Beszédadatbázisok a gépi beszédfelismerés segítésére
|
|
|
- Vince Török
- 8 évvel ezelőtt
- Látták:
Átírás
1 Beszédadatbázisok a gépi beszédfelismerés segítésére Vicsi Klára 1 Adatbázisok jelentősége A gépi beszéd és beszélő felismerési eljárások lényegében két jól elkülöníthető elméleti alapra épülnek. Az egyik a szabálybázisú megközelítés (kognitív módszer), a másik a statisztikai elméleti alapú feldolgozás (információelméleti megközelítés). --Szabálybázis alapon működnek pl. a különböző szakértői rendszerek. --Statisztikai alapú feldolgozást használnak a Rejtett Markov Model ( Hidden Markov Model: HMM ), vagy Neurális hálózatok (Neural Network NN) használatával megvalósuló felismerők. A mai beszédfeldolgozási tudásszinten a gyakorlatban megvalósuló sikeres beszélő és beszédfelismerő rendszerek statisztikai alapokon működnek. A beszéd természetére jellemző a fizikai paraméterek nagymértékű variáltsága beszélők között, egy beszélőn belül, továbbá az akusztikai környezet függvényében is. A beszéd statisztikai modelljének paraméterfelülete a beszéd nagyfokú variálhatóságát kell, hogy tükrözze, így sok dimenziójú kell legyen. Egy pontos paraméterbecslési lépés végrehajtásához (betanítási lépés) nagyszámú minta alapján történő betanítás szükséges. E minták gyűjteményei - a szükséges jegyzetekkel, címkézésekkel és átírásokkal ellátva képezik az adatbázist. Az adatbázisoknak tartalmazni kell azokat a megfigyeléseket, amelyek a paraméterbecsléshez szükségesek, tehát mindazokat a mintákat, amelyek egységesen lefedik a beszéd (és a környezeti zajok) variáltságát. Pl. ha egy beszédhang nincs benne a betanításhoz használt adatbázisban, akkor azt a beszédhangot soha nem fogja a gép felismerni. A mai felismerőket csak egy meghatározott szűk felhasználási területre tudják tervezni. Pl. beszédfelismerő, amely csak egy adott nyelven, telefonon keresztül bemondott számok, szavak felismerésére alkalmas, nem ismer fel mondatokat. Az un. diktáló rendszerek folyamatos beszédet képesek felismerni megadott nyelven, jól meghatározott témakörön belül, de kizárólag csak a felhasználó hangjára működnek elfogadható pontossággal. Ezek a felismerők csak csendes környezetben működnek jól. Azok a felismerők, amelyeket zajtalan környezetbe terveztek, nem működnek zajos körülmények között. Az utcazajban működő felismerő rosszul működik, ha személygépkocsiban kívánják használni. Vagyis csak azokat a mintákat képes felismerni, amelyeket előzőleg már megtapasztalt, vagyis amelyre előzőleg be lett tanítva. Betanítás viszont adatbázisok segítségével hajtandó végre. Ezért nőtt meg az utóbbi években a jelentőségük. Óriási pénzeket költ ma a világ adatbázisokra. A soknyelvű Európa igen nagy feladat előtt áll, hiszen minden nemzet a saját nyelvén akar bekapcsolódni a nemzetközi kommunikációba, tehát nyelvenként kell sokfajta feladatra alkalmas adatbázisokat létrehozni. Nem biztos, hogy a mai statisztikai megközelítések nyújtják a legmegfelelőbb megoldást a gépi beszédfelismerésre, de hogy igen költségesek, az bizonyos.
, vagy Neurális hálózatok (Neural Network NN) használatával megvalósuló felismerők.")
2 2 Megjegyzések a statisztikai feldolgozáshoz A statisztikai felismerő rendszerben egy véletlen folyamat (X) előállít egy diszkrét idejű véletlen jelet (X (n) ), ahol n a diszkrét időindex. Meg kell becsülni azokat a paramétereket, amelyek a modellt jellemzik. A becslés pontossága arányos a rendelkezésre álló megvalósulások számával. Ha minden lehetséges realizáció rendelkezésünkre állna, akkor ismernénk az X véletlen folyamat együttes felületét. Ebben az esetben a modell teljesen pontos valódi paramétereit becsüljük meg. Megjegyzendő azonban, hogy nincs értelme ugyanazon folyamat realizációit hosszú ideig gyűjteni. Lényegében haszontalan ugyanazon beszélő hangjának többszöri rögzítése, vagy több felvétel készítése, mint amennyi az együttes felület lefedéséhez szükséges. Pl. kísérleti tény ma már, hogy 100 megfelelően kiválasztott beszélő elégséges és hatékony a beszélőfüggés betanításhoz. Tovább növelni számukat haszontalan, sőt néha káros!! A gyakorlatban az adatbázisok tervezésénél figyelembe kell venni, hogy az adatbázis létrehozása nem más, mint a véletlenszerű folyamat egyes megvalósulásainak (realizációinak) összegyűjtése. Bármelyik megvalósulás statisztikai tulajdonságai egybe esnek a folyamat sokfajta megvalósulásának együttes tulajdonságaival, egy adott időpillanatban (n). Vegyük a beszédfolyamat együttes felületét {x(n, l)}, ahol l jelenti a járulékos függéseket speciális dimenziókon, mint pl. beszédnél a kiejtés beszélőtől való függését. Itt n az időfüggést, l index pedig a beszédfolyamat járulékos függéseit jelenti ezektől a speciális dimenzióktól. Ilyen speciális dimenzióra vonatkozó index például az amelyiket a beszélők kiejtésének azonosítására használunk. Az X beszédfolyamat együttes felületét befedő adatbázis létrehozása megkívánja ezeknek a különböző megvalósulásoknak az összegyűjtését (x(n, l)), minden l járulékos függés esetében. Ez szükséges a megfelelően pontos becslés kialakításához. A fentiek alapján látható, hogy a paraméter becslés pontossága, tehát a felismerés jósága lényegében a betanításhoz használt adatbázis jóságán múlik. Vagyis azon, hogy az adatbázis elemei helyesen legyenek kiválasztva, egy-egy elemből megfelelő darabszámú reprezentáns legyen, az elemek minősége megfeleljen az előírásoknak stb. Mind a HMM mind az NN alapú felismerés stacionárius folyamatok sorozataként tekinti a beszédet. Viszont a beszédképző szervünk folyamatosan állítja elő a beszédet, a statisztikai tulajdonságok időfüggők. A beszéd modellezhető, mint részeiben stacionárius folyamatok láncolata és HMM nagyon jól alkalmazható ilyen folyamatokra. Ez viszont megkívánja az adatbázis szegmentálását olyan hullámforma részekre, amelyeknek hasonlók a statisztikai tulajdonságaik. A HMM és NN felismerési algoritmusok az adatbázis pontos fonetikai átírását igénylik. A HMM felismerők a betanításhoz igénylik a beszédfolyam szegmentálását, és a már működő HMM felismerők szegmentálásra is használhatók. 3 A beszéd variáltsága A beszéd paraméterek számos hatás következtében megváltoznak, variáltságuknak számos forrása van, amelyek a felismerést megnehezítik. Ezek a források lehetnek pl. a hangképző szervek biológiai tulajdonságai, például személyenként változnak a hangképző szervek méretei, így azt általuk létrehozott fizikai produktum is változik. A hangképzés folyamatosan változó mozgások összessége, amelyet a felismerésnél kvantálva használunk. A folyamatos hangképzőszervi mozgások miatt egyik hang fizikai tulajdonságai Vicsi/Oktatás/Beszédadatbázis.doc 2

3 befolyásolják az azt megelőző és követő hangok fizikai tulajdonságait. Ezt nevezik koartikulációs hatásnak. A fizikai paraméterek variáltságát okozhatják a környezeti, akusztikai körülmények. Ilyenek pl. a zajos, zajtalan környezet, visszhangok, termek, telefonbeszéd stb. A variáltságot okozó tényezők számos módon csoportosíthatók, mégis talán a beszélőkön belüli, és a beszélők közötti variáltság szerinti csoportosítás illik a legjobban a felismerők működési tulajdonságaihoz. 3.1 Beszélőn belüli variálhatóság Beszélőn belüli variáltság okai: a coarticuláció, a ritmus, hangerő, hangmagasság, hanglejtés, nyomatékbeli különbségek. Megfázás igen nagymértékben megváltoztatja a hangok akusztikai paramétereit. Környezeti hatások, izgalom, meglepetés stb. szintén erősen befolyásolják a létrehozott beszéd akusztikai tulajdonságait. 1. Táblázat: Beszédfelismerő tervezésének lényeges szempontjai a beszéd paraméterek variáltságát okozó tényezők csoportosításával környezet zaj típusa jel/zaj viszony használati körülmények átalakító mikrofon telefon csatorna beszélők beszédstílus szótár sávamplitudó torzítás visszhang beszélőfüggőség/függetlenség beszélő neme kor fizikai és pszichikai állapot hangszín: meleg, normál, kiabálás beszédegység, izolált szavak, folyamatos beszéd, spontán beszéd beszédsebesség: lassú, normál, gyors specifikus vagy általános az elérhető betanító anyag jellemzése Vicsi/Oktatás/Beszédadatbázis.doc 3

4 3.2 Beszélők közötti variáltság Biológiai tényezők pl. a beszédképző szervek méretkülönbsége, ami az akusztikai paraméterek jelentős variáltságát okozza női, férfi, gyermekhangok esetében, de egy egy csoporton belül is. Környezeti hatások két csoportban: a statikus (teremakusztikai hatások, utózengési idő, rögzítő berendezések, stb.) és dinamikus (zaj, mikrofon pozíció stb.) hatások szintén erősen befolyásolják a beszéd akusztikai paramétereit. Nyelvi különbözőségek szintén forrásai a beszéd variáltságának. 3.3 Beszédfelismerők, betanításához szükséges adatbázisok osztályozása a beszéd variáltsága függvényében Beszéd variáltságot okozó tényezők hatással vannak a felismerőt megvalósítandó módszerre. Tervezéskor eszerint tudni kell, hogy milyen típusú felismerőt kell létrehozni, és a variáltságot okozó tényezőket rögzíteni kell (1. Táblázat) a következők szerint: beszélőfüggőség: függő, független beszélőadaptáció beszédegység: szó, folyamatos felismerés, kapcsolt szavak beszédtempó: lassú, normál, gyors extra, nem nyelvi kapcsolatú hangok: nyelés, köhögés szótárméret: felismerendő elemek száma 4 Adatbázisok Az adatbázisok számítógép segítségével létrehozott,- tárolt és a szükséges magyarázó jegyzetekkel, címkézésekkel és átírásokkal ellátott beszédfelvételek gyűjteményei. Rádióból, TV-ből felvett beszéd nem adatbázis. Az adatbázis lényeges tartozéka a precízen leírt dokumentáció a rögzítés technikájáról, a beszélők számáról és típusáról, a nyelvi tartalomról, oly módon, hogy az adatbázist felhasználók egyszerűen megkapják a gyűjteményre vonatkozó szükséges információt. Nagyon sokfajta adatbázis létezik. A beszédtechnológiával foglalkozó szakemberek számára igen fontos ezeknek az adatbázisoknak az ismerete, azért hogy közülük egy meghatározott feladatra a legmegfelelőbbet tudják kiválasztani, vagy ha nincs megfelelő adatbázis, hogyan kell az adott feladathoz az optimálisat létrehozni. Az adatbázisok különböznek egymástól abban, hogy milyen felhasználási területre készültek, mekkora a bennük gyűjtött beszéd mérete, a bemondók száma, stb. Vicsi/Oktatás/Beszédadatbázis.doc 4
 hatások szintén erősen befolyásolják a beszéd akusztikai paramétereit. Nyelvi különbözőségek szintén forrásai a beszéd variáltságának. 3.")
5 Analitikus diagnosztikus adatbázis: nyelvi és fonetikai kutatások segítését szolgálja. Ilyen pl. a BABEL (EURM0, EUROM1 adatbázis). Általános adatbázis: nem specifikus, általános szótárakat tartalmaz, sokfajta felhasználásra alkalmas, mint például a SPECO (gyermek beszédadatbázis. Specifikus adatbázis: olyan beszédgyűjtemény, amely meghatározott felhasználási területen készül. Különböző felismerők betanítására alkalmas adatbázis. Ilyen például a SPEECHDAT adatbázis. Adatbázisokra jellemző, hogy milyen nyelvi egységekből épülnek fel, pl. izolált szavakból, mondatokból stb., továbbá a bemondás módja szerint lehet olvasott szöveg, spontán beszéd. 2. Táblázat: Adatbázisok felhasználási terület szerint felosztása 4.1 Adatbázisok felosztása A jelenleg elérhető adatbázisok 3 alap kategóriába sorolhatók felhasználás szerint (2. Táblázat): analitikusdiagnosztikus általános adatbázis specifikus adatbázis alap nyelvi és fonetikai kutatások segítését szolgálja nem specifikus, általános szótárakat tartalmaz; sokfajta felhasználási területre alkalmas olyan beszédgyűjtemény, amely meghatározott felhasználási területre készül 4.2 Az adatbázisok tervezése Az adatbázisok, vagy az adott feladathoz legjobban illeszkedő adatbázis kiválasztásánál az alábbi szempontokat kell figyelembe venni: a felvételek és a rögzítés pontos fizikai leírását, a felvett anyag nyelvi jellemzőit, az adatbázis méretét, a beszélők szoció-, lingvisztikai adatait, az adatbázis feldolgozási módját (3. Táblázat) A beszéd adatbázis bemondási körülményei, a rögzítés módja A felvételi körülmények pontos leírása lényeges része az adatbázisnak. Itt kell figyelembe venni: egy, vagy több mikrofon, mikrofon műszaki leírása környezet: stúdió, süketszoba, iroda stb. felvétel ellenőrzési módszer mintavételi paraméterek Példaképpen bemutatjuk a BABEL magyar beszédadatbázis felvételi körülményeit a 2. ábrán. Vicsi/Oktatás/Beszédadatbázis.doc 5

6 2. ábra BABEL süketszobai felvételek mérési összeállítása VGA IBM PC VGA B&K 2636 OROS AU21 Amplifier Amplifier 3. Táblázat: Adatbázisok jellemző adatai rögzítés fizikai leírása nyelvi jellemzők méretbeli jellemzők Mintavételi paraméterek Felvételi körülmények fizikai leírása Monitor használata Rögzített nyelv, dialektus Nyelvi alapegység: hangkapcsolatok, szavak, mondatok Bemondott anyag leírása Bemondás stílusa: olvasott, spontán beszéd, dialógus Beszélők száma Rögzített anyag időbeli hossza Nagysága CD-k száma szocio-lingvisztikai jellemzők nem, kor, beszéd stílusa adatbázis feldolgozása Címkézés Átírás Szegmentálás Spektrális elemzés Méretbeli jellemzők Beszélők száma szerint külön adatbáziscsoportok léteznek. Kevés beszélő adatbázisa pl. beszéd szintézis fejlesztés céljait szolgálja. Lényeges jellemzője a lehető legnagyobb fonetikai variáltságú anyag összegyűjtése. Az anyagban hangsúlyozottan szerepet kapnak a beszéd mikroszegmentális jellemzői. Rendszerint a bemondást szakértő végzi. Vicsi/Oktatás/Beszédadatbázis.doc 6

7 Adatbázis közepes számú beszélővel a felismerésénél használt modell paraméterek becslésére szolgál. Éppen ezért a nyelvi szöveg variáltsága nagy. Általában csendes helyiségekben történik a felvétel. Beszélők száma kisebb, mint 50. Adatbázis sok beszélővel: Ezek az adatbázisok a beszélő független felismerők betanítására szolgálnak. A beszédstílus, és a rögzítési körülmények nagy variáltsága szükséges. hanghatár bejelölés digitálisan rögzített beszéd B E T Ű K nyelvi tartalmat közvetítő karakterlánc zajok coartikulációs zörejek szünetek 3. ábra: Adatbázisok feldolgozása Szocio-lingvisztikai jellemzők Ebbe a csoportba tartoznak azok a jellemzők, amelyek főleg a bemondók leírására szolgálnak. Férfiak, nők, dohányoznak, nem dohányoznak. Anyanyelvükön történik-e a bemondás. Tájszólások vannak e rögzítve az adatbázisban. Milyen a koreloszlás a bemondók között Adatbázis nyelvi feldolgozása Beszédadatbázisoknak a beszéd digitális tárolása mellett annak nyelvi információ tartalmát is rögzíteniük kell. Ezért a hullámforma tárolása mellett a hozzátartozó ortografikus karaktereket is rögzítik. Különböző zajok, embertől származóak,- (ilyen a köhögés, nyelés, különböző szájmozgásból adódó zajok)), vagy környezetiek (járművek, motorok zaja, székcsikorgás stb.) bejelölésre kerülnek a legtöbb adatbázisban, vagy a szöveganyagban, vagy magában az időfüggvényben (3. ábra). Vicsi/Oktatás/Beszédadatbázis.doc 7

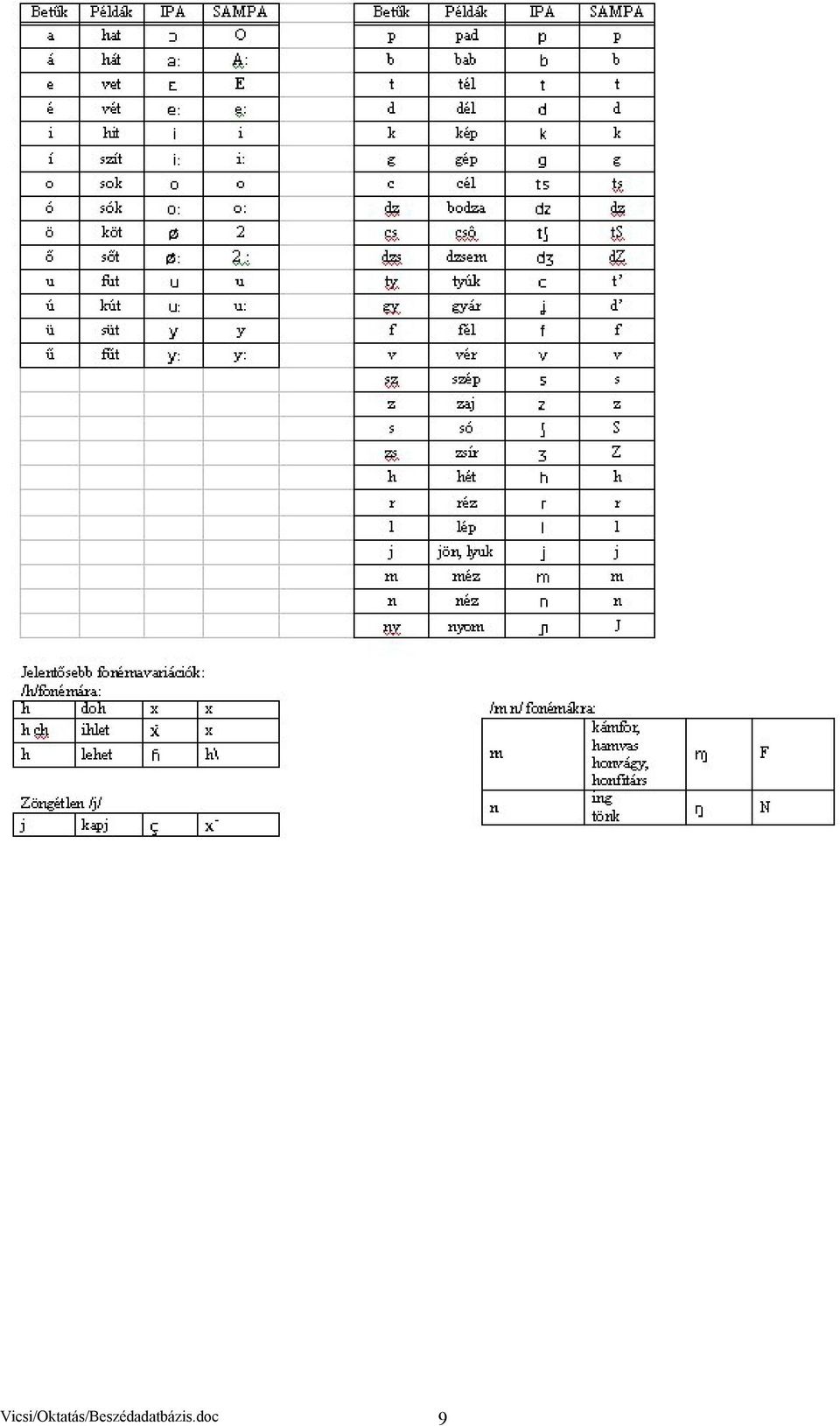
8 Akusztikai jelek fonetikai átírása Rendszerint a karaktereket hozzárendelik a rögzített hullámformához, vagyis a folyamatos beszédet pl. beszédhang egységekben kvantálják, bejelölik a beszédhangok elejét és végét, valamint beírják a beszédjelhez tartozó írásos szimbólumokat. Ezek a szimbólumok lehetnek egy adott nyelv betűi, de ha az adatbázis nemzetközi célra készül, akkor célszerű nemzetközi jelölésrendszert használni, hogy a külföldi szakemberek is pontosan tudják milyen hangok sorozatáról van szó. Ilyen nemzetközi jelölésrendszer az IPhA (International Phonetic Alphabet) a múlt században született, és szimbólum rendszere több száz nyelv hangjainak leírására alkalmas. A szimbólumok még a kézíráshoz alkalmazkodtak. A mai számítógépes billentyűzetek ilyen karakterek egyszerű bevitelére nem megfelelőek, ezért a mai használat céljára a billentyűzet karaktereiből összeállított un. SAMPA szimbólumrendszert dolgoztak ki a 90-es évek elején. Az európai adatbázisok már SAMPA karaktereket használnak. A magyar beszédhangok IPhA és SAMPA szimbólumkészletét a 4. Táblázat mutatja be. 4. Táblázat: IPhA és SAMPA magyar Vicsi/Oktatás/Beszédadatbázis.doc 8

9 Vicsi/Oktatás/Beszédadatbázis.doc 9
10 A fonetikai átírásnak számos szintje létezik: Kanonikus fonetikai átírás: Az adott szöveg karaktereinek olyan átírása, amelyben az ortografikus karaktereket fonémák sorozatára alakítjuk ki, de az adott szövegkörnyezetet nem vesszük figyelembe. Tehát a hasonulás és a koartikuláció nincs figyelembe véve. Fonotipikus fonetikai átírás: A karakterek átírását, az adott nyelv fonetikai szabályainak alapján végezzük, a szövegkörnyezet függvényében (pl. A hasonulási szabályok figyelembe vételével). Hallás alapján történő fonetikai átírás: A figyelmesen lehallgatott szöveg hallás alapján történő lejegyzése. Tehát itt, az írott szöveg figyelembe vétele nélkül, kizárólag a hallott hangok kerülnek lejegyzésre. Audio-vizuális fonetikai átírás: A fonémáknál kisebb egységek alapján történik az átírás, a közel stabil akusztikai-fonetikai részek bejelölésével. Az átírást a szöveg hallgatása, és az időfüggvény vagy a színkép elemzése alapján hajtják végre Szegmentálás Szegmentálás során a beszéd időfüggvényében bejelölik a beszédhangok, vagy egyéb fonetikai egységek határait, és beírják a megfelelő fonetikai szimbólumokat. Kézi vagy automatikus szegmentálást szokás használni. A kézi szegmentálás pontos, de fárasztó és időigényes. (4. ábra) 4. ábra SPECO gyermek beszédadatbázis kézi szegmentálása Az automatikus, vagy félautomatikus szegmentálás gépi felismerésekkel hajtható végre. Gyors eljárás, de elég pontatlan, ilyenkor kézi korrekciót kell végezni. A BME Távközlési és Telematikai Tanszékén 1998-ban kifejlesztett neurális háló alapú beszédfelismerővel végzett automatikus nyelvfüggetlen szegmentálóval készített minta az 5. ábrán látható. Vicsi/Oktatás/Beszédadatbázis.doc 10

11 5. ábra LIAS (Language Independent Automatic Segmentation Method) automatikus szegmentáló 5 Adatbázisok a gyakorlatban Beszédadatbázisokat elsősorban a gépi beszédfelismerésben használunk. Széles felhasználói terület még az automatikus beszédszintézis, kódolás, elemzés, beszédazonosítás, nyelvazonosítás. Mindezen területek nagy adatbázist igényelnek. Nemcsak betanításra használatosak, hanem tesztelésre is, hiszen segítségükkel rögzített, állandó anyaggal, tehát ismétlési lehetőséggel tudjuk végrehajtani a tesztelést. Célszerű lenne a beszédadatbázisok létrehozására egy egységes szabvány eljárást kidolgozni, de ennek komoly akadálya van. A felhasználási területek szélesek, a nyelvi sajátosságok különbözőek, a nemzeti érdekek erősek, így igen nehéz egységes szabványt kidolgozni (elfogadtatni?)mind az adatbázisok létrehozására, mind az értékelési eljárásokra. Európában az ESPRIT projekt keretében szabványos beszéd és nyelvre vonatkozó rögzítési és feldolgozási eljárásokat fogadtak el Speech Assesment Methods néven (SAM), ezek rögzítési eljárások, tárolások, annotálási technikák, adatok eloszlása. E projekt keretében hozták létre a fonémák SAMPA fonetikus szimbólumrendszerét. E szabványeljárások alapján jöttek létre az EUROM 0, EUROM 1, BABEL adatbázisok Európa legtöbb nyelvét átfogva. Csendes szobai felvételeket tartalmaznak megfelelően szerkesztett hangkapcsolatokat, szavakat, mondatokat, számokat felolvasva. A SQUALE projekt keretén belül olyan adatbázist hoztak létre a kutatók, amely a beszédfelismerők értékelésére használható. Vicsi/Oktatás/Beszédadatbázis.doc 11

12 A SPEECHDAT 1,2 és a SPEECHDAT-E adatbázisok vezetékes és mobil telefonon keresztül rögzített beszédet tartalmaznak. Ma már se szeri se száma a különböző adatbázisoknak. Néhány jellemző adatbázis adatait a 5. és 6. Táblázatban mutatjuk be. Európában az ERLA (European Resources of Language and Speech) társaság forgalmazza a legtöbb európai adatbázist, rendszeres kiadványokban tájékoztatva a szakembereket az újonnan megjelent beszéd és nyelvadatbázisokról. 5. Táblázat: Adatbázisok minőségi jellemzői Adatbázis neve Forrás Formátum khz Rögzítési környezet Bemondás módja Feldolgozás alapegység átírás TI Digits mikrofon 20 csendes szoba felolvasás szó nem TIMIT mikrofon 16 csendes szoba felolvasás beszédhang igen NTIMIT telefon 8 ATISO mikrofon 16 hivatal Switchboard (Credit Card) Switchboard (Credit Card) telefon 8 telefon 8 telefonon keresztül telefonfülke, iroda, lakás, utca stb. telefonon keresztül telefonfülke, iroda, lakás, utca stb. telefonon keresztül telefonfülke, iroda, lakás, utca stb. felolvasás beszédhang igen spontán felolvasás spontán beszéd spontán beszéd mondat MARSEC mikrofon 16 változó spontán beszédhang igen ATIS2 mikrofon 16 hivatal spontán mondat nem szó szó nem igen igen EUROM-1 BABEL SpeechDat SpeechDat-E mikrofon 20 csendes helyiség olvasott telefon 8 vezetékes telefon, mobil telefonfülke, iroda, lakás, utca stb. olvasott, spontán beszédhang szó beszédhang szó igen nem Vicsi/Oktatás/Beszédadatbázis.doc 12

13 6. Táblázat: Adatbázisok mennyiségi jellemzői Adatbázis neve CD száma Felvételi idő Méret gigabájt Beszélők száma Egységek száma TI Digits 3 ~ TIMIT 1 5,3 0, NTIMIT 2 5,3 0, ATISO 6 20,2 2,38 69 Switchboard (Credit Card) Switchboard (Credit Card) 1 3,8 0, MARSEC 1 5,5 0, ATIS2 6 ~37 ~5 >124 EUROM-1 BABEL SpeechDat SpeechDat-E 3-5 nyelvfüggő nyelvfüggő nyelvfüggő nyelvfüggő 1,5-4 nyelvfüggő >2 500 szám mondat mondat kiejtés 35 dialógus dialógus 53 mondat kiejtés számok, fonetikailag kiegyensúlyozott mondatok, hangkapcsolatok, szavak számok, nevek, intézmények, utasítások, fonetikailag gazdag mondatok Vicsi/Oktatás/Beszédadatbázis.doc 13

14 Amerikában a TIMIT és az ATIS a legjelentősebb - gépi beszédfelismerés céljára létrehozott - adatbázis, amelyek amerikai angol nyelven akusztikai modellek felépítésére alkalmasak. A TIMIT adatbázis személyfüggetlen fonetikai beszédfelismerők betanítására és tesztelésére szolgál. Szómodellek felépítésére alkalmatlan, mivel szűkített szótárkészletet használ, fonetikailag gazdag mondatai viszont kiválóan alkalmasak beszédhang modellek létrehozására. Az adatbázis egy része betanításra, másik része tesztelésre ad lehetőséget. ATIS (Air Travel Information System) repülőtéri információval kapcsolatos szótárkészleten alapuló adatbázis. Minden elem rögzítésre került, spontán társalgással, és olvasva hivatali körülmények között. 6 Magyar nyelvű adatbázisok Ezideig 3 egymástól igen különböző magyar beszédadatbázis készült el, amelyek összefoglaló adatai a 7. Táblázatban láthatóak. 7. Táblázat Magyar beszédadatbázisok összefoglaló adatai BABEL SpeechDat-E SPECO gyermek adatbázis forrás mikrofon telefon mikrofon formátum 20 khz, 16 bit 8 khz, 16 bit (ISDN) Hz, 16 bit rögzítési környezet bemondás módja szövegtípus süketszoba (tiszta beszéd) olvasott szöveg hangkapcsolatok számok, szavak folyamatos szöveg iroda, lakás, utca, telefonfülke stb. 80% olvasott, 20% spontán szöveg betűzött szavak dátumok, pénzösszegek számok, telefon- és hitelkártyaszámok szavak, tulajdonnevek, mondatok bemondók száma feldolgozás fonotipikus átírás fonémaszintű szegmentálás karakteres leírás nincs szegmentálás zajok, hibák jelölése süketszoba olvasott, utánzott szöveg kitartott beszédhangok hangkapcsolatok számok, szavak mondatok fonotipikus átírás fonémaszintű szegmentálás Vicsi/Oktatás/Beszédadatbázis.doc 14
 repülőtéri információval kapcsolatos szótárkészleten alapuló adatbázis.")
15 6.1 BABEL magyar nyelvű adatbázis Az első magyar beszédadatbázis egy többnyelvű kelet-európai beszédadatbázist létrehozó munkaprogram keretében készült el 1995 és 1998 között. A munkaprogram összefoglaló neve BABEL. Célja egy közös, egységes elvek alapján felépített nagyméretű beszédadatbázis létrehozása a beszédakusztikával, fonetikával, digitális jelfeldolgozással, valamint nyelvészettel foglalkozó európai szakemberek munkájának segítésére. A BABEL program keretén belül 5 közép-és kelet-európai nyelv beszédadatbázisa készült el, ezek a nyelvek: bolgár, észt, magyar, lengyel és román. A magyar BABEL adatbázis a hivatalos magyar köznyelvet reprezentáló rendezett hanganyag, amely hangkapcsolatokat, szavakat, számokat, 5 mondatos bekezdéseket tartalmaz, valamint 120 bekezdés fonetikai szinten címkézett és szegmentált anyagát. Az adatbázis erősen zajcsökkentett környezetben felvett olvasott szöveg, ez az ún. tiszta olvasott beszéd, melyet 60 személlyel, 30 férfivel és 30 nővel rögzítettünk kor és foglalkozás szerint széles eloszlásban. A teljes hanganyag 1,8 GB terjedelmű, amelyet 3 CD-n rögzítettünk. Az adatbázis összetétele Az adatbázis összetétele és formája az ESPRIT programban kialakított SAM szabályokat követi. Az adatbázis szövegkészlete 3 részből áll: - rövid bekezdések, amelyek egyenként 5 tematikailag összefüggő mondatot tartalmaznak; - kiválasztott számok ig; - szisztematikusan megszerkesztett CVC hangkapcsolatok különállóan és mondatba szer kesztve. 40 különböző bekezdés folyamatosan olvasott mondatokból áll, amelyből az első rész, a 30 speciálisan megszerkesztett bekezdés, eltér az EUROM1 szabvány-előírásaitól. A szabványelőírás alapján létrehozott szöveg hangzó és szótag statisztikáját megvizsgálva, az anyag igen szegényesnek bizonyult, ugyanis nem írja le a magyar fonéma-kapcsolódások teljes készletét. Ezért e 30 bekezdést a szabványtól eltérő módon szerkesztettük meg. A magyar nyelv részletes statisztikai elemzése alapján már korábban azt találtuk, hogy a félszótag egység írja le a legtömörebben a magyar nyelv fonológiai szerkezetét. Egy általános magyar szöveg 98%-a leírható 491 félszótaggal, 99%-a pedig 600 félszótaggal. Ez annyit jelent, hogy ha a félszótag eloszlásnak megfelelő szöveget szerkesztünk meg, akkor fedjük le legtömörebben a magyar nyelv hangkapcsolat-variációit. A beszélők kiválasztása A jelen adatbázis, a magyar köznyelvet reprezentálja, tehát a különböző dialektusok nincsenek benne képviselve, de a magyar köznyelvi beszéd olyan széles variációit rögzítettük, amely az adott körülmények között lehetséges volt. Az olvasásnál az egyetlen kritérium az volt, hogy pontosan azt kell felolvasni, ami le van írva. Budapesten élő és dolgozó férfiak és nők voltak a beszélők, éves kor között. A 60 beszélő kor szerinti megoszlását a 8. Táblázat mutatja be. Vicsi/Oktatás/Beszédadatbázis.doc 15

16 8. Táblázat: A beszélők nem és kor szerinti eloszlása (3 női tartalék beszélővel) Életkor Beszélők száma (férfiak) Beszélők száma (nők) Szegmentálás és címkézés Az anyagban összesen 120 paragrafus került fonetikai szintű szegmentálásra és címkézésre. Kézi szegmentálással, a beszéd időfüggvényében, bejelöltük a fizikailag megfigyelhető fonémák határait és beírtuk a megfelelő helyre a fonéma címkéket, audio-vizuális fonetikai átírással. A fonetikai átírás a SAMPA készlet segítségével készült. A BABEL adatbázis viszonylag kis számú bemondóval készült, viszont az összeállított szöveg viszonylag hosszú. Létrehozásánál az volt a cél, hogy jó alapanyagot teremtsen fonetikai kutatásokhoz: a hangkörnyezetnek, a hang helyzetének, a különböző szupraszegmentális jegyeknek stb. a hatása jól vizsgálható legyen. A speciális paragrafusszöveg miatt az alapfonetikai kutatások mellett a hanganyag a beszédfelismerési kutatásoknak is alapot tud biztosítani. A felvételek a Békésy György Akusztikai Kutatólaboratórium süketszobájában készültek. 6.2 SpeechDat-E telefonbeszéd adatbázis Az adatbázis 1000 beszélő által telefonon bemondott szövegből áll. Számos különböző típusú, telefonon keresztül működő beszédfelismerő betanítására és tesztelésére ad lehetőséget. Ezek az izolált szavas rendszerek, szókereső és azonosító rendszerek, dialógus rendszerek, valamint szótárfüggetlen rendszerek, amelyeknél a felismerés szónál kisebb felismerési egységek modellezésén alapul. Az összeállított szöveganyag a sokfeladatos elvárásoknak megfelelően igen sokrétű. Tartalmaz: parancsszavakat, számjegysorozatokat, telefonszámot hitelkártyaszámot, PIN kódot, spontán dátumot, relatív dátumot, parancsszavas kifejezést, számjegyet, betűzött spontán vezetéknevet, betűzött városnevet, betűzött szót, pénzmennyiséget (forint/euro), természetes számot, spontán vezetéknevet, spontán városnevet, cégnevet, vezeték+keresztnevet, igen/nem kérdést igen/nem válasszal, fonetikailag gazdag mondatot. A telefon-beszédadatbázis specifikációja az MLAP LRE SPEECHDAT (M) EU projekt javaslata alapján készült. Ez biztosítja azt, hogy a különböző nyelvű adatbázisok igen hasonlóak, egységes alapot képviselve ugyanazt a beszédtechnológia fejlesztési lehetőséget nyújtsák a feldolgozott nyelvhez. Az adatbázis a BME Távközlési és Telematikai Tanszékén készült. Vicsi/Oktatás/Beszédadatbázis.doc 16

17 6.3 SPECO gyermekbeszéd adatbázis Az adatbázis csendes helyiségben 5-10 éves gyermekek által bemondott szótagokat, szavakat, mondatokat tartalmaz. A fonetikai, beszédfelismerési kutatásokhoz (hangkörnyezet, hanghelyzet, különböző szupraszegmentális jegyek stb. vizsgálata) biztosít megfelelő hanganyagot Az adatbázis nagy részében átlagos köznyelvi olvasott gyermekbeszéd van rögzítve csendes korülmények között. Kisebb részben pösze, és különböző súlyosságú hallássérült gyermekek beszédjét tartalmazza Az adatbázis a BME Távközlési és Telematikai Tanszékén készült. Vicsi/Oktatás/Beszédadatbázis.doc 17

Beszédadatbázis irodai számítógép-felhasználói környezetben
 Beszédadatbázis irodai számítógép-felhasználói környezetben Vicsi Klára*, Kocsor András**, Teleki Csaba*, Tóth László** *BME Távközlési és Médiainformatikai Tanszék, Beszédakusztikai Laboratórium **MTA
Beszédadatbázis irodai számítógép-felhasználói környezetben Vicsi Klára*, Kocsor András**, Teleki Csaba*, Tóth László** *BME Távközlési és Médiainformatikai Tanszék, Beszédakusztikai Laboratórium **MTA
BEKE ANDRÁS, FONETIKAI OSZTÁLY BESZÉDVIZSGÁLATOK GYAKORLATI ALKALMAZÁSA
 BEKE ANDRÁS, FONETIKAI OSZTÁLY BESZÉDVIZSGÁLATOK GYAKORLATI ALKALMAZÁSA BESZÉDTUDOMÁNY Az emberi kommunikáció egyik leggyakrabban használt eszköze a nyelv. A nyelv hangzó változta, a beszéd a nyelvi kommunikáció
BEKE ANDRÁS, FONETIKAI OSZTÁLY BESZÉDVIZSGÁLATOK GYAKORLATI ALKALMAZÁSA BESZÉDTUDOMÁNY Az emberi kommunikáció egyik leggyakrabban használt eszköze a nyelv. A nyelv hangzó változta, a beszéd a nyelvi kommunikáció
MTBA Magyar nyelvű telefonbeszéd adatbázis
 Összefoglalás MTBA Magyar nyelvű telefonbeszéd adatbázis Vicsi Klára,* Tóth László,+ Kocsor András,+ Gordos Géza* és Csirik János+ * Budapesti Műszaki Egyetem Távközlési és Telematikai Tanszék +Szegedi
Összefoglalás MTBA Magyar nyelvű telefonbeszéd adatbázis Vicsi Klára,* Tóth László,+ Kocsor András,+ Gordos Géza* és Csirik János+ * Budapesti Műszaki Egyetem Távközlési és Telematikai Tanszék +Szegedi
Akusztikai mérések SztahóDávid
 Akusztikai mérések SztahóDávid sztaho@tmit.bme.hu http://alpha.tmit.bme.hu/speech http://berber.tmit.bme.hu/oktatas/gyak02.ppt Tartalom Akusztikai produktum Gerjesztés típus Vokális traktus Sugárzási ellenállás
Akusztikai mérések SztahóDávid sztaho@tmit.bme.hu http://alpha.tmit.bme.hu/speech http://berber.tmit.bme.hu/oktatas/gyak02.ppt Tartalom Akusztikai produktum Gerjesztés típus Vokális traktus Sugárzási ellenállás
A beszéd. Segédlet a Kommunikáció-akusztika tanulásához
 A beszéd Segédlet a Kommunikáció-akusztika tanulásához Bevezetés Nyelv: az emberi társadalom egyedei közötti kommunikáció az egyed gondolkodásának legfőbb eszköze Beszéd: a nyelv elsődleges megnyilvánulása
A beszéd Segédlet a Kommunikáció-akusztika tanulásához Bevezetés Nyelv: az emberi társadalom egyedei közötti kommunikáció az egyed gondolkodásának legfőbb eszköze Beszéd: a nyelv elsődleges megnyilvánulása
Beszédinformációs rendszerek 6. gyakorlat
 Beszédinformációs rendszerek 6. gyakorlat Beszédszintetizátorok a gyakorlatban és adatbázisaik könyv 8. és 10. fejezet Olaszy Gábor, Németh Géza, Zainkó Csaba olaszy,nemeth,zainko@tmit.bme.hu 2018. őszi
Beszédinformációs rendszerek 6. gyakorlat Beszédszintetizátorok a gyakorlatban és adatbázisaik könyv 8. és 10. fejezet Olaszy Gábor, Németh Géza, Zainkó Csaba olaszy,nemeth,zainko@tmit.bme.hu 2018. őszi
A HANGOK TANÁTÓL A BESZÉDTECHNOLÓGIÁIG. Gósy Mária. MTA Nyelvtudományi Intézet, Kempelen Farkas Beszédkutató Laboratórium
 A HANGOK TANÁTÓL A BESZÉDTECHNOLÓGIÁIG Gósy Mária MTA Nyelvtudományi Intézet, Kempelen Farkas Beszédkutató Laboratórium beszédzavarok beszédtechnika beszélő felismerése fonológia fonetika alkalmazott fonetika
A HANGOK TANÁTÓL A BESZÉDTECHNOLÓGIÁIG Gósy Mária MTA Nyelvtudományi Intézet, Kempelen Farkas Beszédkutató Laboratórium beszédzavarok beszédtechnika beszélő felismerése fonológia fonetika alkalmazott fonetika
Mély neuronhálók alkalmazása és optimalizálása
 magyar nyelv beszédfelismerési feladatokhoz 2015. január 10. Konzulens: Dr. Mihajlik Péter A megvalósítandó feladatok Irodalomkutatás Nyílt kutatási eszközök keresése, beszédfelismer rendszerek tervezése
magyar nyelv beszédfelismerési feladatokhoz 2015. január 10. Konzulens: Dr. Mihajlik Péter A megvalósítandó feladatok Irodalomkutatás Nyílt kutatási eszközök keresése, beszédfelismer rendszerek tervezése
Beszédinformációs rendszerek. 3. gyakorlat - Elemi jelfeldolgozás (a beszédjel feldolgozásának lépései)
") Beszédinformációs rendszerek 3. gyakorlat - Elemi jelfeldolgozás (a beszédjel feldolgozásának lépései) 1 Beszédinformációs rendszerek Kiss Gábor, Tulics Miklós Gábriel, Tündik Máté Ákos {kiss.gabor,tulics,tundik}@tmit.bme.hu
Beszédinformációs rendszerek 3. gyakorlat - Elemi jelfeldolgozás (a beszédjel feldolgozásának lépései) 1 Beszédinformációs rendszerek Kiss Gábor, Tulics Miklós Gábriel, Tündik Máté Ákos {kiss.gabor,tulics,tundik}@tmit.bme.hu
Szerkesztők és szerzők:
 Szerkesztők szerzők Áttekintő szerkesztő: Gordos Géza (1937) a beszéd mérnöke, a műszaki indíttatású beszédkutatás vezéralakja. A Budapesti Műszaki Egyetemen (BME) szerzett híradástechnikai szakos oklevelet
Szerkesztők szerzők Áttekintő szerkesztő: Gordos Géza (1937) a beszéd mérnöke, a műszaki indíttatású beszédkutatás vezéralakja. A Budapesti Műszaki Egyetemen (BME) szerzett híradástechnikai szakos oklevelet
Beszédfelismerés alapú megoldások. AITIA International Zrt. Fegyó Tibor
 Beszédfelismerés alapú megoldások AITIA International Zrt. Fegyó Tibor fegyo@aitia.hu www.aitia.hu AITIA Magyar tulajdonú vállalkozás Célunk: kutatás-fejlesztési eredményeink integrálása személyre szabott
Beszédfelismerés alapú megoldások AITIA International Zrt. Fegyó Tibor fegyo@aitia.hu www.aitia.hu AITIA Magyar tulajdonú vállalkozás Célunk: kutatás-fejlesztési eredményeink integrálása személyre szabott
Teremakusztikai méréstechnika
 Teremakusztikai méréstechnika Tantermek akusztikája Fürjes Andor Tamás 1 Tartalomjegyzék 1. A teremakusztikai mérések célja 2. Teremakusztikai paraméterek 3. Mérési módszerek 4. ISO 3382 szabvány 5. Méréstechnika
Teremakusztikai méréstechnika Tantermek akusztikája Fürjes Andor Tamás 1 Tartalomjegyzék 1. A teremakusztikai mérések célja 2. Teremakusztikai paraméterek 3. Mérési módszerek 4. ISO 3382 szabvány 5. Méréstechnika
A spontán beszéd kísérőjelenségei
 2013. április 25. A spontán beszéd kísérőjelenségei Neuberger Tilda Fonetikai Osztály A beszéd antropofonikus elmélete A beszéd biológiai alapja: azonos hangképző apparátus (Laver 1994) Elsődlegesen nem
2013. április 25. A spontán beszéd kísérőjelenségei Neuberger Tilda Fonetikai Osztály A beszéd antropofonikus elmélete A beszéd biológiai alapja: azonos hangképző apparátus (Laver 1994) Elsődlegesen nem
Intelligens Rendszerek Elmélete. Versengéses és önszervező tanulás neurális hálózatokban
 Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
A fonetik ar ol altal aban 2014. szeptember 15.
 A fonetikáról általában 2014. szeptember 15. A félévben előforduló témák: Miben más a fonetika, mint a fonológia? Artikuláció, avagy beszédprodukció. Beszédakusztika. A Praat beszédelemző szoftver használata.
A fonetikáról általában 2014. szeptember 15. A félévben előforduló témák: Miben más a fonetika, mint a fonológia? Artikuláció, avagy beszédprodukció. Beszédakusztika. A Praat beszédelemző szoftver használata.
ÉRZÉKELŐK ÉS BEAVATKOZÓK I. 3. MÉRÉSFELDOLGOZÁS
 ÉRZÉKELŐK ÉS BEAVATKOZÓK I. 3. MÉRÉSFELDOLGOZÁS Dr. Soumelidis Alexandros 2018.10.04. BME KÖZLEKEDÉSMÉRNÖKI ÉS JÁRMŰMÉRNÖKI KAR 32708-2/2017/INTFIN SZÁMÚ EMMI ÁLTAL TÁMOGATOTT TANANYAG Mérés-feldolgozás
ÉRZÉKELŐK ÉS BEAVATKOZÓK I. 3. MÉRÉSFELDOLGOZÁS Dr. Soumelidis Alexandros 2018.10.04. BME KÖZLEKEDÉSMÉRNÖKI ÉS JÁRMŰMÉRNÖKI KAR 32708-2/2017/INTFIN SZÁMÚ EMMI ÁLTAL TÁMOGATOTT TANANYAG Mérés-feldolgozás
Szintetizált beszéd természetesebbé tétele
 Csapó Tamás Gábor IV. évf. Szintetizált beszéd természetesebbé tétele Konzulensek: Dr. Németh Géza, Dr. Fék Márk Budapesti Mőszaki és Gazdaságtudományi Egyetem Távközlési és Médiainformatikai Tanszék OTDK
Csapó Tamás Gábor IV. évf. Szintetizált beszéd természetesebbé tétele Konzulensek: Dr. Németh Géza, Dr. Fék Márk Budapesti Mőszaki és Gazdaságtudományi Egyetem Távközlési és Médiainformatikai Tanszék OTDK
Mérési hibák 2006.10.04. 1
 Mérési hibák 2006.10.04. 1 Mérés jel- és rendszerelméleti modellje Mérési hibák_labor/2 Mérési hibák mérési hiba: a meghatározandó értékre a mérés során kapott eredmény és ideális értéke közötti különbség
Mérési hibák 2006.10.04. 1 Mérés jel- és rendszerelméleti modellje Mérési hibák_labor/2 Mérési hibák mérési hiba: a meghatározandó értékre a mérés során kapott eredmény és ideális értéke közötti különbség
Beszédfelismerés, beszédmegértés
 Beszédfelismerés, beszédmegértés Werner Ágnes Beszéd, ember-gép kapcsolat A beszéd az emberek közötti legtermészetesebb információátviteli forma. Az ember és a gép kapcsolatában is ez lehetne talán a legcélravezetőbb,
Beszédfelismerés, beszédmegértés Werner Ágnes Beszéd, ember-gép kapcsolat A beszéd az emberek közötti legtermészetesebb információátviteli forma. Az ember és a gép kapcsolatában is ez lehetne talán a legcélravezetőbb,
A beszédhang felfedezése. A hangok jelölése a fonetikában
 2. témat A hangtan irányai, fajai Olvasnivaló: Bolla Kálmán: A leíró hangtan vázlata. Fejezetek a magyar leíró hangtanból. Szerk. Bolla Kálmán. Bp., 1982. 13 23. A beszédhang felfedezése a hang nem természetes
2. témat A hangtan irányai, fajai Olvasnivaló: Bolla Kálmán: A leíró hangtan vázlata. Fejezetek a magyar leíró hangtanból. Szerk. Bolla Kálmán. Bp., 1982. 13 23. A beszédhang felfedezése a hang nem természetes
A hangtan irányai, fajai Olvasnivaló: Bolla Kálmán: A leíró hangtan vázlata. Fejezetek a magyar leíró hangtanból. Szerk. Bolla Kálmán. Bp., 1982.
 2. témat A hangtan irányai, fajai Olvasnivaló: Bolla Kálmán: A leíró hangtan vázlata. Fejezetek a magyar leíró hangtanból. Szerk. Bolla Kálmán. Bp., 1982. 13 23. A beszédhang felfedezése a hang nem természetes
2. témat A hangtan irányai, fajai Olvasnivaló: Bolla Kálmán: A leíró hangtan vázlata. Fejezetek a magyar leíró hangtanból. Szerk. Bolla Kálmán. Bp., 1982. 13 23. A beszédhang felfedezése a hang nem természetes
Beszédtechnológia az információs esélyegyenlőség szolgálatában
 Beszédtechnológia az információs esélyegyenlőség szolgálatában Németh Géza, Olaszy Gábor Budapesti Műszaki és Gazdaságtudományi Egyetem, Távközlési és Médiainformatikai Tanszék nemeth@tmit.bme.hu Tervezz
Beszédtechnológia az információs esélyegyenlőség szolgálatában Németh Géza, Olaszy Gábor Budapesti Műszaki és Gazdaságtudományi Egyetem, Távközlési és Médiainformatikai Tanszék nemeth@tmit.bme.hu Tervezz
book 2010/9/9 14:36 page v #5
 1 A MAGYAR BESZÉD beszédakusztika, beszédtechnológia, beszédinformációs rendszerek Szrkesztette: Németh Géza, Olaszy Gábor Áttekint! szerkeszt!: Gordos Géza Akadémiai Kiadó KIKNEK SZÓLNA A KÖNYV? A könyv
1 A MAGYAR BESZÉD beszédakusztika, beszédtechnológia, beszédinformációs rendszerek Szrkesztette: Németh Géza, Olaszy Gábor Áttekint! szerkeszt!: Gordos Géza Akadémiai Kiadó KIKNEK SZÓLNA A KÖNYV? A könyv
2006. szeptember 28. A BESZÉDPERCEPCI DPERCEPCIÓ. Fonetikai Osztály
 2006. szeptember 28. ÖNÁLLÓSULÓ FOLYAMATOK A BESZÉDPERCEPCI DPERCEPCIÓ FEJLŐDÉSÉBEN Gósy MáriaM Fonetikai Osztály AZ ANYANYELV-ELSAJ ELSAJÁTÍTÁSRÓL Fő jellemzői: univerzális, relatíve gyors, biológiai
2006. szeptember 28. ÖNÁLLÓSULÓ FOLYAMATOK A BESZÉDPERCEPCI DPERCEPCIÓ FEJLŐDÉSÉBEN Gósy MáriaM Fonetikai Osztály AZ ANYANYELV-ELSAJ ELSAJÁTÍTÁSRÓL Fő jellemzői: univerzális, relatíve gyors, biológiai
BAGME11NNF Munkavédelmi mérnökasszisztens Galla Jánosné, 2011.
 BAGME11NNF Munkavédelmi mérnökasszisztens Galla Jánosné, 2011. 1 Mérési hibák súlya és szerepe a mérési eredményben A mérési hibák csoportosítása A hiba rendűsége Mérési bizonytalanság Standard és kiterjesztett
BAGME11NNF Munkavédelmi mérnökasszisztens Galla Jánosné, 2011. 1 Mérési hibák súlya és szerepe a mérési eredményben A mérési hibák csoportosítása A hiba rendűsége Mérési bizonytalanság Standard és kiterjesztett
Akusztikai tervezés a geometriai akusztika módszereivel
 Akusztikai tervezés a geometriai akusztika módszereivel Fürjes Andor Tamás BME Híradástechnikai Tanszék Kép- és Hangtechnikai Laborcsoport, Rezgésakusztika Laboratórium 1 Tartalom A geometriai akusztika
Akusztikai tervezés a geometriai akusztika módszereivel Fürjes Andor Tamás BME Híradástechnikai Tanszék Kép- és Hangtechnikai Laborcsoport, Rezgésakusztika Laboratórium 1 Tartalom A geometriai akusztika
Beszédfelismerés. Izolált szavas, zárt szótáras beszédfelismerők A dinamikus idővetemítés
 Beszédfelismerés Izolált szavas, zárt szótáras beszédfelismerők A dinamikus idővetemítés Vázlat Zárt szótár előnyei, hátrányai Izoláltság Lehetséges távolságmértékek Dinamikus idővetemítés Emlékeztető
Beszédfelismerés Izolált szavas, zárt szótáras beszédfelismerők A dinamikus idővetemítés Vázlat Zárt szótár előnyei, hátrányai Izoláltság Lehetséges távolságmértékek Dinamikus idővetemítés Emlékeztető
S atisztika 2. előadás
 Statisztika 2. előadás 4. lépés Terepmunka vagy adatgyűjtés Kutatási módszerek osztályozása Kutatási módszer Feltáró kutatás Következtető kutatás Leíró kutatás Ok-okozati kutatás Keresztmetszeti kutatás
Statisztika 2. előadás 4. lépés Terepmunka vagy adatgyűjtés Kutatási módszerek osztályozása Kutatási módszer Feltáró kutatás Következtető kutatás Leíró kutatás Ok-okozati kutatás Keresztmetszeti kutatás
Méréselmélet MI BSc 1
 Mérés és s modellezés 2008.02.15. 1 Méréselmélet - bevezetés a mérnöki problémamegoldás menete 1. A probléma kitűzése 2. A hipotézis felállítása 3. Kísérlettervezés 4. Megfigyelések elvégzése 5. Adatok
Mérés és s modellezés 2008.02.15. 1 Méréselmélet - bevezetés a mérnöki problémamegoldás menete 1. A probléma kitűzése 2. A hipotézis felállítása 3. Kísérlettervezés 4. Megfigyelések elvégzése 5. Adatok
Információ / kommunikáció
 Információ / kommunikáció Ismeret A valóságra vagy annak valamely részére, témájára vonatkozó tapasztalatokat, általánosításokat, fogalmakat. Információ fogalmai Az információ olyan jelsorozatok által
Információ / kommunikáció Ismeret A valóságra vagy annak valamely részére, témájára vonatkozó tapasztalatokat, általánosításokat, fogalmakat. Információ fogalmai Az információ olyan jelsorozatok által
Osztályozóvizsga követelményei
 Osztályozóvizsga követelményei Képzés típusa: Tantárgy: általános iskola angol nyelv Évfolyam: 1. Vizsga típusa: írásbeli, szóbeli Követelmények, témakörök: Én és a családom: üdvözlés, köszönések napszak
Osztályozóvizsga követelményei Képzés típusa: Tantárgy: általános iskola angol nyelv Évfolyam: 1. Vizsga típusa: írásbeli, szóbeli Követelmények, témakörök: Én és a családom: üdvözlés, köszönések napszak
Tartalomjegyzék. Rövidítések jegyzéke... EMBER, NYELV, BESZÉD. 1. A beszéd és az információs társadalom... 3
 Előszó............................................................. Szerkesztők szerzők............................................... Rövidítések jegyzéke................................................
Előszó............................................................. Szerkesztők szerzők............................................... Rövidítések jegyzéke................................................
Beszédfelismerés. Benk Erika
 Beszédfelismerés Benk Erika Tartalom Történelmi áttekintő Miért nehéz a beszédfelismerés? A felismerők képességeinek csoportosítási szempontjai Jelenlegi alkalmazások Felismerési megközelítések Előfeldolgozási
Beszédfelismerés Benk Erika Tartalom Történelmi áttekintő Miért nehéz a beszédfelismerés? A felismerők képességeinek csoportosítási szempontjai Jelenlegi alkalmazások Felismerési megközelítések Előfeldolgozási
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
Beszédhiba és beszédfeldolgozás
 Beszédhiba és beszédfeldolgozás Gósy Mária MTA - ELTE Mi a beszéd? A gondolat kifejeződése, informáci ció,, verbális gesztus, artikuláci ciós s mozgássorozat, akusztikai hullámforma, mechanikus rezgés,
Beszédhiba és beszédfeldolgozás Gósy Mária MTA - ELTE Mi a beszéd? A gondolat kifejeződése, informáci ció,, verbális gesztus, artikuláci ciós s mozgássorozat, akusztikai hullámforma, mechanikus rezgés,
Beszédfeldolgozási zavarok és a tanulási nehézségek összefüggései. Gósy Mária MTA Nyelvtudományi Intézete
 Beszédfeldolgozási zavarok és a tanulási nehézségek összefüggései Gósy Mária MTA Nyelvtudományi Intézete Kutatás, alkalmazás, gyakorlat A tudományos kutatás célja: kérdések megfogalmazása és válaszok keresése
Beszédfeldolgozási zavarok és a tanulási nehézségek összefüggései Gósy Mária MTA Nyelvtudományi Intézete Kutatás, alkalmazás, gyakorlat A tudományos kutatás célja: kérdések megfogalmazása és válaszok keresése
Hibadetektáló rendszer légtechnikai berendezések számára
 Hibadetektáló rendszer légtechnikai berendezések számára Tudományos Diákköri Konferencia A feladatunk Légtechnikai berendezések Monitorozás Hibadetektálás Újrataníthatóság A megvalósítás Mozgásérzékelő
Hibadetektáló rendszer légtechnikai berendezések számára Tudományos Diákköri Konferencia A feladatunk Légtechnikai berendezések Monitorozás Hibadetektálás Újrataníthatóság A megvalósítás Mozgásérzékelő
Gépi tanulás a gyakorlatban. Bevezetés
 Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
Gépi tanulás a gyakorlatban Bevezetés Motiváció Nagyon gyakran találkozunk gépi tanuló alkalmazásokkal Spam detekció Karakter felismerés Fotó címkézés Szociális háló elemzés Piaci szegmentáció analízis
II. rész: a rendszer felülvizsgálati stratégia kidolgozását támogató funkciói. Tóth László, Lenkeyné Biró Gyöngyvér, Kuczogi László
 A kockázat alapú felülvizsgálati és karbantartási stratégia alkalmazása a MOL Rt.-nél megvalósuló Statikus Készülékek Állapot-felügyeleti Rendszerének kialakításában II. rész: a rendszer felülvizsgálati
A kockázat alapú felülvizsgálati és karbantartási stratégia alkalmazása a MOL Rt.-nél megvalósuló Statikus Készülékek Állapot-felügyeleti Rendszerének kialakításában II. rész: a rendszer felülvizsgálati
Matematikai alapok és valószínőségszámítás. Statisztikai becslés Statisztikák eloszlása
 Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
Matematikai alapok és valószínőségszámítás Statisztikai becslés Statisztikák eloszlása Mintavétel A statisztikában a cél, hogy az érdeklõdés tárgyát képezõ populáció bizonyos paramétereit a populációból
Biomatematika 2 Orvosi biometria
 Biomatematika 2 Orvosi biometria 2017.02.13. Populáció és minta jellemző adatai Hibaszámítás Valószínűség 1 Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza)
Biomatematika 2 Orvosi biometria 2017.02.13. Populáció és minta jellemző adatai Hibaszámítás Valószínűség 1 Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza)
ÉS S NYELVI REPREZENTÁCI CIÓ. MTA Nyelvtudományi Intézet
 BESZÉDK DKÉPZÉS ÉS S NYELVI REPREZENTÁCI CIÓ Gósy MáriaM MTA Nyelvtudományi Intézet A legtágabb értelmezés szerint a beszéd az a képesség, hogy érzéseinket és gondolatainkat másokkal jelek útján közöljük.
BESZÉDK DKÉPZÉS ÉS S NYELVI REPREZENTÁCI CIÓ Gósy MáriaM MTA Nyelvtudományi Intézet A legtágabb értelmezés szerint a beszéd az a képesség, hogy érzéseinket és gondolatainkat másokkal jelek útján közöljük.
Értékelési szempont. A kommunikációs cél elérése és az interakció megvalósítása 3 Szókincs, kifejezésmód 2 Nyelvtan 1 Összesen 6
 Összefoglaló táblázatok az emelt szintű vizsga értékeléséhez A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az értékelési eljárás meghatározott értékelési
Összefoglaló táblázatok az emelt szintű vizsga értékeléséhez A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az értékelési eljárás meghatározott értékelési
Angol nyelv. 5. évfolyam
 Angol nyelv 5. évfolyam Témakör 1. Család 2. Otthon 3. Étkezés 4. Idő, Időjárás 5. Öltözködés 6. Sport 7. Iskola 8. Szabadidő 9. Ünnepek, Szokások 10. Város, Bevásárlás 11. Utazás, Pihenés 12. Egészséges
Angol nyelv 5. évfolyam Témakör 1. Család 2. Otthon 3. Étkezés 4. Idő, Időjárás 5. Öltözködés 6. Sport 7. Iskola 8. Szabadidő 9. Ünnepek, Szokások 10. Város, Bevásárlás 11. Utazás, Pihenés 12. Egészséges
SZÁMÍTÓGÉP FELÉPÍTÉSE (TK 61-TŐL)
") SZÁMÍTÓGÉP FELÉPÍTÉSE (TK 61-TŐL) SZÁMÍTÓGÉP Olyan elektronikus berendezés, amely adatok, információk feldolgozására képes emberi beavatkozás nélkül valamilyen program segítségével. HARDVER Összes műszaki
SZÁMÍTÓGÉP FELÉPÍTÉSE (TK 61-TŐL) SZÁMÍTÓGÉP Olyan elektronikus berendezés, amely adatok, információk feldolgozására képes emberi beavatkozás nélkül valamilyen program segítségével. HARDVER Összes műszaki
ÉRTÉKELÉSI ÚTMUTATÓ AZ EMELT SZINTŰ SZÓBELI VIZSGÁHOZ. Általános útmutató
 ÉRTÉKELÉSI ÚTMUTATÓ AZ EMELT SZINTŰ SZÓBELI VIZSGÁHOZ Általános útmutató 1. A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az eljárás meghatározott értékelési
ÉRTÉKELÉSI ÚTMUTATÓ AZ EMELT SZINTŰ SZÓBELI VIZSGÁHOZ Általános útmutató 1. A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az eljárás meghatározott értékelési
Beszédinformációs rendszerek 5. gyakorlat Mintavételezés, kvantálás, beszédkódolás. Csapó Tamás Gábor
 Beszédinformációs rendszerek 5. gyakorlat Mintavételezés, kvantálás, beszédkódolás Csapó Tamás Gábor 2016/2017 ősz MINTAVÉTELEZÉS 2 1. Egy 6 khz-es szinusz jelet szűrés nélkül mintavételezünk
Beszédinformációs rendszerek 5. gyakorlat Mintavételezés, kvantálás, beszédkódolás Csapó Tamás Gábor 2016/2017 ősz MINTAVÉTELEZÉS 2 1. Egy 6 khz-es szinusz jelet szűrés nélkül mintavételezünk
Ütközések vizsgálatához alkalmazható számítási eljárások
 Ütközések vizsgálatához alkalmazható számítási eljárások Az eljárások a kiindulási adatoktól és a számítás menetétől függően két csoportba sorolhatók. Az egyik a visszafelé történő számítások csoportja,
Ütközések vizsgálatához alkalmazható számítási eljárások Az eljárások a kiindulási adatoktól és a számítás menetétől függően két csoportba sorolhatók. Az egyik a visszafelé történő számítások csoportja,
H N S A d a t K a p c s o l a t
 HNS AdatKapcsolat HNS AdatKapcsolat 2009 március 31 HNS SPC Statisztikai folyamatszabályozó és minőségellenőrző program Copyright 1995-2009 HNS Műszaki Fejlesztő Kft. 9027 Győr, Gesztenyefa u. 4. Tel.:
HNS AdatKapcsolat HNS AdatKapcsolat 2009 március 31 HNS SPC Statisztikai folyamatszabályozó és minőségellenőrző program Copyright 1995-2009 HNS Műszaki Fejlesztő Kft. 9027 Győr, Gesztenyefa u. 4. Tel.:
KARAKTERFELISMERÉS AZ EVASYS-BEN
 KARAKTERFELISMERÉS AZ EVASYS-BEN HOL HASZNÁLHATÓ, KI HASZNÁLHATJA A Miskolci Egyetem megvásárolta a kézírásfelismerés (ICR) modult az Evasys legutóbbi licencével együtt. Ezzel lehetőség nyílt a papír alapú
KARAKTERFELISMERÉS AZ EVASYS-BEN HOL HASZNÁLHATÓ, KI HASZNÁLHATJA A Miskolci Egyetem megvásárolta a kézírásfelismerés (ICR) modult az Evasys legutóbbi licencével együtt. Ezzel lehetőség nyílt a papír alapú
A mérések általános és alapvető metrológiai fogalmai és definíciói. Mérések, mérési eredmények, mérési bizonytalanság. mérés. mérési elv
 Mérések, mérési eredmények, mérési bizonytalanság A mérések általános és alapvető metrológiai fogalmai és definíciói mérés Műveletek összessége, amelyek célja egy mennyiség értékének meghatározása. mérési
Mérések, mérési eredmények, mérési bizonytalanság A mérések általános és alapvető metrológiai fogalmai és definíciói mérés Műveletek összessége, amelyek célja egy mennyiség értékének meghatározása. mérési
Folyamatos beszéd szószintű automatikus szegmentálása szupraszegmentális jegyek alapján
 Folyamatos beszéd szószintű automatikus szegmentálása szupraszegmentális jegyek alapján Szaszák György 1, Vicsi Klára 1 1 Budapesti Műszaki és Gazdaságtudományi Egyetem, Távközlési és Médiainformatikai
Folyamatos beszéd szószintű automatikus szegmentálása szupraszegmentális jegyek alapján Szaszák György 1, Vicsi Klára 1 1 Budapesti Műszaki és Gazdaságtudományi Egyetem, Távközlési és Médiainformatikai
Az ember-gép közötti párbeszéd megteremtésének egyik alapja a gépi beszéd felismerésének (Automatic Speech Recognition, ASR) megoldása.
 megoldása.") Az ember-gép közötti párbeszéd megteremtésének egyik alapja a gépi beszéd felismerésének (Automatic Speech Recognition, ASR) megoldása. A beszédfelismer rendszerek számos tudományterület eredményeit egyesítik
Az ember-gép közötti párbeszéd megteremtésének egyik alapja a gépi beszéd felismerésének (Automatic Speech Recognition, ASR) megoldása. A beszédfelismer rendszerek számos tudományterület eredményeit egyesítik
IDEGEN NYELV ÉRETTSÉGI VIZSGA ÁLTALÁNOS KÖVETELMÉNYEI
 IDEGEN NYELV ÉRETTSÉGI VIZSGA ÁLTALÁNOS KÖVETELMÉNYEI Az idegen nyelv érettségi vizsga célja Az idegen nyelvi érettségi vizsga célja a kommunikatív nyelvtudás mérése, azaz annak megállapítása, hogy a vizsgázó
IDEGEN NYELV ÉRETTSÉGI VIZSGA ÁLTALÁNOS KÖVETELMÉNYEI Az idegen nyelv érettségi vizsga célja Az idegen nyelvi érettségi vizsga célja a kommunikatív nyelvtudás mérése, azaz annak megállapítása, hogy a vizsgázó
Beszédfelismerő szoftver adaptálása C# programozási nyelvre
 Beszédfelismerő szoftver adaptálása C# programozási nyelvre Készítette: Sztahó Dávid A szoftver leírása A szoftver által megvalósított funkciók blokkvázlatát az 1. ábra mutatja. A szoftver valós idejű
Beszédfelismerő szoftver adaptálása C# programozási nyelvre Készítette: Sztahó Dávid A szoftver leírása A szoftver által megvalósított funkciók blokkvázlatát az 1. ábra mutatja. A szoftver valós idejű
Beszédadatbázisok elôkészítése kutatási és fejlesztési célok hatékonyabb támogatására
 Beszédadatbázisok elôkészítése kutatási és fejlesztési célok hatékonyabb támogatására NÉMETH GÉZA, OLASZY GÁBOR, BARTALIS MÁTYÁS, ZAINKÓ CSABA, FÉK MÁRK, MIHAJLIK PÉTER BME Távközlési és MédiainformatikaiTanszék
Beszédadatbázisok elôkészítése kutatási és fejlesztési célok hatékonyabb támogatására NÉMETH GÉZA, OLASZY GÁBOR, BARTALIS MÁTYÁS, ZAINKÓ CSABA, FÉK MÁRK, MIHAJLIK PÉTER BME Távközlési és MédiainformatikaiTanszék
3D számítógépes geometria és alakzatrekonstrukció
 3D számítógépes geometria és alakzatrekonstrukció 14. Digitális Alakzatrekonstrukció - Bevezetés http://cg.iit.bme.hu/portal/node/312 https://www.vik.bme.hu/kepzes/targyak/viiima01 Dr. Várady Tamás, Dr.
3D számítógépes geometria és alakzatrekonstrukció 14. Digitális Alakzatrekonstrukció - Bevezetés http://cg.iit.bme.hu/portal/node/312 https://www.vik.bme.hu/kepzes/targyak/viiima01 Dr. Várady Tamás, Dr.
Az Informatika Elméleti Alapjai
 Az Informatika Elméleti Alapjai dr. Kutor László Jelek típusai Átalakítás az analóg és digitális rendszerek között http://mobil.nik.bmf.hu/tantargyak/iea.html Felhasználónév: iea Jelszó: IEA07 IEA 3/1
Az Informatika Elméleti Alapjai dr. Kutor László Jelek típusai Átalakítás az analóg és digitális rendszerek között http://mobil.nik.bmf.hu/tantargyak/iea.html Felhasználónév: iea Jelszó: IEA07 IEA 3/1
Szegmentálási egységek összehasonlítása gépi érzelem felismerés esetén
 Szegmentálási egységek összehasonlítása gépi érzelem felismerés esetén Kiss Gábor, első éves msc-s hallgató BME, Távközlési és Médiainformatikai kar, Beszéd Akusztikai Laboratórium 1. Bevezető Adva volt
Szegmentálási egységek összehasonlítása gépi érzelem felismerés esetén Kiss Gábor, első éves msc-s hallgató BME, Távközlési és Médiainformatikai kar, Beszéd Akusztikai Laboratórium 1. Bevezető Adva volt
ÉRTÉKELÉSI ÚTMUTATÓ A KÖZÉPSZINTŰ SZÓBELI VIZSGÁHOZ. Általános útmutató
 ÉRTÉKELÉSI ÚTMUTATÓ A KÖZÉPSZINTŰ SZÓBELI VIZSGÁHOZ Általános útmutató 1. A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az eljárás meghatározott értékelési
ÉRTÉKELÉSI ÚTMUTATÓ A KÖZÉPSZINTŰ SZÓBELI VIZSGÁHOZ Általános útmutató 1. A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az eljárás meghatározott értékelési
Mérés és modellezés Méréstechnika VM, GM, MM 1
 Mérés és modellezés 2008.02.04. 1 Mérés és modellezés A mérnöki tevékenység alapeleme a mérés. A mérés célja valamely jelenség megismerése, vizsgálata. A mérés tervszerűen végzett tevékenység: azaz rögzíteni
Mérés és modellezés 2008.02.04. 1 Mérés és modellezés A mérnöki tevékenység alapeleme a mérés. A mérés célja valamely jelenség megismerése, vizsgálata. A mérés tervszerűen végzett tevékenység: azaz rögzíteni
Markov modellek 2015.03.19.
 Markov modellek 2015.03.19. Markov-láncok Markov-tulajdonság: egy folyamat korábbi állapotai a későbbiekre csak a jelen állapoton keresztül gyakorolnak befolyást. Semmi, ami a múltban történt, nem ad előrejelzést
Markov modellek 2015.03.19. Markov-láncok Markov-tulajdonság: egy folyamat korábbi állapotai a későbbiekre csak a jelen állapoton keresztül gyakorolnak befolyást. Semmi, ami a múltban történt, nem ad előrejelzést
társadalomtudományokban
 Gépi tanulás, predikció és okság a társadalomtudományokban Muraközy Balázs (MTA KRTK) Bemutatkozik a Számítógépes Társadalomtudomány témacsoport, MTA, 2017 2/20 Empirikus közgazdasági kérdések Felváltja-e
Gépi tanulás, predikció és okság a társadalomtudományokban Muraközy Balázs (MTA KRTK) Bemutatkozik a Számítógépes Társadalomtudomány témacsoport, MTA, 2017 2/20 Empirikus közgazdasági kérdések Felváltja-e
A következő táblázat az értékelési szempontokat és az egyes szempontok szerint adható maximális pontszámot mutatja.
 A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák alapján történik. Ez az értékelési eljárás meghatározott értékelési szempontokon, valamint az egyes szempontokhoz tartozó szintleírásokon
A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák alapján történik. Ez az értékelési eljárás meghatározott értékelési szempontokon, valamint az egyes szempontokhoz tartozó szintleírásokon
ANGLISZTIKA ALAPKÉPZÉSI SZAK ZÁRÓVIZSGA
 ANGLISZTIKA ALAPKÉPZÉSI SZAK ZÁRÓVIZSGA Az anglisztika szak létesítési dokumentuma szerint: a záróvizsgára bocsátás feltétele egy sikeres szakdolgozat, a kritérium jellegű záróvizsga két részből áll: egy
ANGLISZTIKA ALAPKÉPZÉSI SZAK ZÁRÓVIZSGA Az anglisztika szak létesítési dokumentuma szerint: a záróvizsgára bocsátás feltétele egy sikeres szakdolgozat, a kritérium jellegű záróvizsga két részből áll: egy
Minta. Az emelt szintű szóbeli vizsga értékelési útmutatója
 Az emelt szintű szóbeli vizsga értékelési útmutatója A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az értékelési eljárás meghatározott értékelési szempontokon,
Az emelt szintű szóbeli vizsga értékelési útmutatója A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az értékelési eljárás meghatározott értékelési szempontokon,
Populációbecslések és monitoring
 Populációbecslések és monitoring A becslés szerepe az ökológiában és a vadgazdálkodásban. A becslési módszerek csoportosítása. Teljes számlálás. Statisztikai alapfogalmak. Fontos lehet tudnunk, hogy hány
Populációbecslések és monitoring A becslés szerepe az ökológiában és a vadgazdálkodásban. A becslési módszerek csoportosítása. Teljes számlálás. Statisztikai alapfogalmak. Fontos lehet tudnunk, hogy hány
Értékelési útmutató a középszintű szóbeli vizsgához. Angol nyelv
 Értékelési útmutató a középszintű szóbeli vizsgához Angol nyelv Általános jellemzők FELADATTÍPUS ÉRTÉKELÉS SZEMPONTJAI PONTSZÁM Bemelegítő beszélgetés Nincs értékelés 1. Társalgási feladat: - három témakör
Értékelési útmutató a középszintű szóbeli vizsgához Angol nyelv Általános jellemzők FELADATTÍPUS ÉRTÉKELÉS SZEMPONTJAI PONTSZÁM Bemelegítő beszélgetés Nincs értékelés 1. Társalgási feladat: - három témakör
Statisztika I. 4. előadás Mintavétel. Kóczy Á. László KGK-VMI. Minta Mintavétel Feladatok. http://uni-obuda.hu/users/koczyl/statisztika1.
 Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
Középszintű szóbeli érettségi vizsga értékelési útmutatója. Olasz nyelv
 Középszintű szóbeli érettségi vizsga értékelési útmutatója Olasz nyelv FELADATTÍPUS ÉRTÉKELÉS SZEMPONTJAI PONTSZÁM Bemelegítő beszélgetés 1. Társalgási feladat/interjú: három témakör interakció kezdeményezés
Középszintű szóbeli érettségi vizsga értékelési útmutatója Olasz nyelv FELADATTÍPUS ÉRTÉKELÉS SZEMPONTJAI PONTSZÁM Bemelegítő beszélgetés 1. Társalgási feladat/interjú: három témakör interakció kezdeményezés
T E R M É K T Á J É K O Z TAT Ó
 T E R M É K T Á J É K O Z TAT Ó ÚJ!!! SeCorr 08 korrrelátor A legújabb DSP technikával ellátott számítógépes támogatással rendelkező korrelátor a hibahelyek megtalálásához. 1 MI A KORRELÁCIÓ? A korreláció
T E R M É K T Á J É K O Z TAT Ó ÚJ!!! SeCorr 08 korrrelátor A legújabb DSP technikával ellátott számítógépes támogatással rendelkező korrelátor a hibahelyek megtalálásához. 1 MI A KORRELÁCIÓ? A korreláció
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
2. Hozzárendelt azonosítók alapján
 Elektronikus kereskedelem Dr. Kutor László Automatikus azonosító rendszerek http://uni-obuda.hu/users/kutor/ Miért fontos az azonosítás? Az azonosítás az információ-feldolgozó rendszerek működésének alapfeltétele.
Elektronikus kereskedelem Dr. Kutor László Automatikus azonosító rendszerek http://uni-obuda.hu/users/kutor/ Miért fontos az azonosítás? Az azonosítás az információ-feldolgozó rendszerek működésének alapfeltétele.
Elektronikus kereskedelem. Automatikus azonosító rendszerek
 Elektronikus kereskedelem Dr. Kutor László Automatikus azonosító rendszerek http://uni-obuda.hu/users/kutor/ 2012. ősz OE NIK Dr. Kutor László EK-4/42/1 Miért fontos az azonosítás? Az azonosítás az információ-feldolgozó
Elektronikus kereskedelem Dr. Kutor László Automatikus azonosító rendszerek http://uni-obuda.hu/users/kutor/ 2012. ősz OE NIK Dr. Kutor László EK-4/42/1 Miért fontos az azonosítás? Az azonosítás az információ-feldolgozó
Mérés és modellezés 1
 Mérés és modellezés 1 Mérés és modellezés A mérnöki tevékenység alapeleme a mérés. A mérés célja valamely jelenség megismerése, vizsgálata. A mérés tervszerűen végzett tevékenység: azaz rögzíteni kell
Mérés és modellezés 1 Mérés és modellezés A mérnöki tevékenység alapeleme a mérés. A mérés célja valamely jelenség megismerése, vizsgálata. A mérés tervszerűen végzett tevékenység: azaz rögzíteni kell
Beszédészlelés 1: Beszédpercepció. A beszédpercepció helye a beszédmegértési folyamatban
 Beszédészlelés 1: Beszédpercepció A beszédpercepció helye a beszédmegértési folyamatban A beszéd reprezentációja Akusztikus (obj) a frekvencia és intenzitás (változása) az időben Artikulációs (obj) artikulációs
Beszédészlelés 1: Beszédpercepció A beszédpercepció helye a beszédmegértési folyamatban A beszéd reprezentációja Akusztikus (obj) a frekvencia és intenzitás (változása) az időben Artikulációs (obj) artikulációs
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 9 IX. ROBUsZTUs statisztika 1. ROBUsZTUssÁG Az eddig kidolgozott módszerek főleg olyanok voltak, amelyek valamilyen értelemben optimálisak,
[Biomatematika 2] Orvosi biometria
![[Biomatematika 2] Orvosi biometria](/thumbs/47/23623719.jpg "[Biomatematika 2] Orvosi biometria") [Biomatematika 2] Orvosi biometria 2016.02.15. Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza) alkotja az eseményteret. Esemény: az eseménytér részhalmazai.
[Biomatematika 2] Orvosi biometria 2016.02.15. Esemény Egy kísérlet vagy megfigyelés (vagy mérés) lehetséges eredményeinek összessége (halmaza) alkotja az eseményteret. Esemény: az eseménytér részhalmazai.
Statisztika I. 4. előadás Mintavétel. Kóczy Á. László KGK-VMI. Minta Mintavétel Feladatok. http://uni-obuda.hu/users/koczyl/statisztika1.
 Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
ÉRTÉKELÉSI ÚTMUTATÓ A KÖZÉPSZINTŰ SZÓBELI VIZSGÁHOZ
 ÉRTÉKELÉSI ÚTMUTATÓ A KÖZÉPSZINTŰ SZÓBELI VIZSGÁHOZ Általános útmutató 1. A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az eljárás meghatározott értékelési
ÉRTÉKELÉSI ÚTMUTATÓ A KÖZÉPSZINTŰ SZÓBELI VIZSGÁHOZ Általános útmutató 1. A szóbeli feladatok értékelése központilag kidolgozott analitikus skálák segítségével történik. Ez az eljárás meghatározott értékelési
Populációbecslések és monitoring
 Populációbecslések és monitoring A becslés szerepe az ökológiában és a vadgazdálkodásban. A becslési módszerek csoportosítása. Teljes számlálás. Statisztikai alapfogalmak. Fontos lehet tudnunk, hogy hány
Populációbecslések és monitoring A becslés szerepe az ökológiában és a vadgazdálkodásban. A becslési módszerek csoportosítása. Teljes számlálás. Statisztikai alapfogalmak. Fontos lehet tudnunk, hogy hány
Intelligens Rendszerek Elmélete. Párhuzamos keresés genetikus algoritmusokkal. A genetikus algoritmus működése. Az élet információ tárolói
 Intelligens Rendszerek Elmélete dr. Kutor László Párhuzamos keresés genetikus algoritmusokkal http://mobil.nik.bmf.hu/tantargyak/ire.html login: ire jelszó: IRE07 IRE 5/ Természetes és mesterséges genetikus
Intelligens Rendszerek Elmélete dr. Kutor László Párhuzamos keresés genetikus algoritmusokkal http://mobil.nik.bmf.hu/tantargyak/ire.html login: ire jelszó: IRE07 IRE 5/ Természetes és mesterséges genetikus
GHS/CLP végrehajtása a Linde Csoportnál
 GHS/CLP végrehajtása a Linde Csoportnál Alapismeretek 02/2011 Linde termékek: GHS alap információk GHS áttekintése (I) Vegyi anyagok osztályozásának és címkézésének globálisan harmonizált rendszerét jelenti.
GHS/CLP végrehajtása a Linde Csoportnál Alapismeretek 02/2011 Linde termékek: GHS alap információk GHS áttekintése (I) Vegyi anyagok osztályozásának és címkézésének globálisan harmonizált rendszerét jelenti.
Digitális hangszintmérő
 Digitális hangszintmérő Modell DM-1358 A jelen használati útmutató másolása, bemutatása és terjesztése a Transfer Multisort Elektronik írásbeli hozzájárulását igényli. Használati útmutató Óvintézkedések
Digitális hangszintmérő Modell DM-1358 A jelen használati útmutató másolása, bemutatása és terjesztése a Transfer Multisort Elektronik írásbeli hozzájárulását igényli. Használati útmutató Óvintézkedések
TDK-dolgozat. Kis szótáras beszédfelismerő hatékonyságának vizsgálata különböző jel-zaj viszonyokkal
 Miskolci Egyetem Gépészmérnöki és Informatikai kar Automatizálási és Kommunikáció-Technológiai Tanszék TDK-dolgozat Kis szótáras beszédfelismerő hatékonyságának vizsgálata különböző jel-zaj viszonyokkal
Miskolci Egyetem Gépészmérnöki és Informatikai kar Automatizálási és Kommunikáció-Technológiai Tanszék TDK-dolgozat Kis szótáras beszédfelismerő hatékonyságának vizsgálata különböző jel-zaj viszonyokkal
TANTÁRGYI TEMATIKA ÉS FÉLÉVI KÖVETELMÉNYRENDSZER. Szemináriumi témák
 TANTÁRGYI TEMATIKA ÉS FÉLÉVI KÖVETELMÉNYRENDSZER Beszédművelés Tantárgy kódja BTA1102 Meghirdetés féléve 1. Kreditpont 3 Heti kontaktóraszám (elm. + 0+2 gyak.) gyakorlati jegy Előfeltétel (tantárgyi kód)
TANTÁRGYI TEMATIKA ÉS FÉLÉVI KÖVETELMÉNYRENDSZER Beszédművelés Tantárgy kódja BTA1102 Meghirdetés féléve 1. Kreditpont 3 Heti kontaktóraszám (elm. + 0+2 gyak.) gyakorlati jegy Előfeltétel (tantárgyi kód)
Beltéri autonóm négyrotoros helikopter szabályozó rendszerének kifejlesztése és hardware-in-the-loop tesztelése
 Beltéri autonóm négyrotoros helikopter szabályozó rendszerének kifejlesztése és hardware-in-the-loop tesztelése Regula Gergely, Lantos Béla BME Villamosmérnöki és Informatikai Kar Irányítástechnika és
Beltéri autonóm négyrotoros helikopter szabályozó rendszerének kifejlesztése és hardware-in-the-loop tesztelése Regula Gergely, Lantos Béla BME Villamosmérnöki és Informatikai Kar Irányítástechnika és
Beszédfelismerő modellépítési kísérletek akusztikai, fonetikai szinten, kórházi leletező beszédfelismerő kifejlesztése céljából
 Beszédfelismerő modellépítési kísérletek akusztikai, fonetikai szinten, kórházi leletező beszédfelismerő kifejlesztése céljából Velkei Szabolcs, Vicsi Klára BME Távközlési és Médiainformatikai Tanszék,
Beszédfelismerő modellépítési kísérletek akusztikai, fonetikai szinten, kórházi leletező beszédfelismerő kifejlesztése céljából Velkei Szabolcs, Vicsi Klára BME Távközlési és Médiainformatikai Tanszék,
1. számú ábra. Kísérleti kályha járattal
 Kísérleti kályha tesztelése A tesztsorozat célja egy járatos, egy kitöltött harang és egy üres harang hőtároló összehasonlítása. A lehető legkisebb méretű, élére állított téglából épített héjba hagyományos,
Kísérleti kályha tesztelése A tesztsorozat célja egy járatos, egy kitöltött harang és egy üres harang hőtároló összehasonlítása. A lehető legkisebb méretű, élére állított téglából épített héjba hagyományos,
Folyamatos, középszótáras, beszédfelismerô rendszer fejlesztési tapasztalatai: kórházi leletezô beszédfelismerô
 Folyamatos, középszótáras, beszédfelismerô rendszer fejlesztési tapasztalatai: kórházi leletezô beszédfelismerô VICSI KLÁRA, VELKEI SZABOLCS, SZASZÁK GYÖRGY, BOROSTYÁN GÁBOR, GORDOS GÉZA BME Távközlési
Folyamatos, középszótáras, beszédfelismerô rendszer fejlesztési tapasztalatai: kórházi leletezô beszédfelismerô VICSI KLÁRA, VELKEI SZABOLCS, SZASZÁK GYÖRGY, BOROSTYÁN GÁBOR, GORDOS GÉZA BME Távközlési
PRECÍZIÓS, PÁRHUZAMOS, MAGYAR BESZÉDADATBÁZIS FEJLESZTÉSE ÉS SZOLGÁLTATÁSAI. Olaszy Gábor
 261 PRECÍZIÓS, PÁRHUZAMOS, MAGYAR BESZÉDADATBÁZIS FEJLESZTÉSE ÉS SZOLGÁLTATÁSAI Bevezetés A beszédkutatásban világszerte egyre nagyobb teret kapnak az előre elkészített, annotált és szegmentált beszédadatbázisok.
261 PRECÍZIÓS, PÁRHUZAMOS, MAGYAR BESZÉDADATBÁZIS FEJLESZTÉSE ÉS SZOLGÁLTATÁSAI Bevezetés A beszédkutatásban világszerte egyre nagyobb teret kapnak az előre elkészített, annotált és szegmentált beszédadatbázisok.
Nagy számok törvényei Statisztikai mintavétel Várható érték becslése. Dr. Berta Miklós Fizika és Kémia Tanszék Széchenyi István Egyetem
 agy számok törvényei Statisztikai mintavétel Várható érték becslése Dr. Berta Miklós Fizika és Kémia Tanszék Széchenyi István Egyetem A mérés mint statisztikai mintavétel A méréssel az eloszlásfüggvénnyel
agy számok törvényei Statisztikai mintavétel Várható érték becslése Dr. Berta Miklós Fizika és Kémia Tanszék Széchenyi István Egyetem A mérés mint statisztikai mintavétel A méréssel az eloszlásfüggvénnyel
Biomatematika 12. Szent István Egyetem Állatorvos-tudományi Kar. Fodor János
 Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Szent István Egyetem Állatorvos-tudományi Kar Biomatematikai és Számítástechnikai Tanszék Biomatematika 12. Regresszió- és korrelációanaĺızis Fodor János Copyright c Fodor.Janos@aotk.szie.hu Last Revision
Hogyan lesz adatbányából aranybánya?
 Hogyan lesz adatbányából aranybánya? Szolgáltatások kapacitástervezése a Budapest Banknál Németh Balázs Budapest Bank Fehér Péter - Corvinno Visontai Balázs - KFKI Tartalom 1. Szolgáltatás életciklus 2.
Hogyan lesz adatbányából aranybánya? Szolgáltatások kapacitástervezése a Budapest Banknál Németh Balázs Budapest Bank Fehér Péter - Corvinno Visontai Balázs - KFKI Tartalom 1. Szolgáltatás életciklus 2.
MÉRÉSI EREDMÉNYEK PONTOSSÁGA, A HIBASZÁMÍTÁS ELEMEI
 MÉRÉSI EREDMÉYEK POTOSSÁGA, A HIBASZÁMÍTÁS ELEMEI. A mérési eredmény megadása A mérés során kapott értékek eltérnek a mérendő fizikai mennyiség valódi értékétől. Alapvetően kétféle mérési hibát különböztetünk
MÉRÉSI EREDMÉYEK POTOSSÁGA, A HIBASZÁMÍTÁS ELEMEI. A mérési eredmény megadása A mérés során kapott értékek eltérnek a mérendő fizikai mennyiség valódi értékétől. Alapvetően kétféle mérési hibát különböztetünk
Költségbecslési módszerek a szerszámgyártásban. Tartalom. CEE-Product Groups. Költségbecslés. A költségbecslés szerepe. Dr.
 Gépgyártástechnológia Tsz Költségbecslési módszerek a szerszámgyártásban Szerszámgyártók Magyarországi Szövetsége 2003. december 11. 1 2 CEE-Product Groups Tartalom 1. Költségbecslési módszerek 2. MoldCoster
Gépgyártástechnológia Tsz Költségbecslési módszerek a szerszámgyártásban Szerszámgyártók Magyarországi Szövetsége 2003. december 11. 1 2 CEE-Product Groups Tartalom 1. Költségbecslési módszerek 2. MoldCoster
Értékelési szempont A kommunikációs cél elérése és az interakció megvalósítása 3 Szókincs, kifejezésmód 3 Nyelvtan 2 Összesen 8
 Összefoglaló táblázatok a portugál nyelv középszintű szóbeli vizsga értékeléséhez A következő táblázat az értékelési szempontokat és az egyes szempontoknál adható maximális pontszámot mutatja középszinten.
Összefoglaló táblázatok a portugál nyelv középszintű szóbeli vizsga értékeléséhez A következő táblázat az értékelési szempontokat és az egyes szempontoknál adható maximális pontszámot mutatja középszinten.
Analóg-digitális átalakítás. Rencz Márta/ Ress S. Elektronikus Eszközök Tanszék
 Analóg-digitális átalakítás Rencz Márta/ Ress S. Elektronikus Eszközök Tanszék Mai témák Mintavételezés A/D átalakítók típusok D/A átalakítás 12/10/2007 2/17 A/D ill. D/A átalakítók A világ analóg, a jelfeldolgozás
Analóg-digitális átalakítás Rencz Márta/ Ress S. Elektronikus Eszközök Tanszék Mai témák Mintavételezés A/D átalakítók típusok D/A átalakítás 12/10/2007 2/17 A/D ill. D/A átalakítók A világ analóg, a jelfeldolgozás
DIGITÁLIS KÉPANALÍZIS KÉSZÍTETTE: KISS ALEXANDRA ELÉRHETŐSÉG:
 DIGITÁLIS KÉPANALÍZIS KÉSZÍTETTE: KISS ALEXANDRA ELÉRHETŐSÉG: kisszandi@mailbox.unideb.hu ImageJ (Fiji) Nyílt forrás kódú, java alapú képelemző szoftver https://fiji.sc/ Számos képformátumhoz megfelelő
DIGITÁLIS KÉPANALÍZIS KÉSZÍTETTE: KISS ALEXANDRA ELÉRHETŐSÉG: kisszandi@mailbox.unideb.hu ImageJ (Fiji) Nyílt forrás kódú, java alapú képelemző szoftver https://fiji.sc/ Számos képformátumhoz megfelelő
A magánhangzó-formánsok és a szubglottális rezonanciák összefüggése a spontán beszédben
 A magánhangzó-formánsok és a szubglottális rezonanciák összefüggése a spontán beszédben Csapó Tamás Gábor, 1 Bárkányi Zsuzsanna, 2 Gráczi Tekla Etelka, 2 Beke András, 3 Bőhm Tamás 1,4 csapot@tmit.bme.hu
A magánhangzó-formánsok és a szubglottális rezonanciák összefüggése a spontán beszédben Csapó Tamás Gábor, 1 Bárkányi Zsuzsanna, 2 Gráczi Tekla Etelka, 2 Beke András, 3 Bőhm Tamás 1,4 csapot@tmit.bme.hu