OpenCL - The open standard for parallel programming of heterogeneous systems
|
|
|
- Gusztáv Kelemen
- 9 évvel ezelőtt
- Látták:
Átírás

1 OpenCL - The open standard for parallel programming of heterogeneous systems

2 GPU-k általános számításokhoz GPU Graphics Processing Unit Képalkotás: sok, általában egyszerű és független művelet < 2006: programmable shaders renderelés (Pixar RenderMan Toy Story) 2006: CUDA -Compute Unified Device Architecture csak Nvidia kártyákon kezdetben 128 CUDA core, 8 compute unit (Tesla c870) 2008: OpenCL cross-platform Khronos csoport (OpenGL!) OpenCL 1.0: Mac OS X Snow Leopard 2009 fontosabb partnerek: AMD, Intel (Larrabee) és természetesen Nvidia Alternatívák: DirectCompute, OpenMP, OpenACC stb.
 és természetesen Nvidia Alternatívák: DirectCompute,")

3 OpenCL working group members Nvidia in chair, Apple is specification editor Már most is tekinthető általános szabványnak.


4 OpenCL könyvek OpenCL Programming Guide - The Red Book of OpenCL OpenCL in Action Heterogeneous Computing with OpenCL The OpenCL Programming Book

5 OpenCL API AMD INTEL NVIDIA

6 OpenCL: egy példa Soros megoldás OpenCL megoldás void add_vector(int dim,float *A,float *B, float *C) { for(int i=0;i<dim;i++) C[i]=A[i]+B[i]; } kernel void add_vector( global float *A, global float *B,_global float *C) { int tidx = get_global_id(0); Különbségek:? C[tidx]=A[tidx]+B[tidx]; }
![C[i]=A[i]+B[i]; } kernel void add_vector( global float *A, global float](/docs-images/44/4575378/images/page_6.jpg "*B,_global float *C) { int tidx = get_global_id(0); Különbségek:?")
7 OpenCL: egy példa (C) Soros megoldás OpenCL megoldás void add_vector(int dim,float *A,float *B, float *C) { for(int i=0;i<dim;i++) C[i]=A[i]+B[i]; } kernel void add_vector( global float *A, global float *B,_global float *C) { int i = get_global_id(0); C[i]=A[i]+B[i]; } Különbségek: - hol a vektor dimenziója? Soros kód: dim változó OpenCL: a get_global_id(0) maximumális értéke a dimenzió, melyet előzőleg beállítottunk a kernel hívás előtt - milyen memória címeket használhatunk? Minden OpenCL compute device saját memória területtel rendelkezik, melyet előre le kell foglalnunk
 maximumális értéke a dimenzió, melyet előzőleg beállítottunk a kernel hívás előtt - milyen")

8 OpenCL: compute device memory types Global domain: work item size Local groups: workgroups Eszköz specifikus a paraméterezés, de mindent le tudunk kérdezni futásidőben.

9 OpenCL: memória Az architektúra legnagyobb hátránya: Egy számolás eredményének elérése: host device host Még abban az esetben is, ha a kódunkat a lokális CPU-n futtatjuk! A másolás egyik korlátja maga a PCI-express Lehetőség párhuzamos másolás-számolásra Megjegyzés: 1. sok esetben hatékonyabb helyben újraszámolni mint beolvasni 2. sok esetben a kiolvasás lassúsága miatt nem hatékony 3. Nincs virtuális memória de lesz!


10 OpenCL: memória Hierarchikus memória: Minél Az architektúra legnagyobb hátránya: lentebb megyünk annál kisebb a memória eredményének mérete, cserébe egyre Egy számolás elérése: gyorsabb! host device host Még 1. abban esetben is, ha a kódunkat Hostazmemory a lokáliscsak CPU-n futtatjuk! a CPU éri el, GB/s Akár 512 GB 2. Global/Constant memory Csak az adott device-on látható Lehetőség párhuzamos másolás-számolásra GB/sec (GPU), <6GB 3. Local memory Megjegyzés: Csak egy adott workgroup látja 1. sok esetben hatékonyabb helyben KB/work-item újraszámolni mint beolvasni 4. Private memory 2. sok esetben a kiolvasás lassúsága Csak az adott work-item látja miatt nemkb hatékony A másolás egyik korlátja maga a PCI-express 3. Nincs virtuális memória de lesz!

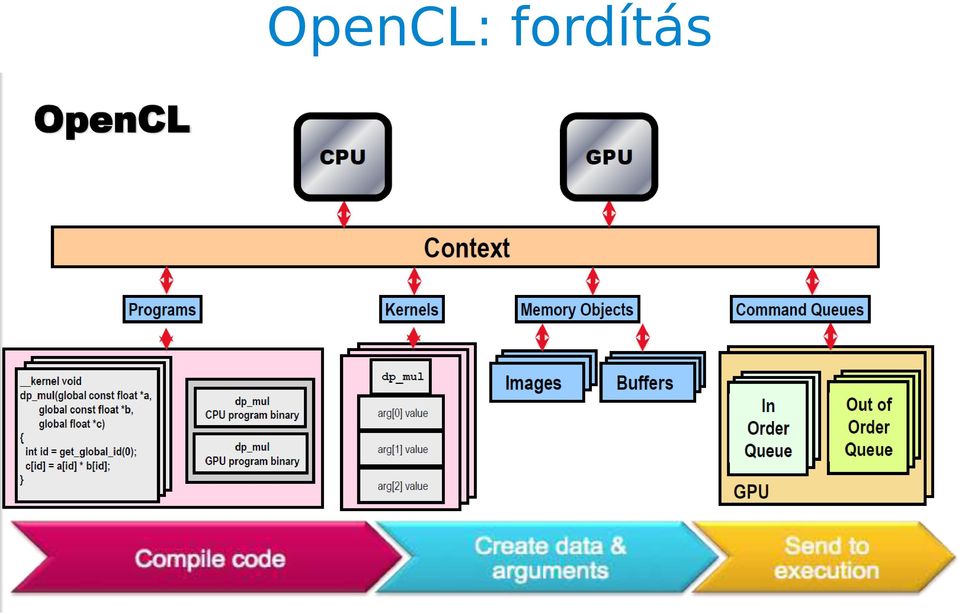
11 OpenCL: fordítás Fordítás történhet offline és online módon. Utóbbi az elterjedt. univerzális OpenCL API: C/C++ objektumok: Konfiguráció: Device - eszköz objektuma Context - eszközök környezet Queue - feladatok kiosztása Memória: Buffer - memória blokkok Image - 2D vagy 3D kép Végrehajtás: Program - kernelek Kernel - maguk a feladatok Példa fordításra: Mac OS X (>10.6): g++ -framework OpenCL cl_test.cpp -o cl_test Linux: Nvidia SDK g++ -I<NVIDIA_SDK>/OpenCL/common/inc/ cl_test.cpp -o cl_test
: g++ -framework OpenCL cl_test.")

12 OpenCL: fordítás

13 Példa: Alacsony szintű képi leírók számolása Segmentation Region of Interest Dense Grid

 Még több ha PCA + Fisher számolás : ~40x")
14 Példa: Alacsony szintű képi leírók számolása Sok ezer független leíró képenként a párhuzamosítás alapja Mivel GPU/CPU közös kód: - csak egy dimenziós párhuzamosítás - no image support Kis memória igény: - maga a nyers kép pl. 1Mio*3Byte - gradiens képek: 1Mio*4Byte - leírók: 128*4*N Byte Nyereség: ~10x CPU-hoz képest (nem optimális) Még több ha PCA + Fisher számolás : ~40x

Eichhardt Iván GPGPU óra anyagai
 OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos programozás elméleti
OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos programozás elméleti
GPGPU alapok. GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai
 GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
Eichhardt Iván GPGPU óra anyagai
 OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos tervezési minták
OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos tervezési minták
A CUDA előnyei: - Elszórt memória olvasás (az adatok a memória bármely területéről olvashatóak) PC-Vilag.hu CUDA, a jövő technológiája?!
 PC-Vilag.hu CUDA, a jövő technológiája?!") A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
Párhuzamos és Grid rendszerek
 Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
Videókártya - CUDA kompatibilitás: CUDA weboldal: Példaterületek:
 Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
Google Summer of Code OpenCL image support for the r600g driver
 Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
Diplomamunka. Miskolci Egyetem. GPGPU technológia kriptográfiai alkalmazása. Készítette: Csikó Richárd VIJFZK mérnök informatikus
 Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
Magas szintű optimalizálás
 Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
GPGPU programozás lehetőségei. Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café
 GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási
 GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
GPGPU. GPU-k felépítése. Valasek Gábor
 GPGPU GPU-k felépítése Valasek Gábor Tartalom A mai órán áttekintjük a GPU-k architekturális felépítését A cél elsősorban egy olyan absztrakt hardvermodell bemutatása, ami segít megérteni a GPU-k hardveres
GPGPU GPU-k felépítése Valasek Gábor Tartalom A mai órán áttekintjük a GPU-k architekturális felépítését A cél elsősorban egy olyan absztrakt hardvermodell bemutatása, ami segít megérteni a GPU-k hardveres
GPU alkalmazása az ALICE eseménygenerátorában
 GPU alkalmazása az ALICE eseménygenerátorában Nagy Máté Ferenc MTA KFKI RMKI ALICE csoport ELTE TTK Fizika MSc Témavezető: Dr. Barnaföldi Gergely Gábor MTA KFKI RMKI ALICE csoport Elméleti Fizikai Főosztály
GPU alkalmazása az ALICE eseménygenerátorában Nagy Máté Ferenc MTA KFKI RMKI ALICE csoport ELTE TTK Fizika MSc Témavezető: Dr. Barnaföldi Gergely Gábor MTA KFKI RMKI ALICE csoport Elméleti Fizikai Főosztály
SAT probléma kielégíthetőségének vizsgálata. masszív parallel. mesterséges neurális hálózat alkalmazásával
 SAT probléma kielégíthetőségének vizsgálata masszív parallel mesterséges neurális hálózat alkalmazásával Tajti Tibor, Bíró Csaba, Kusper Gábor {gkusper, birocs, tajti}@aries.ektf.hu Eszterházy Károly Főiskola
SAT probléma kielégíthetőségének vizsgálata masszív parallel mesterséges neurális hálózat alkalmazásával Tajti Tibor, Bíró Csaba, Kusper Gábor {gkusper, birocs, tajti}@aries.ektf.hu Eszterházy Károly Főiskola
AliROOT szimulációk GPU alapokon
 AliROOT szimulációk GPU alapokon Nagy Máté Ferenc & Barnaföldi Gergely Gábor Wigner FK ALICE Bp csoport OTKA: PD73596 és NK77816 TARTALOM 1. Az ALICE csoport és a GRID hálózat 2. Szimulációk és az AliROOT
AliROOT szimulációk GPU alapokon Nagy Máté Ferenc & Barnaföldi Gergely Gábor Wigner FK ALICE Bp csoport OTKA: PD73596 és NK77816 TARTALOM 1. Az ALICE csoport és a GRID hálózat 2. Szimulációk és az AliROOT
OpenCL Kovács, György
 OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
GPU-Accelerated Collocation Pattern Discovery
 GPU-Accelerated Collocation Pattern Discovery Térbeli együttes előfordulási minták GPU-val gyorsított felismerése Gyenes Csilla Sallai Levente Szabó Andrea Eötvös Loránd Tudományegyetem Informatikai Kar
GPU-Accelerated Collocation Pattern Discovery Térbeli együttes előfordulási minták GPU-val gyorsított felismerése Gyenes Csilla Sallai Levente Szabó Andrea Eötvös Loránd Tudományegyetem Informatikai Kar
GPU Lab. 14. fejezet. OpenCL textúra használat. Grafikus Processzorok Tudományos Célú Programozása. Berényi Dániel Nagy-Egri Máté Ferenc
 14. fejezet OpenCL textúra használat Grafikus Processzorok Tudományos Célú Programozása Textúrák A textúrák 1, 2, vagy 3D-s tömbök kifejezetten szín információk tárolására Főbb különbségek a bufferekhez
14. fejezet OpenCL textúra használat Grafikus Processzorok Tudományos Célú Programozása Textúrák A textúrák 1, 2, vagy 3D-s tömbök kifejezetten szín információk tárolására Főbb különbségek a bufferekhez
Nemlineáris optimalizálási problémák párhuzamos megoldása grafikus processzorok felhasználásával
 Nemlineáris optimalizálási problémák párhuzamos megoldása grafikus processzorok felhasználásával 1 1 Eötvös Loránd Tudományegyetem, Informatikai Kar Kari TDK, 2016. 05. 10. Tartalom 1 2 Tartalom 1 2 Optimalizálási
Nemlineáris optimalizálási problémák párhuzamos megoldása grafikus processzorok felhasználásával 1 1 Eötvös Loránd Tudományegyetem, Informatikai Kar Kari TDK, 2016. 05. 10. Tartalom 1 2 Tartalom 1 2 Optimalizálási
GPGPU és számítások heterogén rendszereken
 GPGPU és számítások heterogén rendszereken Eichhardt Iván eichhardt.ivan@sztaki.mta.hu ELTE-s GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ Gyors bevezetés a Párhuzamosságról OpenCL API Gyakorlati példák
GPGPU és számítások heterogén rendszereken Eichhardt Iván eichhardt.ivan@sztaki.mta.hu ELTE-s GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ Gyors bevezetés a Párhuzamosságról OpenCL API Gyakorlati példák
Grafikus kártyák, mint olcsó szuperszámítógépek - I.
 (1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport (2) Vázlat I. Motiváció Beüzemelés C alapok CUDA programozási modell,
(1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport (2) Vázlat I. Motiváció Beüzemelés C alapok CUDA programozási modell,
Grafikus csővezeték 1 / 44
 Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely
 Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
Számítógépek felépítése
 Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Adat- és feladat párhuzamos modell Az ISO C99 szabvány részhalmaza
 Adat- és feladat párhuzamos modell Az ISO C99 szabvány részhalmaza párhuzamos kiegészítésekkel Numerikus műveletek az IEEE754 alapján Beágyazott és mobil eszközök támogatása OpenGL, OpenGL ES adatcsere
Adat- és feladat párhuzamos modell Az ISO C99 szabvány részhalmaza párhuzamos kiegészítésekkel Numerikus műveletek az IEEE754 alapján Beágyazott és mobil eszközök támogatása OpenGL, OpenGL ES adatcsere
OpenCL alapú eszközök verifikációja és validációja a gyakorlatban
 OpenCL alapú eszközök verifikációja és validációja a gyakorlatban Fekete Tamás 2015. December 3. Szoftver verifikáció és validáció tantárgy Áttekintés Miért és mennyire fontos a megfelelő validáció és
OpenCL alapú eszközök verifikációja és validációja a gyakorlatban Fekete Tamás 2015. December 3. Szoftver verifikáció és validáció tantárgy Áttekintés Miért és mennyire fontos a megfelelő validáció és
4. Funkcionális primitívek GPUn
 4. Funkcionális primitívek GPUn GPU API emlékeztető Jelenleg a következő eszközök állnak rendelkezésre GPUs kódok futtatására: DirectX vagy OpenGL vagy Vulkan Compute Shader Ez grafikai célokra van kitalálva,
4. Funkcionális primitívek GPUn GPU API emlékeztető Jelenleg a következő eszközök állnak rendelkezésre GPUs kódok futtatására: DirectX vagy OpenGL vagy Vulkan Compute Shader Ez grafikai célokra van kitalálva,
Négyprocesszoros közvetlen csatolású szerverek architektúrája:
 SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN
 KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
Haladó Grafika EA. Inkrementális képszintézis GPU-n
 Haladó Grafika EA Inkrementális képszintézis GPU-n Pipeline Az elvégzendő feladatot részfeladatokra bontjuk Mindegyik részfeladatot más-más egység dolgozza fel (ideális esetben) Minden egység inputja,
Haladó Grafika EA Inkrementális képszintézis GPU-n Pipeline Az elvégzendő feladatot részfeladatokra bontjuk Mindegyik részfeladatot más-más egység dolgozza fel (ideális esetben) Minden egység inputja,
Az NIIF új szuperszámítógép infrastruktúrája Új lehetőségek a kutatói hálózatban 2012.02.23.
 Az NIIF új szuperszámítógép infrastruktúrája Új lehetőségek a kutatói hálózatban 2012.02.23. Dr. Máray Tamás NIIF Intézet NIIF szuperszámítógép szolgáltatás a kezdetek 2001 Sun E10k 60 Gflops SMP architektúra
Az NIIF új szuperszámítógép infrastruktúrája Új lehetőségek a kutatói hálózatban 2012.02.23. Dr. Máray Tamás NIIF Intézet NIIF szuperszámítógép szolgáltatás a kezdetek 2001 Sun E10k 60 Gflops SMP architektúra
Felhő alapú hálózatok (VITMMA02) OpenStack Neutron Networking
 OpenStack Neutron Networking") Felhő alapú hálózatok (VITMMA02) OpenStack Neutron Networking Dr. Maliosz Markosz Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Távközlési és Médiainformatikai Tanszék
Felhő alapú hálózatok (VITMMA02) OpenStack Neutron Networking Dr. Maliosz Markosz Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Távközlési és Médiainformatikai Tanszék
OpenGL Compute Shader-ek. Valasek Gábor
 OpenGL Compute Shader-ek Valasek Gábor Compute shader OpenGL 4.3 óta része a Core specifikációnak Speciális shaderek, amikben a szokásos GLSL parancsok (és néhány új) segítségével általános számítási feladatokat
OpenGL Compute Shader-ek Valasek Gábor Compute shader OpenGL 4.3 óta része a Core specifikációnak Speciális shaderek, amikben a szokásos GLSL parancsok (és néhány új) segítségével általános számítási feladatokat
Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15 Fehér
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15 Fehér
Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd.
 1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
Hallgatói segédlet: Nvidia CUDA C programok debugolása Nvidia Optimus technológiás laptopokon. Készítette: Kovács Andor. 2011/2012 első félév
 Hallgatói segédlet: Nvidia CUDA C programok debugolása Nvidia Optimus technológiás laptopokon Készítette: Kovács Andor 2011/2012 első félév 1 A CUDA programok debugolásához kettő grafikus kártyára van
Hallgatói segédlet: Nvidia CUDA C programok debugolása Nvidia Optimus technológiás laptopokon Készítette: Kovács Andor 2011/2012 első félév 1 A CUDA programok debugolásához kettő grafikus kártyára van
Az MTA Cloud a tudományos alkalmazások támogatására. Kacsuk Péter MTA SZTAKI
 Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
PÁRHUZAMOS SZÁMÍTÁSTECHNIKA MODUL AZ ÚJ TECHNOLÓGIÁKHOZ KAPCSOLÓDÓ MEGKÖZELÍTÉSBEN
 PÁRHUZAMOS SZÁMÍTÁSTECHNIKA MODUL AZ ÚJ TECHNOLÓGIÁKHOZ KAPCSOLÓDÓ MEGKÖZELÍTÉSBEN PARALLEL COMPUTING MODULE BASED ON THE NEW TECHNOLOGIES Vámossy Zoltán 1, Sima Dezső 2, Szénási Sándor 3, Rövid András
PÁRHUZAMOS SZÁMÍTÁSTECHNIKA MODUL AZ ÚJ TECHNOLÓGIÁKHOZ KAPCSOLÓDÓ MEGKÖZELÍTÉSBEN PARALLEL COMPUTING MODULE BASED ON THE NEW TECHNOLOGIES Vámossy Zoltán 1, Sima Dezső 2, Szénási Sándor 3, Rövid András
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Bevitel-Kivitel. Eddig a számítógép agyáról volt szó. Szükség van eszközökre. Processzusok, memória, stb
 Input és Output 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel és kivitel a számitógépből, -be Perifériák 2 Perifériákcsoportosításá,
Input és Output 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel és kivitel a számitógépből, -be Perifériák 2 Perifériákcsoportosításá,
Informatikai Rendszerek Intézete Gábor Dénes Foiskola. Operációs rendszerek - 105 1. oldal LINUX
 1. oldal LINUX 2. oldal UNIX történet Elozmény: 1965 Multics 1969 Unix (Kernighen, Thompson) 1973 Unix C nyelven (Ritchie) 1980 UNIX (lényegében a mai forma) AT&T - System V Microsoft - Xenix Berkeley
1. oldal LINUX 2. oldal UNIX történet Elozmény: 1965 Multics 1969 Unix (Kernighen, Thompson) 1973 Unix C nyelven (Ritchie) 1980 UNIX (lényegében a mai forma) AT&T - System V Microsoft - Xenix Berkeley
Utolsó módosítás:
 Utolsó módosítás: 2012. 09. 06. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 Forrás: Gartner Hype Cycle for Virtualization, 2010, http://premierit.intel.com/docs/doc-5768
Utolsó módosítás: 2012. 09. 06. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 Forrás: Gartner Hype Cycle for Virtualization, 2010, http://premierit.intel.com/docs/doc-5768
Jurek Zoltán, Tóth Gyula
 Grafikus kártyák, mint olcsó szuperszámítógépek II. rész: GPU nap 2010, MTA RMKI Budapest, 2010. június 4. Tartalom 1 A CUDA futtatási modellje Implementáció 2 Make it work. - A működő párhuzamos kódig
Grafikus kártyák, mint olcsó szuperszámítógépek II. rész: GPU nap 2010, MTA RMKI Budapest, 2010. június 4. Tartalom 1 A CUDA futtatási modellje Implementáció 2 Make it work. - A működő párhuzamos kódig
A Webtől a. Gridig. A Gridről dióhéjban. Debreczeni Gergely (MTA KFKI RMKI) Debreczeni.Gergely@wigner.mta.hu
 Debreczeni.Gergely@wigner.mta.hu") A Webtől a Gridig A Gridről dióhéjban Debreczeni Gergely (MTA KFKI RMKI) Debreczeni.Gergely@wigner.mta.hu A tartalomból: Számítástechnika a CERN-ben A Web születése Az LHC Grid A Grid alkalmazásai Gyógyászat
A Webtől a Gridig A Gridről dióhéjban Debreczeni Gergely (MTA KFKI RMKI) Debreczeni.Gergely@wigner.mta.hu A tartalomból: Számítástechnika a CERN-ben A Web születése Az LHC Grid A Grid alkalmazásai Gyógyászat
Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15 Fehér
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15 Fehér
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
NIIFI HPC Szolgáltatás
 NIIFI HPC Szolgáltatás 14/11/2011 Óbudai Egyetem Stefán Péter Miről lesz Nemzeti szó? Információs Infrastruktúra Fejlesztési Intézet Rövid történeti áttekintés. Az NIIFI szuperszámítógépei,
NIIFI HPC Szolgáltatás 14/11/2011 Óbudai Egyetem Stefán Péter Miről lesz Nemzeti szó? Információs Infrastruktúra Fejlesztési Intézet Rövid történeti áttekintés. Az NIIFI szuperszámítógépei,
Grafikus kártyák, mint olcsó szuperszámítógépek - II.
 GPU, mint szuperszámítógép II. ( 1 ) Grafikus kártyák, mint olcsó szuperszámítógépek - II. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport GPU, mint szuperszámítógép II. (
GPU, mint szuperszámítógép II. ( 1 ) Grafikus kártyák, mint olcsó szuperszámítógépek - II. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport GPU, mint szuperszámítógép II. (
Gaussian Mixture Modell alapú Fisher vektor számolás GPGPU-n
 Gaussian Mixture Modell alapú Fisher vektor számolás GPGPU-n Daróczy Bálint és András Benczúr, Bodzsár Erik, Petrás István, Siklósi Dávid, Nikházy László, Pethes Róbert Adatbányászat és Webes Keresés Kutatócsoport
Gaussian Mixture Modell alapú Fisher vektor számolás GPGPU-n Daróczy Bálint és András Benczúr, Bodzsár Erik, Petrás István, Siklósi Dávid, Nikházy László, Pethes Róbert Adatbányászat és Webes Keresés Kutatócsoport
OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA
 Multidiszciplináris tudományok, 3. kötet. (2013) sz. pp. 259-268. OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA Mileff Péter Adjunktus, Miskolci Egyetem, Informatikai Intézet, Általános
Multidiszciplináris tudományok, 3. kötet. (2013) sz. pp. 259-268. OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA Mileff Péter Adjunktus, Miskolci Egyetem, Informatikai Intézet, Általános
Ár: 93.900 Ft Garancia: 2 Év
 Terméknév:Asus X553MA-XX388D 15.6" notebook Gyártó cikkszám:x553ma-xx388d Leírás:Szín: fekete Operációs rendszer: FreeDOS Kijelző: 15,6" HD (1366x768) CPU: Intel Celeron Dual-Core N2840 (2,16GHz, 1MB)
Terméknév:Asus X553MA-XX388D 15.6" notebook Gyártó cikkszám:x553ma-xx388d Leírás:Szín: fekete Operációs rendszer: FreeDOS Kijelző: 15,6" HD (1366x768) CPU: Intel Celeron Dual-Core N2840 (2,16GHz, 1MB)
Adatbázis és alkalmazás konszolidáció Oracle SPARC T4/5 alapon
 Adatbázis és alkalmazás konszolidáció Oracle SPARC T4/5 alapon Makár Zénó 2013. október 9. Invigor Informatika Kft 4 éve alakult Oracle Gold Partner HW és SW specializációk Oracle HW Support Provider Szolgáltatások
Adatbázis és alkalmazás konszolidáció Oracle SPARC T4/5 alapon Makár Zénó 2013. október 9. Invigor Informatika Kft 4 éve alakult Oracle Gold Partner HW és SW specializációk Oracle HW Support Provider Szolgáltatások
Hálózati operációs rendszerek II. Novell Netware 5.1 Szerver
 Hálózati operációs rendszerek II. Novell Netware 5.1 Szerver 1 Netware 5 főbb jellemzői (címszavakban) Intel Pentium CPU-n fut Felügyeli és vezérli a különböz ő alrendsze- reket és az azok közötti kommunikációt
Hálózati operációs rendszerek II. Novell Netware 5.1 Szerver 1 Netware 5 főbb jellemzői (címszavakban) Intel Pentium CPU-n fut Felügyeli és vezérli a különböz ő alrendsze- reket és az azok közötti kommunikációt
GPGPU. Architektúra esettanulmány
 GPGPU Architektúra esettanulmány GeForce 7800 (2006) GeForce 7800 Rengeteg erőforrást fordítottak arra, hogy a throughput-ot maximalizálják Azaz a különböző típusú feldolgozóegységek (vertex és fragment
GPGPU Architektúra esettanulmány GeForce 7800 (2006) GeForce 7800 Rengeteg erőforrást fordítottak arra, hogy a throughput-ot maximalizálják Azaz a különböző típusú feldolgozóegységek (vertex és fragment
Novell és Oracle: a csúcsteljesítményű, költséghatékony adatközpont megoldás. Sárecz Lajos Értékesítési konzultáns
 Novell és Oracle: a csúcsteljesítményű, költséghatékony adatközpont megoldás Sárecz Lajos Értékesítési konzultáns lajos.sarecz@oracle.com A Linux fejlődése Oracle: A Linux elkötelezettje Linux története
Novell és Oracle: a csúcsteljesítményű, költséghatékony adatközpont megoldás Sárecz Lajos Értékesítési konzultáns lajos.sarecz@oracle.com A Linux fejlődése Oracle: A Linux elkötelezettje Linux története
GRAFIKUS PROCESSZOROK ALKALMAZÁSA KÉPFELDOLGOZÁSI FELADATOKRA
 GRAFIKUS PROCESSZOROK ALKALMAZÁSA KÉPFELDOLGOZÁSI FELADATOKRA ABSTRACT Simon Pál PhD hallgató Miskolci Egyetem Hatvany József Informatikai Tudományok Doktori Iskola The aim of this paper is the presentation
GRAFIKUS PROCESSZOROK ALKALMAZÁSA KÉPFELDOLGOZÁSI FELADATOKRA ABSTRACT Simon Pál PhD hallgató Miskolci Egyetem Hatvany József Informatikai Tudományok Doktori Iskola The aim of this paper is the presentation
Első sor az érdekes, IBM PC. 8088 ra alapul: 16 bites feldolgozás, 8 bites I/O (olcsóbb megoldás). 16 kbyte RAM. Nem volt háttértár, 5 db ISA foglalat
. 16 kbyte RAM. Nem volt háttértár, 5 db ISA foglalat") 1 2 3 Első sor az érdekes, IBM PC. 8088 ra alapul: 16 bites feldolgozás, 8 bites I/O (olcsóbb megoldás). 16 kbyte RAM. Nem volt háttértár, 5 db ISA foglalat XT: 83. CPU ugyanaz, nagyobb RAM, elsőként jelent
1 2 3 Első sor az érdekes, IBM PC. 8088 ra alapul: 16 bites feldolgozás, 8 bites I/O (olcsóbb megoldás). 16 kbyte RAM. Nem volt háttértár, 5 db ISA foglalat XT: 83. CPU ugyanaz, nagyobb RAM, elsőként jelent
Fejlesztői szemmel - 2010. at K
 Fejlesztői szemmel - 2010 M at K ta is K G i s er C ge on l y su lt in g Tartalom Bemutatkozás Az Androidról röviden, fejlesztői szemmel Az Android 2.2 újdonságai Új média alrendszer: Stagefright Telephony
Fejlesztői szemmel - 2010 M at K ta is K G i s er C ge on l y su lt in g Tartalom Bemutatkozás Az Androidról röviden, fejlesztői szemmel Az Android 2.2 újdonságai Új média alrendszer: Stagefright Telephony
GPU-k a gravitációs hullám kutatásban
 GPU-k a gravitációs hullám kutatásban Debreczeni Gergely MTA KFKI RMKI (Gergely.Debreczeni@rmki.kfki.hu) e-science Cafè 2011. november 14. Óbudai Egyetem Neumann János Informatikai Kar Á.R.: Megfigyelhető
GPU-k a gravitációs hullám kutatásban Debreczeni Gergely MTA KFKI RMKI (Gergely.Debreczeni@rmki.kfki.hu) e-science Cafè 2011. november 14. Óbudai Egyetem Neumann János Informatikai Kar Á.R.: Megfigyelhető
Nyíregyházi Egyetem Matematika és Informatika Intézete. Input/Output
 1 Input/Output 1. I/O műveletek hardveres háttere 2. I/O műveletek szoftveres háttere 3. Diszkek (lemezek) ------------------------------------------------ 4. Órák, Szöveges terminálok 5. GUI - Graphical
1 Input/Output 1. I/O műveletek hardveres háttere 2. I/O műveletek szoftveres háttere 3. Diszkek (lemezek) ------------------------------------------------ 4. Órák, Szöveges terminálok 5. GUI - Graphical
Bentley új generációs alkalmazásai: ContextCapture, LumenRt és Connect Edition. L - Tér Informatika Kft.
 Bentley új generációs alkalmazásai: ContextCapture, LumenRt és Connect Edition L - Tér Informatika Kft. Bentley alkalmazások műszaki folyamatokban Állapot átvétele Tervezett objektumok illesztése meglévő
Bentley új generációs alkalmazásai: ContextCapture, LumenRt és Connect Edition L - Tér Informatika Kft. Bentley alkalmazások műszaki folyamatokban Állapot átvétele Tervezett objektumok illesztése meglévő
CUDA haladó ismeretek
 CUDA haladó ismeretek CUDA környezet részletei Többdimenziós indextér használata Megosztott memória használata Atomi műveletek használata Optimalizálás Hatékonyság mérése Megfelelő blokkméret kiválasztása
CUDA haladó ismeretek CUDA környezet részletei Többdimenziós indextér használata Megosztott memória használata Atomi műveletek használata Optimalizálás Hatékonyság mérése Megfelelő blokkméret kiválasztása
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA. Dr. Szénási Sándor
 KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
2. Generáció (1999-2000) 3. Generáció (2001) NVIDIA TNT2, ATI Rage, 3dfx Voodoo3. Klár Gergely tremere@elte.hu
 3. Generáció (2001) NVIDIA TNT2, ATI Rage, 3dfx Voodoo3. Klár Gergely tremere@elte.hu") 1. Generáció Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. őszi félév NVIDIA TNT2, ATI Rage, 3dfx Voodoo3 A standard 2d-s videokártyák kiegészítése
1. Generáció Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. őszi félév NVIDIA TNT2, ATI Rage, 3dfx Voodoo3 A standard 2d-s videokártyák kiegészítése
GPGPU ÚJ ESZKÖZÖK AZ INFORMÁCIÓBIZTONSÁG TERÜLETÉN
 IV. Évfolyam 4. szám - 2009. december Szénási Sándor szenasi.sandor@nik.bmf.hu GPGPU ÚJ ESZKÖZÖK AZ INFORMÁCIÓBIZTONSÁG TERÜLETÉN Absztrakt A processzor architektúrák elmúlt években bekövetkező fejlődésének
IV. Évfolyam 4. szám - 2009. december Szénási Sándor szenasi.sandor@nik.bmf.hu GPGPU ÚJ ESZKÖZÖK AZ INFORMÁCIÓBIZTONSÁG TERÜLETÉN Absztrakt A processzor architektúrák elmúlt években bekövetkező fejlődésének
Ordering MCMC gyorsítása OpenCL környezetben
 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Méréstechnika és Információs Rendszerek Tanszék Ordering MCMC gyorsítása OpenCL környezetben Önálló laboratórium 1 Készítette
Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Méréstechnika és Információs Rendszerek Tanszék Ordering MCMC gyorsítása OpenCL környezetben Önálló laboratórium 1 Készítette
Operációs rendszerek III.
 A WINDOWS NT memóriakezelése Az NT memóriakezelése Memóriakezelő feladatai: Logikai-fizikai címtranszformáció: A folyamatok virtuális címterének címeit megfelelteti fizikai címeknek. A virtuális memóriakezelés
A WINDOWS NT memóriakezelése Az NT memóriakezelése Memóriakezelő feladatai: Logikai-fizikai címtranszformáció: A folyamatok virtuális címterének címeit megfelelteti fizikai címeknek. A virtuális memóriakezelés
Operációs rendszerek. UNIX fájlrendszer
 Operációs rendszerek UNIX fájlrendszer UNIX fájlrendszer Alapegység: a file, amelyet byte-folyamként kezel. Soros (szekvenciális) elérés. Transzparens (átlátszó) file-szerkezet. Link-ek (kapcsolatok) létrehozásának
Operációs rendszerek UNIX fájlrendszer UNIX fájlrendszer Alapegység: a file, amelyet byte-folyamként kezel. Soros (szekvenciális) elérés. Transzparens (átlátszó) file-szerkezet. Link-ek (kapcsolatok) létrehozásának
Dr. Schuster György október 30.
 Real-time operációs rendszerek RTOS 2015. október 30. Jellemzők ONX POSIX kompatibilis, Jellemzők ONX POSIX kompatibilis, mikrokernel alapú, Jellemzők ONX POSIX kompatibilis, mikrokernel alapú, nem kereskedelmi
Real-time operációs rendszerek RTOS 2015. október 30. Jellemzők ONX POSIX kompatibilis, Jellemzők ONX POSIX kompatibilis, mikrokernel alapú, Jellemzők ONX POSIX kompatibilis, mikrokernel alapú, nem kereskedelmi
GPU (grafikus processzor a nagy teljesítményű feldolgozáshoz, nincs grafikus kimenet)
") Processzor Chipkészlet Memória Windows 7 Ultimate (32-Bit or 64-Bit) Windows 7 Professional (32-Bit or 64-Bit) Windows Vista Ultimate (32-Bit or 64-bit) Windows Vista Business (32-Bit or 64-bit) Red Hat
Processzor Chipkészlet Memória Windows 7 Ultimate (32-Bit or 64-Bit) Windows 7 Professional (32-Bit or 64-Bit) Windows Vista Ultimate (32-Bit or 64-bit) Windows Vista Business (32-Bit or 64-bit) Red Hat
Közösség, projektek, IDE
 Eclipse Közösség, projektek, IDE Eclipse egy nyílt forráskódú (open source) projekteken dolgozó közösség, céljuk egy kiterjeszthető fejlesztői platform és keretrendszer fejlesztése, amely megoldásokkal
Eclipse Közösség, projektek, IDE Eclipse egy nyílt forráskódú (open source) projekteken dolgozó közösség, céljuk egy kiterjeszthető fejlesztői platform és keretrendszer fejlesztése, amely megoldásokkal
Amazon Web Services. Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28.
 Amazon Web Services Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28. Ez nem egy könyváruház? 1994-ben alapította Jeff Bezos Túlélte a dot-com korszakot Eredetileg könyváruház majd az elérhető
Amazon Web Services Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28. Ez nem egy könyváruház? 1994-ben alapította Jeff Bezos Túlélte a dot-com korszakot Eredetileg könyváruház majd az elérhető
Virtualizációs technológiák Linux alatt (teljesítményteszt)
") Virtualizációs technológiák Linux alatt (teljesítményteszt) Ebben a dokumentációban a virtualizációs technológiák sebességét, teljesítményét hasonlítom össze RedHat-alapú Linux disztribúciókkal. A teszteléshez
Virtualizációs technológiák Linux alatt (teljesítményteszt) Ebben a dokumentációban a virtualizációs technológiák sebességét, teljesítményét hasonlítom össze RedHat-alapú Linux disztribúciókkal. A teszteléshez
Intel Pentium G2120 Intel HD Graphics kártyával (3,1 GHz, 3 MB gyorsítótár, 2 mag)
") Rendszerjellemzők Operációs rendszer Windows 8 64 Windows 8 Pro 64 Windows 7 Professional 32 Windows 7 Professional 64 Windows 7 Professional 32 (elérhető Windows 8 Pro 64 downgrade által) Windows 7 Professional
Rendszerjellemzők Operációs rendszer Windows 8 64 Windows 8 Pro 64 Windows 7 Professional 32 Windows 7 Professional 64 Windows 7 Professional 32 (elérhető Windows 8 Pro 64 downgrade által) Windows 7 Professional
Occam 1. Készítette: Szabó Éva
 Occam 1. Készítette: Szabó Éva Párhuzamos programozás Egyes folyamatok (processzek) párhuzamosan futnak. Több processzor -> tényleges párhuzamosság Egy processzor -> Időosztásos szimuláció Folyamatok közötti
Occam 1. Készítette: Szabó Éva Párhuzamos programozás Egyes folyamatok (processzek) párhuzamosan futnak. Több processzor -> tényleges párhuzamosság Egy processzor -> Időosztásos szimuláció Folyamatok közötti
Bevezetés, platformok. Léczfalvy Ádám leczfalvy.adam@nik.bmf.hu
 Bevezetés, platformok Léczfalvy Ádám leczfalvy.adam@nik.bmf.hu Mobil készülékek és tulajdonságaik A mobil eszközök programozása, kihívások, nehézségek Mobilprogramozási platformok Java Micro Edition.NET
Bevezetés, platformok Léczfalvy Ádám leczfalvy.adam@nik.bmf.hu Mobil készülékek és tulajdonságaik A mobil eszközök programozása, kihívások, nehézségek Mobilprogramozási platformok Java Micro Edition.NET
CUDA alapok CUDA projektek. CUDA bemutató. Adatbányászat és Webes Keresés Kutatócsoport SZTAKI
 SZTAKI 2010 Tartalom 1 2 Tartalom 1 2 GPU-k és a CUDA El zmények grakus kártyák: nagy párhuzamos számítási kapacitás eredetileg csak grakus m veleteket tudtak végezni GPU-k és a CUDA El zmények grakus
SZTAKI 2010 Tartalom 1 2 Tartalom 1 2 GPU-k és a CUDA El zmények grakus kártyák: nagy párhuzamos számítási kapacitás eredetileg csak grakus m veleteket tudtak végezni GPU-k és a CUDA El zmények grakus
Big Data. A CERN, mint a. egyik bölcsője... Barnaföldi Gergely Gábor. Berényi Dániel & Biró Gábor & Nagy-Egri Máté Ferenc & Andrew Lowe
 A CERN, mint a Big Data egyik bölcsője... Barnaföldi Gergely Gábor Berényi Dániel & Biró Gábor & Nagy-Egri Máté Ferenc & Andrew Lowe MTA Wigner FK Részecske- és Magfizikai Intézet & Wigner GPU Laboratórium
A CERN, mint a Big Data egyik bölcsője... Barnaföldi Gergely Gábor Berényi Dániel & Biró Gábor & Nagy-Egri Máté Ferenc & Andrew Lowe MTA Wigner FK Részecske- és Magfizikai Intézet & Wigner GPU Laboratórium
Hozzáférés a HPC-hez, kezdő lépések (előadás és demó)
") Hozzáférés a HPC-hez, kezdő lépések (előadás és demó) 2013.04.16. Rőczei Gábor roczei@niif.hu Főbb témák Hozzáférés a HPC-hez (Linux/Windows) Programok elindítása a különböző HPC gépeken Vizualizáció (kapcsolódás
Hozzáférés a HPC-hez, kezdő lépések (előadás és demó) 2013.04.16. Rőczei Gábor roczei@niif.hu Főbb témák Hozzáférés a HPC-hez (Linux/Windows) Programok elindítása a különböző HPC gépeken Vizualizáció (kapcsolódás
UNIX / Linux rendszeradminisztráció
 UNIX / Linux rendszeradminisztráció VIII. előadás Miskolci Egyetem Informatikai és Villamosmérnöki Tanszékcsoport Általános Informatikai Tanszék Virtualizáció Mi az a virtualizáció? Nagyvonalúan: számítógép
UNIX / Linux rendszeradminisztráció VIII. előadás Miskolci Egyetem Informatikai és Villamosmérnöki Tanszékcsoport Általános Informatikai Tanszék Virtualizáció Mi az a virtualizáció? Nagyvonalúan: számítógép
NCS5500 bemutató. Balla Attila
 NCS5500 bemutató Balla Attila Napirend NCS5k család Architektúra Memória Packet forwarding Pozicionálás NCS5500 platform Fix kiépítettségű 1-2 RU magas Nagy portsűrűség 10GE-100GE Base és -SE kivitel Moduláris
NCS5500 bemutató Balla Attila Napirend NCS5k család Architektúra Memória Packet forwarding Pozicionálás NCS5500 platform Fix kiépítettségű 1-2 RU magas Nagy portsűrűség 10GE-100GE Base és -SE kivitel Moduláris
Flynn féle osztályozás Single Isntruction Multiple Instruction Single Data SISD SIMD Multiple Data MISD MIMD
 M5-. A lineáris algebra párhuzamos algoritmusai. Ismertesse a párhuzamos gépi architektúrák Flynn-féle osztályozását. A párhuzamos lineáris algebrai algoritmusok között mi a BLAS csomag célja, melyek annak
M5-. A lineáris algebra párhuzamos algoritmusai. Ismertesse a párhuzamos gépi architektúrák Flynn-féle osztályozását. A párhuzamos lineáris algebrai algoritmusok között mi a BLAS csomag célja, melyek annak
Oktatási Segédlet. OpenCL
 Miskolci Egyetem Gépészmérnöki és Informatikai Kar Oktatási Segédlet OpenCL Új párhuzamos szoftverfejlesztési lehetőségek Dr. Nehéz Károly Miskolc, 2012.02.29 Tartalomjegyzék Tartalomjegyzék Tartalom Bevezetés...
Miskolci Egyetem Gépészmérnöki és Informatikai Kar Oktatási Segédlet OpenCL Új párhuzamos szoftverfejlesztési lehetőségek Dr. Nehéz Károly Miskolc, 2012.02.29 Tartalomjegyzék Tartalomjegyzék Tartalom Bevezetés...
(GP)GPU kezdetek. Avagy hogyan lesz az algoritmusból implementáció. Lectures on Modern Scientific Programming Wigner RCP November 2015.
GPU kezdetek. Avagy hogyan lesz az algoritmusból implementáció. Lectures on Modern Scientific Programming Wigner RCP November 2015.") (GP)GPU kezdetek Avagy hogyan lesz az algoritmusból implementáció Lectures on Modern Scientific Programming Wigner RCP 23-25 November 2015 Tartalom Számítógépes grafika GPU hardver ismeretek GPGPU API
(GP)GPU kezdetek Avagy hogyan lesz az algoritmusból implementáció Lectures on Modern Scientific Programming Wigner RCP 23-25 November 2015 Tartalom Számítógépes grafika GPU hardver ismeretek GPGPU API
Tarantella Secure Global Desktop Enterprise Edition
 Tarantella Secure Global Desktop Enterprise Edition A Secure Global Desktop termékcsalád Az iparilag bizonyított szoftver termékek és szolgáltatások közé tartozó Secure Global Desktop termékcsalád biztonságos,
Tarantella Secure Global Desktop Enterprise Edition A Secure Global Desktop termékcsalád Az iparilag bizonyított szoftver termékek és szolgáltatások közé tartozó Secure Global Desktop termékcsalád biztonságos,
Nokia N9 - MeeGo Harmattan bemutatkozik
 Nokia N9 - MeeGo Harmattan bemutatkozik Bányász Gábor 1 Az előd: Fremantle Nokia N900 2 Fremantle (aka Maemo 5) Okostelefonokra, internet tabletekre (csak ARM proc.) Debian alap
Nokia N9 - MeeGo Harmattan bemutatkozik Bányász Gábor 1 Az előd: Fremantle Nokia N900 2 Fremantle (aka Maemo 5) Okostelefonokra, internet tabletekre (csak ARM proc.) Debian alap
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA CLOUD-ON KACSUK PÉTER, NAGY ENIKŐ, PINTYE ISTVÁN, HAJNAL ÁKOS, LOVAS RÓBERT
 BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA CLOUD-ON KACSUK PÉTER, NAGY ENIKŐ, PINTYE ISTVÁN, HAJNAL ÁKOS, LOVAS RÓBERT TARTALOM MTA Cloud Big Data és gépi tanulást támogató szoftver eszközök Apache Spark
BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA CLOUD-ON KACSUK PÉTER, NAGY ENIKŐ, PINTYE ISTVÁN, HAJNAL ÁKOS, LOVAS RÓBERT TARTALOM MTA Cloud Big Data és gépi tanulást támogató szoftver eszközök Apache Spark
TANÚSÍTVÁNY KARBANTARTÁS Jegyzıkönyv
 TANÚSÍTVÁNY KARBANTARTÁS Jegyzıkönyv A HUNGUARD Számítástechnikai-, informatikai kutató-fejlesztı és általános szolgáltató Kft. a 9/2005. (VII.21.) IHM rendelet alapján, mint a Magyar Köztársaság Miniszterelnöki
TANÚSÍTVÁNY KARBANTARTÁS Jegyzıkönyv A HUNGUARD Számítástechnikai-, informatikai kutató-fejlesztı és általános szolgáltató Kft. a 9/2005. (VII.21.) IHM rendelet alapján, mint a Magyar Köztársaság Miniszterelnöki
Szoftver labor III. Tematika. Gyakorlatok. Dr. Csébfalvi Balázs
 Szoftver labor III. Dr. Csébfalvi Balázs Irányítástechnika és Informatika Tanszék e-mail: cseb@iit.bme.hu http://www.iit.bme.hu/~cseb/ Tematika Bevezetés Java programozás alapjai Kivételkezelés Dinamikus
Szoftver labor III. Dr. Csébfalvi Balázs Irányítástechnika és Informatika Tanszék e-mail: cseb@iit.bme.hu http://www.iit.bme.hu/~cseb/ Tematika Bevezetés Java programozás alapjai Kivételkezelés Dinamikus
Informatikai Tesztek Katalógus
 Informatikai Tesztek Katalógus 2019 SHL és/vagy partnerei. Minden jog fenntartva Informatikai tesztek katalógusa Az SHL informatikai tesztek katalógusa számítástechnikai tudást mérő teszteket és megoldásokat
Informatikai Tesztek Katalógus 2019 SHL és/vagy partnerei. Minden jog fenntartva Informatikai tesztek katalógusa Az SHL informatikai tesztek katalógusa számítástechnikai tudást mérő teszteket és megoldásokat
Lineáris egyenlet. Lineáris egyenletrendszer. algebrai egyenlet konstansok és első fokú ismeretlenek pl.: egyenes egyenlete
 Lieáris egyelet algebrai egyelet kostasok és első fokú ismeretleek pl.: egyees egyelete Lieáris egyeletredser y a b lieáris egyeletek csoportja ugya ao a váltoó halmao Lieáris egyeletredser B b B b B b
Lieáris egyelet algebrai egyelet kostasok és első fokú ismeretleek pl.: egyees egyelete Lieáris egyeletredser y a b lieáris egyeletek csoportja ugya ao a váltoó halmao Lieáris egyeletredser B b B b B b
SQLServer. SQLServer konfigurációk
 SQLServer 2. téma DBMS installáció SQLServer konfigurációk 1 SQLServer konfigurációk SQLServer konfigurációk Enterprise Edition Standart Edition Workgroup Edition Developer Edition Express Edition 2 Enterprise
SQLServer 2. téma DBMS installáció SQLServer konfigurációk 1 SQLServer konfigurációk SQLServer konfigurációk Enterprise Edition Standart Edition Workgroup Edition Developer Edition Express Edition 2 Enterprise
TELJESÍTÉNYMÉRÉS FELHŐ ALAPÚ KÖRNYEZETBEN AZURE CLOUD ANALÍZIS
 TELJESÍTÉNYMÉRÉS FELHŐ ALAPÚ KÖRNYEZETBEN AZURE CLOUD ANALÍZIS Hartung István BME Irányítástechnika és Informatika Tanszék TEMATIKA Cloud definíció, típusok, megvalósítási modellek Rövid Azure cloud bemutatás
TELJESÍTÉNYMÉRÉS FELHŐ ALAPÚ KÖRNYEZETBEN AZURE CLOUD ANALÍZIS Hartung István BME Irányítástechnika és Informatika Tanszék TEMATIKA Cloud definíció, típusok, megvalósítási modellek Rövid Azure cloud bemutatás
Apple számítógépek összehasonlító táblázata
 Remac Computer MacBook White 13" MacBook Pro 13" MacBook Pro 13" MacBook Pro 15" MacBook Pro 15" MacBookPro 15" (MC516ZH/A ) (MC374LL/A) (MC375LL/A) (MC371LL/A) (MB372LL/A) (MB373LL/A) Burkolat Polikarbonát
Remac Computer MacBook White 13" MacBook Pro 13" MacBook Pro 13" MacBook Pro 15" MacBook Pro 15" MacBookPro 15" (MC516ZH/A ) (MC374LL/A) (MC375LL/A) (MC371LL/A) (MB372LL/A) (MB373LL/A) Burkolat Polikarbonát
Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása. Rákosi Péter és Lányi Árpád
 Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása Rákosi Péter és Lányi Árpád Adattárház korábbi üzemeltetési jellemzői Online szolgáltatásokat nem szolgált ki, klasszikus elemzésre
Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása Rákosi Péter és Lányi Árpád Adattárház korábbi üzemeltetési jellemzői Online szolgáltatásokat nem szolgált ki, klasszikus elemzésre
Komponens alapú fejlesztés
 Komponens alapú fejlesztés Szoftver újrafelhasználás Szoftver fejlesztésekor korábbi fejlesztésekkor létrehozott kód felhasználása architektúra felhasználása tudás felhasználása Nem azonos a portolással
Komponens alapú fejlesztés Szoftver újrafelhasználás Szoftver fejlesztésekor korábbi fejlesztésekkor létrehozott kód felhasználása architektúra felhasználása tudás felhasználása Nem azonos a portolással
Mutatók és mutató-aritmetika C-ben március 19.
 Mutatók és mutató-aritmetika C-ben 2018 március 19 Memória a Neumann-architektúrában Neumann-architektúra: a memória egységes a címzéshez a természetes számokat használjuk Ugyanabban a memóriában van:
Mutatók és mutató-aritmetika C-ben 2018 március 19 Memória a Neumann-architektúrában Neumann-architektúra: a memória egységes a címzéshez a természetes számokat használjuk Ugyanabban a memóriában van:
Az operációs rendszerek fejlődése
 Az operációs rendszerek fejlődése PC Windows UNIX DOS Windows 3.1 LINUX Otthoni Windows 95 Windows 98 Windows 98 SE Windows Milennium Windows XP Vállalati Windows NT 4.0 Windows 2000 Mac OS X Home Professional
Az operációs rendszerek fejlődése PC Windows UNIX DOS Windows 3.1 LINUX Otthoni Windows 95 Windows 98 Windows 98 SE Windows Milennium Windows XP Vállalati Windows NT 4.0 Windows 2000 Mac OS X Home Professional
Bevezetés az informatikába
 Bevezetés az informatikába 5. előadás Dr. Istenes Zoltán Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék Matematikus BSc - I. félév / 2008 / Budapest Dr.
Bevezetés az informatikába 5. előadás Dr. Istenes Zoltán Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék Matematikus BSc - I. félév / 2008 / Budapest Dr.