. Egy- vagy kétváltozós eset b. Többváltozós eset 2. a. Becslési problémák, hipotézis vizsgálat b. Mintázatelemzés 3. Szint: a. Egyedi b. Populáció
Számítógépes képelemzés 7. előadás. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Többváltozós lineáris regressziós modell feltételeinek
 Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Petrovics Petra Doktorandusz Többváltozós lineáris regressziós modell x 1, x 2,, x p
Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Petrovics Petra Doktorandusz Többváltozós lineáris regressziós modell x 1, x 2,, x p
Teljesen elosztott adatbányászat pletyka algoritmusokkal. Jelasity Márk Ormándi Róbert, Hegedűs István
 Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Mintavétel fogalmai STATISZTIKA, BIOMETRIA. Mintavételi hiba. Statisztikai adatgyűjtés. Nem véletlenen alapuló kiválasztás
 STATISZTIKA, BIOMETRIA. Előadás Mintavétel, mintavételi technikák, adatbázis Mintavétel fogalmai A mintavételt meg kell tervezni A sokaság elemei: X, X X N, lehet véges és végtelen Mintaelemek: x, x x
STATISZTIKA, BIOMETRIA. Előadás Mintavétel, mintavételi technikák, adatbázis Mintavétel fogalmai A mintavételt meg kell tervezni A sokaság elemei: X, X X N, lehet véges és végtelen Mintaelemek: x, x x
biometria II. foglalkozás előadó: Prof. Dr. Rajkó Róbert Matematikai-statisztikai adatfeldolgozás
 Kísérlettervezés - biometria II. foglalkozás előadó: Prof. Dr. Rajkó Róbert Matematikai-statisztikai adatfeldolgozás A matematikai-statisztika feladata tapasztalati adatok feldolgozásával segítséget nyújtani
Kísérlettervezés - biometria II. foglalkozás előadó: Prof. Dr. Rajkó Róbert Matematikai-statisztikai adatfeldolgozás A matematikai-statisztika feladata tapasztalati adatok feldolgozásával segítséget nyújtani
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
Hipotézis vizsgálatok
 Hipotézis vizsgálatok Hipotézisvizsgálat Hipotézis: az alapsokaság paramétereire vagy az alapsokaság eloszlására vonatkozó feltevés. Hipotézis ellenőrzés: az a statisztikai módszer, amelynek segítségével
Hipotézis vizsgálatok Hipotézisvizsgálat Hipotézis: az alapsokaság paramétereire vagy az alapsokaság eloszlására vonatkozó feltevés. Hipotézis ellenőrzés: az a statisztikai módszer, amelynek segítségével
1. ábra: Magyarországi cégek megoszlása és kockázatossága 10-es Rating kategóriák szerint. Cégek megoszlása. Fizetésképtelenné válás valószínűsége
 Bisnode Minősítés A Bisnode Minősítést a lehető legkorszerűbb, szofisztikált matematikai-statisztikai módszertannal, hazai és nemzetközi szakértők bevonásával fejlesztettük. A Minősítés a múltra vonatkozó
Bisnode Minősítés A Bisnode Minősítést a lehető legkorszerűbb, szofisztikált matematikai-statisztikai módszertannal, hazai és nemzetközi szakértők bevonásával fejlesztettük. A Minősítés a múltra vonatkozó
Osztályozás, regresszió. Nagyméretű adathalmazok kezelése Tatai Márton
 Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
R ++ -tree: an efficient spatial access method for highly redundant point data - Martin Šumák, Peter Gurský
 R ++ -tree: an efficient spatial access method for highly redundant point data - Martin Šumák, Peter Gurský Recenzió: Németh Boldizsár Térbeli indexelés Az adatszerkezetek alapvetően fontos feladata, hogy
R ++ -tree: an efficient spatial access method for highly redundant point data - Martin Šumák, Peter Gurský Recenzió: Németh Boldizsár Térbeli indexelés Az adatszerkezetek alapvetően fontos feladata, hogy
Tartalomjegyzék I. RÉSZ: KÍSÉRLETEK MEGTERVEZÉSE
 Tartalomjegyzék 5 Tartalomjegyzék Előszó I. RÉSZ: KÍSÉRLETEK MEGTERVEZÉSE 1. fejezet: Kontrollált kísérletek 21 1. A Salk-oltás kipróbálása 21 2. A porta-cava sönt 25 3. Történeti kontrollok 27 4. Összefoglalás
Tartalomjegyzék 5 Tartalomjegyzék Előszó I. RÉSZ: KÍSÉRLETEK MEGTERVEZÉSE 1. fejezet: Kontrollált kísérletek 21 1. A Salk-oltás kipróbálása 21 2. A porta-cava sönt 25 3. Történeti kontrollok 27 4. Összefoglalás
Algoritmuselmélet 2. előadás
 Algoritmuselmélet 2. előadás Katona Gyula Y. Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi Tsz. I. B. 137/b kiskat@cs.bme.hu 2002 Február 12. ALGORITMUSELMÉLET 2. ELŐADÁS 1 Buborék-rendezés
Algoritmuselmélet 2. előadás Katona Gyula Y. Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi Tsz. I. B. 137/b kiskat@cs.bme.hu 2002 Február 12. ALGORITMUSELMÉLET 2. ELŐADÁS 1 Buborék-rendezés
Struktúra nélküli adatszerkezetek
 Struktúra nélküli adatszerkezetek Homogén adatszerkezetek (minden adatelem azonos típusú) osztályozása Struktúra nélküli (Nincs kapcsolat az adatelemek között.) Halmaz Multihalmaz Asszociatív 20:24 1 A
Struktúra nélküli adatszerkezetek Homogén adatszerkezetek (minden adatelem azonos típusú) osztályozása Struktúra nélküli (Nincs kapcsolat az adatelemek között.) Halmaz Multihalmaz Asszociatív 20:24 1 A
angolul: greedy algorithms, románul: algoritmi greedy
 Mohó algoritmusok angolul: greedy algorithms, románul: algoritmi greedy 1. feladat. Gazdaságos telefonhálózat építése Bizonyos városok között lehet direkt telefonkapcsolatot kiépíteni, pl. x és y város
Mohó algoritmusok angolul: greedy algorithms, románul: algoritmi greedy 1. feladat. Gazdaságos telefonhálózat építése Bizonyos városok között lehet direkt telefonkapcsolatot kiépíteni, pl. x és y város
Matematikai geodéziai számítások 6.
 Matematikai geodéziai számítások 6. Lineáris regresszió számítás elektronikus távmérőkre Dr. Bácsatyai, László Matematikai geodéziai számítások 6.: Lineáris regresszió számítás elektronikus távmérőkre
Matematikai geodéziai számítások 6. Lineáris regresszió számítás elektronikus távmérőkre Dr. Bácsatyai, László Matematikai geodéziai számítások 6.: Lineáris regresszió számítás elektronikus távmérőkre
Populációbecslések és monitoring
 Populációbecslések és monitoring A becslés szerepe az ökológiában és a vadgazdálkodásban. A becslési módszerek csoportosítása. Teljes számlálás. Statisztikai alapfogalmak. Fontos lehet tudnunk, hogy hány
Populációbecslések és monitoring A becslés szerepe az ökológiában és a vadgazdálkodásban. A becslési módszerek csoportosítása. Teljes számlálás. Statisztikai alapfogalmak. Fontos lehet tudnunk, hogy hány
Többváltozós lineáris regressziós modell feltételeinek tesztelése I.
 Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Kvantitatív statisztikai módszerek Petrovics Petra Többváltozós lineáris regressziós
Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Kvantitatív statisztikai módszerek Petrovics Petra Többváltozós lineáris regressziós
LOGIT-REGRESSZIÓ a függő változó: névleges vagy sorrendi skála
 LOGIT-REGRESSZIÓ a függő változó: névleges vagy sorrendi skála a független változó: névleges vagy sorrendi vagy folytonos skála BIOMETRIA2_NEMPARAMÉTERES_5 1 Y: visszafizeti-e a hitelt x: fizetés (életkor)
LOGIT-REGRESSZIÓ a függő változó: névleges vagy sorrendi skála a független változó: névleges vagy sorrendi vagy folytonos skála BIOMETRIA2_NEMPARAMÉTERES_5 1 Y: visszafizeti-e a hitelt x: fizetés (életkor)
Mesterséges Intelligencia. Csató Lehel. Csató Lehel. Matematika-Informatika Tanszék Babeş Bolyai Tudományegyetem, Kolozsvár 2007/2008
 Matematika-Informatika Tanszék Babeş Bolyai Tudományegyetem, Kolozsvár 007/008 Az Előadások Témái Bevezető: mi a mesterséges intelligencia... Tudás reprezentáció i stratégiák Szemantikus hálók / Keretrendszerek
Matematika-Informatika Tanszék Babeş Bolyai Tudományegyetem, Kolozsvár 007/008 Az Előadások Témái Bevezető: mi a mesterséges intelligencia... Tudás reprezentáció i stratégiák Szemantikus hálók / Keretrendszerek
Zárthelyi dolgozat feladatainak megoldása 2003. õsz
 Zárthelyi dolgozat feladatainak megoldása 2003. õsz 1. Feladat 1. Milyen egységeket rendelhetünk az egyedi információhoz? Mekkora az átváltás közöttük? Ha 10-es alapú logaritmussal számolunk, a mértékegység
Zárthelyi dolgozat feladatainak megoldása 2003. õsz 1. Feladat 1. Milyen egységeket rendelhetünk az egyedi információhoz? Mekkora az átváltás közöttük? Ha 10-es alapú logaritmussal számolunk, a mértékegység
1. A kísérlet naiv fogalma. melyek közül a kísérlet minden végrehajtásakor pontosan egy következik be.
 IX. ESEMÉNYEK, VALÓSZÍNŰSÉG IX.1. Események, a valószínűség bevezetése 1. A kísérlet naiv fogalma. Kísérlet nek nevezzük egy olyan jelenség előidézését vagy megfigyelését, amelynek kimenetelét az általunk
IX. ESEMÉNYEK, VALÓSZÍNŰSÉG IX.1. Események, a valószínűség bevezetése 1. A kísérlet naiv fogalma. Kísérlet nek nevezzük egy olyan jelenség előidézését vagy megfigyelését, amelynek kimenetelét az általunk
Számítógépes döntéstámogatás. Genetikus algoritmusok
 BLSZM-10 p. 1/18 Számítógépes döntéstámogatás Genetikus algoritmusok Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu BLSZM-10 p. 2/18 Bevezetés 1950-60-as
BLSZM-10 p. 1/18 Számítógépes döntéstámogatás Genetikus algoritmusok Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu BLSZM-10 p. 2/18 Bevezetés 1950-60-as
Adatbányászati szemelvények MapReduce környezetben
 Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Felvételi tematika INFORMATIKA
 Felvételi tematika INFORMATIKA 2016 FEJEZETEK 1. Természetes számok feldolgozása számjegyenként. 2. Számsorozatok feldolgozása elemenként. Egydimenziós tömbök. 3. Mátrixok feldolgozása elemenként/soronként/oszloponként.
Felvételi tematika INFORMATIKA 2016 FEJEZETEK 1. Természetes számok feldolgozása számjegyenként. 2. Számsorozatok feldolgozása elemenként. Egydimenziós tömbök. 3. Mátrixok feldolgozása elemenként/soronként/oszloponként.
y ij = µ + α i + e ij STATISZTIKA Sir Ronald Aylmer Fisher Példa Elmélet A variancia-analízis alkalmazásának feltételei Lineáris modell
 Példa STATISZTIKA Egy gazdálkodó k kukorica hibrid termesztése között választhat. Jelöljük a fajtákat A, B, C, D-vel. Döntsük el, hogy a hibridek termesztése esetén azonos terméseredményre számíthatunk-e.
Példa STATISZTIKA Egy gazdálkodó k kukorica hibrid termesztése között választhat. Jelöljük a fajtákat A, B, C, D-vel. Döntsük el, hogy a hibridek termesztése esetén azonos terméseredményre számíthatunk-e.
Gépi tanulás. Féligellenőrzött tanulás. Pataki Béla (Bolgár Bence)
") Gépi tanulás Féligellenőrzött tanulás Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Féligellenőrzött tanulás Mindig kevés az adat, de
Gépi tanulás Féligellenőrzött tanulás Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Féligellenőrzött tanulás Mindig kevés az adat, de
A maximum likelihood becslésről
 A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
Logisztikus regresszió
 Logisztikus regresszió 9. előadás Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó () Nem metrikus Metrikus Kereszttábla
Logisztikus regresszió 9. előadás Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó () Nem metrikus Metrikus Kereszttábla
Populációbecslések és monitoring
 Populációbecslések és monitoring A becslés szerepe az ökológiában és a vadgazdálkodásban. A becslési módszerek csoportosítása. Teljes számlálás. Statisztikai alapfogalmak. Fontos lehet tudnunk, hogy hány
Populációbecslések és monitoring A becslés szerepe az ökológiában és a vadgazdálkodásban. A becslési módszerek csoportosítása. Teljes számlálás. Statisztikai alapfogalmak. Fontos lehet tudnunk, hogy hány
Logisztikus regresszió
 Logisztikus regresszió Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó (x) Nem metrikus Metrikus Kereszttábla elemzés
Logisztikus regresszió Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó (x) Nem metrikus Metrikus Kereszttábla elemzés
A valós számok halmaza
 VA 1 A valós számok halmaza VA 2 A valós számok halmazának axiómarendszere és alapvető tulajdonságai Definíció Az R halmazt a valós számok halmazának nevezzük, ha teljesíti a következő axiómarendszerben
VA 1 A valós számok halmaza VA 2 A valós számok halmazának axiómarendszere és alapvető tulajdonságai Definíció Az R halmazt a valós számok halmazának nevezzük, ha teljesíti a következő axiómarendszerben
ALÁÍRÁS NÉLKÜL A TESZT ÉRVÉNYTELEN!
 A1 A2 A3 (8) A4 (12) A (40) B1 B2 B3 (15) B4 (11) B5 (14) Bónusz (100+10) Jegy NÉV (nyomtatott nagybetűvel) CSOPORT: ALÁÍRÁS: ALÁÍRÁS NÉLKÜL A TESZT ÉRVÉNYTELEN! 2011. december 29. Általános tudnivalók:
A1 A2 A3 (8) A4 (12) A (40) B1 B2 B3 (15) B4 (11) B5 (14) Bónusz (100+10) Jegy NÉV (nyomtatott nagybetűvel) CSOPORT: ALÁÍRÁS: ALÁÍRÁS NÉLKÜL A TESZT ÉRVÉNYTELEN! 2011. december 29. Általános tudnivalók:
17. A 2-3 fák és B-fák. 2-3 fák
 17. A 2-3 fák és B-fák 2-3 fák Fontos jelentősége, hogy belőlük fejlődtek ki a B-fák. Def.: Minden belső csúcsnak 2 vagy 3 gyermeke van. A levelek egy szinten helyezkednek el. Az adatrekordok/kulcsok csak
17. A 2-3 fák és B-fák 2-3 fák Fontos jelentősége, hogy belőlük fejlődtek ki a B-fák. Def.: Minden belső csúcsnak 2 vagy 3 gyermeke van. A levelek egy szinten helyezkednek el. Az adatrekordok/kulcsok csak
Matematikai geodéziai számítások 6.
 Nyugat-magyarországi Egyetem Geoinformatikai Kara Dr. Bácsatyai László Matematikai geodéziai számítások 6. MGS6 modul Lineáris regresszió számítás elektronikus távmérőkre SZÉKESFEHÉRVÁR 2010 Jelen szellemi
Nyugat-magyarországi Egyetem Geoinformatikai Kara Dr. Bácsatyai László Matematikai geodéziai számítások 6. MGS6 modul Lineáris regresszió számítás elektronikus távmérőkre SZÉKESFEHÉRVÁR 2010 Jelen szellemi
Biometria az orvosi gyakorlatban. Korrelációszámítás, regresszió
 SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
Tanulás az idegrendszerben. Structure Dynamics Implementation Algorithm Computation - Function
 Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
E x μ x μ K I. és 1. osztály. pontokként), valamint a bayesi döntést megvalósító szeparáló görbét (kék egyenes)
, valamint a bayesi döntést megvalósító szeparáló görbét (kék egyenes)") 6-7 ősz. gyakorlat Feladatok.) Adjon meg azt a perceptronon implementált Bayes-i klasszifikátort, amely kétdimenziós a bemeneti tér felett szeparálja a Gauss eloszlású mintákat! Rajzolja le a bemeneti
6-7 ősz. gyakorlat Feladatok.) Adjon meg azt a perceptronon implementált Bayes-i klasszifikátort, amely kétdimenziós a bemeneti tér felett szeparálja a Gauss eloszlású mintákat! Rajzolja le a bemeneti
JAVASLAT A TOP-K ELEMCSERÉK KERESÉSÉRE NAGY ONLINE KÖZÖSSÉGEKBEN
 JAVASLAT A TOP-K ELEMCSERÉK KERESÉSÉRE NAGY ONLINE KÖZÖSSÉGEKBEN Supporting Top-k item exchange recommendations in large online communities Barabás Gábor Nagy Dávid Nemes Tamás Probléma Cserekereskedelem
JAVASLAT A TOP-K ELEMCSERÉK KERESÉSÉRE NAGY ONLINE KÖZÖSSÉGEKBEN Supporting Top-k item exchange recommendations in large online communities Barabás Gábor Nagy Dávid Nemes Tamás Probléma Cserekereskedelem
[Biomatematika 2] Orvosi biometria
![[Biomatematika 2] Orvosi biometria](/thumbs/47/23623719.jpg "[Biomatematika 2] Orvosi biometria") [Biomatematika 2] Orvosi biometria 2016.02.15. Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza) alkotja az eseményteret. Esemény: az eseménytér részhalmazai.
[Biomatematika 2] Orvosi biometria 2016.02.15. Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza) alkotja az eseményteret. Esemény: az eseménytér részhalmazai.
Bizonytalanság. Mesterséges intelligencia április 4.
 Bizonytalanság Mesterséges intelligencia 2014. április 4. Bevezetés Eddig: logika, igaz/hamis Ha nem teljes a tudás A világ nem figyelhető meg közvetlenül Részleges tudás nem reprezentálható logikai eszközökkel
Bizonytalanság Mesterséges intelligencia 2014. április 4. Bevezetés Eddig: logika, igaz/hamis Ha nem teljes a tudás A világ nem figyelhető meg közvetlenül Részleges tudás nem reprezentálható logikai eszközökkel
2. Visszalépéses keresés
 2. Visszalépéses keresés Visszalépéses keresés A visszalépéses keresés egy olyan KR, amely globális munkaterülete: egy út a startcsúcsból az aktuális csúcsba (az útról leágazó még ki nem próbált élekkel
2. Visszalépéses keresés Visszalépéses keresés A visszalépéses keresés egy olyan KR, amely globális munkaterülete: egy út a startcsúcsból az aktuális csúcsba (az útról leágazó még ki nem próbált élekkel
Asszociációs szabályok
 Asszociációs szabályok Nikházy László Nagy adathalmazok kezelése 2010. március 10. Mi az értelme? A ö asszociációs szabály azt állítja, hogy azon vásárlói kosarak, amik tartalmaznak pelenkát, általában
Asszociációs szabályok Nikházy László Nagy adathalmazok kezelése 2010. március 10. Mi az értelme? A ö asszociációs szabály azt állítja, hogy azon vásárlói kosarak, amik tartalmaznak pelenkát, általában
7. Régió alapú szegmentálás
 Digitális képek szegmentálása 7. Régió alapú szegmentálás Kató Zoltán http://www.cab.u-szeged.hu/~kato/segmentation/ Szegmentálási kritériumok Particionáljuk a képet az alábbi kritériumokat kielégítő régiókba
Digitális képek szegmentálása 7. Régió alapú szegmentálás Kató Zoltán http://www.cab.u-szeged.hu/~kato/segmentation/ Szegmentálási kritériumok Particionáljuk a képet az alábbi kritériumokat kielégítő régiókba
Gépi tanulás a gyakorlatban. Bevezetés
 Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
Sorozatok határértéke SOROZAT FOGALMA, MEGADÁSA, ÁBRÁZOLÁSA; KORLÁTOS ÉS MONOTON SOROZATOK
 Sorozatok határértéke SOROZAT FOGALMA, MEGADÁSA, ÁBRÁZOLÁSA; KORLÁTOS ÉS MONOTON SOROZATOK Sorozat fogalma Definíció: Számsorozaton olyan függvényt értünk, amelynek értelmezési tartománya a pozitív egész
Sorozatok határértéke SOROZAT FOGALMA, MEGADÁSA, ÁBRÁZOLÁSA; KORLÁTOS ÉS MONOTON SOROZATOK Sorozat fogalma Definíció: Számsorozaton olyan függvényt értünk, amelynek értelmezési tartománya a pozitív egész
Az egyenes egyenlete: 2 pont. Az összevont alak: 1 pont. Melyik ábrán látható e függvény grafikonjának egy részlete?
 1. Írja fel annak az egyenesnek az egyenletét, amely áthalad az (1; 3) ponton, és egyik normálvektora a (8; 1) vektor! Az egyenes egyenlete: 2. Végezze el a következő műveleteket, és vonja össze az egynemű
1. Írja fel annak az egyenesnek az egyenletét, amely áthalad az (1; 3) ponton, és egyik normálvektora a (8; 1) vektor! Az egyenes egyenlete: 2. Végezze el a következő műveleteket, és vonja össze az egynemű
Adaptív dinamikus szegmentálás idősorok indexeléséhez
 Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Matematikai alapok és valószínőségszámítás. Statisztikai becslés Statisztikák eloszlása
 Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
Programozás alapjai 9. előadás. Wagner György Általános Informatikai Tanszék
 9. előadás Wagner György Általános Informatikai Tanszék Leszámoló rendezés Elve: a rendezett listában a j-ik kulcs pontosan j-1 kulcsnál lesz nagyobb. (Ezért ha egy kulcsról tudjuk, hogy 27 másiknál nagyobb,
9. előadás Wagner György Általános Informatikai Tanszék Leszámoló rendezés Elve: a rendezett listában a j-ik kulcs pontosan j-1 kulcsnál lesz nagyobb. (Ezért ha egy kulcsról tudjuk, hogy 27 másiknál nagyobb,
STATISZTIKA. Egymintás u-próba. H 0 : Kefir zsírtartalma 3% Próbafüggvény, alfa=0,05. Egymintás u-próba vagy z-próba
 Egymintás u-próba STATISZTIKA 2. Előadás Középérték-összehasonlító tesztek Tesztelhetjük, hogy a valószínűségi változónk értéke megegyezik-e egy konkrét értékkel. Megválaszthatjuk a konfidencia intervallum
Egymintás u-próba STATISZTIKA 2. Előadás Középérték-összehasonlító tesztek Tesztelhetjük, hogy a valószínűségi változónk értéke megegyezik-e egy konkrét értékkel. Megválaszthatjuk a konfidencia intervallum