Haladó Grafika EA. Inkrementális képszintézis GPU-n
|
|
|
- Róbert Gál
- 8 évvel ezelőtt
- Látták:
Átírás
1 Haladó Grafika EA Inkrementális képszintézis GPU-n
2 Pipeline Az elvégzendő feladatot részfeladatokra bontjuk Mindegyik részfeladatot más-más egység dolgozza fel (ideális esetben) Minden egység inputja, a pipeline-ban őt megelőző egység outputja
3 Pipeline Ha elkészült egy egység a részfeladatával, akkor továbbadja az eredményt nem kell megvárnia, hogy befejeződjön a munka az egész munkadarabon n fázis (stage) bevezetése optimális esetben n-szeres gyorsulást jelent (felfutás után) Nem csak GPU! Már a Pentium IV-nek is 20 pipeline stage-e volt (egy GeForce 3-nak 6-800)

4 Pipeline Vigyázzunk: ha egy részfeladat sokáig tart, akkor az előtte és utána lévők hiába készülnek el, nem tudnak tovább dolgozni a pipeline sebességét a leglassabb komponense határozza meg
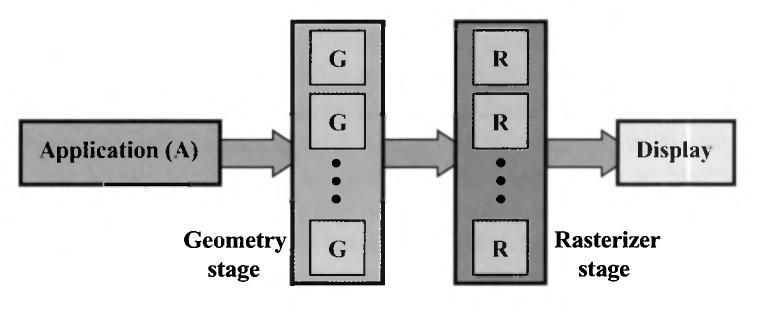
5 Pipeline application stage A CPU-n futó programunkat jelképezi, általános hw-n Feladata a kirajzolandó geometria előállítása (primitívek), és továbbadása a köv. fázisba. Ütközésvizsgálat, gyorsítási adatszerkezetek és műveletek megvalósítása (pl. frustum culling) a felhasználói input kezelése transzformációk módosítása/animálása
6 Pipeline geometry stage A per-vertex és per-poligon műveletek itt zajlanak (és ma már per-patch is) Egy ideje már GPU-n Funkcionálisan a következő alfázisokra bontható: Világ és nézeti transzformáció Vertex és geometry shading/tesszeláció Vetítés Vágás Képernyő leképezés (NDC képernyő (egész) pixelkoordinátái ff: DX9-ig hol a pixel közép...)
7 Pipeline geometry stage
8 Pipeline rasterizer stage Az előző fázis eredményének felhasználásával a feldolgozott primitív által lefedett pixelek színének kiszámítása...azaz a fragmentjeinek kiszínezése Per-pixel/fragment számítások helye Deriváltak stb. kiszámítása Bedrótozva a hw-be Fragment színének kiszámítása, textúrázás, megvilágítás stb. - programozható Color buffer-be illesztése a fragment Mely pixelek középpontjait fedi le a háromszög és adatok interpolációja - ez is bedrótozva a hw-be színének konfigurálható, de nem programozható (még...)
9 GPU implementáció Ahogy előző előadáson láttuk: bedrótozott konfigurálható programozható irányvonal mentén halad
10 GPU implementáció Programozható fázisok (shaderek): Vertex Geometry Tesselation Fragment Unified shading model óta ugyanolyan gpu magokon futnak (desktopon)
11 GPU implementáció

12 GPU implementáció párhuzamosítások FG = fragment generation FM = fragment merging
13 GPU implementáció párhuzamosítások Sort first: Cél: osszuk fel a képernyőt területekre, és az ezekbe eső primitívek egy olyan pipeline-ra kerülnek, amelyiké az adott terület Primitívek rendezése, geometriai fázis egy részét el kell hozzá végezni Ritka
14 GPU implementáció párhuzamosítások Sort middle: Ötlet: a raszterizálást csináljuk csak régiókra, tileokra bontva A primitív ahhoz/azokhoz a raszterizáló(k)hoz kerül(nek), aki(k)nek a tile-jába belemetsz Globális post-process effektek, amelyek tetszőleges pixel-szomszédságot igényelnek (motion blur stb.) problémásak ilyen architektúrán a tile-ok közti kommunikáció igénye miatt Pl.: Mali GPU-k
15 GPU implementáció párhuzamosítások Sort last fragment: FG után, de FM előtt jöjjön a rendezés egy fragment egy FM-hez kerül, ez az optimum Pl.: Playstation 3
16 GPU implementáció párhuzamosítások Sort last image: Tekinthető független pipeline-ok rendszerének is FG és FM után jön csak a rendezés A különböző objektumokat különböz processzorok dolgozzák fel
17 GPU implementáció - trükkök Z-culling: Ha nincs z adat módosítás Eldönteni, hogy a háromszög egy része az adott területen takarva lesz-e mélység alapján (közelítés háromszög csúcspontjainak mélysége stb. alapján) Early-Z: Fragment mélységi értéke alapján tudjuk még a drága fragment shader lefuttatása előtt, hogy a fragment shaderbe beérkező fragment takarva vane már Pontos mélységi érték alapján eldobás, ha takarva van
18 Vashöz közelebb
19 CPU felépítése Vezérlés és nem a nyers aritmetikai teljesítmény a hangsúlyosabb (ALU<32 ált.) A CPU-knál elsődleges egy-egy szál késleltetésének a minimalizálása Control Logic L2 Cache L3 Cache ALU L1 Cache ~ 25GBPS System Memory
20 GPU felépítése Kevesebb vezérlés, több ALU magonként High Bandwidth bus to ALUs On Board System Memory Simple ALUs Cache
21 ATI/AMD
 2.72 Teraflops Single Precision 544 Gigaflops Double Precision Source: Introductory OpenCL SAAHPC2010, Benedict R.")
22 AMD GPU Hardware Architecture AMD 5870 Cypress 20 SIMD engines 16 SIMD units per core Perhaad Mistry & Dana Schaa, Northeastern Univ 5 multiply-adds per functional unit (VLIW processing) 2.72 Teraflops Single Precision 544 Gigaflops Double Precision Source: Introductory OpenCL SAAHPC2010, Benedict R. Gaster 22
23 SIMD Engine One SIMD Engine A SIMD engine consists of a set of Stream s Stream cores arranged as a five way Very Long Instruction Word (VLIW) processor Up to five scalar operations can be issued in a VLIW instruction Scalar operations executed on each processing element Stream cores within compute unitmistry execute Perhaad & Danasame VLIW Schaa, Northeastern Univ One Stream Instruction and Control Flow T-Processing Element Branch Execution Unit Processing Elements General Purpose Registers Source: AMD Accelerated Parallel Processing OpenCL Programming Guide 23
24 NVIDIA
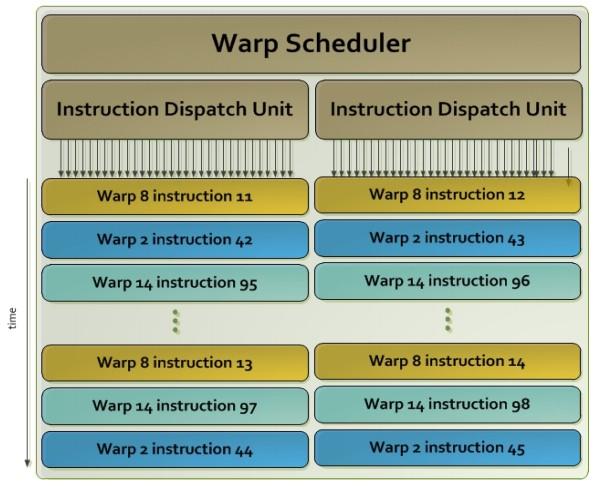
25 Nvidia GPUs - Fermi Architecture Instruction Cache GTX Compute 2.0 capability Warp Scheduler Warp Scheduler Dispatch Unit Dispatch Unit Register File x 32bit 15 cores or Streaming Multiprocessors (SMs) Each SM features 32 CUDA processors 480 CUDA processors Global memory with ECC SFU SFU CUDA SFU Dispatch Port Operand Collector Source: NVIDIA s Next Generation CUDA Architecture Whitepaper FP Unit Int Unit Result Queue Perhaad Mistry & Dana Schaa, Northeastern Univ SFU Interconnect Memory L1 Cache / 64kB Shared Memory L2 Cache 25
26 Nvidia GPUs Fermi Architecture SM executes threads in groups of 32 called warps. Instruction Cache Warp Scheduler Warp Scheduler Dispatch Unit Dispatch Unit Two warp issue units per SM Register File x 32bit Concurrent kernel execution Execute multiple kernels simultaneously to improve efficiency CUDA core consists of a single ALU and floating point unit FPU SFU SFU CUDA SFU Dispatch Port Operand Collector Source: NVIDIA s Next Generation CUDA Compute Architecture Whitepaper FP Unit Int Unit Result Queue Perhaad Mistry & Dana Schaa, Northeastern Univ SFU Interconnect Memory L1 Cache / 64kB Shared Memory L2 Cache 26

27 NVIDIA Kepler Teljes Kepler 15 SMX egységből áll és hat 64 bites memóriavezérlőből
28 SMX egység SMX = Streaming Multiprocessor, megnövelt duplapontosságú teljesítménnyel Multiprocesszor: valahány streamprocessor csoportja (Tesla = 8, Fermi = 2x16) Kepler-ben: 192 egyszeres pontosságú CUDA core SFU: special function unit a különleges dolgokhoz (inverse square root, sin, cos, transzcend fv közelítések stb.) Warp: 32 szál
29
30 SIMT Single Instruction, Multiple Thread Step lock-ban mennek az egy csoporthoz tartozó stream processorok, ugyanazt az utasítást hajtják végre, csak más adatokon
31 PowerVR
32 PowerVR Elsősorban mobileszközökhöz, de skálázható eszközök, GPGPU-t is támogatnak (CPU kisegítésére) Universal Scalable Shader Engine mag (és nő) 32x32-es tile-okra osztja a képernyőt Pl.: ipad, iphone, iakármi, Samsung Galaxy S, Tab, Wave I, II... Több infó:

33 Tile alapú rajzolás
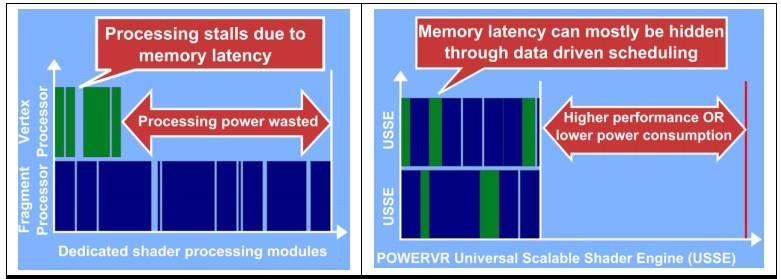
34 USSE

35 Tile Accelerator Vágás, vetítés, cull hagyományos szerelőszalagnál a vertex shadert hajtja végre
 TSP = Texture and")
36 Image Synthesis Processor Tile-onkénti láthatóságvizsgálat (takarás) TSP = Texture and Shading Processor

37 PowerVR SGX Series5XT
38 ARM Mali

39 ARM Mali Nem csak GPU-kat gyártanak és nem csak mobileszközökre Mali 400 MP 1-4 magos Más Mali eszközökkel integrálható Pl.: Samsung Galaxy S2
40 Qualcomm Adreno

41 Qualcomm Adreno Pl.: HTC telefonok (Desire, Evo stb.) Ők is forradalmiak :
42 NVIDIA (megint)

43 Ultra low power GeForce
44 API-k

45 API-k OpenGL ES
46 API-k OpenVG Vektorgrafikákra Microsoft Direct3D Mobile
GPGPU. GPU-k felépítése. Valasek Gábor
 GPGPU GPU-k felépítése Valasek Gábor Tartalom A mai órán áttekintjük a GPU-k architekturális felépítését A cél elsősorban egy olyan absztrakt hardvermodell bemutatása, ami segít megérteni a GPU-k hardveres
GPGPU GPU-k felépítése Valasek Gábor Tartalom A mai órán áttekintjük a GPU-k architekturális felépítését A cél elsősorban egy olyan absztrakt hardvermodell bemutatása, ami segít megérteni a GPU-k hardveres
GPGPU. Architektúra esettanulmány
 GPGPU Architektúra esettanulmány GeForce 7800 (2006) GeForce 7800 Rengeteg erőforrást fordítottak arra, hogy a throughput-ot maximalizálják Azaz a különböző típusú feldolgozóegységek (vertex és fragment
GPGPU Architektúra esettanulmány GeForce 7800 (2006) GeForce 7800 Rengeteg erőforrást fordítottak arra, hogy a throughput-ot maximalizálják Azaz a különböző típusú feldolgozóegységek (vertex és fragment
Grafikus csővezeték 1 / 44
 Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
GPGPU alapok. GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai
 GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
Párhuzamos és Grid rendszerek
 Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási
 GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
OpenCL - The open standard for parallel programming of heterogeneous systems
 OpenCL - The open standard for parallel programming of heterogeneous systems GPU-k általános számításokhoz GPU Graphics Processing Unit Képalkotás: sok, általában egyszerű és független művelet < 2006:
OpenCL - The open standard for parallel programming of heterogeneous systems GPU-k általános számításokhoz GPU Graphics Processing Unit Képalkotás: sok, általában egyszerű és független művelet < 2006:
Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd.
 1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
Direct3D pipeline. Grafikus játékok fejlesztése Szécsi László t03-pipeline
 Direct3D pipeline Grafikus játékok fejlesztése Szécsi László 2013.02.12. t03-pipeline RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
Direct3D pipeline Grafikus játékok fejlesztése Szécsi László 2013.02.12. t03-pipeline RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
2. Generáció (1999-2000) 3. Generáció (2001) NVIDIA TNT2, ATI Rage, 3dfx Voodoo3. Klár Gergely tremere@elte.hu
 3. Generáció (2001) NVIDIA TNT2, ATI Rage, 3dfx Voodoo3. Klár Gergely tremere@elte.hu") 1. Generáció Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. őszi félév NVIDIA TNT2, ATI Rage, 3dfx Voodoo3 A standard 2d-s videokártyák kiegészítése
1. Generáció Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. őszi félév NVIDIA TNT2, ATI Rage, 3dfx Voodoo3 A standard 2d-s videokártyák kiegészítése
Diplomamunka. Miskolci Egyetem. GPGPU technológia kriptográfiai alkalmazása. Készítette: Csikó Richárd VIJFZK mérnök informatikus
 Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre
 GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
HLSL programozás. Grafikus játékok fejlesztése Szécsi László t06-hlsl
 HLSL programozás Grafikus játékok fejlesztése Szécsi László 2013.02.16. t06-hlsl RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
HLSL programozás Grafikus játékok fejlesztése Szécsi László 2013.02.16. t06-hlsl RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
Google Summer of Code OpenCL image support for the r600g driver
 Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
Valasek Gábor
 Valasek Gábor valasek@inf.elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2011/2012. őszi félév Tartalom 1 Textúrázás Bevezetés Textúra leképezés Paraméterezés Textúra szűrés Procedurális textúrák
Valasek Gábor valasek@inf.elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2011/2012. őszi félév Tartalom 1 Textúrázás Bevezetés Textúra leképezés Paraméterezés Textúra szűrés Procedurális textúrák
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA. Dr. Szénási Sándor
 KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
ARM processzorok felépítése
 ARM processzorok felépítése Az ARM processzorok több családra bontható közösséget alkotnak. Az Cortex-A sorozatú processzorok, ill. az azokból felépülő mikrokontrollerek a high-end kategóriájú, nagy teljesítményű
ARM processzorok felépítése Az ARM processzorok több családra bontható közösséget alkotnak. Az Cortex-A sorozatú processzorok, ill. az azokból felépülő mikrokontrollerek a high-end kategóriájú, nagy teljesítményű
A CUDA előnyei: - Elszórt memória olvasás (az adatok a memória bármely területéről olvashatóak) PC-Vilag.hu CUDA, a jövő technológiája?!
 PC-Vilag.hu CUDA, a jövő technológiája?!") A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
Grafikus csővezeték 2 / 77
 Bevezetés 1 / 77 Grafikus csővezeték 2 / 77 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve
Bevezetés 1 / 77 Grafikus csővezeték 2 / 77 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve
Grafikus csővezeték és az OpenGL függvénykönyvtár
 Grafikus csővezeték és az OpenGL függvénykönyvtár 1 / 32 A grafikus csővezeték 3D-s színtér objektumainak leírása primitívekkel: pontok, élek, poligonok. Primitívek szögpontjait vertexeknek nevezzük Adott
Grafikus csővezeték és az OpenGL függvénykönyvtár 1 / 32 A grafikus csővezeték 3D-s színtér objektumainak leírása primitívekkel: pontok, élek, poligonok. Primitívek szögpontjait vertexeknek nevezzük Adott
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Klár Gergely 2010/2011. tavaszi félév
 Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. tavaszi félév Tartalom Generációk Shader Model 3.0 (és korábban) Shader Model 4.0 Shader Model
Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. tavaszi félév Tartalom Generációk Shader Model 3.0 (és korábban) Shader Model 4.0 Shader Model
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
OpenCL Kovács, György
 OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
Nagy adattömbökkel végzett FORRÓ TI BOR tudományos számítások lehetőségei. kisszámítógépes rendszerekben. Kutató Intézet
 Nagy adattömbökkel végzett FORRÓ TI BOR tudományos számítások lehetőségei Kutató Intézet kisszámítógépes rendszerekben Tudományos számításokban gyakran nagy mennyiségű aritmetikai művelet elvégzésére van
Nagy adattömbökkel végzett FORRÓ TI BOR tudományos számítások lehetőségei Kutató Intézet kisszámítógépes rendszerekben Tudományos számításokban gyakran nagy mennyiségű aritmetikai művelet elvégzésére van
Információ megjelenítés Számítógépes ábrázolás. Dr. Iványi Péter
 Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter (adat szerkezet) float x,y,z,w; float r,g,b,a; } vertex; glcolor3f(0, 0.5, 0); glvertex2i(11, 31); glvertex2i(37, 71); glcolor3f(0.5, 0,
Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter (adat szerkezet) float x,y,z,w; float r,g,b,a; } vertex; glcolor3f(0, 0.5, 0); glvertex2i(11, 31); glvertex2i(37, 71); glcolor3f(0.5, 0,
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Információ megjelenítés Számítógépes ábrázolás. Dr. Iványi Péter
 Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter Raszterizáció OpenGL Mely pixelek vannak a primitíven belül fragment generálása minden ilyen pixelre Attribútumok (pl., szín) hozzárendelése
Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter Raszterizáció OpenGL Mely pixelek vannak a primitíven belül fragment generálása minden ilyen pixelre Attribútumok (pl., szín) hozzárendelése
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
8. Fejezet Processzor (CPU) és memória: tervezés, implementáció, modern megoldások
 és memória: tervezés, implementáció, modern megoldások") 8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15 Fehér
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15 Fehér
Magas szintű optimalizálás
 Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
Heterogén számítási rendszerek
 Heterogén számítási rendszerek GPU-k, GPGPU CUDA, OpenCL Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális koordináta rendszerből
Heterogén számítási rendszerek GPU-k, GPGPU CUDA, OpenCL Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális koordináta rendszerből
8. Fejezet Processzor (CPU) és memória: tervezés, implementáció, modern megoldások
 és memória: tervezés, implementáció, modern megoldások") 8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely
 Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
HLSL programozás. Szécsi László
 HLSL programozás Szécsi László RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant buffers and textures Output buffer Constant buffers
HLSL programozás Szécsi László RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant buffers and textures Output buffer Constant buffers
SZÁMÍTÓGÉP ARCHITEKTÚRÁK
 SZÁMÍTÓGÉP ARCHITEKTÚRÁK Az utasítás-pipeline szélesítése Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-05-19 1 UTASÍTÁSFELDOLGOZÁS
SZÁMÍTÓGÉP ARCHITEKTÚRÁK Az utasítás-pipeline szélesítése Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-05-19 1 UTASÍTÁSFELDOLGOZÁS
Grafikus processzorok általános célú programozása (GPGPU)
") 2015. szeptember 17. Grafikus processzorok általános célú programozása (GPGPU) Eichhardt I., Hajder L. és V. Gábor eichhardt.ivan@sztaki.mta.hu, hajder.levente@sztaki.mta.hu, valasek@inf.elte.hu Eötvös
2015. szeptember 17. Grafikus processzorok általános célú programozása (GPGPU) Eichhardt I., Hajder L. és V. Gábor eichhardt.ivan@sztaki.mta.hu, hajder.levente@sztaki.mta.hu, valasek@inf.elte.hu Eötvös
VLIW processzorok (Működési elvük, jellemzőik, előnyeik, hátrányaik, kereskedelmi rendszerek)
") SzA35. VLIW processzorok (Működési elvük, jellemzőik, előnyeik, hátrányaik, kereskedelmi rendszerek) Működési elvük: Jellemzőik: -függőségek kezelése statikusan, compiler által -hátránya: a compiler erősen
SzA35. VLIW processzorok (Működési elvük, jellemzőik, előnyeik, hátrányaik, kereskedelmi rendszerek) Működési elvük: Jellemzőik: -függőségek kezelése statikusan, compiler által -hátránya: a compiler erősen
Plakátok, részecskerendszerek. Szécsi László
 Plakátok, részecskerendszerek Szécsi László Képalapú festés Montázs: képet képekből 2D grafika jellemző eszköze modell: kép [sprite] 3D 2D képével helyettesítsük a komplex geometriát Image-based rendering
Plakátok, részecskerendszerek Szécsi László Képalapú festés Montázs: képet képekből 2D grafika jellemző eszköze modell: kép [sprite] 3D 2D képével helyettesítsük a komplex geometriát Image-based rendering
OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA
 Multidiszciplináris tudományok, 3. kötet. (2013) sz. pp. 259-268. OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA Mileff Péter Adjunktus, Miskolci Egyetem, Informatikai Intézet, Általános
Multidiszciplináris tudományok, 3. kötet. (2013) sz. pp. 259-268. OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA Mileff Péter Adjunktus, Miskolci Egyetem, Informatikai Intézet, Általános
2D képszintézis. Szirmay-Kalos László
 2D képszintézis Szirmay-Kalos László 2D képszintézis Modell szín (200, 200) Kép Kamera ablak (window) viewport Unit=pixel Saját színnel rajzolás Világ koordinátarendszer Pixel vezérelt megközelítés: Tartalmazás
2D képszintézis Szirmay-Kalos László 2D képszintézis Modell szín (200, 200) Kép Kamera ablak (window) viewport Unit=pixel Saját színnel rajzolás Világ koordinátarendszer Pixel vezérelt megközelítés: Tartalmazás
ARM Cortex magú mikrovezérlők
 ARM Cortex magú mikrovezérlők 3. Cortex-M0, M4, M7 Scherer Balázs Budapest University of Technology and Economics Department of Measurement and Information Systems BME-MIT 2018 32 bites trendek 2003-2017
ARM Cortex magú mikrovezérlők 3. Cortex-M0, M4, M7 Scherer Balázs Budapest University of Technology and Economics Department of Measurement and Information Systems BME-MIT 2018 32 bites trendek 2003-2017
Számítógépek felépítése
 Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Bevitel-Kivitel. Eddig a számítógép agyáról volt szó. Szükség van eszközökre. Processzusok, memória, stb
 Input és Output 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel és kivitel a számitógépből, -be Perifériák 2 Perifériákcsoportosításá,
Input és Output 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel és kivitel a számitógépből, -be Perifériák 2 Perifériákcsoportosításá,
GPGPU programozás lehetőségei. Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café
 GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
Grafikus kártyák, mint olcsó szuperszámítógépek - I.
 (1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport (2) Vázlat I. Motiváció Beüzemelés C alapok CUDA programozási modell,
(1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport (2) Vázlat I. Motiváció Beüzemelés C alapok CUDA programozási modell,
Utolsó módosítás:
 Utolsó módosítás: 2012. 09. 06. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 Forrás: Gartner Hype Cycle for Virtualization, 2010, http://premierit.intel.com/docs/doc-5768
Utolsó módosítás: 2012. 09. 06. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 Forrás: Gartner Hype Cycle for Virtualization, 2010, http://premierit.intel.com/docs/doc-5768
D3D, DXUT primer. Grafikus játékok fejlesztése Szécsi László t01-system
 D3D, DXUT primer Grafikus játékok fejlesztése Szécsi László 2013.02.13. t01-system Háromszögháló reprezentáció Mesh Vertex buffer Index buffer Vertex buffer csúcs-rekordok tömbje pos normal tex pos normal
D3D, DXUT primer Grafikus játékok fejlesztése Szécsi László 2013.02.13. t01-system Háromszögháló reprezentáció Mesh Vertex buffer Index buffer Vertex buffer csúcs-rekordok tömbje pos normal tex pos normal
Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15 Fehér
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15 Fehér
Grafika programozása
 MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Grafika programozása Tárgyi jegyzet (béta változat) KÉSZÍTETTE: DR. MILEFF PÉTER Miskolci Egyetem Általános Informatikai Tanszék 2015. Tartalomjegyzék
MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Grafika programozása Tárgyi jegyzet (béta változat) KÉSZÍTETTE: DR. MILEFF PÉTER Miskolci Egyetem Általános Informatikai Tanszék 2015. Tartalomjegyzék
A számítógépes grafika inkrementális képszintézis algoritmusának hardver realizációja Teljesítménykövetelmények:
 Beveetés A sámítógépes grafika inkrementális képsintéis algoritmusának hardver realiációja Teljesítménykövetelmények: Animáció: néhány nsec/ képpont Massívan párhuamos Pipeline(stream processor) Párhuamos
Beveetés A sámítógépes grafika inkrementális képsintéis algoritmusának hardver realiációja Teljesítménykövetelmények: Animáció: néhány nsec/ képpont Massívan párhuamos Pipeline(stream processor) Párhuamos
Eichhardt Iván GPGPU óra anyagai
 OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos tervezési minták
OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos tervezési minták
GPU-Accelerated Collocation Pattern Discovery
 GPU-Accelerated Collocation Pattern Discovery Térbeli együttes előfordulási minták GPU-val gyorsított felismerése Gyenes Csilla Sallai Levente Szabó Andrea Eötvös Loránd Tudományegyetem Informatikai Kar
GPU-Accelerated Collocation Pattern Discovery Térbeli együttes előfordulási minták GPU-val gyorsított felismerése Gyenes Csilla Sallai Levente Szabó Andrea Eötvös Loránd Tudományegyetem Informatikai Kar
PÁRHUZAMOS SZÁMÍTÁSTECHNIKA MODUL AZ ÚJ TECHNOLÓGIÁKHOZ KAPCSOLÓDÓ MEGKÖZELÍTÉSBEN
 PÁRHUZAMOS SZÁMÍTÁSTECHNIKA MODUL AZ ÚJ TECHNOLÓGIÁKHOZ KAPCSOLÓDÓ MEGKÖZELÍTÉSBEN PARALLEL COMPUTING MODULE BASED ON THE NEW TECHNOLOGIES Vámossy Zoltán 1, Sima Dezső 2, Szénási Sándor 3, Rövid András
PÁRHUZAMOS SZÁMÍTÁSTECHNIKA MODUL AZ ÚJ TECHNOLÓGIÁKHOZ KAPCSOLÓDÓ MEGKÖZELÍTÉSBEN PARALLEL COMPUTING MODULE BASED ON THE NEW TECHNOLOGIES Vámossy Zoltán 1, Sima Dezső 2, Szénási Sándor 3, Rövid András
Videókártya - CUDA kompatibilitás: CUDA weboldal: Példaterületek:
 Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
Eichhardt Iván GPGPU óra anyagai
 OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos programozás elméleti
OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos programozás elméleti
Az MTA Cloud a tudományos alkalmazások támogatására. Kacsuk Péter MTA SZTAKI
 Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Analitikai megoldások IBM Power és FlashSystem alapokon. Mosolygó Ferenc - Avnet
 Analitikai megoldások IBM Power és FlashSystem alapokon Mosolygó Ferenc - Avnet Bevezető Legfontosabb elvárásaink az adatbázisokkal szemben Teljesítmény Lekérdezések, riportok és válaszok gyors megjelenítése
Analitikai megoldások IBM Power és FlashSystem alapokon Mosolygó Ferenc - Avnet Bevezető Legfontosabb elvárásaink az adatbázisokkal szemben Teljesítmény Lekérdezések, riportok és válaszok gyors megjelenítése
Tanács Attila. Képfeldolgozás és Számítógépes Grafika Tanszék Szegedi Tudományegyetem
 Tanács Attila Képfeldolgozás és Számítógépes Grafika Tanszék Szegedi Tudományegyetem Direct3D, DirectX o Csak Microsoft platformon OpenGL o Silicon Graphics: IRIS GL (zárt kód) o OpenGL (1992) o Nyílt
Tanács Attila Képfeldolgozás és Számítógépes Grafika Tanszék Szegedi Tudományegyetem Direct3D, DirectX o Csak Microsoft platformon OpenGL o Silicon Graphics: IRIS GL (zárt kód) o OpenGL (1992) o Nyílt
Számítógépek felépítése, alapfogalmak
 2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd SZE MTK MSZT lovas.szilard@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? Nem reprezentatív felmérés kinek van
2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd SZE MTK MSZT lovas.szilard@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? Nem reprezentatív felmérés kinek van
Négyprocesszoros közvetlen csatolású szerverek architektúrája:
 SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
Számítógép architektúrák I. Várady Géza varadygeza@pmmik.pte.hu
 Számítógép architektúrák I. Várady Géza varadygeza@pmmik.pte.hu 1 Bevezetés - fogalmak Informatika sokrétű Információk Szerzése Feldolgozása Tárolása Továbbítása Információtechnika Informatika a technikai
Számítógép architektúrák I. Várady Géza varadygeza@pmmik.pte.hu 1 Bevezetés - fogalmak Informatika sokrétű Információk Szerzése Feldolgozása Tárolása Továbbítása Információtechnika Informatika a technikai
Nagy mennyiségű adatok elemzése és előrejelzési felhasználása masszívan párhuzamosítható architektúrával
 Nagy ennyiségű adatok elezése és előrejelzési felhasználása asszívan párhuzaosítható architektúrával Készítette: Retek Mihály Budapesti Corvinus Egyete, Gazdaságföldrajz és Jövőkutatás Tanszék A Magyar
Nagy ennyiségű adatok elezése és előrejelzési felhasználása asszívan párhuzaosítható architektúrával Készítette: Retek Mihály Budapesti Corvinus Egyete, Gazdaságföldrajz és Jövőkutatás Tanszék A Magyar
Számítógép felépítése
 Alaplap, processzor Számítógép felépítése Az alaplap A számítógép teljesítményét alapvetően a CPU és belső busz sebessége (a belső kommunikáció sebessége), a memória mérete és típusa, a merevlemez sebessége
Alaplap, processzor Számítógép felépítése Az alaplap A számítógép teljesítményét alapvetően a CPU és belső busz sebessége (a belső kommunikáció sebessége), a memória mérete és típusa, a merevlemez sebessége
A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem)
") 65-67 A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem) Két fő része: a vezérlőegység, ami a memóriában tárolt program dekódolását és végrehajtását végzi, az
65-67 A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem) Két fő része: a vezérlőegység, ami a memóriában tárolt program dekódolását és végrehajtását végzi, az
Nyíregyházi Egyetem Matematika és Informatika Intézete. Input/Output
 1 Input/Output 1. I/O műveletek hardveres háttere 2. I/O műveletek szoftveres háttere 3. Diszkek (lemezek) ------------------------------------------------ 4. Órák, Szöveges terminálok 5. GUI - Graphical
1 Input/Output 1. I/O műveletek hardveres háttere 2. I/O műveletek szoftveres háttere 3. Diszkek (lemezek) ------------------------------------------------ 4. Órák, Szöveges terminálok 5. GUI - Graphical
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN
 KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
Tartalom. Hajder Levente 2016/2017. I. félév
 Tartalom Hajder Levente hajder.levente@sztaki.mta.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2016/2017. I. félév 1 Tartalom Motiváció 2 Grafikus szerelőszalag Modellezési transzformácó Nézeti transzformácó
Tartalom Hajder Levente hajder.levente@sztaki.mta.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2016/2017. I. félév 1 Tartalom Motiváció 2 Grafikus szerelőszalag Modellezési transzformácó Nézeti transzformácó
Számítógépes Graka - 4. Gyak
 Számítógépes Graka - 4. Gyak Jámbori András andras.jambori@gmail.com 2012.03.01 Jámbori András andras.jambori@gmail.com Számítógépes Graka - 4. Gyak 1/17 Emlékeztet A múlt órákon tárgyaltuk: WinAPI programozás
Számítógépes Graka - 4. Gyak Jámbori András andras.jambori@gmail.com 2012.03.01 Jámbori András andras.jambori@gmail.com Számítógépes Graka - 4. Gyak 1/17 Emlékeztet A múlt órákon tárgyaltuk: WinAPI programozás
Textúrák. Szécsi László
 Textúrák Szécsi László Textúra interpretációk kép a memóriában ugyanolyan mint a frame buffer pixel helyett texel adatok tömbje 1D, 2D, 3D tömb pl. RGB rekordok függvény diszkrét mintapontjai rácson rekonstrukció:
Textúrák Szécsi László Textúra interpretációk kép a memóriában ugyanolyan mint a frame buffer pixel helyett texel adatok tömbje 1D, 2D, 3D tömb pl. RGB rekordok függvény diszkrét mintapontjai rácson rekonstrukció:
Mikrorendszerek tervezése
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Mikrorendszerek tervezése Beágyazott rendszerek Fehér Béla Raikovich Tamás
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Mikrorendszerek tervezése Beágyazott rendszerek Fehér Béla Raikovich Tamás
Heterogén számítási rendszerek gyakorlatok (2017.)
") Heterogén számítási rendszerek gyakorlatok (2017.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 6 2.1 Global
Heterogén számítási rendszerek gyakorlatok (2017.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 6 2.1 Global
Tartalom. Tartalom. Hajder Levente 2018/2019. I. félév
 Hajder Levente hajder@inf.elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2018/2019. I. félév Emlékeztető Múlt órán megismerkedtünk a sugárkövetéssel Előnyei: A színtér benépesítésére minden használható,
Hajder Levente hajder@inf.elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2018/2019. I. félév Emlékeztető Múlt órán megismerkedtünk a sugárkövetéssel Előnyei: A színtér benépesítésére minden használható,
Hajder Levente 2016/2017.
 Hajder Levente hajder.levente@sztaki.mta.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2016/2017. Tartalom 1 Tartalom Motiváció 2 Grafikus szerelőszalag Áttekintés Modellezési transzformácó Nézeti
Hajder Levente hajder.levente@sztaki.mta.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2016/2017. Tartalom 1 Tartalom Motiváció 2 Grafikus szerelőszalag Áttekintés Modellezési transzformácó Nézeti
Bevezetés a CGI-be. 1. Történelem
 Bevezetés a CGI-be 1. Történelem 1.1 Úttörők Euklidész (ie.. 300-250) - A számítógépes grafika geometriai hátterének a megteremtője Bresenham (60 évek) - Első vonalrajzolás raster raster készüléken, később
Bevezetés a CGI-be 1. Történelem 1.1 Úttörők Euklidész (ie.. 300-250) - A számítógépes grafika geometriai hátterének a megteremtője Bresenham (60 évek) - Első vonalrajzolás raster raster készüléken, később
KISKER AKCIÓS ÁRLISTA
 KISKER AKCIÓS ÁRLISTA 2015. február 1-tıl visszavonásig, illetve a készlet erejéig érvényes Készülékek** Alcatel OT-2004 C Készülékbiztosítás *3 Alcatel OT-2004C/SL 2G Dualband telefon + akkumulátor +
KISKER AKCIÓS ÁRLISTA 2015. február 1-tıl visszavonásig, illetve a készlet erejéig érvényes Készülékek** Alcatel OT-2004 C Készülékbiztosítás *3 Alcatel OT-2004C/SL 2G Dualband telefon + akkumulátor +
GPGPU programozás oktatása
 GPGPU programozás oktatása Szénási Sándor Összefoglalás A grafikus kártyák hagyományosan a képernyő tartalmának megjelenítéséért feleltek, ez azonban az évek folyamán lassan megváltozott. Ennek első látványos
GPGPU programozás oktatása Szénási Sándor Összefoglalás A grafikus kártyák hagyományosan a képernyő tartalmának megjelenítéséért feleltek, ez azonban az évek folyamán lassan megváltozott. Ennek első látványos
Szakdolgozat. Dandár Gábor
 Szakdolgozat Dandár Gábor Debrecen 2008 Debreceni Egyetem Informatikai Kar A shader nyelvek lehetőségeiről A GPU felhasználása általános célú számításokra Témavezető: Készítette: Dr. Tornai Róbert Dandár
Szakdolgozat Dandár Gábor Debrecen 2008 Debreceni Egyetem Informatikai Kar A shader nyelvek lehetőségeiről A GPU felhasználása általános célú számításokra Témavezető: Készítette: Dr. Tornai Róbert Dandár
Digitális Technika I. (VEMIVI1112D)
") Pannon Egyetem Villamosmérnöki és Inf. Rendszerek Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vassányi István vassanyi@almos.vein.hu Feltételek:
Pannon Egyetem Villamosmérnöki és Inf. Rendszerek Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vassányi István vassanyi@almos.vein.hu Feltételek:
5-6. ea Created by mrjrm & Pogácsa, frissítette: Félix
 2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
egy szisztolikus példa
 Automatikus párhuzamosítás egy szisztolikus példa Áttekintés Bevezetés Példa konkrét szisztolikus algoritmus Automatikus párhuzamosítási módszer ötlet Áttekintés Bevezetés Példa konkrét szisztolikus algoritmus
Automatikus párhuzamosítás egy szisztolikus példa Áttekintés Bevezetés Példa konkrét szisztolikus algoritmus Automatikus párhuzamosítási módszer ötlet Áttekintés Bevezetés Példa konkrét szisztolikus algoritmus
Adatfolyam alapú RACER tömbprocesszor és algoritmus implementációs módszerek valamint azok alkalmazásai parallel, heterogén számítási architektúrákra
 Adatfolyam alapú RACER tömbprocesszor és algoritmus implementációs módszerek valamint azok alkalmazásai parallel, heterogén számítási architektúrákra Témavezet : Dr. Cserey György 2014 szeptember 22. Kit
Adatfolyam alapú RACER tömbprocesszor és algoritmus implementációs módszerek valamint azok alkalmazásai parallel, heterogén számítási architektúrákra Témavezet : Dr. Cserey György 2014 szeptember 22. Kit
1. Fejezet: Számítógép rendszerek
 1. Fejezet: Számítógép The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3. kiadás, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley College Linda
1. Fejezet: Számítógép The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3. kiadás, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley College Linda
FIR SZŰRŐK TELJESÍTMÉNYÉNEK JAVÍTÁSA C/C++-BAN
 Multidiszciplináris tudományok, 4. kötet. (2014) 1. sz. pp. 31-38. FIR SZŰRŐK TELJESÍTMÉNYÉNEK JAVÍTÁSA C/C++-BAN Lajos Sándor Mérnöktanár, Miskolci Egyetem, Matematikai Intézet, Ábrázoló Geometriai Intézeti
Multidiszciplináris tudományok, 4. kötet. (2014) 1. sz. pp. 31-38. FIR SZŰRŐK TELJESÍTMÉNYÉNEK JAVÍTÁSA C/C++-BAN Lajos Sándor Mérnöktanár, Miskolci Egyetem, Matematikai Intézet, Ábrázoló Geometriai Intézeti
KOGGM614 JÁRMŰIPARI KUTATÁS ÉS FEJLESZTÉS FOLYAMATA
 KOGGM614 JÁRMŰIPARI KUTATÁS ÉS FEJLESZTÉS FOLYAMATA System Design Wahl István 2019.03.26. BME FACULTY OF TRANSPORTATION ENGINEERING AND VEHICLE ENGINEERING Tartalomjegyzék Rövidítések A rendszer definiálása
KOGGM614 JÁRMŰIPARI KUTATÁS ÉS FEJLESZTÉS FOLYAMATA System Design Wahl István 2019.03.26. BME FACULTY OF TRANSPORTATION ENGINEERING AND VEHICLE ENGINEERING Tartalomjegyzék Rövidítések A rendszer definiálása
2015. február 1-tıl visszavonásig, illetve a készlet erejéig érvényes
 KISKER ÁRLISTA 2015. február 1-tıl visszavonásig, illetve a készlet erejéig érvényes Készülékek** Alcatel OT-2004 C Alcatel OT-2004C/SL 2G Dualband telefon + akkumulátor + USB kábel + hálózati Alcatel
KISKER ÁRLISTA 2015. február 1-tıl visszavonásig, illetve a készlet erejéig érvényes Készülékek** Alcatel OT-2004 C Alcatel OT-2004C/SL 2G Dualband telefon + akkumulátor + USB kábel + hálózati Alcatel
ios alkalmazásfejlesztés Koltai Róbert
 ios alkalmazásfejlesztés Koltai Róbert robert.koltai@ponte.hu Mi az a block? Utasítások sorozata { }-ek között, amit egy objektumként tuduk kezelni. ios 4.0 és Mac OSX 10.6 óta 2 Egy példa a felépítésére
ios alkalmazásfejlesztés Koltai Róbert robert.koltai@ponte.hu Mi az a block? Utasítások sorozata { }-ek között, amit egy objektumként tuduk kezelni. ios 4.0 és Mac OSX 10.6 óta 2 Egy példa a felépítésére
Digitális Technika I. (VEMIVI1112D)
") Pannon Egyetem Villamosmérnöki és Inf. Rendszerek Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vassányi István vassanyi@almos.vein.hu Feltételek:
Pannon Egyetem Villamosmérnöki és Inf. Rendszerek Tanszék Digitális Technika I. (VEMIVI1112D) Bevezetés. Hol tart ma a digitális technológia? Előadó: Dr. Vassányi István vassanyi@almos.vein.hu Feltételek:
2016. június 1-tıl visszavonásig, illetve a készlet erejéig érvényes
 KISKER ÁRLISTA 2016. június 1-tıl visszavonásig, illetve a készlet erejéig érvényes Készülékek** Alcatel OT-2004 C Alcatel OT-2004C/SL 2G Dualband telefon + akkumulátor + USB kábel + hálózati töltıadapter
KISKER ÁRLISTA 2016. június 1-tıl visszavonásig, illetve a készlet erejéig érvényes Készülékek** Alcatel OT-2004 C Alcatel OT-2004C/SL 2G Dualband telefon + akkumulátor + USB kábel + hálózati töltıadapter
Programmable Chip. System on a Chip. Lazányi János. Tartalom. A hagyományos technológia SoC / PSoC SoPC Fejlesztés menete Mi van az FPGA-ban?
 System on a Chip Programmable Chip Lazányi János 2010 Tartalom A hagyományos technológia SoC / PSoC SoPC Fejlesztés menete Mi van az FPGA-ban? Page 2 1 A hagyományos technológia Elmosódó határvonalak ASIC
System on a Chip Programmable Chip Lazányi János 2010 Tartalom A hagyományos technológia SoC / PSoC SoPC Fejlesztés menete Mi van az FPGA-ban? Page 2 1 A hagyományos technológia Elmosódó határvonalak ASIC
Máté: Számítógépes grafika alapjai
 Történeti áttekintés Interaktív grafikai rendszerek A számítógépes grafika osztályozása Valós és képzeletbeli objektumok (pl. tárgyak képei, függvények) szintézise számítógépes modelljeikből (pl. pontok,
Történeti áttekintés Interaktív grafikai rendszerek A számítógépes grafika osztályozása Valós és képzeletbeli objektumok (pl. tárgyak képei, függvények) szintézise számítógépes modelljeikből (pl. pontok,
Processzor (CPU - Central Processing Unit)
") Készíts saját kódolású WEBOLDALT az alábbi ismeretanyag felhasználásával! A lap alján lábjegyzetben hivatkozz a fenti oldalra! Processzor (CPU - Central Processing Unit) A központi feldolgozó egység a
Készíts saját kódolású WEBOLDALT az alábbi ismeretanyag felhasználásával! A lap alján lábjegyzetben hivatkozz a fenti oldalra! Processzor (CPU - Central Processing Unit) A központi feldolgozó egység a
FELHASZNÁLÓI KÉZIKÖNYV 1.sz. melléklet
 FELHASZNÁLÓI KÉZIKÖNYV 1.sz. melléklet Mobil eszköz és böngészı beállítások 1 Bevezetés A melléklet célja, hogy összesítse azokat a mobil eszköz és böngészı beállításokat, melyek ahhoz szükségesek, hogy
FELHASZNÁLÓI KÉZIKÖNYV 1.sz. melléklet Mobil eszköz és böngészı beállítások 1 Bevezetés A melléklet célja, hogy összesítse azokat a mobil eszköz és böngészı beállításokat, melyek ahhoz szükségesek, hogy
Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)
, Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)") 1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)
, Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)") 1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
GPU alkalmazása az ALICE eseménygenerátorában
 GPU alkalmazása az ALICE eseménygenerátorában Nagy Máté Ferenc MTA KFKI RMKI ALICE csoport ELTE TTK Fizika MSc Témavezető: Dr. Barnaföldi Gergely Gábor MTA KFKI RMKI ALICE csoport Elméleti Fizikai Főosztály
GPU alkalmazása az ALICE eseménygenerátorában Nagy Máté Ferenc MTA KFKI RMKI ALICE csoport ELTE TTK Fizika MSc Témavezető: Dr. Barnaföldi Gergely Gábor MTA KFKI RMKI ALICE csoport Elméleti Fizikai Főosztály
Féléves feladat. Miről lesz szó? Bemutatkozás és követelmények 2012.09.16.
 Bemutatkozás és követelmények Dr. Mileff Péter Dr. Mileff Péter Helyileg: A/1-303. szoba. Fizika Tanszék Konzultációs idő: Szerda 10-12 mileff@iit.uni-miskolc.hu Követelmények: Az órák ¾-én kötelező a
Bemutatkozás és követelmények Dr. Mileff Péter Dr. Mileff Péter Helyileg: A/1-303. szoba. Fizika Tanszék Konzultációs idő: Szerda 10-12 mileff@iit.uni-miskolc.hu Követelmények: Az órák ¾-én kötelező a
Amazon Web Services. Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28.
 Amazon Web Services Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28. Ez nem egy könyváruház? 1994-ben alapította Jeff Bezos Túlélte a dot-com korszakot Eredetileg könyváruház majd az elérhető
Amazon Web Services Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28. Ez nem egy könyváruház? 1994-ben alapította Jeff Bezos Túlélte a dot-com korszakot Eredetileg könyváruház majd az elérhető
Architektúra, cache. Mirıl lesz szó? Mi a probléma? Teljesítmény. Cache elve. Megoldás. Egy rövid idıintervallum alatt a memóriahivatkozások a teljes
 Architektúra, cache irıl lesz szó? Alapfogalmak Adat cache tervezési terének alapkomponensei Koschek Vilmos Fejlıdés vkoschek@vonalkodhu Teljesítmény Teljesítmény növelése Technológia Architektúra (mem)
Architektúra, cache irıl lesz szó? Alapfogalmak Adat cache tervezési terének alapkomponensei Koschek Vilmos Fejlıdés vkoschek@vonalkodhu Teljesítmény Teljesítmény növelése Technológia Architektúra (mem)