Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Távközlési és Médiainformatikai Tanszék.
|
|
|
- Adél Pintér
- 6 évvel ezelőtt
- Látták:
Átírás

1 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Távközlési és Médiainformatikai Tanszék Benyó Máté Termékkereslet előrejelzés nagyvállalati környezetben mély neurális hálózatok alkalmazásával KONZULENS Dr. Gyires-Tóth Bálint Pál IPARI KONZULENS Bíró Zoltán Miklós BUDAPEST, 2017

2
3 Tartalomjegyzék Összefoglaló... 1 Abstract Bevezetés Téma bemutatása Neurális hálózatok Neurális hálózatok történelme Neurális hálózatok tulajdonságai Szentiment elemzés Előzmények Tervezés Felhasznált folyamatok Hardver -, szoftver architektúra Neurális hálózati elemek ARIMA és egyéb modellek Megvalósítás Adatforrás kiválasztása Regressziós modell Adatok előkészítése Jellemzők kiválasztása Modellek létrehozása Szentiment modell Aggregált modell Eredmények kiértékelése Hiperparaméter optimalizálás eredményei... 66
4 5.2. Regressziós modell eredmények Szentiment modell eredmények Aggregált modell eredmények Jövőbeli tervek Összefoglalás Köszönetnyílvánítás Irodalomjegyzék Függelék 1: Jellemzők fontossága Függelék 2: Hiperparaméter optimalizáció Függelék 3: Neurális hálózat architektúrák Függelék 4: Előrejelzés vizualizálása modellenként Függelék 5: Terméktípusonkénti modell kiértékelés
5 HALLGATÓI NYILATKOZAT Alulírott Benyó Máté, szigorló hallgató kijelentem, hogy ezt a diplomatervet meg nem engedett segítség nélkül, saját magam készítettem, csak a megadott forrásokat (szakirodalom, eszközök stb.) használtam fel. Minden olyan részt, melyet szó szerint, vagy azonos értelemben, de átfogalmazva más forrásból átvettem, egyértelműen, a forrás megadásával megjelöltem. Hozzájárulok, hogy a jelen munkám alapadatait (szerző(k), cím, angol és magyar nyelvű tartalmi kivonat, készítés éve, konzulens(ek) neve) a BME VIK nyilvánosan hozzáférhető elektronikus formában, a munka teljes szövegét pedig az egyetem belső hálózatán keresztül (vagy hitelesített felhasználók számára) közzétegye. Kijelentem, hogy a benyújtott munka és annak elektronikus verziója megegyezik. Dékáni engedéllyel titkosított diplomatervek esetén a dolgozat szövege csak 3 év eltelte után válik hozzáférhetővé.s Kelt: Budapest, Benyó Máté
6 Összefoglaló Diplomatervezésem során termékkereslet előrejelzéssel foglalkoztam. Ez a folyamat köztudottan kulcsfontosságú szerepet tölt be a termelő vállalatok mindennapi működése során. Fő célja, hogy egyensúlyba hozza a jövőbeli keresletet és kínálatot. Ismertettem az ellátási lánc menedzsment fogalmát és elméletét. Elemeztem a manapság kereslet előrejelzési feladatra széleskörben használt megoldásokat és módszereket. Megismerkedtem a neurális hálózatok elméleti hátterével, és erre támaszkodva gyakorlati alkalmazást készítettem. Dolgozatom célja az volt, hogy elkészítsek egy kereslettervezésre alkalmas, a területet illetően még kevésbé elterjedt neurális hálózati megoldást, majd eredményességét összehasonlítsam a klasszikusnak mondható módszerekkel. Ehhez többek között az általánosságban elismert és alkalmazott ARIMA modellt vettem viszonyítási alapul. Munkám során törekedtem a legfrissebb technológiákat, és kutatási eredményeket felhasználni. Kitűzött feladataim közé tartozott a szükséges adatok beszerzése, megértése, előkészítése is. A munkám során többféle neurális hálózat architektúrával végeztem kísérleteket és értékeltem jóságukat. Ezen túl egyéb strukturális variációkat is kipróbáltam, mint például a kategorikus változók beágyazását (Entity Embeddings). A megvalósításhoz két különböző adatforráson dolgoztam, az egyik egy publikus elérésű adatbázis, a németországi Rossmann üzletlánc és a tudományos versenyeket szervező Kaggle jóvoltából, a másikat az SAP egyik ügyfelének köszönhetem. Mindkét adathalmaz historikus adatokat tartalmaz a vásárlási szokásokat illetően. A különbség, hogy míg az előzőben értékesítési adatok szerepelnek, az utóbbi rendelési mennyiségeket foglal magába. A neurális hálózat ideális paramétereinek megtalálására is tettem lépéseket, ami alatt a hiperparaméter optimalizálást értem. Külön kihívást jelentett a megfelelő bemeneti adatok előállítása és kiválasztása. A diplomatervezés során nagyszámú, különböző terméket egyszerre feldolgozni képes mély neurális hálózatot készítettem kereslettervezés céljából. A pontosabb előrejelzés reményében közösségi hálózatról származó véleményeket is feldolgoztam, ezzel elkészítve az aggregált modell szentiment elemző részét. A modell eredményességét mértem, és összehasonlítottam egyéb megoldásokkal. 1
7 Abstract In my thesis work I was making research in demand planning. This process plays key role in the area of manufacturing industries. The main purpose is to keep demand and supply in balance. In my thesis the concept of Supply Chain Management (SCM) is presented. I analyze the widely used methods and techniques for demand forecasting. I study the theory and application possibilities of neural networks, and I use them for the given task. The main goal of my thesis is to create a neural network for demand forecast and to compare its performance to classical forecast methods. For comparison among many others I used the well-known ARIMA method as baseline model. Deep neural networks aren t commonly used in demand planning yet. In my work I used novel deep learning methods. For implementation I used the Keras framework and Python programming language. First I determined and explored the necessary data sources, explored the data and I ve done feature engineering. During my work I applied different kinds of neural network architectures and evaluated them. Furthermore, I tried other structural variations, for example introducing embedding layer for category features. I was working with two different databases. From one hand it was public sales data of a German drug store, Rossmann, provided by Kaggle.com. On the other hand I used private data of one of the SAP customers (provided by SAP). Both of these datasets contain historical data of customer actions. The difference that the first one is about sales data, the second is about customer orders. It was challenging to find the ideal hyperparameters of the neural net, and to do feature engineering as well. In my thesis work I created deep neural networks for demand forecast that can handle several product types in one. For better accuracy, I also processed online posts from social network and created an ensemble model for sentiment analysis. The results and the performance of the different models were evaluated and compared to each other. 2
8 1. Bevezetés A dolgozat felépítését illetően, a 1. Bevezetés részben mutatom be a témát és területet, amin dolgoztam, valamint nagyon röviden kitérek a neurális hálózatok munkám szempontjából legfontosabb tulajdonságaira. Ezt követően az irodalomkutatási eredményeimet mutatom be az 2. Előzmények fejezetben. Ezután következik a 3. Tervezés, ahol az általam konkrétan megvalósított lépések elméleti hátterét is ismertetem. A 4. Megvalósítás és 5. Eredmények kiértékelése szekcióban az implementációs részleteket és az eredményeket mutatom be. Zárásképpen pedig áttekintést nyújtok a diplomatervezés alatt elvégzett, és a lehetséges további kutatási feladatokról (7. Összefoglalás, 6. Jövőbeli tervek) Téma bemutatása Kutatásom célkeresztjében a termékkereslet előrejelzés állt, illetve annak megvalósítása gyakorlati módszerekkel. A diplomatervezési feladatom megértéséhez szükségesnek érzek bemutatni pár olyan alapvető vállalatirányítási folyamatot és jellemzőt [1], amik szorosan kapcsolódnak a témához, azonban nem célom általános, az egész témakört kimerítő áttekintést nyújtani. A feladatkiírásban foglaltakhoz híven megint csak kiemelném, hogy a vállalatok alap esetben a profit maximalizálására törekszenek, és ennek megfelelően szervezik folyamataikat. Ezek a folyamatok nagyon szerteágazóak és sokrétűek. Ezt az egész rendszert nem is tudnám, és a dolgozatomnak nem is célja bemutatni, de van pár olyan fogalom, aminek megértése és tisztázása kulcsfontosságú annak érdekében, hogy átlássuk a problémát, aminek megoldására javaslatokat fogok tenni. Általánosságban elmondható, hogy egy termék életciklusa során a következő érintettekkel áll kapcsolatban: beszállító, gyártó, elosztó központ, kis-nagykereskedő, viszonteladó és vevő. Mi ebben a felsorolásban a gyártó szerepet töltjük be, és ebben az aspektusban vizsgálom a felmerülő nehézségeket. Főképp termelő vállalatokról beszélek, de sok esetben igazak lehetnek az állítások szolgáltatást biztosító cégekre is. Említettem, hogy a profit lebeg a vállalat vezetőinek szeme előtt. Összetételét tekintve a profit, vagy 3
9 más néven nyereség két komponensből áll: bevételekből, amik növelik értékét, illetve kiadásokból, amik csökkentik azt. (Szigorú gazdasági értelemben a nyereség, haszon és profit nem szinonimák, de ettől itt eltekintek.) Tehát egyfajta értéktöbbletről beszélünk, ami a bevételek és kiadások különbözete. Mind a két tag számos egyéb tényező függvénye. A bevételt nagyban befolyásolja az adott cég árazás politikája, a kínált termék minősége, a cég által nyújtott kiegészítő szolgáltatások mennyisége, marketing tevékenységek, versenytársak kínálata stb. Munkám szempontjából nagyobb hangsúlyt kap a kiadások kérdése. A nyereség érdekében ezt szeretnénk a lehető legalacsonyabb szinten tartani, azaz minimalizálni. Ezért a cégek mindent megtettek, hogy a vállalaton belül különböző módszerekkel, mint például változatos gépütemezések, selejtkezelés, csökkentsék a költségeket. Egy idő után rájöttek azonban, hogy ilyen kiélezett versenyhelyzetben még ez sem elég. Tenni kell egy lépést hátra fele, és nem elégséges a vállalati kereteken belül gondolkozni, hanem ki kell tolni ezt a határt, amennyire lehet. Vagyis a vállalatokon átívelő közös megoldásra volt szükség. Ez azt eredményezte, hogy a termékkel kapcsolatban álló résztvevők (beszállítók, gyártók, elosztó központok, kisés nagykereskedők, viszonteladók) egyesítették erőforrásaikat miközben megőrizték önállóságukat (1.1. ábra). Ezzel egy gazdaságosabb működést tarthatnak fent, aminek vezérlő eleme, hogy a nyersanyagbeszerzést, annak átalakítását félkész és késztermékké, a késztermékek elosztását a fogyasztók felé a megfelelő mennyiségben, a megfelelő helyre, a megfelelő időben a kívánt szolgáltatási színvonalon végrehajtsák minimális költségszinten. Azt, hogy milyen lehetőségeket biztosít egy ilyen összefonódás, jól szemlélteti a beszállító menedzselt raktárkészlet (VMI, Vendor Managed Inventory) fogalma, ami például lehetővé teszi, hogy az ellátó vállalat foglalkozzon a gyártó (beszerző) vállalat raktárkészlet szintjével, ezzel levéve a terhet a termelő cég válláról. Az ilyen jellegű együttműködés annyira fontossá vált, hogy külön folyamat alakult ki támogatására, ami ezzel foglalkozik, neve ellátási/beszállítói lánc menedzsment (SCM, Supply Chain Management). A névben a lánc a termék útját kísérő vállalat típusok szekvenciális sorozatára utal (1.1. ábra) ábra: SCM kapcsolatok A folyamat fontosságát jelzi, hogy az SAP külön termékeket készített (SAP SCM, SAP APO: Advenced Planning and Optimization) a támogatására. Egybevéve az SCM 4
10 segíti a gazdaságos működést a partnerek szorosabb együttműködése révén. Már majdnem elérkeztünk a dolgozatom fókuszpontjába, de még maradt pár elkerülhetetlen fogalom, amit ismertetni szeretnék. Az egyik ilyen a kereslettervezés (DP, Demand Planning), ami az SAP SCM és általában az SCM termékek szerves részét képezi. Feladata a vevők eladási adataira támaszkodva előrejelzést készíteni a várható szükségletek meghatározására. Ehhez tudnunk kell, hogy kétféle fő termelési irányt különböztetünk meg a teljesség igénye nélkül: rendelésre gyártás (MTO, Make-To- Order) és raktárra gyártás (MTS, Make-To-Stock). A kettő abban különbözik, hogy míg az első esetben a gyártást konkrét megrendelés előzi meg, MTS esetében a gyártás a kereslettervezés előrejelzésén alapszik. Ez utóbbit azért is hívják saját kockázatú gyártásnak, mert nincs mögötte tényleges rendelés, a végterméket készletezik, és az előrejelzés jóságától függ a vevői rendelések teljesíthetősége. Ezek nélkül az ismeretek nélkül mindeddig úgy éreztem nem célravezető megemlítenem dolgozatom főszereplőjét, a kereslet előrejelzést, ami nem más, mint a kereslettervezés. Ez a két fogalom felcserélhető, és szinonimaként használható. Tömören fogalmazva a kereslet előrejelzés célja meghatározni azt az adott mennyiséget az előzetes eladási és egyéb rendelkezésre álló információk alapján, ami mellett a később megjelenő vevői rendelések készletről kiszolgálhatók. Azonban nem szabad túlzottan magas raktárkészletet fenntartani, mivel a raktározás mindenféleképpen költségekkel jár, bizonyos esetekben pedig kimagasló ráfordítást igényel. Gondoljunk csak a rövid szavatosságú cikkekre, amik egyrészt kellő igény híján veszendőbe mennek, másrészről, példának okáért egy hűtőházat üzemeltetni feleslegesen, szintén nem jövedelmező. Most pedig vegyük számba az előrejelzés módszereit. Két fő irányt szoktak megkülönböztetni, ezek a kvalitatív és kvantitatív (statisztikai) módszerek. Ezek mellett létezik a kompozit megoldás, azaz több modell valamilyen kombinációja is. Az első csoportba tartozik a szakértői vélemények módszere, a Delphi-módszer és a piackutatásos megközelítés [1]. A szakértői vélemény egy becsült érték, amit a területet illetően nagytudású szakértő határoz meg. A Delphi-módszer alkalmazásánál 2-3 iterációban a kollektíva írásban becsül, ezeket összegyűjtik, kiértékelik, az eredményt visszaküldik a becslőknek, akik korrigálhatják korábbi elképzeléseiket. Az eredmény mentes a főnöktől való félelemtől, a hangadók dominanciájától. Végül a piackutatás alatt a potenciális vevők igényeit mérik fel, például kérdőívek kitöltetésével. Jelen esetben fontosabb számunkra a statisztikai megközelítés. Itt lehetséges csoportosítást végezni aszerint, hogy idősor-, vagy okozati modellről beszélünk. Megpróbáltam összegyűjteni a leggyakrabban 5
11 alkalmazott modelleket: mozgóátlag, konstans-, trend-, szezonális modellek, exponenciális simítás, szezonális lineáris regresszió, Holt-Winter módszer, Croston módszer, okozati analízis [1]. Az SAP-s megoldásoknál sem szerepel a neurális hálózat, mind alapvetően támogatott megoldás. Ez mindenképp kiemelendő, mivel, ahogy említettem, az SAP vállalatirányítás területén egyértelműen a legnagyobb és legjelentősebb piaci szereplő. Ennek valószínűleg az a magyarázata, hogy jelenleg nehéz, illetve nem lehetséges olyan általános, minden feladatra ugyanolyan jól működő neurális hálózatot létrehozni, ami a vevő cégek részéről ne követelne a témakörben jártas szakembereket. Ilyen szakembereket pedig nem feltétlen szeretne minden ügyfél alkalmazni. Mindent egybe vetve ebben a fejezetben szerettem volna érzékeltetni a kereslet előrejelzés létfontosságú szerepét, és felhívni a figyelmet, hogy a neurális háló modellek alkalmazása jelenleg nem szerepel az iparban elsősorban használt alapvető módszerek között. Ezért érdekesnek és fontosnak tartom ezen megközelítés alkalmazhatóságának vizsgálatát. A problémát két irányból közelítettem meg. Egyrészt szerettem volna többféle neurális háló modellt alkalmazni a historikus numerikus adatok feldolgozására. Másrészről valós lehetőségnek találom a világhálón található egyéb információk, mint blogbejegyzések, hírek bevonását az ok-okozati összefüggések felderítésére, és erre szolgál a szentiment elemzés. Szeretném ismertetni a környezetet, amiben szerencsém volt a feladatomat elvégezni. A félév során az SAP és a BME TMIT tanszék keretein belül dolgozhattam. Az SAP-ról érdemes tudni, hogy Európa legnagyobb, a világ 4. legnagyobb szoftverfejlesztő cége, és a vállalatirányítási szoftver termékeivel kiemelkedő pozíciót tudhat magáénak. A cég részéről a kereslettervezés egyik szakértője, Bíró Zoltán Miklós volt segítségemre. BME TMIT tanszék oldaláról pedig a gépi tanulásban és mélytanulásban Dr. Gyires-Tóth Bálint Pál támogatta és irányította a munkámat, valamint konzultált velem heti szinten. 6
12 1.2. Neurális hálózatok Ebben a fejezetben röviden bemutatom a neurális hálózatok történetét és általános tulajdonságait Neurális hálózatok történelme A neurális hálózatok fejlődését Franco Maloberti és társa szerint [2] alapvetően 5+1 nagy korszakba lehet sorolni, úgy, mint: neurális hálózatok megjelenése, első arany korszak, nyugalmas évek, megújult lelkesedés, második tél, második reneszánsz. Ezek a címkék elég beszédesek és mindjárt ki is derül miért pont így nevezték el őket [3] [2]. A neurális hálózatok születése (Beginning of Neural Networks) Ez a korszak nagyjából az 1940-es éveket jelenti. Az első lépéseket részben az idegsejttel kapcsolatos kutatások motiválták, főképp Warren McCulloch és Walter Pitts neuron modellje, amit 1943-ban publikáltak. Ebben azt mutatták be, hogy lényegében egyszerű neurális hálók képesek bármilyen aritmetikai vagy logikai függvényt kiszámolni [4] ben más szerzők, Norbert Wiener és Neumann János szorgalmazták az idegrendszeri felépítéshez és működéshez hasonló lehetőségek tanulmányozását ben jelent meg Hebb könyve, amiben előállt egy tanulási törvénnyel a szinapszisra vonatkozóan. Ebben a korszakban építette meg Minsky (1951) a Snark nevű számítógépet, amit sikeres működésre bírt. A neurális hálózatok első arany kora (The First Golden Age) Ez az időszak az as éveket öleli fel. A következő nagy lépést Frank Rosenblatt, amerikai pszichológus Mark I perceptronja jelentette, ami a Hebb által közzétett tanítási elven alapult, és egyszerű osztályozási feladatokra képes volt, ezért óriási figyelem és lelkesedés övezte. Rosenblattot követte Bernard Widrow, aki megalkotta az Adaline-t és a hozzákapcsolódó Widrow-Hoff tanulási algoritmust [5]. Ekkor mondhatni az izgalom a tetőfokára hágott, amit Minsky hűtött le a Perceptrons (1969) című könyvével [6], amiben arról számolt be, hogy a perceptron csak lineárisan szeparálható osztályozási problémák megoldására képes, azaz egy olyan egyszerű feladatot, mint két bináris változó kizáró vagy kapcsolatát már nem képes megtanulni. Ez ugyebár a valós életbeli problémák nagy részének megoldását ellehetetleníti. Azonban azt is kifejtette, hogy a perceptronokat rétegekbe rendezve, a többrétegű szerkezettel 7
13 nemlineáris szeparáció is lehetséges. Azonban akkoriban nem ismertek olyan algoritmust, amivel többrétegű hálózat tanítható lett volna, sőt Marvin Minsky annak a sejtésnek adott hangot, hogy ilyen algoritmust nem is lehet megalkotni. Mindezek, tekintve, hogy Minsky az MIT professzora, azaz neves szaktekintély volt, kedvét vette sok kutatónak a tématerületet illetően. A neurális hálózatok első tele (The Quiet Years) A baljós megérzések ellenére pár kutató nem adta fel a vizsgálódást, és egyes feltételezések szerint többek között nekik köszönhetjük, hogy a neurális hálózatok tudománya egyáltalán fenn tudott maradni. A neurális hálózatok iránti újult lelkesedés (Renewed Enthusiasm) Mintegy 20 év eltelte után ismét születtek olyan neves eredmények, amelyek magukra irányították a tudósok figyelmét. Az egyik legfontosabb személyiség John J. Hopfield volt, aki megalkotta a Hopfield-hálót, ezzel bemutatva, hogy egy egyszerű hálózat miként képes optimalizálási feladatok elvégzésére. Továbbá korszakalkotó felfedezés volt a hibavisszaterjesztéses (back-propagation) algoritmus megkonstruálása (1986) is, mely mai napig a leggyakrabban használt módszer a hálók tanítására. Ez az módszer megcáfolta Minsky feltételezését, és hatékony eljárásnak mutatkozott a többrétegű háló modelleken alkalmazva. Az algoritmus atyjai David Rumelhart, Geoffrey Hinton és Ronald Williams. Ezen túl sokat nyomott a latba, hogy John Hopfield világszerte elismert fizikus volt, és számos írásos anyagot publikált, valamint megannyi konferencián is bíztatta a kutatókat, hogy igenis érdemes ezzel a szakterülettel foglalkozni. A neurális hálózatok második tele (Second Winter) Ezután jött egy második tél, de csendben születtek az eredmények (konvolúciós hálózatok, LSTM, stb.). Illetve abban az időben más technikák, pl. SVM (Support Vector Machine), HMM (Hidden Markov Model) éles alkalmazásokban jobban teljesítettek, mint a neuronhálók. Ezek az egyéb módszerek használatából származó kedvező eredmények pedig árnyékot vetettek a neuronhálókra, és sokan ígéretesebbnek tartották kutatásaiknak más irányt adni. Ezek mind-mind közrejátszottak ahhoz, hogy a neuronhálókat illetően beköszöntsön egy újabb, második tél. 8
14 Mély tanulás (Deep Learning) Sokak szerint ennek a télnek 2006-ban Hinton cikkével lett vége [7], most pedig a neurális hálózatok második reneszánszát éljük, sok eredménnyel, sikerrel. Ez többek között három dolognak köszönhető: újabb algoritmusok, növekvő számítási kapacitás, növekvő mennyiségű rendelkezésre álló adat. Ez a szerencsés együttállás pedig egyre több helyen mutatja meg a neurális hálók dominanciáját, úgy, mint a kép- és beszéd felismerés vagy szintézis területe, vagy a természetes nyelvfeldolgozás (Natural Language Processing, NLP) csak hogy párat említsek. Valamint ezeknek köszönhetően születtek meg, példának okáért a következő alkalmazások is: Apple hang alapú asszisztense (Siri), Tesla önvezető autói, AlphaGo, ami megverte a Go játék nagymesterét és megannyi orvoslást segítő eszköz. Azonban sokszor túlzott elvárásokat támasztanak a neurális hálózatokkal szemben, aminek kiábrándulás lehet a vége, egy újabb téli álmot eredményezve Neurális hálózatok tulajdonságai A neurális hálók felépítése és működése megannyi forrásban [8] [9] megtalálható. Jelen dolgozatnak nem célja a neurális hálózat elméletének részletes bemutatása, kizárólag a legfontosabb tulajdonságait és az alapvető fogalmakat [2] [8] [9] ismertetem, melyek szorosan kapcsolódtak munkámhoz. Közkedvelt bár sokak által vitatott bemutatási formája a neurális hálózatoknak az idegrendszer felépítésének analógiájára támaszkodó leírás. Ennek hátterében az áll, hogy a neurális hálózatok iránti kezdetleges kutatásokat az emberi idegrendszer működése inspirálta. Ezt tekintve mintának párhuzamot húzhatunk a két rendszer között. Az agyban az alapvető számítást végző elem az idegsejt, neuron. A neuronok kapcsolódási pontja, amin az ingerület átterjed, a szinapszis. Az idegsejtekbe a dendriteken keresztül érkezik az információ, amiket egy ideig összegyűjt, majd egy kisülést követően új jelet ad le az axon nevű nyúlványán a szinapszis kapcsolaton keresztül az őt követő idegsejtnek. Ezeknek a sejteknek a hálózata alkotja az idegrendszert. Mindez persze egy végtelenül leegyszerűsített változata a valóságnak. Más megközelítésben mesterséges neurális hálózatról beszélhetünk, olyan rendszerekről, amik rendelkeznek tanulási és predikciós algoritmussal. Bár elméletileg egy réteg is elegendő tetszőleges probléma modellezésére [10], a gyakorlat azt mutatja, hogy a jelenlegi tudásunk alapján jobb eredményt kapunk, ha több rétegbe szervezzük a 9
15 neuronokat [10]. A neurális hálók alkalmazása sokszor megoldást jelent olyan feladatoknál, ahol ismerünk más megfelelő algoritmust, azonban a feladat komplexitásából adódóan (pl. NP-teljes feladatok) a számítások mennyisége nagymértékben nő. Ilyenkor egy mesterséges neurális hálózat elégséges eredményt adhat. Egy neuront figyelembe véve lényegében négy elemre kell koncentrálnunk. Ezek a bemeneti- és súly mátrix, az eltolás (bias) és az aktivációs függvény. Ezeket egybe vetve a következőképpen áll össze a kimeneti érték (1.1-es egyenlet): neuron kimenet = f( n w i x i + b i=1 ) (1.1.), ahol f az aktivációs függvény, w a súlyvektor, x a bemeneti vektor, b pedig az eltolás. A bemenet a bemeneti értékeket jelenti vektor formájában. A súlyok jelentik a neurális hálózat paramétereit, ezeknek kívánjuk az iteratív tanítás során megtalálni a megfelelő értékeit. Ezeket a súlyparamétereket névlegesen is megkülönböztetjük a hálózat egyéb paramétereitől, amiket épp ezért inkább hiperparaméternek nevezünk. Az aktivációs függvény sokféle lehet, de alapvető feladata, hogy nemlinearitást vigyen a rendszerbe. Észrevehetjük, hogy amennyiben ezt a nemlinearitást elhagyjuk, akkor a bemenetnek egy lineáris függvényét kapjuk meg. A bias egy újabb bemenetként képzelhető el az adott rétegben, ami mindig jelen van, és az aktivációs függvényt kimozdítja az origóból. Ezzel az eljárással gyorsabb konvergenciát érünk el tanítás során. A tanítás pedig a hibavisszaterjesztéses (backpropagation) módszerrel megy végbe [11]. Fontos arra törekedni a tanítás során, hogy a modell megtanuljon általánosítani, ezzel elérve, hogy mindig csak a releváns információt tanulja meg, és eddig nem látott bemenetet kapva a felidézési fázisban, jó választ tudjon adni. Ezt úgy érhetjük el, hogy próbáljuk elkerülni a túltanítást különböző regularizációs módszerekkel. Meg kell jegyeznem, hogy az ideális hiperparaméterek megtalálása időigényes és nehéz feladat. Ezen a téren nincsenek pontos szabályok, heurisztikákra, feltevésekre kell alapozni, és tapasztalati úton keresni a közel optimális hiperparaméter-halmazt. A legfontosabb hiperparaméterből pár: rejtett rétegek és neuronok száma, súlyinicializálás módszere, regularizációs módszerek és mértékük, a tanítási iterációk száma, a hibafüggvény, korai leállítás, a tanulást segítő együtthatók értéke, tanulási ráta, a tanítási adathalmaz mérete [12]. Mindeddig nem ejtettem szót a neurális háló architektúrákról, de szintén rövidre fogva elmondható, hogy a lehetőségek tárháza igen nagy. Manapság talán a 10
, a rekurrens és a konvolúciós rétegek. 1.2.")
16 leggyakrabban használt építőelemek az előrecsatolt (1.2. ábra), a rekurrens és a konvolúciós rétegek ábra: Előrecsatolt hálózat 2 rejtett réteggel Az eltérő architektúrák jellemzően más problémák esetén viselkednek jobban, de építőelemekként kezelve őket, kombinálni is lehet ezeket. Hangzatos kifejezés napjainkban, a mély tanulás (deep learning), de azon belül is a mély neurális hálók szóösszetétel. Ennek oka, hogy bár már egy rejtett rétegre is igaz az univerzális approximátor elmélet, azonban némely függvényt nem lehet hatékonyan reprezentálni sekély hálózati felépítéssel [10]. Ezek a neurális hálózatok néhány alapvető tulajdonságai. Most szeretném bemutatni azokat az elemeket, amik alapvetően meghatározzák működésüket, és amik fejlődésének köszönhetően a neurális hálózatok egyre többrétűek és eredményesebbek lesznek. Többek között ezek is a hiperparaméterek egy részét képezik. Hiperparaméterek A korábbiakban leírtakhoz híven, neurális hálózatok esetén a súlyokat nevezzük paraméternek, és az egyéb jellemzőkre és beállításokra hiperparaméterként szokás hivatkozni. A későbbi érthetőség szempontjából be kell mutatnom pár alapvető hiperparaméter típust [12]. Ezek közül az egyik lényeges a különböző rétegekben jelen lévő aktivációs függvények csoportja. Eleinte a sigmoid-nak nevezett változatot használták előszeretettel, azonban kiderült, hogy több problémát is felvet az alkalmazása. A sigmoid matematikai képlete a 1.2. leírásban látható. 11
17 σ(x) = 1 (1+ e x ) (1.2.), ahol x a bemeneti érték. Alapvető tulajdonsága, hogy a bemenetet 0 és 1 közé szorítja, és az intervallumok szélső értékeit már nagyon nehezen veszi fel, így telítődő jellegű függvénynek számít. Ezzel a probléma az, hogy a 0 és 1 közelében, a derivált értéke 0-hoz közelít, és ezzel úgymond megöli a gradienst, amivel megnehezíti a súlyfrissítést. A másik kifogásolni való jellemző, hogy a sigmoid kimenetének középpontja nem a 0-ban van. Ez azért aggasztó, mert a későbbi rétegekbe beérkező jel, ha mindig pozitív előjelű, akkor a gradiens a hiba visszaterjesztés során, vagy csupa negatív, vagy csupa pozitív értéket fog felvenni. Ezzel egy cikk-cakk jellegű ugrálást fog eredményezni a súlyokat illető gradiens frissítésnél. Ez azonban kisebb jellegű kellemetlenség az előzőhöz képest, mivel a kötegelt feldolgozásnál a végső súlyfrissítések így is változatos előjelű értékek eredménye lesz [12]. Egy másik lehetőség a tanh függvény használata. Ez úgy is értelmezhető, mint egy átskálázott sigmoid. Az előrelépés a sigmoid-al szemben, hogy bár a telítődés rá is igaz, a kimeneti értéke a [-1,1] tartományból kerül ki. Leírása lentebb tekinthető meg (1.3. képlet) tanh(x) = 2σ(2x) 1 (1.3.), ahol x a bemeneti érték, σ a sigmoid függvény. Elérkeztünk az utóbbi évek legnépszerűbb aktivációs függvényéhez, a ReLU (Rectified Linear Unit)-hoz [13]. A ReLU határt állít fel a 0-ban, és csak nagyobb értékeket enged át. Matematikai leírása egyszerű, mint az az 1.4. formában is látható. f(x) = max (0, x) (1.4.), ahol x a bemeneti érték. Számos előnyös tulajdonsággal rendelkezik. Elsőként említendő, az az észrevétel, miszerint meggyorsítja a gradiens módszer konvergálását a sigmoid és tanh függvényekhez képest. Az, hogy ez a telítődés-mentes tulajdonsága miatt van-e, még vitatott. További kedvelt dolog vele kapcsolatban, hogy nagyon egyszerű számítást igényel, szemben a sigmoid/tanh párossal, amik ehhez képest komplex számításigényűek. Azonban, van egy gyenge pontja is, mivel előfordulhat, hogy a neuronok meghalnak a vezérletével, pontosabban konstans 0 lesz a kimenet. Ez olyankor fordul elő, ha negatív értéket kap bemenetként, mivel ilyenkor tulajdonságából adódóan mind a kimenete, mind 12
18 a gradiense 0 lesz, aminek következtében a neuron többé nem fog aktiválódni, és nem történik súlyfrissítés sem. Ezután véglegesen megmarad ebben az állapotában. Ennek elkerülése érdekében tehetünk megelőző lépéseket a tanulási rátának nevezett másik hiperparaméter ideális megválasztásával. A ReLU-t többféleképpen is tovább fejlesztették, ezek Leaky ReLU és PReLU nevet kapták [13]. Ezenkívül egyéb függvények is felhasználhatók, és alkalmaznak is, azonban ezek a legismertebbek. A bemutatott 3 aktivációs függvény a 1.3. ábrán látható ábra: Sigmoid, tanh és ReLU aktivációs függvények ( alapján módosítva) Szintén nagy jelentősége van a Softmax nevű függvénynek is. Általában a kimeneti rétegbe helyezik el osztályozási feladatoknál. Feladata, hogy az osztályba soroláshoz a kimeneti vektort valószínűségi értékekre alakítsa úgy, hogy az értékek együttes összege 1 legyen. Így minden lehetséges osztályhoz egy valószínűséget rendel, aminek egy 13
19 interpretációja lehet, hogy a legnagyobb valószínűségű értékkel rendelkező osztály tagjának tekintjük az adott megfigyelést (1.5. képlet). Softmax = ex i K e x k k=1 i=1 K (1.5.), ahol K az osztályok száma, x a bemeneti vektor. Bár nem számít hiperparaméternek, fontos szerepet játszik a dropout is, ami magyarul kidobást jelent. Ez alapvetően egy regularizációs módszer, azaz azt hivatott elősegíteni, hogy ne történjen túltanítás a modell tanítása közben. Ehhez a dropout-nak egy 0 é 1 közötti értéket kell választani, ami azt fogja eredményezni, hogy az adott réteg neuronjait ilyen valószínűséggel elhagyja az adott iterációban a hálózat. Ez azt jelenti, hogy nem vesz részt sem az előre fele haladó aktivációs eljárásban, sem a súlyfrissítésben. Ennek köszönhetően a súlyok bizonyos mértékű függetlenítése érhető el. Talán úgy érdemes elképzelni, mint ha több más architektúrával rendelkező hálózatot tanítanánk egyszerre. Fontos implementációs feladat, hogy az előhívás szakaszában a dropout mértékétől függetlenül az összes neuront szerepeltetni kell. Egyéb regularizációs lehetőségek például az L1, L2 regularizáció vagy a batch normalization használata. Egy harmadik hiperparaméter, amit változtattam a modell készítés közben a feldolgozott köteg mérete, azaz a batch size. Ennek értéke a [1,n] intervallumban mozog, ahol n a tanító adathalmaz elemszáma. Szélsőséges esetben, 1-et választva stohastic gradient descent (SGD) -et kapunk, n esetén pedig batch gradient descent eljárást. Az utóbbi előnye, hogy a tényleges gradienst használjuk, hiszen felhasználjuk az összes adatrekordot, hátránya, hogy óriási a számítás igénye, és lassú. Ezzel szemben SGD esetén minden egyes rekord feldolgozása után történik egy súlyfrissítés. A gyakorlatban a kettő ötvözetét jelentő mini-batch módszer az elfogadott. Felsorolás szinten beszéltem már a tanulási rátáról (learning rate). Ez tulajdonképpen egy olyan hiperparaméter, ami a súlyfrissítés mértékét szabályozza. Ezt kiegészítendő használnak még úgynevezett momentum módszert is, aminek szintén több változata is ismert (pl. Nesterov-momentum). Fontos észrevétel, hogy a tanulási folyamat során érdemes ezeket iterációról iterációra változtatni, ezzel szabályozva a konvergencia sebességét, aminek lényege az lenne, hogy a lokális optimum helyett a globális optimum közelébe jussunk. Szerencsére léteznek adaptív megoldások ezek ciklusonkénti frissítésére, amik Keras programcsomagban optimizer néven ismertek. Teljesség igénye nélkül a Keras a következő lehetőségeket támogatja: Adam [14], Adadelta [15], Adagrad [16], RMSprop [17], SGD [18]. 14

20 Végezetül még bemutatnám az early stopping fogalmát is, mivel emellett se lehet említés nélkül elmenni. Szintén egy a túltanítást megelőző eszközről van szó. Magyarul talán a korai leállítás a megfelelő kifejezés rá. Alkalmazási feltétele, hogy az adathalmazunkat tanító és validációs adatokra bontsuk. Lényege, hogy minden iterációban kiértékeli a modell jóságát a validációs halmazra is, majd annak függvényében, hogy a kiértékelés (valamilyen metrikát használva) milyen eredményt ad, leállítja a modell tanítását. Paramétere a türelem (patience), ami beszédes elnevezés, hiszen az algoritmus ennyi iteráción keresztül engedi, hogy ne történjen javulás a validációs adatokra nézve. Szemléltetésképpen a 1.4. ábrán látható tanulásnál a patience paramétertől függően az early stopping leállíthatja a tanulást ábra: Valószínűleg túltanítás történik, ha a 3. epoch-nál tovább engedjük a tanítást 15
21 1.3. Szentiment elemzés Szentiment analízisnek azt a folyamatot nevezzük, amely során egy adott személy, esetleg csoport vagy réteg hangulatát igyekszünk megállapítani elsődlegesen természetes nyelvfeldolgozó eljárással (Natural Language Processing, NLP), de akár képek és videók is tárgyát képezhetik az elemzésnek. Nevezik a módszert még vélemény felismerésnek és érzelem detekciónak is [19]. A fogalom azonban nem összekeverendő a fogyasztói szentimenttel 1, ami bár szintén az emberi hangulatot veszi alapul, de figyelmének a központjában sokkal inkább a jólét kérdése, a fizetési hajlandóság, pénzügyi egzisztencia áll, és maga az elemzés se feltétlen szövegelemzési feladat, hanem mondjuk a hírek volumenének mérése. A fogyasztói szentiment pénzügyi körökben használatos, és különböző mutatókat is kidolgoztak ennek mérésére, úgy, mint az MCSI (Michigan Consumer Sentiment Index), ami például telefonos felméréseken alapszik. Később azonban mutatok példát (4.3. Szentiment modell), hogy szentiment analízisnek is lehet monetáris vonatkozása. Szentiment analízis magában is igen sokrétű. Megkülönböztethetünk módszereket az elvárt kimenet, a nyelvfeldolgozás módja, a vizsgált személy, vagy akár az adatforrás, de egyéb paraméterek alapján is. A kimenetet a probléma definiálása szabja meg, így lehet, hogy csak a bejegyzés polaritására vagyunk kíváncsiak, ami jelenthet bináris (p. pozitív, negatív) kimeneti lehetőséget [20], de skálás megoldással is árnyalható a két hangulat(pl. [-10,10]). Más esetben előfordulhat, hogy külön osztályozni szeretnénk a semleges (neutrális) attitűdöt is [21], megint máskor, pedig még szofisztikáltabb megoldásként számos konkrét érzelem megkülönböztetését követeli meg az adott feladat (pl. boldog, szomorú, dühös, ideges stb.) [20][22]. Az analízis módja szintén választás kérdése. Korábbi kutatásokhoz hasonlóan [23] én ehhez is neurális hálót használok, de helyzettől függően célravezető lehet valamilyen szabályalapú vagy statisztikai módszer is [24]. Forrásnak bármilyen tartalom megfelelő lehet, ahol szubjektív megnyilvánulások szerepelnek, úgy, mint kérdőívek, közösségi média, blogok, online hírek. Én a szentiment analízisem forrásának a Twitter nevezetű közösségi hálót választottam, ami világszerte az egyik legnépszerűbb mikroblog, es adatok szerint pedig 340 millió bejegyzés született rajta naponta. A választásom hátterében az oldal népszerűsége, és korábbi tanulmányok állnak [20]. A bejegyzéseket tweeteknek nevezik és formai megszorítás, hogy 140 karaktert nem haladhat meg egy 1 Consumer Sentiment: [megtekintés dátuma: ] 16
22 tweet hossza, de átlagosan még ennél is rövidebb véleményekkel lehet találkozni. A szentiment analízis egyik nehézsége sok más felügyelt tanítási módszerhez hasonlóan a tartalmak címkézése. Sokszor - jobb híján - kézi annotálásra van szükség. Azonban a tweetekre jellemző sajátos szokásnak köszönhetően, ami alatt a hangulatjelek gyakori használatát értem, lehetőség van viszonylag egyszerű szabályok alapján automatikus címkézési algoritmust implementálni [25]. Ezenkívül vannak tudományos célokból mások által már összegyűjtött Twitter korpuszok is. Én az eddig leírtakkal ellentétben a bejegyzésekben rejlő érzelmi töltetet nem az érzelem megnevezésére használom, hanem a kereslettervezési feladat célváltozóját tekintem itt is a függő változónak. A neurális hálózati megközelítés szempontjából fontos megemlítenem, hogy találnom kellett a szavaknak egy olyan reprezentációját, ami az 1-az-N kódolással szemben kezelhető méretű adathalmazt eredményez, ugyanakkor tartalmazza a szavak egymáshoz való viszonyát. Ilyen adatszerkezetet biztosít, mind a GloVe (Global Vectors for Word Representation) [26], mind a word2vec ( szóból vektor ) [27], amik a szavak megfelelő vektoros formában ábrázolják. A teljesség igénye nélkül tudni kell, hogy mindkét megvalósítás a szavak együttes előfordulását veszi figyelembe, de míg a GloVe mátrix faktorizáció útján végzi el a dimenziócsökkentést, addig a word2vec egy neurális hálózati megközelítés. Én a GloVe-ot választottam praktikussági okokból. 17
23 2. Előzmények Itt összefoglaló jelleggel írok az összegyűjtött cikkekről, amik a kereslet előrejelzés, illetve a témához kapcsolódó módszerekről szólnak. Ahogy az előző fejezetben kifejtettem a kereslettervezés történhet okozati modellek alkalmazásával, de létjogosultsága van az idősori modelleknek is. Így mindenképp érdemes volt megvizsgálnom, hogy kereslettervező algoritmusok mellett, tágabb körben melyek a legelterjedtebb módszerek idősorok elemzésére. Nem meglepő módon nagyrészt ugyanazokat a technikákat találtam, amiket a termékkereslet előrejelzésre is használnak. Lényegében a kívánalmak, energia- és egyéb ráfordítások függvénye, hogy melyik módszert használják a gyakorlatban. Van, hogy célravezető lehet egy egyszerű eltoláson alapuló modell vagy egy valamennyivel összetettebb átlag modell (sima átlag, mozgóátlag, simított mozgóátlag). Összességében elmondható, hogy az ARIMA (Autoregressive Integrated Moving Average) modell [28] széleskörben ismert és alkalmazott módszernek számít. Speciális paraméter variációs esetekben más modelleknek is megfelel. Például ARIMA(0,1,0) a véletlen bolyongással, ARIMA(0,1,1) az exponenciális simítással egyenértékű [29]. Így az általam elemzett tanulmányokban is leggyakrabban az ARIMA modell szerepel alapvető megoldásként mikor összehasonlításról és teljesítményértékelésről esik szó. Az általam vizsgált legkorábbi tanulmányban (1997) Thiesing és Vornberger [30] arra vállalkoztak, hogy összehasonlítanak 3 modellt kereslet előrejelzés céljából. Itt meg kell említenem, hogy a címben értékesítés előrejelzés (Sales Forecasting) szerepel, ami nem kristálytisztán egyezik a kereslet előrejelzéssel, de hasonló bemenő adatokon dolgozik, mint ez utóbbi, így talán nem követünk el hibát, ha jelen esetben azonos jelentésűnek tekintjük. A szerzők leírják, hogy abban az időben kevés olyan dolgozat született, ami nem csak használja a neuronhálós megközelítést, hanem össze is hasonlítja azt klasszikus megoldásokkal. A 3 modell, amit kiválasztottak a véletlen bolyongás, a mozgóátlag és a mesterséges neurális háló volt. A méréseket egy német szupermarket adatbázisát felhasználva végezték. Bemenő attribútumoknak az értékesítési előzményeket mellett az ünnepnapokat, árazási információkat és promóciós időpontokat használták. (Éppen ezek miatt az egyéb magyarázó változók miatt gondolom úgy, hogy ez tulajdonképpen kereslettervezés, és nem értékesítés előrejelzés [31].) Az eredmények 18
24 igazolták kutatásaikat, 20 termékre nézve a neurális háló jobb előrejelzést eredményezett, mint a másik 2 megoldás. A szerzők kitértek mind a paraméterválasztás, mind az adatok előfeldolgozásának módjára is. Kumar és társai [32] a különböző neurális háló modelleket egymással hasonlították össze 2014-es cikkükben. Kiemelendő, hogy konkrétan kereslettervezést vizsgáltak, és nem általános idősori feladatot. Eredményül azt kapták, hogy a Levenberg-Marquardt tanulási eljárással kisebb hibát értek el, mint egyéb vizsgált módszerekkel (pl. gradient descent) es beadványában Zhang érdekes eredményeket mutat be általános idősorokra [28]. Elmondja, hogy az ARIMA módszer a legelterjedtebb idősoron alkalmazott predikciós technika, de korlátot jelent számára, hogy nem lineáris összefüggéseket le tudjon képezni. Másik oldalról beszámol a neurális hálók egyre nagyobb térnyeréséről, ami azon alapszik, hogy nemlineáris függvényeket is képesek modellezni. Véleménye szerint viszont, ha egy idősoros jelben lineáris és nemlineáris komponensek is szerepelnek, nem képes a neurális háló ugyanolyan teljesítményt produkálni. Ezért ajánlást tesz egy aggregált, vagy kombinált módszerre, aminek lényege, hogy az ARIMA és a neurális hálót együttesen alkalmazzuk. Mindezt tegyük úgy, hogy az ARIMA modellel modellezzük a jel lineáris részét, és a nemlineáris komponensre pedig neurális hálót futtatunk. Feltevését 3 teljesen különböző idősoros példán értékeli ki, és összeveti a javasolt módszert, az ARIMA modellel és neurális hálót önmagában használó variációkkal. Mind a 3 esetben úgy tűnik, a hibrid modell kerül ki győztesül, második helyen pedig a neurális háló végez. Később Zhang, társával, Qi-vel (2005) [33] azt mutatták ki, hogy a neurális háló nem minden esetben ad jobb eredményt az ARIMA modellnél, hanem attól is függ, hogy milyen trend és szezonalitás jellemzi az adott idősort, és ezt milyen lépésekkel kezeljük az adatelőkészítésénél ös évben Khandelwal harmad magával [34] tovább vitte az előző gondolatmenetet és hasonlóan egy kombinált modellt mutatott be, szintén általános idősorokra. Ugyanúgy arra hívták fel a figyelmet, hogy az ARIMA és a neurális hálók együttes alkalmazása kedvező működést eredményezhet. Az újítás abban rejlik, hogy a jel felbontása lineáris és nemlineáris összetevőkre az úgynevezett DWT (Discrete Wavelet Transform) módszerrel történik. Az így alkotott modellt összevetik az ARIMA, neurális háló, és fentebb említett Zhang aggregált megoldásával. Feltevéseiket 4 19
25 különböző adathalmazon értékelték ki, és eredményként publikálták, hogy a javasolt megoldásuk a másik háromnál nagyobb pontosságot biztosít ben Mitrea két társával együtt kifejezetten kereslettervezési problémát vizsgáltak [35]. Bár nem használtak kombinált modellt, összehasonlításon alapuló kiértékelésük során úgy találták, hogy a neurális hálók jobb eredményt adtak a Panasonictól származó adathalmazra, mint a mozgóátlag vagy az ARIMA módszer ös a következő figyelemfelkeltő cikk [36]. Dhini és kollégái arra hívták fel a figyelmet tanulmányukban fogyasztói cikkek keresletét vizsgálva, hogy az ARIMA - neurális háló hibrid modell nem minden esetben ad jobb eredményt, mint amikor önmagában neurális háló modellt alkalmazunk. Ez azonban ellent mond Zhang 2001-es kutatási eredményeinek. Itt hivatkoznak Taskaya-Temizel és Ahmad (2005) eredményeire is [37], akik szintén azt igazolták, hogy a hibrid megoldások nem minden esetben teljesítenek jobban az önálló modelleknél. Ennek ésszerű magyarázata lehet, hogy az időközben lezajlott deep learning forradalomnak köszönhetően a neurális hálózatok egyre kifinomultabbak, olyan újdonságok miatt, mint például a ReLU aktivációs függvény használata. Összességében változatos eredmények születtek. Néhol érezni véltem némi ellentmondást. Ez betudható annak, hogy bár hasonló témát vizsgáltak, a felhasznált, eltérő jellegű adathalmazok nagy különbségekhez vezethetnek. Ennek ellenére sok új dolgot tudtam meg, és úgy látom, hogy olyan tématerületen dolgozok, aminek tényleg lehet valós tanulsága. Amire mindenképp sarkalnak ezek a művek, hogy próbálkozzak aggregált modellekkel is, valamint, hogy az ARIMA modell jó alap megoldás lehet teljesítmény kiértékeléshez általánosságban elfogadott és alkalmazott volta miatt. Én a munkám során annyival igyekeztem előrelépést tenni a témában, hogy egyrészről a legfrissebb neurális hálózati módszereket használtam. Másrészről a létrehozott kereslettervezést támogató szentiment elemzésre kevés pályaművet találtam, ez alapján ezt is érdekes újításnak vélem. 20

26 3. Tervezés A megvalósításhoz nélkülözhetetlen volt a megfelelő tervezés elvégzése. Ehhez definiálnom kellett a célokat. A kitűzött cél egy aggregált felépítésű neurális háló volt, aminek egyik komponense a historikus adatokon alapul, míg másik mikroblog bejegyzéseket dolgoz fel. A modell felépítését a 3.1-es ábra szemlélteti. Ami megfigyelhető az ábrán, hogy két modell készítését tűztem ki célul. Míg az egyik historikus rendelési adatokon alapul, addig a másik szöveges adatokat (korpusz) használ. Az előbbi egy regressziós feladatot lát el, ahol a modell a bemeneti attribútumok alapján becsüli meg a rendelési mennyiségeket a következő időpontokra. A második, vagyis a szentiment modell pedig a vevői vélemények alapján igyekszik előrejelzést adni. Mindkét modell elkészítéséhez neurális hálózatot alkalmazok, és többféle topológiát is kipróbálok. Az ábra jobb oldalán az látható, hogy a két modellt együttesen is tanítom a jobb eredmény reményében ábra: Aggregált modell felépítése 21

27 3.1. Felhasznált folyamatok A kereslettervezési probléma megoldásához a lenti képen (3.2. ábra) látható folyamatokat hajtottam végre. Sorra veszem a legfontosabb építőkockákat, amik a végső rendszert alkotják, és bemutatom a mögöttük meghúzódó motivációt, a lépések indokoltságát. Összefoglalásképpen az alábbi lépcsőfokokat fogom érinteni: adathalmaz kiválasztása, modell kiválasztása, adatok előfeldolgozása, modell implementálása, modell hiperparaméter optimalizálása, eredmények kiértékelése. Ezek a folyamatok sokszor megtalálhatók egyéb modellépítési eljárásoknál is, de lesznek kifejezetten neurális hálózatokra jellemző mozzanatok is. Általánosságban az adatfeldolgozó lépésekhez a Scipy ökoszisztéma szoftvereit használtam, neuronháló készítésében a Keras, TensorFlow, Theano és StatsModel volt segítségemre. Ezekről az eszközökről a 3.2. Hardver -, szoftver architektúra részben írok Végül a hiperparaméter optimalizációhoz Hyperopt és Hyperas könyvtárakat alkalmaztam, amiket később szintén bemutatok. Ezeket a lépéseket azért tartom fontosnak, mert én is ilyen technikákat alkalmaztam az implementáció során. A 4. Megvalósítás fejezetben fogom a gyakorlatban általam alkalmazott módszereket bemutatni ábra: A feladat megoldásának menete a felhasznált technológiákkal együtt 22
28 Adathalmaz kiválasztása Az adathalmaz, amin dolgozni fogunk, vagy adott, és rendelkezésünkre áll, vagy nekünk kell beszereznünk. Vegyük ez utóbbi esetet. Miután definiáltuk és kijelöltük a célokat, és megvalósítandó funkciókat, be kell szereznünk a szükséges információ forrást. Az információ, mint tudás adatokban testesül meg, vagyis szükségünk van a céljainkhoz illeszkedő adatbázisra. Ennek kiválasztása meghatározó, és hatással van az összes követő folyamatra. Kutatási célokból jó választás olyan adathalmazt választani, amin már sokféle algoritmust alkalmaztak, így egyrészt lesznek eredmények, amikhez viszonyíthatjuk a sajátunkat, másfelől ezeket a kutató társadalom is nagyvalószínűséggel ismeri. Modell kiválasztása Esetemben a modell kiválasztása azt jelenti, hogy milyen neurális hálózat típust és ezzel együtt milyen architektúrát használok. A hálózat típusa további előkészítési lépéseket igényel az adatok szerkezetére vonatkozóan. Ez alatt azt értem, hogy az adott modellnek megfelelő alakra kell alakítani az adatfolyamot. Adatok előkészítése Általában sok időt és energiát emészt fel az előfeldolgozás elvégzése. Miközben igyekszünk, hogy a kiindulási állapotból a kívánt állapotba kerüljenek az adatok, ügyelni kell rá, hogy ne sérüljön azok információ tartalma. Az előfeldolgozásra azért van szükség, mert legtöbb esetben a rendelkezésre álló adathalmaz hiányos, zajos, és/vagy inkonzisztens. Most pedig sorra veszem az általánosságban szükséges lépéseket [38]: Adat megértése, ismerkedés: Mivel a beszerzett adatbázisban van az összes rendelkezésre álló információnk, ezért kiemelkedően fontos dolog, hogy megértsük a benne lévő összefüggéseket, és átlássuk a legfőbb jellemzőit. Elsőre nem tűnik komoly folyamatnak, ám nagyon hasznos és lényeges lépés a meglévő adatok vizualizálása, ami ábrákkal, diagramokkal teszi szemléletesebbé mindezeket. Formátumbeli különbözőség kiküszöbölése: Az első problémát jelentheti, ha a forrás adatok nem a megfelelő formátumban állnak rendelkezésre, ilyenkor el kell végezni a szükséges konverziót. Adattisztítás: Egyik alapelve, hogy egészítsük ki az adatsort a hiányzó értékek pótlásával. Ez sokféleképpen történhet, alap esetben az adott attribútum átlagos értékével egészíthetjük ki a réseket. Esetleg valamilyen tanuló algoritmus 23
29 segítségével következtetünk a hiányzó értékre. Legegyszerűbb esetben elhagyhatjuk az adott megfigyelést a forrás halmazból. Ezek a döntések attól is függenek, hogy milyen arányban fordulnak elő ismeretlen adatok, és, hogy mennyire engedhetünk meg magunknak olyan könnyedséget, hogy elhagyás útján csökkentsük a rendelkezésre álló adat mennyiséget. Szintén adattisztítás címszó alatt szokták a kilógó adatokat korrigálni. Módunkban áll simítással elnyomni ezeket a tüskéket, esetleg kisszámú előfordulás esetén kizárhatjuk ezeket a rekordokat is. Végül, amennyiben tehetjük, szüntessük meg az inkonzisztenciát. Adat dúsítás és csökkentés: Ehhez a ponthoz tartozik mind a rekordok számának bővítése/csökkentése, mind az attribútumok számának bővítése/csökkentése, mind a felvehető attribútum értékek bővítése/csökkentése. Elemek számát mintavételezéssel, ellenkező esetben interpolációval szabályozhatjuk. Az attribútumok esetében lehetőség van valamilyen dimenzió csökkentő eljárással szűkíteni a felhasznált tulajdonságok számát, de ellenkező esetben további tudást is bevihetünk az adathalmazba új, származtatott attribútumok felvételével, meglévő attribútum tovább bontásával. Olykor gondot okozhat, hogy egy adott attribútum esetén a felvehető értékek széles skálán mozognak, ennek redukálására segítségül vehetünk valamilyen klaszterező algoritmust, de az aggregáció és diszaggregáció is a lehetőségek között szerepelnek. Neurális hálózatok esetén például egyfajta dimenziócsökkentési feladatot lát el az úgynevezett embedding réteg alkalmazása. Valamint természetesen eldobhatunk attribútumokat, ha számunkra nem hordoznak releváns információt. Adatok kiegyenlítése: Főleg osztályozási feladatoknál okozhat gondot a kiegyenlítetlen adathalmaz jelenség. Ennek lényege, hogy egyes osztálybeli entitások nagyobb számban képviseltetik magukat más csoportokhoz képest. Ennek kiküszöbölésére jó eljárás lehet a megfelelő mintavételezés, mesterségesen generált újabb egyedek felvétele vagy dedikált algoritmus használata, csak, hogy párat említsek a számos lehetőség közül. Adat átalakítás: Szükség lehet az adatokon olyan átalakításokat végezni, hogy valamilyen feltételeknek eleget tegyenek. Ilyen feltétel lehet, hogy bizonyos intervallumon belüli értéket vegyenek fel, vagy, hogy bizonyos értékű szórással és átlaggal rendelkezzenek. Később kitérek rá, hogy neurális hálózatok esetén is gyakran kell ilyen átalakításokkal élni. Ennek két közkedvelt módja a standardizálás és normalizálás. Fontos, hogy ezeket a kilógó adatok orvoslása után 24
30 végezzük el, különben a szélsőséges esetek miatt elcsúszhatnak az adatok az intervallumban. Neurális hálózatoknál azért is kell átalakításokat végezni, hogy az értékkészlet illeszkedjen az aktivációs függvény lehetséges kimenetéhez. Amennyiben erről nem gondoskodunk a tanítás nem lesz eredményes. Külön figyelmet kell fordítani neurális hálózatok esetén a kategorikus változókra, ezek alap esetben szintén nem viselkednek jól a tanítás szempontjából. A megvalósításnál részletesebb szemléltetést nyújtok. Modell implementálása Amennyiben kiválasztottuk, hogy milyen típusú modellt, esetemben neurális hálózaton belül milyen hálózati architektúrát építünk, és az adatok is a megfelelő formában rendelkezésre állnak az előfeldolgozás elvégeztével, nem marad más hátra, mint magának a modellnek az implementálása. Modell hiperparaméter optimalizálása Neurális hálózatokat tekintve, bármelyik típust is használjuk, szükséges megadni a hiperparaméterek kezdő értékét, amit majd későbbi iterációs lépésekben változtatunk. Ahogy azt a 1. Bevezetés modulban kifejtettem számos ilyen hiperparaméter van, kezdve a rétegek számától, egészen a regularizáció mértékéig. A hiperparaméter optimalizáció pedig az egyik legidőigényesebb feladat a folyamatok között, ennek oka, hogy a hiperparaméter tér óriási, és elviekben az összes lehetőséget ki kéne próbálni, hogy biztosak lehessünk, hogy az optimális modellhez jutottunk. Az optimumról le kell ugyan mondani, és törekedni kell a legjobb megoldásra. A paraméter keresésnek három nagyobb válfaja létezik: kimerítő keresés (grid search), véletlenszerű és Bayes-i megközelítés. Az első esetben a megadott paraméter értékeket az eljárás az összes lehetséges kombinációt figyelembe véve, bizonyos lépésközökkel próbálja végig. Véletlenszerű kombinációkat használva jellemzően hatékonyabban járhatunk el [39]. Azonban a téma súlyának megfelelően aktív tudományterületről beszélünk, és ennek eredménye a Bayes-i megközelítés is. Ez a legösszetettebb, és sok esetben a leghatékonyabb eljárás a három közül. Alapvető lényege, hogy mindig alapoz az előző iterációk során megszerzett tudásra, és annak fényében keres tovább a paramétertérben. Kiindulásként ez az algoritmus is sok esetben véletlenszerűen választ a paramétereknek értéket. A szakirodalomban gyakran emlegetik, hogy a kompromisszumot találja meg a felfedezés (exploration) és a kizsákmányolás (exploitation) között [40]. A kizsákmányolás esete 25
31 akkor állhat fent, ha egy ígéretes jelöltet találva a paramétertérben, leragadunk annak környezetében, feltételezve, hogy itt található meg a legideálisabb pont. Ez könnyen azt eredményezheti, hogy az algoritmus csak a lokális optimumot vagy környékét találja meg. A szuboptimális megoldás helyett, a felfedezés elve támogatja a nagyobb mértékű ugrásokat, így biztosítva a lehetőséget, hogy a globális optimum közelébe eljusson a kereső eljárás. Eredmények kiértékelése Sok esetben neurális hálózatot alkalmazva az eredmények, pontosabban a kimenet nem a megfelelő formátumban áll rendelkezésre. Ennek oka, hogy korábban valamilyen transzformációt végeztünk ezen a kimeneti attribútumon, vagy pedig, hogy igazából nem is erre az attribútum értékre vagyunk kíváncsiak, hanem ez már egy származtatott érték, ezt még megfelelő számításokkal vissza kell vezetnünk, hogy megkapjuk a kívánt eredményt. Másik szintén kihagyhatatlan lépés az eredmények kiértékelése, azaz, hogy valamilyen hiba vagy pontossági mutató segítségével mérni tudjuk a modell és az eredmények jóságát. Egy elképzelhető megoldás a korreláció mérése regressziós esetben az elvárt és a tényleges kimeneti értékekre vonatkoztatva. Sokszor pedig egyéb megoldás által produkált végeredményhez hasonlítjuk a sajátunkat. Próbáltam összefoglalni a legfontosabb lépéseket, és a felsoroltak közül keveset hagyhatunk el, amennyiben hasonló tanulási modellt szeretnénk készíteni. Ami megtévesztő lehet, hogy az egyes pontokat sorrendben mutattam be, azonban ezek a folyamatok legtöbbször iteratív eljárást igényelnek. Így például az adatelőkészítés sem lehet egyszeri feladat, mivel a bemenő attribútumok listája is egy fajta paramétere a neurális hálózatnak, mivel tartalmától függően a modell jobb vagy rosszabb eredményekre lehet képes. Más megközelítésből, nem csak egy fajta modellt próbálunk ki általában, így az adatok átalakítása a megfelelő formába sem egyszeri szükséglet. 26
32 3.2. Hardver -, szoftver architektúra Feladatom szerves részét képezte a felhasznált technológiák kiválasztása. A döntéseimet az adott szoftver vagy egyéb könyvtár mellett igyekeztem mindig megindokolni. Hardver gyanánt hozzáférésem volt a TMIT tanszéken működtetett céleszközökhöz, ami egy NVIDIA Titan X-et jelent. Mindez annak köszönhető, hogy egy sikeres pályázat után az NVIDIA GPU Oktatási Központtá nevezte ki a tanszéket. Ennek előnye, hogy a Titan X felépítését tekintve rendelkezik CUDA maggal és 12GB memóriával. Erről egy kis háttér információ, hogy neurális hálózatok tanítására a GPU feldolgozó egység sokkal jobb teljesítményre képes, mint a CPU. Ennek oka, hogy a GPU-k kezdeti kizárólagos grafikus munkavégzése mellett, egyre inkább használják egyéb programozási feladatokra a nagymértékű párhuzamosítási képessége és nagyszámú feldolgozó egysége miatt [41]. Ennek kihasználására például a bemeneti adatok és a súlyok közötti szorzásnál van lehetőség. Ezenkívül használtam még a saját gépemet, amiben egy NVIDIA GeForce 840M nevezetű 384 magos, 2GB memóriával felszerelt GPU dolgozik, valamint az SAPos laptopot, amiben Intel GPU van, amit nem támogat a CUDA, így az általam felhasznált keretrendszer sem, így eben az esetben a CPU végezte a számításokat. A legnagyobb döntés meghozatalát az jelentette, hogy kiválasszam azt a környezetet, amiben a leghatékonyabban, leggyorsabban tudok neurális hálózatokat létrehozni, mindezt a lehető legrugalmasabb testreszabhatóság mellett. A lehetőségek között olyan könyvtárak szerepeltek, mint Torch7 2, Lasagne 3, Keras, TensorFlow, Theano, Blocks 4, Caffe 5. Végül utánajárás után a Torch7-t és a Keras-t próbáltam ki. A Torch7-t illetően elmondható, hogy egyre több helyen alkalmazzák, és vele részletekbe menően lehet a neurális hálózatot felépíteni. A kódalkotáshoz a Lua nevű szkript nyelvet kell használni, aminek alapjai hamar elsajátíthatók. A Torch7 keretrendszer alapjában véve támogatja a GPU-n való futtatást. Én végül a Keras 6 mellett tettem le a voksomat. Véleményem szerint ebben még gyorsabban lehet fejleszteni, és sok terhet levesz a programozó válláról, illetve a hibázás lehetősége is kisebb. Kétféle lehetőség közül választhatunk, vagy Theano-t [42], vagy TensorFlow-t [43] alkalmazunk a matematikai kifejezések elvégzésére. Vagyis a Keras egy vékony réteget képez az előbbi kettő felett, modulokba 2 Torch7: [megtekintés dátuma: ] 3 Lasagne: [megtekintés dátuma: ] 4 Blocks: [megtekintés dátuma: ] 5 Caffe: [megtekintés dátuma: ] 6 Keras: [megtekintés dátuma: ] 27
33 szervezve a neurális hálózathoz szükséges legfontosabb funkciókat. A Theano és a TensorFlow is támogatja a GPU-n való futtatást, így a kettő közül lényegében mindegy melyiket választjuk. Szigorúbban véve a Theano-t jelenleg jobbnak mondják a rekurrens hálózatok terén, azonban a TensorFlow egy Google termék, és gyorsan fejlődik. Egyik kiemelkedő tulajdonsága a nagyon látványos vizualizálás, aminek a neurális hálózatok rétegei közti kapcsolatok és súlyok értékének megértésénél is hasznát vehetjük. A tanszéki rendszerben, és a saját gépemen TensorFlow van telepítve, az SAP-s hardveren Theano fut. A döntésem a Keras mellett maga után vonzotta, hogy Python nyelvet használjak a programozáshoz. Tapasztalataim szerint a kutatók és fejlesztők is előszeretettel használják a Python nyelvet. A neurális hálózatok ideális paramétereinek megtalálása idő- és számításigényes munka. Szerencsére létezik a megoldást gyorsító és kiszolgáló nyíltforráskódú eszköz. Ennek neve Hyperopt [44]. A Hyperopt nem csak neurális hálózatoknál használható, hanem egyéb tanuló algoritmusoknál is. A Bayes-i megközelítés miatt igen csak meggyorsítja az optimalizációs folyamatot azzal, hogy nem kell az egész hiperparaméter teret végigjárni. Ennek a könyvtárnak létezik egy Keras-os neurális hálózatokra tovább fejlesztett változata is, a Hyperas 7 (Hyperopt + Keras). Sajnos a dokumentáció nem bőbeszédű, azonban gyorsan lehet vele definiálni a hiperparaméter teret, így mindkét eszközt alkalmaztam. Parancssor helyett, fejlesztői környezetnek a Spyder 8 nevű IDE-t használtam, ami alapból tartalmazza NumPy, Matplotlib és IPython könyvtárakat, azaz a SciPy ökoszisztémát [45]. Ezek olyan bővítmények, amelyek a legtöbb Python alapú programban segítségül szolgálnak, legyen szó kalkulációról vagy megjelenítésről. Ezek közül az IPython (Jupyter) egy parancssori környezet, amiben füzeteket (Notebook) hozhatunk létre, amiket böngészőben futtathatunk. Ezek a füzetek bemeneti és kimeneti cellákból állnak, amik tartalmazhatnak kódot, szöveget, képeket, bővítményeket is. JSON formátumban tárolódik, és HTML-ként bármikor megjeleníthető. Nagy hasznát lehet venni kísérletezgetésnél, adatok vizualizációjánál és szemléltetéshez is páratlan eszköz. A NumPy csomag többek között a többdimenziós tömböknél, mátrix műveleteknél tesz jó szolgálatot. A Matplotlib pedig a pythonos világ vizualizációs eszköze. A Scikit-learn nevű, szintén nyílt forráskódú, a NumPy-ra és Matplotlib-re épülő eszköz, ami további 7 Hyperas: [megtekintés dátuma: ] 8 Spyder - The Scientific PYthon Development EnviRonment: [megtekintés dátuma: ] 28
34 kisegítő funkciókat biztosít az adatelemzési és adatbányászati feladatok elvégzéséhez. Nem hagyhatom említés nélkül a Pandas-t (Python Data Analysis Library) [46] sem, amivel nagyméretű adattáblákon is hatékonyan végezhetünk halmazelméleti és relációs algebrai műveleteket, adatmanipulációs lépéseket, és számos formátumot is ismer. A köztes adatok tárolására a Pickle-t és HDF5-öt használtam [47]. A Pickle egy Python-os sorosító eszköz, a H5py pedig a HDF5 pythonos felülete. A HDF5 alapvető lényege, hogy nagyméretű és komplex adatokat tárolhatunk egy fájlban. H5py pedig támogatja, hogy ezek a fájlok, mint NumPy tömbök kerüljenek szerializálásra. Az adatok ábrázolására a klasszikusnak mondható Matplotlib mellett a Seaborn és Plotly könyvtárakat használtam. A Seaborn a Matplotlib-en alapuló Python-beli vizualizációs eszköz, amelynek célja, hogy még látványosabb ábrákat készíthessenek a fejlesztők. A Plotly más nyelveket is támogat a Python-on kívül (R, MATLAB, Javascript), valamint már fizetős változata is van, és megoldásait üzleti intelligenciával és adat tudománnyal foglalkozóknak ajánlja. A különböző ARIMA modellek elkészítésében pedig a Python-os StatsModel 9 könyvtár volt segítségemre. A statisztikai teszteket az SPSS szoftverrel futtattam. A szövegelemzési modulnál az adatok begyűjtéséhez a GetOldTweets 10 és twitterscraper 11 nevű könyvtárakat vettem segítségül, amik Githubon lettek közzé téve. Ezenkívül a GloVe projekt [26] keretein belül létrehozott szóvektorokat használtam fel ehhez a feladathoz. 9 StatsModel: [megtekintés dátuma: ] 10 Get Old Tweets Programatically: [megtekintés dátuma: ] 11 Twitter Scraper: [megtekintés dátuma: ] 29
35 3.3. Neurális hálózati elemek Ebben a szekcióban, a neurális hálózati elemek főbb jellemzőit taglalom. A neurális hálózatok általános működésébe és a hiperparaméterek szerepébe már bepillantást nyújtottam, most az előrecsatolt, rekurrens, konvolúciós réteg típusokat [48], valamint a beágyazási réteg elméleti hátterét fejtem ki bővebben. Ezen fejezet célja, hogy segítse a későbbi megértést, az által, hogy az olvasóval megismerteti az alapvető kifejezéseket. Előrecsatolt hálózat Az előrecsatolt hálózat (feed forward/fully connected, FF/FC) esetén a neuronokat egymás utáni rétegekbe szervezzük, amiket rejtett rétegeknek nevezünk. A rejtett rétegek száma egy hiperparaméter, és úgy is nevezzük, hogy a hálózat mélysége. Az egyes rétegekben szereplő neuronok száma pedig egy másik hiperparaméter. Az előrecsatolt architektúra megkötése, hogy az adott rejtett réteg összes neuronja összeköttetésben kell, hogy álljon a következő réteg, valamint az előző réteg összes neuronjával. Ezenkívül az adatok csak előre fele haladnak a bemenet irányából a rejtett rétegeken át egészen a kimenetig. Rekurrens hálózat Az előrecsatolt architektúrával szemben a rekurrens hálózatok (Recurrent Neural Network, RNN) képesek az előző kimeneteket is figyelembe venni az adott bemeneti értékek mellett. Erre az irányított gráf alapú felépítésük teszi képessé őket. Úgy is gondolhatunk erre a tulajdonságukra, mint egy belső memóriára, ami tárolja az eddigi eredményeket. A rekurrens hálók többek között szöveg- és beszédelemzési területen, illetve általános idősor elemzésre is eredményesen alkalmazhatók. Egy példa a belső memória hasznosságára, mikor szöveg értelmezésekor a hálózat aktuális bemenetére a szeretem szó kerül. Amennyiben csak ezt a bemenetet vesszük figyelembe, arra következtetünk, hogy pozitív töltetű gondolatról van szó. Ezzel szemben könnyen előfordulhat, hogy a kontextusban a nem szeretem vagy nem igazán szeretem, stb. kifejezés szerepelt, ami az eddigi feltevésünkkel szöges ellentétben áll. A rekurrens elnevezés csak gyűjtőnévnek számít, és a visszacsatolásra utal, valójában több hálózattípust fog össze, mint például: egyszerű rekurrens hálózat, kétirányú rekurrens hálózat [35] [36]. A mostani neurális hálózati világban az LSTM-ek [49] használatát támogató trend van kialakulóban, épp ezért én is ezzel foglalkoztam dolgozatom során. Az LSTM a Long Short-Term Memory rövidített változata, aminek tükör fordítása a 30
36 hosszú, rövid távú memória, ami igazából jellemzi fő tulajdonságait, de inkább LSTMként hivatkozok rá a továbbiakban. Csak, hogy tovább bonyolítsam a neurális hálózat típusokat, el kell mondanom, hogy az LSTM is egy család, és több taggal rendelkezik. Minden esetre mindegyik LSTM-re igaz, hogy különböző kapukkal igyekszik az információk áramlását szabályozni. Ez úgy képzelhető el, mint, amikor megnyitunk vagy elzárunk egy csapot. Ezzel a szabályozással határozza meg az LSTM, hogy melyik részét tartsa meg, törölje vagy frissítse az aktuális tudásának, és mindezt milyen mértékbe tegye. Konvolúciós hálózat A konvolúciós hálózat is egy topológiája a neurális hálózatoknak, és előszeretettel használják képek feldolgozásánál, azonban ez koránt sem az egyetlen felhasználási területe. Példaként említve a szövegelemzésben is jó eredményeket értek el vele [50] [23] [51]. Erre a célra én is alkalmaztam ezt a fajta hálózatot. A neuronok működésében nincs különbség a klasszikus előrecsatolt hálózathoz képest. Azonban ebben a hálózat típusban nincsenek az adott réteg neuronjai az összes előző, illetve soron következő réteg neuronjaival összekötve. Ezzel radikálisan lecsökkentik a súlyok számát a hálózatban. Leggyakrabban a 2D konvolúción szokták bemutatni a hálózat, és réteg működését, de létezik 1D és 3D konvolúció is. Egy konvolúciós hálózat általában tartalmaz konvolúciós, úgynevezett pooling, és előrecsatolt rétegeket is. 2D konvolúciónál maradva, ezt leggyakrabban képek feldolgozására használják. A képek tulajdonságukból adódóan nagy dimenzió számmal rendelkeznek, például kis felbontás esetén is: 227x227x3. A három jellemző a szélesség, magasság és mélység, ez utóbbi alap esetben az RGB színcsatornáknak felel meg. A konvolúciós réteg működése során nem kell az összes pixel bemenetet összekötni a következő réteg összes neuronjával, hanem ezzel szemben egy szűrőt (filter) használunk, ami pl. 5x5-ös méretű. Ezt a szűrőt csúsztatjuk végig (konvoláljuk) a képen, és kapunk meg egy 2 dimenziós aktivációs térképet [50]. A csúsztatás nagysága, azaz a lépésköz (stride) mértéke is egy hiperparaméter, és, ha nem illeszkedik pontosan a bemenetre, akkor kiegészítik a bemeneti mátrixot bizonyos nagyságú kerettel (zero padding). Csak, hogy szemléletesebb legyen, az előző példánál maradva, előrecsatolt hálózat esetén egyetlen neuron (227*227*3) súllyal rendelkezne! Ezzel szemben 11x11-es szűrők esetén a súlyok száma csak 363 (11x11x3). Ez igaz akkor is, ha konvolúciós réteg mélyebb, pl. 96, ez esetben is csak (363x96) súlyról beszélünk. Mindez azért lehetséges, mert az aktivációs térkép (activation map), ami most 96 mély, képes a súlyai megosztására. Ezt a jelenséget súly vagy paraméter 31
37 megosztásnak nevezzük. Lényege, hogy szintenként ugyanazokat a súlyokat használják az adott réteg neuronjai. Ezzel lehetővé téve, hogy az aktivációs térkép szélességétől és hosszúságától függetlenül (jelen esetben) csupán 96 különböző súlymátrixra legyen szükség. Súly megosztás nélkül a paraméterek számának meghatározásakor az aktivációs térkép szélessége és hossza szorzó tényezőként szerepelne. A konvolúciós rétegek közé opcionálisan pooling rétegeket helyeznek, amik tulajdonképpen mintavételezik az aktivációs térképeket valamilyen algoritmus szerint. Két paramétere van, az eltolás mértéke és a szűrő mérete. Fontos hozzátenni, hogy a mintavétel nem érinti a mélységet (képeknél a színcsatornákat). Max pooling esetén a mintavételnél a kiválasztás a maximum érték alapján történik. A konvolúciós és esetleges pooling rétegeket követően általában itt is előrecsatolt rétegek következnek, amik illeszkednek az aktuális problémához, legyen az osztályozás, regresszió vagy bármi más. Képeken alkalmazott 2D konvolúciónál a tanulás úgy képzelhető el, hogy az alsó rétegek olyan elemi tulajdonságokat tanulnak, mint élek, görbék, színcsoportok, majd a felsőbb rétegek már formákat, alakzatokat, végül objektumokat is megkülönböztetnek. Ez az absztrakttól a figuralitás felé tartó interpretáció jellemző egyéb topológiákra is, de a képekre értelmezve különösen szemléletes. A neurális hálózatoknak ez a tulajdonsága, hogy a rejtett rétegek egyre komplexebb tulajdonságokat és összefüggéseket képesek megtanulni, jelen van egyéb topológiáknál, illetve más problémaköröknél is, de képekre értelmezve ez a rétegről-rétegre történő fejlődés különösen szemléletes. Ennek oka, hogy képeknél könnyen szemléltethető vizuálisan is, hogy míg az első rétegek vonalakat, éleket, színcsoportosulásokat tanulnak meg, addig a mélyebb rétegekben már ívek, formák és egyéb összetettebb alakok is megjelennek. Beágyazás módszere A magyarra lényeg beágyazás -nak fordítható Entity Embeddings (EE) egy igazán érdekes eleme a neurális hálózatok tárházának [52]. Kategorikus változókra alkalmazható eszköz, amit általában a szövegelemzésben használnak. Célja, hogy az adott kardinalitású változót egy kisebb, meghatározott dimenziójú térben ábrázolja, még pedig úgy, hogy a távolságok a páronként vett hasonlóságokat ábrázolják. Segítségével olyan összefüggőségek ábrázolhatók és nyerhetők ki vektoros formában, mint, hogy Queen - Woman + Man = King (Királynő - Nő + Férfi = Király). Ez a példa szintén a nyelvelemzés területéről származik. Ezt a megoldást azonban nem csak itt alkalmazhatjuk, hanem bármilyen kategorikus változó esetén, legyen az nominális vagy 32
38 ordinális. Az előző két fajta változót hiába látjuk el címkékkel, semmilyen információt nem kapunk a címkék közti összefüggésről. Vegyük nominális változóként például a színeket. Tegyük fel, hogy a piros, kék, sárga színeket 1,2,3 címkékkel reprezentáljuk. Erre a felírásra nem lesznek igazak előbbihez hasonló = 3 formájú kapcsolatokat, vagyis, az, hogy a piros és a kék a sárgával lenne egyen értékű. Akár ordinális esetre is vehetünk példát, tekintsük ehhez a hónapoknak számmal való reprezentálását! Ez sem a legmegfelelőbb módszer tekintettel arra, hogy például január közelebb van júliushoz, mint február, figyelembe véve a hónapokat alkotó napok számát. Ezért tanuló algoritmusoknál gyakran használják az 1-az-N-ből kódolást (one-hot encoding), ahol is minden lehetséges attribútum érték saját jellemző vektort kap, és csak is ott lesz aktív, amelyik sorban ez volt az értéke. Erre példát mutatok a 3.1-es táblázatban, ahol a szín kategorikus jellemzőt alakítom át táblázat: Kategorikus címke 1-az-N kódolása Szín Szín Piros szín Kék szín Zöld szín (eredeti címke) (integer címke) piros kék zöld Az látható, hogy ezzel dúsítottuk a jellemző vektort, és csak 0 és 1 értékeket használunk. Ezzel egy ritka mátrixot kaptunk, aminek soraiban egyedül az 1-es értékek hordoznak releváns információt, az összes többi redundanciának számít, hiszen az 1-es ismeretében kikövetkeztethető, hogy 0 lesz a többi cella értéke. Tehát az 1-az-N-ből megoldással a két probléma, hogy magasfokú kardinalitásnál óriásira nőhet az adat mátrix, valamint még mindig nem tudunk semmit a kategóriák közötti viszonyról. Ebben segíthet az Entity Embeddings, aminek további kellemes tulajdonsága, hogy a beágyazási rétegben kinyert információt eltárolhatjuk, és bemenetül szolgálhat más tanuló algoritmusoknak. 33
39 3.4. ARIMA és egyéb modellek Röviden összefoglalom a felhasznált modellek tulajdonságait és az ezeket jellemző működési elveket. ARIMA Az ARIMA modellt illetően említettem, hogy közkedvelt lineáris modellként tekintenek rá. Az ARIMA az Autoregressive Integrated Moving Average-ből képzett betűszó, magyar megfelelője autóregresszív, integrált mozgóátlag [29]. Az ARIMA modell stacionárius idősorokra alkalmazható, ami azt jelenti, hogy az adatok statisztikai jellemzői változatlanok az idő előrehaladásával. Ezek közé a tulajdonságok közé tartozik az átlag, variancia és az autokorreláció is. Amennyiben nem ilyen jellegű az idősorunk, el kell végezni a megfelelő transzformációkat, mint például a különbség képzés és logaritmizálás. A modellt paramétereivel együtt ARIMA (p,d,q) módon szokták ábrázolni. Ebben szemléltetési módban a p az autoregresszív, a d az integráló, q pedig a mozgóátlag tag fokszámát jelenti. A kimenet pedig az alábbi módon értelmezhető: Y előrejelzett érték = konstans és/vagy súlyozott összege egy vagy több előző Y értéknek és/vagy súlyozott összege egy vagy több előző hiba értéknek. Ahogy már említettem a véletlen bolyongás (ARIMA (0,1,0)), exponenciális simítás (ARIMA (0,1,1)) az ARIMA modell specifikus esetei. Az ARIMA modell általános felírását a 3.1-es egyenlet mutatja be., ahol: t az adott idő pillanat, µ az átlag tag, B Φ(B) (1 B) d Y t = µ + Θ(B) Φ(B) a t (3.1.) a hátra tekintő operátor, azaz BX t = X t 1 az autoregresszív operátor, amit a hátra tekintő operátor polinomjával fejezhetünk ki: Φ(B) = 1 Φ 1 B Φ p B p Θ(B) a mozgóátlag operátor, amit a hátra tekintő operátor polinomjával fejezhetünk ki: Θ(B) = 1 Θ 1 B Θ q B q a t a véletlen hiba. 34
40 Ezek alapján például az ARIMA (1,1,2) modell az alábbiak szerint alakul (3.2. képlet): (1 B)Y t = µ + (1 Θ 1B Θ 2 B 2 ) (1 Φ 1 B) a t (3.2.) Megjegyzendő, hogy léteznek még hasonló modellek, mint a szezonalitást is figyelembe vevő SARIMA módszer is, de ezekkel egyelőre nem foglalkoztam. Az ARMA modellről szóló első leírás pedig 1951-ben került publikálásra [53]. Eltolás modell Amikor eltolás modellre hivatkozok, egy olyan modellt értek alatta, ahol az aktuális elem értéke megegyezik valamelyik előtte lévő elem értékével. Így egyetlen paramétere van, az, hogy milyen nagyságú eltolást használunk az aktuális időpillanathoz tartozó érték meghatározására. Például 7-es eltolás egy teljes idősor esetében azt jelenti, hogy egy hét múlva a mai napi érték fog ismét szerepelni, nyolc nap múlva a holnapi, és így tovább. Lineáris regresszió A klasszikus lineáris regresszión belül a többszörös lineáris regressziót használtam, mivel több független változót is figyelembe vevő modellre volt szükségem, valamint a célváltozó egy skaláris változó. Célja, hogy megtaláljuk a magyarázó változókhoz tartozó paramétereket, amik valamilyen módon minimalizálják az elvárt és kapott kimenet közti különbséget. Ehhez a klasszikus becslési eljárás a legkisebb négyzetek módszere [54]. Ridge regresszió Ridge regresszió a lineáris regresszió azon változata, ahol regularizációt is használunk. Ez azt jelenti, hogy a modell szabályozza a regressziós együtthatókat, mégpedig azzal, hogy bünteti azokat az együtthatókat, amik nagy értéket vesznek fel. A büntetés pedig L2 regularizáció szerint az együttható négyzetes értékével arányos. A Ridge regresszióhoz tartozik egy alfa paraméter is, ami meghatározza, hogy milyen mértékben legyen hangsúlyos a büntetés és a hiba minimalizálás. Ridge regresszió fontos tulajdonsága, hogy mindenképp szerepeltetni fogja az összes független változót (egyik együtható se lesz 0), viszont jó szolgálatot tehet a túltanítás megakadályozásában [55]. 35
41 LASSO regresszió LASSO regresszió a Ridge regresszióhoz hasonló elven működik, és a név egy betűszó, ami a Least Absolute Shrinkage and Selection Operator szóösszetételből származik. Itt a modell komplexitását L1-es regularizáció szabályozza, azaz nem négyzetes, hanem csak lineáris a büntetés mértéke. Itt is ugyanúgy létezik egy alfa paraméter is. LASSO esetén az együtthatók felvehetnek 0 értéket is, ami azt jelenti, hogy az adott változó nem fog hozzájárulni a célváltozó értékének kialakulásában. Ezt a tulajdonságát kihasználva a LASSO regressziót jellemző kiválasztásra is lehet használni. További különbség a két módszer között a korreláló független változók tekintetében, hogy míg a Ridge eljárás nem fog kizárni egyetlen jellemzőt se, addig a LASSO módszer a korreláló attribútumok közül csak egyet fog meghagyni [56]. Döntési fák A döntési fák a felügyelt tanulási módszerek családjába tartoznak. Az algoritmus lényege, hogy egyszerű döntési szabályok alapján készít előrejelzést. Alkalmazható mind osztályozási mind regressziós feladatokra is. A hierarchikus felépítése miatt hívják fának, mivel a döntési szabályokat az algoritmus egymás után hajtja végre, amit fa struktúrával szemléletes ábrázolni. Számos előnyös tulajdonsága között szerepel az is, hogy viszonylag kevés előfeldolgozási lépést követel meg az adathalmazt illetően, valamint white box modellként viselkedik, azaz könnyen érthető és áttekinthető az algoritmus tanulási folyamata. A döntési szabályokat úgynevezett vágások segítségével alakítja ki, amik lehetnek bináris, de több kimenetelű feltételek is. A vágások lényege, hogy a felosztást követően minél homogénebb csoportok jöjjenek létre. Leveleknek nevezzük azokat a csúcsokat, amiknél már nem történik további bontás, ezek adják meg a bemeneti vektorhoz tartozó predikciót. Az algoritmus nem csak vágásokat, hanem visszavágásokat (pruning) is használ, aminek célja többek között a modell komplexitásának csökkentésén keresztül a túltanítás megakadályozása. Az algoritmus lépésszáma logaritmikus nagyságrendű a bemeneti minták függvényében [57]. Random Forest A random forest a döntési fákon alapuló gépi tanulási eljárás. A döntési fák esetében a globális optimum megtalálása NP-teljes feladat. Ehelyett a gyakorlatban megelégszünk a szuboptimális megoldással, illetve együttes (ensemble) tanulással javíthatunk a modell teljesítményén. Az együttes módszerek célja megtalálni a megfelelő hangsúlyt a bias és 36
42 variancia között. Az egyik ilyen módszer a zsákolás (bagging, bootsrap aggregating), aminek feladata a variancia csökkentése ezzel a túltanulás megakadályozása és az általánosítás erősítése. A zsákolás alapelve, hogy az eredeti tanító adathalmazból több tanító halmazt alakítunk ki visszatevéses kiválasztással, majd azon futtatjuk az algoritmust külön-külön, végül pedig eredményeiket kombináljuk. A mintavételezés azért fontos, mivel azonos tanító adatokat alapul véve magas lenne a korreláció a modellek között, vagy determinisztikus modelleket használva ugyanazokat a modelleket kapnánk. A random forest is egy ilyen zsákoló elven működik, kiegészítve azt a véletlen altér módszerrel, ami a vágások során jelenlévő jellemzőket is véletlen módon választja ki. Ennek motivációja megint csak a korreláció csökkentése, mivel lehetnek olyan jellemzők, amik nagymértékben hozzájárulnak a célváltozó értékéhez, és alap esetben szinte mindegyik együttes modellben szerepelnének. A random forest tehát egyszerűen fogalmazva mély döntési fák kombinációja, ahol a kimenetet többségi szavazással (osztályozás) vagy átlag számítással (regresszió) kapjuk. Mind a random forest, mind a döntési fák alkalmasak a jellemzők fontosságát szemléltetni [58]. XGBoost Az XGBoost az Extreme Gradient Boosting kifejezés rövidítése, amiből a boosting gyorsító eljárást jelent. A gyorsító módszer a zsákoláshoz hasonlóan egy együttes módszer. Lényege, hogy kevésbé eredményes önálló modelleket kombinál, és így ér el aggregáltan egy eredményesebb működést. A gyorsítás (boosting) során azonban a soron következő modellt úgy tanítjuk, hogy figyelembe vesszük az előző modell illesztést, és nagyobb hangsúlyt kapnak a hibásan kezelt megfigyelések. A gradient a gradiens eljárásra utal, ugyanis ezt használja a modell tanítás közben hiba minimalizálásra. Gyenge tanulóknak döntési fákat használ, így tulajdonképp az XGBoost egy fa gyorsító eljárás tovább fejlesztett implementációja [59] [60]. Aggregált modellek Aggregált modell alatt a dolgozat során a stacked modell eljárást értem, ami modellek ötvözését jelenti. Ez szintén az együttes módszerek közé sorolandó. Lényege, hogy adott feladatra betanított modellek predikcióját kombinálja. A különbség abban rejlik az eddig felsorolt együttes megoldásokkal szemben, hogy a kombináció nem a többségi módszer vagy átlagolás, hanem egy újabb meta szint, azaz valamilyen tanuló eljárás. Ennek az újabb rétegnek a feladata meghatározni, hogy a betanított modellek milyen arányban és 37
43 módon járuljanak hozzá a végső predikció értékéhez. A modell típusa szerint lehet ugyanolyan típusú, más-más paraméterekkel, de előfordul vegyes megoldás, és nagyon sok egyéb lehetőség is. Ezt a feladatot sokszor látja el logisztikus regresszió, de én neurális rétegeket használok ehhez is. 38
44 4. Megvalósítás Ebben a szekcióban gyakorlatias formában írom le, milyen feladatokat végeztem el a diplomatervezés során. A bemutatás menete részben az előbb kifejtett szempontok alapján történik, részben a megvalósítás ismertetéséhez leginkább illő módon. Bemutatom a problémákat, és ezzel együtt az egyes modellek megvalósítására is kitérek. Célom a feladatkiírásban vállaltak teljesítése volt. Ehhez elsősorban egy konkrét adathalmazt felhasználva készítettem el a modelleket, de volt, hogy egyéb adatforrást használtam fel további vizsgálataimhoz. Létrehoztam regressziós modelleket, illetve a szentiment elemzéshez szükséges osztályozókat is. Ez a megközelítés lehetővé tette, hogy a megalkotott neurális hálózatokat egyéb módszerekkel összevessem. Továbbá a sok paraméteres heurisztikus eljárásoknál fontos szerepet kap a paraméterek optimalizálása. Ez energiaigényes feladat bármilyen módszert is alkalmazunk, mivel ilyenkor sok iterációs futtatást végzünk. Már bemutattam, hogy a különböző megoldások között milyen különbségek vannak. Számos előnyös tulajdonsága miatt én a Bayes-i megközelítést alkalmazó Hyperopt-ot és Hyperas-t alkalmaztam, ahol csak lehetett. Minden a dolgozatban szereplő modellnél végeztem optimalizációs lépéseket. Az egyetlen modell, ami determinisztikus futású, az a lineáris regresszió, így esetében nem kellett finomítanom a paramétereken. Összességében nehéz megmondani az egyes modellek esetén hány fajta paraméter variációt teszteltem és hogy ez az eredmény milyen messze van az optimálistól. Ennek oka, hogy megannyi manuális futtatást is végeztem, valamint modellenként nagyon változó a paraméterek száma is. Általánosságban elmondható, hogy igyekeztem mindegyik modellt legjobb tudásom szerint kalibrálni. Modellenként több száz kísérletet végeztem. A Hyperopt-os futásokat érdemes vizualizálni is, így ellenőrizhető, hogy milyen paraméter értékek, hogy hatnak a végső eredményre. Erről egy szemléltető példát a függelékben (Függelék 2: Hiperparaméter optimalizáció) csatoltam. 39
45 4.1. Adatforrás kiválasztása Feladatomat a tervezés után azzal kezdtem, hogy releváns adatokat találjak az általam kitűzött cél megvalósításához. Ehhez szükségem volt a kereslettervezéshez használt adatok meglétére. Ezt illetően viszonylag nehéz dolgom volt, mert alig található publikus adathalmaz a cégek historikus eladási tranzakcióiról a világhálón. Hosszas kutatás után két adatforrást sikerült találnom. Ebből az egyik bárki számára hozzáférhető, a másik viszont privát elérésű. Az előbbi a már említett Kaggle portálról származik, és egy verseny keretében látott napvilágot. Az adatbázis több, mint németországi Rossmann üzlethelyiség információit tartalmazza. A verseny célja az volt, hogy a játékosok 6 hétre szóló előrejelzést készítsenek az egyes boltok eladási adataira vonatkozóan. A verseny időközben véget ért, és a szokásos módon a legeredményesebb versenyzők munkájáról tudományos leírás is született. A 4. helyen végző csapat [52] egy neurális hálózati modellel érte el ezt az előkelő helyezést. Éppen ezért számomra az ő megvalósításuk egy jó kiindulási pont volt, mikor ezzel a Rossmann-os adathalmazzal foglalkoztam. A másik adatforrásomat az SAP-nak köszönhetem, mivel rendelkezésemre bocsátotta egyik vevője éles megrendelési adatait. A cégről az SAP-s előírások miatt csak korlátozott formában írhatok. Az viszont nem titok, hogy amerikai gyökerű, a világon élvonalbeli termelő vállalatról van szó, akik háztartási, és higiéniai termékeket árusítanak, az éves bevételük pedig meghaladja az 1 millárd USD-t. Mivel a továbbiakban sem nevezhetem meg a vállalatot, ezért ABC néven fogok hivatkozni rá. Az ABC adatoknál a célom a telephelytől független, terméktípus bontású előrejelzés volt. Ezentúl a szövegelemzési modulhoz a Twitter portálról származó bejegyzéseket használtam, amiket több forrásból szereztem be. 40
46 4.2. Regressziós modell Regressziós modellnek nevezem a historikus rendelési adatokon alapuló megközelítést. Nem teljesen különíthető el a szentiment és aggregált hálózatoktól, mivel voltak átfedések, de jó választásnak tartom külön-külön bemutatni az egyes modelleket Adatok előkészítése Az előfeldolgozás összességében hosszadalmas folyamat volt, amihez időközben többször is visszatértem, újabb módszereket, és technikákat próbáltam ki. Az ABC adatsort.dat kiterjesztésű fájlként kaptam meg. Az ilyen fájlok generikus jellegűek, és nyersszövegként, de akár bináris formában is eltárolásra kerülhetnek. Az általam említett adatbázis fejléccel és tagoló karakterekkel volt ellátva. A Python-ban való munka igen könnyű vele, mivel a Pandas csomag beépítve tartalmazza a megfelelő beolvasó függvényt. Így beolvasás után úgynevezett Pandas dataframe-ként használhatjuk, amire úgy lehet gondolni, mint egy adatbázis táblára, azaz tartalmaz fejlécet, indexet és az adatokat rekordonként. Az eredeti jellemző neveket a 4.1. táblázatban lehet figyelemmel kísérni táblázat: ABC adathalmaz attribútumai eredeti nyelven és magyarázattal Attribútum név Magyar megfelelő ORDER_ID Rendelés azonosítója SALE_ORDER_LINE_ID Rekord azonosító ITEM_ID Termék azonosítója LOCATION_ID Forrás telephely azonosítója SHIP_TO_LOCATION_ID Cél telephely azonosítója CREATION_DATE Rendelés felvétel dátuma REQUESTED_DELIVERY_DATE Rendelés igényelt dátuma REQUESTED_QUANTITY Rendelt mennyiség OPEN_QUANTITY Nyitott (még nem szállított) mennyiség A meglévő adatokkal elővigyázatosan kell bánni, ezért én is megvizsgáltam, hogy vannak-e esetleg hiányos megfigyelések, esetleg egyéb torzulások. Ehhez első lépésként érdemes az adattáblák alapvető leíró adatait lekérni. Ennek eredménye látható a 4.1-es ábrán. A kép az ABC vállalat adatait jellemzi. Ebből leolvasható, hogy az ABC adatbázis kicsivel több, mint rekordot tartalmaz, és láthatók az eredeti jellemzők is. 41
47 <class 'pandas.core.frame.dataframe'> RangeIndex: entries, 0 to Data columns (total 9 columns): ORDER_ID non-null int64 SALE_ORDER_LINE_ID non-null object ITEM_ID non-null object LOCATION_ID non-null object SHIP_TO_LOCATION_ID non-null object CREATION_DATE non-null object REQUESTED_DELIVERY_DATE non-null object REQUESTED_QUANTITY non-null float64 OPEN_QUANTITY 0 non-null float64 dtypes: float64(2), int64(1), object(6) memory usage: MB 4.1. ábra: ABC adathalmaz számossága Az ABC adatokból jól látható, hogy az OPEN_QUANTITY attribútumot nem használták, ezt el is dobtam épp ezért. Ezenkívül meglepően jó adatbázist kaptam, mivel máshol nem szerepel ismeretlen érték. Azonban szerepelt 0 értékű rendelési mennyiség, ami szerint ezeken a napokon nem volt rendelés adott termékből. Az ilyen napokhoz 0.1- es szintetikus rendelést generáltam, mivel a későbbiek során a 0-ás értékek sok nem kívánt hibát okoztak volna. Az adatbázis oszlopai közül, amik számomra relevánsak voltak, azok a következők: ITEM_ID, REQUESTED_DELIVERY_DATE, REQUESTED_QUANTITY. Ebből az első a termék fajtákat jelöli, a második a kívánt rendelési dátumot, a harmadik pedig magát a rendelt mennyiséget. A termékfajtából megállapítottam, hogy db különböző szerepel az adatbázisban. Ezek után kíváncsi voltam a rendelési mennyiségek értéke, hogy alakul az idő függvényében. Ez kirajzolva a 4.2-es ábrán jelenik meg. 42
48 4.2. ábra: Érintetlen ABC adathalmaz rendelései az idő függvényében Látható, hogy szembetűnő kiugrások vannak a rendelt mennyiséget illetően, amiket orvosolni kellett. Következő lépésem az volt, hogy elemeztem az egyes terméktípusokból hány megfigyelést tartalmaz a tábla. Itt úgy határoztam, hogy a túlságosan kis számosságú termékeket kiszűröm az adatbázisból, lévén, ezekre egyelőre nem szeretnék előrejelzést adni, vagyis egy konstans értéknél (60) kevesebb megfigyeléssel rendelkező terméktípusokat kivettem az adatok közül. Ez látható a 4.3-as ábrán, ami egy violin plot, aminek neve arra utal, hogy bizonyos esetekben hegedűhöz hasonló formát vesz fel. A violin plot tulajdonképpen nem más, mint egy box plot, valamint két sűrűségfüggvény elforgatva. Ennek megfelelően ábrázol percentiliseket, és egyéb statisztikai leírást. A fehér pont az ábrán a mediánt jelöli, a fekete oszlop (interkvartilis) pedig az összes elem középső 50%-át jelöli. A sűrűség függvénynek köszönhetően pedig a megfigyelések eloszlása látható, azaz ott, ahol hasa van az ábrának, az a megfigyelés szám sokszor szerepel. Észrevehető az ábrán, hogy a legtöbb terméktípushoz db megfigyelés (nap) tartozik, és az alsó határ az explicit definiált 60 nap. 43
49 4.3. ábra: A terméktípusonkénti rekord számok eloszlása Ezután kezdhettem foglalkozni a kilógó, szélsőséges rendelési mennyiségekkel. Ennek kiküszöbölésére, csoportba foglaltam a termékeket, pontosabban aggregáltam őket, nap - terméktípus bontásban. Majd kiszámoltam a csoportonkénti átlagot és szórást, majd ezután azt ellenőriztem, hogy az adott rendelési mennyiség és a csoport várható értékének különbsége, hogyan viszonyul a csoport szórásához. A szórásnál nagyobb eltérést büntettem. Ez Python kódban így történik, mint a 4.1-es kód részletben. orders['outlier'] = orders.groupby(['item_id'])['requested_quantity'].apply( lambda x: abs(x - x.mean()) > 2.9*x.std()) 4.1. kód: Részlet a kilógó adatok szűrésére 44

50 A fentieket annyival egészíteném, ki, hogy nem tisztán a szóráshoz viszonyítok, hanem bizonyos fokú enyhítést engedek meg, mikor a szórás többszörösét veszem. Jól látható a rendelési mennyiségek alakulása a szűrőfeltétel előtt és után a 4.4-es ábrán. Többek között megfigyelhető, hogy sikerült a kiugróan magas rendelési mennyiségeket eliminálni. Ennek ellenőrzésére az eredeti (piros görbe) és új (kék görbe) közti eltérést érdemes szemügyre venni ábra: Kilógó (outlier) adatok eliminálása előtti és utáni rendelés mennyiségek Lényegében ezek voltak a megismerkedés és adattisztítás lépések. Végeredményben az eddig elvégzett előkészítő jellegű döntések azt eredményezték, hogy kizártam db terméktípust, ami rekordnak felel meg (aggregálás után), valamint a kilógó értékek miatt figyelmen kívül hagytam még db bejegyzést. Nem maradt más hátra, mint új attribútumok hozzáadása, és a meglévők részekre bontása. Ez azt jelentette, hogy a dátum mező eredeti év-hónap-nap struktúrájából év, hónap és nap attribútumokat hoztam létre. A neurális hálózatok szempontjából nem lehet pontosan tudni, hogy milyen jellemzők lesznek azok, amikből a modell jól tanul. Úgy tarthatjuk logikusnak, hogy például olyan oszlopokat nem érdemes szerepeltetni, amelyek lineárisan függnek egymástól. Ám ez a valóságban a tapasztalatokra alapozva nem 45
51 mindig van így. Ebből kifolyólag ebben a fázisában érdemesebb inkább több attribútum fajtát alkalmazni, és későbbi lépések során majd szűkíteni ezt a listát a neurális hálózat viselkedésétől függően. Tehát elvégeztem az attribútumok bővítését, és ezeket a jellemzőket építettem be az adatstruktúrába: YEAR: a rendelés éve, MONTH: a rendelés hónapja, WEEK: a rendelés hete (1-53), DAY: a rendelés napja (0-30), DAY_OF_WEEK: a rendelés napja a héten (0-6), DAY_OF_YEAR: a rendelés napja az évben (0-365), QUARTER_OF_YEAR: a rendelés negyedéve (0-3), IS_WEEKEND: a rendelés hétvégére vagy hétköznapra esik (0-1), QTY_DELTA: az adott időpontbeli, és azt megelőző rendelés mennyiségben mért különbsége, QTY_DELTA2: az előző értékek különbsége, QTY_LOG: az adott rendelés mennyiségének természetes alapú logaritmikus értéke, ZEROS_CUMSUM: adott napig előforduló 0-ás rendelések száma adott termékből, ZERO_FULL_RATIO: adott napig a 0-ás és nem 0-ás rendelések aránya adott termékből, ZERO_QTY_SEQUENCE: adott napot megelőző 0-ás rendelés sorozat hossza adott termékből, MAX_ZERO_SEQUENCE: adott napig előforduló leghosszabb 0 sorozat adott termékből, MEAN_OF_ZERO_SEQ: adott napig előforduló átlagos 0 sorozat hossza adott termékből, RETURN: a logaritmikus mennyiség értékek különbsége, RETURN_X: az előzővel megegyező szerepű, X időablakkal eltolt hányados, QTY_PRED: a mennyiségi érték eltolva egy időlépéssel előrefele, MOVEMENT: mozzanat az előző értékhez képest (felfele, lefele, változatlan), NEXT_MNTH_END: a hónap végéig hátra lévő napok száma, NEXT_QRT_END: a negyedév végéig hátra lévő napok száma, DAY_OF_QRT: az adott negyedéven belüli nap, (0-92) 46
52 NEXT_HOLIDAY: PREV_HOLIDAY: ROLLING_MEAN_X: ROLLING_STD_X: a következő ünnepnapig hátra lévő napok száma, az előző ünnepnap óta eltelt napok száma, az utolsó X db bejegyzés mozgóátlaga, az utolsó X db bejegyzés mozgó szórása. A felsorolt attribútumokban megtalálható az említett korreláció, például az aktuális napból egyértelműen következik (a hónap ismeretében), hogy hány nap van még a hónap végéig, ennek ellenére, javító hatású lehet, ha ez utóbbit is felvesszük. Fontos kiemelnem, hogy a különbségeket az egyes rendelések között mindig terméktípus csoportonként végzem el, mivel így lesz következetes a számítás. Továbbá egyes attribútumok külön részletezést érdemelnek. Ezek a RETURN, MOVEMENT és *_HOLIDAY jellemzők. Az ünnepnapok az USA-beli piros napos ünnepeket takarják. Ennek oka, hogy az ABC adathalmaz amerikai lokalizáicók rendeléseit tartalmazza. Ehhez a Pandas USFederalHolidayCalendar modulját használom, és ebből számoltam a különböző távolságokat. A mozzanat (MOVEMENT) a logaritmikus hányadosból (RETURN) származtatott mutató, így először utóbbit részletezem. A logaritmikus megtérülés matematikai leírását a feladatom szempontjából a 4.1-es képleten mutatom be. logaritmikus megtérülés = log e ( qty i+x qty i ) (4.1.), ahol qty i, qty i+x rendre az aktuális rendelési, illetve x időponttal eltolt rendelési mennyiség. Ezt a mutatót a kvantitatív pénzügyi területen használják előszeretettel bizonyos matematikailag kellemes tulajdonsága miatt, mint, hogy mentesíti az idősort a trendtől. Valamint egy egyszerű megtérülés átlagával szemben igaz rá, hogy míg előzőnél egy 20%-os csökkenést követően 25%-os növekedést kéne elérni, hogy a kiindulási értékhez visszatérjünk, addig a logaritmikus változatnál ezek a számok as és as értékekkel érhető el. Ez a mutató volt a predikciók egyik célváltozója, amire szerettem volna becslést adni. Az általam mozzanatnak (MOVEMENT) nevezett attribútum pedig arra szolgál, hogy osztályozási feladatnál 3 különböző csoportba sorolja a megfigyeléseket, úgy, mint változatlan, felfelé irányuló, lefelé irányuló elmozdulás. Ezt az értéket az előző (természetes alapú) logaritmikus hányadosból számoltam. A számolás menete Python kódban a következők szerint történt (4.2-es kódrészlet). 47
53 def trend(x, mean, var): ratio = 0.05 if (abs(x-mean)<ratio*(var)/10): return 0 if (x-mean>ratio*(var)/10): return 1 if (x-mean<-ratio*(var)/10): return kód: Az osztályozáshoz szükséges címkéző függvény A kalkuláció menete szövegesen pedig a következő. Kiszámítom a terméktípusonként az adott csoportot leíró átlagos megtérülési rátát, valamint ugyanennek szórásnégyzetét. Ezt követően az aktuális megtérülési ráta átlagtól való eltérését hasonlítom össze a szórásnégyzettel. Ez a számítás alkalmas arra, hogy megtérülési ráta függvényében eldöntsem egy adott mennyiségbeli változásról, hogy az pozitív, negatív vagy semleges irányú. A ratio nevű paraméter értékének megválasztása kulcsfontosságú, ennek függvénye, hogy hasonló nagyságú osztályok jöjjenek létre. A jellemzők között találhatóak nem maguktól értetődőek is. Ezeket mind azért hoztam létre, hogy megpróbáljam segíteni a modellt a 0-ás rendelési mennyiségek kezelésére. Az olyan jellegű termékeket, amire ritkán jelentkezik igény, sporadikus keresletű termékeknek nevezik, és általában külön eljárást igényelnek. Van ilyen termék ABC vállalat palettáján is, de első megközelítésben mindenképp egyöntetűen szerettem volna kezelni az összes terméktípust. Ezután következhetett az adatok érték szerinti átalakítása, azaz a normalizálás és standardizálás. Jelen esetben normalizáláson egy minimum-maximum érték közti skálázást, standardizáláson pedig olyan átalakítást értek, aminek következtében a transzformált adatoknak 0 lesz a várható értéke és 1 a szórása. A neurális hálózatok bemenetét szokás szerint standardizálni szokták, mivel így gyorsabb konvergenciát lehet elérni a tanulás során. A kimenetre a normalizálás jellemző ([0,1] intervallum), mivel így az utolsó rétegbeli aktivációs függvény kimenetéhez igazíthatjuk a kimeneti értékkészlet intervallumát. Ennek megfelelően én is elvégeztem a bemeneti adatokon a standardizálást, a kimeneten a normalizálást. Ezeket sorra a as egyenleteken szemléltetem. x = x x (4.2) σ, ahol x az eredeti jellemző vektor, x a vektor átlaga, σ pedig a standard szórása. 48
54 y = y min(y) max(y) min(y) (4.3), feltéve, hogy a [0,1] intervallumba skálázunk, és ahol y az eredeti, y a normalizált érték, a min(y), max(y) értékek rendre az y vektor minimum és maximum értékét jelentik. Az intervallumot pedig azért [0,1]-nek határoztam meg, mert bevett szokás regressziós esetben a neurális hálózat kimeneti rétegében sigmoid függvényt alkalmazni, ami ezt az értékkészletet támogatja. Osztályba sorolásnál a meghatározandó címkék értéke pedig az 1-az-N-ből kódolás miatt, csak 0 és 1 értéket vehet fel. Ezekkel a lépésekkel az ABC adathalmazt a megfelelő struktúrára hoztam. Így elértem ahhoz a ponthoz, hogy neurális hálózati modellt építsek, és felhasználjam ezeket az adatokat a modell tanítására. A kezdeti információs táblázat az előfeldolgozás után erősen átalakult. Az aggregáció bevezetése például az körüli rekord számot harmadára redukálta, viszont ez egy elkerülhetetlen lépés volt, ahhoz, hogy termék szintű kereslettervezést tegyek lehetővé. Az átalakított adattábla jellemzői a következők: RangeIndex: entries, 0 to Data columns (total 31 columns): ITEM_ID non-null object REQUESTED_DELIVERY_DATE non-null datetime64[ns] REQUESTED_QUANTITY non-null float64 ORDERS_THAT_DAY non-null float64 YEAR non-null int64 MONTH non-null int64 DAY non-null int64 WEEK non-null int64 DAY_OF_WEEK non-null int64 DAY_OF_YEAR non-null int64 QUARTER_OF_YEAR non-null int64 IS_WEEKEND non-null int64 QTY_LOG non-null float64 DATE_DELTA non-null float64 DATE_DELTA non-null float64 QTY_DELTA non-null float64 QTY_DELTA non-null float64 RETURN non-null float64 QTY_PRED non-null float64 MOVEMENT non-null int64 IS_ZERO non-null bool ZEROS_CUMSUM non-null int64 ZERO_FULL_RATIO non-null float64 ZERO_QTY_SEQUENCE non-null int64 MAX_ZERO_SEQUENCE non-null int64 MEAN_OF_ZERO_SEQ non-null float64 NEXT_MNTH_END non-null int64 NEXT_QRT_END non-null int64 DAY_OF_QRT non-null int64 NEXT_HOLIDAY non-null int64 PREV_HOLIDAY non-null int64 dtypes: bool(1), datetime64[ns](1), float64(11), int64(17), object(1) memory usage: MB 49
55 Ehhez a listához még hozzáadódnak a mozgó mutató értékek és a korábbi időpontokra vett megtérülési ráta mutatók is, de ezeket a könnyebb változtathatóság miatt később adom a táblához. Ezenkívül voltak olyan átalakítások, amik szintén nem minden neurális hálózati modell feltételeinek felelnek meg, ezért ezeket modell specifikusan kezeltem Jellemzők kiválasztása Az adatok előkészítésénél látható volt, hogy számos származtatott jellemzőt bevezettem a meglévők mellé. Ahogy már ott is írtam ezeknek a variációit ki kell próbálni majd meg kell határozni melyik a legideálisabb attribútum halmaz. Így is tettem, és készítettem egy szkriptet, ami pontosan ezeknek a kombinációknak a kipróbálását teszi lehetővé automatizált módon. Ennek a programnak 4 fő része van: Előkészítő egység: Ez a rész az összes lehetséges bemenetet legenerálja. A későbbiek során történik az aktuális bemenet kiválasztása. Tesztet irányító főprogram: Itt zajlik tulajdonképpen a teszt menetének szervezése. Végig iterál a paraméterül kapott teszt listán, és az abban szereplő összes esetre elvégzi a regressziós tesztet. Emellett globális adatrögzítést végez, hogy összehasonlíthatók legyenek a teszt eredmények. Lehetőség van legenerálni vele az összes lehetséges bemeneti kombinációt, azonban ez sok lehetséges bemeneti változó esetén nem szerencsés mivel exponenciális mértékben nő a kombinációk száma. Nálam összesen kb. 45 db változó szerepelt a bemeneti listán, ennek kimerítő tesztelése 2 45 tesztesetet jelentett volna. Ezt elkerülve, heurisztikákra alapozva alakítottam ki a lehetséges bemeneti kombinációkat, nagyságrendileg 50-et. Tesztesetek listája: Ez egy szöveg alapú fájl, amiben a különböző oszlopokat kitöltve adhatjuk meg, hogy milyen bemeneti tesztesetekre vagyunk kíváncsiak. Kisegítő eszközök: Ez a modul olyan függvényeket tartalmaz, ami az adatok merevlemezre mentését, és a standard kimenetre történő naplózást teszi lehetővé. 50
56 Végül a teszt eljárás eredményéül azt kaptam, hogy ezeket a változókat érdemes szerepeltetnem első körben a modellben: YEAR: a rendelés éve, MONTH: a rendelés hónapja, WEEK: a rendelés hete (1-53), DAY: a rendelés napja (0-30), DAY_OF_WEEK: a rendelés napja a héten (0-6), IS_WEEKEND: a rendelés hétvégére vagy hétköznapra esik (0-1), NEXT_HOLIDAY: a következő ünnepnapig hátra lévő napok száma, PREV_HOLIDAY: az előző ünnepnap óta eltelt napok száma, ITEM_ID: terméktípusa, ZEROS_CUMSUM: adott napig előforduló 0-ás rendelések száma adott termékből, ZERO_FULL_RATIO: adott napig a 0-ás és nem 0-ás rendelések aránya adott termékből, ZERO_QTY_SEQUENCE: adott napot megelőző 0-ás rendelés sorozat hossza adott termékből, MAX_ZERO_SEQUENCE: adott napig előforduló leghosszabb 0 sorozat adott termékből, MEAN_OF_ZERO_SEQ: adott napig előforduló átlagos 0 sorozat hossza adott termékből, ORDERS_THAT_DAY: rendelések száma adott napon, ROLLING_MEAN_X: az utolsó X db bejegyzés mozgóátlaga, Az összes modellhez ezeket az attribútumokat használtam bemenetként (, kivétel ARIMA modell, ami idősor alapú és nem okozati módszer). Érdekes lehet megfigyelni, hogy az egyes modellek, amik képesek a jellemzőket fontosságuk szerint rangsorolni, hogyan vélekedtek az attribútumokról. Erről egy összefoglaló táblázatot készítettem 3 modellen kiértékelve az együtthatóikat (Függelék 1: Jellemzők fontossága). 51
57 4.2.3 Modellek létrehozása A historikus rendelési adatok feldolgozásához regressziós modellre volt szükségem, hogy konkrét értéket tudjak meghatározni előrejelzés céljából. Így a célváltozó minden esetben a logaritmikus megtérülési ráta volt. Ennek hátránya, hogy a kiértékelésnél komplexebb visszaalakítást igényel, ugyanakkor elhangzottak már az előnyös tulajdonságai is. Amiben a legnagyobb különbség volt, azok a neurális hálózat topológiák, amiket alkalmaztam, valamint a hozzájuk tartozó hiperparaméterek és a kiválasztott bemeneti jellemzők. A kimeneti rétegben aktivációs függvénynek sigmoidot, költségfüggvénynek pedig MSE-t, MAE-t, MAPE-t és MASE-t használtam. Az architektúrát tekintve tanítottam előrecsatolt (FC), rekurrens (LSTM) és konvolúciós (1D Convnet, CNN) hálózatot is. Kategorikus attribútumok tekintetében, az ABC vállalat esetében eleinte különböző terméket tartalmazott az adatbázisom. Igaz ezt bizonyos szűrő feltételekkel redukáltam, de így is terméktípust különböztettem meg, ami még mindig magas kardinalitást jelent. Egy lehetséges megoldás lehetett volna, hogy a termék neveket címkékre cserélem le (pl. 1,2,3,4 ), azonban ez azt jelentené az átskálázott adatokon, hogy egy kis tévedés is egy egészen más terméket jelent. További megoldást jelenthet a már bemutatott 1-az-N-ből kódolás használata. Ez az átalakítás már egy fokkal jobbnak mondható, azonban új problémákat idézhet elő, ahogy nálam is idézett. A tábla aritása, azaz a jellemzők száma több, mint lett. Az ilyen átalakítás meglehetősen nagyméretű ritka mátrixot eredményez, ami nehezíti a neurális hálózat tanítását. A másik probléma az 1-az-N-ből kódolással, hogy semmiféle viszonyt nem vesz figyelembe a terméktípusok között, hasonlóan a címkékkel való megkülönböztetéshez. Ezzel szemben a beágyazásos módszer képes interpretálni bizonyos jellemvonásokat, és ennek megfelelően kialakítani jellemzővektorokat, amik már magukban hordozzák a 52
 egy példa a neurális háló beágyazási rétegében kinyert értelmezésről.")
58 termékek közti viszonyrendszert. Ezt a módszert érdemesnek találtam a többi kategorikus változóra is alkalmazni ábra: Embedding réteg által kinyert tudás t-sne 2D vizualizálása a hét napjait illetően A fenti ábrázolás (4.5. ábra) egy példa a neurális háló beágyazási rétegében kinyert értelmezésről. A megjelenítéshez a t-sne algoritmust használtam [61] [62]. A t-sne, vagy teljes nevén t-distributed Stohastic Neighbor Embedding egy gépi tanuló algoritmusok családjába tartozó dimenzióredukciós eljárás, amit Hinton professzor társával fejlesztett ki, Hinton korábbi SNE nevű módszerére alapozva. A tanulmányban számos előnyös tulajdonságát bemutatják egyéb dimenzió csökkentő algoritmushoz képest. Az eredményeket vizuálisan és matematikailag is szemléltetik. A t-sne 2 és 3 dimenzióba képes leképezni a sok dimenziós vektorokat. Nagyon magas dimenziójú tér esetén érdemes valamilyen más redukciós módszerrel (pl. PCA) csökkenteni a dimenzió számot (pl. 50-re) t-sne használata előtt. Érdemes tudni, hogy újbóli futtatása során másmás vizualizációt kapunk. Ezenkívül az se feltétlen igaz, hogy az eredeti pont csoportok a redukció után is ugyanakkora csoportokként, ugyanolyan távolságokkal jelennek meg. Zárásképp, a kategorikus jellemzők ilyen fajta ábrázolásában olyan lehetőség rejlik, amit ki is használtam, hogy a beágyazási réteg súlyait eltárolva, később azt fel lehet használni egyéb modellek bemeneténél. 53
59 FC, LSTM és 1D Convnet A három, általam alkalmazott neurális hálózat típus közti különbségeket elméleti szinten már röviden bemutattam és kifejtettem, hogy melyiknek milyen előnyös tulajdonságai vannak. Neurális hálózat implementációja során az egyik gyakorlati különbségeket a bemeneti adatok szerkezete jelenti. A kimeneti réteg viszont megegyezik mind a három esetben, mivel ugyanarra a regressziós feladatra tanítom őket. A bemenetre FC esetén az a jellemző, hogy a tanító eljárásnak egy rekord magyarázó változóit és célváltozóját kell beadni. A hiperparaméter optimalizálás során pedig az alábbi feltételekkel futtattam a tesztet: Optimalizáló: [ rmsprop, adam, adadelta, nadam ] lista Aktivációs függvény (minden rétegben): [ relu, sigmoid, tanh ] lista Neuronok száma (minden rétegben): [128, 256, 512, 1024] lista Dropout (minden rétegben): [0.1, 0.5] intervallum A végső paraméter értékek minden esetben az 5.1. Hiperparaméter optimalizálás eredményei fejezetben kerülnek bemutatásra, az optimalizáció pedig a 3.1. Felhasznált folyamatok című részben bemutatott Bayes-i alapon működik, és megvalósításához a már említett Hyperopt és Hyperas könyvtárakat használtam. Az LSTM bemenete némiképp eltér az előzőtől, itt egymást követő adatokat kell beadni, amiben engedjük, hogy megtalálja a szekvenciákban rejlő mintákat, és kialakíthassa a belső memóriának nevezhető tudást. Azaz az aktuális kimenet értékét nem csak az aktuális, hanem visszamenőleg több megfigyelésből levont tanulság alakítja. LSTM hálózat esetén a következő lehetséges paraméterteret adtam be tesztelésre: Optimalizáló: [ rmsprop, adam, adadelta, nadam ] lista LSTM egysége száma 1. réteg: [64, 128, 256] lista LSTM egysége száma 2. réteg: [32, 64] lista LSTM egysége száma 3. réteg (ha szerepel): [64, 128] lista Dropout (minden rétegben): [0.1, 0.5] intervallum 54
60 Praktikusság szempontjából szerencsésnek mondható, hogy az 1D Convnet bemenete ugyanolyan formában várja el az adatokat, mint az LSTM. Ennek a típusnak a tesztelt hiperparaméter értékei így alakultak: Optimalizáló: [ rmsprop, adam, adadelta, nadam ] lista Szűrők száma (minden rétegben): [4, 8, 16, 32, 64] lista Szűrő mérete - 1. réteg: [2,3,4, 5, 6, 7] lista Szűrő mérete - 2. réteg: [2,3] lista ARIMA Az ARIMA modell volt az egyik viszonyítási modell, amihez a neurális hálózat eredményeit hasonlítottam (lásd 2. Előzmények fejezet). Ehhez el kellett készítenem a szükséges ARIMA modellt. Az ARIMA modelles megközelítésben nagy változást jelentett, hogy a termékeket nem tudom egységesen kezelni, hanem egyenként kell, mindegyik (1.289 db) termékre megalkotni az azt leíró modellt. Ehhez ugyanazt az előfeldolgozott adatsort használtam, mint a többi modell esetén. Azonban az ARIMA egy idősori modell, így az egyetlen változó maga a rendelési mennyiség napi bontásban. Ezután stacionárius idősort kellett használnom az ARIMA eredményes tanításához. A stacionaritás azt jelenti, hogy az idősor statisztikai jellemzői nem változnak. Emiatt a kereslet logaritmusát használtam, illetve az ARIMA integráló paraméterét ( d ) 1-re állítottam. A modell illesztést termékre kellett elvégeznem. Ezt két körös megközelítésben végeztem. Először mindegyik modellre tapasztalati úton megkerestem az ideális p,d,q paraméter hármast. Ebből az integráló tag fix volt a fentiek alapján, viszont az autoregresszív ( p ) és mozgóátlag ( q ) paraméter több kombinációján is végeztem tesztet a validációs halmazon. Előzetes tesztek során úgy tapasztaltam, hogy míg a p paraméter leggyakrabban a [1,2,3,4,5,6,7] lista egyik értékét veszi fel, addig a q paraméter az [1,2,3,4,5] lehetőségek közül kerül ki. Ennek fényében termékenként 35 (7x5) különböző lehetőséget vizsgált a szkript, amit készítettem. Ezután az AIC mutató [63] szerinti legkedvezőbb paramétereket használtam a végső kiértékeléshez. Az AIC (Akaike information criterion) teszt feladata összehasonlítani bizonyos statisztikai modelleket az illeszkedés és komplexitás szempontjából. Minél alacsonyabb értéket mutat az AIC érték, annál jobb a modell, azaz annál kedvezőbb az illeszkedés és a modell bonyolultsága közötti egyensúly. Figyelembe kell venni, hogy az AIC csak relatív jóságot mér, azaz ideális két modell összehasonlítására. Azonban abból a megfigyelésből, 55
61 hogy az egyik megoldás AIC-je kisebb, még nem következik, hogy az egy jó modell, hanem csak annyit tudtunk meg, hogy előnyösebb, mint a másik. ARIMA volt az egyetlen modell, ahol nem a Hyperopt könyvtárat használtam, bár itt is tapasztalati megoldással éltem. Ahogy említettem az AIC mutatót figyeltem a különböző kombinációk esetén terméktípusonként külön-külön. Így a tanító, illetve validációs halmazon értékeltem ki a modell jóságát, és a legígéretesebb paraméterekkel futtattam a végső kiértékelést a teszt halmazon. Az eredmény termékre adott p, q paraméter páros (a d paraméter konstans 1). Lineáris regresszió Megvalósításához a Scikit programcsomag LinearRegression osztályát használtam, ami nem gradiens alapú, hanem analitikus megoldás (normal equation) alapján működik. Az adatok nem igényeltek további előfeldolgozási lépéseket, mivel egyrészt ugyanazokat a jellemzőket használtam bemenetnek, mint a neurális hálózat esetén, másrészt ugyanúgy érdemes standardizálni (0 várható érték, 1 szórás). A standardizálás azért fontos, mivel az együtthatók értelmezésekor félrevezető eredményt kaphatunk olyan esetben, ha az eredeti attribútumok más tartományból vehették fel értékeiket. A lineáris regresszió esetén 2 modellt is illesztettem. Míg elsőbe az összes terméket együtt kezeltem, addig a másodikban termékenként, vagyis alkalommal végeztem tanítást. Ezzel explicit elkülönítettem a termékeket egymástól. Előbbi esetben a termék változó bemenete itt is a regressziós neurális hálózat tanítása során kinyert termék mátrixból származik, ezzel redukálva dimenziószámot. Termékenkénti illesztésnél erre értelemszerűen nincs szükség. Ridge és LASSO regresszió A lineáris regresszióhoz hasonlóan tanítottam mindkettő modellt, szintén Scikit-es implementációt használva. Ugyanúgy végeztem összes terméket magába foglaló futtatást, valamint termékenkénti modelleket is. Mind Ridge, mind LASSO regresszió esetén az alpha paraméter ideális értékét kerestem a [0.1, 100] intervallumban. Döntési fák Döntési fáknak szintén létezik Scikit-es megvalósítása, ezért én is ezt alkalmaztam. Az előbb említett regressziókkal szemben sok hiperparamétere van, ezért optimalizáló 56
62 eljárást is használtam. Ez az optimalizálás szintén a Hyperopt programcsomag segítségével történt. A bemenet hasonlóan a fenti modellekhez, ugyanazokat az attribútumokat tartalmazta, ugyanolyan formában. Megjegyzem, hogy a döntési fák érzéketlenek az attribútumok értékeiben mutatkozó nagyságrendi különbségekre, de a standardizált jellemzők sem okoznak problémát neki. Az optimalizáció során a lehetséges paramértérnek a következőt határoztam meg: max_features: [1, 40] intervallum min_samples_split: [2, 100] intervallum max_depth: [1, 1000] intervallum max_leaf_nodes: [1, ] intervallum min_samples_leaf: [1, 100] intervallum min_impurity_split: [ , 0.1] intervallum Random Forest Ennél a modellnél megint csak az ismertetett adatokat használtam. Itt is elmondható, hogy sok állítható paramétere van, ezért ismételten a Hyperopt-hoz fordultam. Ennek köszönhetően itt sem az alapértelmezett hiperparamétereket használom, hanem a futás során megtalált legideálisabbakat. Itt hasonló paraméter lehetőségeket definiáltam, mint a döntési fa esetén. XGBoost Az XGBoost kivételesen nem Scikit-beli implementáció, de van Scikit-es illesztés is hozzá. Tapasztalataim és a kapcsolódó fórumok szerint azonban az eredeti Github-os XGBoost megvalósítás gyorsabb futást eredményez, mint a Scikit csomagban implementált, ezért én is ennél a változatnál maradtam. Hyperopt-nak ennél a modellnél a következő paraméterteret adtam át: max_depth: [1, 100] intervallum min_child_weight: [0, 1000] intervallum gamma: [1, 1000] intervallum eta: [0.1, 1] intervallum colsample_bytree: [0.1, 1] intervallum subsample: [0.1, 1] intervallum 57
63 4.3. Szentiment modell A szövegelemzésen alapuló modellt szintén neurális hálóval valósítottam meg. Fontos eltérés az előző feladathoz képest, hogy itt nem regressziót, hanem osztályozást végeztem. Az osztályozás kimenete eltért a klasszikus érzelem meghatározástól, ugyanis én a rendelési mennyiségek alakulását szerettem volna meghatározni az algoritmus segítségével. Ehhez hozzá tenném, hogy akár a szövegekben tükröződő hangulatra, akár a szövegben rejlő keresletre irányuló hatásra vagyok kíváncsi, hasonlóan kell és kellett megalkotnom a modellt. Ez azért van, mert a háló sekélyebb rétegeiben hasonló absztrakt tudás halmozódik fel mindkét esetben, és a mélyebb, illetve kimeneti rétegekben jelenik meg az az intelligencia, amivel a modellnek rendelkeznie kell a különböző problémához tartozó kimenet előállításához. Ennél fogva az elvárt kimenet ennél a modellnél a logaritmikus megtérülési rátából származtatott mutató, a MOVEMENT attribútum volt. Felelevenítve, ez a változó a következő lépéshez tartozó trend irányt tartalmazza. Egyszerűbben: a kereslet a mai napihoz képest nő, csökken vagy stagnál. Mindezt figyelembe véve a probléma egy többosztályos osztályozási feladatnak felelt meg, ahol 0 (stagnál), 1 (nő) és 2 (csökken) címkék jelölték az egyes rendelésbeli irányváltásokat, vagyis, hogy az aktuális rendelési mennyiség, hogyan viszonyul egy előző időpontbeli rendelés értékéhez. A címkék fenti megfeleltetése csupán egyéni választás volt, de más reprezentáció ugyanúgy működőképes lett volna. A szentiment modell architekturális megközelítésből 4 modulból áll: Tweetek letöltése Tweetek előkészítése Szómátrix illesztése Modell futtatása A 4.6. ábrán látható a négy modul kapcsolata és a kommunikáció, valamint az adatok mozgásának iránya. A kommunikációs diagram definíciójának megfelelően az egyes entitások és a köztük lévő viszonyrendszer szerepel a képen, mégpedig az üzenetek szempontjából sorrendhelyesen, azaz nagyobb sorszám időben későbbi interakciót jelent. 58
64 4.6. ábra: Szentiment elemzés kommunikációs diagramja A tweet letöltő program szerepe a neuronháló tanítására szolgáló szöveg korpusz létrehozása. Ehhez a Twitter oldal releváns bejegyzéseit gyűjtöttem össze. Két megközelítést alkalmaztam. Egyrészről kulcsszó alapú szűrést végeztem a Twitter portálon található bejegyzésekre, másrészről volt 3 felhasználói fiók (4.2. táblázat), ami az ABC vállalathoz fűződik, így befolyással bírhat pozíciója és népszerűsége miatt egyéb Twitter felhasználókra. (Ezeket a titoktartási kötelezettségem miatt nem nevezem meg.) Felhasználói Fiók 4.2. táblázat: Igénybe vett Twitter felhasználói fiókok főbb jellemzői Bejegyzések száma Követések száma Követők száma A B C Kedvelések száma A kulcsszó alapú keresésnél a kifejezés konkrétan az ABC vállalat neve volt. Azaz olyan tweeteket kerestem, amikben szerepelt az ABC szó. Ez egy választás volt a részemről, miszerint termék neve helyett, a vállalat nevére szűrök. Azért döntöttem így,
65 mert a termék azonosítók nem beszédes elnevezésűek, de talán még csak nem is publikusak, így nem is tartozik hozzájuk online tartalom. Ezzel szemben maga a cég neve biztosan kapcsolatba hozható bármelyik termékével. Így arra számítottam, hogy a cég általános reputációja befolyásolja a rendelések alakulását. Ez később tovább bontható, és a termékcsaládok nevét felhasználva esetleg egyéb releváns találatok is kinyerhetők, mivel a termékcsaládok nevei a fogyasztók körében is ismertek és használatosak. Gyakorlati szempontból a fiókok oldaláról való letöltéshez a twitterscraper, a kulcsszó alapú szelekcióhoz a GetOldTweets könyvtárat használtam. A 4.6. kommunikációs diagramon ez a részlet az 1-es sorszámmal kezdődő üzenetek és az érintett szereplők formájában bontakozik ki, ahol a tweetek letöltésének kezdeményezése két irányban folytatódik a fent említettekhez híven, és így hozom létre a korpusz adatokat. A következő érintett modulban a tweeteket előkészítettem. Ehhez először meghatároztam minden napra a 100 legrelevánsabb bejegyzést, az átlagos 384 darabból. Ezt úgy csináltam, hogy rangsoroltam a posztokat a népszerűségük (kedvelések és megosztások száma) alapján. Ezt követően reguláris kifejezések segítségével megtisztítottam a szöveget a zajtól, valamint bizonyos elemeket címkékkel helyettesítettem. Ehhez egy, a hivatalos GloVe oldalról származó, ajánlott Ruby szkript Python-os megvalósítását használtam. A cserék olyan elemeket érintettek, mint a hangulatjelek, webcímek, felhasználónevek, címkék (úgynevezett hashtag-ek), számok. Ezek helyett rendre a <smile> (pl. mosolygós hangulatjel), <url>, <user>, <hashtag> [címke szövege], <number> jelölőket használtam. Eredményül a következőkhöz hasonló szövegek születtek: <user>: sadly that product isn t on the market now. it's important for us to hear of your continued interest & how much it helped you. <user> <user> we often have giveaways on our channel so stay tuned for the next one! <user> our thoughts exactly! how do you plan to make the most of the shortest month of the year? Látható, hogy számtalan kevésbé hasznos bejegyzés is előfordult a relevánsak mellett. Következő lépésként a GloVe-os Twitter adatokon tanított szómátrixot kellett használnom. Ehhez a 25 dimenziós változatot választottam. Ez azt jelenti, hogy minden szót egy 25-dimenziós vektor reprezentál. A meglévő tweetek szavai közül a 60
66 leggyakoribb et használtam, majd a szavakat címkékre cseréltem. Ezután még két dolgot kellett elvégezni. Egyenlő hosszúságúra kiegyenlíteni a bejegyzéseket, amit én 20 szóra szabtam meg, valamint a GloVe mátrixból is kiválasztani azt a szót, amiket meghagytam a bejegyzésekben. Majd a szó szóvektor megfeleltetés alapján létrehozni a címke szóvektor reprezentációt. Minderről egy összefoglaló ábra tekinthető meg a 4.7. illusztráción. Felül egy lehetséges tweet látható magyar nyelven, valamint ennek GloVe-beli reprezentációja. A kép alsó felén pedig azt lehet megfigyelni, hogy miként alakul a tweetek bemenete az egyes CNN típusoknak megfelelően ábra: GloVe mátrix felépítése egy példa bemenettel (felül), valamint a CNN modellek bemenetének dimenziói (alul) Utolsóként, de nem utolsó sorban következhetett a modell elkészítése és tanítása. Ehhez 1D és 2D konvolúciós hálózatokat is létrehoztam, és bemenetként az előkészített tweeteket és terméktípusokat adtam meg. A terméktípusnál a regressziós feladat tanítása során kialakított terméktípus vektort használtam a már kifejtett előnyei miatt. Az elvárt kimenet a 3 állapotú trend alakulás volt, és így végeztem el az osztályozást. A bemeneti rétegeket követő beágyazási rétegek a tweetek szó címkéit a 3. lépésben előállított beágyazási mátrix alapján 25-dimenziós szóvektorokra cserélik. A 4.6. ábrán is látható ez a jelenség, miszerint a szentiment modell betölti mind a szöveges tweet állományt, mind 61
67 a szómátrixot, és ezután történik a modell tanítása a kiértékeléssel lezárva. Szentiment modellnél az optimalizációhoz a következő lehetőségeket biztosítottam: Optimalizáló: [ rmsprop, adam, adadelta, nadam ] lista Szűrők száma - 1. rétegben: [16, 32, 64] lista Szűrő mérete - 1. rétegben: [5,10,20] lista Neuronok száma (előrecsatolt rétegekben): [32, 64, 128] lista Aktivációs függvény (minden rétegben): [ relu, sigmoid, tanh ] lista Dropout (előrecsatolt rétegekben): [0.1, 0.5] intervallum További információkat az architektúráról szintén a Függelék 3: Neurális hálózat architektúrák fejezetben lehet megtalálni. 62
68 4.4. Aggregált modell Aggregált modelles megközelítés során a regressziós és szentiment modellt fogom össze egy együttes modellbe, és így végzek további tanításokat szintén neurális hálózattal. Ezek a rétegek egyszerű előrecsatolt rétegek, és regressziós feladatot látnak el. Azaz a regressziós neurális hálózathoz hasonlóan a célja a logaritmikus megtérülési ráta előrejelzése adott bemenetek mellett. A bemeneteket egyrészről a regressziós neurális hálózat bemenetei, valamint a tweet bejegyzések alkotják. Technikai részről az eredeti modellek utolsó rétegeit kell elhagyni, és ezeket a belső réteg kimeneteket belevezetni az aggregált modell bemeneti rétegeire. Ezenkívül mivel ez is egy neurális hálózat, a modell tanítása és a kiértékelés módja megegyezik az eddig ismertetett módszerekkel. Az együttes tanítás során a Hyperopt-ot ezekkel a lehetséges paraméter értékekkel futtattam: Optimalizáló: [ rmsprop, adam, adadelta, nadam ] lista Neuronok száma (előrecsatolt rétegekben): [32, 64, 128] lista Aktivációs függvény (előrecsatolt rétegekben): [ relu, sigmoid, tanh ] lista Dropout (előrecsatolt rétegekben): [0.1, 0.5] intervallum A függelékben erről a hálózatról is további leírást adok a Függelék 3: Neurális hálózat architektúrák pontban. 63
69 5. Eredmények kiértékelése Minden hasonló feladatnál fontos kérdés, hogy mi alapján törtétjent a kiértékelés. Ez nálam is nagy hangsúlyt kapott, és több hibafüggvényt is figyelembe vettem. Az általam használt hat mutatót szeretném bemutatni: Átlagos abszolút eltérés (MAE: Mean Absolute Error), ami regressziós problémákhoz használható (5.1. képlet). MAE = 1 n n Y i Y i i=1, ahol n a halmaz elemszáma, Y a becsült érték, Y az eredeti megfigyelés, n az elemszám. (5.1.) Átlagos négyezetes eltérés (MSE: Mean Squared Error), ami szintén regressziós esetekben alkalmazható (5.2. képlet). MSE = 1 n n (Y i Y i ) 2 i=1, ahol n a halmaz elemszáma, Y a becsült érték, Y az eredeti megfigyelés, n az elemszám. (5.2.) Négyzetes hiba várható értékének a gyöke (RMSE: Root Mean Square Error), ami az MSE-hez hasonló hibafüggvény (5.3. képlet). RMSE = 1 n n (Y i Y i ) 2 i=1 (5.3.), ahol n a halmaz elemszáma, Y a becsült érték, Y az eredeti megfigyelés, n az elemszám. Százalékos átlagos abszolút hiba (MAPE: Mean Absolute Percentage Error), amit ugyancsak folytonos változók mérésére használnak (5.4. képlet). MAPE = 100 n Y i Y i n i=1 Y i, ahol n a halmaz elemszáma, Y a becsült érték, Y az eredeti megfigyelés. Arányosított átlagos abszolút hiba (MASE: Mean Absolute Scaled Error) [64], aminek olyan előnyös tulajdonságai vannak, mint: szimmetrikusan értékel, érzéketlen a skálázásra, valamint kezeli a 0-és értékeket (5.5. képlet). (5.4.) 64
70 MASE = T T e t t=1 T t=2 T 1 Y t Y t 1, ahol n a halmaz elemszáma, Y a megfigyeléseket, e az elvárt és kapott érték különbsége (hiba), T az elemszám. (5.5.) Kategorikus kereszt entrópia (Categorical Cross Entropy), ami többosztályos osztályozási feladat kiértékelésében segíthet (5.6. képlet). N M j=1 CCE = 1 N y ijln (p ij ) i=1, ahol N a halmaz elemszáma, M az osztályok száma, y ij értéke 0 vagy 1, attól függően, hogy ez volt-e a helyes címke, p ij pedig az adott címkére adott valószínűségi érték. (5.6.) Regressziós esetekben, ahogy kifejtettem a logaritmikus megtérülési ráta volt a célváltozó. Ebből az értékből visszakaphatom a rendelt mennyiség (REQUESTED_QUANTITY) nagyságát. Ehhez a logaritmikus megtérülési ráta kiszámolásához szükséges lépésekből kiindulva, el kell végezni a szükséges kalkulációt. Ennek menete az alábbi (5.7. képlet): qty i+x = qty i e RETURN i (5.7.), ahol qty i, qty i+x rendre az aktuális rendelési, illetve x időponttal eltolt rendelési mennyiség, RETURN i pedig a (természetes alapú) logaritmikus megtérülési ráta az i. megfigyelésre nézve. Ehhez vegyük észre, hogy a logaritmikus megtérülés képletét alakítottam át (logaritmikus megtérülés = log e ( qty i+x qty i )). 65
71 5.1. Hiperparaméter optimalizálás eredményei Ebben a fejezetben röviden, felsorolás jelleggel adok számot arról, hogyan alakult a hiperparaméter optimalizáció az egyes modelleket illetően, azaz a hiperparaméterek milyen végső értéket vettek fel a lehetőségek közül. Az optimalizálást a Hyperas és a Hyperopt programcsomagokkal végeztem. Ezek működési elvéről a 3.1. Felhasznált folyamatok fejezetben írtam. Összefoglalva, az optimalizációs eljárás feladata, hogy az előre definiált paramétertérben megtalálja a legkedvezőbb paraméter kombinációt, és mindezt minél kevesebb iterációs lépéssel legyen képes megtenni. Neurális hálózatok hiperparaméterei Előrecsatolt neurális hálózat esetén az 5.1. táblázatban látható eredmények voltak a legmeghatározóbb végső hiperparaméterek. LSTM hálózat esetén ezek az 5.2. táblázat szerint alakultak. Az 5.3. táblázat tartalmazza CNN modell ideálisnak vélt hiperparaméter értékeit. Szentiment modellt illetően az 5.4. táblázatot érdemes megfigyelni. Végül az aggregált modellhez tartozó eredményeket az 5.5. táblázatban lehet nyomon követni táblázat: Előrecsatolt neurális háló végső paraméterei Hiperparaméter név Hiperparaméter érték Batch size 1024 Patience 10 Epoch szám 100 Optimalizáló Adam Első réteg Neuronok száma 512 Aktivációs függvény ReLU Dropout 0.1 Második réteg Neuronok száma 512 Aktivációs függvény ReLU Dropout
72 5.2. táblázat: LSTM háló végső paraméterei Hiperparaméter név Hiperparaméter érték Batch size 1024 Patience 10 Epoch szám 100 Optimalizáló Adam Első réteg LSTM egységek száma 256 Dropout 0.1 Második réteg LSTM egységek száma 64 Dropout 0.1 Harmadik réteg LSTM egységek száma 128 Dropout táblázat: Konvolúciós neurális háló végső paraméterei Hiperparaméter név Hiperparaméter érték Batch size 1024 Patience 10 Epoch szám 100 Optimalizáló Adam Első réteg Szűrők száma 8 Szűrő mérete 2 Eltolás nagysága 1 Súly inicalizálás glorot_uniform Aktivációs függvény ReLU Második réteg Szűrők száma 64 Szűrő mérete 2 Eltolás nagysága 1 Súly inicalizálás glorot_uniform Aktivációs függvény ReLU Harmadik réteg Szűrők száma 64 Szűrő mérete 1 Eltolás nagysága 1 Súly inicalizálás glorot_uniform Aktivációs függvény ReLU 67
73 5.4. táblázat: Szentiment modell végső hiperparaméterei Hiperparaméter név Hiperparaméter érték Batch size 86 Patience 4 Epoch szám 20 Optimalizáló Adam Első réteg (konvolúciós) 2D konvolúciós szűrők száma 32 Szűrő mérete 1x20 Második réteg (maxpooling) Keret mérete 2x2 Harmadik réteg (előrecsatolt) Neuronok száma 64 Dropout 0.4 Aktivációs függvény ReLU Negyedik réteg (előrecsatolt) Neuronok száma 32 Aktivációs függvény ReLU Ötödik réteg (előrecsatolt) Neuronok száma 64 Dropout 0.3 Aktivációs függvény ReLU 5.5. táblázat: Aggregált modell végső hiperparaméterei Hiperparaméter név Hiperparaméter érték Batch size 128 Patience 3 Epoch szám 10 Optimalizáló Adam Első réteg (előrecsatolt) Neuronok száma 256 Dropout 0.3 Aktivációs függvény ReLU Második réteg (előrecsatolt) Neuronok száma 512 Dropout 0.5 Aktivációs függvény ReLU 68
74 Ridge és LASSO regresszió hiperparaméterei Ridge és LASSO esetén rendre az 5.6. és 5.7. táblázat tartalmazza a releváns adatokat táblázat: Ridge regresszió modell végső paraméterei Ridge regresszió Ridge regresszió Paraméter név (egyben) (termékenként) alpha táblázat: LASSO regresszió modell végső paraméterei LASSO regresszió LASSO regresszió Paraméter név (egyben) (termékenként) alpha Döntési fa és random forest hiperparaméterei A végső paramétereket döntési fa és random forest esetén rendre az 5.8. és az 5.9. táblázat tartalmazza táblázat: Döntési fa modell végső paraméterei Paraméter név Döntési fa Döntési fa (egyben) (termékenként) max_depth min_impurity_split min_samples_split max_features 10 default min_samples_leaf max_leaf_nodes default 5.9. táblázat: Random forest modell végső paraméterei Paraméter név Random Forest Random Forest (egyben) (termékenként) n_estimators max_depth min_impurity_split min_samples_split max_features 5 default min_samples_leaf max_leaf_nodes default 69
75 XGBoost hiperparaméterei XGBoost végső hiperparaméterei az alábbi táblázatban tekinthetők meg (5.10. táblázat) táblázat: XGBOOST modell végső paraméterei Paraméter név XGBoost XGBoost (egyben) (termékenként) num_round eta max_depth colsample_bytree subsample 0.45 default min_child_weight gamma
76 5.2. Regressziós modell eredmények Az utófeldolgozáshoz hozzátartozott az is, hogy a visszakapott rendelési mennyiségeket bizonyos intervallumra korlátoztam. Ez azt jelenti, hogy a tanító adathalmaz maximum és minimum rendelési mennyisége volt az a tartomány, ahova beszorítottam a kapott előrejelzési értékeket. Ezzel elértem, hogy ne szerepeljen a kapott értékek között olyan, ami kívül esik a reális értékkészletből. Ez kód szinten az alábbiak szerint történt (5.1. kód). #Terméktípusonkénti küszöbölés def threshold(group): max_value = GROUP_MAXES[group.name] return group[['qty_predicted']].clip(0,max_value) df_qty_grouped[['qty_predicted']] = df_qty_grouped.groupby('item_id')[['qty_predicted']].apply(threshold) 5.1. kód: Előrejelzési eredmények küszöbölése Végül talán a legérdekesebb rész az, hogy hogy is alakultak az egyes modellek eredményei. Ezt tartalmazza az alábbi 5.11-es összehasonlító táblázat, kiegészítve a nagyságrendi futási időkkel. 71
77 Modell illesztés módja táblázat: Modellek eredményei a különböző hibafüggvények szerint Terméktípusonként Összes terméktípusra együtt 7 napos előrejelzés hibája modellenként futási idővel együtt Modell neve MAE RMSE MAPE MASE Futási idő (perc) ARIMA Eltolás modell Lineáris regresszió LASSO regresszió Ridge regresszió Döntési fa Random forest XGBoost Lineáris regresszió LASSO regresszió Ridge regresszió Döntési fa Random forest XGBoost Előrecsatolt neurális háló LSTM háló Konvolúciós háló Aggregált modell

78 Az eredmények ismeretében azt tapasztaltam, hogy a neurális hálók eredményesebben viselkedtek az ABC adathalmazra, mint a kipróbált egyéb modellek, figyelembe véve a négy kiértékelési metrikát. Az is észrevehető, ahogy említettem, hogy a különböző neurális hálózat típusok között ilyen téren kicsi volt a különbség. Vizualizálás és az előrejelzés bemutatása végett a legeredményesebb 5 modell predikcióját is bemutatom. Az összes modellt a hibák alapján sorba rendeztem, és így került ki az 5 legígéretesebb. Ezek a modellek név szerint: előrecsatolt neurális hálózat, konvolúciós hálózat, LSTM hálózat, aggregált modell, Ridge regresszió (egyben tanítva). Az alábbi 5.1-es ábrán látható egy képen az 5 predikcióból egy részlet ábra: 5 legígéretesebb modell előrejelzéséből vett minta a 0-ás rendelési mennyiségek elhagyása után Különböző görbék jelölik az egyes modellek előrejelzéseit, míg az oszlopok az eredeti, elvárt mennyiségeket szimbolizálják. Esztétikai okoból elhagytam azokat a pontokat, ahol az eredeti mennyiség 0 értéket vett fel, hogy kevésbé legyen zavaró az ábra. A láthatóság kedvéért pedig 50 lépést választottam találomra. Az ábrán többek között olyan jelenségek figyelhetők meg, minthogy a különböző modellek más-más pontossággal jelzik előre a rendelés alakulását. Például az FC modell egész szépen becsüli a 35. környéki magasabb rendelési igényt, a többi modellhez képest. Ezenkívül fontosnak találtam külön-külön is megjeleníteni az eredményeket. Itt csupán az előrecsatolt hálózat 73

79 előrejelzéseit teszem közzé (5.2. ábra), de a függelékben (Függelék 4: Előrejelzés vizualizálása modellenként) a legeredményesebbnek számító 5 modell becslését is feltüntetem ábra: A legígéretesebb modell előrejelzésének bemutatása a hiba értékekkel együtt Az eddigi hiba értékek terméktípustól függetlenül egységesen értendőek. Szintén érdekesnek találtam azonban megvizsgálni, hogy terméktípusonként melyik modell, hogy viselkedett. Ebből kiindulva terméktípusonként értékeltem, hogy melyik modell volt a legeredményesebb adott hiba metrika szerint és, hogy hány terméktípusnál produkálta adott modell a legkisebb hibát eredményező predikciót. Ezt kördiagrammokkal az 5.3-as képen szemléltetem. Ezen a képen egy kördiagramm látható, ami a MAE hibafüggvényhez tartozik. A diagramm a legjobbnak ítélt öt modell eredményét mutatja. Egész pontosan azt, hogy adott modell hány terméktípusnál jelzett előre a legpontosabban MAE hibafüggvényt használva. A másik három (RMSE, MAPE, MASE) metrika szerinti hasonló kiértékelés a Függelék 5: Terméktípusonkénti modell kiértékelés-ben szerepel. 74

80 5.3. ábra: 5 legígéretesebb modell eredményessége terméktípusonként. Adott modell ennyi db terméktípusnál becsült a legkisebb hibával MAE szerint. A neurális hálózatok közül a három modell a kiértékelésnél hasonló eredményeket adott, illetve az FC hálózatot találtam a legeredményesebbnek az alkalmazott hibafüggvények alapján. Következő lépésként a Rossmann-os adathalmazhoz elkészítettem egy LSTM és egy 1D konvolúciós hálózatot, a hivatkozott cikkben [52] szereplő FC típus mellé. Erre a problémára is a három architektúra hasonlóan szerepelt, illetve az FC predikciói bizonyultak a legpontosabbaknak. A modellek egy, a MAPE-hoz nagyon hasonló (a szerzők által javasolt) metrikával lettek kiértékelve, és a következő szerint alakultak: FC LSTM D konvolúciós hálózat A tisztán látáshoz hozzá kell tennem, hogy az újabb modellek (LSTM, 1D konvolúciós hálózat) finomhangolása manuálisan történt pár paraméter variációt felhasználva. Az aggregált modellhez én is az FC architektúrát választottam az eredmények fényében, miszerint az ABC és a Rossmann adathalmazon is ez a típus teljesített a legeredményesebben. Mivel az előrecsatolt hálózatot találtam a legeredményesebbnek az egységes kiértékelésnél, ezért szerettem volna statisztikailag is igazolni a szignifikáns különbséget 75
![a többi modellhez viszonyítva. Ehhez a Friedman próbát [65] használtam.](/docs-images/91/106620041/images/81-0.jpg "A Friedman teszt a nem parametrikus alternatívája az ismételt méréses egyszempontos ANOVA-nak, mikor a kellő feltételek nem teljesülnek. Esetemben a normális eloszlás megléte nem garantált.")
81 a többi modellhez viszonyítva. Ehhez a Friedman próbát [65] használtam. A Friedman teszt a nem parametrikus alternatívája az ismételt méréses egyszempontos ANOVA-nak, mikor a kellő feltételek nem teljesülnek. Esetemben a normális eloszlás megléte nem garantált. K összetartozó csoport összehasonlítására használják ordinális, vagy akár folytonos függő változó esetén. A nullhipotézis szerint a minták azonos populációba tartoznak. A teszt futása alatt soronként rangsorolja a megfigyeléseket, majd az így kapott mátrix oszlopain végez átlag számítást. Végezetül az így kapott értékek szórásnégyzetét vizsgálja, és így kapjuk meg a p-értéket. A teszt futtatása után, amennyiben a nullhipotézist elvetettük, érdekes lehet post hoc analízist végezni, hogy megállapítsuk melyik csoportok tértek el egymástól, amit Conover is javasol [66]. Ehhez használható páronként példul a Wilcoxon-féle előjeles rang próba [67]. Először Az FC hálózat előrejelzését összehasonlítottam a többi 17 modell predikciójával. Ehhez minden modellnél az eredeti elvárt rendelési mennyiség és a becsült rendelési mennyiség különbségét vettem. Majd ezen az adatsoron elvégeztem a Friedman próbát. Eredményül azt kaptam, hogy el kell vetni a nullhipotézist, mivel szignifikáns különbség van a változók eloszlása között (Asymp. Sig. < 0.005). Ezt szemlélteti az SPSS log fájljából kimentett ábra is (5.4. ábra) ábra: Friedman próba eredménye 76
82 Ezzel még nem voltam kész, mivel ez csak azt jelentette, hogy vannak olyan modellek, amik eredményei szignifikánsan eltérnek egymástól. Ahhoz, hogy fény derüljön a modellek páronkénti viszonyára, post hoc tesztet futtattam az FC modellre, mégpedig a Wilcoxon-féle előjeles rang próbát. Ez 17 vizsgálatot jelentett. A teszt eredménye szerint egyedül az ARIMA modell volt az, amelyik a szignifikancia szint közelében volt. A szignifikancia szint ebben az esetben a Bonferroni korrekció miatt és a vizsgált nullhipotézisek számának hányadosa, ami (0.005/17). Az ARIMA modellnél kapott eredmény pedig volt, azaz a nullhipotézis nem volt elvethető a Wilcoxon próba alapján. Ez figyelhető meg az 5.5. ábrán ábra: Wilcoxon próba eredménye FC-ARIMA előrejelzésre 77
83 Épp ezért lefuttattam egyéb teszteket is, név szerint az előjel tesztet és a marginális homogenitás tesztet. Ezek már egyöntetűen igazolták a szignifikáns különbséget a két modell előrejelzései között (5.6. ábra) ábra: 2 post hoc teszt eredménye FC-ARIMA előrejelzésre 78
84 5.3. Szentiment modell eredmények A szentiment modellnél, ahogy említettem, szintén neurális hálózatot használtam. A feladatból adódóan azonban itt egy osztályozási problémát kellett megoldani. Emiatt a neurális hálózat tanításánál kategorikus keresztentrópiát használtam. Kiértékelésnél emellett a pontosság (accuracy) volt a segítségemre. Ennek számolása az alábbiak szerint történik (5.2. kód). K.mean(K.equal(K.argmax(y_true, axis=-1), K.argmax(y_pred, axis=-1))) 5.2. kód: Pontosság számítás Keras-ban Ez a képlet alkalmas több osztályos osztályozás eredményének kiértékeléséhez is. A számítás előkövetelménye, hogy a célattribútum 1-az-N kódolással legyen átalakítva. A formula így azt vizsgálja, hogy hány helyen találta el átlagosan a modell a megfelelő osztályt. A szentiment modellen mért legjobb eredmény as pontosság volt. A predikcióhoz tartozó igazság mátrix (confusion matrix) pedig a következő: Az igazság mátrix szabad szemmel is jól láthatóan mutatja meg a találatok és a hibák nagyságrendi arányát. A főátlóban található a jól osztályozott megfigyelések száma osztályonként. További mutatók is pedig könnyen számolhatók belőle, mint a már említett pontosság, továbbá precizitás (precision), szenzitivitás (recall) stb. 79
85 5.4. Aggregált modell eredmények Futtatásához a neurális hálózatok közül legjobbnak ítélt előrecsatolt hálózatot (FC), valamint a szentiment elemzéshez használt 2D konvolúciós hálózatot használtam. Ezeket egy többrétegű előrecsatolt hálózatban fogtam össze és tanítottam tovább. Az elért eredményeket az 5.1. táblázatban mutattam be. Az összehasonlítások után arra a következtetésre jutottam, hogy nehéz eldönteni, hogy a meglévő FC hálózat teljesítményét javítja-e a Twitter bejegyzések jelenléte. A mérőszámokból az látható, hogy 3-ban (MAE, RMSE, MASE) kismértékű romlás jelentkezett, míg a negyedikben (MAPE) a legkisebb hibát produkálta az aggregált modell mind a 18 modell között. Ennek következtében az a benyomásom, hogy érdemes tovább kutatni ebben az irányban, és több forrásból származó, nagyobb mennyiségű és speciálisabb szűrőfeltételeknek megfelelő szöveges tartalmat kell összegyűjteni, és ezen részletesebb előfeldolgozást végezni. A fentebb bemutatott eredmények alapján dolgozatom elsődleges eredményének azt tartom, hogy vizsgálataim alapján topológiától függetlenül a neurális hálózatok eredményesebben szerepeltek négy hibafüggvény szerint a másik 15 algoritmusnál, amik között megtalálhatók klasszikus és gépi tanuló eljárások is. A szentiment elemzés hatásos alkalmazása érdekében azonban további erőfeszítéseket kell tenni, hogy az aggregált modell együttes tanítása során hasznos információt tudjon szolgáltatni a rendszernek. 80
86 6. Jövőbeli tervek Jövőbeli tervek között szerepel az eddig megalkotott modellek további finomítása, további hiperparaméter optimalizálási iterációk során. A neurális hálózatokat illetően szeretnék speciálisabb, és még több architektúrát megalkotni. Érdekes lenne kipróbálni ezeket a módszereket más forrásból származó adathalmazokon is. További elemzéseket is végeznék az idősorok tulajdonságaival kapcsolatosan. A szentiment elemzéshez szükség lenne az összefoglalóban ismertetettekhez híven még további szöveges tartalmat gyűjteni más kulcsszavak használatával, ami például a termékcsalád lehet, mivel ez terméktípusnál általánosabb, de a vállalat nevénél specifikusabb. Így nem csak a cég általános reputációja, hanem konkrét termékvonalak megítélése is szerepet kaphatna az előrejelzés kimenetelében. További kutatási lehetőséget rejt magában a különböző modell típusok használata az együttes tanítás terén. További felfedezéseket lehet tenni a terméktípushoz tartozó idősorok fajtáján alapuló megkülönböztetésben. A különböző modellek különböző eredményt adhatnak az egyes terméktípushoz tartozó idősor jellemzőinek függvényében, így például érdemes lehet más-más modellt tanítani a sporadikus, szezonális, vagy valamilyen egyéb egyedi jellemzővel rendelkező típusok esetében. 81
87 7. Összefoglalás Dolgozatomban bemutattam a termék kereslettervezés fogalmát és folyamatát. Elemeztem a kereslet előrejelzéshez használatos klasszikus és újabb módszereket, ebből jópárat saját magam is megvalósítottam. Megismerkedtem a gépi tanuláson belül a mély tanulás egyik irányával a neurális hálózatokkal. Ezekből több architektúrát is kipróbáltam és használtam. Tanulmányoztam hasonló témában született korábbi dolgozatokat és implementációkat is. Konkrét, valós historikus adatokra alapozva számos modellt alkottam, majd ezeket több módszerrel és megközelítéssel is kiértékeltem, összehasonlítottam. Bizonyos feltevéseket más forrásból származó publikus adathalmazon is igazoltam. Kísérletet tettem a létrehozott neurális hálózatok pontosságát közösségi platformról származó bejegyzésekben rejlő hangulatiság alapján javítani. Ehhez szövegelemzési módszereket használtam, és aggregált módon tanítottam a neurális hálózatokat. Eredményként arról tudok beszámolni, hogy a neurális hálózatoknak van létjogosultsága a nagyvállalatok működésének kereslettervezési területén. Az általam készített modellek közül a neurális hálózatok becsültek a legkisebb hibával több hibafüggvény mérése alapján is. Az egyéb modellekről megfigyeléseim alapján elmondható, hogy kismértékben számít, hogy termékenként, vagy egységesen történik a modell illesztése. A szentiment elemzést illetően arra a következtetésre jutottam, hogy ilyen általános korpusszal nehéz javítani a rendelési adatokon alapuló modell teljesítményén. Javaslatom ebben az irányban, hogy specifikusabb szöveg forrásokat kell használni és egyéb online tartalmakat is be kell venni az elemzésbe. 82
88 Köszönetnyílvánítás A dolgozat nem készülhetett volna el egyetemi konzulensem, Dr. Gyires-Tóth Bálint Pál folyamatos iránymutatása nélkül, neki ezúton is köszönöm a heti szintű konzultációs lehetőségeket, valamint a témának és nekem szentelt időt. Köszönet illeti Dr. Ketskeméty László tanár urat is, aki lektorálta a statisztikai próbákkal kapcsolatosan elvégzett munkámat. Szintén hálás vagyok Bíró Zoltán Miklósnak az SAP részéről, hogy szakmai tanácsokkal látott el. Továbbá köszönettel tartozom családom felé, hogy bíztattak és segítettek, hogy a kutatásra koncentrálhassak. 83
89 Irodalomjegyzék [1] B. Szikora, Integrált Vállalatirányítási Rendszerek tárgy sillabusz, Budapesti Műszaki és Gazdaságtudományi Egyetem, Budapest, pp. 1 95, [2] A. C. D. Franco Maloberti, A Short History of Circuits and Systems, River Publisher, pp , [3] M. Altrichter, G. Horváth, B. Pataki, és G. Strausz, Neurális hálózatok, Panem, Budapest, pp. 1 19, , [4] W. S. Mcculloch and W. Pitts, A logical calculus of the ideas immanent in nervous activity, Bulletin of Mathematical Biophysics, vol. 5, pp , [5] B. Widrow and M. E. Hoff, Adaptive Switching Circuits, Neurocomputing: foundations of research, pp [6] M. Minsky and S. A. Papert, "Perceptrons," MIT Press, [7] G. E. Hinton, S. Osindero, and Y.-W. Teh, A fast learning algorithm for deep belief nets, Neural Computation, pp , [8] S. Haykin, Neural networks: a comprehensive foundation," Pearson Education pp , [9] A. C. Ian Goodfellow, Yoshua Bengio, "Deep Learning," The MIT Press, pp , [10] Y. Bengio, Learning Deep Architectures for AI, Machine Learning, vol. 2, no. 1, pp , [11] Y. LeCun, L. Bottou, G. Orr, and K.-R. Müller, Efficient BackProp, Springer Berlin Heidelberg, pp. 9-48, [12] J. J. Andrej Karpathy, Fei-Fei Li, Stanford University, Convolutional Neural Networks for Visual Recognition, [Megtekintés dátuma: ]. Elérhetőség: [13] V. Nair and G. E. Hinton, Rectified Linear Units Improve Restricted Boltzmann Machines, International Conference on Machine Learning, pp , [14] D. P. Kingma and J. L. Ba, ADAM: A Method for Stochastic Optimization, arxiv preprint, [15] M. D. Zeiler, ADADELTA: An Adaptive Learning Rate Method, arxiv preprint,
90 [16] J. Duchi, J. B. Edu, E. Hazan, and Y. Singer, Adaptive Subgradient Methods for Online Learning and Stochastic Optimization, Journal of Machine Learning Resarch, vol. 12, pp , [17] T. Tieleman and G. Hinton, Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude, COURSERA Neural Networks Machine Learning, vol. 4, no. 2, [18] L. Bottou and O. Bousquet, The Tradeoffs of Large Scale Learning, Advances in Neural Information Processing Systems, pp , [19] B. Pang and L. Lee, Opinion mining and sentiment analysis, Foundations and Trends Information Retrieval, vol. 2, no. 1--2, pp. 1 8, [20] J. Bollen, H. Mao, and X.-J. Zeng, Twitter mood predicts the stock market, Journal of Computational Science, pp. 1-8, 2010 [21] E. Kouloumpis, T. Wilson, and J. D. Moore, Twitter sentiment analysis: The good the bad and the omg!, International AAAI Conference on Weblogs and Social Media, vol. 11, pp , [22] J. Bollen, H. Mao, and A. Pepe, Modeling Public Mood and Emotion: Twitter Sentiment and Socio-Economic Phenomena, International AAAI Conference on Weblogs and Social Media, pp , 2009 [23] Y. Kim, Convolutional Neural Networks for Sentence Classification, Conference on Empirical Methods in Natural Language Processing, pp , 2014 [24] T. Wilson, P. Hoffmann, S. Somasundaran, J. Kessler, J. Wiebe, Y. Choi, C. Cardie, E. Riloff, S. Patwardhan, OpinionFinder: A system for subjectivity analysis, Proceedings of HLT/EMNLP on Interactive Demonstrations, pp , [25] A. Go, R. Bhayani, and L. Huang, Twitter Sentiment Classification using Distant Supervision, Processing, pp. 1-6, 2011 [26] J. Pennington, R. Socher, and C. D. Manning, GloVe: Global Vectors for Word Representation, Conference on Empirical Methods in Natural Language Processing, pp , 2014 [27] T. Mikolov, K. Chen, G. Corrado, and J. Dean, Efficient Estimation of Word Representations in Vector Space, arxiv preprint, 2013 [28] G. P. Zhang, Time series forecasting using a hybrid ARIMA and neural network model, Neurocomputing, vol. 50, pp ,
91 [29] D. University, Models, Introduction to ARIMA: nonseasonal, [Megtekintés dátuma: ]. Elérhetőség: [30] F. M. Thiesing and O. Vornberger, Sales Forecasting Using Neural Networks, InternationalConference on Neural Networks, vol. 4, pp , [31] R. Nigro, Differences between Demand Forecasting and Sales Forecasting for Inventory Replenishment, [Megtekintés dátuma: ]. Elérhetőség: [32] P. Kumar, M. Herbert, and S. Rao, Demand forecasting Using Artificial Neural Network Based on Different Learning Methods: Comparative Analysis, International Journal for Research in Applied Science and Engineering Technology, vol. 2, pp , [33] G. P. Zhang and M. Qi, Neural network forecasting for seasonal and trend time series, European Journal of Operational Research, vol. 160, no. 2, pp , [34] I. Khandelwal, R. Adhikari, and G. Verma, Time Series Forecasting using Hybrid ARIMA and ANN Models based on DWT Decomposition, Procedia Computer Science, vol. 48, no. 48, pp , [35] C. A. Mitrea, C. K. M. Lee, and Z. Wu, A Comparison between Neural Networks and Traditional Forecasting Methods: A Case Study, International Journal of Engineering Business Management, vol. 1, no. 2, pp , [36] A. Dhini, I. Surjandari, M. Riefqi, and M. A. Puspasari, Forecasting Analysis of Consumer Goods Demand Using Neural Networks and ARIMA, International Journal of Technology, vol. 5, pp , [37] T. Taskaya-Temizel and K. Ahmad, Are ARIMA neural network hybrids better than single models?, Proceedings of the International Joint Conference on Neural Networks, vol. 5, pp , [38] D. K. and P. E. P. S. B. Kotsiantis, Data Preprocessing for Supervised Leaning, International Journal of Computer Science, pp , 2006 [39] J. Bergstra JAMESBERGSTRA and U. Yoshua Bengio YOSHUABENGIO, Random Search for Hyper-Parameter Optimization, Journal of Machine Learning Research, vol. 13, pp , [40] M. Pelikan, D. E. Goldberg, and E. Cantú-Paz, BOA: The Bayesian Optimization 86
92 Algorithm, Annual Genetic and Evolutionary Computation Conference, pp , [41] V. W. Lee, C. Kim, J. Chhugani, M. Deisher, D. Kim, A. D. Nguyen, N. Satish, M. Smelyanskiy, S. Chennupaty, P. Hammarlund, R. Singhal, P. Dubey, Debunking the 100X GPU vs. CPU Myth: An Evaluation of Throughput Computing on CPU and GPU, Annual International Symposium on Computer Architecture, pp , [42] J. Bergstra, O. Breuleux, F. Bastien, P. Lamblin, R. Pascanu, G. Desjardins, J. Turian, D. Warde-Farley, Y. Bengio, Theano: A CPU and GPU Math Compiler in Python, 9th Python in Science Conference, pp. 1-7, [43] M. Abadi,A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mané, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Viégas, O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu, X. Zheng, TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems, arxiv preprint, [44] J. Bergstra, D. Yamins, and D. D. Cox, Hyperopt: A Python Library for Optimizing the Hyperparameters of Machine Learning Algorithms, Python in Science Conference, pp , [45] P. P. Jones E, Oliphant E, SciPy: Open Source Scientific Tools for Python, [46] W. Mckinney, pandas: a Foundational Python Library for Data Analysis and Statistics, [47] The HDF Group, Hierarchical Data Format, version 5, [48] G. H. Yann LeCun, Yoshua Bengio, Deep learning, Nature, pp , [49] S. Hochreiter and J. Urgen Schmidhuber, Long Short-Term Memory, Neural Computation, vol. 9, no. 8, pp , [50] Y. Bengio and Y. Lecun, Convolutional Networks for Images, Speech, and Timeseries, The handbook of brain theory and neural networks, MIT Press, pp , [51] N. Kalchbrenner, E. Grefenstette, and P. Blunsom, A Convolutional Neural Network for Modelling Sentences, Association for Computational Linguistics, pp ,
93 [52] C. Guo and F. Berkhahn, Entity Embeddings of Categorical Variables, Kaggle competition, [53] P. Whitle, "Hypothesis testing in time series analysis," Almqvist & Wiksells, [54] F. Galton, Regression towards mediocrity in hereditary stature., The Journal of the Anthropological Institute of Great Britain and Ireland, vol. 15, pp , [55] A. E. Hoerl and R. W. Kennard, Ridge regression: Biased estimation for nonorthogonal problems, Technometrics, vol. 12, no. 1, pp , [56] R. Tibshirani, Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society Series B (Methodological), pp , [57] J. R. Quinlan, Induction of decision trees, Machine Learning, vol. 1, no. 1, pp , [58] L. Breiman, Random forests, Machine Learning, vol. 45, no. 1, pp. 5 32, [59] T. Chen and C. Guestrin, XGBoost: A Scalable Tree Boosting System, Computing Research Repository, 2016 [60] J. H. Friedman, Greedy function approximation: a gradient boosting machine, Annals of Statistics, pp , [61] L. Van Der Maaten and G. Hinton, Visualizing Data using t-sne, Journal of Machine Learning Research, vol. 9, pp , [62] G. Hinton and S. Roweis, Stochastic Neighbor Embedding, Neural Information Processing Systems, vol. 15, pp , 2002 [63] H. Akaike, Information theory and an extension of the maximum likelihood principle, International Symposium on Information Theory, Akadémia Kiadó, 1998, pp [64] R. J. Hyndman and A. B. Koehler, Another look at measures of forecast accuracy, International Journal of Forecasting, vol. 22, no. 4, pp , [65] M. Friedman, The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance, Source Journal of the American Statistical Association, vol. 32, no. 200, pp , [66] W. J. Conover and W. J. Conover, Practical nonparametric statistics, [67] F. Wilcoxon, Individual comparisons by ranking methods, Biometrics Bulletin, vol. 1, no. 6, pp ,
94 Függelék 1: Jellemzők fontossága A Ridge és LASSO regresszió, valamint random forest szerinti jellemzők fontosságát mutatom be itt. Ezek a modellek az összes terméktípust magukba foglalóan futottak. Kizárólag a 10 legfontosabb attribútumot tüntettem fel, lentről felfele csökkenő prioritás szerint. Ridge regresszió LASSO regresszió Random forest 1 ROLLING_MEAN-1 ( ) MONTH ( ) IS_WEEKEND ( ) 2 MONTH ( ) ROLLING_MEAN-1 ( ) NEXT_HOLIDAY ( ) 3 NEXT_HOLIDAY ( ) ZERO_FULL_RATIO ( ) PREV_HOLIDAY ( ) 4 ZERO_FULL_RATIO ( ) NEXT_HOLIDAY ( ) MONTH ( ) 5 MEAN_OF_ZERO_SEQ ( ) MEAN_OF_ZERO_SEQ ( ) ROLLING_MEAN-1 ( ) 6 ROLLING_MEAN-7 ( ) ROLLING_MEAN-7 ( ) MEAN_OF_ZERO_SEQ ( ) 7 DAY_OF_WEEK ( ) DAY_OF_WEEK ( ) ROLLING_MEAN-13 ( ) 8 ROLLING_MEAN-5 ( ) ROLLING_MEAN-5 ( ) MAX_ZERO_SEQUENCE ( ) 9 MAX_ZERO_SEQUENCE ( ) MAX_ZERO_SEQUENCE ( ) ZEROS_CUMSUM ( ) 10 ROLLING_MEAN-2 ( ) ROLLING_MEAN-2 ( ) ROLLING_MEAN-2 ( ) 89
95 Függelék 2: Hiperparaméter optimalizáció Ez egy egyszerű példa arról, hogyan lehet egy hiperparaméter optimalizálás eredményét vizualizálni. A függőleges tengely a modell pontosságát (accuracy) mutatja, a vízszintes tengely pedig az attribútum választást. Ilyen formában észrevehetünk bizonyos kapcsolatokat paraméter értékek és a pontosság alakulásának viszonyáról. 90
96 Függelék 3: Neurális hálózat architektúrák Itt szeretném bemutatni a végső neurális hálózati architektúrák felépítését. Ezeket a modell leírásokat a program futása során generáltam. Előrecsatolt neurális hálózat modell architektúrája a regressziós feladatra: Layer (type) Output Shape Param # Connected to ======================================================================================== embedding_1 (Embedding) (None, 1, 27) reshape_1 (Reshape) (None, 27) 0 embedding_2 (Embedding) (None, 1, 2) 6 reshape_2 (Reshape) (None, 2) 0 embedding_3 (Embedding) (None, 1, 3) 36 reshape_3 (Reshape) (None, 3) 0 embedding_4 (Embedding) (None, 1, 13) 403 reshape_4 (Reshape) (None, 13) 0 embedding_5 (Embedding) (None, 1, 3) 21 reshape_5 (Reshape) (None, 3) 0 embedding_6 (Embedding) (None, 1, 1) 2 reshape_6 (Reshape) (None, 1) 0 dense_1 (Dense) (None, 1) 24 dense_2 (Dense) (None, 512) merge_1[0][0] dropout_1 (Dropout) (None, 512) 0 dense_2[0][0] dense_3 (Dense) (None, 512) dropout_1[0][0] dropout_2 (Dropout) (None, 512) 0 dense_3[0][0] dense_4 (Dense) (None, 1) 513 dropout_2[0][0] ======================================================================================== Total params:
97 LSTM hálózat modell architektúrája a regressziós feladatra: Layer (type) Output Shape Param # Connected to ======================================================================================== lstm_1 (LSTM) (None, 10L, 256) lstm_input_1[0][0] dropout_1 (Dropout) (None, 10L, 256) 0 lstm_1[0][0] lstm_2 (LSTM) (None, 10L, 64) dropout_1[0][0] dropout_2 (Dropout) (None, 10L, 64) 0 lstm_2[0][0] lstm_3 (LSTM) (None, 128) dropout_2[0][0] dropout_3 (Dropout) (None, 128) 0 lstm_3[0][0] dense_2 (Dense) (None, 1) 129 dropout_3[0][0] ======================================================================================== Total params: D konvolúciós hálózat modell architektúrája a regressziós feladatra: Layer (type) Output Shape Param # Connected to ======================================================================================== convolution1d_1 (Convolution1D) (None, 9L, 8) 1160 convolution1d_input_1[0][0] convolution1d_2 (Convolution1D) (None, 8L, 64) 1088 convolution1d_1[0][0] convolution1d_3 (Convolution1D) (None, 8L, 64) 4160 convolution1d_2[0][0] flatten_1 (Flatten) (None, 512) 0 convolution1d_3[0][0] dense_1 (Dense) (None, 1) 513 flatten_1[0][0] ======================================================================================== Total params:
98 Szentiment elemzésre készített hálózat architektúrája: Layer (type) Output Shape Param # Connected to ======================================================================================== embedding_1 (Embedding) (None, 1, 27) reshape_1 (Reshape) (None, 27) 0 embedding_2 (Embedding) (None, 1, 2) 6 reshape_2 (Reshape) (None, 2) 0 embedding_3 (Embedding) (None, 1, 3) 36 reshape_3 (Reshape) (None, 3) 0 embedding_4 (Embedding) (None, 1, 13) 403 reshape_4 (Reshape) (None, 13) 0 embedding_5 (Embedding) (None, 1, 3) 21 reshape_5 (Reshape) (None, 3) 0 embedding_6 (Embedding) (None, 1, 1) 2 reshape_6 (Reshape) (None, 1) 0 dense_1 (Dense) (None, 1) 24 dense_2 (Dense) (None, 128) 6528 dense_3 (Dense) (None, 1) 129 embedding_7 (Embedding) (None, 20, 25) embedding_8 (Embedding) (None, 20, 25) embedding_9 (Embedding) (None, 20, 25) (FOLYTATÁS...) embedding_105 (Embedding) (None, 20, 25) embedding_106 (Embedding) (None, 20, 25) reshape_7 (Reshape) (None, 100, 20, 25) 0 convolution2d_1 (Convolution2D) (None, 256, 20, 6) maxpooling2d_1 (MaxPooling2D) (None, 256, 10, 3) 0 93
99 flatten_1 (Flatten) (None, 7680) 0 dense_4 (Dense) (None, 256) dropout_1 (Dropout) (None, 256) 0 dense_5 (Dense) (None, 128) dense_6 (Dense) (None, 256) merge_3[0][0] dropout_2 (Dropout) (None, 256) 0 dense_6[0][0] dense_7 (Dense) (None, 512) dropout_2[0][0] dropout_3 (Dropout) (None, 512) 0 dense_7[0][0] dense_8 (Dense) (None, 1) 513 dropout_3[0][0] ======================================================================================== Total params:
100 Aggregált hálózat architektúrája: Layer (type) Output Shape Param # Connected to ======================================================================================== embedding_1 (Embedding) (None, 1, 27) reshape_1 (Reshape) (None, 27) 0 embedding_2 (Embedding) (None, 1, 2) 6 reshape_2 (Reshape) (None, 2) 0 embedding_3 (Embedding) (None, 1, 3) 36 reshape_3 (Reshape) (None, 3) 0 embedding_4 (Embedding) (None, 1, 13) 403 reshape_4 (Reshape) (None, 13) 0 embedding_5 (Embedding) (None, 1, 3) 21 reshape_5 (Reshape) (None, 3) 0 embedding_6 (Embedding) (None, 1, 1) 2 reshape_6 (Reshape) (None, 1) 0 dense_1 (Dense) (None, 1) 24 dense_2 (Dense) (None, 128) 6528 dense_3 (Dense) (None, 1) 129 embedding_7 (Embedding) (None, 20, 25) embedding_8 (Embedding) (None, 20, 25) embedding_9 (Embedding) (None, 20, 25) (FOLYTATÁS...) embedding_105 (Embedding) (None, 20, 25) embedding_106 (Embedding) (None, 20, 25) reshape_7 (Reshape) (None, 100, 20, 25) 0 convolution2d_1 (Convolution2D) (None, 256, 20, 6) maxpooling2d_1 (MaxPooling2D) (None, 256, 10, 3) 0 95
101 flatten_1 (Flatten) (None, 7680) 0 dense_4 (Dense) (None, 256) dropout_1 (Dropout) (None, 256) 0 dense_5 (Dense) (None, 128) dense_6 (Dense) (None, 256) merge_3[0][0] dropout_2 (Dropout) (None, 256) 0 dense_6[0][0] dense_7 (Dense) (None, 512) dropout_2[0][0] dropout_3 (Dropout) (None, 512) 0 dense_7[0][0] dense_8 (Dense) (None, 1) 513 dropout_3[0][0] ======================================================================================== Total params:
102 Függelék 4: Előrejelzés vizualizálása modellenként Itt mutatok be az egyes modellek előrejelzési képességéből egy-egy részletet. Soknak találtam az összes modellt bemutató 18 képet mellékelni, ezért a legígéretesebb 5 modell becsléseiből mutatok be részleteket. Ez az 5 modell név szerint: FC, 1D CNN, LSTM, Aggregált modell, Ridge regresszió (együtt tanítva az összes terméktípust). 97
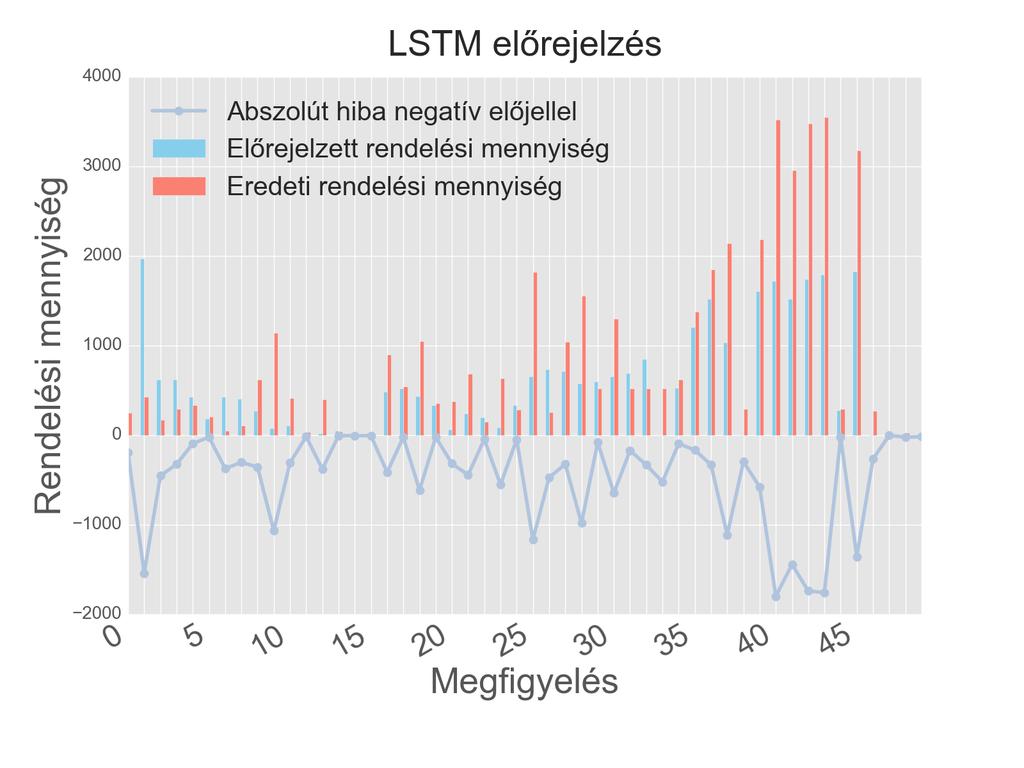
103 98
104 99

105 Függelék 5: Terméktípusonkénti modell kiértékelés Alább látható a kiértékelés szekcióban már bemutatott kördiagram három másik változata, a különböző hibafüggvények szerint, sorban: RMSE, MAPE, MASE. 100
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék. Neurális hálók. Pataki Béla
 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók Előadó: Előadás anyaga: Hullám Gábor Pataki Béla Dobrowiecki Tadeusz BME I.E. 414, 463-26-79
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók Előadó: Előadás anyaga: Hullám Gábor Pataki Béla Dobrowiecki Tadeusz BME I.E. 414, 463-26-79
Deep Learning a gyakorlatban Python és LUA alapon Tanítás: alap tippek és trükkök
 Gyires-Tóth Bálint Deep Learning a gyakorlatban Python és LUA alapon Tanítás: alap tippek és trükkök http://smartlab.tmit.bme.hu Deep Learning Híradó Hírek az elmúlt 168 órából Deep Learning Híradó Google
Gyires-Tóth Bálint Deep Learning a gyakorlatban Python és LUA alapon Tanítás: alap tippek és trükkök http://smartlab.tmit.bme.hu Deep Learning Híradó Hírek az elmúlt 168 órából Deep Learning Híradó Google
Regresszió. Csorba János. Nagyméretű adathalmazok kezelése március 31.
 Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017.
 Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Gépi tanulás a gyakorlatban. Lineáris regresszió
 Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Intelligens Rendszerek Gyakorlata. Neurális hálózatok I.
 : Intelligens Rendszerek Gyakorlata Neurális hálózatok I. dr. Kutor László http://mobil.nik.bmf.hu/tantargyak/ir2.html IRG 3/1 Trend osztályozás Pnndemo.exe IRG 3/2 Hangulat azonosítás Happy.exe IRG 3/3
: Intelligens Rendszerek Gyakorlata Neurális hálózatok I. dr. Kutor László http://mobil.nik.bmf.hu/tantargyak/ir2.html IRG 3/1 Trend osztályozás Pnndemo.exe IRG 3/2 Hangulat azonosítás Happy.exe IRG 3/3
Keresés képi jellemzők alapján. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Tanulás az idegrendszerben. Structure Dynamics Implementation Algorithm Computation - Function
 Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Számítógépes képelemzés 7. előadás. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
I. LABOR -Mesterséges neuron
 I. LABOR -Mesterséges neuron A GYAKORLAT CÉLJA: A mesterséges neuron struktúrájának az ismertetése, neuronhálókkal kapcsolatos elemek, alapfogalmak bemutatása, aktivációs függvénytípusok szemléltetése,
I. LABOR -Mesterséges neuron A GYAKORLAT CÉLJA: A mesterséges neuron struktúrájának az ismertetése, neuronhálókkal kapcsolatos elemek, alapfogalmak bemutatása, aktivációs függvénytípusok szemléltetése,
FELÜGYELT ÉS MEGERŐSÍTÉSES TANULÓ RENDSZEREK FEJLESZTÉSE
 FELÜGYELT ÉS MEGERŐSÍTÉSES TANULÓ RENDSZEREK FEJLESZTÉSE Dr. Aradi Szilárd, Fehér Árpád Mesterséges intelligencia kialakulása 1956 Dartmouth-i konferencián egy maroknyi tudós megalapította a MI területét
FELÜGYELT ÉS MEGERŐSÍTÉSES TANULÓ RENDSZEREK FEJLESZTÉSE Dr. Aradi Szilárd, Fehér Árpád Mesterséges intelligencia kialakulása 1956 Dartmouth-i konferencián egy maroknyi tudós megalapította a MI területét
Gépi tanulás a gyakorlatban. Bevezetés
 Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
Neurális hálózatok elméleti alapjai TULICS MIKLÓS GÁBRIEL
 Neurális hálózatok elméleti alapjai TULICS MIKLÓS GÁBRIEL TULICS@TMIT.BME.HU Példa X (tanult órák száma, aludt órák száma) y (dolgozaton elért pontszám) (5, 8) 80 (3, 5) 78 (5, 1) 82 (10, 2) 93 (4, 4)
Neurális hálózatok elméleti alapjai TULICS MIKLÓS GÁBRIEL TULICS@TMIT.BME.HU Példa X (tanult órák száma, aludt órák száma) y (dolgozaton elért pontszám) (5, 8) 80 (3, 5) 78 (5, 1) 82 (10, 2) 93 (4, 4)
Vezetői információs rendszerek
 Vezetői információs rendszerek Kiadott anyag: Vállalat és információk Elekes Edit, 2015. E-mail: elekes.edit@eng.unideb.hu Anyagok: eng.unideb.hu/userdir/vezetoi_inf_rd 1 A vállalat, mint információs rendszer
Vezetői információs rendszerek Kiadott anyag: Vállalat és információk Elekes Edit, 2015. E-mail: elekes.edit@eng.unideb.hu Anyagok: eng.unideb.hu/userdir/vezetoi_inf_rd 1 A vállalat, mint információs rendszer
A kibontakozó új hajtóerő a mesterséges intelligencia
 5. Magyar Jövő Internet Konferencia» Okos város a célkeresztben «A kibontakozó új hajtóerő a mesterséges intelligencia Dr. Szűcs Gábor Budapesti Műszaki és Gazdaságtudományi Egyetem Távközlési és Médiainformatikai
5. Magyar Jövő Internet Konferencia» Okos város a célkeresztben «A kibontakozó új hajtóerő a mesterséges intelligencia Dr. Szűcs Gábor Budapesti Műszaki és Gazdaságtudományi Egyetem Távközlési és Médiainformatikai
Visszacsatolt (mély) neurális hálózatok
 neurális hálózatok") Visszacsatolt (mély) neurális hálózatok Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Sima előrecsatolt neurális hálózat Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Pl.: kép feliratozás,
Visszacsatolt (mély) neurális hálózatok Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Sima előrecsatolt neurális hálózat Visszacsatolt hálózatok kimenet rejtett rétegek bemenet Pl.: kép feliratozás,
Teljesen elosztott adatbányászat pletyka algoritmusokkal. Jelasity Márk Ormándi Róbert, Hegedűs István
 Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Neurális hálózatok bemutató
 Neurális hálózatok bemutató Füvesi Viktor Miskolci Egyetem Alkalmazott Földtudományi Kutatóintézet Miért? Vannak feladatok amelyeket az agy gyorsabban hajt végre mint a konvencionális számítógépek. Pl.:
Neurális hálózatok bemutató Füvesi Viktor Miskolci Egyetem Alkalmazott Földtudományi Kutatóintézet Miért? Vannak feladatok amelyeket az agy gyorsabban hajt végre mint a konvencionális számítógépek. Pl.:
Fuzzy rendszerek és neurális hálózatok alkalmazása a diagnosztikában
 Budapesti Műszaki és Gazdaságtudományi Egyetem Fuzzy rendszerek és neurális hálózatok alkalmazása a diagnosztikában Cselkó Richárd 2009. október. 15. Az előadás fő témái Soft Computing technikák alakalmazásának
Budapesti Műszaki és Gazdaságtudományi Egyetem Fuzzy rendszerek és neurális hálózatok alkalmazása a diagnosztikában Cselkó Richárd 2009. október. 15. Az előadás fő témái Soft Computing technikák alakalmazásának
Hibadetektáló rendszer légtechnikai berendezések számára
 Hibadetektáló rendszer légtechnikai berendezések számára Tudományos Diákköri Konferencia A feladatunk Légtechnikai berendezések Monitorozás Hibadetektálás Újrataníthatóság A megvalósítás Mozgásérzékelő
Hibadetektáló rendszer légtechnikai berendezések számára Tudományos Diákköri Konferencia A feladatunk Légtechnikai berendezések Monitorozás Hibadetektálás Újrataníthatóság A megvalósítás Mozgásérzékelő
TARTALOMJEGYZÉK. TARTALOMJEGYZÉK...vii ELŐSZÓ... xiii BEVEZETÉS A lágy számításról A könyv célkitűzése és felépítése...
 TARTALOMJEGYZÉK TARTALOMJEGYZÉK...vii ELŐSZÓ... xiii BEVEZETÉS...1 1. A lágy számításról...2 2. A könyv célkitűzése és felépítése...6 AZ ÖSSZETEVŐ LÁGY RENDSZEREK...9 I. BEVEZETÉS...10 3. Az összetevő
TARTALOMJEGYZÉK TARTALOMJEGYZÉK...vii ELŐSZÓ... xiii BEVEZETÉS...1 1. A lágy számításról...2 2. A könyv célkitűzése és felépítése...6 AZ ÖSSZETEVŐ LÁGY RENDSZEREK...9 I. BEVEZETÉS...10 3. Az összetevő
Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok
 Zrínyi Miklós Gimnázium Művészet és tudomány napja Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok 10/9/2009 Dr. Viharos Zsolt János Elsősorban volt Zrínyis diák Tudományos főmunkatárs
Zrínyi Miklós Gimnázium Művészet és tudomány napja Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok 10/9/2009 Dr. Viharos Zsolt János Elsősorban volt Zrínyis diák Tudományos főmunkatárs
A CMMI alapú szoftverfejlesztési folyamat
 A CMMI alapú szoftverfejlesztési folyamat Készítette: Szmetankó Gábor G-5S8 Mi a CMMI? Capability Maturity Modell Integration Folyamat fejlesztési referencia modell Bevált gyakorlatok, praktikák halmaza,
A CMMI alapú szoftverfejlesztési folyamat Készítette: Szmetankó Gábor G-5S8 Mi a CMMI? Capability Maturity Modell Integration Folyamat fejlesztési referencia modell Bevált gyakorlatok, praktikák halmaza,
I. BESZÁLLÍTÓI TELJESÍTMÉNYEK ÉRTÉKELÉSE
 I. BESZÁLLÍTÓI TELJESÍTMÉNYEK ÉRTÉKELÉSE Komplex termékek gyártására jellemző, hogy egy-egy termékbe akár több ezer alkatrész is beépül. Ilyenkor az alkatrészek általában sok különböző beszállítótól érkeznek,
I. BESZÁLLÍTÓI TELJESÍTMÉNYEK ÉRTÉKELÉSE Komplex termékek gyártására jellemző, hogy egy-egy termékbe akár több ezer alkatrész is beépül. Ilyenkor az alkatrészek általában sok különböző beszállítótól érkeznek,
A maximum likelihood becslésről
 A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
Deep Learning a gyakorlatban Python és LUA alapon Felhasználói viselkedés modellezés
 Gyires-Tóth Bálint Deep Learning a gyakorlatban Python és LUA alapon Felhasználói viselkedés modellezés http://smartlab.tmit.bme.hu Modellezés célja A telefon szenzoradatai alapján egy általános viselkedési
Gyires-Tóth Bálint Deep Learning a gyakorlatban Python és LUA alapon Felhasználói viselkedés modellezés http://smartlab.tmit.bme.hu Modellezés célja A telefon szenzoradatai alapján egy általános viselkedési
Termelés- és szolgáltatásmenedzsment
 Termelés- és szolgáltatásmenedzsment egyetemi adjunktus Menedzsment és Vállalatgazdaságtan Tanszék Termelés- és szolgáltatásmenedzsment 13. Előrejelzési módszerek 14. Az előrejelzési modellek felépítése
Termelés- és szolgáltatásmenedzsment egyetemi adjunktus Menedzsment és Vállalatgazdaságtan Tanszék Termelés- és szolgáltatásmenedzsment 13. Előrejelzési módszerek 14. Az előrejelzési modellek felépítése
Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására
 VÉGZŐS KONFERENCIA 2009 2009. május 20, Budapest Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására Hidasi Balázs hidasi@tmit.bme.hu Konzulens: Gáspár-Papanek Csaba Budapesti
VÉGZŐS KONFERENCIA 2009 2009. május 20, Budapest Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására Hidasi Balázs hidasi@tmit.bme.hu Konzulens: Gáspár-Papanek Csaba Budapesti
Konvolúciós neurális hálózatok (CNN)
") Konvolúciós neurális hálózatok (CNN) Konvolúció Jelfeldolgozásban: Diszkrét jelek esetén diszkrét konvolúció: Képfeldolgozásban 2D konvolúció (szűrők): Konvolúciós neurális hálózat Konvolúciós réteg Kép,
Konvolúciós neurális hálózatok (CNN) Konvolúció Jelfeldolgozásban: Diszkrét jelek esetén diszkrét konvolúció: Képfeldolgozásban 2D konvolúció (szűrők): Konvolúciós neurális hálózat Konvolúciós réteg Kép,
Intelligens orvosi műszerek VIMIA023
 Intelligens orvosi műszerek VIMIA023 Neurális hálók (Dobrowiecki Tadeusz anyagának átdolgozásával) 2017 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu (463-)2679 A
Intelligens orvosi műszerek VIMIA023 Neurális hálók (Dobrowiecki Tadeusz anyagának átdolgozásával) 2017 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu (463-)2679 A
KONVOLÚCIÓS NEURONHÁLÓK. A tananyag az EFOP pályázat támogatásával készült.
 KONVOLÚCIÓS NEURONHÁLÓK A tananyag az EFOP-3.5.1-16-2017-00004 pályázat támogatásával készült. 1. motiváció A klasszikus neuronháló struktúra a fully connected háló Két réteg között minden neuron kapcsolódik
KONVOLÚCIÓS NEURONHÁLÓK A tananyag az EFOP-3.5.1-16-2017-00004 pályázat támogatásával készült. 1. motiváció A klasszikus neuronháló struktúra a fully connected háló Két réteg között minden neuron kapcsolódik
y ij = µ + α i + e ij
 Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai
Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai
Neurális hálózatok.... a gyakorlatban
 Neurális hálózatok... a gyakorlatban Java NNS Az SNNS Javás változata SNNS: Stuttgart Neural Network Simulator A Tübingeni Egyetemen fejlesztik http://www.ra.cs.unituebingen.de/software/javanns/ 2012/13.
Neurális hálózatok... a gyakorlatban Java NNS Az SNNS Javás változata SNNS: Stuttgart Neural Network Simulator A Tübingeni Egyetemen fejlesztik http://www.ra.cs.unituebingen.de/software/javanns/ 2012/13.
Gépi tanulás a gyakorlatban. Kiértékelés és Klaszterezés
 Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Intelligens Rendszerek Elmélete. Versengéses és önszervező tanulás neurális hálózatokban
 Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Kollektív tanulás milliós hálózatokban. Jelasity Márk
 Kollektív tanulás milliós hálózatokban Jelasity Márk 2 3 Motiváció Okostelefon platform robbanásszerű terjedése és Szenzorok és gazdag kontextus jelenléte, ami Kollaboratív adatbányászati alkalmazások
Kollektív tanulás milliós hálózatokban Jelasity Márk 2 3 Motiváció Okostelefon platform robbanásszerű terjedése és Szenzorok és gazdag kontextus jelenléte, ami Kollaboratív adatbányászati alkalmazások
Függvények növekedési korlátainak jellemzése
 17 Függvények növekedési korlátainak jellemzése A jellemzés jól bevált eszközei az Ω, O, Θ, o és ω jelölések. Mivel az igények általában nemnegatívak, ezért az alábbi meghatározásokban mindenütt feltesszük,
17 Függvények növekedési korlátainak jellemzése A jellemzés jól bevált eszközei az Ω, O, Θ, o és ω jelölések. Mivel az igények általában nemnegatívak, ezért az alábbi meghatározásokban mindenütt feltesszük,
Output menedzsment felmérés. Tartalomjegyzék
 Összefoglaló Output menedzsment felmérés 2009.11.12. Alerant Zrt. Tartalomjegyzék 1. A kutatásról... 3 2. A célcsoport meghatározása... 3 2.1 Célszervezetek... 3 2.2 Célszemélyek... 3 3. Eredmények...
Összefoglaló Output menedzsment felmérés 2009.11.12. Alerant Zrt. Tartalomjegyzék 1. A kutatásról... 3 2. A célcsoport meghatározása... 3 2.1 Célszervezetek... 3 2.2 Célszemélyek... 3 3. Eredmények...
Gyártási termelési folyamat és a Microsoft Dynamics AX 2012 R2 logisztikai szolgáltatások
 Gyártási termelési folyamat és a Microsoft Dynamics AX 2012 R2 logisztikai szolgáltatások Ez a dokumentum gépi fordítással készült, emberi beavatkozás nélkül. A szöveget adott állapotában bocsátjuk rendelkezésre,
Gyártási termelési folyamat és a Microsoft Dynamics AX 2012 R2 logisztikai szolgáltatások Ez a dokumentum gépi fordítással készült, emberi beavatkozás nélkül. A szöveget adott állapotában bocsátjuk rendelkezésre,
Mély neuronhálók alkalmazása és optimalizálása
 magyar nyelv beszédfelismerési feladatokhoz 2015. január 10. Konzulens: Dr. Mihajlik Péter A megvalósítandó feladatok Irodalomkutatás Nyílt kutatási eszközök keresése, beszédfelismer rendszerek tervezése
magyar nyelv beszédfelismerési feladatokhoz 2015. január 10. Konzulens: Dr. Mihajlik Péter A megvalósítandó feladatok Irodalomkutatás Nyílt kutatási eszközök keresése, beszédfelismer rendszerek tervezése
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
Fiáth Attila Nagy Balázs Tóth Péter Dóczi Szilvia Dinya Mariann
 Fiáth Attila Nagy Balázs Tóth Péter Dóczi Szilvia Dinya Mariann Egységes kockázatkezelési módszertan kialakítása a villamosenergia-ipari átviteli rendszerirányító társaságnál A felelős vállalatirányítás
Fiáth Attila Nagy Balázs Tóth Péter Dóczi Szilvia Dinya Mariann Egységes kockázatkezelési módszertan kialakítása a villamosenergia-ipari átviteli rendszerirányító társaságnál A felelős vállalatirányítás
Megerősítéses tanulás
 Megerősítéses tanulás elméleti kognitív neurális Introduction Knowledge representation Probabilistic models Bayesian behaviour Approximate inference I (computer lab) Vision I Approximate inference II:
Megerősítéses tanulás elméleti kognitív neurális Introduction Knowledge representation Probabilistic models Bayesian behaviour Approximate inference I (computer lab) Vision I Approximate inference II:
Nagyméretű adathalmazok kezelése (BMEVISZM144) Reinhardt Gábor április 5.
 Reinhardt Gábor április 5.") Asszociációs szabályok Budapesti Műszaki- és Gazdaságtudományi Egyetem 2012. április 5. Tartalom 1 2 3 4 5 6 7 ismétlés A feladat Gyakran együtt vásárolt termékek meghatározása Tanultunk rá hatékony algoritmusokat
Asszociációs szabályok Budapesti Műszaki- és Gazdaságtudományi Egyetem 2012. április 5. Tartalom 1 2 3 4 5 6 7 ismétlés A feladat Gyakran együtt vásárolt termékek meghatározása Tanultunk rá hatékony algoritmusokat
Lineáris regresszió vizsgálata resampling eljárással
 Lineáris regresszió vizsgálata resampling eljárással Dolgozatomban az European Social Survey (ESS) harmadik hullámának adatait fogom felhasználni, melyben a teljes nemzetközi lekérdezés feldolgozásra került,
Lineáris regresszió vizsgálata resampling eljárással Dolgozatomban az European Social Survey (ESS) harmadik hullámának adatait fogom felhasználni, melyben a teljes nemzetközi lekérdezés feldolgozásra került,
NEURONHÁLÓK ÉS TANÍTÁSUK A BACKPROPAGATION ALGORITMUSSAL. A tananyag az EFOP pályázat támogatásával készült.
 NEURONHÁLÓK ÉS TANÍTÁSUK A BACKPROPAGATION ALGORITMUSSAL A tananyag az EFOP-3.5.1-16-2017-00004 pályázat támogatásával készült. Neuron helyett neuronháló Neuron reprezentációs erejének növelése: építsünk
NEURONHÁLÓK ÉS TANÍTÁSUK A BACKPROPAGATION ALGORITMUSSAL A tananyag az EFOP-3.5.1-16-2017-00004 pályázat támogatásával készült. Neuron helyett neuronháló Neuron reprezentációs erejének növelése: építsünk
Modellezés és szimuláció. Szatmári József SZTE Természeti Földrajzi és Geoinformatikai Tanszék
 Modellezés és szimuláció Szatmári József SZTE Természeti Földrajzi és Geoinformatikai Tanszék Kvantitatív forradalmak a földtudományban - geográfiában 1960- as évek eleje: statisztika 1970- as évek eleje:
Modellezés és szimuláció Szatmári József SZTE Természeti Földrajzi és Geoinformatikai Tanszék Kvantitatív forradalmak a földtudományban - geográfiában 1960- as évek eleje: statisztika 1970- as évek eleje:
Tanulás az idegrendszerben
 Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Funkcióvezérelt modellezés Abból indulunk ki, hogy milyen feladatot valósít meg a rendszer Horace Barlow: "A
Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Funkcióvezérelt modellezés Abból indulunk ki, hogy milyen feladatot valósít meg a rendszer Horace Barlow: "A
Minitab 16 újdonságai május 18
 Minitab 16 újdonságai 2010. május 18 Minitab 16 köszöntése! A Minitab statisztikai szoftver új verziója több mint hetven újdonságot tartalmaz beleértve az erősebb statisztikai képességet, egy új menüt
Minitab 16 újdonságai 2010. május 18 Minitab 16 köszöntése! A Minitab statisztikai szoftver új verziója több mint hetven újdonságot tartalmaz beleértve az erősebb statisztikai képességet, egy új menüt
Hogyan lesz adatbányából aranybánya?
 Hogyan lesz adatbányából aranybánya? Szolgáltatások kapacitástervezése a Budapest Banknál Németh Balázs Budapest Bank Fehér Péter - Corvinno Visontai Balázs - KFKI Tartalom 1. Szolgáltatás életciklus 2.
Hogyan lesz adatbányából aranybánya? Szolgáltatások kapacitástervezése a Budapest Banknál Németh Balázs Budapest Bank Fehér Péter - Corvinno Visontai Balázs - KFKI Tartalom 1. Szolgáltatás életciklus 2.
Termeléstervezés és -irányítás Termelés és kapacitás tervezés Xpress-Mosel FICO Xpress Optimization Suite
 Termeléstervezés és -irányítás Termelés és kapacitás tervezés Xpress-Mosel FICO Xpress Optimization Suite Alkalmazásával 214 Monostori László egyetemi tanár Váncza József egyetemi docens 1 Probléma Igények
Termeléstervezés és -irányítás Termelés és kapacitás tervezés Xpress-Mosel FICO Xpress Optimization Suite Alkalmazásával 214 Monostori László egyetemi tanár Váncza József egyetemi docens 1 Probléma Igények
Stratégiák tanulása az agyban
 Statisztikai tanulás az idegrendszerben, 2019. Stratégiák tanulása az agyban Bányai Mihály banyai.mihaly@wigner.mta.hu http://golab.wigner.mta.hu/people/mihaly-banyai/ Kortárs MI thispersondoesnotexist.com
Statisztikai tanulás az idegrendszerben, 2019. Stratégiák tanulása az agyban Bányai Mihály banyai.mihaly@wigner.mta.hu http://golab.wigner.mta.hu/people/mihaly-banyai/ Kortárs MI thispersondoesnotexist.com
Megerősítéses tanulás 7. előadás
 Megerősítéses tanulás 7. előadás 1 Ismétlés: TD becslés s t -ben stratégia szerint lépek! a t, r t, s t+1 TD becslés: tulajdonképpen ezt mintavételezzük: 2 Akcióértékelő függvény számolása TD-vel még mindig
Megerősítéses tanulás 7. előadás 1 Ismétlés: TD becslés s t -ben stratégia szerint lépek! a t, r t, s t+1 TD becslés: tulajdonképpen ezt mintavételezzük: 2 Akcióértékelő függvény számolása TD-vel még mindig
Kovács Ernő 1, Füvesi Viktor 2
 Kovács Ernő 1, Füvesi Viktor 2 1 Miskolci Egyetem, Elektrotechnikai - Elektronikai Tanszék 2 Miskolci Egyetem, Alkalmazott Földtudományi Kutatóintézet 1 HU-3515 Miskolc-Egyetemváros 2 HU-3515 Miskolc-Egyetemváros,
Kovács Ernő 1, Füvesi Viktor 2 1 Miskolci Egyetem, Elektrotechnikai - Elektronikai Tanszék 2 Miskolci Egyetem, Alkalmazott Földtudományi Kutatóintézet 1 HU-3515 Miskolc-Egyetemváros 2 HU-3515 Miskolc-Egyetemváros,
SZTE Eötvös Loránd Kollégium. 2. Móra György: Információkinyerés természetes nyelvű szövegekből
 2010/2011 tavaszi félév SZTE Eötvös Loránd Kollégium 1. Dombi József: Fuzzy elmélet és alkalmazásai 2011. március 3. 19:00 2. Móra György: Információkinyerés természetes nyelvű szövegekből 2011. március
2010/2011 tavaszi félév SZTE Eötvös Loránd Kollégium 1. Dombi József: Fuzzy elmélet és alkalmazásai 2011. március 3. 19:00 2. Móra György: Információkinyerés természetes nyelvű szövegekből 2011. március
Kontrollcsoport-generálási lehetőségek retrospektív egészségügyi vizsgálatokhoz
 Kontrollcsoport-generálási lehetőségek retrospektív egészségügyi vizsgálatokhoz Szekér Szabolcs 1, Dr. Fogarassyné dr. Vathy Ágnes 2 1 Pannon Egyetem Rendszer- és Számítástudományi Tanszék, szekersz@gmail.com
Kontrollcsoport-generálási lehetőségek retrospektív egészségügyi vizsgálatokhoz Szekér Szabolcs 1, Dr. Fogarassyné dr. Vathy Ágnes 2 1 Pannon Egyetem Rendszer- és Számítástudományi Tanszék, szekersz@gmail.com
2651. 1. Tételsor 1. tétel
 2651. 1. Tételsor 1. tétel Ön egy kft. logisztikai alkalmazottja. Ez a cég új logisztikai ügyviteli fogalmakat kíván bevezetni az operatív és stratégiai működésben. A munkafolyamat célja a hatékony készletgazdálkodás
2651. 1. Tételsor 1. tétel Ön egy kft. logisztikai alkalmazottja. Ez a cég új logisztikai ügyviteli fogalmakat kíván bevezetni az operatív és stratégiai működésben. A munkafolyamat célja a hatékony készletgazdálkodás
y ij = µ + α i + e ij STATISZTIKA Sir Ronald Aylmer Fisher Példa Elmélet A variancia-analízis alkalmazásának feltételei Lineáris modell
 Példa STATISZTIKA Egy gazdálkodó k kukorica hibrid termesztése között választhat. Jelöljük a fajtákat A, B, C, D-vel. Döntsük el, hogy a hibridek termesztése esetén azonos terméseredményre számíthatunk-e.
Példa STATISZTIKA Egy gazdálkodó k kukorica hibrid termesztése között választhat. Jelöljük a fajtákat A, B, C, D-vel. Döntsük el, hogy a hibridek termesztése esetén azonos terméseredményre számíthatunk-e.
társadalomtudományokban
 Gépi tanulás, predikció és okság a társadalomtudományokban Muraközy Balázs (MTA KRTK) Bemutatkozik a Számítógépes Társadalomtudomány témacsoport, MTA, 2017 2/20 Empirikus közgazdasági kérdések Felváltja-e
Gépi tanulás, predikció és okság a társadalomtudományokban Muraközy Balázs (MTA KRTK) Bemutatkozik a Számítógépes Társadalomtudomány témacsoport, MTA, 2017 2/20 Empirikus közgazdasági kérdések Felváltja-e
DOKTORI (PhD) ÉRTEKEZÉS
 ÉRTEKEZÉS") ZRÍNYI MIKLÓS NEMZETVÉDELMI EGYETEM BOLYAI JÁNOS KATONAI MŰSZAKI KAR Katonai Műszaki Doktori Iskola Alapítva: 2002 évben Alapító: Prof. Solymosi József DSc. DOKTORI (PhD) ÉRTEKEZÉS Tibenszkyné Fórika Krisztina
ZRÍNYI MIKLÓS NEMZETVÉDELMI EGYETEM BOLYAI JÁNOS KATONAI MŰSZAKI KAR Katonai Műszaki Doktori Iskola Alapítva: 2002 évben Alapító: Prof. Solymosi József DSc. DOKTORI (PhD) ÉRTEKEZÉS Tibenszkyné Fórika Krisztina
A hálózattervezés alapvető ismeretei
 A hálózattervezés alapvető ismeretei Infokommunikációs hálózatok tervezése és üzemeltetése 2011 2011 Sipos Attila ügyvivő szakértő BME Híradástechnikai Tanszék siposa@hit.bme.hu A terv általános meghatározásai
A hálózattervezés alapvető ismeretei Infokommunikációs hálózatok tervezése és üzemeltetése 2011 2011 Sipos Attila ügyvivő szakértő BME Híradástechnikai Tanszék siposa@hit.bme.hu A terv általános meghatározásai
Kvantitatív módszerek
 Kvantitatív módszerek szimuláció Kovács Zoltán Szervezési és Vezetési Tanszék E-mail: kovacsz@gtk.uni-pannon.hu URL: http://almos/~kovacsz Mennyiségi problémák megoldása analitikus numerikus szimuláció
Kvantitatív módszerek szimuláció Kovács Zoltán Szervezési és Vezetési Tanszék E-mail: kovacsz@gtk.uni-pannon.hu URL: http://almos/~kovacsz Mennyiségi problémák megoldása analitikus numerikus szimuláció
Gépi tanulás és Mintafelismerés
 Gépi tanulás és Mintafelismerés jegyzet Csató Lehel Matematika-Informatika Tanszék BabesBolyai Tudományegyetem, Kolozsvár 2007 Aug. 20 2 1. fejezet Bevezet A mesterséges intelligencia azon módszereit,
Gépi tanulás és Mintafelismerés jegyzet Csató Lehel Matematika-Informatika Tanszék BabesBolyai Tudományegyetem, Kolozsvár 2007 Aug. 20 2 1. fejezet Bevezet A mesterséges intelligencia azon módszereit,
Intelligens Rendszerek Elmélete
 Intelligens Rendszerek Elmélete Dr. Kutor László : Mesterséges neurális hálózatok felügyelt tanítása hiba visszateresztő Back error Propagation algoritmussal Versengéses tanulás http://mobil.nik.bmf.hu/tantargyak/ire.html
Intelligens Rendszerek Elmélete Dr. Kutor László : Mesterséges neurális hálózatok felügyelt tanítása hiba visszateresztő Back error Propagation algoritmussal Versengéses tanulás http://mobil.nik.bmf.hu/tantargyak/ire.html
Matematikai geodéziai számítások 6.
 Matematikai geodéziai számítások 6. Lineáris regresszió számítás elektronikus távmérőkre Dr. Bácsatyai, László Matematikai geodéziai számítások 6.: Lineáris regresszió számítás elektronikus távmérőkre
Matematikai geodéziai számítások 6. Lineáris regresszió számítás elektronikus távmérőkre Dr. Bácsatyai, László Matematikai geodéziai számítások 6.: Lineáris regresszió számítás elektronikus távmérőkre
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
Adatbázis rendszerek 6.. 6. 1.1. Definíciók:
 Adatbázis Rendszerek Budapesti Műszaki és Gazdaságtudományi Egyetem Fotogrammetria és Térinformatika 6.1. Egyed relációs modell lényegi jellemzői 6.2. Egyed relációs ábrázolás 6.3. Az egyedtípus 6.4. A
Adatbázis Rendszerek Budapesti Műszaki és Gazdaságtudományi Egyetem Fotogrammetria és Térinformatika 6.1. Egyed relációs modell lényegi jellemzői 6.2. Egyed relációs ábrázolás 6.3. Az egyedtípus 6.4. A
Tanulás az idegrendszerben. Structure Dynamics Implementation Algorithm Computation - Function
 Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Globális ellátási lánc menedzsment a National Instruments gyakorlatában
 Globális ellátási lánc menedzsment a National Instruments gyakorlatában Kertész Csaba, Horváth Gergő 2015 október 16. Agenda Az NI bemutatása Ellátási lánc, ellátási lánc menedzsment Az NI egységei, kapcsolatai
Globális ellátási lánc menedzsment a National Instruments gyakorlatában Kertész Csaba, Horváth Gergő 2015 október 16. Agenda Az NI bemutatása Ellátási lánc, ellátási lánc menedzsment Az NI egységei, kapcsolatai
Dualitás Dualitási tételek Általános LP feladat Komplementáris lazaság 2017/ Szegedi Tudományegyetem Informatikai Intézet
 Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 7. Előadás Árazási interpretáció Tekintsük újra az erőforrás allokációs problémát (vonat
Operációkutatás I. 2017/2018-2. Szegedi Tudományegyetem Informatikai Intézet Számítógépes Optimalizálás Tanszék 7. Előadás Árazási interpretáció Tekintsük újra az erőforrás allokációs problémát (vonat
V. Félév Információs rendszerek tervezése Komplex információs rendszerek tervezése dr. Illyés László - adjunktus
 V. Félév Információs rendszerek tervezése Komplex információs rendszerek tervezése dr. Illyés László - adjunktus 1 Az előadás tartalma A GI helye az informatikában Az előadás tartalmának magyarázata A
V. Félév Információs rendszerek tervezése Komplex információs rendszerek tervezése dr. Illyés László - adjunktus 1 Az előadás tartalma A GI helye az informatikában Az előadás tartalmának magyarázata A
A PiFast program használata. Nagy Lajos
 A PiFast program használata Nagy Lajos Tartalomjegyzék 1. Bevezetés 3 2. Bináris kimenet létrehozása. 3 2.1. Beépített konstans esete.............................. 3 2.2. Felhasználói konstans esete............................
A PiFast program használata Nagy Lajos Tartalomjegyzék 1. Bevezetés 3 2. Bináris kimenet létrehozása. 3 2.1. Beépített konstans esete.............................. 3 2.2. Felhasználói konstans esete............................
Matematikai alapok és valószínőségszámítás. Középértékek és szóródási mutatók
 Matematikai alapok és valószínőségszámítás Középértékek és szóródási mutatók Középértékek A leíró statisztikák talán leggyakrabban használt csoportját a középértékek jelentik. Legkönnyebben mint az adathalmaz
Matematikai alapok és valószínőségszámítás Középértékek és szóródási mutatók Középértékek A leíró statisztikák talán leggyakrabban használt csoportját a középértékek jelentik. Legkönnyebben mint az adathalmaz
Statisztikai módszerek a skálafüggetlen hálózatok
 Statisztikai módszerek a skálafüggetlen hálózatok vizsgálatára Gyenge Ádám1 1 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Számítástudományi és Információelméleti
Statisztikai módszerek a skálafüggetlen hálózatok vizsgálatára Gyenge Ádám1 1 Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Számítástudományi és Információelméleti
FMEA tréning OKTATÁSI SEGÉDLET
 FMEA tréning OKTATÁSI SEGÉDLET 1. Hibamód és hatás elemzés : FMEA (Failure Mode and Effects Analysis) A fejlett nyugati piacokon csak azok a vállalatok képesek hosszabbtávon megmaradni, melyek gazdaságosan
FMEA tréning OKTATÁSI SEGÉDLET 1. Hibamód és hatás elemzés : FMEA (Failure Mode and Effects Analysis) A fejlett nyugati piacokon csak azok a vállalatok képesek hosszabbtávon megmaradni, melyek gazdaságosan
Ellátási lánc optimalizálás egy új multinál
 Ellátási lánc optimalizálás egy új multinál Provimi Pet Food Europe A PPF Supply Center koncepció Az optimalizálás első lépései A PPF ellátási láncának optimalizálása Az AIMMS project tanulságai Költségcsökkentés
Ellátási lánc optimalizálás egy új multinál Provimi Pet Food Europe A PPF Supply Center koncepció Az optimalizálás első lépései A PPF ellátási láncának optimalizálása Az AIMMS project tanulságai Költségcsökkentés
Teljesen elosztott adatbányászat alprojekt
 Teljesen elosztott adatbányászat alprojekt Hegedűs István, Ormándi Róbert, Jelasity Márk Big Data jelenség Big Data jelenség Exponenciális növekedés a(z): okos eszközök használatában, és a szenzor- és
Teljesen elosztott adatbányászat alprojekt Hegedűs István, Ormándi Róbert, Jelasity Márk Big Data jelenség Big Data jelenség Exponenciális növekedés a(z): okos eszközök használatában, és a szenzor- és
Adaptív dinamikus szegmentálás idősorok indexeléséhez
 Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Állatokon végzett vizsgálatok alternatíváinak használata a REACHrendelet
 Hiv.: ECHA-11-FS-06-HU ISBN-13: 978-92-9217-604-4 Állatokon végzett vizsgálatok alternatíváinak használata a REACHrendelet alapján A REACH-rendelet kidolgozásának és elfogadásának egyik legfontosabb oka
Hiv.: ECHA-11-FS-06-HU ISBN-13: 978-92-9217-604-4 Állatokon végzett vizsgálatok alternatíváinak használata a REACHrendelet alapján A REACH-rendelet kidolgozásának és elfogadásának egyik legfontosabb oka
A távmunka és a távdolgozók jellemzői
 TÁRSADALOM A távmunka és a távdolgozók jellemzői Tárgyszavak: foglalkoztatás; humánerőforrás; információtechnológia; munkahely; távmunka trend. Bevezetés A távmunka képlékeny meghatározása arra enged következtetni,
TÁRSADALOM A távmunka és a távdolgozók jellemzői Tárgyszavak: foglalkoztatás; humánerőforrás; információtechnológia; munkahely; távmunka trend. Bevezetés A távmunka képlékeny meghatározása arra enged következtetni,
Ellátási lánc optimalizálás P-gráf módszertan alkalmazásával mennyiségi és min ségi paraméterek gyelembevételével
 Ellátási lánc optimalizálás P-gráf módszertan alkalmazásával mennyiségi és min ségi paraméterek gyelembevételével Pekárdy Milán, Baumgartner János, Süle Zoltán Pannon Egyetem, Veszprém XXXII. Magyar Operációkutatási
Ellátási lánc optimalizálás P-gráf módszertan alkalmazásával mennyiségi és min ségi paraméterek gyelembevételével Pekárdy Milán, Baumgartner János, Süle Zoltán Pannon Egyetem, Veszprém XXXII. Magyar Operációkutatási
Biomatematika 12. Szent István Egyetem Állatorvos-tudományi Kar. Fodor János
 Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
XVII. econ Konferencia és ANSYS Felhasználói Találkozó
 XVII. econ Konferencia és ANSYS Felhasználói Találkozó Hazay Máté, Bakos Bernadett, Bojtár Imre hazay.mate@epito.bme.hu PhD hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Tartószerkezetek Mechanikája
XVII. econ Konferencia és ANSYS Felhasználói Találkozó Hazay Máté, Bakos Bernadett, Bojtár Imre hazay.mate@epito.bme.hu PhD hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Tartószerkezetek Mechanikája
S atisztika 1. előadás
 Statisztika 1. előadás A kutatás hatlépcsős folyamata 1. lépés: Problémameghatározás 2. lépés: A probléma megközelítésének kidolgozása 3. lépés: A kutatási terv meghatározása 4. lépés: Terepmunka vagy
Statisztika 1. előadás A kutatás hatlépcsős folyamata 1. lépés: Problémameghatározás 2. lépés: A probléma megközelítésének kidolgozása 3. lépés: A kutatási terv meghatározása 4. lépés: Terepmunka vagy
Osztályozás, regresszió. Nagyméretű adathalmazok kezelése Tatai Márton
 Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
Szezonális kiigazítás az NFSZ regisztrált álláskeresők idősorain. Készítette: Multiráció Kft.
 az NFSZ regisztrált álláskeresők idősorain Készítette: Multiráció Kft. SZEZONÁLITÁS Többé kevésbe szabályos hullámzás figyelhető meg a regisztrált álláskeresők adatsoraiban. Oka: az időjárás hatásainak
az NFSZ regisztrált álláskeresők idősorain Készítette: Multiráció Kft. SZEZONÁLITÁS Többé kevésbe szabályos hullámzás figyelhető meg a regisztrált álláskeresők adatsoraiban. Oka: az időjárás hatásainak
MUNKAERŐPIACI IGÉNYEKNEK A FOLYAMATOS ÖSSZEHANGOLÁSA A WEB 2.0 KORSZAKÁBAN
 A FELSŐOKTATÁS TARTALMÁNAK ÉS A MUNKAERŐPIACI IGÉNYEKNEK A FOLYAMATOS ÖSSZEHANGOLÁSA A WEB 2.0 KORSZAKÁBAN Határterületek tanterve Milyen közgazdasági ismeretekre van szüksége egy jogásznak, mérnöknek,
A FELSŐOKTATÁS TARTALMÁNAK ÉS A MUNKAERŐPIACI IGÉNYEKNEK A FOLYAMATOS ÖSSZEHANGOLÁSA A WEB 2.0 KORSZAKÁBAN Határterületek tanterve Milyen közgazdasági ismeretekre van szüksége egy jogásznak, mérnöknek,
Hasraütés és horoszkóp a beszerzéstervezésben. Korszerű tervezési megoldás a kereslet- és a készlettervezés területén
 Hasraütés és horoszkóp a beszerzéstervezésben Korszerű tervezési megoldás a kereslet- és a készlettervezés területén 1 1.Válaszd szét a két folyamatot! 2. Gyűjts adatokat! 3. Alkalmazz tudományos módszertant!
Hasraütés és horoszkóp a beszerzéstervezésben Korszerű tervezési megoldás a kereslet- és a készlettervezés területén 1 1.Válaszd szét a két folyamatot! 2. Gyűjts adatokat! 3. Alkalmazz tudományos módszertant!
Dr. Kalló Noémi. Termelés- és szolgáltatásmenedzsment. egyetemi adjunktus Menedzsment és Vállalatgazdaságtan Tanszék. Dr.
 Termelés- és szolgáltatásmenedzsment egyetemi adjunktus Menedzsment és Vállalatgazdaságtan Tanszék Termelés- és szolgáltatásmenedzsment 13. Ismertesse a legfontosabb előrejelzési módszereket és azok gyakorlati
Termelés- és szolgáltatásmenedzsment egyetemi adjunktus Menedzsment és Vállalatgazdaságtan Tanszék Termelés- és szolgáltatásmenedzsment 13. Ismertesse a legfontosabb előrejelzési módszereket és azok gyakorlati
Közgazdaságtan alapjai. Dr. Karajz Sándor Gazdaságelméleti Intézet
 Közgazdaságtan alapjai Dr. Karajz Sándor Gazdaságelméleti 4. Előadás Az árupiac és az IS görbe IS-LM rendszer A rövidtávú gazdasági ingadozások modellezésére használt legismertebb modell az úgynevezett
Közgazdaságtan alapjai Dr. Karajz Sándor Gazdaságelméleti 4. Előadás Az árupiac és az IS görbe IS-LM rendszer A rövidtávú gazdasági ingadozások modellezésére használt legismertebb modell az úgynevezett
CARE. Biztonságos. otthonok idős embereknek CARE. Biztonságos otthonok idős embereknek 2010-09-02. Dr. Vajda Ferenc Egyetemi docens
 CARE Biztonságos CARE Biztonságos otthonok idős embereknek otthonok idős embereknek 2010-09-02 Dr. Vajda Ferenc Egyetemi docens 3D Érzékelés és Mobilrobotika kutatócsoport Budapesti Műszaki és Gazdaságtudományi
CARE Biztonságos CARE Biztonságos otthonok idős embereknek otthonok idős embereknek 2010-09-02 Dr. Vajda Ferenc Egyetemi docens 3D Érzékelés és Mobilrobotika kutatócsoport Budapesti Műszaki és Gazdaságtudományi
Algoritmusok Tervezése. 6. Előadás Algoritmusok 101 Dr. Bécsi Tamás
 Algoritmusok Tervezése 6. Előadás Algoritmusok 101 Dr. Bécsi Tamás Mi az algoritmus? Lépések sorozata egy feladat elvégzéséhez (legáltalánosabban) Informálisan algoritmusnak nevezünk bármilyen jól definiált
Algoritmusok Tervezése 6. Előadás Algoritmusok 101 Dr. Bécsi Tamás Mi az algoritmus? Lépések sorozata egy feladat elvégzéséhez (legáltalánosabban) Informálisan algoritmusnak nevezünk bármilyen jól definiált
Gépi tanulás a Rapidminer programmal. Stubendek Attila
 Gépi tanulás a Rapidminer programmal Stubendek Attila Rapidminer letöltése Google: download rapidminer Rendszer kiválasztása (iskolai gépeken Other Systems java) Kicsomagolás lib/rapidminer.jar elindítása
Gépi tanulás a Rapidminer programmal Stubendek Attila Rapidminer letöltése Google: download rapidminer Rendszer kiválasztása (iskolai gépeken Other Systems java) Kicsomagolás lib/rapidminer.jar elindítása
MŰSZAKI TUDOMÁNY AZ ÉSZAK-ALFÖLDI RÉGIÓBAN 2010
 MŰSZAKI TUDOMÁNY AZ ÉSZAK-ALFÖLDI RÉGIÓBAN 2010 KONFERENCIA ELŐADÁSAI Nyíregyháza, 2010. május 19. Szerkesztette: Edited by Pokorádi László Kiadja: Debreceni Akadémiai Bizottság Műszaki Szakbizottsága
MŰSZAKI TUDOMÁNY AZ ÉSZAK-ALFÖLDI RÉGIÓBAN 2010 KONFERENCIA ELŐADÁSAI Nyíregyháza, 2010. május 19. Szerkesztette: Edited by Pokorádi László Kiadja: Debreceni Akadémiai Bizottság Műszaki Szakbizottsága
Az éghajlati modellek eredményeinek alkalmazhatósága hatásvizsgálatokban
 Az éghajlati modellek eredményeinek alkalmazhatósága hatásvizsgálatokban Szépszó Gabriella Országos Meteorológiai Szolgálat, szepszo.g@met.hu RCMTéR hatásvizsgálói konzultációs workshop 2015. június 23.
Az éghajlati modellek eredményeinek alkalmazhatósága hatásvizsgálatokban Szépszó Gabriella Országos Meteorológiai Szolgálat, szepszo.g@met.hu RCMTéR hatásvizsgálói konzultációs workshop 2015. június 23.
Modern műszeres analitika szeminárium Néhány egyszerű statisztikai teszt
 Modern műszeres analitika szeminárium Néhány egyszerű statisztikai teszt Galbács Gábor KIUGRÓ ADATOK KISZŰRÉSE STATISZTIKAI TESZTEKKEL Dixon Q-tesztje Gyakori feladat az analitikai kémiában, hogy kiugrónak
Modern műszeres analitika szeminárium Néhány egyszerű statisztikai teszt Galbács Gábor KIUGRÓ ADATOK KISZŰRÉSE STATISZTIKAI TESZTEKKEL Dixon Q-tesztje Gyakori feladat az analitikai kémiában, hogy kiugrónak
Szoftverarchitektúrák 3. előadás (második fele) Fornai Viktor
 Fornai Viktor") Szoftverarchitektúrák 3. előadás (második fele) Fornai Viktor A szotverarchitektúra fogalma A szoftverarchitektúra nagyon fiatal diszciplína. A fogalma még nem teljesen kiforrott. Néhány definíció: A szoftverarchitektúra
Szoftverarchitektúrák 3. előadás (második fele) Fornai Viktor A szotverarchitektúra fogalma A szoftverarchitektúra nagyon fiatal diszciplína. A fogalma még nem teljesen kiforrott. Néhány definíció: A szoftverarchitektúra
A digitális analóg és az analóg digitális átalakító áramkör
 A digitális analóg és az analóg digitális átalakító áramkör I. rész Bevezetésként tisztázzuk a címben szereplő két fogalmat. A számítástechnikai kislexikon a következőképpen fogalmaz: digitális jel: olyan
A digitális analóg és az analóg digitális átalakító áramkör I. rész Bevezetésként tisztázzuk a címben szereplő két fogalmat. A számítástechnikai kislexikon a következőképpen fogalmaz: digitális jel: olyan
Adatmodellezés. 1. Fogalmi modell
 Adatmodellezés MODELL: a bonyolult (és időben változó) valóság leegyszerűsített mása, egy adott vizsgálat céljából. A modellben többnyire a vizsgálat szempontjából releváns jellemzőket (tulajdonságokat)
Adatmodellezés MODELL: a bonyolult (és időben változó) valóság leegyszerűsített mása, egy adott vizsgálat céljából. A modellben többnyire a vizsgálat szempontjából releváns jellemzőket (tulajdonságokat)
Jogi és menedzsment ismeretek
 Jogi és menedzsment ismeretek Értékesítési politika Célja: A marketingcsatorna kiválasztására és alkalmazására vonatkozó elvek és módszerek meghatározása Lépései: a) a lehetséges értékesítési csatornák
Jogi és menedzsment ismeretek Értékesítési politika Célja: A marketingcsatorna kiválasztására és alkalmazására vonatkozó elvek és módszerek meghatározása Lépései: a) a lehetséges értékesítési csatornák