Random Forests - Véletlen erdők
|
|
|
- Andor Horváth
- 9 évvel ezelőtt
- Látták:
Átírás
1 Random Forests - Véletlen erdők Szabó Adrienn Adatbányászat és Webes Keresés Kutatócsoport 2010

2 Tartalom Fő forrás: Leo Breiman: Random Forests Machine Learning, 45, 5-32, 2001 Alapok Döntési fa Véletlen erdők Véletlen erdők építése Nem formálisan Formálisan Véletlen erdő típusok A véletlen erdők jó tulajdonságai Belső becslések Kiértékelés Klasszifikáció További eredmények Regresszió

3 Amiből építkezni fogunk: döntési fa Az egyes attribútumok értékei alapján a mintákat hierarchikusan csoportosítjuk. A levelek: osztálycímkék. ID Gyártás helye Kor Motor Szín ccm Jól eladható? 1 Németo. 3-6 dízel fehér igen 2 Japán 6-10 dízel piros 1600 felett igen 3 Japán 3-6 dízel piros nem

4 Döntési fa A jó döntési fa: példákkal konzisztens, minél tömörebb (lehető legkevesebb teszttel döntésre jussunk) Hogyan építsük fel? Legegyszerűbb az ID3 algoritmus: a gyökértől kezdve építjük a fát, mohó módon mindig úgy válasszunk döntési attribútumot egy csúcspontban, hogy az információnyereség ( IG(S, a) = H(S) H(S a) ) maximális legyen Továbbfejlesztés: Information Gain helyett Gain Ratio, ami nem súlyozza túl azokat az attribútumokat amik sok különböző értéket felvehetnek
 = H(S) H(S a) ) maximális legyen Továbbfejlesztés: Information")
5 Döntési fa A jó döntési fa: példákkal konzisztens, minél tömörebb (lehető legkevesebb teszttel döntésre jussunk) Hogyan építsük fel? Legegyszerűbb az ID3 algoritmus: a gyökértől kezdve építjük a fát, mohó módon mindig úgy válasszunk döntési attribútumot egy csúcspontban, hogy az információnyereség ( IG(S, a) = H(S) H(S a) ) maximális legyen Továbbfejlesztés: Information Gain helyett Gain Ratio, ami nem súlyozza túl azokat az attribútumokat amik sok különböző értéket felvehetnek
 = H(S) H(S a) ) maximális legyen Továbbfejlesztés: Information")
6 Döntési fa A jó döntési fa: példákkal konzisztens, minél tömörebb (lehető legkevesebb teszttel döntésre jussunk) Hogyan építsük fel? Legegyszerűbb az ID3 algoritmus: a gyökértől kezdve építjük a fát, mohó módon mindig úgy válasszunk döntési attribútumot egy csúcspontban, hogy az információnyereség ( IG(S, a) = H(S) H(S a) ) maximális legyen Továbbfejlesztés: Information Gain helyett Gain Ratio, ami nem súlyozza túl azokat az attribútumokat amik sok különböző értéket felvehetnek
 = H(S) H(S a) ) maximális legyen Továbbfejlesztés: Information")
7 Döntési fa A jó döntési fa: példákkal konzisztens, minél tömörebb (lehető legkevesebb teszttel döntésre jussunk) Hogyan építsük fel? Legegyszerűbb az ID3 algoritmus: a gyökértől kezdve építjük a fát, mohó módon mindig úgy válasszunk döntési attribútumot egy csúcspontban, hogy az információnyereség ( IG(S, a) = H(S) H(S a) ) maximális legyen Továbbfejlesztés: Information Gain helyett Gain Ratio, ami nem súlyozza túl azokat az attribútumokat amik sok különböző értéket felvehetnek
 = H(S) H(S a) ) maximális legyen Továbbfejlesztés: Information")
8 Mik a véletlen erdők? Alapötlet: sok döntési fa, amik valamennyire különbözőek Mindegyik tippel majd valamit, a szavazás végeredményeként a leggykoribb választ fogadjuk el Az erdő hatékonysága a következőkön múlik: generált fák számán (ált. ha több fa szavaz, javul az eredmény) és minőségén generált fák közötti korreláción (ha nő a fák közötti korreláció, az eredmény romlik)

9 Mik a véletlen erdők? Alapötlet: sok döntési fa, amik valamennyire különbözőek Mindegyik tippel majd valamit, a szavazás végeredményeként a leggykoribb választ fogadjuk el Az erdő hatékonysága a következőkön múlik: generált fák számán (ált. ha több fa szavaz, javul az eredmény) és minőségén generált fák közötti korreláción (ha nő a fák közötti korreláció, az eredmény romlik)

10 Random forest előnyei Jó eredmények (pontos klasszifikáció) Gyorsan lefut, nagy adatokra is használható Több ezres dimenziójú bemenetet is képes kezelni Becsléseket ad arra hogy mely változók fontosak Hiányzó adatokat képes megbecsülni Használható regresszióra; kis kiterjesztéssel klaszterezésre vagy outlier-szűrésre is

11 Véletlen erdő építése Breiman módszere: Képezünk K döntési fát úgy, hogy bootstrapping-gal (visszatevéses sorsolás, N-ből N-et sorsolunk) külön-külön tanuló adathalmazt készítünk hozzájuk Az egyes fák építésekor a csomópontokban az attribútum választáskor a lehetséges attribútumhalmazt megszorítjuk egy jóval kisebb méretűre véletlenszerű választással. (Utána a max. IG-t vesszük) Nyesést nem alkalmazunk a fákon

12 Véletlen erdő építése Breiman módszere: Képezünk K döntési fát úgy, hogy bootstrapping-gal (visszatevéses sorsolás, N-ből N-et sorsolunk) külön-külön tanuló adathalmazt készítünk hozzájuk Az egyes fák építésekor a csomópontokban az attribútum választáskor a lehetséges attribútumhalmazt megszorítjuk egy jóval kisebb méretűre véletlenszerű választással. (Utána a max. IG-t vesszük) Nyesést nem alkalmazunk a fákon

13 Véletlen erdő építése Breiman módszere: Képezünk K döntési fát úgy, hogy bootstrapping-gal (visszatevéses sorsolás, N-ből N-et sorsolunk) külön-külön tanuló adathalmazt készítünk hozzájuk Az egyes fák építésekor a csomópontokban az attribútum választáskor a lehetséges attribútumhalmazt megszorítjuk egy jóval kisebb méretűre véletlenszerű választással. (Utána a max. IG-t vesszük) Nyesést nem alkalmazunk a fákon

14 Véletlen erdő építése Breiman módszere: Képezünk K döntési fát úgy, hogy bootstrapping-gal (visszatevéses sorsolás, N-ből N-et sorsolunk) külön-külön tanuló adathalmazt készítünk hozzájuk Az egyes fák építésekor a csomópontokban az attribútum választáskor a lehetséges attribútumhalmazt megszorítjuk egy jóval kisebb méretűre véletlenszerű választással. (Utána a max. IG-t vesszük) Nyesést nem alkalmazunk a fákon

15 Véletlen erdő építése
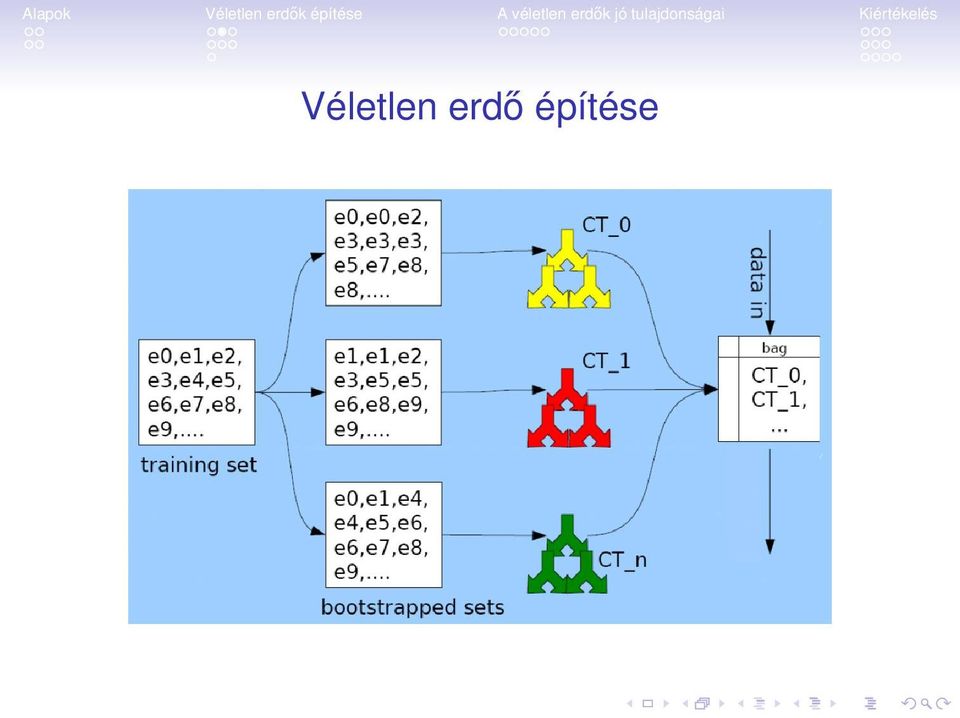
16 Véletlen erdők építése Az egyes fák egyes csúcsainál véletlenszerűen sorsolt attribútumokól választhatjuk csak ki a döntési attribútumot.

17 Formális definíció Véletlen erdőnek nevezzük azt az osztályozót amely döntési fák {h(x, θ k ), k = 1,... K } halmazából áll ahol a {θ k }-k független, azonos eloszlású random vektorok, és a fák többségi szavazással döntenek (minden fa egy-egy szavazatot adhat le egy-egy osztályozandó vektorra). Tétel: A fák számának növelésével a klasszifikáció minősége konvergál (nem lesz túltanulás). Bizonyítás: Nagy számok erős törvénye segítségével.
.")
18 Formális definíció Véletlen erdőnek nevezzük azt az osztályozót amely döntési fák {h(x, θ k ), k = 1,... K } halmazából áll ahol a {θ k }-k független, azonos eloszlású random vektorok, és a fák többségi szavazással döntenek (minden fa egy-egy szavazatot adhat le egy-egy osztályozandó vektorra). Tétel: A fák számának növelésével a klasszifikáció minősége konvergál (nem lesz túltanulás). Bizonyítás: Nagy számok erős törvénye segítségével.
.")
19 Formális definíció Margin: minél nagyobb, annál biztosabb az eredmény; ha negatív akkor hibázott az erdő: mg(x, Y ) = avg k I(h k (X) = Y ) max j Y (avg ki(h k (X) = j)) (X: a bemeneti vektorok, Y : a hozzájuk tartozó osztályok) A döntési fák általánosítási hibája (generalization error): PE = P X,Y (mg(x, Y ) < 0)
: PE = P X,Y (mg(x, Y")
20 Formális definíció Margin: minél nagyobb, annál biztosabb az eredmény; ha negatív akkor hibázott az erdő: mg(x, Y ) = avg k I(h k (X) = Y ) max j Y (avg ki(h k (X) = j)) (X: a bemeneti vektorok, Y : a hozzájuk tartozó osztályok) A döntési fák általánosítási hibája (generalization error): PE = P X,Y (mg(x, Y ) < 0)
: PE = P X,Y (mg(x, Y")
21 A fák ereje és korrelációja Felső korlát adható a véletlen erdő általánosítási hibájára, ami két dologtól függ: az egyes klasszifikátorok (döntési fák) pontosságától a fák közötti korrelációtól PE ρ(1 s 2 )/s 2 ahol ρ az átlagos korreláció a fák között, és s a h(x, θ) klasszifikátorhalmaz ereje: s = E X,Y mg(x, Y )
22 A fák ereje és korrelációja Felső korlát adható a véletlen erdő általánosítási hibájára, ami két dologtól függ: az egyes klasszifikátorok (döntési fák) pontosságától a fák közötti korrelációtól PE ρ(1 s 2 )/s 2 ahol ρ az átlagos korreláció a fák között, és s a h(x, θ) klasszifikátorhalmaz ereje: s = E X,Y mg(x, Y )
23 Véletlen erdő típusok Egyszerű bagging: lehetne belül más klasszifikátor is, de döntési fa van Random Split Selection: faépítésnél mindig a legjobb B válozóból választunk egyet véletlenszerűen Random Subspace: minden fát egy-egy rögzített, véletlenül választott attribútumhalmaz alapján építünk fel Breiman módszere: a fent bemutatott (bagging + random m változóból a legjobb választása a facsúcsoknál, ahol m << M, ahol M az attribútumok száma; általában m < log 2 M)
24 Véletlen erdő típusok Egyszerű bagging: lehetne belül más klasszifikátor is, de döntési fa van Random Split Selection: faépítésnél mindig a legjobb B válozóból választunk egyet véletlenszerűen Random Subspace: minden fát egy-egy rögzített, véletlenül választott attribútumhalmaz alapján építünk fel Breiman módszere: a fent bemutatott (bagging + random m változóból a legjobb választása a facsúcsoknál, ahol m << M, ahol M az attribútumok száma; általában m < log 2 M)
25 Véletlen erdő típusok Egyszerű bagging: lehetne belül más klasszifikátor is, de döntési fa van Random Split Selection: faépítésnél mindig a legjobb B válozóból választunk egyet véletlenszerűen Random Subspace: minden fát egy-egy rögzített, véletlenül választott attribútumhalmaz alapján építünk fel Breiman módszere: a fent bemutatott (bagging + random m változóból a legjobb választása a facsúcsoknál, ahol m << M, ahol M az attribútumok száma; általában m < log 2 M)
26 Véletlen erdő típusok Egyszerű bagging: lehetne belül más klasszifikátor is, de döntési fa van Random Split Selection: faépítésnél mindig a legjobb B válozóból választunk egyet véletlenszerűen Random Subspace: minden fát egy-egy rögzített, véletlenül választott attribútumhalmaz alapján építünk fel Breiman módszere: a fent bemutatott (bagging + random m változóból a legjobb választása a facsúcsoknál, ahol m << M, ahol M az attribútumok száma; általában m < log 2 M)
27 Out-of-bag becslések A bagging alkalmazásának előnyei: a pontosságot növeli, szórást csökkenti Minden fánál a tanítómintából kihagyott értékekre ( out-of bag vagy OOB értékek, ált. kb. a minták egyharmada) jóslatokat kérhetünk Az eredményeket átlagolva elég pontosan becsülhető az erdő hibája (PE), és a fák közötti korreláció is Kb olyan pontos becsléseket kapunk a jóságra mintha egy tanítóhalmaz méretű teszthalmazunk lenne 1 Ezért nem kell Cross Validation-t alkalmazni 1 Breiman egy korábbi cikkének empirikus eredménye, akkor igaz ha K elég nagy (a hiba már konvergált).
28 Out-of-bag becslések A bagging alkalmazásának előnyei: a pontosságot növeli, szórást csökkenti Minden fánál a tanítómintából kihagyott értékekre ( out-of bag vagy OOB értékek, ált. kb. a minták egyharmada) jóslatokat kérhetünk Az eredményeket átlagolva elég pontosan becsülhető az erdő hibája (PE), és a fák közötti korreláció is Kb olyan pontos becsléseket kapunk a jóságra mintha egy tanítóhalmaz méretű teszthalmazunk lenne 1 Ezért nem kell Cross Validation-t alkalmazni 1 Breiman egy korábbi cikkének empirikus eredménye, akkor igaz ha K elég nagy (a hiba már konvergált).
29 Out-of-bag becslések A bagging alkalmazásának előnyei: a pontosságot növeli, szórást csökkenti Minden fánál a tanítómintából kihagyott értékekre ( out-of bag vagy OOB értékek, ált. kb. a minták egyharmada) jóslatokat kérhetünk Az eredményeket átlagolva elég pontosan becsülhető az erdő hibája (PE), és a fák közötti korreláció is Kb olyan pontos becsléseket kapunk a jóságra mintha egy tanítóhalmaz méretű teszthalmazunk lenne 1 Ezért nem kell Cross Validation-t alkalmazni 1 Breiman egy korábbi cikkének empirikus eredménye, akkor igaz ha K elég nagy (a hiba már konvergált).
30 Out-of-bag becslések A bagging alkalmazásának előnyei: a pontosságot növeli, szórást csökkenti Minden fánál a tanítómintából kihagyott értékekre ( out-of bag vagy OOB értékek, ált. kb. a minták egyharmada) jóslatokat kérhetünk Az eredményeket átlagolva elég pontosan becsülhető az erdő hibája (PE), és a fák közötti korreláció is Kb olyan pontos becsléseket kapunk a jóságra mintha egy tanítóhalmaz méretű teszthalmazunk lenne 1 Ezért nem kell Cross Validation-t alkalmazni 1 Breiman egy korábbi cikkének empirikus eredménye, akkor igaz ha K elég nagy (a hiba már konvergált).
31 Out-of-bag becslések A bagging alkalmazásának előnyei: a pontosságot növeli, szórást csökkenti Minden fánál a tanítómintából kihagyott értékekre ( out-of bag vagy OOB értékek, ált. kb. a minták egyharmada) jóslatokat kérhetünk Az eredményeket átlagolva elég pontosan becsülhető az erdő hibája (PE), és a fák közötti korreláció is Kb olyan pontos becsléseket kapunk a jóságra mintha egy tanítóhalmaz méretű teszthalmazunk lenne 1 Ezért nem kell Cross Validation-t alkalmazni 1 Breiman egy korábbi cikkének empirikus eredménye, akkor igaz ha K elég nagy (a hiba már konvergált).
32 Fontos változók (Feature selection) Egy v bemenő attribútum (feature) fontossága így becsülhető: Minden fát szavaztassunk meg a hozzá tartozó OOB bemenetekre Jegyezzük meg a helyes válaszok arányát Permutáluk meg az OOB halmazon belül a v változó értékeit, és így is kérjünk jóslatokat a fától A helyes válaszok aránya mennyivel csökkent? Ezt átlagoljuk az összes fára = v fontossági értéke Nagyon sok bemeneti változó esetén először kiválaszthatjuk a jobbakat, aztán csak ezeket használva új, hatékonyabb erdőt építhetünk.
33 Fontos változók (Feature selection) Egy v bemenő attribútum (feature) fontossága így becsülhető: Minden fát szavaztassunk meg a hozzá tartozó OOB bemenetekre Jegyezzük meg a helyes válaszok arányát Permutáluk meg az OOB halmazon belül a v változó értékeit, és így is kérjünk jóslatokat a fától A helyes válaszok aránya mennyivel csökkent? Ezt átlagoljuk az összes fára = v fontossági értéke Nagyon sok bemeneti változó esetén először kiválaszthatjuk a jobbakat, aztán csak ezeket használva új, hatékonyabb erdőt építhetünk.
34 Fontos változók (Feature selection) Egy v bemenő attribútum (feature) fontossága így becsülhető: Minden fát szavaztassunk meg a hozzá tartozó OOB bemenetekre Jegyezzük meg a helyes válaszok arányát Permutáluk meg az OOB halmazon belül a v változó értékeit, és így is kérjünk jóslatokat a fától A helyes válaszok aránya mennyivel csökkent? Ezt átlagoljuk az összes fára = v fontossági értéke Nagyon sok bemeneti változó esetén először kiválaszthatjuk a jobbakat, aztán csak ezeket használva új, hatékonyabb erdőt építhetünk.
35 Fontos változók (Feature selection) Egy v bemenő attribútum (feature) fontossága így becsülhető: Minden fát szavaztassunk meg a hozzá tartozó OOB bemenetekre Jegyezzük meg a helyes válaszok arányát Permutáluk meg az OOB halmazon belül a v változó értékeit, és így is kérjünk jóslatokat a fától A helyes válaszok aránya mennyivel csökkent? Ezt átlagoljuk az összes fára = v fontossági értéke Nagyon sok bemeneti változó esetén először kiválaszthatjuk a jobbakat, aztán csak ezeket használva új, hatékonyabb erdőt építhetünk.
36 Fontos változók (Feature selection) Egy v bemenő attribútum (feature) fontossága így becsülhető: Minden fát szavaztassunk meg a hozzá tartozó OOB bemenetekre Jegyezzük meg a helyes válaszok arányát Permutáluk meg az OOB halmazon belül a v változó értékeit, és így is kérjünk jóslatokat a fától A helyes válaszok aránya mennyivel csökkent? Ezt átlagoljuk az összes fára = v fontossági értéke Nagyon sok bemeneti változó esetén először kiválaszthatjuk a jobbakat, aztán csak ezeket használva új, hatékonyabb erdőt építhetünk.
37 Fontos változók (Feature selection) Egy v bemenő attribútum (feature) fontossága így becsülhető: Minden fát szavaztassunk meg a hozzá tartozó OOB bemenetekre Jegyezzük meg a helyes válaszok arányát Permutáluk meg az OOB halmazon belül a v változó értékeit, és így is kérjünk jóslatokat a fától A helyes válaszok aránya mennyivel csökkent? Ezt átlagoljuk az összes fára = v fontossági értéke Nagyon sok bemeneti változó esetén először kiválaszthatjuk a jobbakat, aztán csak ezeket használva új, hatékonyabb erdőt építhetünk.
38 Fontos változók (Feature selection) Egy v bemenő attribútum (feature) fontossága így becsülhető: Minden fát szavaztassunk meg a hozzá tartozó OOB bemenetekre Jegyezzük meg a helyes válaszok arányát Permutáluk meg az OOB halmazon belül a v változó értékeit, és így is kérjünk jóslatokat a fától A helyes válaszok aránya mennyivel csökkent? Ezt átlagoljuk az összes fára = v fontossági értéke Nagyon sok bemeneti változó esetén először kiválaszthatjuk a jobbakat, aztán csak ezeket használva új, hatékonyabb erdőt építhetünk.
39 A bemeneti vektorok hasonlóságának becslése Mire is jó ez? Outlier-szűrés: Az összes többitől nagyon különböző tanítóminták zajnak tekinthetők (pl. elrontott mérés), jobb ha kidobjuk ezeket. Akár osztályonként is szűrhetjük őket. Klaszterezés: A minták közti hasonlóság alapján klaszterezést is végezhetünk. Hogyan? Minden bemenet-párra vegyük azon fáknak az arányát amikre ugyanabban a levélben ér véget a hozzájuk tartozó döntési folyamat. Proximity : s i,j Dissimilarity : d i,j = 1 s i,j
40 A bemeneti vektorok hasonlóságának becslése Mire is jó ez? Outlier-szűrés: Az összes többitől nagyon különböző tanítóminták zajnak tekinthetők (pl. elrontott mérés), jobb ha kidobjuk ezeket. Akár osztályonként is szűrhetjük őket. Klaszterezés: A minták közti hasonlóság alapján klaszterezést is végezhetünk. Hogyan? Minden bemenet-párra vegyük azon fáknak az arányát amikre ugyanabban a levélben ér véget a hozzájuk tartozó döntési folyamat. Proximity : s i,j Dissimilarity : d i,j = 1 s i,j
41 A bemeneti vektorok hasonlóságának becslése Mire is jó ez? Outlier-szűrés: Az összes többitől nagyon különböző tanítóminták zajnak tekinthetők (pl. elrontott mérés), jobb ha kidobjuk ezeket. Akár osztályonként is szűrhetjük őket. Klaszterezés: A minták közti hasonlóság alapján klaszterezést is végezhetünk. Hogyan? Minden bemenet-párra vegyük azon fáknak az arányát amikre ugyanabban a levélben ér véget a hozzájuk tartozó döntési folyamat. Proximity : s i,j Dissimilarity : d i,j = 1 s i,j
42 A bemeneti vektorok hasonlóságának becslése Mire is jó ez? Outlier-szűrés: Az összes többitől nagyon különböző tanítóminták zajnak tekinthetők (pl. elrontott mérés), jobb ha kidobjuk ezeket. Akár osztályonként is szűrhetjük őket. Klaszterezés: A minták közti hasonlóság alapján klaszterezést is végezhetünk. Hogyan? Minden bemenet-párra vegyük azon fáknak az arányát amikre ugyanabban a levélben ér véget a hozzájuk tartozó döntési folyamat. Proximity : s i,j Dissimilarity : d i,j = 1 s i,j
43 A bemeneti vektorok hasonlóságának becslése Mire is jó ez? Outlier-szűrés: Az összes többitől nagyon különböző tanítóminták zajnak tekinthetők (pl. elrontott mérés), jobb ha kidobjuk ezeket. Akár osztályonként is szűrhetjük őket. Klaszterezés: A minták közti hasonlóság alapján klaszterezést is végezhetünk. Hogyan? Minden bemenet-párra vegyük azon fáknak az arányát amikre ugyanabban a levélben ér véget a hozzájuk tartozó döntési folyamat. Proximity : s i,j Dissimilarity : d i,j = 1 s i,j
44 A bemeneti vektorok hasonlóságának becslése Mire is jó ez? Outlier-szűrés: Az összes többitől nagyon különböző tanítóminták zajnak tekinthetők (pl. elrontott mérés), jobb ha kidobjuk ezeket. Akár osztályonként is szűrhetjük őket. Klaszterezés: A minták közti hasonlóság alapján klaszterezést is végezhetünk. Hogyan? Minden bemenet-párra vegyük azon fáknak az arányát amikre ugyanabban a levélben ér véget a hozzájuk tartozó döntési folyamat. Proximity : s i,j Dissimilarity : d i,j = 1 s i,j
45 Hiányzó adatok kitöltése Iteratívan becsülhetjük a tanítóhalmaz hiányzó értékeit: Első közelítés: vegyük a hiányzó attribútum átlagát (ill. leggyakoribb értékét) a többi soron, és ezt helyettesítsük be Az így kiegészített adatokkal építsünk erdőt Minden i adatsorhoz amiben f hiányzott, vegyük az összes (nem-f -hiányos j sorral páronként vett hasonlóságait (s i,j ) Az új becslés: s i,j súlyokkal átlagoljuk a j-kben talált f -értékeket, ezt tegyük i f -be Ezt iterálhatjuk (új erdő építése, stb.) amíg már nem változnak az értékek (általában 4-6 kör elég)
46 Hiányzó adatok kitöltése Iteratívan becsülhetjük a tanítóhalmaz hiányzó értékeit: Első közelítés: vegyük a hiányzó attribútum átlagát (ill. leggyakoribb értékét) a többi soron, és ezt helyettesítsük be Az így kiegészített adatokkal építsünk erdőt Minden i adatsorhoz amiben f hiányzott, vegyük az összes (nem-f -hiányos j sorral páronként vett hasonlóságait (s i,j ) Az új becslés: s i,j súlyokkal átlagoljuk a j-kben talált f -értékeket, ezt tegyük i f -be Ezt iterálhatjuk (új erdő építése, stb.) amíg már nem változnak az értékek (általában 4-6 kör elég)
47 Hiányzó adatok kitöltése Iteratívan becsülhetjük a tanítóhalmaz hiányzó értékeit: Első közelítés: vegyük a hiányzó attribútum átlagát (ill. leggyakoribb értékét) a többi soron, és ezt helyettesítsük be Az így kiegészített adatokkal építsünk erdőt Minden i adatsorhoz amiben f hiányzott, vegyük az összes (nem-f -hiányos j sorral páronként vett hasonlóságait (s i,j ) Az új becslés: s i,j súlyokkal átlagoljuk a j-kben talált f -értékeket, ezt tegyük i f -be Ezt iterálhatjuk (új erdő építése, stb.) amíg már nem változnak az értékek (általában 4-6 kör elég)
48 Hiányzó adatok kitöltése Iteratívan becsülhetjük a tanítóhalmaz hiányzó értékeit: Első közelítés: vegyük a hiányzó attribútum átlagát (ill. leggyakoribb értékét) a többi soron, és ezt helyettesítsük be Az így kiegészített adatokkal építsünk erdőt Minden i adatsorhoz amiben f hiányzott, vegyük az összes (nem-f -hiányos j sorral páronként vett hasonlóságait (s i,j ) Az új becslés: s i,j súlyokkal átlagoljuk a j-kben talált f -értékeket, ezt tegyük i f -be Ezt iterálhatjuk (új erdő építése, stb.) amíg már nem változnak az értékek (általában 4-6 kör elég)
49 Hiányzó adatok kitöltése Iteratívan becsülhetjük a tanítóhalmaz hiányzó értékeit: Első közelítés: vegyük a hiányzó attribútum átlagát (ill. leggyakoribb értékét) a többi soron, és ezt helyettesítsük be Az így kiegészített adatokkal építsünk erdőt Minden i adatsorhoz amiben f hiányzott, vegyük az összes (nem-f -hiányos j sorral páronként vett hasonlóságait (s i,j ) Az új becslés: s i,j súlyokkal átlagoljuk a j-kben talált f -értékeket, ezt tegyük i f -be Ezt iterálhatjuk (új erdő építése, stb.) amíg már nem változnak az értékek (általában 4-6 kör elég)
50 Hiányzó adatok kitöltése Iteratívan becsülhetjük a tanítóhalmaz hiányzó értékeit: Első közelítés: vegyük a hiányzó attribútum átlagát (ill. leggyakoribb értékét) a többi soron, és ezt helyettesítsük be Az így kiegészített adatokkal építsünk erdőt Minden i adatsorhoz amiben f hiányzott, vegyük az összes (nem-f -hiányos j sorral páronként vett hasonlóságait (s i,j ) Az új becslés: s i,j súlyokkal átlagoljuk a j-kben talált f -értékeket, ezt tegyük i f -be Ezt iterálhatjuk (új erdő építése, stb.) amíg már nem változnak az értékek (általában 4-6 kör elég)
51 Hiányzó adatok kitöltése
52 A kiértékeléshez használt adathalmazok Data set Train size Test size Dimension Classes Letters Sat-images Zip-code Waveform Twonorm Threenorm Ringnorm
53 Eredmények (hibaszázalékok) Data set Adaboost Forest-RI 2 Forest-RI 3 One tree Letters Sat-images Zip-code Waveform Twonorm 4.9? Threenorm 18.8? Ringnorm 6.9? Forest-RI (Random Input selection): Véletlen erdő, véletlen attribútum választással. Fák száma: K = 100 (kivéve Zip-code: K = 200) AdaBoost iterációk száma: 50 (kivéve Zip-code: 100) 2 m = log 2 M 3 m = 1
54 Eredmények (hibaszázalékok) Data set Adaboost Forest-RC 4 Forest-RC 5 One tree Letters Sat-images Zip-code Waveform Twonorm Threenorm Ringnorm Forest-RC: bemenetek lineáris kombinációival épített erdő. Összekombinált változók száma: 3 4 m = 8 5 m = 2
55 A korreláció és jóslóerő változása m növelésével
56 A hiba változása m növelésével
57 Zaj tolerancia A véletlen erdők sokkal jobban tolerálják a zajt mint az AdaBoost. Amikor az AdaBoost elrontja (vagyis valójában jól klasszfikálná) a zaj-bementeteket akkor növekvő súllyal kerül a tanítóhalmazba a hibás adat, és ez eltozítja a végső eredményt is. 5%-os osztálycímke-permutáció után a hibák növekedése (%): Data set Adaboost Forest-RI Forest-RC Breast cancer Diabetes Sonar Ionosphere Soybean Ecoli Liver
58 Regresszió A döntési fák képesek regresszióra is ekkor minden elágazásnál az alapján határozzuk meg a döntési attrubútumot és vágási határt, hogy a két új halmazon belül a jóslandó érték szórásnégyzetei minimálisak legyenek. Data set Train size Test size Dimension Boston Housing % 12 Ozone % 8 Abalone % 8 Robot Arm Friedman# Friedman# Friedman#
59 Regresszió eredményei Erdők paraméterei: 100 fa, m = 25, random lineáris kombinációi 2 bemenetnek. Megfigyelések: a fák közti korreláció itt lassababn nő m növelésével. Mean squared test set errors Data set Bagging Adapt. bag. Forest Boston Housing Ozone Abalone Robot Arm Friedman# Friedman# Friedman#
60 Összefoglalás A véletlen erdők hatékony klasszifikátorok, nagy adathalmazokkal is megbirkóznak. A két paraméter, K és m választására nem túl érzékeny (de K legyen elég nagy, m pedig ne legyen túl nagy).
61 Köszönöm a figyelmet!
Új típusú döntési fa építés és annak alkalmazása többtényezős döntés területén
 Új típusú döntési fa építés és annak alkalmazása többtényezős döntés területén Dombi József Szegedi Tudományegyetem Bevezetés - ID3 (Iterative Dichotomiser 3) Az ID algoritmusok egy elemhalmaz felhasználásával
Új típusú döntési fa építés és annak alkalmazása többtényezős döntés területén Dombi József Szegedi Tudományegyetem Bevezetés - ID3 (Iterative Dichotomiser 3) Az ID algoritmusok egy elemhalmaz felhasználásával
Egy uttes m odszerek Isp any M arton es Jeszenszky P eter okt ober 18.
 Együttes módszerek Ispány Márton és Jeszenszky Péter 2016. október 18. Tartalom Bevezetés Zsákolás (bagging) Gyorsítás (boosting) AdaBoost Véletlen erdők (random forests) Hibajavító kimenet kódolás (error-correcting
Együttes módszerek Ispány Márton és Jeszenszky Péter 2016. október 18. Tartalom Bevezetés Zsákolás (bagging) Gyorsítás (boosting) AdaBoost Véletlen erdők (random forests) Hibajavító kimenet kódolás (error-correcting
1. gyakorlat. Mesterséges Intelligencia 2.
 1. gyakorlat Mesterséges Intelligencia. Elérhetőségek web: www.inf.u-szeged.hu/~gulyasg mail: gulyasg@inf.u-szeged.hu Követelmények (nem teljes) gyakorlat látogatása kötelező ZH írása a gyakorlaton elhangzott
1. gyakorlat Mesterséges Intelligencia. Elérhetőségek web: www.inf.u-szeged.hu/~gulyasg mail: gulyasg@inf.u-szeged.hu Követelmények (nem teljes) gyakorlat látogatása kötelező ZH írása a gyakorlaton elhangzott
Csima Judit április 9.
 Osztályozókról még pár dolog Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2018. április 9. Csima Judit Osztályozókról még pár dolog 1 / 19 SVM (support vector machine) ez is egy
Osztályozókról még pár dolog Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2018. április 9. Csima Judit Osztályozókról még pár dolog 1 / 19 SVM (support vector machine) ez is egy
Döntési fák. (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART ))
)") Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
Osztályozás, regresszió. Nagyméretű adathalmazok kezelése Tatai Márton
 Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
Regresszió. Csorba János. Nagyméretű adathalmazok kezelése március 31.
 Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Közösség detektálás gráfokban
 Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
Közösség detektálás gráfokban Önszervező rendszerek Hegedűs István Célkitűzés: valamilyen objektumok halmaza felett minták, csoportok detektálása csakis az egyedek közötti kapcsolatok struktúrájának a
Gépi tanulás. Hány tanítómintára van szükség? VKH. Pataki Béla (Bolgár Bence)
") Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
Adatbányászati szemelvények MapReduce környezetben
 Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Gépi tanulás a gyakorlatban. Lineáris regresszió
 Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Fodor Gábor március 17. Fodor Gábor Osztályozás március / 39
 Osztályozás Fodor Gábor 2010. március 17. Fodor Gábor (fodgabor@math.bme.hu) Osztályozás 2010. március 17. 1 / 39 Bevezetés 1 Bevezetés 2 Döntési szabályok 3 Döntési fák 4 Bayes-hálók 5 Lineáris szeparálás
Osztályozás Fodor Gábor 2010. március 17. Fodor Gábor (fodgabor@math.bme.hu) Osztályozás 2010. március 17. 1 / 39 Bevezetés 1 Bevezetés 2 Döntési szabályok 3 Döntési fák 4 Bayes-hálók 5 Lineáris szeparálás
Gépi tanulás. Féligellenőrzött tanulás. Pataki Béla (Bolgár Bence)
") Gépi tanulás Féligellenőrzött tanulás Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Féligellenőrzött tanulás Mindig kevés az adat, de
Gépi tanulás Féligellenőrzött tanulás Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Féligellenőrzött tanulás Mindig kevés az adat, de
Biomatematika 12. Szent István Egyetem Állatorvos-tudományi Kar. Fodor János
 Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Számítógépes képelemzés 7. előadás. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Statisztikai következtetések Nemlineáris regresszió Feladatok Vége
 [GVMGS11MNC] Gazdaságstatisztika 10. előadás: 9. Regressziószámítás II. Kóczy Á. László koczy.laszlo@kgk.uni-obuda.hu Keleti Károly Gazdasági Kar Vállalkozásmenedzsment Intézet A standard lineáris modell
[GVMGS11MNC] Gazdaságstatisztika 10. előadás: 9. Regressziószámítás II. Kóczy Á. László koczy.laszlo@kgk.uni-obuda.hu Keleti Károly Gazdasági Kar Vállalkozásmenedzsment Intézet A standard lineáris modell
Gépi tanulás a gyakorlatban. Kiértékelés és Klaszterezés
 Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására
 VÉGZŐS KONFERENCIA 2009 2009. május 20, Budapest Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására Hidasi Balázs hidasi@tmit.bme.hu Konzulens: Gáspár-Papanek Csaba Budapesti
VÉGZŐS KONFERENCIA 2009 2009. május 20, Budapest Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására Hidasi Balázs hidasi@tmit.bme.hu Konzulens: Gáspár-Papanek Csaba Budapesti
Nagyméretű adathalmazok kezelése (BMEVISZM144) Reinhardt Gábor április 5.
 Reinhardt Gábor április 5.") Asszociációs szabályok Budapesti Műszaki- és Gazdaságtudományi Egyetem 2012. április 5. Tartalom 1 2 3 4 5 6 7 ismétlés A feladat Gyakran együtt vásárolt termékek meghatározása Tanultunk rá hatékony algoritmusokat
Asszociációs szabályok Budapesti Műszaki- és Gazdaságtudományi Egyetem 2012. április 5. Tartalom 1 2 3 4 5 6 7 ismétlés A feladat Gyakran együtt vásárolt termékek meghatározása Tanultunk rá hatékony algoritmusokat
Szomszédság alapú ajánló rendszerek
 Nagyméretű adathalmazok kezelése Szomszédság alapú ajánló rendszerek Készítette: Szabó Máté A rendelkezésre álló adatmennyiség növelésével egyre nehezebb kiválogatni a hasznos információkat Megoldás: ajánló
Nagyméretű adathalmazok kezelése Szomszédság alapú ajánló rendszerek Készítette: Szabó Máté A rendelkezésre álló adatmennyiség növelésével egyre nehezebb kiválogatni a hasznos információkat Megoldás: ajánló
Asszociációs szabályok
 Asszociációs szabályok Nikházy László Nagy adathalmazok kezelése 2010. március 10. Mi az értelme? A ö asszociációs szabály azt állítja, hogy azon vásárlói kosarak, amik tartalmaznak pelenkát, általában
Asszociációs szabályok Nikházy László Nagy adathalmazok kezelése 2010. március 10. Mi az értelme? A ö asszociációs szabály azt állítja, hogy azon vásárlói kosarak, amik tartalmaznak pelenkát, általában
Autoregresszív és mozgóátlag folyamatok. Géczi-Papp Renáta
 Autoregresszív és mozgóátlag folyamatok Géczi-Papp Renáta Autoregresszív folyamat Az Y t diszkrét paraméterű sztochasztikus folyamatok k-ad rendű autoregresszív folyamatnak nevezzük, ha Y t = α 1 Y t 1
Autoregresszív és mozgóátlag folyamatok Géczi-Papp Renáta Autoregresszív folyamat Az Y t diszkrét paraméterű sztochasztikus folyamatok k-ad rendű autoregresszív folyamatnak nevezzük, ha Y t = α 1 Y t 1
Keresés képi jellemzők alapján. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Autoregresszív és mozgóátlag folyamatok
 Géczi-Papp Renáta Autoregresszív és mozgóátlag folyamatok Autoregresszív folyamat Az Y t diszkrét paraméterű sztochasztikus folyamatok k-ad rendű autoregresszív folyamatnak nevezzük, ha Y t = α 1 Y t 1
Géczi-Papp Renáta Autoregresszív és mozgóátlag folyamatok Autoregresszív folyamat Az Y t diszkrét paraméterű sztochasztikus folyamatok k-ad rendű autoregresszív folyamatnak nevezzük, ha Y t = α 1 Y t 1
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
Programozási módszertan. A gépi tanulás alapmódszerei
 SZDT-12 p. 1/24 Programozási módszertan A gépi tanulás alapmódszerei Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu SZDT-12 p. 2/24 Ágensek Az új
SZDT-12 p. 1/24 Programozási módszertan A gépi tanulás alapmódszerei Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu SZDT-12 p. 2/24 Ágensek Az új
Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok
 Zrínyi Miklós Gimnázium Művészet és tudomány napja Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok 10/9/2009 Dr. Viharos Zsolt János Elsősorban volt Zrínyis diák Tudományos főmunkatárs
Zrínyi Miklós Gimnázium Művészet és tudomány napja Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok 10/9/2009 Dr. Viharos Zsolt János Elsősorban volt Zrínyis diák Tudományos főmunkatárs
Gépi tanulás Gregorics Tibor Mesterséges intelligencia
 Gépi tanulás Tanulás fogalma Egy algoritmus akkor tanul, ha egy feladat megoldása során olyan változások következnek be a működésében, hogy később ugyanazt a feladatot vagy ahhoz hasonló más feladatokat
Gépi tanulás Tanulás fogalma Egy algoritmus akkor tanul, ha egy feladat megoldása során olyan változások következnek be a működésében, hogy később ugyanazt a feladatot vagy ahhoz hasonló más feladatokat
IBNR számítási módszerek áttekintése
 1/13 IBNR számítási módszerek áttekintése Prokaj Vilmos email: Prokaj.Vilmos@pszaf.hu 1. Kifutási háromszög Év 1 2 3 4 5 2/13 1 X 1,1 X 1,2 X 1,3 X 1,4 X 1,5 2 X 2,1 X 2,2 X 2,3 X 2,4 X 2,5 3 X 3,1 X 3,2
1/13 IBNR számítási módszerek áttekintése Prokaj Vilmos email: Prokaj.Vilmos@pszaf.hu 1. Kifutási háromszög Év 1 2 3 4 5 2/13 1 X 1,1 X 1,2 X 1,3 X 1,4 X 1,5 2 X 2,1 X 2,2 X 2,3 X 2,4 X 2,5 3 X 3,1 X 3,2
Gyakorló feladatok adatbányászati technikák tantárgyhoz
 Gyakorló feladatok adatbányászati technikák tantárgyhoz Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Klaszterezés kiértékelése Feladat:
Gyakorló feladatok adatbányászati technikák tantárgyhoz Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Klaszterezés kiértékelése Feladat:
Számítógépes döntéstámogatás. Genetikus algoritmusok
 BLSZM-10 p. 1/18 Számítógépes döntéstámogatás Genetikus algoritmusok Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu BLSZM-10 p. 2/18 Bevezetés 1950-60-as
BLSZM-10 p. 1/18 Számítógépes döntéstámogatás Genetikus algoritmusok Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu BLSZM-10 p. 2/18 Bevezetés 1950-60-as
A maximum likelihood becslésről
 A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
Babeş Bolyai Tudományegyetem, Kolozsvár Matematika és Informatika Kar Magyar Matematika és Informatika Intézet
 / Babeş Bolyai Tudományegyetem, Kolozsvár Matematika és Informatika Kar Magyar Matematika és Informatika Intézet / Tartalom 3/ kernelek segítségével Felügyelt és félig-felügyelt tanulás felügyelt: D =
/ Babeş Bolyai Tudományegyetem, Kolozsvár Matematika és Informatika Kar Magyar Matematika és Informatika Intézet / Tartalom 3/ kernelek segítségével Felügyelt és félig-felügyelt tanulás felügyelt: D =
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
Statisztika I. 8. előadás. Előadó: Dr. Ertsey Imre
 Statisztika I. 8. előadás Előadó: Dr. Ertsey Imre Minták alapján történő értékelések A statisztika foglalkozik. a tömegjelenségek vizsgálatával Bizonyos esetekben lehetetlen illetve célszerűtlen a teljes
Statisztika I. 8. előadás Előadó: Dr. Ertsey Imre Minták alapján történő értékelések A statisztika foglalkozik. a tömegjelenségek vizsgálatával Bizonyos esetekben lehetetlen illetve célszerűtlen a teljes
A számítástudomány alapjai. Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem
 A számítástudomány alapjai Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Bináris keresőfa, kupac Katona Gyula Y. (BME SZIT) A számítástudomány
A számítástudomány alapjai Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Bináris keresőfa, kupac Katona Gyula Y. (BME SZIT) A számítástudomány
BAGME11NNF Munkavédelmi mérnökasszisztens Galla Jánosné, 2011.
 BAGME11NNF Munkavédelmi mérnökasszisztens Galla Jánosné, 2011. 1 Mérési hibák súlya és szerepe a mérési eredményben A mérési hibák csoportosítása A hiba rendűsége Mérési bizonytalanság Standard és kiterjesztett
BAGME11NNF Munkavédelmi mérnökasszisztens Galla Jánosné, 2011. 1 Mérési hibák súlya és szerepe a mérési eredményben A mérési hibák csoportosítása A hiba rendűsége Mérési bizonytalanság Standard és kiterjesztett
angolul: greedy algorithms, románul: algoritmi greedy
 Mohó algoritmusok angolul: greedy algorithms, románul: algoritmi greedy 1. feladat. Gazdaságos telefonhálózat építése Bizonyos városok között lehet direkt telefonkapcsolatot kiépíteni, pl. x és y város
Mohó algoritmusok angolul: greedy algorithms, románul: algoritmi greedy 1. feladat. Gazdaságos telefonhálózat építése Bizonyos városok között lehet direkt telefonkapcsolatot kiépíteni, pl. x és y város
Tanulás az idegrendszerben. Structure Dynamics Implementation Algorithm Computation - Function
 Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Statisztikai módszerek a skálafüggetlen hálózatok
 Statisztikai módszerek a skálafüggetlen hálózatok vizsgálatára Gyenge Ádám1 1 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Számítástudományi és Információelméleti
Statisztikai módszerek a skálafüggetlen hálózatok vizsgálatára Gyenge Ádám1 1 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Számítástudományi és Információelméleti
Lineáris regresszió vizsgálata resampling eljárással
 Lineáris regresszió vizsgálata resampling eljárással Dolgozatomban az European Social Survey (ESS) harmadik hullámának adatait fogom felhasználni, melyben a teljes nemzetközi lekérdezés feldolgozásra került,
Lineáris regresszió vizsgálata resampling eljárással Dolgozatomban az European Social Survey (ESS) harmadik hullámának adatait fogom felhasználni, melyben a teljes nemzetközi lekérdezés feldolgozásra került,
A Markovi forgalomanalízis legújabb eredményei és ezek alkalmazása a távközlő hálózatok teljesítményvizsgálatában
 A Markovi forgalomanalízis legújabb eredményei és ezek alkalmazása a távközlő hálózatok teljesítményvizsgálatában Horváth Gábor ghorvath@hit.bme.hu (Horváth András, Telek Miklós) - p. 1 Motiváció, problémafelvetés
A Markovi forgalomanalízis legújabb eredményei és ezek alkalmazása a távközlő hálózatok teljesítményvizsgálatában Horváth Gábor ghorvath@hit.bme.hu (Horváth András, Telek Miklós) - p. 1 Motiváció, problémafelvetés
[1000 ; 0] 7 [1000 ; 3000]
![[1000 ; 0] 7 [1000 ; 3000]](/thumbs/88/116286101.jpg "[1000 ; 0] 7 [1000 ; 3000]") Gépi tanulás (vimim36) Gyakorló feladatok 04 tavaszi félév Ahol lehet, ott konkrét számértékeket várok nem puszta egyenleteket. (Azok egy részét amúgyis megadom.). Egy bináris osztályozási feladatra tanított
Gépi tanulás (vimim36) Gyakorló feladatok 04 tavaszi félév Ahol lehet, ott konkrét számértékeket várok nem puszta egyenleteket. (Azok egy részét amúgyis megadom.). Egy bináris osztályozási feladatra tanított
Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl sok szelet se legyen.
 KEMOMETRIA VIII-1/27 /2013 ősz CART Classification and Regression Trees Osztályozó fák Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl
KEMOMETRIA VIII-1/27 /2013 ősz CART Classification and Regression Trees Osztályozó fák Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl
Mérés és modellezés 1
 Mérés és modellezés 1 Mérés és modellezés A mérnöki tevékenység alapeleme a mérés. A mérés célja valamely jelenség megismerése, vizsgálata. A mérés tervszerűen végzett tevékenység: azaz rögzíteni kell
Mérés és modellezés 1 Mérés és modellezés A mérnöki tevékenység alapeleme a mérés. A mérés célja valamely jelenség megismerése, vizsgálata. A mérés tervszerűen végzett tevékenység: azaz rögzíteni kell
Alap-ötlet: Karl Friedrich Gauss ( ) valószínűségszámítási háttér: Andrej Markov ( )
 valószínűségszámítási háttér: Andrej Markov ( )") Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Kabos: Statisztika II. t-próba 9.1. Ha ismert a doboz szórása de nem ismerjük a
 Kabos: Statisztika II. t-próba 9.1 Egymintás z-próba Ha ismert a doboz szórása de nem ismerjük a doboz várhatóértékét, akkor a H 0 : a doboz várhatóértéke = egy rögzített érték hipotézisről úgy döntünk,
Kabos: Statisztika II. t-próba 9.1 Egymintás z-próba Ha ismert a doboz szórása de nem ismerjük a doboz várhatóértékét, akkor a H 0 : a doboz várhatóértéke = egy rögzített érték hipotézisről úgy döntünk,
E x μ x μ K I. és 1. osztály. pontokként), valamint a bayesi döntést megvalósító szeparáló görbét (kék egyenes)
, valamint a bayesi döntést megvalósító szeparáló görbét (kék egyenes)") 6-7 ősz. gyakorlat Feladatok.) Adjon meg azt a perceptronon implementált Bayes-i klasszifikátort, amely kétdimenziós a bemeneti tér felett szeparálja a Gauss eloszlású mintákat! Rajzolja le a bemeneti
6-7 ősz. gyakorlat Feladatok.) Adjon meg azt a perceptronon implementált Bayes-i klasszifikátort, amely kétdimenziós a bemeneti tér felett szeparálja a Gauss eloszlású mintákat! Rajzolja le a bemeneti
Klaszterezés, 2. rész
 Klaszterezés, 2. rész Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 208. április 6. Csima Judit Klaszterezés, 2. rész / 29 Hierarchikus klaszterezés egymásba ágyazott klasztereket
Klaszterezés, 2. rész Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 208. április 6. Csima Judit Klaszterezés, 2. rész / 29 Hierarchikus klaszterezés egymásba ágyazott klasztereket
Algoritmuselmélet. 2-3 fák. Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem. 8.
 Algoritmuselmélet 2-3 fák Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 8. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet 8. előadás
Algoritmuselmélet 2-3 fák Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 8. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet 8. előadás
7. Régió alapú szegmentálás
 Digitális képek szegmentálása 7. Régió alapú szegmentálás Kató Zoltán http://www.cab.u-szeged.hu/~kato/segmentation/ Szegmentálási kritériumok Particionáljuk a képet az alábbi kritériumokat kielégítő régiókba
Digitális képek szegmentálása 7. Régió alapú szegmentálás Kató Zoltán http://www.cab.u-szeged.hu/~kato/segmentation/ Szegmentálási kritériumok Particionáljuk a képet az alábbi kritériumokat kielégítő régiókba
Megerősítéses tanulás 7. előadás
 Megerősítéses tanulás 7. előadás 1 Ismétlés: TD becslés s t -ben stratégia szerint lépek! a t, r t, s t+1 TD becslés: tulajdonképpen ezt mintavételezzük: 2 Akcióértékelő függvény számolása TD-vel még mindig
Megerősítéses tanulás 7. előadás 1 Ismétlés: TD becslés s t -ben stratégia szerint lépek! a t, r t, s t+1 TD becslés: tulajdonképpen ezt mintavételezzük: 2 Akcióértékelő függvény számolása TD-vel még mindig
Hipotézis STATISZTIKA. Kétmintás hipotézisek. Munkahipotézis (H a ) Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok
 Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok") STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
17. A 2-3 fák és B-fák. 2-3 fák
 17. A 2-3 fák és B-fák 2-3 fák Fontos jelentősége, hogy belőlük fejlődtek ki a B-fák. Def.: Minden belső csúcsnak 2 vagy 3 gyermeke van. A levelek egy szinten helyezkednek el. Az adatrekordok/kulcsok csak
17. A 2-3 fák és B-fák 2-3 fák Fontos jelentősége, hogy belőlük fejlődtek ki a B-fák. Def.: Minden belső csúcsnak 2 vagy 3 gyermeke van. A levelek egy szinten helyezkednek el. Az adatrekordok/kulcsok csak
Izgalmas újdonságok a klaszteranalízisben
 Izgalmas újdonságok a klaszteranalízisben Vargha András KRE és ELTE, Pszichológiai Intézet Vargha András KRE és ELTE, Pszichológiai Intézet Mi a klaszteranalízis (KLA)? Keressük a személyek (vagy bármilyen
Izgalmas újdonságok a klaszteranalízisben Vargha András KRE és ELTE, Pszichológiai Intézet Vargha András KRE és ELTE, Pszichológiai Intézet Mi a klaszteranalízis (KLA)? Keressük a személyek (vagy bármilyen
Matematikai alapok és valószínőségszámítás. Statisztikai becslés Statisztikák eloszlása
 Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
Szalai Péter. April 17, Szalai Péter April 17, / 36
 Szociális hálók Szalai Péter April 17, 2015 Szalai Péter April 17, 2015 1 / 36 Miről lesz szó? 1 Megfigyelések Kis világ Power-law Klaszterezhetőség 2 Modellek Célok Erdős-Rényi Watts-Strogatz Barabási
Szociális hálók Szalai Péter April 17, 2015 Szalai Péter April 17, 2015 1 / 36 Miről lesz szó? 1 Megfigyelések Kis világ Power-law Klaszterezhetőség 2 Modellek Célok Erdős-Rényi Watts-Strogatz Barabási
Adatbányászati feladatgyűjtemény tehetséges hallgatók számára
 Adatbányászati feladatgyűjtemény tehetséges hallgatók számára Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Tartalomjegyék Modellek kiértékelése...
Adatbányászati feladatgyűjtemény tehetséges hallgatók számára Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Tartalomjegyék Modellek kiértékelése...
ANOVA összefoglaló. Min múlik?
 ANOVA összefoglaló Min múlik? Kereszt vagy beágyazott? Rögzített vagy véletlen? BIOMETRIA_ANOVA5 1 I. Kereszt vagy beágyazott Két faktor viszonyát mondja meg. Ha több, mint két faktor van, akkor bármely
ANOVA összefoglaló Min múlik? Kereszt vagy beágyazott? Rögzített vagy véletlen? BIOMETRIA_ANOVA5 1 I. Kereszt vagy beágyazott Két faktor viszonyát mondja meg. Ha több, mint két faktor van, akkor bármely
19. AZ ÖSSZEHASONLÍTÁSOS RENDEZÉSEK MŰVELETIGÉNYÉNEK ALSÓ KORLÁTJAI
 19. AZ ÖSSZEHASONLÍTÁSOS RENDEZÉSEK MŰVELETIGÉNYÉNEK ALSÓ KORLÁTJAI Ebben a fejezetben aszimptotikus (nagyságrendi) alsó korlátot adunk az összehasonlításokat használó rendező eljárások lépésszámára. Pontosabban,
19. AZ ÖSSZEHASONLÍTÁSOS RENDEZÉSEK MŰVELETIGÉNYÉNEK ALSÓ KORLÁTJAI Ebben a fejezetben aszimptotikus (nagyságrendi) alsó korlátot adunk az összehasonlításokat használó rendező eljárások lépésszámára. Pontosabban,
Diverzifikáció Markowitz-modell MAD modell CAPM modell 2017/ Szegedi Tudományegyetem Informatikai Intézet
 Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 11. Előadás Portfólió probléma Portfólió probléma Portfólió probléma Adott részvények (kötvények,tevékenységek,
Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 11. Előadás Portfólió probléma Portfólió probléma Portfólió probléma Adott részvények (kötvények,tevékenységek,
Gauss-Seidel iteráció
 Közelítő és szimbolikus számítások 5. gyakorlat Iterációs módszerek: Jacobi és Gauss-Seidel iteráció Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor London András Deák Gábor jegyzetei alapján 1 ITERÁCIÓS
Közelítő és szimbolikus számítások 5. gyakorlat Iterációs módszerek: Jacobi és Gauss-Seidel iteráció Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor London András Deák Gábor jegyzetei alapján 1 ITERÁCIÓS
bármely másikra el lehessen jutni. A vállalat tudja, hogy tetszőlegesen adott
 . Minimális súlyú feszítő fa keresése Képzeljük el, hogy egy útépítő vállalat azt a megbízást kapja, hogy építsen ki egy úthálózatot néhány település között (a települések között jelenleg nincs út). feltétel
. Minimális súlyú feszítő fa keresése Képzeljük el, hogy egy útépítő vállalat azt a megbízást kapja, hogy építsen ki egy úthálózatot néhány település között (a települések között jelenleg nincs út). feltétel
Nagyságrendek. Kiegészítő anyag az Algoritmuselmélet tárgyhoz. Friedl Katalin BME SZIT február 1.
 Nagyságrendek Kiegészítő anyag az Algoritmuselmélet tárgyhoz (a Rónyai Ivanyos Szabó: Algoritmusok könyv mellé) Friedl Katalin BME SZIT friedl@cs.bme.hu 018. február 1. Az O, Ω, Θ jelölések Az algoritmusok
Nagyságrendek Kiegészítő anyag az Algoritmuselmélet tárgyhoz (a Rónyai Ivanyos Szabó: Algoritmusok könyv mellé) Friedl Katalin BME SZIT friedl@cs.bme.hu 018. február 1. Az O, Ω, Θ jelölések Az algoritmusok
Intelligens Rendszerek Elmélete. Versengéses és önszervező tanulás neurális hálózatokban
 Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
Biometria az orvosi gyakorlatban. Korrelációszámítás, regresszió
 SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
Intelligens orvosi műszerek VIMIA023
 Intelligens orvosi műszerek VIMIA023 A mintapéldákból tanuló számítógépes program (egyik lehetőség): döntési fák 2018 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu
Intelligens orvosi műszerek VIMIA023 A mintapéldákból tanuló számítógépes program (egyik lehetőség): döntési fák 2018 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu
Lineáris algebra gyakorlat
 Lineáris algebra gyakorlat 7. gyakorlat Gyakorlatvezet : Bogya Norbert 2012. március 26. Ismétlés Tartalom 1 Ismétlés 2 Koordinátasor 3 Bázistranszformáció és alkalmazásai Vektorrendszer rangja Mátrix
Lineáris algebra gyakorlat 7. gyakorlat Gyakorlatvezet : Bogya Norbert 2012. március 26. Ismétlés Tartalom 1 Ismétlés 2 Koordinátasor 3 Bázistranszformáció és alkalmazásai Vektorrendszer rangja Mátrix
Több valószínűségi változó együttes eloszlása, korreláció
 Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Teljesen elosztott adatbányászat pletyka algoritmusokkal. Jelasity Márk Ormándi Róbert, Hegedűs István
 Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Közösségek keresése nagy gráfokban
 Közösségek keresése nagy gráfokban Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 2011. április 14. Katona Gyula Y. (BME SZIT) Közösségek
Közösségek keresése nagy gráfokban Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 2011. április 14. Katona Gyula Y. (BME SZIT) Közösségek
Mesterséges Intelligencia I.
 Mesterséges Intelligencia I. 10. elıadás (2008. november 10.) Készítette: Romhányi Anita (ROANAAT.SZE) - 1 - Statisztikai tanulás (Megfigyelések alapján történı bizonytalan következetésnek tekintjük a
Mesterséges Intelligencia I. 10. elıadás (2008. november 10.) Készítette: Romhányi Anita (ROANAAT.SZE) - 1 - Statisztikai tanulás (Megfigyelések alapján történı bizonytalan következetésnek tekintjük a
Support Vector Machines
 Support Vector Machnes Ormánd Róbert MA-SZE Mest. Int. Kutatócsoport 2009. február 17. Előadás vázlata Rövd bevezetés a gép tanulásba Bevezetés az SVM tanuló módszerbe Alapötlet Nem szeparálható eset Kernel
Support Vector Machnes Ormánd Róbert MA-SZE Mest. Int. Kutatócsoport 2009. február 17. Előadás vázlata Rövd bevezetés a gép tanulásba Bevezetés az SVM tanuló módszerbe Alapötlet Nem szeparálható eset Kernel
PONTFELHŐ REGISZTRÁCIÓ
 PONTFELHŐ REGISZTRÁCIÓ ITERATIVE CLOSEST POINT Cserteg Tamás, URLGNI, 2018.11.22. TARTALOM Röviden Alakzatrekonstrukció áttekintés ICP algoritmusok Projektfeladat Demó FORRÁSOK Cikkek Efficient Variants
PONTFELHŐ REGISZTRÁCIÓ ITERATIVE CLOSEST POINT Cserteg Tamás, URLGNI, 2018.11.22. TARTALOM Röviden Alakzatrekonstrukció áttekintés ICP algoritmusok Projektfeladat Demó FORRÁSOK Cikkek Efficient Variants
Mérés és modellezés Méréstechnika VM, GM, MM 1
 Mérés és modellezés 2008.02.04. 1 Mérés és modellezés A mérnöki tevékenység alapeleme a mérés. A mérés célja valamely jelenség megismerése, vizsgálata. A mérés tervszerűen végzett tevékenység: azaz rögzíteni
Mérés és modellezés 2008.02.04. 1 Mérés és modellezés A mérnöki tevékenység alapeleme a mérés. A mérés célja valamely jelenség megismerése, vizsgálata. A mérés tervszerűen végzett tevékenység: azaz rögzíteni
6. Előadás. Vereb György, DE OEC BSI, október 12.
 6. Előadás Visszatekintés: a normális eloszlás Becslés, mintavételezés Reprezentatív minta A statisztika, mint változó Paraméter és Statisztika Torzítatlan becslés A mintaközép eloszlása - centrális határeloszlás
6. Előadás Visszatekintés: a normális eloszlás Becslés, mintavételezés Reprezentatív minta A statisztika, mint változó Paraméter és Statisztika Torzítatlan becslés A mintaközép eloszlása - centrális határeloszlás
Neurális hálózatok.... a gyakorlatban
 Neurális hálózatok... a gyakorlatban Java NNS Az SNNS Javás változata SNNS: Stuttgart Neural Network Simulator A Tübingeni Egyetemen fejlesztik http://www.ra.cs.unituebingen.de/software/javanns/ 2012/13.
Neurális hálózatok... a gyakorlatban Java NNS Az SNNS Javás változata SNNS: Stuttgart Neural Network Simulator A Tübingeni Egyetemen fejlesztik http://www.ra.cs.unituebingen.de/software/javanns/ 2012/13.
Intelligens orvosi műszerek (VIMIA023) Gyakorló feladatok, megoldással (2016 ősz)
 Gyakorló feladatok, megoldással (2016 ősz)") Intelligens orvosi műszerek (VIMIA23) Gyakorló feladatok, megoldással (216 ősz) Régi zárthelyi- és vizsgafeladatok, egyéb feladatok megoldással. Nem jelenti azt, hogy pontosan ezek, vagy pontosan ilyenek
Intelligens orvosi műszerek (VIMIA23) Gyakorló feladatok, megoldással (216 ősz) Régi zárthelyi- és vizsgafeladatok, egyéb feladatok megoldással. Nem jelenti azt, hogy pontosan ezek, vagy pontosan ilyenek
Gépi tanulás. Egyszerű döntés tanulása (döntési fák) (Részben Dobrowiecki Tadeusz fóliáinak átdolgozásával) Pataki Béla (Bolgár Bence)
 (Részben Dobrowiecki Tadeusz fóliáinak átdolgozásával) Pataki Béla (Bolgár Bence)") Gépi tanulás Egyszerű döntés tanulása (döntési fák) (Részben Dobrowiecki Tadeusz fóliáinak átdolgozásával) Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki
Gépi tanulás Egyszerű döntés tanulása (döntési fák) (Részben Dobrowiecki Tadeusz fóliáinak átdolgozásával) Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki
Méréselmélet MI BSc 1
 Mérés és s modellezés 2008.02.15. 1 Méréselmélet - bevezetés a mérnöki problémamegoldás menete 1. A probléma kitűzése 2. A hipotézis felállítása 3. Kísérlettervezés 4. Megfigyelések elvégzése 5. Adatok
Mérés és s modellezés 2008.02.15. 1 Méréselmélet - bevezetés a mérnöki problémamegoldás menete 1. A probléma kitűzése 2. A hipotézis felállítása 3. Kísérlettervezés 4. Megfigyelések elvégzése 5. Adatok
Mérési hibák 2006.10.04. 1
 Mérési hibák 2006.10.04. 1 Mérés jel- és rendszerelméleti modellje Mérési hibák_labor/2 Mérési hibák mérési hiba: a meghatározandó értékre a mérés során kapott eredmény és ideális értéke közötti különbség
Mérési hibák 2006.10.04. 1 Mérés jel- és rendszerelméleti modellje Mérési hibák_labor/2 Mérési hibák mérési hiba: a meghatározandó értékre a mérés során kapott eredmény és ideális értéke közötti különbség
Nem teljesen kitöltött páros összehasonlítás mátrixok sajátérték optimalizálása Newton-módszerrel p. 1/29. Ábele-Nagy Kristóf BCE, ELTE
 Nem teljesen kitöltött páros összehasonlítás mátrixok sajátérték optimalizálása Newton-módszerrel Ábele-Nagy Kristóf BCE, ELTE Bozóki Sándor BCE, MTA SZTAKI 2010. november 4. Nem teljesen kitöltött páros
Nem teljesen kitöltött páros összehasonlítás mátrixok sajátérték optimalizálása Newton-módszerrel Ábele-Nagy Kristóf BCE, ELTE Bozóki Sándor BCE, MTA SZTAKI 2010. november 4. Nem teljesen kitöltött páros
Diszkrét idejű felújítási paradoxon
 Magda Gábor Szaller Dávid Tóvári Endre 2009. 11. 18. X 1, X 2,... független és X-szel azonos eloszlású, pozitív egész értékeket felvevő valószínűségi változó (felújítási idők) P(X M) = 1 valamilyen M N
Magda Gábor Szaller Dávid Tóvári Endre 2009. 11. 18. X 1, X 2,... független és X-szel azonos eloszlású, pozitív egész értékeket felvevő valószínűségi változó (felújítási idők) P(X M) = 1 valamilyen M N
Gépi tanulás a Rapidminer programmal. Stubendek Attila
 Gépi tanulás a Rapidminer programmal Stubendek Attila Rapidminer letöltése Google: download rapidminer Rendszer kiválasztása (iskolai gépeken Other Systems java) Kicsomagolás lib/rapidminer.jar elindítása
Gépi tanulás a Rapidminer programmal Stubendek Attila Rapidminer letöltése Google: download rapidminer Rendszer kiválasztása (iskolai gépeken Other Systems java) Kicsomagolás lib/rapidminer.jar elindítása
Diszkrét matematika 2.C szakirány
 Diszkrét matematika 2.C szakirány 2017. tavasz 1. Diszkrét matematika 2.C szakirány 11. előadás Nagy Gábor nagygabr@gmail.com nagy@compalg.inf.elte.hu compalg.inf.elte.hu/ nagy Komputeralgebra Tanszék
Diszkrét matematika 2.C szakirány 2017. tavasz 1. Diszkrét matematika 2.C szakirány 11. előadás Nagy Gábor nagygabr@gmail.com nagy@compalg.inf.elte.hu compalg.inf.elte.hu/ nagy Komputeralgebra Tanszék
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
A Statisztika alapjai
 A Statisztika alapjai BME A3c Magyar Róbert 2016.05.12. Mi az a Statisztika? A statisztika a valóság számszerű információinak megfigyelésére, összegzésére, elemzésére és modellezésére irányuló gyakorlati
A Statisztika alapjai BME A3c Magyar Róbert 2016.05.12. Mi az a Statisztika? A statisztika a valóság számszerű információinak megfigyelésére, összegzésére, elemzésére és modellezésére irányuló gyakorlati
Branch-and-Bound. 1. Az egészértéketű programozás. a korlátozás és szétválasztás módszere Bevezető Definíció. 11.
 11. gyakorlat Branch-and-Bound a korlátozás és szétválasztás módszere 1. Az egészértéketű programozás 1.1. Bevezető Bizonyos feladatok modellezése kapcsán előfordulhat olyan eset, hogy a megoldás során
11. gyakorlat Branch-and-Bound a korlátozás és szétválasztás módszere 1. Az egészértéketű programozás 1.1. Bevezető Bizonyos feladatok modellezése kapcsán előfordulhat olyan eset, hogy a megoldás során
Van-e kapcsolat a változók között? (példák: fizetés-távolság; felvételi pontszám - görgetett átlag)
") , rangkorreláció Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék 1111, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-16-80 Fax: 463-30-91 http://www.vizgep.bme.hu
, rangkorreláció Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék 1111, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-16-80 Fax: 463-30-91 http://www.vizgep.bme.hu
Többváltozós lineáris regressziós modell feltételeinek
 Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Petrovics Petra Doktorandusz Többváltozós lineáris regressziós modell x 1, x 2,, x p
Többváltozós lineáris regressziós modell feltételeinek tesztelése I. - A hibatagra vonatkozó feltételek tesztelése - Petrovics Petra Doktorandusz Többváltozós lineáris regressziós modell x 1, x 2,, x p
Adaptív dinamikus szegmentálás idősorok indexeléséhez
 Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Kísérlettervezés alapfogalmak
 Kísérlettervezés alapfogalmak Rendszermodellezés Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and Economics Department of Measurement
Kísérlettervezés alapfogalmak Rendszermodellezés Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and Economics Department of Measurement
Számítógépes döntéstámogatás. Statisztikai elemzés
 SZDT-03 p. 1/22 Számítógépes döntéstámogatás Statisztikai elemzés Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Előadás SZDT-03 p. 2/22 Rendelkezésre
SZDT-03 p. 1/22 Számítógépes döntéstámogatás Statisztikai elemzés Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Előadás SZDT-03 p. 2/22 Rendelkezésre
Adatelemzési eljárások az idegrendszer kutatásban Somogyvári Zoltán
 Adatelemzési eljárások az idegrendszer kutatásban Somogyvári Zoltán MTA KFKI Részecske és Magfizikai Intézet, Biofizikai osztály Az egy adatsorra (idősorra) is alkalmazható módszerek Példa: Az epileptikus
Adatelemzési eljárások az idegrendszer kutatásban Somogyvári Zoltán MTA KFKI Részecske és Magfizikai Intézet, Biofizikai osztály Az egy adatsorra (idősorra) is alkalmazható módszerek Példa: Az epileptikus
Minimális feszítőfák Legyen G = (V,E,c), c : E R + egy súlyozott irányítatlan gráf. Terjesszük ki a súlyfüggvényt a T E élhalmazokra:
, c : E R + egy súlyozott irányítatlan gráf. Terjesszük ki a súlyfüggvényt a T E élhalmazokra:") Minimális feszítőfák Legyen G = (V,E,c), c : E R + egy súlyozott irányítatlan gráf. Terjesszük ki a súlyfüggvényt a T E élhalmazokra: C(T ) = (u,v) T c(u,v) Az F = (V,T) gráf minimális feszitőfája G-nek,
Minimális feszítőfák Legyen G = (V,E,c), c : E R + egy súlyozott irányítatlan gráf. Terjesszük ki a súlyfüggvényt a T E élhalmazokra: C(T ) = (u,v) T c(u,v) Az F = (V,T) gráf minimális feszitőfája G-nek,
(Independence, dependence, random variables)
") Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
Két valószínűségi változó együttes vizsgálata Feltételes eloszlások Két diszkrét változó együttes eloszlása a lehetséges értékpárok és a hozzájuk tartozó valószínűségek (táblázat) Példa: Egy urna 3 fehér,
A mérések általános és alapvető metrológiai fogalmai és definíciói. Mérések, mérési eredmények, mérési bizonytalanság. mérés. mérési elv
 Mérések, mérési eredmények, mérési bizonytalanság A mérések általános és alapvető metrológiai fogalmai és definíciói mérés Műveletek összessége, amelyek célja egy mennyiség értékének meghatározása. mérési
Mérések, mérési eredmények, mérési bizonytalanság A mérések általános és alapvető metrológiai fogalmai és definíciói mérés Műveletek összessége, amelyek célja egy mennyiség értékének meghatározása. mérési
y ij = µ + α i + e ij
 Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai
Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai