Az adatelemzés alapfeladatai
|
|
|
- Irén Tamás
- 7 évvel ezelőtt
- Látták:
Átírás

1 Az adatelemzés alapfeladatai 2017 ősz 6./7. alkalom Kocsis Imre Budapesti Műszaki és Gazdaságtudományi Egyetem Hibatűrő Rendszerek Kutatócsoport Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék 1
2 MACHINE LEARNING / DATA MINING: ALAPFELADATOK 2
3 Adatelemzés: legfontosabb problémák Csoportosítás (clustering) Osztályozás (classification) Asszoc. szabályok (assoc. rules) Regresszió (regression) 3
4 Probléma-osztály; Szemléltetés; (Egy algoritmus kivonata) Megközelítés Fő cél: orientáció Deep learning, TensorFlow,... N.B. egyre kevésbé kézműves tevékenység o 10 Algorithms every Data Scientist has to know o SaaS/PaaS o Lásd később 4
5 Csoportosítás
6 K-means Adatpontok: vektortér Klaszter reprezentációja: súlyponttal / középponttal (vektor-átlag) r(c i ): i-edik klaszter reprezentánsa Minimalizálandó a négyzetes távolságösszeg, mint hiba: E C = k i=1 u C i d u, r C i 2
7 Demo 7
 változik do for u D")
) if h j then { C j C j u C i")

8 Egy megoldás {r C 1, r C 2,, r(c k )} repr. kezdeti halmaza while r(c i ) változik do for u D adott sorrendben do return C h u klaszter-indexe j argmin i d(u, r(c i )) if h j then { C j C j u C i C i u r(c j ) 1 C j r(c h ) 1 C h v C j v v C h v} Régi klaszter Új klaszter Itt rögtön újra is számoljuk
9 Alapkérdések Klasztereken belül maximális homogenitás o nagy hasonlóság o kis távolság Klaszterek között nagy távolság o kis hasonlóság különböző klaszterek elemei között Hasonlósági mérce: similarity metric o Kategorikus változókra nehéz o Skálatranszformáció kellhet o Lehet választani... o Hierarchikus klaszterezés: dissimilarity metric Hasonlósági küszöb választása? Optimális klaszterszám? 9
 és (1,1) távolsága?")
10 Néhány távolság-mérték (0,0) és (1,1) távolsága? 10
11 Mahalanobis távolság? Pont és eloszlás távolsága (S: kov-mátrix) Szemléletesen : 11



 o Magpontok: legalább minpts")
12 Lineárisan nem szeparálható klaszterek: sűrűség alapú klaszterezés További változatok packing together closely grouped points Pl. DBSCAN ( Density-based spatial clustering of applications with noise ) o Magpontok: legalább minpts pont e távolságon belül o Sűrűség-elérhető pontok o Outlierek 12

13 (Agglomeratív) hierarchikus klaszterezés CSAK KITEKINTÉS 13

14 Osztályozás Képosztályozás: a képen látható objektum madár vagy repülő?
15 Osztályozás Levelek osztályozása: SPAM vagy nem SPAM?

16 Osztályozás Szabályok alapján Severity osztályozása Kép forrása:

17 Döntési fák (Titanic, túlélési esélyek) Túlélés esélye -> osztály tisztasága Number of siblings or spouses aboard Megfigyelések aránya

18 ~= klaszterezés Klaszterezés és klasszifikáció alapfeladat Semi-supervised ~= klasszifikáció Kép forrása: Ramaswamy S, Golub T R JCO 2002;20:


19 Felügyelt és nem felügyelt tanulás Felügyelt tanulás o Adott néhány pontra az elvárt kimenet is o a tanuló példákból való általánosítás o Output: függvény a meglévő mintapontokra jól képez le megfelelően általánosítható Nem felügyelt tanulás o Nincs meg az elvárt kimenet o Visszajelzés nélkül építi a modellt Tanulóhalmaz: amin építjük a modellt Teszthalmaz: amin ellenőrizzük o szabályok, összefüggések keresése (ismeretfeltárás)
20 Demo R party csomag Conditional Inference Tree, iris o Hogy ez mi, azt nem kezdjük itt nagyon részletezni o Party ctree dokumentáció: Roughly, the algorithm works as follows: 1) Test the global null hypothesis of independence between any of the input variables and the response (which may be multivariate as well). Stop if this hypothesis cannot be rejected. Otherwise select the input variable with strongest association to the response. This association is measured by a p-value corresponding to a test for the partial null hypothesis of a single input variable and the response. 2) Implement a binary split in the selected input variable. 3) Recursively repeat steps 1) and 2). 20
 null indikatív hypothesis a (függetlenségi) of independence hipotézis between ellen any of the input variables and the response (which may be multivariate as well).")
21 Demo R party csomag Conditional Inference Tree, iris o Hogy ez mi, azt nem kezdjük itt nagyon részletezni o Party ctree dokumentáció: Roughly, the algorithm works as follows: Kis 1) érték Test the (tip. global 0.05) null indikatív hypothesis a (függetlenségi) of independence hipotézis between ellen any of the input variables and the response (which may be multivariate as well). Stop if this hypothesis cannot be rejected. Otherwise select the input variable with strongest association to the response. This association is measured by a p-value corresponding to a test for the partial null hypothesis of a single input variable and the response. 2) Implement a binary split in the selected input variable. 3) Recursively repeat steps 1) and 2). Pl. entrópia-csökkenés maximalizálásával: a split csökkenti az össz-entrópiát (alágak entrópiájának súlyozott összege) 21
22 Demo 22

23 Bináris döntések jóságának mérése 23

24 Érzékenység vagy specifikusság a fontos? További jellemzők:
25 Asszociációs szabályok


26 Alapfogalmak Asszoc. szabályok: elemhalmazok közötti asszociáció vagy korreláció o if LEFT then RIGHT Pl. Tx DB-k: sör + pelenka + fejfájáscsillapító Adatkeretre is működik Sokszor igaz Ritkán téved Nem véletlen support LEFT RIGHT = N BOTH N TOTAL confidence LEFT RIGHT = N BOTH N LEFT lift LEFT RIGHT = confidence(left RIGHT) N RIGHT 26
27 Alapfogalmak lift B 1 = 1.56 P({B;1}) P B; P({ ;1}) >1: többször fordulnak elő együtt, mint várható o ha pelenka, akkor többször sör <1: kevesebbszer fordulnak elő együtt, mint várható Lásd még: 27
28 Néhány megfontolás Potenciálisan rengeteg szabály Amit szeretnénk: elég magas confidence és support Redundanciák is lehetnek A legérdekesebbeket bányásszuk ki o Valamilyen érdekességi metrika alapján 28
29 Demo (Titanic, ismét) 29
30 Regresszió

31 f függvény, bemenet: az attribútumok értéke, kimenet: megfigyelések legjobb közelítése ökölszabály Példa: testtömeg/magasság együttes eloszlás valójában egyenesre illeszthető Regresszió
32 Regressziós módszerek Alapelv: Véletlen változó Közelítés t Y f t Hiba Jósolt esemény Átlagos hiba (mean error) Becsült érték Y f ( X, X,..., X ) 1 2 n ME n t 1 Y t n F t Megfigyelhető változók Mért érték
33 Lineáris regresszió Egyszerű lin. függvény illesztése az adatokra o nem vár alapvető változást a rendszer viselkedésében Y a bx Legkisebb négyzetek módszere o keressük azokat az a,b paramétereket, amelyekre n n 2 t t t t 1 t 1 minimális (Sum of Squared Errors) 2 SSE Y F cél: n n 2 2 Y F Y a bx minimalizálása t t t t t 1 t 1
34 Zárt alak: levezetés (parc. deriválás) n 2 d Y t a bx t n t 1 2 Yt a bx t 0 da n 2 t 1 t 1 d Y t a bx t n t 1 Xt Yt a bx t 0 db t 1 n na Y bx a Y bx t t t t t t t t t t t t t 1 n t 1 t 1 n t 1 t 1 n t 1 t 1 t n n X Y Y bx bx X Y X Y b X X b Xt 0 t 1 n n n n n n b n n n n X Y X Y t t t t t 1 t 1 t 1 n n 2 2 n Xt Xt t 1 t 1 Xi, Yi a mért értékpárok (pl. idő, terhelés)
35 Ismétlés: Anscombe négyese Legjobban illeszkedő egyenes mindenre van Minőségileg különböző adatpontokra is
36 Demo 36



37 Néhány tulajdonság 0-1; a várhatóérték körüli varabilitás mekkora részét magyarázza a modell (de: bias!) Kvantilisek: azonos valószínűségű intervallumokat adó vágáspontok (2-kvantilis: medián) 37




38 Néhány tulajdonság Tfh. A hiba ftlen, normál eloszlású, 0 várhatóértékű és konstans szórású. Szinte biztos, hogy ide esik az előrejelzés (ált. 95%) Szinte biztos, hogy a függő változó átlaga ide esik (ált. 95%) 38
 Mintakeresés (freq.")
39 Adatelemzés: legfontosabb problémák Idősorelemzés- és előrejelzés Anomália-detektálás (anomaly detection) Structured prediction Asszoc. szabályok (assoc. rules) Mintakeresés (freq. pattern mining) Osztályozás (classification) Csoportosítás (clustering) Regresszió (regression) Feature selection Dimensionality reduction Feature extraction Graph analysis 39
40 Principal Component Analysis Ortogonális transzformáció olyan ortogonális bázisra (lineárisan független változók; főkomponensek ), ahol o Az első komponens varianciája a lehető legnagyobb o Az i-edik varianciája a lehető legnagyobb úgy, hogy merőleges legyen az eddigiekre. Értelme: lehet, hogy összvarianciát leíró komponens jóval kevesebb lesz, mint változó Nem faktoranalízis; az látens változók által okozott közös varianciát keres o És ezzel felteszi egy mögöttes modell létezését o Az Exploratory Factor Analysis tartalmazhat PCA-szerű lépést 40
41 Principal Component Analysis Eltolás a várhatóértékbe + utána forgatás Skálaérzékeny, de lehet normalizálva is csinálni (pl. Z-score-ra) Ennek persze megint lehetnek nem kívánt hatásai Matematikáját nem tárgyaljuk 41
 + Az eredeti változók súlya ( loading ) az első két faktorban")
42 (Implicit) feltételezés: 2 komponens elégségesen leírja Biplot Komponensenkénti koordináták (score-ok) + Az eredeti változók súlya ( loading ) az első két faktorban 42 Demo

43 Gépi tanulás 43
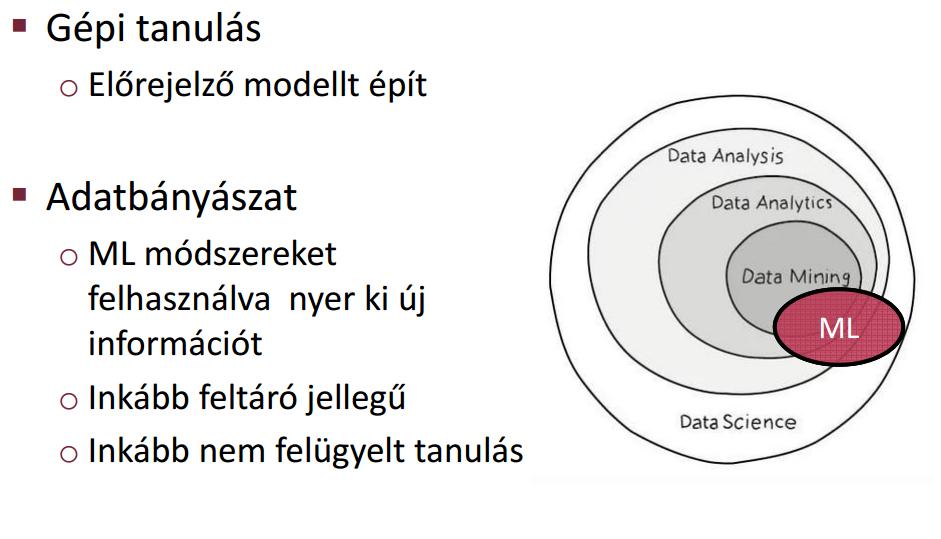
44 Adatbányászat 44

45 ML vs DM 45

46 ML alapú üzleti intelligencia alkalmazások 46
47 Machine Learning, Data Mining, statisztika Az eszközök és a DNS ugyanaz; különböző kultúrák Statisztika: (stochasztikus) adatmodellezés ML: informatikusok tanuló programot akartak DM: tudás kinyerése az adatokból (EDA...stat. Modellezés) Lásd [2][3] 47
48 Közel ugyanaz Lásd [4] 48
49 AUTOMATIZÁLT ADATELEMZÉS: IBM WATSON ANALYTICS 49
50 Automatizált adatelemzés IBM Watson Analytics Automatikus predikció 50



51 Automatizált adatelemzés IBM Watson Analytics Érdekes asszociációk automatikus feltárása Automatizált adatminőségértékelés 51
52 IRODALOM 52
53 Javasolt magyar nyelvű anyagok Helyenként nagyon mély, de kiváló tanulmány/jegyzet a Számításelméleti és Inf. Tud. Tanszékről: o Egyéb: o Dr. Abonyi János: Adatbányászat a hatékonyság eszköze o Iványi Antal: Informatikai Algoritmusok 2. kötet ( fejezetek), ELTE Eötvös Kiadó 53


54 További javasolt kezdőirodalom 54
55 Hivatkozások [1] Theus, M., Urbanek, S.: Interactive graphics for data analysis: principles and examples. CRC Press (2011) [2] [3] [4] 55
Adatbányászati szemelvények MapReduce környezetben
 Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Gépi tanulási (MachineLearning) módszerek alkalmazása
 módszerek alkalmazása") Gépi tanulási (MachineLearning) módszerek alkalmazása Hullám Gábor (hullam.gabor@ ) Salánki Ágnes, Kocsis Imre salanki@, ikocsis@ 2016.11.03. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika
Gépi tanulási (MachineLearning) módszerek alkalmazása Hullám Gábor (hullam.gabor@ ) Salánki Ágnes, Kocsis Imre salanki@, ikocsis@ 2016.11.03. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika
Klaszterezés, 2. rész
 Klaszterezés, 2. rész Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 208. április 6. Csima Judit Klaszterezés, 2. rész / 29 Hierarchikus klaszterezés egymásba ágyazott klasztereket
Klaszterezés, 2. rész Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 208. április 6. Csima Judit Klaszterezés, 2. rész / 29 Hierarchikus klaszterezés egymásba ágyazott klasztereket
The nontrivial extraction of implicit, previously unknown, and potentially useful information from data.
 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Adatelemzés intelligens módszerekkel Hullám Gábor Adatelemzés hagyományos megközelítésben I. Megválaszolandó
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Adatelemzés intelligens módszerekkel Hullám Gábor Adatelemzés hagyományos megközelítésben I. Megválaszolandó
Adatbányászati technikák (VISZM185) 2015 tavasz
 2015 tavasz") Adatbányászati technikák (VISZM185) 2015 tavasz Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2015. február 11. Csima Judit Adatbányászati technikák (VISZM185) 2015 tavasz 1 / 27
Adatbányászati technikák (VISZM185) 2015 tavasz Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2015. február 11. Csima Judit Adatbányászati technikák (VISZM185) 2015 tavasz 1 / 27
Biomatematika 12. Szent István Egyetem Állatorvos-tudományi Kar. Fodor János
 Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Diszkriminancia-analízis
 Diszkriminancia-analízis az SPSS-ben Petrovics Petra Doktorandusz Diszkriminancia-analízis folyamata Feladat Megnyitás: Employee_data.sav Milyen tényezőktől függ a dolgozók beosztása? Nem metrikus Független
Diszkriminancia-analízis az SPSS-ben Petrovics Petra Doktorandusz Diszkriminancia-analízis folyamata Feladat Megnyitás: Employee_data.sav Milyen tényezőktől függ a dolgozók beosztása? Nem metrikus Független
Minden az adatról. Csima Judit. 2015. február 11. BME, VIK, Csima Judit Minden az adatról 1 / 41
 Minden az adatról Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2015. február 11. Csima Judit Minden az adatról 1 / 41 Adat: alapfogalmak Adathalmaz elvileg bármi, ami információt
Minden az adatról Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2015. február 11. Csima Judit Minden az adatról 1 / 41 Adat: alapfogalmak Adathalmaz elvileg bármi, ami információt
Döntési fák. (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART ))
)") Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
Osztályozás, regresszió. Nagyméretű adathalmazok kezelése Tatai Márton
 Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
Közösség detektálás gráfokban
 Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
Principal Component Analysis
 Principal Component Analysis Principal Component Analysis Principal Component Analysis Definíció Ortogonális transzformáció, amely az adatokat egy új koordinátarendszerbe transzformálja úgy, hogy a koordináták
Principal Component Analysis Principal Component Analysis Principal Component Analysis Definíció Ortogonális transzformáció, amely az adatokat egy új koordinátarendszerbe transzformálja úgy, hogy a koordináták
Asszociációs szabályok
 Asszociációs szabályok Nikházy László Nagy adathalmazok kezelése 2010. március 10. Mi az értelme? A ö asszociációs szabály azt állítja, hogy azon vásárlói kosarak, amik tartalmaznak pelenkát, általában
Asszociációs szabályok Nikházy László Nagy adathalmazok kezelése 2010. március 10. Mi az értelme? A ö asszociációs szabály azt állítja, hogy azon vásárlói kosarak, amik tartalmaznak pelenkát, általában
Keresés képi jellemzők alapján. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Regresszió. Csorba János. Nagyméretű adathalmazok kezelése március 31.
 Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Számítógépes képelemzés 7. előadás. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl sok szelet se legyen.
 KEMOMETRIA VIII-1/27 /2013 ősz CART Classification and Regression Trees Osztályozó fák Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl
KEMOMETRIA VIII-1/27 /2013 ősz CART Classification and Regression Trees Osztályozó fák Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl
ELTE TáTK Közgazdaságtudományi Tanszék GAZDASÁGSTATISZTIKA. Készítette: Bíró Anikó. Szakmai felelős: Bíró Anikó június
 GAZDASÁGSTATISZTIKA GAZDASÁGSTATISZTIKA Készült a TÁMOP-4.1.2-08/2/A/KMR-2009-0041pályázati projekt keretében Tartalomfejlesztés az ELTE TátK Közgazdaságtudományi Tanszékén az ELTE Közgazdaságtudományi
GAZDASÁGSTATISZTIKA GAZDASÁGSTATISZTIKA Készült a TÁMOP-4.1.2-08/2/A/KMR-2009-0041pályázati projekt keretében Tartalomfejlesztés az ELTE TátK Közgazdaságtudományi Tanszékén az ELTE Közgazdaságtudományi
Miskolci Egyetem Gazdaságtudományi Kar Üzleti Információgazdálkodási és Módszertani Intézet Factor Analysis
 Factor Analysis Factor analysis is a multiple statistical method, which analyzes the correlation relation between data, and it is for data reduction, dimension reduction and to explore the structure. Aim
Factor Analysis Factor analysis is a multiple statistical method, which analyzes the correlation relation between data, and it is for data reduction, dimension reduction and to explore the structure. Aim
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
Nagyméretű adathalmazok kezelése (BMEVISZM144) Reinhardt Gábor április 5.
 Reinhardt Gábor április 5.") Asszociációs szabályok Budapesti Műszaki- és Gazdaságtudományi Egyetem 2012. április 5. Tartalom 1 2 3 4 5 6 7 ismétlés A feladat Gyakran együtt vásárolt termékek meghatározása Tanultunk rá hatékony algoritmusokat
Asszociációs szabályok Budapesti Műszaki- és Gazdaságtudományi Egyetem 2012. április 5. Tartalom 1 2 3 4 5 6 7 ismétlés A feladat Gyakran együtt vásárolt termékek meghatározása Tanultunk rá hatékony algoritmusokat
Geokémia gyakorlat. 1. Geokémiai adatok értelmezése: egyszerű statisztikai módszerek. Geológus szakirány (BSc) Dr. Lukács Réka
 Dr. Lukács Réka") Geokémia gyakorlat 1. Geokémiai adatok értelmezése: egyszerű statisztikai módszerek Geológus szakirány (BSc) Dr. Lukács Réka MTA-ELTE Vulkanológiai Kutatócsoport e-mail: reka.harangi@gmail.com ALAPFOGALMAK:
Geokémia gyakorlat 1. Geokémiai adatok értelmezése: egyszerű statisztikai módszerek Geológus szakirány (BSc) Dr. Lukács Réka MTA-ELTE Vulkanológiai Kutatócsoport e-mail: reka.harangi@gmail.com ALAPFOGALMAK:
Gépi tanulás a gyakorlatban. Kiértékelés és Klaszterezés
 Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Gépi tanulás a gyakorlatban. Bevezetés
 Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
Több valószínűségi változó együttes eloszlása, korreláció
 Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Regressziós vizsgálatok
 Regressziós vizsgálatok Regresszió (regression) Általános jelentése: visszaesés, hanyatlás, visszafelé mozgás, visszavezetés. Orvosi területen: visszafejlődés, involúció. A betegség tünetei, vagy maga
Regressziós vizsgálatok Regresszió (regression) Általános jelentése: visszaesés, hanyatlás, visszafelé mozgás, visszavezetés. Orvosi területen: visszafejlődés, involúció. A betegség tünetei, vagy maga
A többváltozós lineáris regresszió III. Főkomponens-analízis
 A többváltozós lineáris regresszió III. 6-7. előadás Nominális változók a lineáris modellben 2017. október 10-17. 6-7. előadás A többváltozós lineáris regresszió III., Alapok Többváltozós lineáris regresszió
A többváltozós lineáris regresszió III. 6-7. előadás Nominális változók a lineáris modellben 2017. október 10-17. 6-7. előadás A többváltozós lineáris regresszió III., Alapok Többváltozós lineáris regresszió
Modellek paraméterezése: regresszió, benchmarkok
 Modellek paraméterezése: regresszió, benchmarkok Rendszermodellezés 2017. Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and Economics
Modellek paraméterezése: regresszió, benchmarkok Rendszermodellezés 2017. Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and Economics
Többváltozós lineáris regresszió 3.
 Többváltozós lineáris regresszió 3. Orlovits Zsanett 2018. október 10. Alapok Kérdés: hogyan szerepeltethetünk egy minőségi (nominális) tulajdonságot (pl. férfi/nő, egészséges/beteg, szezonális hatások,
Többváltozós lineáris regresszió 3. Orlovits Zsanett 2018. október 10. Alapok Kérdés: hogyan szerepeltethetünk egy minőségi (nominális) tulajdonságot (pl. férfi/nő, egészséges/beteg, szezonális hatások,
Lineáris regressziós modellek 1
 Lineáris regressziós modellek 1 Ispány Márton és Jeszenszky Péter 2016. szeptember 19. 1 Az ábrák C.M. Bishop: Pattern Recognition and Machine Learning c. könyvéből származnak. Tartalom Bevezető példák
Lineáris regressziós modellek 1 Ispány Márton és Jeszenszky Péter 2016. szeptember 19. 1 Az ábrák C.M. Bishop: Pattern Recognition and Machine Learning c. könyvéből származnak. Tartalom Bevezető példák
Sztochasztikus kapcsolatok
 Sztochasztikus kapcsolatok Petrovics Petra PhD Hallgató Ismérvek közötti kapcsolat (1) Függvényszerű az egyik ismérv szerinti hovatartozás egyértelműen meghatározza a másik ismérv szerinti hovatartozást.
Sztochasztikus kapcsolatok Petrovics Petra PhD Hallgató Ismérvek közötti kapcsolat (1) Függvényszerű az egyik ismérv szerinti hovatartozás egyértelműen meghatározza a másik ismérv szerinti hovatartozást.
Egyenlőtlenségi mérőszámok alkalmazása az adatbányászatban. Hajdu Ottó BCE: Statisztika Tanszék BME: Pénzügyek tanszék Budapest, 2011
 Egyenlőtlenségi mérőszámok alkalmazása az adatbányászatban Hajdu Ottó BCE: Statisztika Tanszék BME: Pénzügyek tanszék Budapest, 2011 Adatbányászati feladatok 1. Ismert mintákon, példákon való tanulás (extracting
Egyenlőtlenségi mérőszámok alkalmazása az adatbányászatban Hajdu Ottó BCE: Statisztika Tanszék BME: Pénzügyek tanszék Budapest, 2011 Adatbányászati feladatok 1. Ismert mintákon, példákon való tanulás (extracting
Cluster Analysis. Potyó László
 Cluster Analysis Potyó László What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis
Cluster Analysis Potyó László What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis
PONTFELHŐ REGISZTRÁCIÓ
 PONTFELHŐ REGISZTRÁCIÓ ITERATIVE CLOSEST POINT Cserteg Tamás, URLGNI, 2018.11.22. TARTALOM Röviden Alakzatrekonstrukció áttekintés ICP algoritmusok Projektfeladat Demó FORRÁSOK Cikkek Efficient Variants
PONTFELHŐ REGISZTRÁCIÓ ITERATIVE CLOSEST POINT Cserteg Tamás, URLGNI, 2018.11.22. TARTALOM Röviden Alakzatrekonstrukció áttekintés ICP algoritmusok Projektfeladat Demó FORRÁSOK Cikkek Efficient Variants
Adatelemzés és adatbányászat MSc
 Adatelemzés és adatbányászat MSc 12. téma Klaszterezési módszerek Klaszterezés célja Adott az objektumok, tulajdonságaik együttese. Az objektumok között hasonlóságot és különbözőséget fedezhetünk fel.
Adatelemzés és adatbányászat MSc 12. téma Klaszterezési módszerek Klaszterezés célja Adott az objektumok, tulajdonságaik együttese. Az objektumok között hasonlóságot és különbözőséget fedezhetünk fel.
Miskolci Egyetem Gazdaságtudományi Kar Üzleti Információgazdálkodási és Módszertani Intézet Nonparametric Tests
 Nonparametric Tests Petra Petrovics Hypothesis Testing Parametric Tests Mean of a population Population proportion Population Standard Deviation Nonparametric Tests Test for Independence Analysis of Variance
Nonparametric Tests Petra Petrovics Hypothesis Testing Parametric Tests Mean of a population Population proportion Population Standard Deviation Nonparametric Tests Test for Independence Analysis of Variance
end function Az A vektorban elõforduló legnagyobb és legkisebb értékek indexeinek különbségét.. (1.5 pont) Ha üres a vektor, akkor 0-t..
 Ha üres a vektor, akkor 0-t..") A Név: l 2014.04.09 Neptun kód: Gyakorlat vezető: HG BP MN l 1. Adott egy (12 nem nulla értékû elemmel rendelkezõ) 6x7 méretû ritka mátrix hiányos 4+2 soros reprezentációja. SOR: 1 1 2 2 2 3 3 4 4 5 6
A Név: l 2014.04.09 Neptun kód: Gyakorlat vezető: HG BP MN l 1. Adott egy (12 nem nulla értékû elemmel rendelkezõ) 6x7 méretû ritka mátrix hiányos 4+2 soros reprezentációja. SOR: 1 1 2 2 2 3 3 4 4 5 6
Logisztikus regresszió
 Logisztikus regresszió 9. előadás Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó () Nem metrikus Metrikus Kereszttábla
Logisztikus regresszió 9. előadás Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó () Nem metrikus Metrikus Kereszttábla
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017.
 Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Gyakorló feladatok adatbányászati technikák tantárgyhoz
 Gyakorló feladatok adatbányászati technikák tantárgyhoz Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Klaszterezés kiértékelése Feladat:
Gyakorló feladatok adatbányászati technikák tantárgyhoz Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Klaszterezés kiértékelése Feladat:
7. Régió alapú szegmentálás
 Digitális képek szegmentálása 7. Régió alapú szegmentálás Kató Zoltán http://www.cab.u-szeged.hu/~kato/segmentation/ Szegmentálási kritériumok Particionáljuk a képet az alábbi kritériumokat kielégítő régiókba
Digitális képek szegmentálása 7. Régió alapú szegmentálás Kató Zoltán http://www.cab.u-szeged.hu/~kato/segmentation/ Szegmentálási kritériumok Particionáljuk a képet az alábbi kritériumokat kielégítő régiókba
Searching in an Unsorted Database
 Searching in an Unsorted Database "Man - a being in search of meaning." Plato History of data base searching v1 2018.04.20. 2 History of data base searching v2 2018.04.20. 3 History of data base searching
Searching in an Unsorted Database "Man - a being in search of meaning." Plato History of data base searching v1 2018.04.20. 2 History of data base searching v2 2018.04.20. 3 History of data base searching
IBM SPSS Modeler 18.2 Újdonságok
 IBM SPSS Modeler 18.2 Újdonságok 1 2 Új, modern megjelenés Vizualizáció fejlesztése Újabb algoritmusok (Python, Spark alapú) View Data, t-sne, e-plot GMM, HDBSCAN, KDE, Isotonic-Regression 3 Új, modern
IBM SPSS Modeler 18.2 Újdonságok 1 2 Új, modern megjelenés Vizualizáció fejlesztése Újabb algoritmusok (Python, Spark alapú) View Data, t-sne, e-plot GMM, HDBSCAN, KDE, Isotonic-Regression 3 Új, modern
KISTERV2_ANOVA_
 Két faktor szerinti ANOVA Az A faktor minden szintjét kombináljuk a B faktor minden szintjével, minden cellában azonos számú ismétlés (kiegyensúlyozott terv). A terv szerkezete miatt a faktorok hatását
Két faktor szerinti ANOVA Az A faktor minden szintjét kombináljuk a B faktor minden szintjével, minden cellában azonos számú ismétlés (kiegyensúlyozott terv). A terv szerkezete miatt a faktorok hatását
Biometria az orvosi gyakorlatban. Korrelációszámítás, regresszió
 SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
Korreláció és lineáris regresszió
 Korreláció és lineáris regresszió Két folytonos változó közötti összefüggés vizsgálata Szűcs Mónika SZTE ÁOK-TTIK Orvosi Fizikai és Orvosi Informatikai Intézet Orvosi Fizika és Statisztika I. előadás 2016.11.02.
Korreláció és lineáris regresszió Két folytonos változó közötti összefüggés vizsgálata Szűcs Mónika SZTE ÁOK-TTIK Orvosi Fizikai és Orvosi Informatikai Intézet Orvosi Fizika és Statisztika I. előadás 2016.11.02.
Statisztika I. 12. előadás. Előadó: Dr. Ertsey Imre
 Statisztika I. 1. előadás Előadó: Dr. Ertsey Imre Regresszió analízis A korrelációs együttható megmutatja a kapcsolat irányát és szorosságát. A kapcsolat vizsgálata során a gyakorlatban ennél messzebb
Statisztika I. 1. előadás Előadó: Dr. Ertsey Imre Regresszió analízis A korrelációs együttható megmutatja a kapcsolat irányát és szorosságát. A kapcsolat vizsgálata során a gyakorlatban ennél messzebb
Irányításelmélet és technika II.
 Irányításelmélet és technika II. Legkisebb négyzetek módszere Magyar Attila Pannon Egyetem Műszaki Informatikai Kar Villamosmérnöki és Információs Rendszerek Tanszék amagyar@almos.vein.hu 200 november
Irányításelmélet és technika II. Legkisebb négyzetek módszere Magyar Attila Pannon Egyetem Műszaki Informatikai Kar Villamosmérnöki és Információs Rendszerek Tanszék amagyar@almos.vein.hu 200 november
Tanulás az idegrendszerben. Structure Dynamics Implementation Algorithm Computation - Function
 Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Feltesszük, hogy a mintaelemek között nincs két azonos. ha X n a rendezett mintában az R n -ik. ha n 1 n 2
 Kabos: Ordinális változók Hipotézisvizsgálat-1 Minta: X 1, X 2,..., X N EVM (=egyszerű véletlen minta) X-re Feltesszük, hogy a mintaelemek között nincs két azonos. Rendezett minta: X (1), X (2),..., X
Kabos: Ordinális változók Hipotézisvizsgálat-1 Minta: X 1, X 2,..., X N EVM (=egyszerű véletlen minta) X-re Feltesszük, hogy a mintaelemek között nincs két azonos. Rendezett minta: X (1), X (2),..., X
Izgalmas újdonságok a klaszteranalízisben
 Izgalmas újdonságok a klaszteranalízisben Vargha András KRE és ELTE, Pszichológiai Intézet Vargha András KRE és ELTE, Pszichológiai Intézet Mi a klaszteranalízis (KLA)? Keressük a személyek (vagy bármilyen
Izgalmas újdonságok a klaszteranalízisben Vargha András KRE és ELTE, Pszichológiai Intézet Vargha András KRE és ELTE, Pszichológiai Intézet Mi a klaszteranalízis (KLA)? Keressük a személyek (vagy bármilyen
Többváltozós lineáris regressziós modell feltételeinek
 Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Petrovics Petra Doktorandusz Többváltozós lineáris regressziós modell x 1, x 2,, x p
Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Petrovics Petra Doktorandusz Többváltozós lineáris regressziós modell x 1, x 2,, x p
BIOMETRIA_ANOVA_2 1 1
 Két faktor szerinti ANOVA Az A faktor minden szintjét kombináljuk a B faktor minden szintjével, minden cellában azonos számú ismétlés (kiegyensúlyozott terv). A terv szerkezete miatt a faktorok hatását
Két faktor szerinti ANOVA Az A faktor minden szintjét kombináljuk a B faktor minden szintjével, minden cellában azonos számú ismétlés (kiegyensúlyozott terv). A terv szerkezete miatt a faktorok hatását
Ambiens szabályozás problémája Kontroll és tanulás-1
 Ambiens szabályozás problémája Kontroll és tanulás-1 Ambiens (fizikai) tér Ambiens Intelligencia szenzorok beavatkozók Ágens szervezet AmI - megfigyelés, elemzés - tervezés, megtanulás AmI - statikus -
Ambiens szabályozás problémája Kontroll és tanulás-1 Ambiens (fizikai) tér Ambiens Intelligencia szenzorok beavatkozók Ágens szervezet AmI - megfigyelés, elemzés - tervezés, megtanulás AmI - statikus -
Anyagvizsgálati módszerek Mérési adatok feldolgozása. Anyagvizsgálati módszerek
 Anyagvizsgálati módszerek Mérési adatok feldolgozása Anyagvizsgálati módszerek Pannon Egyetem Mérnöki Kar Anyagvizsgálati módszerek Statisztika 1/ 22 Mérési eredmények felhasználása Tulajdonságok hierarchikus
Anyagvizsgálati módszerek Mérési adatok feldolgozása Anyagvizsgálati módszerek Pannon Egyetem Mérnöki Kar Anyagvizsgálati módszerek Statisztika 1/ 22 Mérési eredmények felhasználása Tulajdonságok hierarchikus
Többváltozós lineáris regressziós modell feltételeinek tesztelése I.
 Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Kvantitatív statisztikai módszerek Petrovics Petra Többváltozós lineáris regressziós
Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Kvantitatív statisztikai módszerek Petrovics Petra Többváltozós lineáris regressziós
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék. Neurális hálók. Pataki Béla
 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók Előadó: Előadás anyaga: Hullám Gábor Pataki Béla Dobrowiecki Tadeusz BME I.E. 414, 463-26-79
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók Előadó: Előadás anyaga: Hullám Gábor Pataki Béla Dobrowiecki Tadeusz BME I.E. 414, 463-26-79
Intelligens adatelemzés
 Antal Péter, Antos András, Horváth Gábor, Hullám Gábor, Kocsis Imre, Marx Péter, Millinghoffer András, Pataricza András, Salánki Ágnes Intelligens adatelemzés Szerkesztette: Antal Péter A jegyzetben az
Antal Péter, Antos András, Horváth Gábor, Hullám Gábor, Kocsis Imre, Marx Péter, Millinghoffer András, Pataricza András, Salánki Ágnes Intelligens adatelemzés Szerkesztette: Antal Péter A jegyzetben az
ADATBÁNYÁSZAT AZ AUTÓIPARI TERMÉKEK FEJLESZTÉSÉBEN
 ADATBÁNYÁSZAT AZ AUTÓIPARI TERMÉKEK FEJLESZTÉSÉBEN Zámborszky Judit 2019.05.14. Adatbányászat az autóipari termékek fejlesztésében Industry 4.0 Ipar 4.0 Ipari forradalmak: 1.: Gépek használata (gőzgép)
ADATBÁNYÁSZAT AZ AUTÓIPARI TERMÉKEK FEJLESZTÉSÉBEN Zámborszky Judit 2019.05.14. Adatbányászat az autóipari termékek fejlesztésében Industry 4.0 Ipar 4.0 Ipari forradalmak: 1.: Gépek használata (gőzgép)
Két diszkrét változó függetlenségének vizsgálata, illeszkedésvizsgálat
 Két diszkrét változó függetlenségének vizsgálata, illeszkedésvizsgálat Szűcs Mónika SZTE ÁOK-TTIK Orvosi Fizikai és Orvosi Informatikai Intézet Orvosi fizika és statisztika I. előadás 2016.11.09 Orvosi
Két diszkrét változó függetlenségének vizsgálata, illeszkedésvizsgálat Szűcs Mónika SZTE ÁOK-TTIK Orvosi Fizikai és Orvosi Informatikai Intézet Orvosi fizika és statisztika I. előadás 2016.11.09 Orvosi
Leíró és matematikai statisztika el adásnapló Matematika alapszak, matematikai elemz szakirány 2016/2017. tavaszi félév
 Leíró és matematikai statisztika el adásnapló Matematika alapszak, matematikai elemz szakirány 2016/2017. tavaszi félév A pirossal írt anyagrészeket nem fogom közvetlenül számon kérni a vizsgán, azok háttérismeretként,
Leíró és matematikai statisztika el adásnapló Matematika alapszak, matematikai elemz szakirány 2016/2017. tavaszi félév A pirossal írt anyagrészeket nem fogom közvetlenül számon kérni a vizsgán, azok háttérismeretként,
Adatbányászat: Klaszterezés Haladó fogalmak és algoritmusok
 Adatbányászat: Klaszterezés Haladó fogalmak és algoritmusok 9. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Logók és támogatás A tananyag a TÁMOP-4.1.2-08/1/A-2009-0046
Adatbányászat: Klaszterezés Haladó fogalmak és algoritmusok 9. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Logók és támogatás A tananyag a TÁMOP-4.1.2-08/1/A-2009-0046
Random Forests - Véletlen erdők
 Random Forests - Véletlen erdők Szabó Adrienn Adatbányászat és Webes Keresés Kutatócsoport 2010 Tartalom Fő forrás: Leo Breiman: Random Forests Machine Learning, 45, 5-32, 2001 Alapok Döntési fa Véletlen
Random Forests - Véletlen erdők Szabó Adrienn Adatbányászat és Webes Keresés Kutatócsoport 2010 Tartalom Fő forrás: Leo Breiman: Random Forests Machine Learning, 45, 5-32, 2001 Alapok Döntési fa Véletlen
Miskolci Egyetem Gazdaságtudományi Kar Üzleti Információgazdálkodási és Módszertani Intézet. Nonparametric Tests. Petra Petrovics.
 Nonparametric Tests Petra Petrovics PhD Student Hypothesis Testing Parametric Tests Mean o a population Population proportion Population Standard Deviation Nonparametric Tests Test or Independence Analysis
Nonparametric Tests Petra Petrovics PhD Student Hypothesis Testing Parametric Tests Mean o a population Population proportion Population Standard Deviation Nonparametric Tests Test or Independence Analysis
Matematikai statisztika c. tárgy oktatásának célja és tematikája
 Matematikai statisztika c. tárgy oktatásának célja és tematikája 2015 Tematika Matematikai statisztika 1. Időkeret: 12 héten keresztül heti 3x50 perc (előadás és szeminárium) 2. Szükséges előismeretek:
Matematikai statisztika c. tárgy oktatásának célja és tematikája 2015 Tematika Matematikai statisztika 1. Időkeret: 12 héten keresztül heti 3x50 perc (előadás és szeminárium) 2. Szükséges előismeretek:
Bevezetés a Korreláció &
 Bevezetés a Korreláció & Regressziószámításba Petrovics Petra Doktorandusz Statisztikai kapcsolatok Asszociáció 2 minőségi/területi ismérv között Vegyes kapcsolat minőségi/területi és egy mennyiségi ismérv
Bevezetés a Korreláció & Regressziószámításba Petrovics Petra Doktorandusz Statisztikai kapcsolatok Asszociáció 2 minőségi/területi ismérv között Vegyes kapcsolat minőségi/területi és egy mennyiségi ismérv
Correlation & Linear Regression in SPSS
 Petra Petrovics Correlation & Linear Regression in SPSS 4 th seminar Types of dependence association between two nominal data mixed between a nominal and a ratio data correlation among ratio data Correlation
Petra Petrovics Correlation & Linear Regression in SPSS 4 th seminar Types of dependence association between two nominal data mixed between a nominal and a ratio data correlation among ratio data Correlation
MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR
 MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Korszerű információs technológiák Klaszteranalízis Tompa Tamás tanársegéd Általános Informatikai Intézeti Tanszék Miskolc, 2018. október 20. Tartalom
MISKOLCI EGYETEM GÉPÉSZMÉRNÖKI ÉS INFORMATIKAI KAR Korszerű információs technológiák Klaszteranalízis Tompa Tamás tanársegéd Általános Informatikai Intézeti Tanszék Miskolc, 2018. október 20. Tartalom
Logisztikus regresszió
 Logisztikus regresszió Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó (x) Nem metrikus Metrikus Kereszttábla elemzés
Logisztikus regresszió Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó (x) Nem metrikus Metrikus Kereszttábla elemzés
Statisztikai eljárások a mintafelismerésben és a gépi tanulásban
 Statisztikai eljárások a mintafelismerésben és a gépi tanulásban Varga Domonkos (I.évf. PhD hallgató) 2014 május A prezentáció felépítése 1) Alapfogalmak 2) A gépi tanulás, mintafelismerés alkalmazási
Statisztikai eljárások a mintafelismerésben és a gépi tanulásban Varga Domonkos (I.évf. PhD hallgató) 2014 május A prezentáció felépítése 1) Alapfogalmak 2) A gépi tanulás, mintafelismerés alkalmazási
Alap-ötlet: Karl Friedrich Gauss ( ) valószínűségszámítási háttér: Andrej Markov ( )
 valószínűségszámítási háttér: Andrej Markov ( )") Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
(Independence, dependence, random variables)
") Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
Mesterséges Intelligencia. Csató Lehel. Csató Lehel. Matematika-Informatika Tanszék Babeş Bolyai Tudományegyetem, Kolozsvár 2010/2011 1/363
 1/363 Matematika-Informatika Tanszék Babeş Bolyai Tudományegyetem, Kolozsvár 20/2011 Az Előadások Témái 226/363 Bevezető: mi a mesterséges intelligencia... Tudás reprezentáció Gráfkeresési stratégiák Szemantikus
1/363 Matematika-Informatika Tanszék Babeş Bolyai Tudományegyetem, Kolozsvár 20/2011 Az Előadások Témái 226/363 Bevezető: mi a mesterséges intelligencia... Tudás reprezentáció Gráfkeresési stratégiák Szemantikus
LOGIT-REGRESSZIÓ a függő változó: névleges vagy sorrendi skála
 LOGIT-REGRESSZIÓ a függő változó: névleges vagy sorrendi skála a független változó: névleges vagy sorrendi vagy folytonos skála BIOMETRIA2_NEMPARAMÉTERES_5 1 Y: visszafizeti-e a hitelt x: fizetés (életkor)
LOGIT-REGRESSZIÓ a függő változó: névleges vagy sorrendi skála a független változó: névleges vagy sorrendi vagy folytonos skála BIOMETRIA2_NEMPARAMÉTERES_5 1 Y: visszafizeti-e a hitelt x: fizetés (életkor)
Probabilisztikus funkcionális modellek idegrendszeri adatok elemzésére
 Probabilisztikus funkcionális modellek idegrendszeri adatok elemzésére Bányai Mihály! MTA Wigner FK! Computational Systems Neuroscience Lab!! KOKI-VIK szeminárium! 2014. február 11. Struktúra és funkció
Probabilisztikus funkcionális modellek idegrendszeri adatok elemzésére Bányai Mihály! MTA Wigner FK! Computational Systems Neuroscience Lab!! KOKI-VIK szeminárium! 2014. február 11. Struktúra és funkció
Mérési adatok illesztése, korreláció, regresszió
 Mérési adatok illesztése, korreláció, regresszió Korreláció, regresszió Két változó mennyiség közötti kapcsolatot vizsgálunk. Kérdés: van-e kapcsolat két, ugyanabban az egyénben, állatban, kísérleti mintában,
Mérési adatok illesztése, korreláció, regresszió Korreláció, regresszió Két változó mennyiség közötti kapcsolatot vizsgálunk. Kérdés: van-e kapcsolat két, ugyanabban az egyénben, állatban, kísérleti mintában,
Szomszédság alapú ajánló rendszerek
 Nagyméretű adathalmazok kezelése Szomszédság alapú ajánló rendszerek Készítette: Szabó Máté A rendelkezésre álló adatmennyiség növelésével egyre nehezebb kiválogatni a hasznos információkat Megoldás: ajánló
Nagyméretű adathalmazok kezelése Szomszédság alapú ajánló rendszerek Készítette: Szabó Máté A rendelkezésre álló adatmennyiség növelésével egyre nehezebb kiválogatni a hasznos információkat Megoldás: ajánló
Visszacsatolt (mély) neurális hálózatok
 neurális hálózatok") Visszacsatolt (mély) neurális hálózatok Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Sima előrecsatolt neurális hálózat Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Pl.: kép feliratozás,
Visszacsatolt (mély) neurális hálózatok Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Sima előrecsatolt neurális hálózat Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Pl.: kép feliratozás,
Nagy méretű adathalmazok vizualizációja
 Nagy méretű adathalmazok vizualizációja Big Data elemzési módszerek Kocsis Imre, Salánki Ágnes ikocsis, salanki@mit.bme.hu 2014.10.15. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs
Nagy méretű adathalmazok vizualizációja Big Data elemzési módszerek Kocsis Imre, Salánki Ágnes ikocsis, salanki@mit.bme.hu 2014.10.15. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs
Strukturált Generátorrendszerek Online Tanulása és Alk-ai
 Strukturált Generátorrendszerek Online Tanulása és Alkalmazásai Problémamegoldó Szeminárium 2010. nov. 5 Tartalomjegyzék Motiváció, példák Regressziós feladatok (generátorrendszer fix) Legkisebb négyzetes
Strukturált Generátorrendszerek Online Tanulása és Alkalmazásai Problémamegoldó Szeminárium 2010. nov. 5 Tartalomjegyzék Motiváció, példák Regressziós feladatok (generátorrendszer fix) Legkisebb négyzetes
KÖZELÍTŐ INFERENCIA II.
 STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
Társadalmi és gazdasági hálózatok modellezése
 Társadalmi és gazdasági hálózatok modellezése 5. el adás Közösségszerkezet El adó: London András 2017. október 16. Közösségek hálózatban Homofília, asszortatívitás Newman modularitás Közösségek hálózatban
Társadalmi és gazdasági hálózatok modellezése 5. el adás Közösségszerkezet El adó: London András 2017. október 16. Közösségek hálózatban Homofília, asszortatívitás Newman modularitás Közösségek hálózatban
Problémás regressziók
 Universitas Eotvos Nominata 74 203-4 - II Problémás regressziók A közönséges (OLS) és a súlyozott (WLS) legkisebb négyzetes lineáris regresszió egy p- változós lineáris egyenletrendszer megoldása. Az egyenletrendszer
Universitas Eotvos Nominata 74 203-4 - II Problémás regressziók A közönséges (OLS) és a súlyozott (WLS) legkisebb négyzetes lineáris regresszió egy p- változós lineáris egyenletrendszer megoldása. Az egyenletrendszer
Faktoranalízis az SPSS-ben
 Faktoranalízis az SPSS-ben Kvantitatív statisztikai módszerek Petrovics Petra Feladat Megnyitás: faktor.sav Fogyasztók materialista vonásai (Richins-skála) Forrás: Sajtos-Mitev, 250.oldal Faktoranalízis
Faktoranalízis az SPSS-ben Kvantitatív statisztikai módszerek Petrovics Petra Feladat Megnyitás: faktor.sav Fogyasztók materialista vonásai (Richins-skála) Forrás: Sajtos-Mitev, 250.oldal Faktoranalízis
Statistical Dependence
 Statistical Dependence Petra Petrovics Statistical Dependence Deinition: Statistical dependence exists when the value o some variable is dependent upon or aected by the value o some other variable. Independent
Statistical Dependence Petra Petrovics Statistical Dependence Deinition: Statistical dependence exists when the value o some variable is dependent upon or aected by the value o some other variable. Independent
Faktoranalízis az SPSS-ben
 Faktoranalízis az SPSS-ben = Adatredukciós módszer Petrovics Petra Doktorandusz Feladat Megnyitás: faktoradat_msc.sav Forrás: Sajtos-Mitev 250.oldal Fogyasztók materialista vonásai (Richins-skála) Faktoranalízis
Faktoranalízis az SPSS-ben = Adatredukciós módszer Petrovics Petra Doktorandusz Feladat Megnyitás: faktoradat_msc.sav Forrás: Sajtos-Mitev 250.oldal Fogyasztók materialista vonásai (Richins-skála) Faktoranalízis
GEOSTATISZTIKA. Földtudományi mérnöki MSc, geofizikus-mérnöki szakirány. 2018/2019 I. félév TANTÁRGYI KOMMUNIKÁCIÓS DOSSZIÉ
 GEOSTATISZTIKA Földtudományi mérnöki MSc, geofizikus-mérnöki szakirány 2018/2019 I. félév TANTÁRGYI KOMMUNIKÁCIÓS DOSSZIÉ Miskolci Egyetem Műszaki Földtudományi Kar Geofizikai és Térinformatikai Intézet
GEOSTATISZTIKA Földtudományi mérnöki MSc, geofizikus-mérnöki szakirány 2018/2019 I. félév TANTÁRGYI KOMMUNIKÁCIÓS DOSSZIÉ Miskolci Egyetem Műszaki Földtudományi Kar Geofizikai és Térinformatikai Intézet
Klaszterezés. Kovács Máté március 22. BME. Kovács Máté (BME) Klaszterezés március / 37
 Klaszterezés március / 37") Klaszterezés Kovács Máté BME 2012. március 22. Kovács Máté (BME) Klaszterezés 2012. március 22. 1 / 37 Mi a klaszterezés? Intuitív meghatározás Adott dolgokból halmazokat klasztereket alakítunk ki úgy,
Klaszterezés Kovács Máté BME 2012. március 22. Kovács Máté (BME) Klaszterezés 2012. március 22. 1 / 37 Mi a klaszterezés? Intuitív meghatározás Adott dolgokból halmazokat klasztereket alakítunk ki úgy,
Standardizálás, transzformációk
 Standardizálás, transzformációk A transzformációk ugynúgy mennek, mint egyváltozós esetben. Itt még fontosabbak a linearitás miatt. Standardizálás átskálázás. Centrálás: kivonjuk minden változó átlagát,
Standardizálás, transzformációk A transzformációk ugynúgy mennek, mint egyváltozós esetben. Itt még fontosabbak a linearitás miatt. Standardizálás átskálázás. Centrálás: kivonjuk minden változó átlagát,
Példák jellemzőkre: - minden pixelérték egy jellemző pl. neurális hálózat esetében csak kis képekre, nem invariáns sem a megvilágításra, sem a geom.
 Lépések 1. tanító és teszt halmaz összeállítása / megszerzése 2. jellemzők kinyerése 3. tanító eljárás választása Sok vagy kevés adat áll-e rendelkezésünkre? Mennyi tanítási idő/memória áll rendelkezésre?
Lépések 1. tanító és teszt halmaz összeállítása / megszerzése 2. jellemzők kinyerése 3. tanító eljárás választása Sok vagy kevés adat áll-e rendelkezésünkre? Mennyi tanítási idő/memória áll rendelkezésre?
4/24/12. Regresszióanalízis. Legkisebb négyzetek elve. Regresszióanalízis
 1. feladat Regresszióanalízis. Legkisebb négyzetek elve 2. feladat Az iskola egy évfolyamába tartozó diákok átlagéletkora 15,8 év, standard deviációja 0,6 év. A 625 fős évfolyamból hány diák fiatalabb
1. feladat Regresszióanalízis. Legkisebb négyzetek elve 2. feladat Az iskola egy évfolyamába tartozó diákok átlagéletkora 15,8 év, standard deviációja 0,6 év. A 625 fős évfolyamból hány diák fiatalabb
2013 ŐSZ. 1. Mutassa be az egymintás z-próba célját, alkalmazásának feltételeit és módszerét!
 GAZDASÁGSTATISZTIKA KIDOLGOZOTT ELMÉLETI KÉRDÉSEK A 3. ZH-HOZ 2013 ŐSZ Elméleti kérdések összegzése 1. Mutassa be az egymintás z-próba célját, alkalmazásának feltételeit és módszerét! 2. Mutassa be az
GAZDASÁGSTATISZTIKA KIDOLGOZOTT ELMÉLETI KÉRDÉSEK A 3. ZH-HOZ 2013 ŐSZ Elméleti kérdések összegzése 1. Mutassa be az egymintás z-próba célját, alkalmazásának feltételeit és módszerét! 2. Mutassa be az
Pletykaalapú gépi tanulás teljesen elosztott környezetben
 Pletykaalapú gépi tanulás teljesen elosztott környezetben Hegedűs István Jelasity Márk témavezető Szegedi Tudományegyetem MTA-SZTE Mesterséges Intelligencia Kutatócsopot Motiváció Az adat adatközpontokban
Pletykaalapú gépi tanulás teljesen elosztott környezetben Hegedűs István Jelasity Márk témavezető Szegedi Tudományegyetem MTA-SZTE Mesterséges Intelligencia Kutatócsopot Motiváció Az adat adatközpontokban
Általánosan, bármilyen mérés annyit jelent, mint meghatározni, hányszor van meg
 LMeasurement.tex, March, 00 Mérés Általánosan, bármilyen mérés annyit jelent, mint meghatározni, hányszor van meg a mérendő mennyiségben egy másik, a mérendővel egynemű, önkényesen egységnek választott
LMeasurement.tex, March, 00 Mérés Általánosan, bármilyen mérés annyit jelent, mint meghatározni, hányszor van meg a mérendő mennyiségben egy másik, a mérendővel egynemű, önkényesen egységnek választott
Számítógépes döntéstámogatás. Genetikus algoritmusok
 BLSZM-10 p. 1/18 Számítógépes döntéstámogatás Genetikus algoritmusok Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu BLSZM-10 p. 2/18 Bevezetés 1950-60-as
BLSZM-10 p. 1/18 Számítógépes döntéstámogatás Genetikus algoritmusok Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu BLSZM-10 p. 2/18 Bevezetés 1950-60-as
Standardizálás, transzformációk
 Standardizálás, transzformációk A transzformációk ugynúgy mennek, mint egyváltozós esetben. Itt még fontosabbak a linearitás miatt. Standardizálás átskálázás. Centrálás: kivonjuk minden változó átlagát,
Standardizálás, transzformációk A transzformációk ugynúgy mennek, mint egyváltozós esetben. Itt még fontosabbak a linearitás miatt. Standardizálás átskálázás. Centrálás: kivonjuk minden változó átlagát,
A preferencia térképezés kritikus pontjai az élelmiszeripari termékfejlesztésben
 A preferencia térképezés kritikus pontjai az élelmiszeripari termékfejlesztésben Gere A., Losó, V., Györey, A., Szabó, D., Sipos, L., Kókai, Z. Budapesti Corvinus Egyetem, Élelmiszertudományi Kar Érzékszervi
A preferencia térképezés kritikus pontjai az élelmiszeripari termékfejlesztésben Gere A., Losó, V., Györey, A., Szabó, D., Sipos, L., Kókai, Z. Budapesti Corvinus Egyetem, Élelmiszertudományi Kar Érzékszervi
GEOSTATISZTIKA II. Geográfus MSc szak. 2019/2020 I. félév TANTÁRGYI KOMMUNIKÁCIÓS DOSSZIÉ
 GEOSTATISZTIKA II. Geográfus MSc szak 2019/2020 I. félév TANTÁRGYI KOMMUNIKÁCIÓS DOSSZIÉ Miskolci Egyetem Műszaki Földtudományi Kar Geofizikai és Térinformatikai Intézet A tantárgy adatlapja Tantárgy neve:
GEOSTATISZTIKA II. Geográfus MSc szak 2019/2020 I. félév TANTÁRGYI KOMMUNIKÁCIÓS DOSSZIÉ Miskolci Egyetem Műszaki Földtudományi Kar Geofizikai és Térinformatikai Intézet A tantárgy adatlapja Tantárgy neve:
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
Adatok statisztikai értékelésének főbb lehetőségei
 Adatok statisztikai értékelésének főbb lehetőségei 1. a. Egy- vagy kétváltozós eset b. Többváltozós eset 2. a. Becslési problémák, hipotézis vizsgálat b. Mintázatelemzés 3. Szint: a. Egyedi b. Populáció
Adatok statisztikai értékelésének főbb lehetőségei 1. a. Egy- vagy kétváltozós eset b. Többváltozós eset 2. a. Becslési problémák, hipotézis vizsgálat b. Mintázatelemzés 3. Szint: a. Egyedi b. Populáció