Készítette: Hadházi Dániel
|
|
|
- Balázs Boros
- 6 évvel ezelőtt
- Látták:
Átírás
1 Készítette: Hadházi Dániel
2 Ellenőrzött (osztályozás, predikció): Adott bemeneti mintákhoz elvárt kimenetek. Félig ellenőrzött (valódi problémák): Nincs minden bemeneti mintához ellenőrzött kimenet, de minden mintát felhasználunk. Megerősítéses problémák (szabtech): Döntésszekvenciák kumulált minősítése lehetséges csak, viszont az egyes döntéseket kell tanulni. Nem ellenőrzött (klaszterezés): Nincs egyetlen tanító mintához sem elvárt kimenet.
3 Cél a bemeneti változók, és a célváltozó értéke közötti leképezést megtanulni. Példa: Legyen adott egy osztályozó, ami (egyetemi hallgatót játszva) memorizálja a megadott mintákat. Elvégzi az osztályozó a kitűzött célt? NEM
4 Tanítópontok helyesen osztályozása nem releváns bonyolult osztályozóknál. Mi az, ami számít: Mennyire sikerült jól megtanulni a problémát. Mennyire képes általánosítani. Hogyan mérjük mindkettőt: Lehetőleg minél több, az osztályozó / regresszor kialakításánál fel nem használt, valódi eloszlást reprezentáló minták osztályozási arányával.
5 Alapprobléma: csak véges minta áll rendelkezésre, melyből még tanulni is kell. Gyakran tanuló eljárások paramétereinek hangolására használjuk: MLP: bátorsági tényező, struktúrák validálása SVM: Hibásan osztályozási költsége (C), Érzéketlenségi sáv megválasztása (ε) Kernel leképzés hiperparaméterei.
6 Bernoulli eloszlással modellezzük az egyes minták helyesen osztályozását (p): Pr f p z z c p1 p / N c: konfidencia szint 2 zc : konfidencia-intervallum szélessége a standardizált normális eloszlásnak.
7 Konfidencia intervallumok szélessége: f=0.75 C=0.9 C=0.8 C=0.6 N= N= N= f=0.9 C=0.9 C=0.8 C=0.6 N= N= N= Az előző dián lévő normalizálás csak nagy N esetén állít elő standard normális eloszlást!
8 Alapprobléma: Adott véges mintakészlet alapján szeretnénk osztályozók szeparálási képességeit minősíteni. Osszuk fel a tanítóhalmazokat két részre: Releváns mintákból álljon mind a tanító, mind a validáló halmaz. Ezt így igen nehéz lenne megtenni, ezért inkább kereszt kiértékelünk (Cross Validation).
9 Osszuk fel k diszjunkt részhalmazra a tanító mintákat: Minden kimeneti osztály mintái az egyes partíciókban kummulált relatív gyakoriságuknak megfelelő számban forduljanak elő. A partíciók méretei azonosak legyenek. Tanítsunk k darab osztályozót: i-edik esetén az i-edik partíció alapján validáljunk, a maradék pontkészlettel tanítsunk.
10 Elrettentő példa: Egy teljesen zajszerű mintahalmazt kell megtanulni: független a kimeneti és a bemenet. Minták 50%-a pozitív, 50%-a negatív. Osztályozó: minden bemenetre a tanítóminták közül a gyakoribb besorolását választja Leave-one-out: minden esetben hibás a validáló elem besorolása => 0% becsült pontosság Valójában 50% a pontossága
11 Alkalmazási példák: 10 fold Cross-validation Leave-one-out
12 Véletlen, visszatevésen alapuló kiválasztással állítsuk elő az N méretű tanítóhalmazt. A kimaradó mintákkal teszteljünk. Annak a valószínűsége, hogy az i-edik minta kimarad: N e N
13 Nem érdemes csak a validációs halmaz alapján minősíteni: Várhatólag csak a minták 63.2%-át látta a tanuló algoritmus. err=0.632 err(teszt) err(tanító) Végezzük el többször a bootstrapet, majd annak átlaghibájával minősíthetjük az osztályozót.
14 Elrettentő példa: Ugyanaz a mintahalmaz, mint amit a Kereszt kiértékelésnél közöltem (kimenet a bemenettől független, 50-50% a mintaosztályok rel. gyakorisága) Az osztályozó memorizálja a tanítómintákat, új mintákra véletlenül dönt: err= hibásan osztályozás becsült valsége: Valódi valószínűsége: 0.5
15 Eddig azt néztük, hogyan lehet becsülni egy osztályozó képességeit, de ez mennyire pontos? Student t-próbához nyúlunk: k -os kereszt validációval tanítsuk és minősítünk X egy k-1 szabadságfokú Student eloszlás 2 x / k k növelésével közelíti a std. normál eloszlást
16 k -os kereszt kiértékeléssel alakítsuk/ minősítsük az osztályozókat (ugyanazon tanító/teszt felosztással xi, yi jelölje a két osztályozó minősítését az i-edik kereszt kiértékelésnél. Vizsgáljuk a minősítések különbségét: 0 várható értékű, 1 szórású t statisztika minősíti a 0-hipotézist (u.a. eloszlás mintái): t d 2 d / k k-tól függ a t statisztika megbízhatósága. d x y i i i
17 Tanulás: osztályozók paramétereinek hangolása egy tanító mintakészlet alapján (nem csak). Hogyan működnek az osztályozók: Adott bemeneti mintára osztályba tartozási valószínűségek küszöbölése szerint válaszolnak. Pl. egy rosszul osztályozott mintánál számít, hogy a minta besorolási bizonyossága 51%, vagy 90%. Definiáljunk veszteség fgv-eket!
18 Szakirodalomban SSE, MSE. Err x 2 i yi i Gradiens alapú/ analitikus tanításnál használt hiba fgv példák (ezt minimalizáljuk): Adaline lin. regresszió MLP LS-SVM Err Xθ y Xθ y C/ε SVM, QP célfüggvénye is kvadratikus (megoldhatóság feltétele itt a konvexség) T
19 Vizsgáljuk a konvex, kvadratikus felületű függvényeket: Egyszerű belátni, hogy az előző fejezetben definiált Err konvex felületű. A lokális derivált -1 szerese minden pontban a globális minimum felé mutat. Folytonos függvény -> Minden pontban létezik deriváltja, aminek iránya ellentétes a lokális szélsőérték irányával
20 Vizsgáljuk meg a küszöbölés előtti állapotot általánosabb osztályozót feltételezve, egyetlen input mintára: Minden kimeneti osztályra megmondja, hogy mekkora valószínűséggel eleme az adott osztálynak a minta ( a j Pr class j xi, p j Eaj ) Valójában a kimenet egyetlen osztály. Egy mintára a hiba értéke: 2 j j j j Err p p p 1 p j Err E p a j 2 j j
21 ( ) log 2 Err x p class y x Bemenet: x, elvárt kimenet: y Logisztikus regresszió kritériumfüggvénye Információelméleti megközelítés: hány bitnyi információ szükséges a biztos, helyes döntéshez p(class=y x) ismerete mellé. E Err( x) p log j 2 p j 1 2 j argmin E Err( x) p, p,... p p, p,... p n 1 2 n
22 Logisztikus osztályozók minden kimeneti osztálynak pozitív valószínűséget adnak minden bemenet esetén. Ellenkező esetben a hibafüggvényük értéke végtelen lenne, ha egy olyan példát látnak. Zero frequency problem: Adott bemenethez tartozó kimeneti értékek eloszlásáról nincs információ a mintahalmazban.
23 Négyzetes hibaösszeg: A hiba értéke függ attól, mi a predikált eloszlás a helytelen alternatívák között: Tegyük fel, hogy az x bemenet az i-edik osztályba tartozik. Ekkor Err x 1 p i p j 2 2 ji De a maximális hiba korlátos: Err x 1 p 2 Logisztikus hiba ennek ellentettje. 2 j j
24 Valóság 2 osztályos osztályozás esetén az osztályozási mátrix: Előrejelzés IGAZ HAMIS IGAZ TP FN HAMIS FP TN
25 Valóság Érzékenység: TPR=TP/(TP+FN) Érzékenység Előrejelzés IGAZ HAMIS IGAZ TP FN HAMIS FP TN
26 Valóság Specificitás:SPC=TN/(FP+TN) Szenzitivitás Előrejelzés IGAZ HAMIS IGAZ TP FN HAMIS FP TN
27 Valóság Precizitás:PPV=TP/(TP+FP) Precizitás Előrejelzés IGAZ HAMIS IGAZ TP FN HAMIS FP TN

28 Valóság Negatív prediktív érték:npv=tn/(tn+fn) Negatív prediktív érték Előrejelzés IGAZ HAMIS IGAZ TP FN HAMIS FP TN
29 Valóság Fals pozitív arány:fpr=fp/(fp+tn) Fals pozitív arány Előrejelzés IGAZ HAMIS IGAZ TP FN HAMIS FP TN
30 Valóság Fals riasztás arány:fdr=fp/(tp+fp) Fals riasztás arány Előrejelzés IGAZ HAMIS IGAZ TP FN HAMIS FP TN
31 Valóság Pontosság: ACC=(TP+TN)/(TP+FP+FN+TN) Pontosság Előrejelzés IGAZ HAMIS IGAZ TP FN HAMIS FP TN Cél a főátlóbeli elemek maximalizálása.
32 Azt vizsgáljuk, hogy mennyivel pontosabb a vizsgált osztályozó egy olyannál, ami csak az domén mintáinak gyakorisága alapján becsül. Kappa score: Kappa arány: diag 1 diag C C score T real naiv score N 1 diag C T naiv
33 Eddigiekben uniform hibasúlyok voltak Miért is fontos a különböző hibák eltérő súlyozása? Tehenészetben mért adatokból próbálták megállapítani, hogy melyik tehén mikor kezd menstruálni. Tehenek menstruációs ciklusa az emberekéhez hasonlóan 30 napos -> 1/30 valószínűséggel igaz, hogy egy tehén egy adott nap menstruált. Az osztályozó a null megoldással 97%-os pontosságot ért el (ez így önmagában nagyon jó).
34 Más példák: Üzembiztonságot felügyelő rendszerek fals riasztása kisebb költségű, mint ha nem riaszt, amikor kellene. Bank részéről megközelítve: hitelezni egy olyannak, aki nem fizeti vissza nagyobb veszteség, mint visszatartani a hitelt egy fals megbízhatósági besorolás miatt. Egészségügyi szűréseknél fals negatív eset sokkal rosszabb a fals pozitívnál.
35 Példa: Uniform hibasúllyal kialakítottunk egy osztályozót. Utólag meghatározott valaki egy hibákhoz kapcsolódó súlymátrixot. Megoldás (k osztályozós eset): Predikált valószínűségeket páronként súlyozva hasonlítsuk össze, majd a páronkénti score-ok alapján válasszuk ki a legvalószínűbbet. Problémás lehet, mert nem biztos, hogy tranzitívak a páronkénti súlyozott valószínűség különbségek
36 Itt a tanítás esetén már rendelkezésre áll a különböző hibák súlya: felhasználjuk tanításnál: Gépi tanulásnál legtöbbször az input osztályt tudjuk csak súlyozni. MLP: minták ismételt használata 1 epochon belül Aszimmetrikus C-SVM: megadhatóak osztály súlyok Bayes háló: minták ismételt használata
37 Értelem szerűen minősítésnél is vegyük figyelembe a hibasúlyokat. Legtöbbször kiegyensúlyozatlan tanítóhalmaz miatt használjuk: Ha pl. illesztett szűrővel keresünk alakzatot egy képen, majd jellemzők alapján akarjuk a jelölteket osztályozni, akkor a P/N<<1 eset áll fel mindig α*n/p legyen a P minták súlya, α 1.
38 Spammelik nyereményjátékkal a lakosságot Ismert súlyok: Levél költsége (nyomtatás+ kézbesítés+ kenőpénz a hatóságnak, hogy adják ki a névjegyzéket). Ha valaki részt vesz a játékban, az mekkora bevétel. T.f.h hogy létezik fő, akik 5%-a, míg a teljes lakosság 1%-a válaszol csak: Az fős csoport lift faktora 5.

39 Megoldás: 1. Vegyünk egy mintahalmazt hasonló esetről (emberek jellemzői a bemenetek részt vett-e a kimenet). 2. Tanítsunk egy olyan osztályozót, aminek részvételi valószínűségek a kimenetei. 3. Rangsoroljuk az embereket ez alapján, majd a legjobb k%-nak küldjük ki a leveleket.
40
41 Újfent valószínűségi kimenetekkel rendelkező 2 osztályos osztályozónk van. FPR=FP/(FP+TN) függvényében ábrázoljuk a TPR=TP/(TP+FN)-t.
42 Lehetséges osztályozók munkapont független rangsorolása:
43 Munkapont független minősítést (AUC): AUC 1 TPR xdx 0 Munkapont kijelölése (hol küszöböljük a kiadott valószínűségeket): arg min TPR( k) C FPR( k) C k
44 Tetszőleges munkatartományon belüli minősítés: NAUC ( FPR1, FPR2) FPR2 FPR1 TPR( x) dx FPR2 FPR1 NAUC ( TPR1, TPR2) TPR2 TPR2 TPR1 FPR( x) dx TPR1 TPR2TPR1
45
46
47 Keresőket minősítünk: Egyik 100 találatot ad, abból 40 releváns Másik 400-at, amiből 80 releváns. Recall: releváns dokumentumok mekkora része eleme a találatoknak (TP/(TP+FN)) Precision: a találatok mekkora része releváns Ez is ábrázolható grafikusan. (TP/(TP+FP)) Munkapont kiválasztása talán ezzel a módszernél a legkézenfekvőbb.
48 k pontos átlagos recall: k=3 esetén 20%,50%,80%-os recall-hoz tartozó precision átlaga F-mérték: 2recall precision 2TP recall precision 2TP FP FN ROC- AUC Helyesen osztályzási arány: (TP+TN)/(P+N)

49 Eddigi görbék: Hibasúly függő munkapont választás De nem hibasúly függő kiértékelés Költség görbék: Egy osztályozóhoz egy egyenest rendelünk: várható osztályozási hiba a teszthalmaz mintáinak eloszlásának a függvényében. Tehát itt küszöböljük a predikált valségeket
50
51
52 Hol marad a hibák súlyozása? Valószínűségi költség: 0-1 között változik p C p C pc pc Normalizált várható költség: nec( p ) fn p fp 1 p c c c C[+ +]=C[- -]=0 feltételezéssel éltünk.
53 Mi is a normalizált várható költség értéke: nec( p ) c fn p C fp p C pc pc Piros: FN besorolásból eredő várható hiba Zöld: FP besorolásból eredő várható hiba Kék: Elérhető legnagyobb várható hiba (minden elemet rosszul osztályzunk)
54
55

56 Alapvetően a kritériumfüggvények által definiált sorrendezés egymástól relevánsan eltérő osztályozókra megegyezik.
57 Gépi tanulás célja: Leképzést lehető legkisebb hibával annak mintáiból megtanulni. De egy véges ponthalmazra végtelen sok függvény illeszkedhet. Zajjal terheltek a bemenetek, illetve a kimenetek Occam elv: Azonos valószínűségű magyarázatokból az egyszerűbbet preferáljuk. Statisztikai tanuláselmélet tárgyalja behatóbban
58 MDL szerinti legjobb teória: Legkisebb méretű a mögöttes modell A tanításhoz felhasznált minták esetén átlagosan legkevesebb plusz információra van szükség. MDL elv analógiája: Zajmentes csatornán kell a tanítómintákat átvinni. Keressük azt a módszert, amivel a lehető legkevesebb bitet kell csak forgalmazni.

59 Szélsőséges esetek: Memorizáló modell Null modell Ezen esetek leírásai nagyok Nincs szükség szeparált teszthalmazra: Statisztikai tanuláselmélet szerint R=Remp+Q A mintakészlet átviteléhez szükséges információ mennyiségét vizsgáljuk csak. Ellenben nem igazán alkalmazható jól.
60 Egy szakértő VC dimenziója azon mintahalmaz maximális mérete, mely mintái: Tetszőleges, de nem elfajuló elhelyezkedésű Tetszőlegesen két osztályba sorolásúak És létezik olyan paraméterezése a szakértőnek, amivel helyesen képes a halmazt osztályozni. Mekkora a VC dimenziója egy lineáris szakértőnek?
61 Bayes szabály: Pr TE Pr E T Pr Pr E T Log-lieklihood elven maximalizáljuk: log Pr T E log Pr E T log Pr T log Pr E Tehát minimalizáljuk az alábbi kifejezést: E T log PrT log Pr
62 Pr[T] meghatározása lehetetlen: Függ a modell kódjától Mekkora komplexitása van egy műveletnek? Mekkora a komplexitása egy művelet sorozatnak? Gyakorlatban alacsony szintű (C/ Pascal) program kódjának hosszával közelítik.
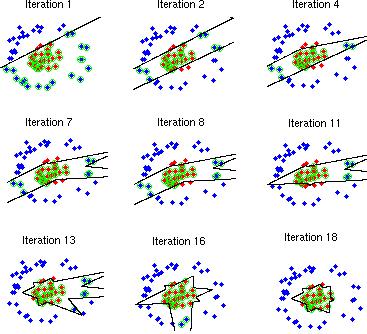
63 Pr[E T] körüli problémák: Szekvenciaként értelmezzük a tanító mintákat, vagy halmazként? Ha szekvenciaként értelmezzük, akkor kihasználhatjuk a hibák autokorreláltságát? A megválaszolhatatlan kérdések miatt gyakorlatban inkább Vapnik statisztikai tanuláselméletét alkalmazzuk.
64 Cél: mintapontok koordinátáit megengedett ε maximális pontatlansággal átvinni a csatornán minél kevesebb bitet forgalmazva. Mit küldjünk el a csatornán: Klaszterek centroidját Melyik minta melyik klaszterbe tartozik Minták attribútumainak eltérése a klaszter középponttól ezen eltérések eloszlása szerint tömörítve.
65 Klaszteren belüli eloszlást hogy kódoljuk? Átküldjük pár, klaszteren belüli minta attribútumait. Ezekre illeszti mindkét oldal a tömörítéshez felhasznált eloszlás paramétereit. (Ennek konkrét kivitelezése aktuális kutatások témája). Jelentős tömörítés elérhető, ha a módszer jól képes klaszterezni. Ha viszont a módszer elbukik adott mintán, akkor általában jobban megéri a 0 modell.
66 Moduláris szakértőket hozunk létre: Az egyes szakértőket különböző eloszlású, de azonos halmazból generált mintakészlettel tanítjuk Elméleti háttér: Egy olyan osztályba sorolást kell megtanulni, mely szeparáló felülete jól közelíthető egyszerűbb szeparáló felületek súlyozott átlagával. Összességében viszont egy komplex, nem lineáris leképzéssel állunk szemben.
67 Az általánosítási hiba várható értéke kisebb a hálónak, mint egy azonos határoló felületű szakértőnek: Pl. k darab lineáris szakértő egyszerűbb egy erősen nem lineárisnál (pl. nem tudjuk megmondani előre, hogy a k szakértő kimenete egy 4-ed fokú polinommal közelíthető).
68 1. 2. t:=1 3. SZ(t)-t alakítsuk ki D súlyokkal D : 1 Ll re : Pr y x d 8. t:=t+1 l t t l l 1 1 t t : ln 2 t D : D exp(( y x d 1) l re l l t l l t D : D D l re l l k k
69
70 Itt moduláris szakértőt alakítunk ki. Viszont itt a domént partícionáljuk különböző területekre: Egyes részdoménekben elég egyszerűbb osztályozó Összességében itt is nemlineáris szeparáló felülettel küzdünk. Jobb az általánosító képessége az így kialakított szakértő együttesnek.
71 [1]: Ian H. Witten, Eibe Frank, Mark A. Hall: Data Mining Practical Machine Learning Tools and Techniques 3rd edition pp [2]: Horváth G. (szerk): Neurális hálózatok 2006, 2. fejezet [3]: Schapire, R. E., A Brief Introduction to Boosting, (IJCAI-99) Vol. 2. pp [4]:Jacobs, R.A., Jordan, M. I., Nowlan, S. J., Hinton, G. E. Adaptive Mixture of Local Experts, Neural Computation, Vol. 3. pp
72
Eredmények kiértékelése
 Eredmények kiértékelése Nagyméretű adathalmazok kezelése (2010/2011/2) Katus Kristóf, hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi és Információelméleti Tanszék 2011. március
Eredmények kiértékelése Nagyméretű adathalmazok kezelése (2010/2011/2) Katus Kristóf, hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi és Információelméleti Tanszék 2011. március
Gépi tanulás a gyakorlatban. Kiértékelés és Klaszterezés
 Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Gépi tanulás. Hány tanítómintára van szükség? VKH. Pataki Béla (Bolgár Bence)
") Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
Gépi tanulás Hány tanítómintára van szükség? VKH Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Induktív tanulás A tanítás folyamata: Kiinduló
Biomatematika 12. Szent István Egyetem Állatorvos-tudományi Kar. Fodor János
 Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 8 VIII. REGREssZIÓ 1. A REGREssZIÓs EGYENEs Két valószínűségi változó kapcsolatának leírására az eddigiek alapján vagy egy numerikus
Anyagvizsgálati módszerek Mérési adatok feldolgozása. Anyagvizsgálati módszerek
 Anyagvizsgálati módszerek Mérési adatok feldolgozása Anyagvizsgálati módszerek Pannon Egyetem Mérnöki Kar Anyagvizsgálati módszerek Statisztika 1/ 22 Mérési eredmények felhasználása Tulajdonságok hierarchikus
Anyagvizsgálati módszerek Mérési adatok feldolgozása Anyagvizsgálati módszerek Pannon Egyetem Mérnöki Kar Anyagvizsgálati módszerek Statisztika 1/ 22 Mérési eredmények felhasználása Tulajdonságok hierarchikus
Keresés képi jellemzők alapján. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
Keresés képi jellemzők alapján Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Lusta gépi tanulási algoritmusok Osztályozás: k=1: piros k=5: kék k-legközelebbi szomszéd (k=1,3,5,7)
[1000 ; 0] 7 [1000 ; 3000]
![[1000 ; 0] 7 [1000 ; 3000]](/thumbs/88/116286101.jpg "[1000 ; 0] 7 [1000 ; 3000]") Gépi tanulás (vimim36) Gyakorló feladatok 04 tavaszi félév Ahol lehet, ott konkrét számértékeket várok nem puszta egyenleteket. (Azok egy részét amúgyis megadom.). Egy bináris osztályozási feladatra tanított
Gépi tanulás (vimim36) Gyakorló feladatok 04 tavaszi félév Ahol lehet, ott konkrét számértékeket várok nem puszta egyenleteket. (Azok egy részét amúgyis megadom.). Egy bináris osztályozási feladatra tanított
Statisztika - bevezetés Méréselmélet PE MIK MI_BSc VI_BSc 1
 Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék. Neurális hálók. Pataki Béla
 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók Előadó: Előadás anyaga: Hullám Gábor Pataki Béla Dobrowiecki Tadeusz BME I.E. 414, 463-26-79
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók Előadó: Előadás anyaga: Hullám Gábor Pataki Béla Dobrowiecki Tadeusz BME I.E. 414, 463-26-79
Gépi tanulás. Féligellenőrzött tanulás. Pataki Béla (Bolgár Bence)
") Gépi tanulás Féligellenőrzött tanulás Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Féligellenőrzött tanulás Mindig kevés az adat, de
Gépi tanulás Féligellenőrzött tanulás Pataki Béla (Bolgár Bence) BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki Féligellenőrzött tanulás Mindig kevés az adat, de
Tanulás az idegrendszerben. Structure Dynamics Implementation Algorithm Computation - Function
 Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Tanulás az idegrendszerben Structure Dynamics Implementation Algorithm Computation - Function Tanulás pszichológiai szinten Classical conditioning Hebb ötlete: "Ha az A sejt axonja elég közel van a B sejthez,
Kódverifikáció gépi tanulással
 Kódverifikáció gépi tanulással Szoftver verifikáció és validáció kiselőadás Hidasi Balázs 2013. 12. 12. Áttekintés Gépi tanuló módszerek áttekintése Kódverifikáció Motiváció Néhány megközelítés Fault Invariant
Kódverifikáció gépi tanulással Szoftver verifikáció és validáció kiselőadás Hidasi Balázs 2013. 12. 12. Áttekintés Gépi tanuló módszerek áttekintése Kódverifikáció Motiváció Néhány megközelítés Fault Invariant
Regresszió. Csorba János. Nagyméretű adathalmazok kezelése március 31.
 Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Gépi tanulás a gyakorlatban. Lineáris regresszió
 Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Gépi tanulás a gyakorlatban Lineáris regresszió Lineáris Regresszió Legyen adott egy tanuló adatbázis: Rendelkezésünkre áll egy olyan előfeldolgozott adathalmaz, aminek sorai az egyes ingatlanokat írják
Adatbányászati feladatgyűjtemény tehetséges hallgatók számára
 Adatbányászati feladatgyűjtemény tehetséges hallgatók számára Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Tartalomjegyék Modellek kiértékelése...
Adatbányászati feladatgyűjtemény tehetséges hallgatók számára Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Tartalomjegyék Modellek kiértékelése...
Statisztika I. 8. előadás. Előadó: Dr. Ertsey Imre
 Statisztika I. 8. előadás Előadó: Dr. Ertsey Imre Minták alapján történő értékelések A statisztika foglalkozik. a tömegjelenségek vizsgálatával Bizonyos esetekben lehetetlen illetve célszerűtlen a teljes
Statisztika I. 8. előadás Előadó: Dr. Ertsey Imre Minták alapján történő értékelések A statisztika foglalkozik. a tömegjelenségek vizsgálatával Bizonyos esetekben lehetetlen illetve célszerűtlen a teljes
Számítógépes képelemzés 7. előadás. Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék
 Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
Számítógépes képelemzés 7. előadás Dr. Balázs Péter SZTE, Képfeldolgozás és Számítógépes Grafika Tanszék Momentumok Momentum-alapú jellemzők Tömegközéppont Irányultáság 1 2 tan 2 1 2,0 1,1 0, 2 Befoglaló
KÖVETKEZTETŐ STATISZTIKA
 ÁVF GM szak 2010 ősz KÖVETKEZTETŐ STATISZTIKA A MINTAVÉTEL BECSLÉS A sokasági átlag becslése 2010 ősz Utoljára módosítva: 2010-09-07 ÁVF Oktató: Lipécz György 1 A becslés alapfeladata Pl. Hányan láttak
ÁVF GM szak 2010 ősz KÖVETKEZTETŐ STATISZTIKA A MINTAVÉTEL BECSLÉS A sokasági átlag becslése 2010 ősz Utoljára módosítva: 2010-09-07 ÁVF Oktató: Lipécz György 1 A becslés alapfeladata Pl. Hányan láttak
Irányításelmélet és technika II.
 Irányításelmélet és technika II. Legkisebb négyzetek módszere Magyar Attila Pannon Egyetem Műszaki Informatikai Kar Villamosmérnöki és Információs Rendszerek Tanszék amagyar@almos.vein.hu 200 november
Irányításelmélet és technika II. Legkisebb négyzetek módszere Magyar Attila Pannon Egyetem Műszaki Informatikai Kar Villamosmérnöki és Információs Rendszerek Tanszék amagyar@almos.vein.hu 200 november
[Biomatematika 2] Orvosi biometria
![[Biomatematika 2] Orvosi biometria](/thumbs/54/33134304.jpg "[Biomatematika 2] Orvosi biometria") [Biomatematika 2] Orvosi biometria 2016.02.29. A statisztika típusai Leíró jellegű statisztika: összegzi egy adathalmaz jellemzőit. A középértéket jelemzi (medián, módus, átlag) Az adatok változékonyságát
[Biomatematika 2] Orvosi biometria 2016.02.29. A statisztika típusai Leíró jellegű statisztika: összegzi egy adathalmaz jellemzőit. A középértéket jelemzi (medián, módus, átlag) Az adatok változékonyságát
Hipotézis STATISZTIKA. Kétmintás hipotézisek. Munkahipotézis (H a ) Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok
 Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok") STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
y ij = µ + α i + e ij
 Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai
Elmélet STATISZTIKA 3. Előadás Variancia-analízis Lineáris modellek A magyarázat a függő változó teljes heterogenitásának két részre bontását jelenti. A teljes heterogenitás egyik része az, amelynek okai
E x μ x μ K I. és 1. osztály. pontokként), valamint a bayesi döntést megvalósító szeparáló görbét (kék egyenes)
, valamint a bayesi döntést megvalósító szeparáló görbét (kék egyenes)") 6-7 ősz. gyakorlat Feladatok.) Adjon meg azt a perceptronon implementált Bayes-i klasszifikátort, amely kétdimenziós a bemeneti tér felett szeparálja a Gauss eloszlású mintákat! Rajzolja le a bemeneti
6-7 ősz. gyakorlat Feladatok.) Adjon meg azt a perceptronon implementált Bayes-i klasszifikátort, amely kétdimenziós a bemeneti tér felett szeparálja a Gauss eloszlású mintákat! Rajzolja le a bemeneti
Adatbányászati szemelvények MapReduce környezetben
 Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
Adatbányászati szemelvények MapReduce környezetben Salánki Ágnes salanki@mit.bme.hu 2014.11.10. Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Felügyelt
BAGME11NNF Munkavédelmi mérnökasszisztens Galla Jánosné, 2011.
 BAGME11NNF Munkavédelmi mérnökasszisztens Galla Jánosné, 2011. 1 Mérési hibák súlya és szerepe a mérési eredményben A mérési hibák csoportosítása A hiba rendűsége Mérési bizonytalanság Standard és kiterjesztett
BAGME11NNF Munkavédelmi mérnökasszisztens Galla Jánosné, 2011. 1 Mérési hibák súlya és szerepe a mérési eredményben A mérési hibák csoportosítása A hiba rendűsége Mérési bizonytalanság Standard és kiterjesztett
Véletlen jelenség: okok rendszere hozza létre - nem ismerhetjük mind, ezért sztochasztikus.
 Valószín ségelméleti és matematikai statisztikai alapfogalmak összefoglalása (Kemény Sándor - Deák András: Mérések tervezése és eredményeik értékelése, kivonat) Véletlen jelenség: okok rendszere hozza
Valószín ségelméleti és matematikai statisztikai alapfogalmak összefoglalása (Kemény Sándor - Deák András: Mérések tervezése és eredményeik értékelése, kivonat) Véletlen jelenség: okok rendszere hozza
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék. Neurális hálók 2. Pataki Béla
 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók 2. Előadó: Hullám Gábor Pataki Béla BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Neurális hálók 2. Előadó: Hullám Gábor Pataki Béla BME I.E. 414, 463-26-79 pataki@mit.bme.hu, http://www.mit.bme.hu/general/staff/pataki
Véletlenszám generátorok és tesztelésük. Tossenberger Tamás
 Véletlenszám generátorok és tesztelésük Tossenberger Tamás Érdekességek Pénzérme feldobó gép: $0,25-os érme 1/6000 valószínűséggel esik az élére 51% eséllyel érkezik a felfelé mutató oldalára Pörgetésnél
Véletlenszám generátorok és tesztelésük Tossenberger Tamás Érdekességek Pénzérme feldobó gép: $0,25-os érme 1/6000 valószínűséggel esik az élére 51% eséllyel érkezik a felfelé mutató oldalára Pörgetésnél
1. Adatok kiértékelése. 2. A feltételek megvizsgálása. 3. A hipotézis megfogalmazása
 HIPOTÉZIS VIZSGÁLAT A hipotézis feltételezés egy vagy több populációról. (pl. egy gyógyszer az esetek 90%-ában hatásos; egy kezelés jelentősen megnöveli a rákos betegek túlélését). A hipotézis vizsgálat
HIPOTÉZIS VIZSGÁLAT A hipotézis feltételezés egy vagy több populációról. (pl. egy gyógyszer az esetek 90%-ában hatásos; egy kezelés jelentősen megnöveli a rákos betegek túlélését). A hipotézis vizsgálat
Mérési hibák 2006.10.04. 1
 Mérési hibák 2006.10.04. 1 Mérés jel- és rendszerelméleti modellje Mérési hibák_labor/2 Mérési hibák mérési hiba: a meghatározandó értékre a mérés során kapott eredmény és ideális értéke közötti különbség
Mérési hibák 2006.10.04. 1 Mérés jel- és rendszerelméleti modellje Mérési hibák_labor/2 Mérési hibák mérési hiba: a meghatározandó értékre a mérés során kapott eredmény és ideális értéke közötti különbség
Alap-ötlet: Karl Friedrich Gauss ( ) valószínűségszámítási háttér: Andrej Markov ( )
 valószínűségszámítási háttér: Andrej Markov ( )") Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Budapesti Műszaki és Gazdaságtudományi Egyetem Gépészmérnöki Kar Hidrodinamikai Rendszerek Tanszék, Budapest, Műegyetem rkp. 3. D ép. 334. Tel: 463-6-80 Fa: 463-30-9 http://www.vizgep.bme.hu Alap-ötlet:
Intelligens Rendszerek Elmélete. Versengéses és önszervező tanulás neurális hálózatokban
 Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Osztályozás, regresszió. Nagyméretű adathalmazok kezelése Tatai Márton
 Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
Osztályozás, regresszió Nagyméretű adathalmazok kezelése Tatai Márton Osztályozási algoritmusok Osztályozás Diszkrét értékkészletű, ismeretlen attribútumok értékének meghatározása ismert attribútumok értéke
Matematikai alapok és valószínőségszámítás. Statisztikai becslés Statisztikák eloszlása
 Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
Least Squares becslés
 Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
Least Squares becslés A négyzetes hibafüggvény: i d i ( ) φx i A négyzetes hibafüggvény mellett a minimumot biztosító megoldás W=( d LS becslés A gradiens számítása és nullává tétele eredményeképp A megoldás
STATISZTIKA. A maradék független a kezelés és blokk hatástól. Maradékok leíró statisztikája. 4. A modell érvényességének ellenőrzése
 4. A modell érvényességének ellenőrzése STATISZTIKA 4. Előadás Variancia-analízis Lineáris modellek 1. Függetlenség 2. Normális eloszlás 3. Azonos varianciák A maradék független a kezelés és blokk hatástól
4. A modell érvényességének ellenőrzése STATISZTIKA 4. Előadás Variancia-analízis Lineáris modellek 1. Függetlenség 2. Normális eloszlás 3. Azonos varianciák A maradék független a kezelés és blokk hatástól
VALÓSZÍNŰSÉG, STATISZTIKA TANÍTÁSA
 VALÓSZÍNŰSÉG, STATISZTIKA TANÍTÁSA A VALÓSZÍNŰSÉGI SZEMLÉLET ALAPOZÁSA 1-6. OSZTÁLY A biztos, a lehetetlen és a lehet, de nem biztos események megkülünböztetése Valószínűségi játékok, kísérletek események
VALÓSZÍNŰSÉG, STATISZTIKA TANÍTÁSA A VALÓSZÍNŰSÉGI SZEMLÉLET ALAPOZÁSA 1-6. OSZTÁLY A biztos, a lehetetlen és a lehet, de nem biztos események megkülünböztetése Valószínűségi játékok, kísérletek események
Egyszempontos variancia analízis. Statisztika I., 5. alkalom
 Statisztika I., 5. alkalom Számos t-próba versus variancia analízis Kreativitás vizsgálata -nık -férfiak ->kétmintás t-próba I. Fajú hiba=α Kreativitás vizsgálata -informatikusok -építészek -színészek
Statisztika I., 5. alkalom Számos t-próba versus variancia analízis Kreativitás vizsgálata -nık -férfiak ->kétmintás t-próba I. Fajú hiba=α Kreativitás vizsgálata -informatikusok -építészek -színészek
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
Gépi tanulás Gregorics Tibor Mesterséges intelligencia
 Gépi tanulás Tanulás fogalma Egy algoritmus akkor tanul, ha egy feladat megoldása során olyan változások következnek be a működésében, hogy később ugyanazt a feladatot vagy ahhoz hasonló más feladatokat
Gépi tanulás Tanulás fogalma Egy algoritmus akkor tanul, ha egy feladat megoldása során olyan változások következnek be a működésében, hogy később ugyanazt a feladatot vagy ahhoz hasonló más feladatokat
Hipotézis, sejtés STATISZTIKA. Kétmintás hipotézisek. Tudományos hipotézis. Munkahipotézis (H a ) Nullhipotézis (H 0 ) 11. Előadás
 Nullhipotézis (H 0 ) 11. Előadás") STATISZTIKA Hipotézis, sejtés 11. Előadás Hipotézisvizsgálatok, nem paraméteres próbák Tudományos hipotézis Nullhipotézis felállítása (H 0 ): Kétmintás hipotézisek Munkahipotézis (H a ) Nullhipotézis (H
STATISZTIKA Hipotézis, sejtés 11. Előadás Hipotézisvizsgálatok, nem paraméteres próbák Tudományos hipotézis Nullhipotézis felállítása (H 0 ): Kétmintás hipotézisek Munkahipotézis (H a ) Nullhipotézis (H
Algoritmuselmélet. Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem. 13.
 Algoritmuselmélet NP-teljes problémák Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 13. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet
Algoritmuselmélet NP-teljes problémák Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem 13. előadás Katona Gyula Y. (BME SZIT) Algoritmuselmélet
Lineáris regressziós modellek 1
 Lineáris regressziós modellek 1 Ispány Márton és Jeszenszky Péter 2016. szeptember 19. 1 Az ábrák C.M. Bishop: Pattern Recognition and Machine Learning c. könyvéből származnak. Tartalom Bevezető példák
Lineáris regressziós modellek 1 Ispány Márton és Jeszenszky Péter 2016. szeptember 19. 1 Az ábrák C.M. Bishop: Pattern Recognition and Machine Learning c. könyvéből származnak. Tartalom Bevezető példák
A maximum likelihood becslésről
 A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
A maximum likelihood becslésről Definíció Parametrikus becsléssel foglalkozunk. Adott egy modell, mellyel elképzeléseink szerint jól leírható a meghatározni kívánt rendszer. (A modell típusának és rendszámának
Funkcionálanalízis. n=1. n=1. x n y n. n=1
 Funkcionálanalízis 2011/12 tavaszi félév - 2. előadás 1.4. Lényeges alap-terek, példák Sorozat terek (Folytatás.) C: konvergens sorozatok tere. A tér pontjai sorozatok: x = (x n ). Ezen belül C 0 a nullsorozatok
Funkcionálanalízis 2011/12 tavaszi félév - 2. előadás 1.4. Lényeges alap-terek, példák Sorozat terek (Folytatás.) C: konvergens sorozatok tere. A tér pontjai sorozatok: x = (x n ). Ezen belül C 0 a nullsorozatok
I. LABOR -Mesterséges neuron
 I. LABOR -Mesterséges neuron A GYAKORLAT CÉLJA: A mesterséges neuron struktúrájának az ismertetése, neuronhálókkal kapcsolatos elemek, alapfogalmak bemutatása, aktivációs függvénytípusok szemléltetése,
I. LABOR -Mesterséges neuron A GYAKORLAT CÉLJA: A mesterséges neuron struktúrájának az ismertetése, neuronhálókkal kapcsolatos elemek, alapfogalmak bemutatása, aktivációs függvénytípusok szemléltetése,
Csima Judit április 9.
 Osztályozókról még pár dolog Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2018. április 9. Csima Judit Osztályozókról még pár dolog 1 / 19 SVM (support vector machine) ez is egy
Osztályozókról még pár dolog Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2018. április 9. Csima Judit Osztályozókról még pár dolog 1 / 19 SVM (support vector machine) ez is egy
Statisztikai következtetések Nemlineáris regresszió Feladatok Vége
 [GVMGS11MNC] Gazdaságstatisztika 10. előadás: 9. Regressziószámítás II. Kóczy Á. László koczy.laszlo@kgk.uni-obuda.hu Keleti Károly Gazdasági Kar Vállalkozásmenedzsment Intézet A standard lineáris modell
[GVMGS11MNC] Gazdaságstatisztika 10. előadás: 9. Regressziószámítás II. Kóczy Á. László koczy.laszlo@kgk.uni-obuda.hu Keleti Károly Gazdasági Kar Vállalkozásmenedzsment Intézet A standard lineáris modell
KÖZELÍTŐ INFERENCIA II.
 STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
Nagy számok törvényei Statisztikai mintavétel Várható érték becslése. Dr. Berta Miklós Fizika és Kémia Tanszék Széchenyi István Egyetem
 agy számok törvényei Statisztikai mintavétel Várható érték becslése Dr. Berta Miklós Fizika és Kémia Tanszék Széchenyi István Egyetem A mérés mint statisztikai mintavétel A méréssel az eloszlásfüggvénnyel
agy számok törvényei Statisztikai mintavétel Várható érték becslése Dr. Berta Miklós Fizika és Kémia Tanszék Széchenyi István Egyetem A mérés mint statisztikai mintavétel A méréssel az eloszlásfüggvénnyel
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
Intelligens orvosi műszerek VIMIA023
 Intelligens orvosi műszerek VIMIA023 Diagnózistámogatás = döntéstámogatás A döntések jellemzése (ROC, AUC) 2018 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu (463-)2679
Intelligens orvosi műszerek VIMIA023 Diagnózistámogatás = döntéstámogatás A döntések jellemzése (ROC, AUC) 2018 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu (463-)2679
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
Hadházi Dániel.
 Hadházi Dániel hadhazi@mit.bme.hu Orvosi képdiagnosztika: Szerepe napjaink orvoslásában Képszegmentálás orvosi kontextusban Elvárások az adekvát szegmentálásokkal szemben Verifikáció és validáció lehetséges
Hadházi Dániel hadhazi@mit.bme.hu Orvosi képdiagnosztika: Szerepe napjaink orvoslásában Képszegmentálás orvosi kontextusban Elvárások az adekvát szegmentálásokkal szemben Verifikáció és validáció lehetséges
Intelligens orvosi műszerek VIMIA023
 Intelligens orvosi műszerek VIMIA023 Neurális hálók (Dobrowiecki Tadeusz anyagának átdolgozásával) 2017 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu (463-)2679 A
Intelligens orvosi műszerek VIMIA023 Neurális hálók (Dobrowiecki Tadeusz anyagának átdolgozásával) 2017 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu (463-)2679 A
A következő feladat célja az, hogy egyszerű módon konstruáljunk Poisson folyamatokat.
 Poisson folyamatok, exponenciális eloszlások Azt mondjuk, hogy a ξ valószínűségi változó Poisson eloszlású λ, 0 < λ
Poisson folyamatok, exponenciális eloszlások Azt mondjuk, hogy a ξ valószínűségi változó Poisson eloszlású λ, 0 < λ
Adatok statisztikai értékelésének főbb lehetőségei
 Adatok statisztikai értékelésének főbb lehetőségei 1. a. Egy- vagy kétváltozós eset b. Többváltozós eset 2. a. Becslési problémák, hipotézis vizsgálat b. Mintázatelemzés 3. Szint: a. Egyedi b. Populáció
Adatok statisztikai értékelésének főbb lehetőségei 1. a. Egy- vagy kétváltozós eset b. Többváltozós eset 2. a. Becslési problémák, hipotézis vizsgálat b. Mintázatelemzés 3. Szint: a. Egyedi b. Populáció
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 3 III. VÉLETLEN VEKTOROK 1. A KÉTDIMENZIÓs VÉLETLEN VEKTOR Definíció: Az leképezést (kétdimenziós) véletlen vektornak nevezzük, ha Definíció:
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 3 III. VÉLETLEN VEKTOROK 1. A KÉTDIMENZIÓs VÉLETLEN VEKTOR Definíció: Az leképezést (kétdimenziós) véletlen vektornak nevezzük, ha Definíció:
Biomatematika 2 Orvosi biometria
 Biomatematika 2 Orvosi biometria 2017.02.13. Populáció és minta jellemző adatai Hibaszámítás Valószínűség 1 Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza)
Biomatematika 2 Orvosi biometria 2017.02.13. Populáció és minta jellemző adatai Hibaszámítás Valószínűség 1 Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza)
Korreláció és lineáris regresszió
 Korreláció és lineáris regresszió Két folytonos változó közötti összefüggés vizsgálata Szűcs Mónika SZTE ÁOK-TTIK Orvosi Fizikai és Orvosi Informatikai Intézet Orvosi Fizika és Statisztika I. előadás 2016.11.02.
Korreláció és lineáris regresszió Két folytonos változó közötti összefüggés vizsgálata Szűcs Mónika SZTE ÁOK-TTIK Orvosi Fizikai és Orvosi Informatikai Intézet Orvosi Fizika és Statisztika I. előadás 2016.11.02.
Mesterséges Intelligencia MI
 Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
Mesterséges Intelligencia MI Valószínűségi hálók - következtetés Dobrowiecki Tadeusz Eredics Péter, és mások BME I.E. 437, 463-28-99 dobrowiecki@mit.bme.hu, http://www.mit.bme.hu/general/staff/tade Következtetés
x, x R, x rögzített esetén esemény. : ( ) x Valószínűségi Változó: Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel:
 x Valószínűségi Változó: Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel:") Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel: Valószínűségi változó általános fogalma: A : R leképezést valószínűségi változónak nevezzük, ha : ( ) x, x R, x rögzített esetén esemény.
Feltételes valószínűség: Teljes valószínűség Tétele: Bayes Tétel: Valószínűségi változó általános fogalma: A : R leképezést valószínűségi változónak nevezzük, ha : ( ) x, x R, x rögzített esetén esemény.
Nem-lineáris programozási feladatok
 Nem-lineáris programozási feladatok S - lehetséges halmaz 2008.02.04 Dr.Bajalinov Erik, NyF MII 1 Elég egyszerű példa: nemlineáris célfüggvény + lineáris feltételek Lehetséges halmaz x 1 *x 2 =6.75 Gradiens
Nem-lineáris programozási feladatok S - lehetséges halmaz 2008.02.04 Dr.Bajalinov Erik, NyF MII 1 Elég egyszerű példa: nemlineáris célfüggvény + lineáris feltételek Lehetséges halmaz x 1 *x 2 =6.75 Gradiens
Statisztika I. 4. előadás Mintavétel. Kóczy Á. László KGK-VMI. Minta Mintavétel Feladatok. http://uni-obuda.hu/users/koczyl/statisztika1.
 Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
Regressziós vizsgálatok
 Regressziós vizsgálatok Regresszió (regression) Általános jelentése: visszaesés, hanyatlás, visszafelé mozgás, visszavezetés. Orvosi területen: visszafejlődés, involúció. A betegség tünetei, vagy maga
Regressziós vizsgálatok Regresszió (regression) Általános jelentése: visszaesés, hanyatlás, visszafelé mozgás, visszavezetés. Orvosi területen: visszafejlődés, involúció. A betegség tünetei, vagy maga
1/1. Házi feladat. 1. Legyen p és q igaz vagy hamis matematikai kifejezés. Mutassuk meg, hogy
 /. Házi feladat. Legyen p és q igaz vagy hamis matematikai kifejezés. Mutassuk meg, hogy mindig igaz. (p (( p) q)) (( p) ( q)). Igazoljuk, hogy minden A, B és C halmazra A \ (B C) = (A \ B) (A \ C) teljesül.
/. Házi feladat. Legyen p és q igaz vagy hamis matematikai kifejezés. Mutassuk meg, hogy mindig igaz. (p (( p) q)) (( p) ( q)). Igazoljuk, hogy minden A, B és C halmazra A \ (B C) = (A \ B) (A \ C) teljesül.
A L Hospital-szabály, elaszticitás, monotonitás, konvexitás
 A L Hospital-szabály, elaszticitás, monotonitás, konvexitás 9. előadás Farkas István DE ATC Gazdaságelemzési és Statisztikai Tanszék A L Hospital-szabály, elaszticitás, monotonitás, konvexitás p. / A L
A L Hospital-szabály, elaszticitás, monotonitás, konvexitás 9. előadás Farkas István DE ATC Gazdaságelemzési és Statisztikai Tanszék A L Hospital-szabály, elaszticitás, monotonitás, konvexitás p. / A L
Konjugált gradiens módszer
 Közelítő és szimbolikus számítások 12. gyakorlat Konjugált gradiens módszer Készítette: Gelle Kitti Csendes Tibor Vinkó Tamás Faragó István Horváth Róbert jegyzetei alapján 1 LINEÁRIS EGYENLETRENDSZEREK
Közelítő és szimbolikus számítások 12. gyakorlat Konjugált gradiens módszer Készítette: Gelle Kitti Csendes Tibor Vinkó Tamás Faragó István Horváth Róbert jegyzetei alapján 1 LINEÁRIS EGYENLETRENDSZEREK
4/24/12. Regresszióanalízis. Legkisebb négyzetek elve. Regresszióanalízis
 1. feladat Regresszióanalízis. Legkisebb négyzetek elve 2. feladat Az iskola egy évfolyamába tartozó diákok átlagéletkora 15,8 év, standard deviációja 0,6 év. A 625 fős évfolyamból hány diák fiatalabb
1. feladat Regresszióanalízis. Legkisebb négyzetek elve 2. feladat Az iskola egy évfolyamába tartozó diákok átlagéletkora 15,8 év, standard deviációja 0,6 év. A 625 fős évfolyamból hány diák fiatalabb
1. Házi feladat. Határidő: I. Legyen f : R R, f(x) = x 2, valamint. d : R + 0 R+ 0
 = x 2, valamint. d : R + 0 R+ 0") I. Legyen f : R R, f(x) = 1 1 + x 2, valamint 1. Házi feladat d : R + 0 R+ 0 R (x, y) f(x) f(y). 1. Igazoljuk, hogy (R + 0, d) metrikus tér. 2. Adjuk meg az x {0, 3} pontok és r {1, 2} esetén a B r (x)
I. Legyen f : R R, f(x) = 1 1 + x 2, valamint 1. Házi feladat d : R + 0 R+ 0 R (x, y) f(x) f(y). 1. Igazoljuk, hogy (R + 0, d) metrikus tér. 2. Adjuk meg az x {0, 3} pontok és r {1, 2} esetén a B r (x)
STATISZTIKA ELŐADÁS ÁTTEKINTÉSE. Matematikai statisztika. Mi a modell? Binomiális eloszlás sűrűségfüggvény. Binomiális eloszlás
 ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 9. Előadás Binomiális eloszlás Egyenletes eloszlás Háromszög eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell 2/62 Matematikai statisztika
ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 9. Előadás Binomiális eloszlás Egyenletes eloszlás Háromszög eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell 2/62 Matematikai statisztika
Kísérlettervezés alapfogalmak
 Kísérlettervezés alapfogalmak Rendszermodellezés Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and Economics Department of Measurement
Kísérlettervezés alapfogalmak Rendszermodellezés Budapest University of Technology and Economics Fault Tolerant Systems Research Group Budapest University of Technology and Economics Department of Measurement
Kísérlettervezés alapfogalmak
 Kísérlettervezés alapfogalmak Rendszermodellezés Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Kísérlettervezés Cél: a modell paraméterezése a valóság alapján
Kísérlettervezés alapfogalmak Rendszermodellezés Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Kísérlettervezés Cél: a modell paraméterezése a valóság alapján
Gépi tanulás a gyakorlatban SVM
 Gépi tanulás a gyakorlatban SVM Klasszifikáció Feladat: előre meghatározott csoportok elkülönítése egymástól Osztályokat elkülönítő felület Osztályokhoz rendelt döntési függvények Klasszifikáció Feladat:
Gépi tanulás a gyakorlatban SVM Klasszifikáció Feladat: előre meghatározott csoportok elkülönítése egymástól Osztályokat elkülönítő felület Osztályokhoz rendelt döntési függvények Klasszifikáció Feladat:
Több valószínűségi változó együttes eloszlása, korreláció
 Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Tartalomjegzék Előszó... 6 I. Valószínűségelméleti és matematikai statisztikai alapok... 8 1. A szükséges valószínűségelméleti és matematikai statisztikai alapismeretek összefoglalása... 8 1.1. Alapfogalmak...
Statisztika I. 4. előadás Mintavétel. Kóczy Á. László KGK-VMI. Minta Mintavétel Feladatok. http://uni-obuda.hu/users/koczyl/statisztika1.
 Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
KÖZELÍTŐ INFERENCIA II.
 STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
STATISZTIKAI TANULÁS AZ IDEGRENDSZERBEN KÖZELÍTŐ INFERENCIA II. MONTE CARLO MÓDSZEREK ISMÉTLÉS Egy valószínűségi modellben a következtetéseinket a látensek vagy a paraméterek fölötti poszterior írja le.
BEKE ANDRÁS, FONETIKAI OSZTÁLY BESZÉDVIZSGÁLATOK GYAKORLATI ALKALMAZÁSA
 BEKE ANDRÁS, FONETIKAI OSZTÁLY BESZÉDVIZSGÁLATOK GYAKORLATI ALKALMAZÁSA BESZÉDTUDOMÁNY Az emberi kommunikáció egyik leggyakrabban használt eszköze a nyelv. A nyelv hangzó változta, a beszéd a nyelvi kommunikáció
BEKE ANDRÁS, FONETIKAI OSZTÁLY BESZÉDVIZSGÁLATOK GYAKORLATI ALKALMAZÁSA BESZÉDTUDOMÁNY Az emberi kommunikáció egyik leggyakrabban használt eszköze a nyelv. A nyelv hangzó változta, a beszéd a nyelvi kommunikáció
Gépi tanulás a gyakorlatban. Bevezetés
 Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
A mérések általános és alapvető metrológiai fogalmai és definíciói. Mérések, mérési eredmények, mérési bizonytalanság. mérés. mérési elv
 Mérések, mérési eredmények, mérési bizonytalanság A mérések általános és alapvető metrológiai fogalmai és definíciói mérés Műveletek összessége, amelyek célja egy mennyiség értékének meghatározása. mérési
Mérések, mérési eredmények, mérési bizonytalanság A mérések általános és alapvető metrológiai fogalmai és definíciói mérés Műveletek összessége, amelyek célja egy mennyiség értékének meghatározása. mérési
Modellkiválasztás és struktúrák tanulása
 Modellkiválasztás és struktúrák tanulása Szervezőelvek keresése Az unsupervised learning egyik fő célja Optimális reprezentációk Magyarázatok Predikciók Az emberi tanulás alapja Általános strukturális
Modellkiválasztás és struktúrák tanulása Szervezőelvek keresése Az unsupervised learning egyik fő célja Optimális reprezentációk Magyarázatok Predikciók Az emberi tanulás alapja Általános strukturális
3. Fuzzy aritmetika. Gépi intelligencia I. Fodor János NIMGI1MIEM BMF NIK IMRI
 3. Fuzzy aritmetika Gépi intelligencia I. Fodor János BMF NIK IMRI NIMGI1MIEM Tartalomjegyzék I 1 Intervallum-aritmetika 2 Fuzzy intervallumok és fuzzy számok Fuzzy intervallumok LR fuzzy intervallumok
3. Fuzzy aritmetika Gépi intelligencia I. Fodor János BMF NIK IMRI NIMGI1MIEM Tartalomjegyzék I 1 Intervallum-aritmetika 2 Fuzzy intervallumok és fuzzy számok Fuzzy intervallumok LR fuzzy intervallumok
A szimplex algoritmus
 A szimplex algoritmus Ismétlés: reprezentációs tétel, az optimális megoldás és az extrém pontok kapcsolata Alapfogalmak: bázisok, bázismegoldások, megengedett bázismegoldások, degenerált bázismegoldás
A szimplex algoritmus Ismétlés: reprezentációs tétel, az optimális megoldás és az extrém pontok kapcsolata Alapfogalmak: bázisok, bázismegoldások, megengedett bázismegoldások, degenerált bázismegoldás
Hipotéziselmélet - paraméteres próbák. eloszlások. Matematikai statisztika Gazdaságinformatikus MSc szeptember 10. 1/58
 u- t- Matematikai statisztika Gazdaságinformatikus MSc 2. előadás 2018. szeptember 10. 1/58 u- t- 2/58 eloszlás eloszlás m várható értékkel, σ szórással N(m, σ) Sűrűségfüggvénye: f (x) = 1 e (x m)2 2σ
u- t- Matematikai statisztika Gazdaságinformatikus MSc 2. előadás 2018. szeptember 10. 1/58 u- t- 2/58 eloszlás eloszlás m várható értékkel, σ szórással N(m, σ) Sűrűségfüggvénye: f (x) = 1 e (x m)2 2σ
Numerikus integrálás
 Közelítő és szimbolikus számítások 11. gyakorlat Numerikus integrálás Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor Vinkó Tamás London András Deák Gábor jegyzetei alapján 1. Határozatlan integrál
Közelítő és szimbolikus számítások 11. gyakorlat Numerikus integrálás Készítette: Gelle Kitti Csendes Tibor Somogyi Viktor Vinkó Tamás London András Deák Gábor jegyzetei alapján 1. Határozatlan integrál
Intelligens Rendszerek Gyakorlata. Neurális hálózatok I.
 : Intelligens Rendszerek Gyakorlata Neurális hálózatok I. dr. Kutor László http://mobil.nik.bmf.hu/tantargyak/ir2.html IRG 3/1 Trend osztályozás Pnndemo.exe IRG 3/2 Hangulat azonosítás Happy.exe IRG 3/3
: Intelligens Rendszerek Gyakorlata Neurális hálózatok I. dr. Kutor László http://mobil.nik.bmf.hu/tantargyak/ir2.html IRG 3/1 Trend osztályozás Pnndemo.exe IRG 3/2 Hangulat azonosítás Happy.exe IRG 3/3
Biometria az orvosi gyakorlatban. Korrelációszámítás, regresszió
 SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
SZDT-08 p. 1/31 Biometria az orvosi gyakorlatban Korrelációszámítás, regresszió Werner Ágnes Villamosmérnöki és Információs Rendszerek Tanszék e-mail: werner.agnes@virt.uni-pannon.hu Korrelációszámítás
Teljesen elosztott adatbányászat pletyka algoritmusokkal. Jelasity Márk Ormándi Róbert, Hegedűs István
 Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Teljesen elosztott adatbányászat pletyka algoritmusokkal Jelasity Márk Ormándi Róbert, Hegedűs István Motiváció Nagyméretű hálózatos elosztott alkalmazások az Interneten egyre fontosabbak Fájlcserélő rendszerek
Feladatok a Gazdasági matematika II. tárgy gyakorlataihoz
 Debreceni Egyetem Közgazdaságtudományi Kar Feladatok a Gazdasági matematika II tárgy gyakorlataihoz a megoldásra ajánlott feladatokat jelöli e feladatokat a félév végére megoldottnak tekintjük a nehezebb
Debreceni Egyetem Közgazdaságtudományi Kar Feladatok a Gazdasági matematika II tárgy gyakorlataihoz a megoldásra ajánlott feladatokat jelöli e feladatokat a félév végére megoldottnak tekintjük a nehezebb
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017.
 Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Adatbányászati, data science tevékenység projektmenedzsmentje
 Adatbányászati, data science tevékenység projektmenedzsmentje IPE képzés II. félév Körmendi György, Hans Zoltán Clementine Consulting 2018.03.08. L Bemelegítés Adatbányászat célja Szegmentálás Leíró modellek
Adatbányászati, data science tevékenység projektmenedzsmentje IPE képzés II. félév Körmendi György, Hans Zoltán Clementine Consulting 2018.03.08. L Bemelegítés Adatbányászat célja Szegmentálás Leíró modellek
Statisztika Elıadások letölthetık a címrıl
 Statisztika Elıadások letölthetık a http://www.cs.elte.hu/~arato/stat*.pdf címrıl Konfidencia intervallum Def.: 1-α megbízhatóságú konfidencia intervallum: Olyan intervallum, mely legalább 1-α valószínőséggel
Statisztika Elıadások letölthetık a http://www.cs.elte.hu/~arato/stat*.pdf címrıl Konfidencia intervallum Def.: 1-α megbízhatóságú konfidencia intervallum: Olyan intervallum, mely legalább 1-α valószínőséggel
Matematika III előadás
 Matematika III. - 3. előadás Vinczéné Varga Adrienn Debreceni Egyetem Műszaki Kar, Műszaki Alaptárgyi Tanszék Előadáskövető fóliák Vinczéné Varga Adrienn (DE-MK) Matematika III. 2016/2017/I 1 / 19 Skalármezők
Matematika III. - 3. előadás Vinczéné Varga Adrienn Debreceni Egyetem Műszaki Kar, Műszaki Alaptárgyi Tanszék Előadáskövető fóliák Vinczéné Varga Adrienn (DE-MK) Matematika III. 2016/2017/I 1 / 19 Skalármezők
y ij = µ + α i + e ij STATISZTIKA Sir Ronald Aylmer Fisher Példa Elmélet A variancia-analízis alkalmazásának feltételei Lineáris modell
 Példa STATISZTIKA Egy gazdálkodó k kukorica hibrid termesztése között választhat. Jelöljük a fajtákat A, B, C, D-vel. Döntsük el, hogy a hibridek termesztése esetén azonos terméseredményre számíthatunk-e.
Példa STATISZTIKA Egy gazdálkodó k kukorica hibrid termesztése között választhat. Jelöljük a fajtákat A, B, C, D-vel. Döntsük el, hogy a hibridek termesztése esetén azonos terméseredményre számíthatunk-e.
Készítette: Fegyverneki Sándor
 VALÓSZÍNŰSÉGSZÁMÍTÁS Összefoglaló segédlet Készítette: Fegyverneki Sándor Miskolci Egyetem, 2001. i JELÖLÉSEK: N a természetes számok halmaza (pozitív egészek) R a valós számok halmaza R 2 {(x, y) x, y
VALÓSZÍNŰSÉGSZÁMÍTÁS Összefoglaló segédlet Készítette: Fegyverneki Sándor Miskolci Egyetem, 2001. i JELÖLÉSEK: N a természetes számok halmaza (pozitív egészek) R a valós számok halmaza R 2 {(x, y) x, y
Konvex optimalizálás feladatok
 (1. gyakorlat, 2014. szeptember 16.) 1. Feladat. Mutassuk meg, hogy az f : R R, f(x) := x 2 függvény konvex (a másodrend derivált segítségével, illetve deníció szerint is)! 2. Feladat. Mutassuk meg, hogy
(1. gyakorlat, 2014. szeptember 16.) 1. Feladat. Mutassuk meg, hogy az f : R R, f(x) := x 2 függvény konvex (a másodrend derivált segítségével, illetve deníció szerint is)! 2. Feladat. Mutassuk meg, hogy
Bevezetés a hipotézisvizsgálatokba
 Bevezetés a hipotézisvizsgálatokba Nullhipotézis: pl. az átlag egy adott µ becslése : M ( x -µ ) = 0 Alternatív hipotézis: : M ( x -µ ) 0 Szignifikancia: - teljes bizonyosság csak teljes enumerációra -
Bevezetés a hipotézisvizsgálatokba Nullhipotézis: pl. az átlag egy adott µ becslése : M ( x -µ ) = 0 Alternatív hipotézis: : M ( x -µ ) 0 Szignifikancia: - teljes bizonyosság csak teljes enumerációra -
Biostatisztika VIII. Mátyus László. 19 October
 Biostatisztika VIII Mátyus László 19 October 2010 1 Ha σ nem ismert A gyakorlatban ritkán ismerjük σ-t. Ha kiszámítjuk s-t a minta alapján, akkor becsülhetjük σ-t. Ez további bizonytalanságot okoz a becslésben.
Biostatisztika VIII Mátyus László 19 October 2010 1 Ha σ nem ismert A gyakorlatban ritkán ismerjük σ-t. Ha kiszámítjuk s-t a minta alapján, akkor becsülhetjük σ-t. Ez további bizonytalanságot okoz a becslésben.
Teljesen elosztott adatbányászat alprojekt
 Teljesen elosztott adatbányászat alprojekt Hegedűs István, Ormándi Róbert, Jelasity Márk Big Data jelenség Big Data jelenség Exponenciális növekedés a(z): okos eszközök használatában, és a szenzor- és
Teljesen elosztott adatbányászat alprojekt Hegedűs István, Ormándi Róbert, Jelasity Márk Big Data jelenség Big Data jelenség Exponenciális növekedés a(z): okos eszközök használatában, és a szenzor- és