GPGPU. Architektúra esettanulmány
|
|
|
- Egon Gáspár
- 6 évvel ezelőtt
- Látták:
Átírás
1 GPGPU Architektúra esettanulmány

2 GeForce 7800 (2006)
3 GeForce 7800 Rengeteg erőforrást fordítottak arra, hogy a throughput-ot maximalizálják Azaz a különböző típusú feldolgozóegységek (vertex és fragment árnyalók) mindig dolgozzanak Ez pedig sok bottleneck-et hozott magával Ezért az NVIDIA (is) egységesítette az architektúrát
4 GeForce 8800 ( Tesla)
5 GeForce 8800 processing element

6 GeForce 8800 shader core
7 GeForce 8800 Processing element Shader core egyetlen feldolgozó egység 128 van belőle 16 processing element egysége egy shader core kap meg egy feladatot ( <X> fragment shader futtatása ) Egyúttal megjelent a CUDA is
8 Fermi
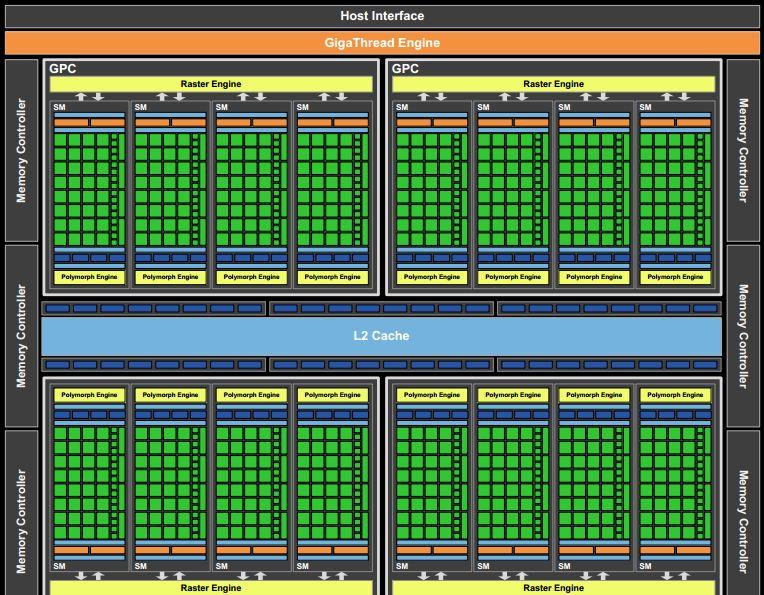
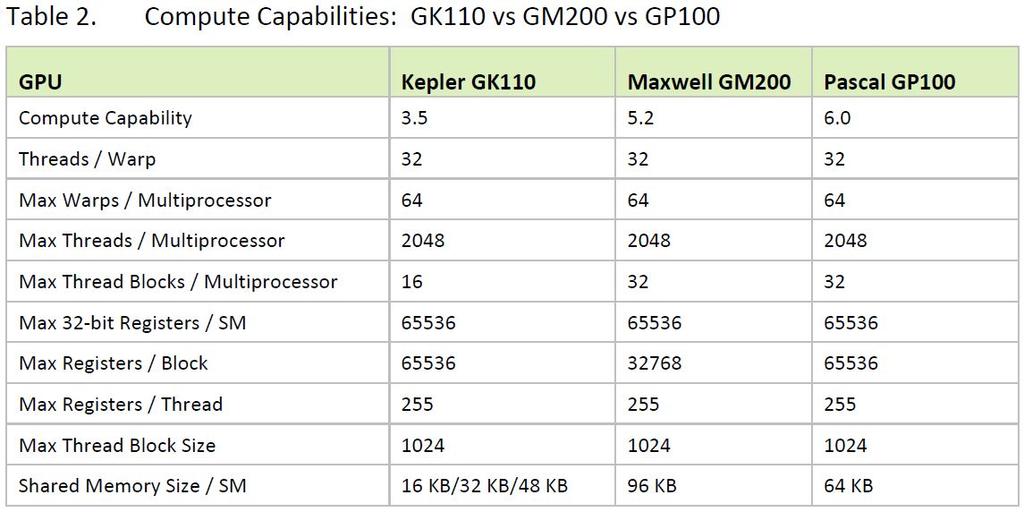
9 NVIDIA GF100 - Fermi (2009) Az NVIDIA 2009-ben debütáló architektúrája Az előző generáció (GeForce 8) vezette be az egységesített architektúrát azaz innentől kezdve az NVIDIA GPU-knál is egységesített stream processzorok voltak előtte dedikált processzorok a különböző feladatokra (vertex és fragment programok futtatására) A Fermi már DirectX11 kompatibilis volt új kihívás például a tessellation shaderek támogatása (ez több, mint szteroid-kezelt geometry shader: utóbbinak sosem volt célja a nagymértékű geometriai generálása) A Fermi-nél a hangsúly a grafikus alkalmazások gyorsításán volt
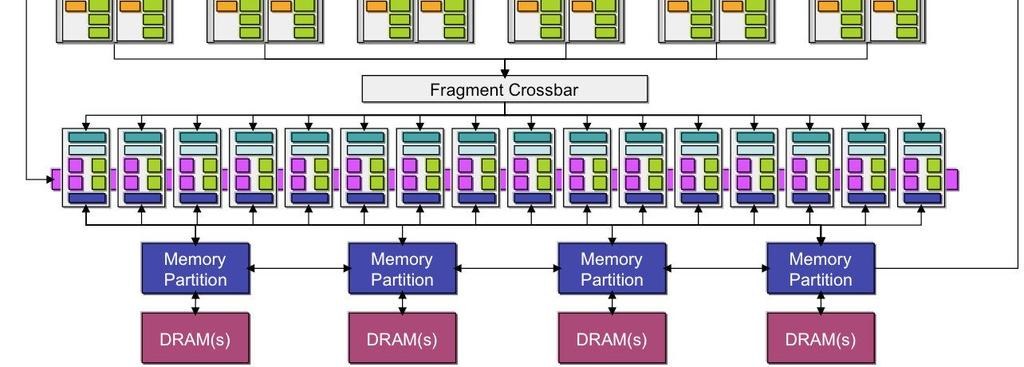
10 Fermi architektúra Főbb építőelemei: GPC (Graphics Processing Cluster): grafikus feldolgozóegységek skálázható méretű tömbje SM (Streaming Multiprocessor): valahány streamprocesszor ( GPU mag, most: CUDA mag) csoportja. CUDA mag: konkrét végrehajtó egység. Minden SM-ben 32 van. Egységesített feldolgozóegység - ugyanúgy képes vertex, geometry, fragment és compute kernelek ( shaderek ) futtatására Konkrétan a GF100-nál (a GeForce 480-ban) 4 darab GPC mindegyikben 4 SM (azaz összesen 16 SM) 6 memóriavezérlő A CPU-hoz PCIe-n keresztül csatlakozott

11 CUDA mag FP: IEEE , FMA INT: bool, shift, move,...
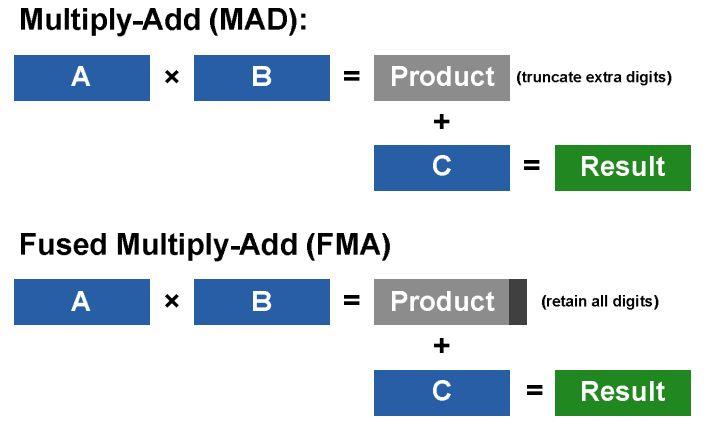
12 FMA
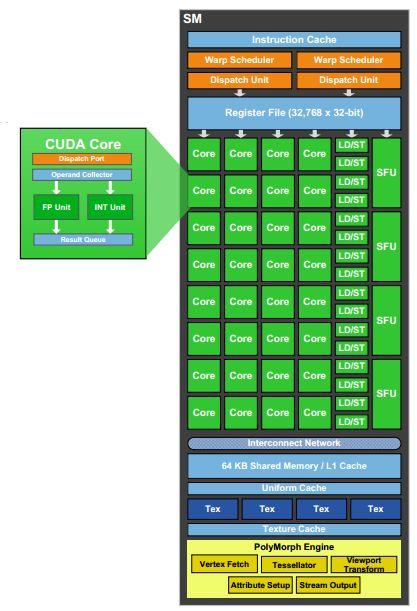
13 SM
14 SM 32 CUDA mag egysége 4 special function unit: transzcendens függvények kiértékelésére, grafikus szerelőszalag interpolációs lépéseit is ők végzik, egy órajel alatt egy szál egy utasítását hajtják végre => egy warp feldolgozása 8 órajel Két warpot tud egyszerre párhuzamosan feldolgozni (2x32 szál) A dual warp scheduler kiválaszt kettő warp-ot és mindkettőből 1 utasítást elküld (ha lehet - Fermin-n double-t pl. nem lehetett) 16 magnak, vagy 16 L/S egységnek, vagy 4 SFU-nak
 2 órajel kell egy warp 32 utasításának lefuttatásához (L/S-nél is) 8 órajel alatt értékelődik ki 32 SFU")
15 SM Két végrehajtási blokkra (execution block) van osztva, maggal Minden órajelben 32 utasítást adunk ki a végrehajtási blokkoknak (1 vagy 2 warpból) 2 órajel kell egy warp 32 utasításának lefuttatásához (L/S-nél is) 8 órajel alatt értékelődik ki 32 SFU utasítás

16 SM ütemezés

17 SM Minden SM-ben 4 textúrázó egység (TU) van Cache a textúrázónak Minden SM-hez L1 cache Igazából: minden SM-hez tartozik 64KB mem Ez kétféleképpen is beállítható: egy TU órajelenként 4 textúra mintát tud fetch-cselni ezeket szűrve is át tudja adni 16KB L1 + 48KB shared 48KB L1 + 16KB shared Renderingnél 16KB L1-es konfig megy

18 L2 cache 768KB, ami közös az összes SM-mel Írható, olvasható, koherens memória
19
20 Fermi működés Host interface: a CPU parancsokat olvassa GigaThread: a kért adatokat betölti a rendszermemóriából a framebufferhez a futtatandó szállakat blokkokra osztja és hozzárendeli SM-ekhez ezeket a szálakat aztán az SM-ek belső ütemezői osztják el SM: a hozzá rendelt szállakat 32-es csoportokban (warp-okban) futtatja a CUDA magjain

21 PolyMorph Engine Lényegében a grafikus szerelőszalag primitív feldolgozásának lépéseit vezérli 5 lépéses pipeline Az eredményül előálló primitíveket a raszterizáló engine-nek adja át
 Órajelenként 8 pixelt ad ki minden Raster Engine A Z-cull nem pixel szinten, hanem tile alapon működik.")
22 Raster Engine 4 Raster Engine működik párhuzamosan (GPC-nként 1 darab) 3 lépéses pipeline Az Edge Setup a háromszögek oldalainak egyenleteit határozza meg (és ezek végzik a backface culling-ot is) Órajelenként 8 pixelt ad ki minden Raster Engine A Z-cull nem pixel szinten, hanem tile alapon működik. Ha a tile minden pixele elbukja a Z-tesztet, akkor eldobja az egész tile-t.

23 Kepler
 A fogyasztás is szempont már (új varázsszó: performance per")
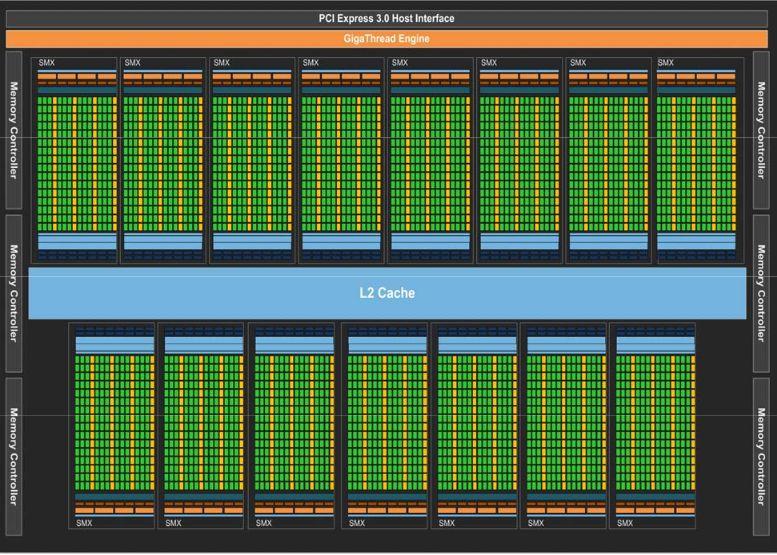
24 Kepler (2012) A Fermi utódja (GeForce 680) Teljesítménynövelés (főleg dupla pontosságnál) A fogyasztás is szempont már (új varázsszó: performance per watt )
25 Kepler felépítés 4 GPC 8 új SMX (újgenerációs SM) 4 memóriavezérlő
26 SMX 192 egyszeres pontosságú CUDA mag, FMA-val 32 SFU A magok GPU órajelen futnak Az SMX most már egyidőben 4 warp-ot tud ütemezni és végrehajtani Maga az ütemező is változott Egy szál most már akár 255 regisztert is elér
27 Memória A Fermihez hasonlóan konfigurálható 64KB-s memória per SMX +48KB-s read-only cache 1536KB L2 cache (amit minden SMX lát)
28
29
30

31 Maxwell
32 Maxwell (2014) Még jobb teljesítmény/fogyasztás arány volt a cél (performance per watt) Két generáció (GeForce 750, 8xx, illetve GeForce 9xx) Felépítés: 4 darab GPC 16 darab Maxwell SM (SMM) - 4 darab GPC-nként 4 memóriavezérlő Érdekes változtatások: memória sín: 192 bitről 128-ra SMM-ben CUDA magok száma: 192-ről 128-ra további egyszerűsítések
33 SMM 128 CUDA mag 1 PolyMorph Engine 8 textúrázó egység Felépítés: 32-es egységekben Minden 32-es egység dedikált ütemező erőforrással és utasításpufferrel rendelkezik egyszerűsítések, hogy kevesebb vezérlés kelljen Memória kiosztás revamp: L1 cache megosztva a textúra cache-sel 96KB dedikált osztott memória Az L2 cache 2048 KB
34 SMM 4 darab warp scheduler: Minden warp scheduler két utasítást tud egyszerre futtatni órajelenként adott 32 CUDA maggal dolgozik (korábban: közös kezelésben voltak a magok, kellett plusz hozzárendelés a warp schedulerek és a magok között) 8 L/S egység 8 SFU egység

35

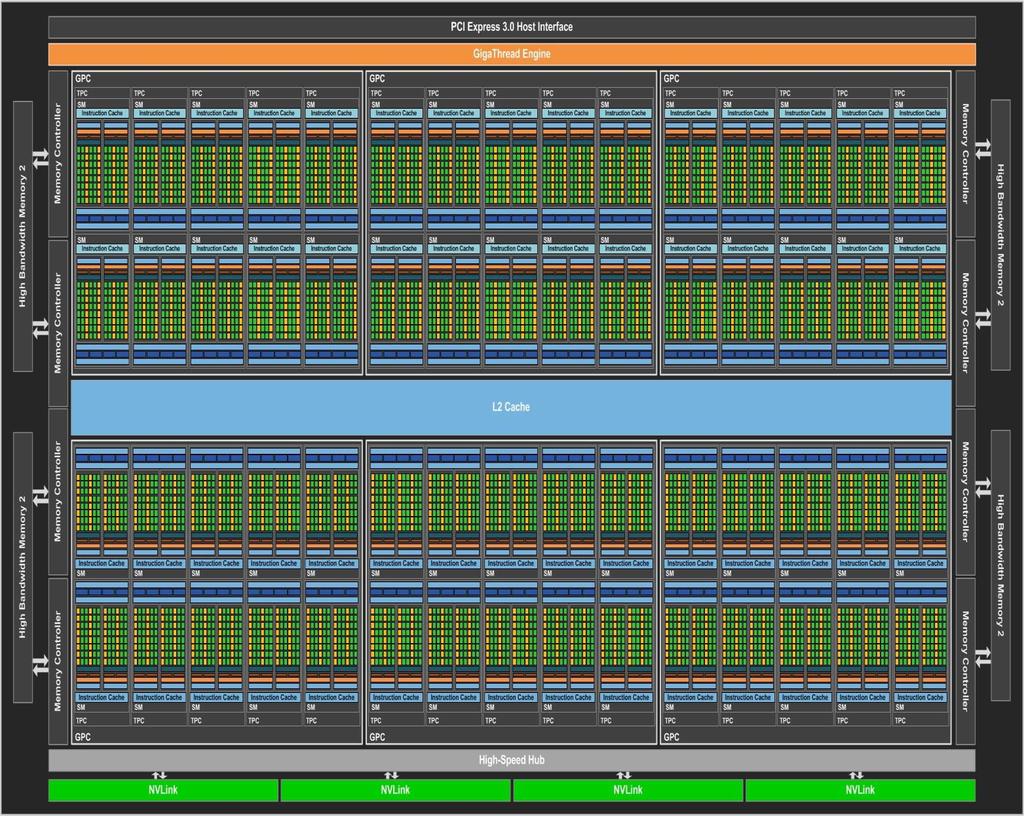
36 Pascal
, 21.")
37 Pascal (2016) Számítási teljesítmény növelése (deep learning) 5.3 TFLOPS FP64-re (~double), 10.6 TFLOPS FP32-re (~float), 21.2 TFLOPS FP16-ra (~half) NVLink nagysebességű és sávszélességű összeköttetésekhez Módosított memória-architektúra

38 Pascal Az NVLink-et GPU-GPU adatátivelhez használják: 160 GByte/sec-es kétirányú sávszélességet ad

39 High Bandwidth Memory (HBM) A munkaállomásokba szánt Tesla P100-ban A HBM stack-elt memóriaelrendezés Lényegében több rétegnyi memórialapkát helyeznek egymásra, esetleg a legalsó szinten egy memóriavezérlővel irányítva egy-egy ilyen tornyot A HBM2-ben akár 8 réteg is lehet Akár ECC memória (!) Még az AMD kezdte el fejleszteni a HBM1-et 2008-ban
40 GDDR5X Memory A GeForce GTX 1080-ban

41 Memóriatömörítés A GPU-n az adatokat veszteségmentes tömörített formában tárolja a hw A textúráknál egy fontos séma a delta color compression (DCC): A DCC-ben a pixeleket blokkokban kezelik Minden blokkhoz tartozik egy referenciaszín A blokkbéli pixelek színét pedig az ettől a referenciaszíntől vett eltéréssel kódolják Pascal-ban új módok is vannak ehhez

42 Load balancing Bizonyos feladatok nem tudják lefoglalni a teljes GPU-t Ekkor akár kettő vagy több ilyen munka is futhatna a GPU-n (például a fizikai számítások a rendering-gel) A Maxwell előre felosztotta a fizikai hardvert egy részhalmazra ami grafikát, egy másikat pedig amit általános számításokat futtatott A Pascal-ban behozták ennek a dinamikus változatát

43 Simultaneous Multi-Projection Engine

44 Simultaneous Multi-Projection Engine
")

45 Pascal Egyetlen, közös virtuális memóriatér a CPU-nak és a GPU-nak (legalábbis 512 TB-ig) Compute preemption most már gépi műveletek szintjén működnek, nem Kepler/Maxwell szintű threadblock-okban
46 Pascal Egy teljes Pascal-ban 1 GPC-ben: 10 SM 1 SM-ben: 6 GPC 60 Pascal SM 30 TPC (mindegyik Texture Processing clusterben kettő SM) 8 darab 512 bites memóriavezérlő 64 CUDA mag 4 textúrázó egység Azaz összesen 3840 egyszeres pontosságú CUDA mag és 240 textúrázóegység
47

48

49
50
51 Források Fermi whitepaper: rchitecture.pdf Kepler whitepaper: Maxwell whitepaper: AL.PDF Pascal whitepaper: AL.pdf
GPGPU. GPU-k felépítése. Valasek Gábor
 GPGPU GPU-k felépítése Valasek Gábor Tartalom A mai órán áttekintjük a GPU-k architekturális felépítését A cél elsősorban egy olyan absztrakt hardvermodell bemutatása, ami segít megérteni a GPU-k hardveres
GPGPU GPU-k felépítése Valasek Gábor Tartalom A mai órán áttekintjük a GPU-k architekturális felépítését A cél elsősorban egy olyan absztrakt hardvermodell bemutatása, ami segít megérteni a GPU-k hardveres
Haladó Grafika EA. Inkrementális képszintézis GPU-n
 Haladó Grafika EA Inkrementális képszintézis GPU-n Pipeline Az elvégzendő feladatot részfeladatokra bontjuk Mindegyik részfeladatot más-más egység dolgozza fel (ideális esetben) Minden egység inputja,
Haladó Grafika EA Inkrementális képszintézis GPU-n Pipeline Az elvégzendő feladatot részfeladatokra bontjuk Mindegyik részfeladatot más-más egység dolgozza fel (ideális esetben) Minden egység inputja,
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási
 GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
GPGPU-k és programozásuk Dezső, Sima Sándor, Szénási GPGPU-k és programozásuk írta Dezső, Sima és Sándor, Szénási Szerzői jog 2013 Typotex Kivonat A processzor technika alkalmazásának fejlődése terén napjaink
Párhuzamos és Grid rendszerek
 Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
Párhuzamos és Grid rendszerek (10. ea) GPGPU Szeberényi Imre BME IIT Az ábrák egy része az NVIDIA oktató anyagaiból és dokumentációiból származik. Párhuzamos és Grid rendszerek BME-IIT
Magas szintű optimalizálás
 Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre
 GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
A CUDA előnyei: - Elszórt memória olvasás (az adatok a memória bármely területéről olvashatóak) PC-Vilag.hu CUDA, a jövő technológiája?!
 PC-Vilag.hu CUDA, a jövő technológiája?!") A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
A CUDA (Compute Unified Device Architecture) egy párhuzamos számításokat használó architektúra, amelyet az NVIDIA fejlesztett ki. A CUDA valójában egy számoló egység az NVIDIA GPU-n (Graphic Processing
Grafikus csővezeték 1 / 44
 Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd.
 1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
GPGPU alapok. GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai
 GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu GPGPU alapok GPGPU alapok Grafikus kártyák evolúciója GPU programozás sajátosságai Szenasi.sandor@nik.uni-obuda.hu
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Heterogén számítási rendszerek
 Heterogén számítási rendszerek GPU-k, GPGPU CUDA, OpenCL Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális koordináta rendszerből
Heterogén számítási rendszerek GPU-k, GPGPU CUDA, OpenCL Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális koordináta rendszerből
Grafikus processzorok általános célú programozása (GPGPU)
") 2015. szeptember 17. Grafikus processzorok általános célú programozása (GPGPU) Eichhardt I., Hajder L. és V. Gábor eichhardt.ivan@sztaki.mta.hu, hajder.levente@sztaki.mta.hu, valasek@inf.elte.hu Eötvös
2015. szeptember 17. Grafikus processzorok általános célú programozása (GPGPU) Eichhardt I., Hajder L. és V. Gábor eichhardt.ivan@sztaki.mta.hu, hajder.levente@sztaki.mta.hu, valasek@inf.elte.hu Eötvös
Információ megjelenítés Számítógépes ábrázolás. Dr. Iványi Péter
 Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter (adat szerkezet) float x,y,z,w; float r,g,b,a; } vertex; glcolor3f(0, 0.5, 0); glvertex2i(11, 31); glvertex2i(37, 71); glcolor3f(0.5, 0,
Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter (adat szerkezet) float x,y,z,w; float r,g,b,a; } vertex; glcolor3f(0, 0.5, 0); glvertex2i(11, 31); glvertex2i(37, 71); glcolor3f(0.5, 0,
Számítógépek felépítése
 Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Számítógép felépítése
 Alaplap, processzor Számítógép felépítése Az alaplap A számítógép teljesítményét alapvetően a CPU és belső busz sebessége (a belső kommunikáció sebessége), a memória mérete és típusa, a merevlemez sebessége
Alaplap, processzor Számítógép felépítése Az alaplap A számítógép teljesítményét alapvetően a CPU és belső busz sebessége (a belső kommunikáció sebessége), a memória mérete és típusa, a merevlemez sebessége
Diplomamunka. Miskolci Egyetem. GPGPU technológia kriptográfiai alkalmazása. Készítette: Csikó Richárd VIJFZK mérnök informatikus
 Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
Diplomamunka Miskolci Egyetem GPGPU technológia kriptográfiai alkalmazása Készítette: Csikó Richárd VIJFZK mérnök informatikus Témavezető: Dr. Kovács László Miskolc, 2014 Köszönetnyilvánítás Ezúton szeretnék
OpenCL - The open standard for parallel programming of heterogeneous systems
 OpenCL - The open standard for parallel programming of heterogeneous systems GPU-k általános számításokhoz GPU Graphics Processing Unit Képalkotás: sok, általában egyszerű és független művelet < 2006:
OpenCL - The open standard for parallel programming of heterogeneous systems GPU-k általános számításokhoz GPU Graphics Processing Unit Képalkotás: sok, általában egyszerű és független művelet < 2006:
Ismerkedjünk tovább a számítógéppel. Alaplap és a processzeor
 Ismerkedjünk tovább a számítógéppel Alaplap és a processzeor Neumann-elvű számítógépek főbb egységei A részek feladatai: Központi egység: Feladata a számítógép vezérlése, és a számítások elvégzése. Operatív
Ismerkedjünk tovább a számítógéppel Alaplap és a processzeor Neumann-elvű számítógépek főbb egységei A részek feladatai: Központi egység: Feladata a számítógép vezérlése, és a számítások elvégzése. Operatív
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai
 Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
Újrakonfigurálható technológiák nagy teljesítményű alkalmazásai GPU-k, GPGPU CUDA Szántó Péter BME MIT, FPGA Laboratórium GPU-k Graphics Processing Unit 2 fő feladat Objektumok transzformációja a lokális
SZÁMÍTÓGÉP ARCHITEKTÚRÁK
 SZÁMÍTÓGÉP ARCHITEKTÚRÁK Az utasítás-pipeline szélesítése Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-05-19 1 UTASÍTÁSFELDOLGOZÁS
SZÁMÍTÓGÉP ARCHITEKTÚRÁK Az utasítás-pipeline szélesítése Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-05-19 1 UTASÍTÁSFELDOLGOZÁS
2. Generáció (1999-2000) 3. Generáció (2001) NVIDIA TNT2, ATI Rage, 3dfx Voodoo3. Klár Gergely tremere@elte.hu
 3. Generáció (2001) NVIDIA TNT2, ATI Rage, 3dfx Voodoo3. Klár Gergely tremere@elte.hu") 1. Generáció Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. őszi félév NVIDIA TNT2, ATI Rage, 3dfx Voodoo3 A standard 2d-s videokártyák kiegészítése
1. Generáció Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. őszi félév NVIDIA TNT2, ATI Rage, 3dfx Voodoo3 A standard 2d-s videokártyák kiegészítése
GPGPU programozás lehetőségei. Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café
 GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
GPGPU programozás lehetőségei Nagy Máté Ferenc Budapest ALICE ELTE TTK Fizika MSc 2011 e-science Café Vázlat Egy, (kettő,) sok. Bevezetés a sokszálas univerzumba. A párhuzamosok a végtelenben találkoznak,
GPU-Accelerated Collocation Pattern Discovery
 GPU-Accelerated Collocation Pattern Discovery Térbeli együttes előfordulási minták GPU-val gyorsított felismerése Gyenes Csilla Sallai Levente Szabó Andrea Eötvös Loránd Tudományegyetem Informatikai Kar
GPU-Accelerated Collocation Pattern Discovery Térbeli együttes előfordulási minták GPU-val gyorsított felismerése Gyenes Csilla Sallai Levente Szabó Andrea Eötvös Loránd Tudományegyetem Informatikai Kar
6. óra Mi van a számítógépházban? A számítógép: elektronikus berendezés. Tárolja az adatokat, feldolgozza és az adatok ki és bevitelére is képes.
 6. óra Mi van a számítógépházban? A számítógép: elektronikus berendezés. Tárolja az adatokat, feldolgozza és az adatok ki és bevitelére is képes. Neumann elv: Külön vezérlő és végrehajtó egység van Kettes
6. óra Mi van a számítógépházban? A számítógép: elektronikus berendezés. Tárolja az adatokat, feldolgozza és az adatok ki és bevitelére is képes. Neumann elv: Külön vezérlő és végrehajtó egység van Kettes
Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15 Fehér
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogén számítási rendszerek VIMIMA15 Fehér
Hardver Ismeretek IA32 -> IA64
 Hardver Ismeretek IA32 -> IA64 Problémák az IA-32-vel Bonyolult architektúra CISC ISA (RISC jobb a párhuzamos feldolgozás szempontjából) Változó utasításhossz és forma nehéz dekódolni és párhuzamosítani
Hardver Ismeretek IA32 -> IA64 Problémák az IA-32-vel Bonyolult architektúra CISC ISA (RISC jobb a párhuzamos feldolgozás szempontjából) Változó utasításhossz és forma nehéz dekódolni és párhuzamosítani
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN
 KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
KÉPFELDOLGOZÓ ALGORITMUSOK FEJLESZTÉSE GRAFIKUS HARDVER KÖRNYEZETBEN Takács Gábor Konzulens: Vajda Ferenc PhD, adjunktus 1 TARTALOMJEGYZÉK: Budapesti Műszaki és Gazdaságtudományi Egyetem A kutatási projekt
HLSL programozás. Grafikus játékok fejlesztése Szécsi László t06-hlsl
 HLSL programozás Grafikus játékok fejlesztése Szécsi László 2013.02.16. t06-hlsl RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
HLSL programozás Grafikus játékok fejlesztése Szécsi László 2013.02.16. t06-hlsl RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA. Dr. Szénási Sándor
 KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
KUTATÁSOK INFORMATIKAI TÁMOGATÁSA Dr. Szénási Sándor szenasi.sandor@nik.uni-obuda.hu Óbudai Egyetem Neumann János Informatikai Kar Alkalmazott Informatikai Intézet Alapvető jellemzői NVIDIA GTX 1080 2560
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely
 Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
5-6. ea Created by mrjrm & Pogácsa, frissítette: Félix
 2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15 Fehér
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Parciális rekonfiguráció Heterogán számítási rendszerek VIMIMA15 Fehér
Az MTA Cloud a tudományos alkalmazások támogatására. Kacsuk Péter MTA SZTAKI
 Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Számítógépek felépítése, alapfogalmak
 2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd, Krankovits Melinda SZE MTK MSZT kmelinda@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? 2 Nem reprezentatív felmérés
2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd, Krankovits Melinda SZE MTK MSZT kmelinda@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? 2 Nem reprezentatív felmérés
Direct3D pipeline. Grafikus játékok fejlesztése Szécsi László t03-pipeline
 Direct3D pipeline Grafikus játékok fejlesztése Szécsi László 2013.02.12. t03-pipeline RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
Direct3D pipeline Grafikus játékok fejlesztése Szécsi László 2013.02.12. t03-pipeline RESOURCES PIPELINE STAGES RENDER STATES Vertex buffer Instance buffer Constant buffers and textures Index buffer Constant
OpenCL alapú eszközök verifikációja és validációja a gyakorlatban
 OpenCL alapú eszközök verifikációja és validációja a gyakorlatban Fekete Tamás 2015. December 3. Szoftver verifikáció és validáció tantárgy Áttekintés Miért és mennyire fontos a megfelelő validáció és
OpenCL alapú eszközök verifikációja és validációja a gyakorlatban Fekete Tamás 2015. December 3. Szoftver verifikáció és validáció tantárgy Áttekintés Miért és mennyire fontos a megfelelő validáció és
Utolsó módosítás:
 Utolsó módosítás:2011. 09. 29. 1 2 4 5 MMU!= fizikai memóriaillesztő áramkör. Az utóbbinak a feladata a memória modulok elektromos alacsonyszintű vezérlése, ez sokáig a CPU-n kívül a chipset északi hídban
Utolsó módosítás:2011. 09. 29. 1 2 4 5 MMU!= fizikai memóriaillesztő áramkör. Az utóbbinak a feladata a memória modulok elektromos alacsonyszintű vezérlése, ez sokáig a CPU-n kívül a chipset északi hídban
Bevezetés a CGI-be. 1. Történelem
 Bevezetés a CGI-be 1. Történelem 1.1 Úttörők Euklidész (ie.. 300-250) - A számítógépes grafika geometriai hátterének a megteremtője Bresenham (60 évek) - Első vonalrajzolás raster raster készüléken, később
Bevezetés a CGI-be 1. Történelem 1.1 Úttörők Euklidész (ie.. 300-250) - A számítógépes grafika geometriai hátterének a megteremtője Bresenham (60 évek) - Első vonalrajzolás raster raster készüléken, később
OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA
 Multidiszciplináris tudományok, 3. kötet. (2013) sz. pp. 259-268. OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA Mileff Péter Adjunktus, Miskolci Egyetem, Informatikai Intézet, Általános
Multidiszciplináris tudományok, 3. kötet. (2013) sz. pp. 259-268. OSZTOTT 2D RASZTERIZÁCIÓS MODELL TÖBBMAGOS PROCESSZOROK SZÁMÁRA Mileff Péter Adjunktus, Miskolci Egyetem, Informatikai Intézet, Általános
OpenCL Kovács, György
 OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
OpenCL Kovács, György OpenCL Kovács, György Szerzői jog 2013 Typotex Tartalom Bevezetés... xii 1. Az OpenCL története... xii 2. Az OpenCL jelene és jövője... xvii 3. OpenCL a Flynn-osztályokban... xviii
Hallgatói segédlet: Nvidia CUDA C programok debugolása Nvidia Optimus technológiás laptopokon. Készítette: Kovács Andor. 2011/2012 első félév
 Hallgatói segédlet: Nvidia CUDA C programok debugolása Nvidia Optimus technológiás laptopokon Készítette: Kovács Andor 2011/2012 első félév 1 A CUDA programok debugolásához kettő grafikus kártyára van
Hallgatói segédlet: Nvidia CUDA C programok debugolása Nvidia Optimus technológiás laptopokon Készítette: Kovács Andor 2011/2012 első félév 1 A CUDA programok debugolásához kettő grafikus kártyára van
efocus Content management, cikkírás referencia
 Gainward nvidia GeForce GTX 550 Ti VGA A GTX 460 sikeres folytatásaként aposztrofált GTX 550 Ti egy kicsit GTS, egy kicsit Ti, de leginkább GTX. Ebben a hárombetűs forgatagban az ember már lassan alig
Gainward nvidia GeForce GTX 550 Ti VGA A GTX 460 sikeres folytatásaként aposztrofált GTX 550 Ti egy kicsit GTS, egy kicsit Ti, de leginkább GTX. Ebben a hárombetűs forgatagban az ember már lassan alig
Bevitel-Kivitel. Eddig a számítógép agyáról volt szó. Szükség van eszközökre. Processzusok, memória, stb
 Input és Output 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel és kivitel a számitógépből, -be Perifériák 2 Perifériákcsoportosításá,
Input és Output 1 Bevitel-Kivitel Eddig a számítógép agyáról volt szó Processzusok, memória, stb Szükség van eszközökre Adat bevitel és kivitel a számitógépből, -be Perifériák 2 Perifériákcsoportosításá,
Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)
, Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)") 1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
Magic xpi 4.0 vadonatúj Architektúrája Gigaspaces alapokon
 Magic xpi 4.0 vadonatúj Architektúrája Gigaspaces alapokon Mi az IMDG? Nem memóriában futó relációs adatbázis NoSQL hagyományos relációs adatbázis Más fajta adat tárolás Az összes adat RAM-ban van, osztott
Magic xpi 4.0 vadonatúj Architektúrája Gigaspaces alapokon Mi az IMDG? Nem memóriában futó relációs adatbázis NoSQL hagyományos relációs adatbázis Más fajta adat tárolás Az összes adat RAM-ban van, osztott
Négyprocesszoros közvetlen csatolású szerverek architektúrája:
 SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
egy szisztolikus példa
 Automatikus párhuzamosítás egy szisztolikus példa Áttekintés Bevezetés Példa konkrét szisztolikus algoritmus Automatikus párhuzamosítási módszer ötlet Áttekintés Bevezetés Példa konkrét szisztolikus algoritmus
Automatikus párhuzamosítás egy szisztolikus példa Áttekintés Bevezetés Példa konkrét szisztolikus algoritmus Automatikus párhuzamosítási módszer ötlet Áttekintés Bevezetés Példa konkrét szisztolikus algoritmus
Operációs rendszerek. Az NT folyamatok kezelése
 Operációs rendszerek Az NT folyamatok kezelése Folyamatok logikai felépítése A folyamat modell: egy adott program kódját végrehajtó szál(ak)ból és, a szál(ak) által lefoglalt erőforrásokból állnak. Folyamatok
Operációs rendszerek Az NT folyamatok kezelése Folyamatok logikai felépítése A folyamat modell: egy adott program kódját végrehajtó szál(ak)ból és, a szál(ak) által lefoglalt erőforrásokból állnak. Folyamatok
Valasek Gábor
 Valasek Gábor valasek@inf.elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2011/2012. őszi félév Tartalom 1 Textúrázás Bevezetés Textúra leképezés Paraméterezés Textúra szűrés Procedurális textúrák
Valasek Gábor valasek@inf.elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2011/2012. őszi félév Tartalom 1 Textúrázás Bevezetés Textúra leképezés Paraméterezés Textúra szűrés Procedurális textúrák
Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)
, Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication)") 1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
1 Processzusok (Processes), Szálak (Threads), Kommunikáció (IPC, Inter-Process Communication) 1. A folyamat (processzus, process) fogalma 2. Folyamatok: műveletek, állapotok, hierarchia 3. Szálak (threads)
Mikrorendszerek tervezése
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Mikrorendszerek tervezése Beágyazott rendszerek Fehér Béla Raikovich Tamás
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Mikrorendszerek tervezése Beágyazott rendszerek Fehér Béla Raikovich Tamás
Heterogén számítási rendszerek gyakorlatok (2017.)
") Heterogén számítási rendszerek gyakorlatok (2017.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 6 2.1 Global
Heterogén számítási rendszerek gyakorlatok (2017.) Tartalom 1. 2D konvolúció megvalósítása C-ben... 2 1.1 C implementáció... 2 1.2 OpenMP... 5 1.3 Vektorizáció... 5 2. 2D konvolúció GPU-val... 6 2.1 Global
Információ megjelenítés Számítógépes ábrázolás. Dr. Iványi Péter
 Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter Raszterizáció OpenGL Mely pixelek vannak a primitíven belül fragment generálása minden ilyen pixelre Attribútumok (pl., szín) hozzárendelése
Információ megjelenítés Számítógépes ábrázolás Dr. Iványi Péter Raszterizáció OpenGL Mely pixelek vannak a primitíven belül fragment generálása minden ilyen pixelre Attribútumok (pl., szín) hozzárendelése
Bepillantás a gépházba
 Bepillantás a gépházba Neumann-elvű számítógépek főbb egységei A részek feladatai: Központi egység: Feladata a számítógép vezérlése, és a számítások elvégzése. Operatív memória: A számítógép bekapcsolt
Bepillantás a gépházba Neumann-elvű számítógépek főbb egységei A részek feladatai: Központi egység: Feladata a számítógép vezérlése, és a számítások elvégzése. Operatív memória: A számítógép bekapcsolt
Féléves feladat. Miről lesz szó? Bemutatkozás és követelmények 2012.09.16.
 Bemutatkozás és követelmények Dr. Mileff Péter Dr. Mileff Péter Helyileg: A/1-303. szoba. Fizika Tanszék Konzultációs idő: Szerda 10-12 mileff@iit.uni-miskolc.hu Követelmények: Az órák ¾-én kötelező a
Bemutatkozás és követelmények Dr. Mileff Péter Dr. Mileff Péter Helyileg: A/1-303. szoba. Fizika Tanszék Konzultációs idő: Szerda 10-12 mileff@iit.uni-miskolc.hu Követelmények: Az órák ¾-én kötelező a
A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem)
") 65-67 A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem) Két fő része: a vezérlőegység, ami a memóriában tárolt program dekódolását és végrehajtását végzi, az
65-67 A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem) Két fő része: a vezérlőegység, ami a memóriában tárolt program dekódolását és végrehajtását végzi, az
Hozzáférés a HPC-hez, kezdő lépések (előadás és demó)
") Hozzáférés a HPC-hez, kezdő lépések (előadás és demó) 2013.04.16. Rőczei Gábor roczei@niif.hu Főbb témák Hozzáférés a HPC-hez (Linux/Windows) Programok elindítása a különböző HPC gépeken Vizualizáció (kapcsolódás
Hozzáférés a HPC-hez, kezdő lépések (előadás és demó) 2013.04.16. Rőczei Gábor roczei@niif.hu Főbb témák Hozzáférés a HPC-hez (Linux/Windows) Programok elindítása a különböző HPC gépeken Vizualizáció (kapcsolódás
Operációs rendszerek III.
 A WINDOWS NT memóriakezelése Az NT memóriakezelése Memóriakezelő feladatai: Logikai-fizikai címtranszformáció: A folyamatok virtuális címterének címeit megfelelteti fizikai címeknek. A virtuális memóriakezelés
A WINDOWS NT memóriakezelése Az NT memóriakezelése Memóriakezelő feladatai: Logikai-fizikai címtranszformáció: A folyamatok virtuális címterének címeit megfelelteti fizikai címeknek. A virtuális memóriakezelés
TUDOMÁNYOS ADATBÁZISOK MA ÉS A JÖVŐBEN. X64 ALAPÚ KISZOLGÁLÓ RENDSZEREK Tudomány Adatbázisok, 1. előadás, (c) 2010
 2010") Tudományos adatbázisok tervezése és építése 1. előadás TUDOMÁNYOS ADATBÁZISOK MA ÉS A JÖVŐBEN X64 ALAPÚ KISZOLGÁLÓ RENDSZEREK Tudomány Adatbázisok, 1. előadás, (c) 2010 2010.02.15. 1 Dobos László A tudományos
Tudományos adatbázisok tervezése és építése 1. előadás TUDOMÁNYOS ADATBÁZISOK MA ÉS A JÖVŐBEN X64 ALAPÚ KISZOLGÁLÓ RENDSZEREK Tudomány Adatbázisok, 1. előadás, (c) 2010 2010.02.15. 1 Dobos László A tudományos
Grafikus kártyák, mint olcsó szuperszámítógépek - I.
 (1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport (2) Vázlat I. Motiváció Beüzemelés C alapok CUDA programozási modell,
(1) Grafikus kártyák, mint olcsó szuperszámítógépek - I. tanuló szeminárium Jurek Zoltán, Tóth Gyula SZFKI, Röntgendiffrakciós csoport (2) Vázlat I. Motiváció Beüzemelés C alapok CUDA programozási modell,
Utolsó módosítás:
 Utolsó módosítás:2010. 09. 15. 1 2 Kicsit konkrétabban: az utasítás hatására a belső regiszterek valamelyikének értékét módosítja, felhasználva regiszter értékeket és/vagy kívülről betöltött adatot. A
Utolsó módosítás:2010. 09. 15. 1 2 Kicsit konkrétabban: az utasítás hatására a belső regiszterek valamelyikének értékét módosítja, felhasználva regiszter értékeket és/vagy kívülről betöltött adatot. A
Videókártya - CUDA kompatibilitás: CUDA weboldal: Példaterületek:
 Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
Hasznos weboldalak Videókártya - CUDA kompatibilitás: https://developer.nvidia.com/cuda-gpus CUDA weboldal: https://developer.nvidia.com/cuda-zone Példaterületek: http://www.nvidia.com/object/imaging_comp
A számítógépes grafika inkrementális képszintézis algoritmusának hardver realizációja Teljesítménykövetelmények:
 Beveetés A sámítógépes grafika inkrementális képsintéis algoritmusának hardver realiációja Teljesítménykövetelmények: Animáció: néhány nsec/ képpont Massívan párhuamos Pipeline(stream processor) Párhuamos
Beveetés A sámítógépes grafika inkrementális képsintéis algoritmusának hardver realiációja Teljesítménykövetelmények: Animáció: néhány nsec/ képpont Massívan párhuamos Pipeline(stream processor) Párhuamos
ROBUSZTUS GPGPU PLUGIN FEJLESZTÉSE A RAPIDMINER ADATBÁNYÁSZATI SZOFTVERHEZ
 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Távközlési és Médiainformatikai Tanszék ROBUSZTUS GPGPU PLUGIN FEJLESZTÉSE A RAPIDMINER ADATBÁNYÁSZATI SZOFTVERHEZ KÉSZÍTETTE:
Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Távközlési és Médiainformatikai Tanszék ROBUSZTUS GPGPU PLUGIN FEJLESZTÉSE A RAPIDMINER ADATBÁNYÁSZATI SZOFTVERHEZ KÉSZÍTETTE:
Operációs rendszerek. Az NT memóriakezelése
 Operációs rendszerek MS Windows NT (2000) memóriakezelés Az NT memóriakezelése 32-bites virtuális memóriakezelés: 4 GB-os címtartomány, alapesetben: a fels! 2 GB az alkalmazásoké, az alsó 2 GB az OPR-é.
Operációs rendszerek MS Windows NT (2000) memóriakezelés Az NT memóriakezelése 32-bites virtuális memóriakezelés: 4 GB-os címtartomány, alapesetben: a fels! 2 GB az alkalmazásoké, az alsó 2 GB az OPR-é.
Digitális rendszerek. Mikroarchitektúra szintje
 Digitális rendszerek Mikroarchitektúra szintje Mikroarchitektúra Jellemzők A digitális logika feletti szint Feladata az utasításrendszer-architektúra szint megalapozása, illetve megvalósítása Példa Egy
Digitális rendszerek Mikroarchitektúra szintje Mikroarchitektúra Jellemzők A digitális logika feletti szint Feladata az utasításrendszer-architektúra szint megalapozása, illetve megvalósítása Példa Egy
Utolsó módosítás:
 Utolsó módosítás: 2012. 09. 06. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 Forrás: Gartner Hype Cycle for Virtualization, 2010, http://premierit.intel.com/docs/doc-5768
Utolsó módosítás: 2012. 09. 06. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 Forrás: Gartner Hype Cycle for Virtualization, 2010, http://premierit.intel.com/docs/doc-5768
GPU alkalmazása az ALICE eseménygenerátorában
 GPU alkalmazása az ALICE eseménygenerátorában Nagy Máté Ferenc MTA KFKI RMKI ALICE csoport ELTE TTK Fizika MSc Témavezető: Dr. Barnaföldi Gergely Gábor MTA KFKI RMKI ALICE csoport Elméleti Fizikai Főosztály
GPU alkalmazása az ALICE eseménygenerátorában Nagy Máté Ferenc MTA KFKI RMKI ALICE csoport ELTE TTK Fizika MSc Témavezető: Dr. Barnaföldi Gergely Gábor MTA KFKI RMKI ALICE csoport Elméleti Fizikai Főosztály
Fábián Zoltán Hálózatok elmélet
 Fábián Zoltán Hálózatok elmélet Fizikai memória Félvezetőkből előállított memóriamodulok RAM - (Random Access Memory) -R/W írható, olvasható, pldram, SDRAM, A dinamikusan frissítendők : Nagyon rövid időnként
Fábián Zoltán Hálózatok elmélet Fizikai memória Félvezetőkből előállított memóriamodulok RAM - (Random Access Memory) -R/W írható, olvasható, pldram, SDRAM, A dinamikusan frissítendők : Nagyon rövid időnként
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Grafikus csővezeték és az OpenGL függvénykönyvtár
 Grafikus csővezeték és az OpenGL függvénykönyvtár 1 / 32 A grafikus csővezeték 3D-s színtér objektumainak leírása primitívekkel: pontok, élek, poligonok. Primitívek szögpontjait vertexeknek nevezzük Adott
Grafikus csővezeték és az OpenGL függvénykönyvtár 1 / 32 A grafikus csővezeték 3D-s színtér objektumainak leírása primitívekkel: pontok, élek, poligonok. Primitívek szögpontjait vertexeknek nevezzük Adott
GPU Lab. 4. fejezet. Fordítók felépítése. Grafikus Processzorok Tudományos Célú Programozása. Berényi Dániel Nagy-Egri Máté Ferenc
 4. fejezet Fordítók felépítése Grafikus Processzorok Tudományos Célú Programozása Fordítók Kézzel assembly kódot írni nem érdemes, mert: Egyszerűen nem skálázik nagy problémákhoz arányosan sok kódot kell
4. fejezet Fordítók felépítése Grafikus Processzorok Tudományos Célú Programozása Fordítók Kézzel assembly kódot írni nem érdemes, mert: Egyszerűen nem skálázik nagy problémákhoz arányosan sok kódot kell
2D képszintézis. Szirmay-Kalos László
 2D képszintézis Szirmay-Kalos László 2D képszintézis Modell szín (200, 200) Kép Kamera ablak (window) viewport Unit=pixel Saját színnel rajzolás Világ koordinátarendszer Pixel vezérelt megközelítés: Tartalmazás
2D képszintézis Szirmay-Kalos László 2D képszintézis Modell szín (200, 200) Kép Kamera ablak (window) viewport Unit=pixel Saját színnel rajzolás Világ koordinátarendszer Pixel vezérelt megközelítés: Tartalmazás
Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása. Rákosi Péter és Lányi Árpád
 Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása Rákosi Péter és Lányi Árpád Adattárház korábbi üzemeltetési jellemzői Online szolgáltatásokat nem szolgált ki, klasszikus elemzésre
Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása Rákosi Péter és Lányi Árpád Adattárház korábbi üzemeltetési jellemzői Online szolgáltatásokat nem szolgált ki, klasszikus elemzésre
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Szakdolgozat. Dandár Gábor
 Szakdolgozat Dandár Gábor Debrecen 2008 Debreceni Egyetem Informatikai Kar A shader nyelvek lehetőségeiről A GPU felhasználása általános célú számításokra Témavezető: Készítette: Dr. Tornai Róbert Dandár
Szakdolgozat Dandár Gábor Debrecen 2008 Debreceni Egyetem Informatikai Kar A shader nyelvek lehetőségeiről A GPU felhasználása általános célú számításokra Témavezető: Készítette: Dr. Tornai Róbert Dandár
Google Summer of Code OpenCL image support for the r600g driver
 Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
Google Summer of Code 2015 OpenCL image support for the r600g driver Képek: http://www.google-melange.com a Min szeretnék dolgozni? Kapcsolatfelvétel a mentorral Project proposal Célok Miért jó ez? Milestone-ok
A számítógép egységei
 A számítógép egységei A számítógépes rendszer két alapvető részből áll: Hardver (a fizikai eszközök összessége) Szoftver (a fizikai eszközöket működtető programok összessége) 1.) Hardver a) Alaplap: Kommunikációt
A számítógép egységei A számítógépes rendszer két alapvető részből áll: Hardver (a fizikai eszközök összessége) Szoftver (a fizikai eszközöket működtető programok összessége) 1.) Hardver a) Alaplap: Kommunikációt
Teszt: Az nvidia GeForce kártyák Crysis 2-ben mért teljesítménye
 Teszt: Az nvidia GeForce kártyák Crysis 2-ben mért teljesítménye Mivel úgy gondoljuk, hogy az egyes nvidia GeForce kártyák teljesítményét legjobban egy játékteszt során lehet bemutatni, így a Dirt3 teszt
Teszt: Az nvidia GeForce kártyák Crysis 2-ben mért teljesítménye Mivel úgy gondoljuk, hogy az egyes nvidia GeForce kártyák teljesítményét legjobban egy játékteszt során lehet bemutatni, így a Dirt3 teszt
Nagy mennyiségű adatok elemzése és előrejelzési felhasználása masszívan párhuzamosítható architektúrával
 Nagy ennyiségű adatok elezése és előrejelzési felhasználása asszívan párhuzaosítható architektúrával Készítette: Retek Mihály Budapesti Corvinus Egyete, Gazdaságföldrajz és Jövőkutatás Tanszék A Magyar
Nagy ennyiségű adatok elezése és előrejelzési felhasználása asszívan párhuzaosítható architektúrával Készítette: Retek Mihály Budapesti Corvinus Egyete, Gazdaságföldrajz és Jövőkutatás Tanszék A Magyar
Hibrid előadás: az ea másik felében a Morgen Stanley munkatársa kiegészítéseket fog hozzáfűzni a témához. Hagyományos és szerverrendszerek.
 Hibrid előadás: az ea másik felében a Morgen Stanley munkatársa kiegészítéseket fog hozzáfűzni a témához. Hagyományos és szerverrendszerek. 1 2 3 2000 őszén bejelentés: Netburst architektúra meghírdetése:
Hibrid előadás: az ea másik felében a Morgen Stanley munkatársa kiegészítéseket fog hozzáfűzni a témához. Hagyományos és szerverrendszerek. 1 2 3 2000 őszén bejelentés: Netburst architektúra meghírdetése:
Matematikai és Informatikai Intézet. 4. Folyamatok
 4. Folyamatok A folyamat (processzus) fogalma Folyamat ütemezés (scheduling) Folyamatokon végzett "mûveletek" Folyamatok együttmûködése, kooperációja Szálak (thread) Folyamatok közötti kommunikáció 49
4. Folyamatok A folyamat (processzus) fogalma Folyamat ütemezés (scheduling) Folyamatokon végzett "mûveletek" Folyamatok együttmûködése, kooperációja Szálak (thread) Folyamatok közötti kommunikáció 49
Grafikus csővezeték 2 / 77
 Bevezetés 1 / 77 Grafikus csővezeték 2 / 77 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve
Bevezetés 1 / 77 Grafikus csővezeték 2 / 77 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve
Informatika el adás: Hardver
 Informatika 1. 1. el adás: Hardver Wettl Ferenc és Kovács Kristóf prezentációjának felhasználásával Budapesti M szaki és Gazdaságtudományi Egyetem 2017-09-05 Követelmények 3 ZH 5. 9. 14. héten egyenként
Informatika 1. 1. el adás: Hardver Wettl Ferenc és Kovács Kristóf prezentációjának felhasználásával Budapesti M szaki és Gazdaságtudományi Egyetem 2017-09-05 Követelmények 3 ZH 5. 9. 14. héten egyenként
D3D, DXUT primer. Grafikus játékok fejlesztése Szécsi László t01-system
 D3D, DXUT primer Grafikus játékok fejlesztése Szécsi László 2013.02.13. t01-system Háromszögháló reprezentáció Mesh Vertex buffer Index buffer Vertex buffer csúcs-rekordok tömbje pos normal tex pos normal
D3D, DXUT primer Grafikus játékok fejlesztése Szécsi László 2013.02.13. t01-system Háromszögháló reprezentáció Mesh Vertex buffer Index buffer Vertex buffer csúcs-rekordok tömbje pos normal tex pos normal
ARM Cortex magú mikrovezérlők
 ARM Cortex magú mikrovezérlők 3. Cortex-M0, M4, M7 Scherer Balázs Budapest University of Technology and Economics Department of Measurement and Information Systems BME-MIT 2018 32 bites trendek 2003-2017
ARM Cortex magú mikrovezérlők 3. Cortex-M0, M4, M7 Scherer Balázs Budapest University of Technology and Economics Department of Measurement and Information Systems BME-MIT 2018 32 bites trendek 2003-2017
HP-SEE projekt eredményei
 2013. március 26. Networkshop 2013 Sopron Rőczei Gábor roczei@niif.hu HP-SEE projekt High-Performance Computing Infrastructure for South East Europe s Research Communities (HP-SEE) PRACE mintájára jött
2013. március 26. Networkshop 2013 Sopron Rőczei Gábor roczei@niif.hu HP-SEE projekt High-Performance Computing Infrastructure for South East Europe s Research Communities (HP-SEE) PRACE mintájára jött
Teszt Az nvidia GeForce VGA kártyák gyakorlati teljesítménye a Dirt3-ban
 Teszt Az nvidia GeForce VGA kártyák gyakorlati teljesítménye a Dirt3-ban Nemrég megjelent a Codemasters nevével fémjelzett Dirt3 videojáték. Kaptunk az alkalmon és megnéztük, hogy a különböző árszegmensű
Teszt Az nvidia GeForce VGA kártyák gyakorlati teljesítménye a Dirt3-ban Nemrég megjelent a Codemasters nevével fémjelzett Dirt3 videojáték. Kaptunk az alkalmon és megnéztük, hogy a különböző árszegmensű
GPU Lab. 14. fejezet. OpenCL textúra használat. Grafikus Processzorok Tudományos Célú Programozása. Berényi Dániel Nagy-Egri Máté Ferenc
 14. fejezet OpenCL textúra használat Grafikus Processzorok Tudományos Célú Programozása Textúrák A textúrák 1, 2, vagy 3D-s tömbök kifejezetten szín információk tárolására Főbb különbségek a bufferekhez
14. fejezet OpenCL textúra használat Grafikus Processzorok Tudományos Célú Programozása Textúrák A textúrák 1, 2, vagy 3D-s tömbök kifejezetten szín információk tárolására Főbb különbségek a bufferekhez
Klár Gergely 2010/2011. tavaszi félév
 Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. tavaszi félév Tartalom Generációk Shader Model 3.0 (és korábban) Shader Model 4.0 Shader Model
Számítógépes Grafika Klár Gergely tremere@elte.hu Eötvös Loránd Tudományegyetem Informatikai Kar 2010/2011. tavaszi félév Tartalom Generációk Shader Model 3.0 (és korábban) Shader Model 4.0 Shader Model
Mikrorendszerek tervezése
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Mikrorendszerek tervezése MicroBlaze processzor Fehér Béla Raikovich Tamás
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Mikrorendszerek tervezése MicroBlaze processzor Fehér Béla Raikovich Tamás
Utolsó módosítás:
 Utolsó módosítás: 2011. 09. 08. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 10 11 12 13 14 Erősen buzzword-fertőzött terület, manapság mindent szeretnek
Utolsó módosítás: 2011. 09. 08. 1 A tantárggyal kapcsolatos adminisztratív kérdésekkel Micskei Zoltánt keressétek. 2 3 4 5 6 7 8 9 10 11 12 13 14 Erősen buzzword-fertőzött terület, manapság mindent szeretnek
GRAFIKA PROGRAMOZÁSA. Bemutatkozás és követelmények. Dr. Mileff Péter
 Dr. Mileff Péter GRAFIKA PROGRAMOZÁSA BEVEZETÉS Miskolci Egyetem Általános Informatikai Tanszék Bemutatkozás és követelmények Dr. Mileff Péter Helyileg: Informatikai Intézet 110. szoba Konzultációs idő:
Dr. Mileff Péter GRAFIKA PROGRAMOZÁSA BEVEZETÉS Miskolci Egyetem Általános Informatikai Tanszék Bemutatkozás és követelmények Dr. Mileff Péter Helyileg: Informatikai Intézet 110. szoba Konzultációs idő:
elektronikus adattárolást memóriacím
 MEMÓRIA Feladata A memória elektronikus adattárolást valósít meg. A számítógép csak olyan műveletek elvégzésére és csak olyan adatok feldolgozására képes, melyek a memóriájában vannak. Az információ tárolása
MEMÓRIA Feladata A memória elektronikus adattárolást valósít meg. A számítógép csak olyan műveletek elvégzésére és csak olyan adatok feldolgozására képes, melyek a memóriájában vannak. Az információ tárolása
Bentley új generációs alkalmazásai: ContextCapture, LumenRt és Connect Edition. L - Tér Informatika Kft.
 Bentley új generációs alkalmazásai: ContextCapture, LumenRt és Connect Edition L - Tér Informatika Kft. Bentley alkalmazások műszaki folyamatokban Állapot átvétele Tervezett objektumok illesztése meglévő
Bentley új generációs alkalmazásai: ContextCapture, LumenRt és Connect Edition L - Tér Informatika Kft. Bentley alkalmazások műszaki folyamatokban Állapot átvétele Tervezett objektumok illesztése meglévő
Az NIIF új szuperszámítógép infrastruktúrája Új lehetőségek a kutatói hálózatban 2012.02.23.
 Az NIIF új szuperszámítógép infrastruktúrája Új lehetőségek a kutatói hálózatban 2012.02.23. Dr. Máray Tamás NIIF Intézet NIIF szuperszámítógép szolgáltatás a kezdetek 2001 Sun E10k 60 Gflops SMP architektúra
Az NIIF új szuperszámítógép infrastruktúrája Új lehetőségek a kutatói hálózatban 2012.02.23. Dr. Máray Tamás NIIF Intézet NIIF szuperszámítógép szolgáltatás a kezdetek 2001 Sun E10k 60 Gflops SMP architektúra
Operációs rendszerek Folyamatok 1.1
 Operációs rendszerek p. Operációs rendszerek Folyamatok 1.1 Pere László (pipas@linux.pte.hu) PÉCSI TUDOMÁNYEGYETEM TERMÉSZETTUDOMÁNYI KAR INFORMATIKA ÉS ÁLTALÁNOS TECHNIKA TANSZÉK A rendszermag Rendszermag
Operációs rendszerek p. Operációs rendszerek Folyamatok 1.1 Pere László (pipas@linux.pte.hu) PÉCSI TUDOMÁNYEGYETEM TERMÉSZETTUDOMÁNYI KAR INFORMATIKA ÉS ÁLTALÁNOS TECHNIKA TANSZÉK A rendszermag Rendszermag
(kernel3d vizualizáció: kernel245_graph.mpg)
") (kernel3d vizualizáció: kernel245_graph.mpg) http://www.pabr.org/kernel3d/kernel3d.html http://blog.mit.bme.hu/meszaros/node/163 1 (ml4 unix mérés boot demo) 2 UNIX: folyamatok kezelése kiegészítő fóliák
(kernel3d vizualizáció: kernel245_graph.mpg) http://www.pabr.org/kernel3d/kernel3d.html http://blog.mit.bme.hu/meszaros/node/163 1 (ml4 unix mérés boot demo) 2 UNIX: folyamatok kezelése kiegészítő fóliák
Memóriák - tárak. Memória. Kapacitás Ár. Sebesség. Háttértár. (felejtő) (nem felejtő)
 (nem felejtő)") Memóriák (felejtő) Memória Kapacitás Ár Sebesség Memóriák - tárak Háttértár (nem felejtő) Memória Vezérlő egység Központi memória Aritmetikai Logikai Egység (ALU) Regiszterek Programok Adatok Ez nélkül
Memóriák (felejtő) Memória Kapacitás Ár Sebesség Memóriák - tárak Háttértár (nem felejtő) Memória Vezérlő egység Központi memória Aritmetikai Logikai Egység (ALU) Regiszterek Programok Adatok Ez nélkül