Stream processing ősz, 10. alkalom Kocsis Imre,
|
|
|
- Lőrinc Ignác Fazekas
- 5 évvel ezelőtt
- Látták:
Átírás

1 Stream processing 2017 ősz, 10. alkalom Kocsis Imre, Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék
2 Az adatfolyam-feldolgozó elem: blokkséma
3 Az adatfolyam-feldolgozó elem 1. Sok forrás 2. Ismeretlen ráta/mintavételi frekvencia

4 Az adatfolyam-feldolgozó elem 1. Many sources 2. With unknown sampling frequency Erőforráskövetelmények
5 Az adatfolyam-feldolgozó elem Folyamonként ad-hoc módon 1. Sok forrás 2. Ismeretlen ráta/mintavételi frekvencia Erőforráskövetelmények


6 Az adatfolyam-feldolgozó elem Folyamonként ad-hoc módon Folyamatos kiértékelés: Minden új maximum 1. Sok forrás 2. Ismeretlen ráta/mintavételi frekvencia Erőforráskövetelmények

7 Tipikus logika: mozgóablakos elemzések Pl. előzőleg felépített autoregresszív modellel előrejelzés o Hol térünk el a predikciótól? o Hol változik a modell?
8 Feldolgozás: időkorlát! Diszk nem használható Megengedett memóriaigény: korlátos Elemenkénti számítási igény: korlátos Szokásos megoldások: o n-esenkénti (tuple) feldolgozási logika o Csúszóablakos tárolás és feldolgozás o Mintavételezés o Közelítő algoritmusok o WCET-menedzsment: skálázási logikán keresztül Illetve lehet heurisztika/mintavétel-hangolás is, de az nehéz

9 Logikai topológia vs deployment Forrás: [2], p 76
![Apache Spark Streaming Apache Storm Eszközök Ábra forrása: [3] IBM](/docs-images/88/115730786/images/10-0.jpg "InfoSphere Streams Amazon Kinesis LinkedIn Apache Samza + kapcsolódó")
10 Apache Spark Streaming Apache Storm Eszközök Ábra forrása: [3] IBM InfoSphere Streams Amazon Kinesis LinkedIn Apache Samza + kapcsolódó projektek
11 APACHE STORM

12 Demo: egy villanykari kollégium Netflow rekordjai
13 Apache Storm Twitter, open source: 2011 Belül: Clojure ( LISP JVM felett ) o Leginkább érdekesség Netflix, Twitter, Yahoo, Spotify, Igazi stream processing o Nem mikrokötegelés (lehet azt is) Elosztott, hibatűrő Alacsony késleltetés Kiváló skálázódás


14 Topológia: kifolyók és villámok Spout 1 Bolt 1 Bolt 3 Spout 2 Bolt 2 DAG topology: data + functions
15 Spouts and bolts Kifolyó: adatfolyam forrása o Failed tuple újrajátszása: fire & forget vagy reliable o Kafka, HDFS, MQTT, Villám: 1 vagy több folyamot feldolgoz o És 0+ létrehoz o Bármi (időkereten belül) filter, join, kibeszélés, o Hbase, HDFS, JDBC, Mongo, Redis, Cassandra, JMS, ElasticSearch, Nyelvi lehetőségek o JVM Java, Scala, Jruby, Clojure, o Akármi (JSON stdin/stdout) Ruby, Python, Javascript, Perl, R,

16 Leterített topológia - fogalmak Ábra forrása:

17 Storm - párhuzamosítás Ábra forrása:

18 Stream-csoportosítás routing Shuffle: random Fields: GROUP BY k,l Partial Key: fields, de terheléselosztva két bolt-ra All: replikálás Global: minden a legkisebb IDjú bolthoz Direct: a küldő oszt Custom
19 Alkalmazás adatfolyam A lementett hálózati adatokat tartalmazó rekordokat fájlból kiolvassuk Egy rekordban szerepel a forrás és cél IP cím, időpont forgalmazott csomagszám adatmennység
20 Alkalmazás adatfolyam A hálózati rekordokat egy adatbázisba küldjük

21 Alkalmazás adatfolyam A Storm alkalmazás első komponense kiolvassa a beküldött rekordokat


22 Alkalmazás adatfolyam Az alkalmazás szempontjából lényegtelen adatokat levágja a rekordokból


23 Alkalmazás adatfolyam Csak az időpontot és a cél IP címet tartalmazó értékpárok lesznek továbbküldve


24 Alkalmazás adatfolyam Egy külső web szolgáltatás segítségével az IP címekhez megkeresi a hozzátartozó országot
")
25 Alkalmazás adatfolyam (időpont, ország) értékpárok


26 Alkalmazás adatfolyam Az adatokat idő alapján aggregálja 3 perces blokkokba Országok szerint összegez Adatbázisba ment

27 Alkalmazás adatfolyam A csúszó ablakból kieső adatok törlésért felel

")
28 Nem a beérkező rekordok hatására ( percenként) Alkalmazás adatfolyam



29 Alkalmazás adatfolyam Ország név és gyakoriság értékpárok Megjelenítés: egyszerű webszolgáltatás és weblap
30 Alkalmazás adatfolyam
31 Szöveges folyamat (topológia) TopologyBuilder builder = new TopologyBuilder(); builder.setspout("redis_spout", new RedisSpout(), 1); builder.setbolt("gatherer", new Gatherer(), 5).shuffleGrouping("redis_spout"); builder.setbolt("locator", new GeoTagger(), 10).shuffleGrouping("gatherer"); builder.setbolt("aggregator", new Aggregator(), 10).fieldsGrouping("locator", new Fields("date")); builder.setspout("timer_spout", new TimerSpout(), 1); builder.setbolt("sweeper", new Sweeper(), 5).shuffleGrouping("timer_spout");
32 Kód példa: szószámlálás
33 Szószámlálás topológiája
34 Amiről nem beszélünk Méretezés o Áteresztőképesség o Késleltetés o Rate limiting mechanizmsok Architektúra o Terítés, erőforráskezelés (semmi, YARN, Mesos, ) o Topológia-koordináció: ZooKeeper o nem kötelezően kötött a Hadoop stackhez o HDFS és YARN kellhet; Kafka integráció valószínűleg fontosabb További használati módok o DRPC (Distributed RPC), folyamatosan futó számítások


35 Valamikor réges-régen o MQ, pub/sub o WebSphere MQ, JMS, Kafka + Storm Innováció o F/OSS o DC elosztott, real time, nagy áteresztőképességű, hibatűrő, perzisztens pub/sub stream-ek pl. Kafka o Embedded/IoT/CPS alacsony overhead, nyílt, esetleg brokerless pl. OMG DDS


36 Ábrák forrása: Apache Kafka
37 Apache Kafka Producer dönti el a partícióba rendelést Egy P-t CG-onként egy C olvashat, de több CG (sub) Írás és olvasás szigorúan rendezett partíciónként N- szeres partíció-replikáció: N-1 hiba tűrése Ábrák forrása:
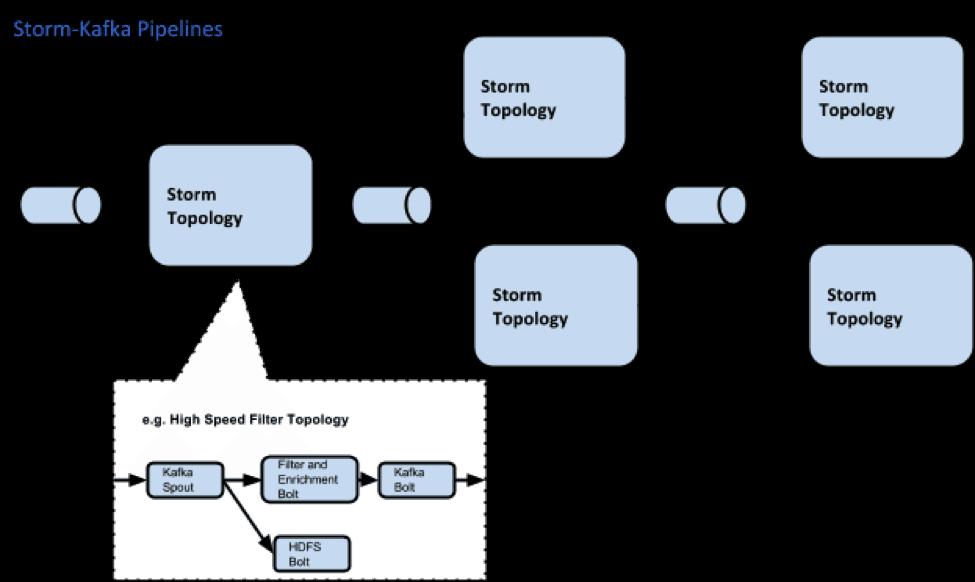
38 Kafka + Storm Ábra forrása:

39 Mikrokötegelés (microbatching) A mikro azért relatív
40 Magas szintű microbatching: Trident Állapot-definíció Query-definíció Lekérdezés


41 Magas szintű microbatching: Trident Karbantartott állapot Állapot-definíció Karbantartott állapot Query-definíció Lekérdezés
42 SPARK STREAMING
43 Sparks streaming

44 Fogadók és mikrokötegek
45 Példa tabricks_guide/07%20spark%20streaming/01%20 Streaming%20Word%20Count%20-%20Scala.html
46 ALKALMAZÁSI MINTÁK
![Forrás: [2], p 80](/docs-images/88/115730786/images/47-0.jpg)
47 Forrás: [2], p 80 Alkalmazás-osztályok
![Forrás: [2], 3.](/docs-images/88/115730786/images/48-0.jpg "2 alfejezet Tervezési")
48 Forrás: [2], 3.2 alfejezet Tervezési minták: filter

49 Tervezési minták: outliers

50 Tervezési minták: parallel


51 Tervezési minták: supplemental data Lassan/nem változó referenciaadatokkal dúsítás

52 Tervezési minták: consolidation Pl. időablakos join
 különböző")
53 Tervezési minták: merge Azonos információ, (formailag) különböző folyamok
54 ALGORITMIKAI SZEMELVÉNYEK
55 Folyam-algoritmikai szemelvények A számítási modellt láttuk Fő korlát: adott tár + WCET, be nem látott adat Néhány tipikus probléma o Mintavételezett kulcstér, kulcsok minden értéke o Elég jó halmazba tartozás-szűrés kicsi leíróval o Count distinct korlátos tárral o Momentumok Részletes tárgyalás: [1] 4. fejezete
 h(k ) o Vödrös hash-elés, http://en.wikipedia.")
56 Kitérő: hash-függvények Cél: U nem rendezett univerzum elemein (átlagosan) gyors keresés, beszúrás, törlés, módosítás Eszköz: h hash függvény, ami rekordhoz logikai címet rendel o A címtartomány jellemzően sokkal kisebb, mint U o Ütközések: K K h(k) h(k ) o Vödrös hash-elés,
57 Hash-függvények: jellemző követelmények Alkalmazási területenként eltérőek! o Kriptográfia indexelés adattároláshoz Néhány tipikus követelmény o Determinizmus o Uniformitás o Meghatározott értékkészlet o Folytonosság o Irreverzibilitás ( egyirányú függvény)
58 Mintavételezés Modell: o n komponensű elemek o ezek egy része key (pl. user,query,time) o a kulcsok felett mintavételezünk Probléma o Egy kulcsnak vagy minden értéke megjelenjen, vagy egy sem Megoldás o a/b méretű mintához a (kulcstér)méretű folyamon a kulcsot b vödörbe hasheljük o A hash-függvény valójában konzisztens random-generátor : a < b esetén tárolunk (továbbengedünk) o Nem véges minta kisebb módosítás Példa: a felhasználók mekkora része ismétel meg lekérdezéseket a felhasználók 1/10 mintáján


59 Bloom filterek
60 Szűrés: Bloom filterek Bloom filter: o n bites vektor, kezdetben azonosan 0 o Hash függvények kollekciója: h 1, h 2, h k. Mindegyik kulcsokat rendel n vödörhöz (a vektor elemeinek felelnek meg). o S: kulcshalmaz ( S = m) Cél: minden K S átengedése, a legtöbb K S kiszűrése tárhely-hatékonyan Példa: spam -cím alapján
61 Szűrés: Bloom filterek Indulás: minden j bit-et 1-re állítunk, amire van h i és K S, hogy h i K = j Kulcs tesztelése: minden függvény eredménye 1 értékű bitbe visz-e o Igen: továbbengedés (lehet hogy S-ben) o Nem: dobás (nem lehet S-ben) Kaszkádolható! False positive valószínűség: lásd könyv (darts-modell)
62 Bloom filterek: néhány tétel Hibás pozitív valószínűség (uniform hashekkel): o (1 e km/n ) k Optimális hashfüggvény-szám o k = n m ln2
63 Count-Distinct : a Flajolet-Martin algoritmus N.B. nem-algoritmikai megoldások is működhetnek Legyen egy bit-sztring hash-függvénynek több kimenete, mint az univerzum elemei o Pl. 64 bit elég az URL-ekhez Ezekből sokat alkalmazunk h a a folyam-elemre r 0-ban végződik (tail length). Legyen ezek maximuma R. Count-Distinct közelítés: 2 R o Ha m 2 r, akkor szinte biztos van legalább r hosszú farok o Ha m 2 r, akkor szinte biztos nincs legalább r hosszú farok Sok hash függvény, kis csoportok (legalább c log 2 m) átlaga, ezek mediánja
64 Count-Distinct : a Flajolet-Martin algoritmus Intuitívan: o Egy a ra h a legalább r 0-ban végződik: 2 r val. (Uniform hash azért nem árt.) o m különböző elem, egyikükre sem legalább r hosszú a tail: r m 1 2 m2 r o Átírható: 1 2 r 2r o Elég nagy r-re a belső tag 1 e o Nincs elem legalább r hosszú tail-el: e m2 r val. o m jóval nagyobb, mint 2 r : szinte biztosan látunk legalább r hosszút o m jóval kisebb, mint 2 r : szinte biztosan nem látunk r hosszút o 2 R nem valószínű, hogy túl nagy vagy túl kicsi lenne o Kiátlagolás önmagában nem jó: túl nagy a felfelé nagyot tévedő 2 R -ek hatása o Medián sem jó: mindig 2 hatvány, 2 x+1 2 x egyre nagyobb, szoros becslést nem tud adni
65 Rendezett univerzum Momentumok m i : i-ik elem előfordulási száma Stream k-adrendű momentuma (k-ik momentum): i(m i ) k Néhány momentum o 0: count distinct o 1: stream hossza o 2: előfordulások négyzetösszege surprise number: eloszlás egyenetlensége V.ö. I ω n = log(p(ω n ))
66 Az Alon-Matias-Szegedy algoritmus Legyen a stream n hosszú, Nem tudunk minden m i -t tárolni, Második momentum közelítése, Korlátos tárhellyel (több jobb közelítés) o Elemei változók Minden X változónkhoz tárolni fogjuk: o Az univerzum egy elemét: X. element o Egy X. value egészet. Inicializálás: uniform, véletlenszerű választással 1 és n között pozíciót rendelünk minden változóhoz. X. element: amit a pozíciókban találunk X. value: előfordulások száma a sorsolt kezdőpozíciótól
67 Az Alon-Matias-Szegedy algoritmus Minden X-ből lehet becsülni: n (2 X. value 1) Legyen e i a stream i-ik eleme; legyen c(i) ezen elem előfordulási száma az i-ik pozíciótól. Első lépés: a kifejezés várhatóértéke az uniform módon választott pozíciókon egy átlag. E n(2 X. value 1) = 1 n n i=1 n 2 c i 1 = n i=1 (2c i 1)
68 Az Alon-Matias-Szegedy algoritmus Tekintsünk egy a elemet, ami m a -szor fordul elő. n i=1 (2c i 1)-ben a kontribúciói hátulról : Utolsó előfordulása: 2x1 1 = 1 Azelőtti: 2x2 1 = 3 Összes: (m a 1) n i=1 (2c i 1) szétbontható ilyen csoportokra! Akkor E n(2 X. value 1) = a (m a 1)
69 Az Alon-Matias-Szegedy algoritmus Indukcióval: m a 1 = m a 2 m a Vagy egyszerűen x=1 2x 1 átrendezés Így: E 2 X. value + 1 = a m a 2
70 Az Alon-Matias-Szegedy algoritmus k-ik momentumra: v = X. value n (v k v 1 k ) Kiterjesztés nem véges stream-ekre: o Nem a tárolás, hanem a korai elemekkel elfogultság a probléma o Mindig s változót tárolunk, inicializáció s o Minden új elemet valószínűséggel választunk n+1 változónak o Ha választjuk, egy régit eldobunk o Megmutatható: így a pozíció-kiválasztási valószínűség egyenletes eloszlású marad
71 Hivatkozások [1] Rajaraman, A., & Ullman, J. D. (2011). Mining of Massive Datasets. Cambridge: Cambridge University Press. doi: /cbo [2] International Technical Support Organization. IBM InfoSphere Streams: Harnessing Data in Motion. September [3] [4] [5]
Stream Processing. Big Data elemzési módszerek. Kocsis Imre
 Stream Processing Big Data elemzési módszerek Kocsis Imre ikocsis@mit.bme.hu 2014.11.12. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Szenzor-adatok Adatfolyam-források
Stream Processing Big Data elemzési módszerek Kocsis Imre ikocsis@mit.bme.hu 2014.11.12. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Szenzor-adatok Adatfolyam-források
Házi Feladat. 3 fős csapatok o Javasolt: legyen benne > másodéves informatikus
 HÁZI FELADAT Házi Feladat 3 fős csapatok o Javasolt: legyen benne > másodéves informatikus Feladatválasztás listából o Eseti elbírálással: hozott feladat o Kiírások: honlap o Jelentkezés: form Teljesítés
HÁZI FELADAT Házi Feladat 3 fős csapatok o Javasolt: legyen benne > másodéves informatikus Feladatválasztás listából o Eseti elbírálással: hozott feladat o Kiírások: honlap o Jelentkezés: form Teljesítés
Folyamatmodellezés (BPMN) és alkalmazásai
 és alkalmazásai") Folyamatmodellezés (BPMN) és alkalmazásai Rendszermodellezés 2018. Budapesti Műszaki és Gazdaságtudományi Egyetem Hibatűrő Rendszerek Kutatócsoport Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika
Folyamatmodellezés (BPMN) és alkalmazásai Rendszermodellezés 2018. Budapesti Műszaki és Gazdaságtudományi Egyetem Hibatűrő Rendszerek Kutatócsoport Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika
RHadoop. Kocsis Imre Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék
 RHadoop Kocsis Imre ikocsis@mit.bme.hu Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Házi feladat Csapatépítés o 2 fő, tetszőleges kombinációkban http://goo.gl/m8yzwq
RHadoop Kocsis Imre ikocsis@mit.bme.hu Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Házi feladat Csapatépítés o 2 fő, tetszőleges kombinációkban http://goo.gl/m8yzwq
GENERÁCIÓS ADATBÁZISOK A BIG DATA KÜLÖNBÖZŐ TERÜLETEIN
 INFORMATIKAI PROJEKTELLENŐR 30 MB Szabó Csenger ÚJ GENERÁCIÓS ADATBÁZISOK A BIG DATA KÜLÖNBÖZŐ TERÜLETEIN 2016. 12. 31. MMK- Informatikai projektellenőr képzés Big Data definíció 2016. 12. 31. MMK-Informatikai
INFORMATIKAI PROJEKTELLENŐR 30 MB Szabó Csenger ÚJ GENERÁCIÓS ADATBÁZISOK A BIG DATA KÜLÖNBÖZŐ TERÜLETEIN 2016. 12. 31. MMK- Informatikai projektellenőr képzés Big Data definíció 2016. 12. 31. MMK-Informatikai
Folyamatmodellezés (BPMN), adatfolyamhálók
, adatfolyamhálók") Folyamatmodellezés (BPMN), adatfolyamhálók Rendszermodellezés 2015. Budapesti Műszaki és Gazdaságtudományi Egyetem Hibatűrő Rendszerek Kutatócsoport Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika
Folyamatmodellezés (BPMN), adatfolyamhálók Rendszermodellezés 2015. Budapesti Műszaki és Gazdaságtudományi Egyetem Hibatűrő Rendszerek Kutatócsoport Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika
Folyamatmodellezés (BPMN), adatfolyamhálók
, adatfolyamhálók") Folyamatmodellezés (BPMN), adatfolyamhálók Rendszermodellezés 2016. Budapesti Műszaki és Gazdaságtudományi Egyetem Hibatűrő Rendszerek Kutatócsoport Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika
Folyamatmodellezés (BPMN), adatfolyamhálók Rendszermodellezés 2016. Budapesti Műszaki és Gazdaságtudományi Egyetem Hibatűrő Rendszerek Kutatócsoport Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika
MMK-Informatikai projekt ellenőr képzés 4
 Miről lesz szó Big Data definíció Mi a Hadoop Hadoop működése, elemei Köré épülő technológiák Disztribúciók, Big Data a felhőben Miért, hol és hogyan használják Big Data definíció Miért Big a Data? 2017.
Miről lesz szó Big Data definíció Mi a Hadoop Hadoop működése, elemei Köré épülő technológiák Disztribúciók, Big Data a felhőben Miért, hol és hogyan használják Big Data definíció Miért Big a Data? 2017.
Mintavételezés, szűrés, kilógó esetek detektálása
 Mintavételezés, szűrés, kilógó esetek detektálása Salánki Ágnes salanki@mit.bme.hu Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology
Mintavételezés, szűrés, kilógó esetek detektálása Salánki Ágnes salanki@mit.bme.hu Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology
Muppet: Gyors adatok MapReduce stílusú feldolgozása. Muppet: MapReduce-Style Processing of Fast Data
 Muppet: Gyors adatok MapReduce stílusú feldolgozása Muppet: MapReduce-Style Processing of Fast Data Tartalom Bevezető MapReduce MapUpdate Muppet 1.0 Muppet 2.0 Eredmények Jelenlegi tendenciák Nagy mennyiségű
Muppet: Gyors adatok MapReduce stílusú feldolgozása Muppet: MapReduce-Style Processing of Fast Data Tartalom Bevezető MapReduce MapUpdate Muppet 1.0 Muppet 2.0 Eredmények Jelenlegi tendenciák Nagy mennyiségű
KÖZELÍTŐ INFERENCIA II.
 STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
KÖZELÍTŐ INFERENCIA II.
 STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
Elosztott adatbázis-kezelő formális elemzése
 Elosztott adatbázis-kezelő formális elemzése Szárnyas Gábor szarnyas@mit.bme.hu 2014. december 10. Budapesti Műszaki és Gazdaságtudományi Egyetem Hibatűrő Rendszerek Kutatócsoport Budapesti Műszaki és
Elosztott adatbázis-kezelő formális elemzése Szárnyas Gábor szarnyas@mit.bme.hu 2014. december 10. Budapesti Műszaki és Gazdaságtudományi Egyetem Hibatűrő Rendszerek Kutatócsoport Budapesti Műszaki és
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
Felhők teljesítményelemzése felhő alapokon
 Felhők teljesítményelemzése felhő alapokon Kocsis Imre ikocsis@mit.bme.hu HTE Infokom 2014 Budapest University of Technology and Economics Department of Measurement and Information Systems 1 IT Szolgáltatásmenedzsment
Felhők teljesítményelemzése felhő alapokon Kocsis Imre ikocsis@mit.bme.hu HTE Infokom 2014 Budapest University of Technology and Economics Department of Measurement and Information Systems 1 IT Szolgáltatásmenedzsment
Big Data elemzési módszerek
 Big Data elemzési módszerek 2015.09.09. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Előadók, közreműködők o dr. Pataricza András o Dr. Horváth Gábor o
Big Data elemzési módszerek 2015.09.09. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Előadók, közreműködők o dr. Pataricza András o Dr. Horváth Gábor o
IBM SPSS Modeler 18.2 Újdonságok
 IBM SPSS Modeler 18.2 Újdonságok 1 2 Új, modern megjelenés Vizualizáció fejlesztése Újabb algoritmusok (Python, Spark alapú) View Data, t-sne, e-plot GMM, HDBSCAN, KDE, Isotonic-Regression 3 Új, modern
IBM SPSS Modeler 18.2 Újdonságok 1 2 Új, modern megjelenés Vizualizáció fejlesztése Újabb algoritmusok (Python, Spark alapú) View Data, t-sne, e-plot GMM, HDBSCAN, KDE, Isotonic-Regression 3 Új, modern
Big Data adattárházas szemmel. Arató Bence ügyvezető, BI Consulting
 Big Data adattárházas szemmel Arató Bence ügyvezető, BI Consulting 1 Bemutatkozás 15 éves szakmai tapasztalat az üzleti intelligencia és adattárházak területén A BI Consulting szakmai igazgatója A BI.hu
Big Data adattárházas szemmel Arató Bence ügyvezető, BI Consulting 1 Bemutatkozás 15 éves szakmai tapasztalat az üzleti intelligencia és adattárházak területén A BI Consulting szakmai igazgatója A BI.hu
Mintavételezés, szűrés, outlierek detektálása
 Mintavételezés, szűrés, outlierek detektálása Salánki Ágnes salanki@mit.bme.hu Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and
Mintavételezés, szűrés, outlierek detektálása Salánki Ágnes salanki@mit.bme.hu Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and
Alternatív adatbázisok Gráfadatbázisok
 Alternatív adatbázisok Gráfadatbázisok Adatbázis típusok Relációs PostgreSQL, Oracle, MySQL, stb. Dokumentum MongoDB, CouchDB, OrientDB Gráfadatbázis Neo4J, OrientDB, ArangoDB, InfiniteGraph Key-value
Alternatív adatbázisok Gráfadatbázisok Adatbázis típusok Relációs PostgreSQL, Oracle, MySQL, stb. Dokumentum MongoDB, CouchDB, OrientDB Gráfadatbázis Neo4J, OrientDB, ArangoDB, InfiniteGraph Key-value
Információs Rendszerek Szakirány
 Információs Rendszerek Szakirány Laki Sándor Kommunikációs Hálózatok Kutatócsoport ELTE IK - Információs Rendszerek Tanszék lakis@elte.hu http://lakis.web.elte.hu Információs Rendszerek szakirány Közös
Információs Rendszerek Szakirány Laki Sándor Kommunikációs Hálózatok Kutatócsoport ELTE IK - Információs Rendszerek Tanszék lakis@elte.hu http://lakis.web.elte.hu Információs Rendszerek szakirány Közös
Adatbázisok. 8. gyakorlat. SQL: CREATE TABLE, aktualizálás (INSERT, UPDATE, DELETE), SELECT október október 26. Adatbázisok 1 / 17
, SELECT október október 26. Adatbázisok 1 / 17") Adatbázisok 8. gyakorlat SQL: CREATE TABLE, aktualizálás (INSERT, UPDATE, DELETE), SELECT 2015. október 26. 2015. október 26. Adatbázisok 1 / 17 SQL nyelv Structured Query Language Struktúrált lekérdez
Adatbázisok 8. gyakorlat SQL: CREATE TABLE, aktualizálás (INSERT, UPDATE, DELETE), SELECT 2015. október 26. 2015. október 26. Adatbázisok 1 / 17 SQL nyelv Structured Query Language Struktúrált lekérdez
Big Data tömeges adatelemzés gyorsan
 MEDIANET 2015 Big Data tömeges adatelemzés gyorsan STADLER GELLÉRT Oracle Hungary Kft. gellert.stadler@oracle.com Kulcsszavak: big data, döntéstámogatás, hadoop, üzleti intelligencia Az utóbbi években
MEDIANET 2015 Big Data tömeges adatelemzés gyorsan STADLER GELLÉRT Oracle Hungary Kft. gellert.stadler@oracle.com Kulcsszavak: big data, döntéstámogatás, hadoop, üzleti intelligencia Az utóbbi években
Algoritmuselmélet 6. előadás
 Algoritmuselmélet 6. előadás Katona Gyula Y. Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi Tsz. I. B. 137/b kiskat@cs.bme.hu 2002 Március 4. ALGORITMUSELMÉLET 6. ELŐADÁS 1 Hash-elés
Algoritmuselmélet 6. előadás Katona Gyula Y. Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi Tsz. I. B. 137/b kiskat@cs.bme.hu 2002 Március 4. ALGORITMUSELMÉLET 6. ELŐADÁS 1 Hash-elés
Algoritmuselmélet. Hashelés. Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem
 Algoritmuselmélet Hashelés Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 8. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet 8. előadás
Algoritmuselmélet Hashelés Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 8. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet 8. előadás
KÓDOLÁSTECHNIKA PZH. 2006. december 18.
 KÓDOLÁSTECHNIKA PZH 2006. december 18. 1. Hibajavító kódolást tekintünk. Egy lineáris bináris blokk kód generátormátrixa G 10110 01101 a.) Adja meg a kód kódszavait és paramétereit (n, k,d). (3 p) b.)
KÓDOLÁSTECHNIKA PZH 2006. december 18. 1. Hibajavító kódolást tekintünk. Egy lineáris bináris blokk kód generátormátrixa G 10110 01101 a.) Adja meg a kód kódszavait és paramétereit (n, k,d). (3 p) b.)
Folyamatmodellezés és eszközei. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék
 Folyamatmodellezés és eszközei Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Folyamat, munkafolyamat Ez vajon egy állapotgép-e? Munkafolyamat (Workflow):
Folyamatmodellezés és eszközei Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Folyamat, munkafolyamat Ez vajon egy állapotgép-e? Munkafolyamat (Workflow):
Hálózati réteg. WSN topológia. Útvonalválasztás.
 Hálózati réteg WSN topológia. Útvonalválasztás. Tartalom Hálózati réteg WSN topológia Útvonalválasztás 2015. tavasz Szenzorhálózatok és alkalmazásaik (VITMMA09) - Okos város villamosmérnöki MSc mellékspecializáció,
Hálózati réteg WSN topológia. Útvonalválasztás. Tartalom Hálózati réteg WSN topológia Útvonalválasztás 2015. tavasz Szenzorhálózatok és alkalmazásaik (VITMMA09) - Okos város villamosmérnöki MSc mellékspecializáció,
Adatbázis-lekérdezés. Az SQL nyelv. Makány György
 Adatbázis-lekérdezés Az SQL nyelv Makány György SQL (Structured Query Language=struktúrált lekérdező nyelv): relációs adatbázisok adatainak visszakeresésére, frissítésére, kezelésére szolgáló nyelv. Születési
Adatbázis-lekérdezés Az SQL nyelv Makány György SQL (Structured Query Language=struktúrált lekérdező nyelv): relációs adatbázisok adatainak visszakeresésére, frissítésére, kezelésére szolgáló nyelv. Születési
webalkalmazások fejlesztése elosztott alapon
 1 Nagy teljesítményű és magas rendelkezésreállású webalkalmazások fejlesztése elosztott alapon Nagy Péter Termékmenedzser Agenda Java alkalmazás grid Coherence Topológiák Architektúrák
1 Nagy teljesítményű és magas rendelkezésreállású webalkalmazások fejlesztése elosztott alapon Nagy Péter Termékmenedzser Agenda Java alkalmazás grid Coherence Topológiák Architektúrák
Az adatok a vállalat kulcsfontosságú erőforrásai. Az információs rendszer adatai kezelésének két alapvető változata:
 ADATSZERVEZÉS Az adatok a vállalat kulcsfontosságú erőforrásai. Az információs rendszer adatai kezelésének két alapvető változata: fájlrendszerek (a konvencionális módszer) és adatbázis rendszerek (a haladóbb
ADATSZERVEZÉS Az adatok a vállalat kulcsfontosságú erőforrásai. Az információs rendszer adatai kezelésének két alapvető változata: fájlrendszerek (a konvencionális módszer) és adatbázis rendszerek (a haladóbb
Adatbányászati szemelvények MapReduce környezetben
 Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
KORSZERŰ BIG DATA FELDOLGOZÓ KERETRENDSZEREK. 2014.02.03. Hermann Gábor MTA-SZTAKI
 KORSZERŰ BIG DATA FELDOLGOZÓ KERETRENDSZEREK 2014.02.03. Hermann Gábor MTA-SZTAKI MI AZ A BIG DATA? MI AZ A BIG DATA? Sok adat! ENNYI? BIG DATA 4V Volume Velocity Variety Veracity +3V (7V) Variability
KORSZERŰ BIG DATA FELDOLGOZÓ KERETRENDSZEREK 2014.02.03. Hermann Gábor MTA-SZTAKI MI AZ A BIG DATA? MI AZ A BIG DATA? Sok adat! ENNYI? BIG DATA 4V Volume Velocity Variety Veracity +3V (7V) Variability
Történet John Little (1970) (Management Science cikk)
 (Management Science cikk)") Információ menedzsment Szendrői Etelka Rendszer- és Szoftvertechnológia Tanszék szendroi@witch.pmmf.hu Vezetői információs rendszerek Döntéstámogató rendszerek (Decision Support Systems) Döntések információn
Információ menedzsment Szendrői Etelka Rendszer- és Szoftvertechnológia Tanszék szendroi@witch.pmmf.hu Vezetői információs rendszerek Döntéstámogató rendszerek (Decision Support Systems) Döntések információn
Intelligens Rendszerek Elmélete. Versengéses és önszervező tanulás neurális hálózatokban
 Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Mesterséges neurális hálózatok II. - A felügyelt tanítás paraméterei, gyorsító megoldásai - Versengéses tanulás
 Mesterséges neurális hálózatok II. - A felügyelt tanítás paraméterei, gyorsító megoldásai - Versengéses tanulás http:/uni-obuda.hu/users/kutor/ IRE 7/50/1 A neurális hálózatok általános jellemzői 1. A
Mesterséges neurális hálózatok II. - A felügyelt tanítás paraméterei, gyorsító megoldásai - Versengéses tanulás http:/uni-obuda.hu/users/kutor/ IRE 7/50/1 A neurális hálózatok általános jellemzői 1. A
Adatbázis-kezelő rendszerek. dr. Siki Zoltán
 Adatbázis-kezelő rendszerek I. dr. Siki Zoltán Adatbázis fogalma adatok valamely célszerűen rendezett, szisztéma szerinti tárolása Az informatika elterjedése előtt is számos adatbázis létezett pl. Vállalati
Adatbázis-kezelő rendszerek I. dr. Siki Zoltán Adatbázis fogalma adatok valamely célszerűen rendezett, szisztéma szerinti tárolása Az informatika elterjedése előtt is számos adatbázis létezett pl. Vállalati
Digitális jelfeldolgozás
 Digitális jelfeldolgozás Kvantálás Magyar Attila Pannon Egyetem Műszaki Informatikai Kar Villamosmérnöki és Információs Rendszerek Tanszék magyar.attila@virt.uni-pannon.hu 2010. szeptember 15. Áttekintés
Digitális jelfeldolgozás Kvantálás Magyar Attila Pannon Egyetem Műszaki Informatikai Kar Villamosmérnöki és Információs Rendszerek Tanszék magyar.attila@virt.uni-pannon.hu 2010. szeptember 15. Áttekintés
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
Párhuzamosítás adatbáziskezelő rendszerekben
 Párhuzamosítás adatbáziskezelő rendszerekben Erős Levente, 2018. 1 Párhuzamos műveletvégzés Miért? Nagy adatmennyiségek Nagyságrendileg nő a keletkező/feldolgozandó/tárolandó adat mennyisége Célhardver
Párhuzamosítás adatbáziskezelő rendszerekben Erős Levente, 2018. 1 Párhuzamos műveletvégzés Miért? Nagy adatmennyiségek Nagyságrendileg nő a keletkező/feldolgozandó/tárolandó adat mennyisége Célhardver
Adatszerkezetek Hasító táblák. Dr. Iványi Péter
 Adatszerkezetek Hasító táblák Dr. Iványi Péter 1 Hash tábla A bináris fáknál O(log n) a legjobb eset a keresésre. Ha valamilyen közvetlen címzést használunk, akkor akár O(1) is elérhető. A hash tábla a
Adatszerkezetek Hasító táblák Dr. Iványi Péter 1 Hash tábla A bináris fáknál O(log n) a legjobb eset a keresésre. Ha valamilyen közvetlen címzést használunk, akkor akár O(1) is elérhető. A hash tábla a
Teljesítménymodellezés
 Teljesítménymodellezés Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and Economics Department of Measurement and Information Systems
Teljesítménymodellezés Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and Economics Department of Measurement and Information Systems
Adatbázisok-1 előadás Előadó: dr. Hajas Csilla
 Adatbázisok-1 előadás Előadó: dr. Hajas Csilla Áttekintés az I.zh-ig Áttekintés az 1ZH-ig // Adatbázisok-1 elıadás // Ullman (Stanford) tananyaga alapján // Hajas Csilla (ELTE IK) 1 Hol tartunk? Mit tanultunk
Adatbázisok-1 előadás Előadó: dr. Hajas Csilla Áttekintés az I.zh-ig Áttekintés az 1ZH-ig // Adatbázisok-1 elıadás // Ullman (Stanford) tananyaga alapján // Hajas Csilla (ELTE IK) 1 Hol tartunk? Mit tanultunk
Struktúra nélküli adatszerkezetek
 Struktúra nélküli adatszerkezetek Homogén adatszerkezetek (minden adatelem azonos típusú) osztályozása Struktúra nélküli (Nincs kapcsolat az adatelemek között.) Halmaz Multihalmaz Asszociatív 20:24 1 A
Struktúra nélküli adatszerkezetek Homogén adatszerkezetek (minden adatelem azonos típusú) osztályozása Struktúra nélküli (Nincs kapcsolat az adatelemek között.) Halmaz Multihalmaz Asszociatív 20:24 1 A
Algoritmuselmélet. Hashelés. Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem
 Algoritmuselmélet Hashelés Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 9. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet 9. előadás
Algoritmuselmélet Hashelés Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 9. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet 9. előadás
Nagy méretű adathalmazok vizualizációja
 Nagy méretű adathalmazok vizualizációja Big Data elemzési módszerek Kocsis Imre, Salánki Ágnes ikocsis, salanki@mit.bme.hu 2014.10.15. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs
Nagy méretű adathalmazok vizualizációja Big Data elemzési módszerek Kocsis Imre, Salánki Ágnes ikocsis, salanki@mit.bme.hu 2014.10.15. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs
The modular mitmót system. DPY kijelző kártya C API
 The modular mitmót system DPY kijelző kártya C API Dokumentációkód: -D 01.0.0.0 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Beágyazott Információs Rendszerek
The modular mitmót system DPY kijelző kártya C API Dokumentációkód: -D 01.0.0.0 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Beágyazott Információs Rendszerek
Adaptív dinamikus szegmentálás idősorok indexeléséhez
 Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Hadoop és használata az LPDS cloud-on
 Hadoop és használata az LPDS cloud-on Bendig Loránd lbendig@ilab.sztaki.hu 2012.04.13 Miről lesz szó? Bevezetés Hadoop áttekintés OpenNebula Hadoop cluster az LPDS cloud-on Tapasztalatok, nyitott kérdések
Hadoop és használata az LPDS cloud-on Bendig Loránd lbendig@ilab.sztaki.hu 2012.04.13 Miről lesz szó? Bevezetés Hadoop áttekintés OpenNebula Hadoop cluster az LPDS cloud-on Tapasztalatok, nyitott kérdések
Virtuális Obszervatórium. Gombos Gergő
 Virtuális Obszervatórium Gombos Gergő Áttekintés Motiváció, probléma felvetés Megoldások Virtuális obszervatóriumok NMVO Twitter VO Gombos Gergő Virtuális Obszervatórium 2 Motiváció Tudományos módszer
Virtuális Obszervatórium Gombos Gergő Áttekintés Motiváció, probléma felvetés Megoldások Virtuális obszervatóriumok NMVO Twitter VO Gombos Gergő Virtuális Obszervatórium 2 Motiváció Tudományos módszer
Adatbázis-kezelés. Harmadik előadás
 Adatbázis-kezelés Harmadik előadás 39 Műveletek csoportosítása DDL adat definiálás Objektum létrehozás CREATE Objektum törlés DROP Objektum módosítás ALTER DML adat módosítás Rekord felvitel INSERT Rekord
Adatbázis-kezelés Harmadik előadás 39 Műveletek csoportosítása DDL adat definiálás Objektum létrehozás CREATE Objektum törlés DROP Objektum módosítás ALTER DML adat módosítás Rekord felvitel INSERT Rekord
Sapientia Egyetem, Matematika-Informatika Tanszék.
 Kriptográfia és Információbiztonság 7. előadás Sapientia Egyetem, Matematika-Informatika Tanszék Marosvásárhely, Románia mgyongyi@ms.sapientia.ro 2018 Miről volt szó az elmúlt előadáson? Kriptográfiai
Kriptográfia és Információbiztonság 7. előadás Sapientia Egyetem, Matematika-Informatika Tanszék Marosvásárhely, Románia mgyongyi@ms.sapientia.ro 2018 Miről volt szó az elmúlt előadáson? Kriptográfiai
Tipikus időbeli internetezői profilok nagyméretű webes naplóállományok alapján
 Tipikus időbeli internetezői profilok nagyméretű webes naplóállományok alapján Schrádi Tamás schraditamas@aut.bme.hu Automatizálási és Alkalmazott Informatikai Tanszék BME A feladat A webszerverek naplóállományainak
Tipikus időbeli internetezői profilok nagyméretű webes naplóállományok alapján Schrádi Tamás schraditamas@aut.bme.hu Automatizálási és Alkalmazott Informatikai Tanszék BME A feladat A webszerverek naplóállományainak
BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA CLOUD-ON KACSUK PÉTER, NAGY ENIKŐ, PINTYE ISTVÁN, HAJNAL ÁKOS, LOVAS RÓBERT
 BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA CLOUD-ON KACSUK PÉTER, NAGY ENIKŐ, PINTYE ISTVÁN, HAJNAL ÁKOS, LOVAS RÓBERT TARTALOM MTA Cloud Big Data és gépi tanulást támogató szoftver eszközök Apache Spark
BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA CLOUD-ON KACSUK PÉTER, NAGY ENIKŐ, PINTYE ISTVÁN, HAJNAL ÁKOS, LOVAS RÓBERT TARTALOM MTA Cloud Big Data és gépi tanulást támogató szoftver eszközök Apache Spark
Alapszintű formalizmusok
 Alapszintű formalizmusok dr. Majzik István BME Méréstechnika és Információs Rendszerek Tanszék 1 Mit szeretnénk elérni? Informális tervek Informális követelmények Formális modell Formalizált követelmények
Alapszintű formalizmusok dr. Majzik István BME Méréstechnika és Információs Rendszerek Tanszék 1 Mit szeretnénk elérni? Informális tervek Informális követelmények Formális modell Formalizált követelmények
Gelle Kitti Algoritmusok és adatszerkezetek gyakorlat - 07 Hasítótáblák
 Algoritmusok és adatszerkezetek gyakorlat - 07 Hasítótáblák Gelle Kitti 2017. 10. 25. Gelle Kitti Algoritmusok és adatszerkezetek gyakorlat - 07 Hasítótáblák 2017. 10. 25. 1 / 20 Hasítótáblák T 0 h(k 2)
Algoritmusok és adatszerkezetek gyakorlat - 07 Hasítótáblák Gelle Kitti 2017. 10. 25. Gelle Kitti Algoritmusok és adatszerkezetek gyakorlat - 07 Hasítótáblák 2017. 10. 25. 1 / 20 Hasítótáblák T 0 h(k 2)
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
Kommunikációs middleware, stream processing
 Kommunikációs middleware, stream processing Szolgáltatásintegráció 2014. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Kérdések Hogyan kommunikálhat két
Kommunikációs middleware, stream processing Szolgáltatásintegráció 2014. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Kérdések Hogyan kommunikálhat két
Számítógépes döntéstámogatás. Genetikus algoritmusok
 BLSZM-10 p. 1/18 Számítógépes döntéstámogatás Genetikus algoritmusok Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu BLSZM-10 p. 2/18 Bevezetés 1950-60-as
BLSZM-10 p. 1/18 Számítógépes döntéstámogatás Genetikus algoritmusok Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu BLSZM-10 p. 2/18 Bevezetés 1950-60-as
Nem klaszterezett index. Klaszterezett index. Beágyazott oszlopok. Index kitöltési faktor. Indexek tulajdonságai
 1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
Adatszerkezetek Adatszerkezet fogalma. Az értékhalmaz struktúrája
 Adatszerkezetek Összetett adattípus Meghatározói: A felvehető értékek halmaza Az értékhalmaz struktúrája Az ábrázolás módja Műveletei Adatszerkezet fogalma Direkt szorzat Minden eleme a T i halmazokból
Adatszerkezetek Összetett adattípus Meghatározói: A felvehető értékek halmaza Az értékhalmaz struktúrája Az ábrázolás módja Műveletei Adatszerkezet fogalma Direkt szorzat Minden eleme a T i halmazokból
Gyakorló feladatok. Az alábbi feladatokon kívül a félév szemináriumi anyagát is nézzék át. Jó munkát! Gaál László
 Gyakorló feladatok Az alábbi feladatokon kívül a félév szemináriumi anyagát is nézzék át. Jó munkát! Gaál László I/. A vizsgaidőszak második napján a hallgatók %-ának az E épületben, %-ának a D épületben,
Gyakorló feladatok Az alábbi feladatokon kívül a félév szemináriumi anyagát is nézzék át. Jó munkát! Gaál László I/. A vizsgaidőszak második napján a hallgatók %-ának az E épületben, %-ának a D épületben,
Searching in an Unsorted Database
 Searching in an Unsorted Database "Man - a being in search of meaning." Plato History of data base searching v1 2018.04.20. 2 History of data base searching v2 2018.04.20. 3 History of data base searching
Searching in an Unsorted Database "Man - a being in search of meaning." Plato History of data base searching v1 2018.04.20. 2 History of data base searching v2 2018.04.20. 3 History of data base searching
Webes alkalmazások fejlesztése 11. előadás. Alkalmazások felhőben. 2015 Giachetta Roberto groberto@inf.elte.hu http://people.inf.elte.
 Eötvös Loránd Tudományegyetem Informatikai Kar Webes alkalmazások fejlesztése 11. előadás Alkalmazások felhőben 2015 Giachetta Roberto groberto@inf.elte.hu http://people.inf.elte.hu/groberto Számítástechnikai
Eötvös Loránd Tudományegyetem Informatikai Kar Webes alkalmazások fejlesztése 11. előadás Alkalmazások felhőben 2015 Giachetta Roberto groberto@inf.elte.hu http://people.inf.elte.hu/groberto Számítástechnikai
Statisztika - bevezetés Méréselmélet PE MIK MI_BSc VI_BSc 1
 Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
RDBMS fejlesztési irányok. Ferris Wheel (óriáskerék) Jim Gray törvényei. Elosztott adatbázisok problémái. Elosztott adatbázisok
 Jim Gray törvényei. Elosztott adatbázisok problémái. Elosztott adatbázisok") 1 RDBMS fejlesztési irányok Column store Tömb adatmodell JIT fordító és vektorizált végrehajtás Ferris wheel (óriáskerék) Elosztott adatbázisok Ferris Wheel (óriáskerék) Optimalizált scan műveletek Table
1 RDBMS fejlesztési irányok Column store Tömb adatmodell JIT fordító és vektorizált végrehajtás Ferris wheel (óriáskerék) Elosztott adatbázisok Ferris Wheel (óriáskerék) Optimalizált scan műveletek Table
Teljesen elosztott adatbányászat pletyka algoritmusokkal. Jelasity Márk Ormándi Róbert, Hegedűs István
 Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Osztott jáva programok automatikus tesztelése. Matkó Imre BBTE, Kolozsvár Informatika szak, IV. Év 2007 január
 Osztott jáva programok automatikus tesztelése Matkó Imre BBTE, Kolozsvár Informatika szak, IV. Év 2007 január Osztott alkalmazások Automatikus tesztelés Tesztelés heurisztikus zaj keltés Tesztelés genetikus
Osztott jáva programok automatikus tesztelése Matkó Imre BBTE, Kolozsvár Informatika szak, IV. Év 2007 január Osztott alkalmazások Automatikus tesztelés Tesztelés heurisztikus zaj keltés Tesztelés genetikus
Statisztikai becslés
 Kabos: Statisztika II. Becslés 1.1 Statisztikai becslés Freedman, D. - Pisani, R. - Purves, R.: Statisztika. Typotex, 2005. Reimann J. - Tóth J.: Valószínűségszámítás és matematikai statisztika. Tankönyvkiadó,
Kabos: Statisztika II. Becslés 1.1 Statisztikai becslés Freedman, D. - Pisani, R. - Purves, R.: Statisztika. Typotex, 2005. Reimann J. - Tóth J.: Valószínűségszámítás és matematikai statisztika. Tankönyvkiadó,
Véletlenszám generátorok és tesztelésük. Tossenberger Tamás
 Véletlenszám generátorok és tesztelésük Tossenberger Tamás Érdekességek Pénzérme feldobó gép: $0,25-os érme 1/6000 valószínűséggel esik az élére 51% eséllyel érkezik a felfelé mutató oldalára Pörgetésnél
Véletlenszám generátorok és tesztelésük Tossenberger Tamás Érdekességek Pénzérme feldobó gép: $0,25-os érme 1/6000 valószínűséggel esik az élére 51% eséllyel érkezik a felfelé mutató oldalára Pörgetésnél
Adatbázis rendszerek. dr. Siki Zoltán
 Adatbázis rendszerek I. dr. Siki Zoltán Adatbázis fogalma adatok valamely célszerűen rendezett, szisztéma szerinti tárolása Az informatika elterjedése előtt is számos adatbázis létezett pl. Vállalati személyzeti
Adatbázis rendszerek I. dr. Siki Zoltán Adatbázis fogalma adatok valamely célszerűen rendezett, szisztéma szerinti tárolása Az informatika elterjedése előtt is számos adatbázis létezett pl. Vállalati személyzeti
Takács Gábor mérnök informatikus, okl. mérnöktanár
 Takács Gábor mérnök informatikus, okl. mérnöktanár takacsg@sze.hu http://rs1.sze.hu/~takacsg/ Big Data Definition Big Data is data that can t be stored or analyzed using traditional tools. Információ tartalom,
Takács Gábor mérnök informatikus, okl. mérnöktanár takacsg@sze.hu http://rs1.sze.hu/~takacsg/ Big Data Definition Big Data is data that can t be stored or analyzed using traditional tools. Információ tartalom,
Bevezetés: az SQL-be
 Bevezetés: az SQL-be Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 2.3. Relációsémák definiálása SQL-ben, adattípusok, kulcsok megadása 02B_BevSQLsemak
Bevezetés: az SQL-be Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 2.3. Relációsémák definiálása SQL-ben, adattípusok, kulcsok megadása 02B_BevSQLsemak
Láncolt listák Témakörök. Lista alapfogalmak
 Láncolt listák szenasi.sandor@nik.bmf.hu PPT 2007/2008 tavasz http://nik.bmf.hu/ppt 1 Lista alapfogalmai Egyirányú egyszerű láncolt lista Egyirányú rendezett láncolt lista Speciális láncolt listák Témakörök
Láncolt listák szenasi.sandor@nik.bmf.hu PPT 2007/2008 tavasz http://nik.bmf.hu/ppt 1 Lista alapfogalmai Egyirányú egyszerű láncolt lista Egyirányú rendezett láncolt lista Speciális láncolt listák Témakörök
Webes alkalmazások fejlesztése 11. előadás. Alkalmazások felhőben. Alkalmazások felhőben Számítástechnikai felhő
 Eötvös Loránd Tudományegyetem Informatikai Kar Webes alkalmazások fejlesztése 11. előadás Számítástechnikai felhő A számítástechnikai felhő (computational cloud) egy olyan szolgáltatás alapú rendszer,
Eötvös Loránd Tudományegyetem Informatikai Kar Webes alkalmazások fejlesztése 11. előadás Számítástechnikai felhő A számítástechnikai felhő (computational cloud) egy olyan szolgáltatás alapú rendszer,
Mintavétel fogalmai STATISZTIKA, BIOMETRIA. Mintavételi hiba. Statisztikai adatgyűjtés. Nem véletlenen alapuló kiválasztás
 STATISZTIKA, BIOMETRIA. Előadás Mintavétel, mintavételi technikák, adatbázis Mintavétel fogalmai A mintavételt meg kell tervezni A sokaság elemei: X, X X N, lehet véges és végtelen Mintaelemek: x, x x
STATISZTIKA, BIOMETRIA. Előadás Mintavétel, mintavételi technikák, adatbázis Mintavétel fogalmai A mintavételt meg kell tervezni A sokaság elemei: X, X X N, lehet véges és végtelen Mintaelemek: x, x x
Adatbáziskezelő-szerver. Relációs adatbázis-kezelők SQL. Házi feladat. Relációs adatszerkezet
 1 2 Adatbáziskezelő-szerver Általában dedikált szerver Optimalizált háttértár konfiguráció Csak OS + adatbázis-kezelő szoftver Teljes memória az adatbázisoké Fő funkciók: Adatok rendezett tárolása a háttértárolón
1 2 Adatbáziskezelő-szerver Általában dedikált szerver Optimalizált háttértár konfiguráció Csak OS + adatbázis-kezelő szoftver Teljes memória az adatbázisoké Fő funkciók: Adatok rendezett tárolása a háttértárolón
Algoritmusok és adatszerkezetek 2.
 Algoritmusok és adatszerkezetek 2. Varga Balázs gyakorlata alapján Készítette: Nagy Krisztián 1. gyakorlat Nyílt címzéses hash-elés A nyílt címzésű hash táblákban a láncolással ellentétben egy indexen
Algoritmusok és adatszerkezetek 2. Varga Balázs gyakorlata alapján Készítette: Nagy Krisztián 1. gyakorlat Nyílt címzéses hash-elés A nyílt címzésű hash táblákban a láncolással ellentétben egy indexen
7. előadás. Karbantartási anomáliák, 1NF, 2NF, 3NF, BCNF. Adatbázisrendszerek előadás november 3.
 7. előadás,,,, Adatbázisrendszerek előadás 2008. november 3. és Debreceni Egyetem Informatikai Kar 7.1 relációs adatbázisokhoz Mit jelent a relációs adatbázis-tervezés? Az csoportosítását, hogy jó relációsémákat
7. előadás,,,, Adatbázisrendszerek előadás 2008. november 3. és Debreceni Egyetem Informatikai Kar 7.1 relációs adatbázisokhoz Mit jelent a relációs adatbázis-tervezés? Az csoportosítását, hogy jó relációsémákat
Szoftverminőségbiztosítás
 NGB_IN003_1 SZE 2017-18/2 (9) Szoftverminőségbiztosítás Specifikáció alapú (black-box) technikák A szoftver mint leképezés Szoftverhiba Hibát okozó bement Hibás kimenet Input Szoftver Output Funkcionális
NGB_IN003_1 SZE 2017-18/2 (9) Szoftverminőségbiztosítás Specifikáció alapú (black-box) technikák A szoftver mint leképezés Szoftverhiba Hibát okozó bement Hibás kimenet Input Szoftver Output Funkcionális
Informatikai alapismeretek Földtudományi BSC számára
 Informatikai alapismeretek Földtudományi BSC számára 2010-2011 Őszi félév Heizlerné Bakonyi Viktória HBV@ludens.elte.hu Titkosítás,hitelesítés Szimmetrikus DES 56 bites kulcs (kb. 1000 év) felcserél, helyettesít
Informatikai alapismeretek Földtudományi BSC számára 2010-2011 Őszi félév Heizlerné Bakonyi Viktória HBV@ludens.elte.hu Titkosítás,hitelesítés Szimmetrikus DES 56 bites kulcs (kb. 1000 év) felcserél, helyettesít
The nontrivial extraction of implicit, previously unknown, and potentially useful information from data.
 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Adatelemzés intelligens módszerekkel Hullám Gábor Adatelemzés hagyományos megközelítésben I. Megválaszolandó
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Adatelemzés intelligens módszerekkel Hullám Gábor Adatelemzés hagyományos megközelítésben I. Megválaszolandó
Adatbányászati technikák (VISZM185) 2015 tavasz
 2015 tavasz") Adatbányászati technikák (VISZM185) 2015 tavasz Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2015. február 11. Csima Judit Adatbányászati technikák (VISZM185) 2015 tavasz 1 / 27
Adatbányászati technikák (VISZM185) 2015 tavasz Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2015. február 11. Csima Judit Adatbányászati technikák (VISZM185) 2015 tavasz 1 / 27
Eredmények kiértékelése
 Eredmények kiértékelése Nagyméretű adathalmazok kezelése (2010/2011/2) Katus Kristóf, hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi és Információelméleti Tanszék 2011. március
Eredmények kiértékelése Nagyméretű adathalmazok kezelése (2010/2011/2) Katus Kristóf, hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi és Információelméleti Tanszék 2011. március
STATISZTIKA ELŐADÁS ÁTTEKINTÉSE. Mi a modell? Matematikai statisztika. 300 dobás. sűrűségfüggvénye. Egyenletes eloszlás
 ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 7. Előadás Egyenletes eloszlás Binomiális eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell /56 Matematikai statisztika Reprezentatív mintavétel
ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 7. Előadás Egyenletes eloszlás Binomiális eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell /56 Matematikai statisztika Reprezentatív mintavétel
i p i p 0 p 1 p 2... i p i
 . vizsga, 06--9, Feladatok és megoldások. (a) Adja meg az diszkrét eloszlás várható értékének a definícióját! i 0... p i p 0 p p... i p i (b) Tegyük fel, hogy a rigófészkekben található tojások X száma
. vizsga, 06--9, Feladatok és megoldások. (a) Adja meg az diszkrét eloszlás várható értékének a definícióját! i 0... p i p 0 p p... i p i (b) Tegyük fel, hogy a rigófészkekben található tojások X száma
API tervezése mobil környezetbe. gyakorlat
 API tervezése mobil környezetbe gyakorlat Feladat Szenzoradatokat gyűjtő rendszer Mobil klienssel Webes adminisztrációs felület API felhasználói Szenzor node Egyirányú adatküldés Kis számítási kapacitás
API tervezése mobil környezetbe gyakorlat Feladat Szenzoradatokat gyűjtő rendszer Mobil klienssel Webes adminisztrációs felület API felhasználói Szenzor node Egyirányú adatküldés Kis számítási kapacitás
Véges állapotú gépek (FSM) tervezése
 tervezése") Véges állapotú gépek (FSM) tervezése F1. A 2. gyakorlaton foglalkoztunk a 3-mal vagy 5-tel osztható 4 bites számok felismerésével. Abban a feladatban a bemenet bitpárhuzamosan, azaz egy időben minden adatbit
Véges állapotú gépek (FSM) tervezése F1. A 2. gyakorlaton foglalkoztunk a 3-mal vagy 5-tel osztható 4 bites számok felismerésével. Abban a feladatban a bemenet bitpárhuzamosan, azaz egy időben minden adatbit
4: Az IP Prefix Lookup Probléma Bináris keresés hosszosztályok alapján. HálózatokII, 2007
 Hálózatok II 2007 4: Az IP Prefix Lookup Probléma Bináris keresés hosszosztályok alapján 1 Internet Protocol IP Az adatok a küldőtől a cél-állomásig IP-csomagokban kerülnek átvitelre A csomagok fejléce
Hálózatok II 2007 4: Az IP Prefix Lookup Probléma Bináris keresés hosszosztályok alapján 1 Internet Protocol IP Az adatok a küldőtől a cél-állomásig IP-csomagokban kerülnek átvitelre A csomagok fejléce
Nem klaszterezett index. Beágyazott oszlopok. Klaszterezett index. Indexek tulajdonságai. Index kitöltési faktor
 1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
Algoritmuselmélet. 2-3 fák. Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem. 8.
 Algoritmuselmélet 2-3 fák Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 8. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet 8. előadás
Algoritmuselmélet 2-3 fák Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 8. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet 8. előadás
Big Data: a több adatnál is több
 Big Data: a több adatnál is több Sidló Csaba István MTA Számítástechnikai és Automatizálási Kutatóintézet Üzleti Intelligencia és Adattárházak Csoport sidlo@sztaki.mta.hu http://dms.sztaki.hu CIO Hungary
Big Data: a több adatnál is több Sidló Csaba István MTA Számítástechnikai és Automatizálási Kutatóintézet Üzleti Intelligencia és Adattárházak Csoport sidlo@sztaki.mta.hu http://dms.sztaki.hu CIO Hungary
Weblog elemzés Hadoopon 1/39
 Weblog elemzés Hadoopon 1/39 Az előadás témái Egy Hadoop job életciklusa A Weblog-projekt 2/39 Mi a Hadoop? A Hadoop egy párhuzamos programozási séma egy implementációja. 3/39 A programozási séma: MapReduce
Weblog elemzés Hadoopon 1/39 Az előadás témái Egy Hadoop job életciklusa A Weblog-projekt 2/39 Mi a Hadoop? A Hadoop egy párhuzamos programozási séma egy implementációja. 3/39 A programozási séma: MapReduce
Véges állapotú gépek (FSM) tervezése
 tervezése") Véges állapotú gépek (FSM) tervezése F1. Tervezzünk egy soros mintafelismerőt, ami a bemenetére ciklikusan, sorosan érkező 4 bites számok közül felismeri azokat, amelyek 3-mal vagy 5-tel oszthatók. A fenti
Véges állapotú gépek (FSM) tervezése F1. Tervezzünk egy soros mintafelismerőt, ami a bemenetére ciklikusan, sorosan érkező 4 bites számok közül felismeri azokat, amelyek 3-mal vagy 5-tel oszthatók. A fenti
Az MTA Cloud a tudományos alkalmazások támogatására. Kacsuk Péter MTA SZTAKI
 Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
A napsugárzás mérések szerepe a napenergia előrejelzésében
 A napsugárzás mérések szerepe a napenergia előrejelzésében Nagy Zoltán 1, Dobos Attila 2, Rácz Csaba 2 1 Országos Meteorológiai Szolgálat 2 Debreceni Egyetem Agrártudományi Központ Könnyű, vagy nehéz feladat
A napsugárzás mérések szerepe a napenergia előrejelzésében Nagy Zoltán 1, Dobos Attila 2, Rácz Csaba 2 1 Országos Meteorológiai Szolgálat 2 Debreceni Egyetem Agrártudományi Központ Könnyű, vagy nehéz feladat
Gépi tanulás. Hány tanítómintára van szükség? VKH. Pataki Béla (Bolgár Bence)
") Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
COMET webalkalmazás fejlesztés. Tóth Ádám Jasmin Media Group
 COMET webalkalmazás fejlesztés Tóth Ádám Jasmin Media Group Az előadás tartalmából Alapproblémák, fundamentális kérdések Az eseményvezérelt architektúra alapjai HTTP-streaming megoldások AJAX Polling COMET
COMET webalkalmazás fejlesztés Tóth Ádám Jasmin Media Group Az előadás tartalmából Alapproblémák, fundamentális kérdések Az eseményvezérelt architektúra alapjai HTTP-streaming megoldások AJAX Polling COMET
SAT probléma kielégíthetőségének vizsgálata. masszív parallel. mesterséges neurális hálózat alkalmazásával
 SAT probléma kielégíthetőségének vizsgálata masszív parallel mesterséges neurális hálózat alkalmazásával Tajti Tibor, Bíró Csaba, Kusper Gábor {gkusper, birocs, tajti}@aries.ektf.hu Eszterházy Károly Főiskola
SAT probléma kielégíthetőségének vizsgálata masszív parallel mesterséges neurális hálózat alkalmazásával Tajti Tibor, Bíró Csaba, Kusper Gábor {gkusper, birocs, tajti}@aries.ektf.hu Eszterházy Károly Főiskola
Web harvesztelés. Automatikus módszerekkel
 Országos Széchényi Könyvtár Miről lesz szó? Mi is az a web harvesztelés? Mire és hol használjuk? Miért hasznos? Saját megvalósításaink Mi a web harvesztelés? Interneten található weboldalak begyűjtése,
Országos Széchényi Könyvtár Miről lesz szó? Mi is az a web harvesztelés? Mire és hol használjuk? Miért hasznos? Saját megvalósításaink Mi a web harvesztelés? Interneten található weboldalak begyűjtése,