Grafikus kártyák, mint olcsó szuperszámítógépek - I.
|
|
|
- Barnabás Erik Dudás
- 10 évvel ezelőtt
- Látták:
Átírás

1 (1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport

2 (2) Vázlat I. Motiváció Beüzemelés C alapok CUDA programozási modell, hardware adottságok II. Optimalizálás Tippek (pl. több GPU egyidejű használata) Könyvtárak (cufft, cublas,...) GPU számolás CUDA programozás nélkül

3 (3) Irodalom - CUDA CUDA, Supercomputing for the Masses Part CUDA official manuals Programming Guide, Reference Manual, Release Notes

4 (4) Irodalom - Egyéb Kernighan, Ritchie: The C Programming Language OpenMP tutorial MPI tutorial

5 Motiváció (5)


6 (6) Szuperszámítógép GPU-ból
7 (7) Moore törvénye Tranzisztorok száma másfél-két évente duplázódik Számítógép sebessége exp. növekszik DE az utóbbi ~4 évben megtorpant! 3GHz, 45nm

8 (8) A párhuzamosítás korszaka! Nem a sebesség, hanem a processzorok száma nő Át kell gondolni algoritmusaink szerkezetét: soros párhuzamos

9 (9) A párhuzamosítás korszaka! MPI (Message Passing Interface) - process szintű Tipikus sok gép (klaszter) esetén Külön memória a processznek Hálózati (TCP/IP) adattranszfer

10 ( 10 ) A párhuzamosítás korszaka! OpenMP (Open Multi-Processing) szál (thread) szintű Egy gép sok mag esetén Szálak: közös memóriaterület + saját változók

11 Grafikus kártyák nvidia GTX295: 2 x 240 db 1.3GHz proc 2 x 900MB memória Tesla C x 240 db 1.3GHz proc 1 x 4000MB memória ( 11 )


12 ( 12 ) Grafikus kártyák CPU + coprocesszor (GPU) 1920 mag, 14 Tflops (float) (FLoating point Operations Per Second) 200x asztali gép teljesítmény,,személyi szuperszámítógép : 1 kutató, 1 számítógép Elérhető: megfizethető ár win/linux/mac + C


13 Heterogén számolások Host computer + Device ( 13 )


14 GPU vs. CPU TEXT Számítási teljesítmény ( 14 )


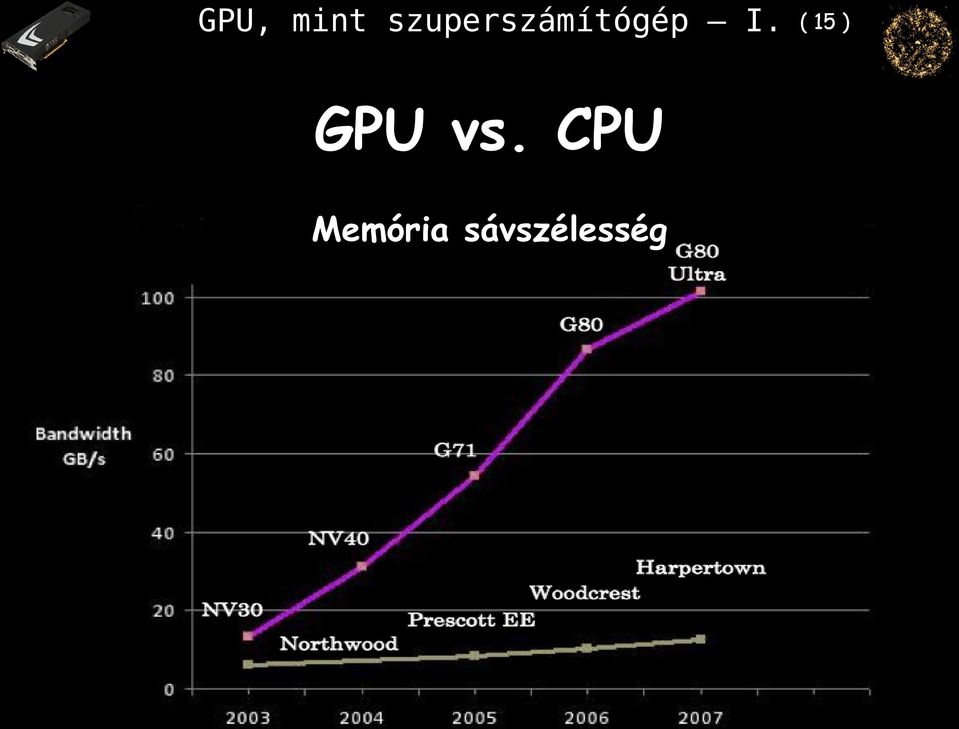
15 GPU vs. CPU Memória sávszélesség ( 15 )

16 ( 16 ) GPU vs. CPU Szál-végrehajtás CPU: MIMD Multiple Instruction, Multiple Data GPU: SIMD Single Instruction, Multiple Data

17 ( 17 ) GPU vs. CPU A nagy memória (RAM) elérése rendkívül időigényes (~100 órajel) gyorsítás szükséges CPU GPU ~MB gyorsmemória (cache) a CPU-n kicsi (~16kB) gyorsmemória de ~128szál/mag hyperthreading
 a CPU-n kicsi (~16kB)")
 (- intel: Larrabee, ~x86) OpenCL (Open Computing Language): nyílt szabvány heterogén rendszerek (pl.")
18 ( 18 ) GPGPU programozás története Kezdet: masszív GPU programozás Utóbbi években két fejlesztői környezet: - nvidia Compute Unified Device Architecture, CUDA - AMD Firestream (ATI) (- intel: Larrabee, ~x86) OpenCL (Open Computing Language): nyílt szabvány heterogén rendszerek (pl. CPU+GPU) programozáshoz
: nyílt szabvány heterogén rendszerek (pl.")
19 ( 19 ) CUDA Compute Unified Device Architecture Magas szintű kiterjesztés a C/C++ nyelvhez CUDA programozási és memória modell nvcc fordító GPUmagok számával skálázódó programok (kód újrafordítása nélkül)


20 Példák TEXT ( 20 )

21 ( 21 ) Példák Molekula dinamika / kvantumkémia kódok + GPU
22 CUDA - Beüzemelés ( 22 )

23 ( 23 ) CUDA eszközök
24 CUDA telepítés Hardware: GPU: 4 x nvidia GTX295 (1920 x 1.3GHz mag) CPU: Intel(R) Xeon(R) CPU 2.27GHz (8 valós + 8 virtuális mag) Software: OpenSuse 11.2 Linux gcc kernel x86_64 ( 24 )
25 CUDA telepítés Hardware: GPU: 4 x nvidia GTX295 (1920 x 1.3GHz mag) CPU: Intel(R) Xeon(R) CPU 2.27GHz (8 valós + 8 virtuális mag) Software: OpenSuse 11.2 Linux gcc kernel x86_64 ( 25 )
26 CUDA telepítés Hardware: GPU: 4 x nvidia GTX295 (1920 x 1.3GHz mag) CPU: Intel(R) Xeon(R) CPU 2.27GHz (8 valós + 8 virtuális mag) Software: OpenSuse 11.2 Linux gcc kernel x86_64 ( 26 )
27 CUDA telepítés Hardware: GPU: 4 x nvidia GTX295 (1920 x 1.3GHz mag) CPU: Intel(R) Xeon(R) CPU 2.27GHz (8 valós + 8 virtuális mag) Software: OpenSuse 11.2 Linux gcc kernel x86_64 ( 27 )
28 ( 28 ) CUDA telepítés Driver (root-ként telepíteni) nvidia.ko; /usr/lib64/libcuda.so Toolkit (célszerű root-ként telepíteni) nvcc compiler; CUDA FFT,BLAS; profiler; gdb default install: /usr/local/cuda SDK (Software Development Kit; lehet felhasználóként is telepíteni) Példaprogramok; ~/NVIDIA_GPU_Computing_SDK

29 ( 29 ) CUDA letöltések
30 ( 30 ) CUDA letöltések
31 ( 31 ) CUDA telepítés Driver NVIDIA-Linux-x86_ pkg2.run root@linux> sh NVIDIA-Linux-x86_ pkg2.run szükséges: Base-development (gcc, make) Kernel-devel (kernel-source, headers) Toolkit cudatoolkit_2.3_linux_64_suse11.1.run root@linux> sh cudatoolkit_2.3_linux_64_suse11.1.run SDK cudasdk_2.3_linux.run user@linux> sh cudasdk_2.3_linux.run
32 ( 32 ) CUDA telepítés rendszerbeállítások Futtatni release_notes_linux.txt (CUDA download page) scriptjét (- load module, devs) ~/.bashrc-be: export PATH=/usr/local/cuda/bin export LD_LIBRARY_PATH=/usr/local/cuda/lib64 Megj. ( nem támogatott linux esetén): nvcc nem kompatibilis gcc-4.4-gyel gcc-4.3 SDK példaprog.-hoz kellett: freeglut freeglut-devel
33 ( 33 ) SDK - példaprogramok Fordítás: cd ~/NVIDIA_GPU_Computing_SDK/C make Példaprogramok: cd ~/NVIDIA_GPU_Computing_SDK/C/bin/linux/release ls

34 ( 34 ) SDK - példaprogramok TEXT
35 C gyorstalpaló ( 35 )
36 ( 36 ) C gyorstalpaló main függvény, változók int main(void) { int i; // main fg. definiálás // lokális változó def. i=1; // értékadás return(i); // fg. visszatérési érték } // Ez egy komment Adattípusok: int, float, double, char,...
37 C gyorstalpaló Fordítás: gcc -o test.out test.c Futtatás:./test.out ( 37 )
38 ( 38 ) C gyorstalpaló Külső függvények #include <stdio.h> void main(void) { int i; i=1; // küls fg-ek deklarálása // main fg. definiálás // lokális változó def. // értékadás printf( %d\n,i); // küls fg. hívása } // Ez egy komment Adattípusok: int, float, double, char,...
39 C gyorstalpaló Külső függvények #include <math.h> #include <stdio.h> // void main(void) { double x; x = sqrt(2.0); printf( %e\n,x); } // Küls fg. ( 39 )
40 C gyorstalpaló Fordítás: gcc -o test.out test.c -lm Futtatás:./test.out ( 40 )
41 ( 41 ) C gyorstalpaló Függvények int foo(int i, int j) { return(j*i); } int main(void) { int i=1; } // fg. definiálás // visszatérési érték // main fg. definiálás // lokális változó def. i = foo(2,i); // függvényhívás return(i); // fg. visszatérési érték
42 ( 42 ) C gyorstalpaló Függvények int foo(int i, int j); int main(void) { int i=1; // fg. deklarálás // main fg. definiálás // lokális változó def. i = foo(2,i); // függvényhívás return(i); // fg. visszatérési érték } int foo(int i, int j) { return(j*i); } // fg. definiálás // visszatérési érték
43 ( 43 ) C gyorstalpaló Mutatók int i, *p ; p p = &i ; *p Memória i i
44 ( 44 ) C gyorstalpaló Mutatók #include <stdio.h> void main(void) { int i, *p; // mutató definiálás i=1; p = &i; // mutató i címére printf( %d %d\n,i,*p);// p értékének kiírása *p = 2; // értékadás p értékére printf( %d %d\n,i,*p); // kiiratás }
45 ( 45 ) C gyorstalpaló Mutatók - tömbök int *p ; p p+2 Memória p[0] p[2] sizeof(int) p = malloc(5*sizeof(int)); p[0] *p p[2] *(p+2)
46 ( 46 ) C gyorstalpaló Tömbök - vektorok #include <stdlib.h> void main(void) { int i, *p, N=10; p = (int*)malloc(n*sizeof(int)); //din.mem.f. for (i=0; i<n; i=i+1) // tömbfeltöltés { p[i] = 2*i; // vektorelem } // 2.0: double, 2.0f: float free(p); } // mem. felszabadítás
47 ( 47 ) C gyorstalpaló Tömbök - mátrixok #include <stdlib.h> void main(void) { int i, j, *p, N=10, M=20; p = (int*)malloc(n*m*sizeof(int)); //mem.f. for (i=0; i<n; i=i+1) { for (j=0; j<m; j=j+1) { p[i*m+j] = 2*(i*M+j); } } free(p); } // tömbfeltöltés
48 ( 48 ) CUDA programozási modell és hardware felépítés
49 ( 49 ) Programozási modell A CPU egy számoló egysége (coprocesszora) a GPU. A CPU és GPU külön memóriával rendelkezik (adatmásolás) Az eszközre fordított objektum a kernel A szálanként (thread) futó kernel adatpárhuzamos sok azonos vázú számolás különböző adatokon
50 ( 50 ) Kódséma CUDA programkód (.cu kiterjesztéssel) Fordítás nvcc fordítóval Futtatás Megj.: célszerű egy könyvtárat létrehozni az adott részfeladat GPU-n történő elvégzéséhez, majd azt CPU-s programunkhoz kapcsolni ( linkelni ).
51 ( 51 ) Kódséma CUDA programkód: GPU-n futó rész (kernel): fg., ami a számolási feladat időigényes részét számolja (általában eredetileg röveidebb CPU kódrész) CPU-n futó rész: adatelőkészítés adatmásolás a GPU-ra GPU kernel futtatása adatmásolás a GPU-ról
52 Futtatási modell Emlékeztető: OpenMP a CPU-n N N-2 N-1 N-1 Szálak: 0, 1, 2,..., N-1 ( 52 )

53 SDK - devicequery ( 53 )
54 ( 54 ) Fizikai felépítés N db multiprocessor (MP) M db singleprocessor(sp) / MP Reg Reg Global S H A R E D GeForce 9400M GTX295 N 2 30 M 8 8 Órajel 0.2 GHz 1.24 GHz Megj. dupla kártya
55 ( 55 ) Futtatási modell Device Grid Block 0 A grid thread blockokból áll A threadek a kernelt hajtják végre Thread 0 Thread 1... Thread bsize-1... A blockok számát és méretét (execution configuration) a host alkalmazás állítja be Block nblck-1 Thread 0 Thread 1... Thread bsize-1 Azonosítás (beépített): blockidx, threadidx (blockon belül), blockdim idx = blockidx.x * blockdim.x + threadidx.x
56 ( 56 ) Futtatási modell Device Grid griddim.x = 3, blockdim.x = 4 blockidx.x=0 blockidx.x=1 blockidx.x=2 threadidx.x: Global threadid: idx = blockidx.x * blockdim.x + threadidx.x

57 ( 57 ) Futtatási modell A grid és a blockok méretét a host alkalmazás állítja be Grid dim.: 1 vagy 2 Block dim.: 1, 2 vagy 3 pl. threadidx.x threadidx.y threadidx.z
58 ( 58 ) Példaprogram soros CPU #include <stdlib.h> void myfunc(float *v, int D, float c) {... } int main(void) { int i, D= , s; float *h; s = D * sizeof(float); // size in bytes h = (float*) malloc(s); for (i=0; i<d; i=i+1) { h[i] = (float)i; } myfunc (h, D, 2.0f); free(h); }
59 ( 59 ) Példaprogram soros CPU #include <stdlib.h> void myfunc(float *v, int D, float c) { int i; for (i=0; i<d; i=i+1) { v[i] = v[i] * c; } } int main(void) {... } 0 1 D
60 ( 60 ) Példaprogram párhuzamos CPU #include <stdlib.h> #include <omp.h> void myfunc(float *v, int D, float c) { int id,n,i; N = omp_get_num_procs(); omp_set_num_threads(n); #pragma omp parallel private(id,i) { id = omp_get_thread_num(); for (i=id; i<d; i=i+n) { v[i] = v[i] * c; } } } i. thread: i i+n i+2n
61 ( 61 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { } int main(void) { int i, D= , s; float *h, *d; s = D * sizeof(float); cudamallochost((void**) &h, s); cudamalloc( (void**) &d, s) ; for (i=0; i<d; i=i+1) { h[i] = (float)i; } cudamemcpy( d, h, s, cudamemcpyhosttodevice); dim3 grid (30); dim3 threads (32); mykernel <<< grid, threads >>> (d, D, 2.0f); cudamemcpy( h, d, s, cudamemcpydevicetohost); cudafreehost(h); cudafree(d); }
62 ( 62 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { } int main(void) { // var. deklarációk int i, D= , s; // tömb hossza byte-ban float *h, *d; s = D * sizeof(float); cudamallochost((void**) &h, s); cudamalloc( (void**) &d, s) ; for (i=0; i<d; i=i+1) { h[i] = (float)i; } cudamemcpy( d, h, s, cudamemcpyhosttodevice); dim3 grid (30); dim3 threads (32); mykernel <<< grid, threads >>> (d, D, 2.0f); cudamemcpy( h, d, s, cudamemcpydevicetohost); cudafreehost(h); cudafree(d); }
63 ( 63 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { } int main(void) { // mem. foglalás int i, D= , s; // host-on és device-on float *h, *d; s = D * sizeof(float); cudamallochost((void**) &h, s); cudamalloc( (void**) &d, s) ; for (i=0; i<d; i=i+1) { h[i] = (float)i; } cudamemcpy( d, h, s, cudamemcpyhosttodevice); dim3 grid (30); dim3 threads (32); mykernel <<< grid, threads >>> (d, D, 2.0f); cudamemcpy( h, d, s, cudamemcpydevicetohost); cudafreehost(h); cudafree(d); }
64 ( 64 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { } int main(void) { // tömb inicializálás int i, D= , s; float *h, *d; s = D * sizeof(float); cudamallochost((void**) &h, s); cudamalloc( (void**) &d, s) ; for (i=0; i<d; i=i+1) { h[i] = (float)i; } cudamemcpy( d, h, s, cudamemcpyhosttodevice); dim3 grid (30); dim3 threads (32); mykernel <<< grid, threads >>> (d, D, 2.0f); cudamemcpy( h, d, s, cudamemcpydevicetohost); cudafreehost(h); cudafree(d); }
65 ( 65 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { } int main(void) { // tömb másolása device-ra int i, D= , s; float *h, *d; s = D * sizeof(float); cudamallochost((void**) &h, s); cudamalloc( (void**) &d, s) ; for (i=0; i<d; i=i+1) { h[i] = (float)i; } cudamemcpy( d, h, s, cudamemcpyhosttodevice); dim3 grid (30); dim3 threads (32); mykernel <<< grid, threads >>> (d, D, 2.0f); cudamemcpy( h, d, s, cudamemcpydevicetohost); cudafreehost(h); cudafree(d); }
66 ( 66 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { } int main(void) { // grid definiálás int i, D= , s; float *h, *d; s = D * sizeof(float); cudamallochost((void**) &h, s); cudamalloc( (void**) &d, s) ; for (i=0; i<d; i=i+1) { h[i] = (float)i; } cudamemcpy( d, h, s, cudamemcpyhosttodevice); dim3 grid (30); dim3 threads (32); mykernel <<< grid, threads >>> (d, D, 2.0f); cudamemcpy( h, d, s, cudamemcpydevicetohost); cudafreehost(h); cudafree(d); }
67 ( 67 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { } int main(void) { // kernel futtatása device-on int i, D= , s; // futtatási konfig. megadása float *h, *d; s = D * sizeof(float); cudamallochost((void**) &h, s); cudamalloc( (void**) &d, s) ; for (i=0; i<d; i=i+1) { h[i] = (float)i; } cudamemcpy( d, h, s, cudamemcpyhosttodevice); dim3 grid (30); dim3 threads (32); mykernel <<< grid, threads >>> (d, D, 2.0f); cudamemcpy( h, d, s, cudamemcpydevicetohost); cudafreehost(h); cudafree(d); }
68 ( 68 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { } int main(void) { // eredmény visszamásolása int i, D= , s; float *h, *d; s = D * sizeof(float); cudamallochost((void**) &h, s); cudamalloc( (void**) &d, s) ; for (i=0; i<d; i=i+1) { h[i] = (float)i; } cudamemcpy( d, h, s, cudamemcpyhosttodevice); dim3 grid (30); dim3 threads (32); mykernel <<< grid, threads >>> (d, D, 2.0f); cudamemcpy( h, d, s, cudamemcpydevicetohost); cudafreehost(h); cudafree(d); }
69 ( 69 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { } int main(void) { // memóriafelszabadítás int i, D= , s; // host-on és device-on float *h, *d; s = D * sizeof(float); cudamallochost((void**) &h, s); cudamalloc( (void**) &d, s) ; for (i=0; i<d; i=i+1) { h[i] = (float)i; } cudamemcpy( d, h, s, cudamemcpyhosttodevice); dim3 grid (30); dim3 threads (32); mykernel <<< grid, threads >>> (d, D, 2.0f); cudamemcpy( h, d, s, cudamemcpydevicetohost); cudafreehost(h); cudafree(d); }
70 ( 70 ) Példaprogram - CUDA device void mykernel(float *v, int D, float c) { int id,n,i; id = blockidx.x * blockdim.x + threadidx.x ; N = griddim.x * blockdim.x; for (i=id; i<d; i=i+n) { v[i] = v[i] * c; } } int main(void) {... } i. thread: i i+n i+2n
71 ( 71 ) Példaprogramok Fordítás: gcc -o testserial.out testserial.c gcc -o testomp.out testomp.c -fopenmp -lgomp nvcc -o testcuda.out testcuda.c
72 Aritmetika időigénye ( 72 )
73 GPU memória Global Shared Register Constant Texture Local ( 73 )
74 ( 74 ) GPU memória Global (~GB): lassú elérés ( órajel) host és device írja, olvassa elérése gyorsítható, ha a szálak rendezetten olvasnak/írnak pl. cudamalloc cudamemcpy
75 ( 75 ) GPU memória Register (16384 db): leggyorsabb memória egy thread látja csak device írja/olvassa pl. kernel ( device ) lokális változói: int id, N, i;
76 ( 76 ) GPU memória Shared (16kB): gyors egy Block összes threadje látja csak device írja/olvassa pl. kernelben: shared float x[8]
77 ( 77 ) GPU memória Local: lassú (global-ban fekszik) csak egy thread látja csak device írja/olvassa
78 ( 78 ) GPU memória Constant: ld. irodalom Texture: ld. irodalom
79 ( 79 ) GPU memória Memória láthatóság R/W sebesség Global grid RW lassú Shared block RW gyors Register thread RW gyors Local thread RW lassú Constant grid RO lassú/cache gyorsít Texture grid RO lassú/cache gyorsít

80 ( 80 ) Fizikai végrehajtás Reg Reg Global S H A R E D N db multiprocessor (MP) M db singleprocessor(sp) / MP Egy MP több Blockot is számol - egy Block-ot egy MP számol Minden Block SIMD csoportokra van osztva: warp - a warpok fizikailag egyszerre hajtódnak végre Egy warpot alkotó threadek ID-jai egymást követőek manapság a warp 32 szálból áll

81 CUDA skálázódás ( 81 )

82 CUDA skálázódás ( 82 )
83 ( 83 ) Következmények # Block / # MP 1 minden MP számol # Block / # MP 2 egy MP egyszerre több Blockot is számol # Block / # MP 100 egy Block erőforrás-igénye MP teljes erőforrása shared memória, register egy MP egyszerre több Blockot is számolhat egy warpon belüli thread-divergencia kerülendő a különböző ágak sorbarendezve hajtódnak végre
84 ( 84 ) FOLYT. KÖV.: Optimalizálás
Grafikus kártyák, mint olcsó szuperszámítógépek - I.
 (1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. RMKI GPU nap 2010 Jurek Zoltán, Tóth Gyula MTA SZFKI, Röntgendiffrakciós csoport (2) Vázlat Motiváció Beüzemelés GPU számolás CUDA programozás nélkül,
(1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. RMKI GPU nap 2010 Jurek Zoltán, Tóth Gyula MTA SZFKI, Röntgendiffrakciós csoport (2) Vázlat Motiváció Beüzemelés GPU számolás CUDA programozás nélkül,
Grafikus kártyák, mint olcsó szuperszámítógépek - II.
 GPU, mint szuperszámítógép II. ( 1 ) Grafikus kártyák, mint olcsó szuperszámítógépek - II. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport GPU, mint szuperszámítógép II. (
GPU, mint szuperszámítógép II. ( 1 ) Grafikus kártyák, mint olcsó szuperszámítógépek - II. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport GPU, mint szuperszámítógép II. (
Párhuzamos és Grid rendszerek
 Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
Videókártya - CUDA kompatibilitás: CUDA weboldal: Példaterületek:
 Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
OpenCL - The open standard for parallel programming of heterogeneous systems
 OpenCL - The open standard for parallel programming of heterogeneous systems GPU-k általános számításokhoz GPU Graphics Processing Unit Képalkotás: sok, általában egyszerű és független művelet < 2006:
OpenCL - The open standard for parallel programming of heterogeneous systems GPU-k általános számításokhoz GPU Graphics Processing Unit Képalkotás: sok, általában egyszerű és független művelet < 2006:
Magas szintű optimalizálás
 Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
CUDA alapok CUDA projektek. CUDA bemutató. Adatbányászat és Webes Keresés Kutatócsoport SZTAKI
 SZTAKI 2010 Tartalom 1 2 Tartalom 1 2 GPU-k és a CUDA El zmények grakus kártyák: nagy párhuzamos számítási kapacitás eredetileg csak grakus m veleteket tudtak végezni GPU-k és a CUDA El zmények grakus
SZTAKI 2010 Tartalom 1 2 Tartalom 1 2 GPU-k és a CUDA El zmények grakus kártyák: nagy párhuzamos számítási kapacitás eredetileg csak grakus m veleteket tudtak végezni GPU-k és a CUDA El zmények grakus
Hallgatói segédlet: Nvidia CUDA C programok debugolása Nvidia Optimus technológiás laptopokon. Készítette: Kovács Andor. 2011/2012 első félév
 Hallgatói segédlet: Nvidia CUDA C programok debugolása Nvidia Optimus technológiás laptopokon Készítette: Kovács Andor 2011/2012 első félév 1 A CUDA programok debugolásához kettő grafikus kártyára van
Hallgatói segédlet: Nvidia CUDA C programok debugolása Nvidia Optimus technológiás laptopokon Készítette: Kovács Andor 2011/2012 első félév 1 A CUDA programok debugolásához kettő grafikus kártyára van
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási
 GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
A CUDA előnyei: - Elszórt memória olvasás (az adatok a memória bármely területéről olvashatóak) PC-Vilag.hu CUDA, a jövő technológiája?!
 PC-Vilag.hu CUDA, a jövő technológiája?!") A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN
 KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
GPGPU. GPU-k felépítése. Valasek Gábor
 GPGPU GPU-k felépítése Valasek Gábor Tartalom A mai órán áttekintjük a GPU-k architekturális felépítését A cél elsősorban egy olyan absztrakt hardvermodell bemutatása, ami segít megérteni a GPU-k hardveres
GPGPU GPU-k felépítése Valasek Gábor Tartalom A mai órán áttekintjük a GPU-k architekturális felépítését A cél elsősorban egy olyan absztrakt hardvermodell bemutatása, ami segít megérteni a GPU-k hardveres
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programok futásának kiértékelése Scalasca profiler segítségével
 Párhuzamos programok futásának kiértékelése segítségével 2014. Április 24. Pécs, Networkshop 2014 Rőczei Gábor roczei@niif.hu Főbb témák Miért használjunk szuperszámítógépet?! Alapfogalmak Miért van szükség
Párhuzamos programok futásának kiértékelése segítségével 2014. Április 24. Pécs, Networkshop 2014 Rőczei Gábor roczei@niif.hu Főbb témák Miért használjunk szuperszámítógépet?! Alapfogalmak Miért van szükség
Jurek Zoltán, Tóth Gyula
 Grafikus kártyák, mint olcsó szuperszámítógépek II. rész: GPU nap 2010, MTA RMKI Budapest, 2010. június 4. Tartalom 1 A CUDA futtatási modellje Implementáció 2 Make it work. - A működő párhuzamos kódig
Grafikus kártyák, mint olcsó szuperszámítógépek II. rész: GPU nap 2010, MTA RMKI Budapest, 2010. június 4. Tartalom 1 A CUDA futtatási modellje Implementáció 2 Make it work. - A működő párhuzamos kódig
Négyprocesszoros közvetlen csatolású szerverek architektúrája:
 SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely
 Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
Heterogén számítási rendszerek gyakorlatok (2017.)
") Heterogén számítási rendszerek gyakorlatok (2017.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 6 2.1 Global
Heterogén számítási rendszerek gyakorlatok (2017.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 6 2.1 Global
CUDA haladó ismeretek
 CUDA haladó ismeretek CUDA környezet részletei Többdimenziós indextér használata Megosztott memória használata Atomi műveletek használata Optimalizálás Hatékonyság mérése Megfelelő blokkméret kiválasztása
CUDA haladó ismeretek CUDA környezet részletei Többdimenziós indextér használata Megosztott memória használata Atomi műveletek használata Optimalizálás Hatékonyság mérése Megfelelő blokkméret kiválasztása
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
GPGPU. Architektúra esettanulmány
 GPGPU Architektúra esettanulmány GeForce 7800 (2006) GeForce 7800 Rengeteg erőforrást fordítottak arra, hogy a throughput-ot maximalizálják Azaz a különböző típusú feldolgozóegységek (vertex és fragment
GPGPU Architektúra esettanulmány GeForce 7800 (2006) GeForce 7800 Rengeteg erőforrást fordítottak arra, hogy a throughput-ot maximalizálják Azaz a különböző típusú feldolgozóegységek (vertex és fragment
GPGPU-k és programozásuk
 GPGPU-k és programozásuk Szénási Sándor Augusztus 2013 (1.1 verzió) Szénási Sándor Tartalomjegyzék 1. Bevezetés 2. Programozási modell 1. CUDA környezet alapjai 2. Fordítás és szerkesztés 3. Platform modell
GPGPU-k és programozásuk Szénási Sándor Augusztus 2013 (1.1 verzió) Szénási Sándor Tartalomjegyzék 1. Bevezetés 2. Programozási modell 1. CUDA környezet alapjai 2. Fordítás és szerkesztés 3. Platform modell
4. Funkcionális primitívek GPUn
 4. Funkcionális primitívek GPUn GPU API emlékeztető Jelenleg a következő eszközök állnak rendelkezésre GPUs kódok futtatására: DirectX vagy OpenGL vagy Vulkan Compute Shader Ez grafikai célokra van kitalálva,
4. Funkcionális primitívek GPUn GPU API emlékeztető Jelenleg a következő eszközök állnak rendelkezésre GPUs kódok futtatására: DirectX vagy OpenGL vagy Vulkan Compute Shader Ez grafikai célokra van kitalálva,
Számítógépek felépítése
 Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Az MTA Cloud a tudományos alkalmazások támogatására. Kacsuk Péter MTA SZTAKI
 Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Mutatók és mutató-aritmetika C-ben március 19.
 Mutatók és mutató-aritmetika C-ben 2018 március 19 Memória a Neumann-architektúrában Neumann-architektúra: a memória egységes a címzéshez a természetes számokat használjuk Ugyanabban a memóriában van:
Mutatók és mutató-aritmetika C-ben 2018 március 19 Memória a Neumann-architektúrában Neumann-architektúra: a memória egységes a címzéshez a természetes számokat használjuk Ugyanabban a memóriában van:
OpenCL Kovács, György
 OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre
 GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
Bevezetés a párhuzamos programozási koncepciókba
 Bevezetés a párhuzamos programozási koncepciókba Kacsuk Péter és Dózsa Gábor MTA SZTAKI Párhuzamos és Elosztott Rendszerek Laboratórium E-mail: kacsuk@sztaki.hu Web: www.lpds.sztaki.hu Programozási modellek
Bevezetés a párhuzamos programozási koncepciókba Kacsuk Péter és Dózsa Gábor MTA SZTAKI Párhuzamos és Elosztott Rendszerek Laboratórium E-mail: kacsuk@sztaki.hu Web: www.lpds.sztaki.hu Programozási modellek
A C programozási nyelv V. Struktúra Dinamikus memóriakezelés
 A C programozási nyelv V. Struktúra Dinamikus memóriakezelés Miskolci Egyetem Általános Informatikai Tanszék A C programozási nyelv V. (Struktúra, memóriakezelés) CBEV5 / 1 A struktúra deklarációja 1.
A C programozási nyelv V. Struktúra Dinamikus memóriakezelés Miskolci Egyetem Általános Informatikai Tanszék A C programozási nyelv V. (Struktúra, memóriakezelés) CBEV5 / 1 A struktúra deklarációja 1.
Grafikus csővezeték 1 / 44
 Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
GPGPU alapok. GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai
 GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
Mintavételes szabályozás mikrovezérlő segítségével
 Automatizálási Tanszék Mintavételes szabályozás mikrovezérlő segítségével Budai Tamás budai.tamas@sze.hu http://maxwell.sze.hu/~budait Tartalom Mikrovezérlőkről röviden Programozási alapismeretek ismétlés
Automatizálási Tanszék Mintavételes szabályozás mikrovezérlő segítségével Budai Tamás budai.tamas@sze.hu http://maxwell.sze.hu/~budait Tartalom Mikrovezérlőkről röviden Programozási alapismeretek ismétlés
Programozás alapjai gyakorlat. 2. gyakorlat C alapok
 Programozás alapjai gyakorlat 2. gyakorlat C alapok 2016-2017 Bordé Sándor 2 Forráskód, fordító, futtatható állomány Először megírjuk a programunk kódját (forráskód) Egyszerű szövegszerkesztőben vagy fejlesztőkörnyezettel
Programozás alapjai gyakorlat 2. gyakorlat C alapok 2016-2017 Bordé Sándor 2 Forráskód, fordító, futtatható állomány Először megírjuk a programunk kódját (forráskód) Egyszerű szövegszerkesztőben vagy fejlesztőkörnyezettel
GPU alkalmazása az ALICE eseménygenerátorában
 GPU alkalmazása az ALICE eseménygenerátorában Nagy Máté Ferenc MTA KFKI RMKI ALICE csoport ELTE TTK Fizika MSc Témavezető: Dr. Barnaföldi Gergely Gábor MTA KFKI RMKI ALICE csoport Elméleti Fizikai Főosztály
GPU alkalmazása az ALICE eseménygenerátorában Nagy Máté Ferenc MTA KFKI RMKI ALICE csoport ELTE TTK Fizika MSc Témavezető: Dr. Barnaföldi Gergely Gábor MTA KFKI RMKI ALICE csoport Elméleti Fizikai Főosztály
Google Summer of Code OpenCL image support for the r600g driver
 Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
Programozás I. gyakorlat
 Programozás I. gyakorlat 1. gyakorlat Alapok Eszközök Szövegszerkesztő: Szintaktikai kiemelés Egyszerre több fájl szerkesztése pl.: gedit, mcedit, joe, vi, Notepad++ stb. Fordító: Szöveges file-ban tárolt
Programozás I. gyakorlat 1. gyakorlat Alapok Eszközök Szövegszerkesztő: Szintaktikai kiemelés Egyszerre több fájl szerkesztése pl.: gedit, mcedit, joe, vi, Notepad++ stb. Fordító: Szöveges file-ban tárolt
Diplomamunka. Miskolci Egyetem. GPGPU technológia kriptográfiai alkalmazása. Készítette: Csikó Richárd VIJFZK mérnök informatikus
 Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
Utolsó módosítás:
 Utolsó módosítás:2011. 09. 29. 1 2 4 5 MMU!= fizikai memóriaillesztő áramkör. Az utóbbinak a feladata a memória modulok elektromos alacsonyszintű vezérlése, ez sokáig a CPU-n kívül a chipset északi hídban
Utolsó módosítás:2011. 09. 29. 1 2 4 5 MMU!= fizikai memóriaillesztő áramkör. Az utóbbinak a feladata a memória modulok elektromos alacsonyszintű vezérlése, ez sokáig a CPU-n kívül a chipset északi hídban
C programozás. 1 óra Bevezetés
 C programozás 1 óra Bevezetés A C nyelv eredete, fő tulajdonságai 1. Bevezető C nyelv alapelemei többsége a BCPL (Basic Combined Programming Language {1963}) Martin Richards B nyelv Ken Thompson {1970}
C programozás 1 óra Bevezetés A C nyelv eredete, fő tulajdonságai 1. Bevezető C nyelv alapelemei többsége a BCPL (Basic Combined Programming Language {1963}) Martin Richards B nyelv Ken Thompson {1970}
Eichhardt Iván GPGPU óra anyagai
 OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos programozás elméleti
OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos programozás elméleti
Operációs rendszerek III.
 A WINDOWS NT memóriakezelése Az NT memóriakezelése Memóriakezelő feladatai: Logikai-fizikai címtranszformáció: A folyamatok virtuális címterének címeit megfelelteti fizikai címeknek. A virtuális memóriakezelés
A WINDOWS NT memóriakezelése Az NT memóriakezelése Memóriakezelő feladatai: Logikai-fizikai címtranszformáció: A folyamatok virtuális címterének címeit megfelelteti fizikai címeknek. A virtuális memóriakezelés
Haladó Grafika EA. Inkrementális képszintézis GPU-n
 Haladó Grafika EA Inkrementális képszintézis GPU-n Pipeline Az elvégzendő feladatot részfeladatokra bontjuk Mindegyik részfeladatot más-más egység dolgozza fel (ideális esetben) Minden egység inputja,
Haladó Grafika EA Inkrementális képszintézis GPU-n Pipeline Az elvégzendő feladatot részfeladatokra bontjuk Mindegyik részfeladatot más-más egység dolgozza fel (ideális esetben) Minden egység inputja,
Heterogén számítási rendszerek gyakorlatok (2018.)
") Heterogén számítási rendszerek gyakorlatok (2018.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 8 2.1 Global
Heterogén számítási rendszerek gyakorlatok (2018.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 8 2.1 Global
C programozás. 6 óra Függvények, függvényszerű makrók, globális és
 C programozás 6 óra Függvények, függvényszerű makrók, globális és lokális változók 1.Azonosítók A program bizonyos összetevőire névvel (azonosító) hivatkozunk Első karakter: _ vagy betű (csak ez lehet,
C programozás 6 óra Függvények, függvényszerű makrók, globális és lokális változók 1.Azonosítók A program bizonyos összetevőire névvel (azonosító) hivatkozunk Első karakter: _ vagy betű (csak ez lehet,
GPU-Accelerated Collocation Pattern Discovery
 GPU-Accelerated Collocation Pattern Discovery Térbeli együttes előfordulási minták GPU-val gyorsított felismerése Gyenes Csilla Sallai Levente Szabó Andrea Eötvös Loránd Tudományegyetem Informatikai Kar
GPU-Accelerated Collocation Pattern Discovery Térbeli együttes előfordulási minták GPU-val gyorsított felismerése Gyenes Csilla Sallai Levente Szabó Andrea Eötvös Loránd Tudományegyetem Informatikai Kar
Eichhardt Iván GPGPU óra anyagai
 OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos tervezési minták
OpenCL modul 1. óra Eichhardt Iván iffan@caesar.elte.hu GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ OpenCL API és alkalmazása Gyakorlati példák (C/C++) Pl.: Képfeldolgozás Párhuzamos tervezési minták
Járműfedélzeti rendszerek II. 3. előadás Dr. Bécsi Tamás
 Járműfedélzeti rendszerek II. 3. előadás Dr. Bécsi Tamás 5.3. Mutatók,tömbök A mutató vagy pointer olyan változó, amely egy másik változó címét tartalmazza. A C nyelvű programokban gyakran használják a
Járműfedélzeti rendszerek II. 3. előadás Dr. Bécsi Tamás 5.3. Mutatók,tömbök A mutató vagy pointer olyan változó, amely egy másik változó címét tartalmazza. A C nyelvű programokban gyakran használják a
Flynn féle osztályozás Single Isntruction Multiple Instruction Single Data SISD SIMD Multiple Data MISD MIMD
 M5-. A lineáris algebra párhuzamos algoritmusai. Ismertesse a párhuzamos gépi architektúrák Flynn-féle osztályozását. A párhuzamos lineáris algebrai algoritmusok között mi a BLAS csomag célja, melyek annak
M5-. A lineáris algebra párhuzamos algoritmusai. Ismertesse a párhuzamos gépi architektúrák Flynn-féle osztályozását. A párhuzamos lineáris algebrai algoritmusok között mi a BLAS csomag célja, melyek annak
main int main(int argc, char* argv[]) { return 0; } main return 0; (int argc, char* argv[]) main int int int main main main
![main int main(int argc, char* argv[]) { return 0; } main return 0; (int argc, char* argv[]) main int int int main main main](/thumbs/96/128728163.jpg "main int main(int argc, char* argv[]) { return 0; } main return 0; (int argc, char* argv[]) main int int int main main main") main int main(int argc, char* argv[]) { return 0; main main int int main int return 0; main (int argc, char* argv[]) main #include #include int main(int argc, char* argv[]) { double
main int main(int argc, char* argv[]) { return 0; main main int int main int return 0; main (int argc, char* argv[]) main #include #include int main(int argc, char* argv[]) { double
Programozás I gyakorlat. 10. Stringek, mutatók
 Programozás I gyakorlat 10. Stringek, mutatók Karakter típus A char típusú változókat karakerként is kiírhatjuk: #include char c = 'A'; printf("%c\n", c); c = 80; printf("%c\n", c); printf("%c\n",
Programozás I gyakorlat 10. Stringek, mutatók Karakter típus A char típusú változókat karakerként is kiírhatjuk: #include char c = 'A'; printf("%c\n", c); c = 80; printf("%c\n", c); printf("%c\n",
Informatika el adás: Hardver
 Informatika 1. 1. el adás: Hardver Wettl Ferenc és Kovács Kristóf prezentációjának felhasználásával Budapesti M szaki és Gazdaságtudományi Egyetem 2017-09-05 Követelmények 3 ZH 5. 9. 14. héten egyenként
Informatika 1. 1. el adás: Hardver Wettl Ferenc és Kovács Kristóf prezentációjának felhasználásával Budapesti M szaki és Gazdaságtudományi Egyetem 2017-09-05 Követelmények 3 ZH 5. 9. 14. héten egyenként
Programozás II. 2. Dr. Iványi Péter
 Programozás II. 2. Dr. Iványi Péter 1 C++ Bjarne Stroustrup, Bell Laboratórium Első implementáció, 1983 Kezdetben csak precompiler volt C++ konstrukciót C-re fordította A kiterjesztés alapján ismerte fel:.cpp.cc.c
Programozás II. 2. Dr. Iványi Péter 1 C++ Bjarne Stroustrup, Bell Laboratórium Első implementáció, 1983 Kezdetben csak precompiler volt C++ konstrukciót C-re fordította A kiterjesztés alapján ismerte fel:.cpp.cc.c
Programozás alapjai 2.Gy: A C nyelv alapjai P R O
 Programozás alapjai 2.Gy: A C nyelv alapjai. P R O A L A G 1/32 B ITv: MAN 2018.10.02 Code::Blocks Indítsa el mindenki! 2/32 1 Code::Blocks Új projekt 2 3 4 5 3/32 Code::Blocks Forráskód Kód fordítása:
Programozás alapjai 2.Gy: A C nyelv alapjai. P R O A L A G 1/32 B ITv: MAN 2018.10.02 Code::Blocks Indítsa el mindenki! 2/32 1 Code::Blocks Új projekt 2 3 4 5 3/32 Code::Blocks Forráskód Kód fordítása:
Függvények. Programozás I. Hatwágner F. Miklós november 16. Széchenyi István Egyetem, Gy r
 Programozás I. Széchenyi István Egyetem, Gy r 2014. november 16. Áttekintés kel kapcsolatos fogalmak deklaráció Több, kompatibilis változat is elképzelhet. Meg kell el znie a fv. hívását. Mindenképp rögzíti
Programozás I. Széchenyi István Egyetem, Gy r 2014. november 16. Áttekintés kel kapcsolatos fogalmak deklaráció Több, kompatibilis változat is elképzelhet. Meg kell el znie a fv. hívását. Mindenképp rögzíti
Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)
, Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)") 1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
Nemlineáris optimalizálási problémák párhuzamos megoldása grafikus processzorok felhasználásával
 Nemlineáris optimalizálási problémák párhuzamos megoldása grafikus processzorok felhasználásával 1 1 Eötvös Loránd Tudományegyetem, Informatikai Kar Kari TDK, 2016. 05. 10. Tartalom 1 2 Tartalom 1 2 Optimalizálási
Nemlineáris optimalizálási problémák párhuzamos megoldása grafikus processzorok felhasználásával 1 1 Eötvös Loránd Tudományegyetem, Informatikai Kar Kari TDK, 2016. 05. 10. Tartalom 1 2 Tartalom 1 2 Optimalizálási
C programozási nyelv Pointerek, tömbök, pointer aritmetika
 C programozási nyelv Pointerek, tömbök, pointer aritmetika Dr. Schuster György 2011. június 16. C programozási nyelv Pointerek, tömbök, pointer aritmetika 2011. június 16. 1 / 15 Pointerek (mutatók) Pointerek
C programozási nyelv Pointerek, tömbök, pointer aritmetika Dr. Schuster György 2011. június 16. C programozási nyelv Pointerek, tömbök, pointer aritmetika 2011. június 16. 1 / 15 Pointerek (mutatók) Pointerek
Programozás 1. Dr. Iványi Péter
 Programozás 1. Dr. Iványi Péter 1 C nyelv B.W. Kernighan és D.M. Ritchie, 1978 The C Programming language 2 C nyelv Amerikai Szabványügy Hivatal (ANSI), 1983 X3J11 bizottság a C nyelv szabványosítására
Programozás 1. Dr. Iványi Péter 1 C nyelv B.W. Kernighan és D.M. Ritchie, 1978 The C Programming language 2 C nyelv Amerikai Szabványügy Hivatal (ANSI), 1983 X3J11 bizottság a C nyelv szabványosítására
Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd.
 1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
A verem (stack) A verem egy olyan struktúra, aminek a tetejéről kivehetünk egy (vagy sorban több) elemet. A verem felhasználása
 A verem egy olyan struktúra, aminek a tetejéről kivehetünk egy (vagy sorban több) elemet. A verem felhasználása") A verem (stack) A verem egy olyan struktúra, aminek a tetejére betehetünk egy új (vagy sorban több) elemet a tetejéről kivehetünk egy (vagy sorban több) elemet A verem felhasználása Függvény visszatérési
A verem (stack) A verem egy olyan struktúra, aminek a tetejére betehetünk egy új (vagy sorban több) elemet a tetejéről kivehetünk egy (vagy sorban több) elemet A verem felhasználása Függvény visszatérési
1. Alapok. Programozás II
 1. Alapok Programozás II Elérhetőség Név: Smidla József Elérhetőség: smidla dcs.uni-pannon.hu Szoba: I916 2 Irodalom Bjarne Stroustrup: A C++ programozási nyelv 3 Irodalom Erich Gamma, Richard Helm, Ralph
1. Alapok Programozás II Elérhetőség Név: Smidla József Elérhetőség: smidla dcs.uni-pannon.hu Szoba: I916 2 Irodalom Bjarne Stroustrup: A C++ programozási nyelv 3 Irodalom Erich Gamma, Richard Helm, Ralph
HP-SEE projekt eredményei
 2013. március 26. Networkshop 2013 Sopron Rőczei Gábor roczei@niif.hu HP-SEE projekt High-Performance Computing Infrastructure for South East Europe s Research Communities (HP-SEE) PRACE mintájára jött
2013. március 26. Networkshop 2013 Sopron Rőczei Gábor roczei@niif.hu HP-SEE projekt High-Performance Computing Infrastructure for South East Europe s Research Communities (HP-SEE) PRACE mintájára jött
GPGPU programozás lehetőségei. Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café
 GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
TI TMDSEVM6472 rövid bemutatása
 6.6.1. Linux futtatása TMDSEVM6472 eszközön TI TMDSEVM6472 rövid bemutatása A TMDSEVM6472 az alábbi fő hardver paraméterekkel rendelkezik: 1db fix pontos, több magos (6 C64x+ mag) C6472 DSP 700MHz 256MB
6.6.1. Linux futtatása TMDSEVM6472 eszközön TI TMDSEVM6472 rövid bemutatása A TMDSEVM6472 az alábbi fő hardver paraméterekkel rendelkezik: 1db fix pontos, több magos (6 C64x+ mag) C6472 DSP 700MHz 256MB
Masszívan párhuzamos alkalmazások fejlesztése. Dr. Szénási Sándor Kertész Gábor, Kiss Dániel
 Masszívan párhuzamos alkalmazások fejlesztése Dr. Szénási Sándor Kertész Gábor, Kiss Dániel For over a decade prophets have voiced the contention that the organization of a single computer has reached
Masszívan párhuzamos alkalmazások fejlesztése Dr. Szénási Sándor Kertész Gábor, Kiss Dániel For over a decade prophets have voiced the contention that the organization of a single computer has reached
Programozás alapjai. (GKxB_INTM023) Dr. Hatwágner F. Miklós október 11. Széchenyi István Egyetem, Gy r
 Dr. Hatwágner F. Miklós október 11. Széchenyi István Egyetem, Gy r") Programozás alapjai (GKxB_INTM023) Széchenyi István Egyetem, Gy r 2018. október 11. Függvények Mi az a függvény (function)? Programkód egy konkrét, azonosítható, paraméterezhet, újrahasznosítható blokkja
Programozás alapjai (GKxB_INTM023) Széchenyi István Egyetem, Gy r 2018. október 11. Függvények Mi az a függvény (function)? Programkód egy konkrét, azonosítható, paraméterezhet, újrahasznosítható blokkja
Programozás alapjai C nyelv 8. gyakorlat. Mutatók és címek (ism.) Indirekció (ism)
 Indirekció (ism)") Programozás alapjai C nyelv 8. gyakorlat Szeberényi Imre BME IIT Programozás alapjai I. (C nyelv, gyakorlat) BME-IIT Sz.I. 2005.11.07. -1- Mutatók és címek (ism.) Minden változó és függvény
Programozás alapjai C nyelv 8. gyakorlat Szeberényi Imre BME IIT Programozás alapjai I. (C nyelv, gyakorlat) BME-IIT Sz.I. 2005.11.07. -1- Mutatók és címek (ism.) Minden változó és függvény
Mutatók és címek (ism.) Programozás alapjai C nyelv 8. gyakorlat. Indirekció (ism) Néhány dolog érthetőbb (ism.) Változók a memóriában
 Programozás alapjai C nyelv 8. gyakorlat. Indirekció (ism) Néhány dolog érthetőbb (ism.) Változók a memóriában") Programozás alapjai C nyelv 8. gyakorlat Szeberényi mre BME T Programozás alapjai. (C nyelv, gyakorlat) BME-T Sz.. 2005.11.07. -1- Mutatók és címek (ism.) Minden változó és függvény
Programozás alapjai C nyelv 8. gyakorlat Szeberényi mre BME T Programozás alapjai. (C nyelv, gyakorlat) BME-T Sz.. 2005.11.07. -1- Mutatók és címek (ism.) Minden változó és függvény
7. fejezet: Mutatók és tömbök
 7. fejezet: Mutatók és tömbök Minden komolyabb programozási nyelvben vannak tömbök, amelyek gondos kezekben komoly fegyvert jelenthetnek. Először is tanuljunk meg tömböt deklarálni! //Tömbök használata
7. fejezet: Mutatók és tömbök Minden komolyabb programozási nyelvben vannak tömbök, amelyek gondos kezekben komoly fegyvert jelenthetnek. Először is tanuljunk meg tömböt deklarálni! //Tömbök használata
Alprogramok, paraméterátadás
 ELTE Informatikai Kar, Programozási Nyelvek és Fordítóprogramok Tanszék October 24, 2016 Programozási nyelvek Alprogramok Függvények, eljárások Metódusok Korutinok stb. Alprogramok Alprogram: olyan nyelvi
ELTE Informatikai Kar, Programozási Nyelvek és Fordítóprogramok Tanszék October 24, 2016 Programozási nyelvek Alprogramok Függvények, eljárások Metódusok Korutinok stb. Alprogramok Alprogram: olyan nyelvi
Párhuzamos és Grid rendszerek
 Párhuzamos és Grid rendszerek (7. ea) szálak, openmp Szeberényi Imre BME IIT M Ű E G Y E T E M 1 7 8 2 Párhuzamos és Grid rendszerek BME-IIT Sz.I. 2013.03.25. - 1 - Áttekintés Eddig
Párhuzamos és Grid rendszerek (7. ea) szálak, openmp Szeberényi Imre BME IIT M Ű E G Y E T E M 1 7 8 2 Párhuzamos és Grid rendszerek BME-IIT Sz.I. 2013.03.25. - 1 - Áttekintés Eddig
Párhuzamos és Grid rendszerek. Áttekintés. Szálak. Eddig általános eszközöket láttunk, melyek
 Párhuzamos és Grid rendszerek (7. ea) szálak, openmp Szeberényi Imre BME IIT M Ű E G Y E T E M 1 7 8 2 Párhuzamos és Grid rendszerek BME-IIT Sz.I. 2013.03.25. - 1 - Áttekintés Eddig
Párhuzamos és Grid rendszerek (7. ea) szálak, openmp Szeberényi Imre BME IIT M Ű E G Y E T E M 1 7 8 2 Párhuzamos és Grid rendszerek BME-IIT Sz.I. 2013.03.25. - 1 - Áttekintés Eddig
Heterogén számítási rendszerek
 Heterogén számítási rendszerek GPU-k, GPGPU CUDA, OpenCL Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális koordináta rendszerből
Heterogén számítási rendszerek GPU-k, GPGPU CUDA, OpenCL Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális koordináta rendszerből
Az NIIF új szuperszámítógép infrastruktúrája Új lehetőségek a kutatói hálózatban 2012.02.23.
 Az NIIF új szuperszámítógép infrastruktúrája Új lehetőségek a kutatói hálózatban 2012.02.23. Dr. Máray Tamás NIIF Intézet NIIF szuperszámítógép szolgáltatás a kezdetek 2001 Sun E10k 60 Gflops SMP architektúra
Az NIIF új szuperszámítógép infrastruktúrája Új lehetőségek a kutatói hálózatban 2012.02.23. Dr. Máray Tamás NIIF Intézet NIIF szuperszámítógép szolgáltatás a kezdetek 2001 Sun E10k 60 Gflops SMP architektúra
Programozás 5. Dr. Iványi Péter
 Programozás 5. Dr. Iványi Péter 1 Struktúra Véges számú különböző típusú, logikailag összetartozó változó együttese, amelyeket az egyszerű kezelhetőség érdekében gyűjtünk össze. Rekord-nak felel meg struct
Programozás 5. Dr. Iványi Péter 1 Struktúra Véges számú különböző típusú, logikailag összetartozó változó együttese, amelyeket az egyszerű kezelhetőség érdekében gyűjtünk össze. Rekord-nak felel meg struct
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA. Dr. Szénási Sándor
 KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
Programozás II. 2. gyakorlat Áttérés C-ről C++-ra
 Programozás II. 2. gyakorlat Áttérés C-ről C++-ra Tartalom Új kommentelési lehetőség Változók deklarációjának helye Alapértelmezett függvényparaméterek Névterek I/O műveletek egyszerűsödése Logikai adattípus,
Programozás II. 2. gyakorlat Áttérés C-ről C++-ra Tartalom Új kommentelési lehetőség Változók deklarációjának helye Alapértelmezett függvényparaméterek Névterek I/O műveletek egyszerűsödése Logikai adattípus,
5-6. ea Created by mrjrm & Pogácsa, frissítette: Félix
 2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
Operációs rendszerek. Az NT memóriakezelése
 Operációs rendszerek MS Windows NT (2000) memóriakezelés Az NT memóriakezelése 32-bites virtuális memóriakezelés: 4 GB-os címtartomány, alapesetben: a fels! 2 GB az alkalmazásoké, az alsó 2 GB az OPR-é.
Operációs rendszerek MS Windows NT (2000) memóriakezelés Az NT memóriakezelése 32-bites virtuális memóriakezelés: 4 GB-os címtartomány, alapesetben: a fels! 2 GB az alkalmazásoké, az alsó 2 GB az OPR-é.
GPGPU és számítások heterogén rendszereken
 GPGPU és számítások heterogén rendszereken Eichhardt Iván eichhardt.ivan@sztaki.mta.hu ELTE-s GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ Gyors bevezetés a Párhuzamosságról OpenCL API Gyakorlati példák
GPGPU és számítások heterogén rendszereken Eichhardt Iván eichhardt.ivan@sztaki.mta.hu ELTE-s GPGPU óra anyagai http://cg.inf.elte.hu/~gpgpu/ Gyors bevezetés a Párhuzamosságról OpenCL API Gyakorlati példák
A C programozási nyelv I. Bevezetés
 A C programozási nyelv I. Bevezetés Miskolci Egyetem Általános Informatikai Tanszék A C programozási nyelv I. (bevezetés) CBEV1 / 1 A C nyelv története Dennis M. Ritchie AT&T Lab., 1972 rendszerprogramozás,
A C programozási nyelv I. Bevezetés Miskolci Egyetem Általános Informatikai Tanszék A C programozási nyelv I. (bevezetés) CBEV1 / 1 A C nyelv története Dennis M. Ritchie AT&T Lab., 1972 rendszerprogramozás,
Programozás C és C++ -ban
 Programozás C és C++ -ban 2. További különbségek a C és C++ között 2.1 Igaz és hamis A C++ programozási nyelv a C-hez hasonlóan definiál néhány alap adattípust: char int float double Ugyanakkor egy új
Programozás C és C++ -ban 2. További különbségek a C és C++ között 2.1 Igaz és hamis A C++ programozási nyelv a C-hez hasonlóan definiál néhány alap adattípust: char int float double Ugyanakkor egy új
Dr. Schuster György október 30.
 Real-time operációs rendszerek RTOS 2015. október 30. Jellemzők ONX POSIX kompatibilis, Jellemzők ONX POSIX kompatibilis, mikrokernel alapú, Jellemzők ONX POSIX kompatibilis, mikrokernel alapú, nem kereskedelmi
Real-time operációs rendszerek RTOS 2015. október 30. Jellemzők ONX POSIX kompatibilis, Jellemzők ONX POSIX kompatibilis, mikrokernel alapú, Jellemzők ONX POSIX kompatibilis, mikrokernel alapú, nem kereskedelmi
Operációs rendszerek. Az NT folyamatok kezelése
 Operációs rendszerek Az NT folyamatok kezelése Folyamatok logikai felépítése A folyamat modell: egy adott program kódját végrehajtó szál(ak)ból és, a szál(ak) által lefoglalt erőforrásokból állnak. Folyamatok
Operációs rendszerek Az NT folyamatok kezelése Folyamatok logikai felépítése A folyamat modell: egy adott program kódját végrehajtó szál(ak)ból és, a szál(ak) által lefoglalt erőforrásokból állnak. Folyamatok
1. Template (sablon) 1.1. Függvénysablon Függvénysablon példányosítás Osztálysablon
 1.1. Függvénysablon Függvénysablon példányosítás Osztálysablon") 1. Template (sablon) 1.1. Függvénysablon Maximum függvény megvalósítása függvénynév túlterheléssel. i n l i n e f l o a t Max ( f l o a t a, f l o a t b ) { return a>b? a : b ; i n l i n e double Max (
1. Template (sablon) 1.1. Függvénysablon Maximum függvény megvalósítása függvénynév túlterheléssel. i n l i n e f l o a t Max ( f l o a t a, f l o a t b ) { return a>b? a : b ; i n l i n e double Max (
10. gyakorlat. Pointerek Tárolási osztályok
 10. gyakorlat Pointerek Tárolási osztályok Pointer A pointer egy mutató egy memóriacellára, egyfajta "parancsikon", csak nem fájlokra, hanem változókra. Létrehozás: tipus * név;, ahol a típus a hivatkozott
10. gyakorlat Pointerek Tárolási osztályok Pointer A pointer egy mutató egy memóriacellára, egyfajta "parancsikon", csak nem fájlokra, hanem változókra. Létrehozás: tipus * név;, ahol a típus a hivatkozott
AliROOT szimulációk GPU alapokon
 AliROOT szimulációk GPU alapokon Nagy Máté Ferenc & Barnaföldi Gergely Gábor Wigner FK ALICE Bp csoport OTKA: PD73596 és NK77816 TARTALOM 1. Az ALICE csoport és a GRID hálózat 2. Szimulációk és az AliROOT
AliROOT szimulációk GPU alapokon Nagy Máté Ferenc & Barnaföldi Gergely Gábor Wigner FK ALICE Bp csoport OTKA: PD73596 és NK77816 TARTALOM 1. Az ALICE csoport és a GRID hálózat 2. Szimulációk és az AliROOT
Grafikus processzorok általános célú programozása (GPGPU)
") 2015. szeptember 17. Grafikus processzorok általános célú programozása (GPGPU) Eichhardt I., Hajder L. és V. Gábor eichhardt.ivan@sztaki.mta.hu, hajder.levente@sztaki.mta.hu, valasek@inf.elte.hu Eötvös
2015. szeptember 17. Grafikus processzorok általános célú programozása (GPGPU) Eichhardt I., Hajder L. és V. Gábor eichhardt.ivan@sztaki.mta.hu, hajder.levente@sztaki.mta.hu, valasek@inf.elte.hu Eötvös
Bevezetés a programozásba. 9. Előadás: Rekordok
 Bevezetés a programozásba 9. Előadás: Rekordok ISMÉTLÉS Függvényhívás #include #include #include #include using using namespace namespace std; std; double double terulet(double
Bevezetés a programozásba 9. Előadás: Rekordok ISMÉTLÉS Függvényhívás #include #include #include #include using using namespace namespace std; std; double double terulet(double
Ismerkedés a Python programnyelvvel. és annak micropython változatával
 Ismerkedés a Python programnyelvvel és annak micropython változatával A Python programozási nyelv története Az alapötlet 1980-ban született, 1989 decemberében kezdte el fejleszteni Guido van Rossum a CWI-n
Ismerkedés a Python programnyelvvel és annak micropython változatával A Python programozási nyelv története Az alapötlet 1980-ban született, 1989 decemberében kezdte el fejleszteni Guido van Rossum a CWI-n
GPU Lab. 14. fejezet. OpenCL textúra használat. Grafikus Processzorok Tudományos Célú Programozása. Berényi Dániel Nagy-Egri Máté Ferenc
 14. fejezet OpenCL textúra használat Grafikus Processzorok Tudományos Célú Programozása Textúrák A textúrák 1, 2, vagy 3D-s tömbök kifejezetten szín információk tárolására Főbb különbségek a bufferekhez
14. fejezet OpenCL textúra használat Grafikus Processzorok Tudományos Célú Programozása Textúrák A textúrák 1, 2, vagy 3D-s tömbök kifejezetten szín információk tárolására Főbb különbségek a bufferekhez
Programozás C++ -ban 2007/1
 Programozás C++ -ban 2007/1 1. Különbségek a C nyelvhez képest Több alapvető különbség van a C és a C++ programozási nyelvek szintaxisában. A programozó szempontjából ezek a különbségek könnyítik a programozó
Programozás C++ -ban 2007/1 1. Különbségek a C nyelvhez képest Több alapvető különbség van a C és a C++ programozási nyelvek szintaxisában. A programozó szempontjából ezek a különbségek könnyítik a programozó
OpenCL alapú eszközök verifikációja és validációja a gyakorlatban
 OpenCL alapú eszközök verifikációja és validációja a gyakorlatban Fekete Tamás 2015. December 3. Szoftver verifikáció és validáció tantárgy Áttekintés Miért és mennyire fontos a megfelelő validáció és
OpenCL alapú eszközök verifikációja és validációja a gyakorlatban Fekete Tamás 2015. December 3. Szoftver verifikáció és validáció tantárgy Áttekintés Miért és mennyire fontos a megfelelő validáció és
Utolsó módosítás:
 Utolsó módosítás: 2012. 09. 06. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 Forrás: Gartner Hype Cycle for Virtualization, 2010, http://premierit.intel.com/docs/doc-5768
Utolsó módosítás: 2012. 09. 06. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 Forrás: Gartner Hype Cycle for Virtualization, 2010, http://premierit.intel.com/docs/doc-5768
A C programozási nyelv I. Bevezetés
 A C programozási nyelv I. Bevezetés Miskolci Egyetem Általános Informatikai Tanszék A C programozási nyelv I. (bevezetés) CBEV1 / 1 A C nyelv története Dennis M. Ritchie AT&T Lab., 1972 rendszerprogramozás,
A C programozási nyelv I. Bevezetés Miskolci Egyetem Általános Informatikai Tanszék A C programozási nyelv I. (bevezetés) CBEV1 / 1 A C nyelv története Dennis M. Ritchie AT&T Lab., 1972 rendszerprogramozás,
11. gyakorlat Sturktúrák használata. 1. Definiáljon dátum típust. Olvasson be két dátumot, és határozza meg melyik a régebbi.
 11. gyakorlat Sturktúrák használata I. Új típus új műveletekkel 1. Definiáljon dátum típust. Olvasson be két dátumot, és határozza meg melyik a régebbi. typedef struct datum { int ev; int ho; int nap;
11. gyakorlat Sturktúrák használata I. Új típus új műveletekkel 1. Definiáljon dátum típust. Olvasson be két dátumot, és határozza meg melyik a régebbi. typedef struct datum { int ev; int ho; int nap;
Ordering MCMC gyorsítása OpenCL környezetben
 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Méréstechnika és Információs Rendszerek Tanszék Ordering MCMC gyorsítása OpenCL környezetben Önálló laboratórium 1 Készítette
Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Méréstechnika és Információs Rendszerek Tanszék Ordering MCMC gyorsítása OpenCL környezetben Önálló laboratórium 1 Készítette