Adatbányászati, data science tevékenység
|
|
|
- Brigitta Bakos
- 6 évvel ezelőtt
- Látták:
Átírás
1 Adatbányászati, data science tevékenység projektmenedzsmentje IPE képzés II. félév Körmendi György Clementine Consulting
2 Bemelegítés




3 Adatbányászat célja Szegmentálás Leíró modellek Előrejelző modellek Jellemző mintázatok feltárása Kapcsolatok feltárása Események előrejelzése Csoportok differenciált kezelése Összefüggések megértése Megelőzés 3
4 Adatbányászati, DS projektek Van ilyen? Ki végzi? Hol végzi? Mit csinál? Hogyan végzi? Mi az eredménye?
5 Adatbányászati projektek L Ki végzi? Adatbányász, adattudós, adatelemző (gyakran matematikus fizikus végzettségű) Általában NEM programozó Gyakran NEM üzleti szakértő (pl. marketinges, értékesítő, vagy ügyfélszolgálatos De általában masszív informatikai, és üzleti tudással IS rendelkezik
6 Adatbányászati, DS projektek Hol végzi? Általában belsős, ritkábban külsős Általában üzleti területhez tartozik, ritkábban IT
7 Adatbányászati, DS projektek Mit csinál? L Leíró statisztikákat gyárt(gyakoriság, eloszlások, kereszttáblák) Riportokat készít, diagramokat gyárt Prediktív modelleket készít, fejleszt Prediktív analitikai rendszert üzemeltet De persze többnyire (80%): Adatot tisztít, formáz, kérdez le Adatot gyurmáz (number crunching)
8 Adatbányászati, DS projektek L Hogyan végzi? Meglehetősen kötetlenül,nem szigorú lépésekben Gyakran egyedül, de legalábbis szeparálva Sok kreativitással Módszertanok CRISP-DM SEMMA
9 Módszertan
10 History of data analytics terminologies Data science Predictive Modeling Data mining Machine learning KDD (Knowledge Discovery from Databases) Statistics

11 Alkalmazási területek Bárhol ahol: Van matematikailag megfelelő probléma Van hozzá adat És megéri.
12 Alkalmazási területek Bárhol ahol: Van matematikailag megfelelő probléma Van hozzá adat És megéri.
13 Alkalmazási területek Bárhol ahol: Van matematikailag megfelelő probléma Van hozzá adat És megéri.
14 Alkalmazási területek Bárhol ahol: Van matematikailag megfelelő probléma Van hozzá adat És megéri.
15 Eszközök Platformok vs programnyelvek Open source vs fizetős /Rexer, 2015/
16 Eszközök /Gartner, 2017/
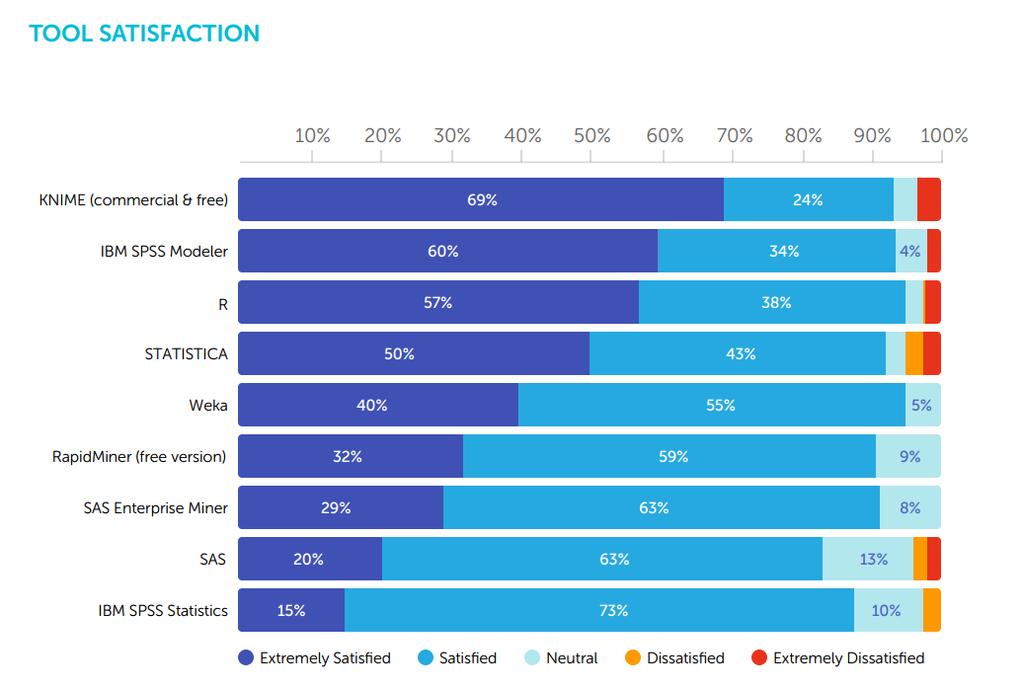
17 Eszközök
18 Adatbányászati, DS projektek L Mi az eredménye? Riportok, diagramok, előrejelzések célváltozó (pl. lemorzsolódók, vagy csalók) Gépi automaták lelke (pl. ajánlórendszerek, optimalizáló rendszerek )
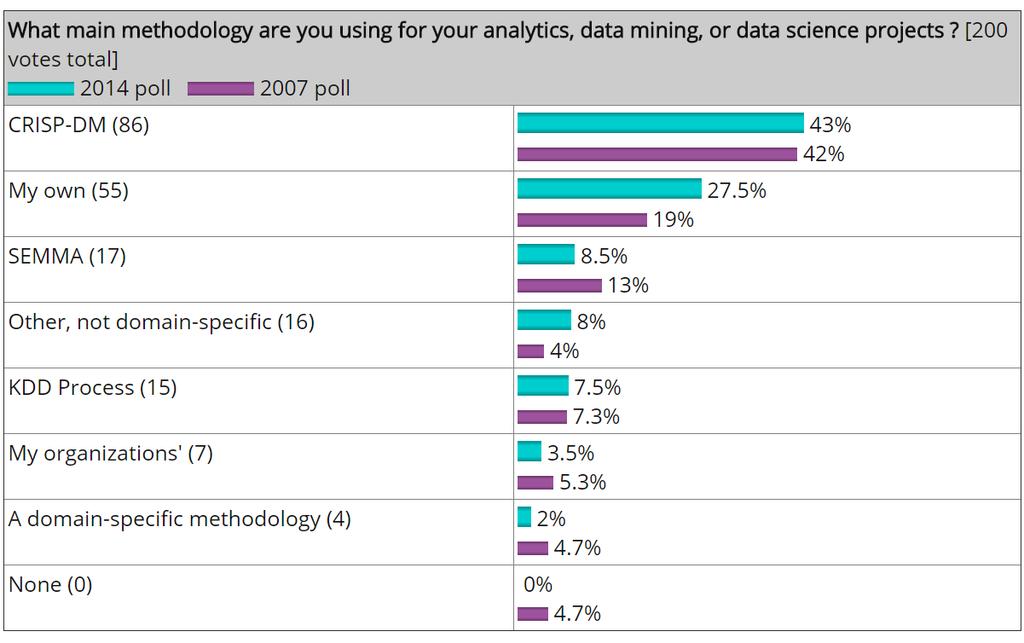
19 Módszertan
 Adatbányászati folyamatok iparágak közötti")
20 Módszertan L CRoss-Industry Standard Process for Data Mining (CRISP-DM) Adatbányászati folyamatok iparágak közötti szabványa
21 CRISP-DM L Üzleti célok meghatározása Üzleti problémák és célok megfogalmazása Helyzet értékelés mi valósítható meg, és hogyan Feladat adatbányászati megfogalmazása Projekt terv elkészítése Adatok megismerése Adatok begyűjtése Adatok vizsgálata, megértése Adatminőség felmérése Adatok előkészítése Adatok kiválogatása Adattisztítás Adattranszformálás
22 CRISP-DM Modellezés Modellezési technika kiválasztása Tesztkörnyezet kialakítása (tanító, tesztelő, validáló minta) Modellek építése Generált modell értelmezése Kiértékelés Eredmények kiértékelése Eredmény összevetése az üzleti célokkal Folyamat áttekintése Következő adatbányászati lépés meghatározása Alkalmazás Alkalmazási terv elkészítése Monitoring terv A kész modellek átadása/telepítése Végső jelentések elkészítése L
23 Algoritmusok Sok ezer létezik Nagy családokba rendezhetők A legtöbb csak Pythonban, R-ben érhető el Üzleti életben csak néhányat használnak Feladat, adat specifikusak NINCS csodaalgoritmus Az általánosan elterjedtek általában elég jók

24 Megerősített tanulás Nem irányított tanítás Irányított, felügyelt tanítás
25 Irányított tanuló modellek összefoglalás Algoritmus Célváltozó Input Flag Kat. Folyt. Hiányzó értékek Regresszió x Folytonos eldobás v. használat Linear x Bármi Nem kezeli Log. Regr. x x Bármi Nem kezeli Discriminant x x Folytonos Nem kezeli Genlin x x x Bármi Nem kezeli SVM x x x Bármi Nem kezeli C5.0 x x Bármi kezeli C&RT x x x Bármi pótvágás CHAID x x x Bármi* becslés, külön kategória QUEST x x Bármi pótvágás Decision list x Bármi* külön kat. v. eldobás Neurális háló x x x Bármi Semleges érték Bayes háló x x Bármi* eldobás v. használat KNN x x x Bármi Nen kezeli *A folytonos változókat kategóriákra osztja.
26 Modell értékelés Előre nem lehet megmondani mikor elfogadható, még becslés sincs Főleg a felügyelt eljárásokat értékeljük, a célváltozó modellezési pontosságát Modellek két módon javíthatók: Több adattal, jobban előkészített adattal L Algoritmus megválasztásával (próbálgatás) Modell értékelési módszerek: Gains, Lift görbe Gini ROC AUC Szakmai kérdés, hogy hogyan történik de a projekt elején megadhatóak, elvárható a megadása!
27 Klasszifikáció - modellértékelés 1. A modell alapján minden esethez egy pontszámot rendelünk (score érték) 2. A rekordokat a pontszám alapján csökkenő sorba rendezzük 3. A lista elején több találatot várunk No Score Target CustID Age Y N Y Y N N N találat a lista első 5%-ában Ha a mintában összesen 15 találat van, akkor a top 5%- kal a találatok 20%- át (3/15=0,2) találjuk meg.
28 Klasszifikáció - modellértékelés Gains chart Gains ~ CPH ~ Cumulative % Hits Nr of hits in top P% Total Nr of hits 100 Véletlen rendezés esetén a lista első 5%-ában a találatok 5%-a szerepel.

29 Klasszifikáció - modellértékelés Gains chart Gains ~ CPH ~ Cumulative % Hits Nr of hits in top P% Total Nr of hits 100 Véletlen rendezés esetén a lista első 5%-ában a találatok 5%-a szerepel. A modell alapján rendezett lista első 5%-ában a találatok 21%-a szerepel.
 Gain(P%)")
30 Klasszifikáció - modellértékelés Lift chart Lift Rate of hits in top P% Total rate of hits Lift(P%) Gain(P%) P

31 Klasszifikáció - modellértékelés ROC görbe Bináris célváltozó esetén a rangsorolás minőségének mérésére True positive / false positive Görbe alatti terület ~ modell jósága Egy véletlen pozitív példa milyen valószínűséggel van előrébb a rangsorban, mint egy véletlen negatív példa. Véletlen modell: 0.5 Tökéletes modell: 1 Jó: 0.8 fölött
32 Klasszifikáció - modellértékelés ROC görbe alakja Kiváló rangsorolás és szeparáció esete Megfelelő rangsorolás kevés konkáv résszel Gyenge rangsorolás: a középső tartományban a rangsorolás teljesen véletlenszerű A rangsorolás minősége egyenlő egy véletlen rangsorolás minőségével
 Elvárt érték: 0.")
33 Gini A Gini index a Gain görbe és az átló (véletlen modell) közötti terület normálva az elméleti legjobb modell és az átló közötti területtel (PSZÁF definíció) Elvárt érték: 0.27
34 Arány cutt off Kolmogorov-Smirnov A KS mutató a várható defaultos- és nem defaultos ügyfelek scoring értékeinek eloszlásfüggvényei közötti maximális különbség Elvárt érték Performance mutató Nem defaultos várható csökkenése Várható össz átengedési arány Defaultos várható csökkenése Default Nem Default Együtt KS=max(F ndf (scoring)-f df (scoring)) PD_Scoring 34
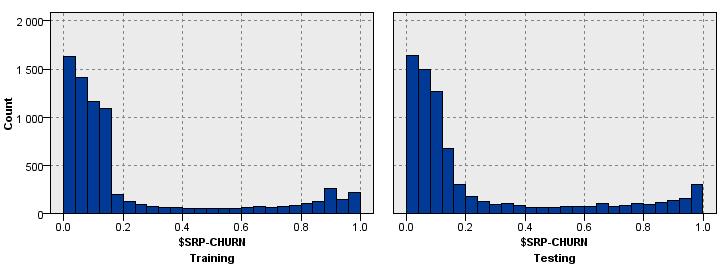
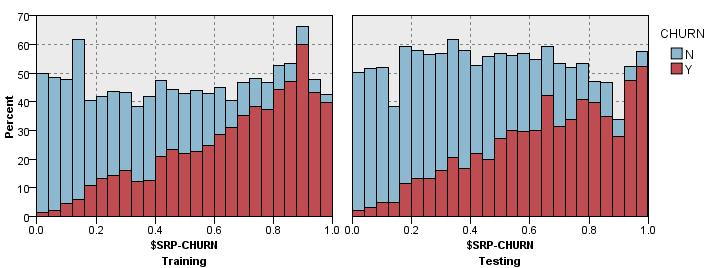
35 Klasszifikáció Cut-off Training Testing 35
36 Klasszifikáció - modellértékelés Találati mátrix ~ misclassification matrix Actual class Pontosság: helyes osztályozás aránya Érzékenység ~ sensitivity (Recall): helyesen osztályozott pozitív minták aránya Yes No Yes Predicted class TP: True positive FP: False positive Másodfajú hiba Sajátosság ~ specificity: helyesen osztályozott negatív minták aránya Megbízhatóság ~ precision: helyesen pozitív osztályba sorolt minták aránya No FN: False negative TN: True negative TP TN N TP TP FN TP TP FP Első -fajú hiba TN TN FP
37 Szakmai hatékonyság Az adattudomány ugyan művészet, de mennyi idő egy műalkotás létrehozása? Kaggle.com Give me some credit Tiszta adatok Nagyon kevés változó Nagyon világos probléma Befektetett munka: 1,5 nap 37
 A javulás pénz, tehát kérdés, hogy mekkora befektetést ér meg?")
38 A verseny eredménye (87 nap) X X X Best 0, CC 0, (-0,003062) Benchmark 0, (-0,005309) A javulás pénz, tehát kérdés, hogy mekkora befektetést ér meg? (Nagyon ritkán igazán sokat. 38
39 Adatbányászati, DS projektek L Mikor hatékony egy projekt? A tipikus DS projekt eredményterméke a projekt egy már gyakran korai fázisától létrejön, és fejlődik, javul Ezért az értelmes kérdés, hogy mikor elég jó, mennyit (mennyi időt) érdemes invesztálni bele? Ez üzleti megtérülési modellel támoatható
40 Adatbányászati, DS projektek L Mikor jó egy projekt? Reprodukálható Összehasonlítható, mérhető Standard kimenet képes (PMML, SQL, stb.) Módosítható
41 Adatbányászati, DS projektek L Milyen dokumentáció várható? Programnyelv (R, Python) alapúnál fejlesztésekhez hasonlóan részletes (bár szinte sohasem készül) Fejlett GUI-nál, vizuális kódnál (pl. Modeler) egyszerűbb leírás is elég Architektúra ábra, leírás
42 Adatbányászati, DS projektek Mik a DS projektek specifikus jellemzői? A jó DS tevékenység igazából nem projekt(!) hanem folyamatszemléletű Erősen üzleti fókuszú Jellemzően 2 hét-2 hónap, (ha nem igényel extra adatelőkészítést) 70-80%-a adatmanipuláció, adattisztítás Általában 1-2 elemző végzi a fő tevékenységet (ezért sem igényel klasszikus menedzsmentet) Erősen integrált, eredménye beépül L
43 Adatbányászati, DS projektek Tétel: Mik az adatbányászati, data science projektek legfontosabb megkülönböztető jegyei? Milyen dokumentáció várható el? Hogyan mérhető a modellek teljesítőképessége, performanciája?

44 Kérdések?
Adatbányászati, data science tevékenység projektmenedzsmentje
 Adatbányászati, data science tevékenység projektmenedzsmentje IPE képzés II. félév Körmendi György, Hans Zoltán Clementine Consulting 2018.03.08. L Bemelegítés Adatbányászat célja Szegmentálás Leíró modellek
Adatbányászati, data science tevékenység projektmenedzsmentje IPE képzés II. félév Körmendi György, Hans Zoltán Clementine Consulting 2018.03.08. L Bemelegítés Adatbányászat célja Szegmentálás Leíró modellek
The nontrivial extraction of implicit, previously unknown, and potentially useful information from data.
 Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Adatelemzés intelligens módszerekkel Hullám Gábor Adatelemzés hagyományos megközelítésben I. Megválaszolandó
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs rendszerek Tanszék Adatelemzés intelligens módszerekkel Hullám Gábor Adatelemzés hagyományos megközelítésben I. Megválaszolandó
Intelligens orvosi műszerek VIMIA023
 Intelligens orvosi műszerek VIMIA023 Diagnózistámogatás = döntéstámogatás A döntések jellemzése (ROC, AUC) 2018 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu (463-)2679
Intelligens orvosi műszerek VIMIA023 Diagnózistámogatás = döntéstámogatás A döntések jellemzése (ROC, AUC) 2018 ősz http://www.mit.bme.hu/oktatas/targyak/vimia023 dr. Pataki Béla pataki@mit.bme.hu (463-)2679
Egyenlőtlenségi mérőszámok alkalmazása az adatbányászatban. Hajdu Ottó BCE: Statisztika Tanszék BME: Pénzügyek tanszék Budapest, 2011
 Egyenlőtlenségi mérőszámok alkalmazása az adatbányászatban Hajdu Ottó BCE: Statisztika Tanszék BME: Pénzügyek tanszék Budapest, 2011 Adatbányászati feladatok 1. Ismert mintákon, példákon való tanulás (extracting
Egyenlőtlenségi mérőszámok alkalmazása az adatbányászatban Hajdu Ottó BCE: Statisztika Tanszék BME: Pénzügyek tanszék Budapest, 2011 Adatbányászati feladatok 1. Ismert mintákon, példákon való tanulás (extracting
Eredmények kiértékelése
 Eredmények kiértékelése Nagyméretű adathalmazok kezelése (2010/2011/2) Katus Kristóf, hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi és Információelméleti Tanszék 2011. március
Eredmények kiértékelése Nagyméretű adathalmazok kezelése (2010/2011/2) Katus Kristóf, hallgató Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi és Információelméleti Tanszék 2011. március
Adatbányászati feladatgyűjtemény tehetséges hallgatók számára
 Adatbányászati feladatgyűjtemény tehetséges hallgatók számára Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Tartalomjegyék Modellek kiértékelése...
Adatbányászati feladatgyűjtemény tehetséges hallgatók számára Buza Krisztián Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Tartalomjegyék Modellek kiértékelése...
Tartalom. Jó hogy jön Jucika, maga biztosan emlékszik még, hányadik oldalon van a Leszállás ködben.
 Tartalom Jó hogy jön Jucika, maga biztosan emlékszik még, hányadik oldalon van a Leszállás ködben. Előszó 1. Az adatbányászatról általában 19 1.1. Miért adatbányászat? 21 1.2. Technológia a rejtett információk
Tartalom Jó hogy jön Jucika, maga biztosan emlékszik még, hányadik oldalon van a Leszállás ködben. Előszó 1. Az adatbányászatról általában 19 1.1. Miért adatbányászat? 21 1.2. Technológia a rejtett információk
Mit mond a XXI. század emberének a statisztika?
 Mit mond a XXI. század emberének a statisztika? Rudas Tamás Magyar Tudományos Akadémia Társadalomtudományi Kutatóközpont Eötvös Loránd Tudományegyetem Statisztika Tanszék Nehéz a jövőbe látni Változik
Mit mond a XXI. század emberének a statisztika? Rudas Tamás Magyar Tudományos Akadémia Társadalomtudományi Kutatóközpont Eötvös Loránd Tudományegyetem Statisztika Tanszék Nehéz a jövőbe látni Változik
1. ábra: Magyarországi cégek megoszlása és kockázatossága 10-es Rating kategóriák szerint. Cégek megoszlása. Fizetésképtelenné válás valószínűsége
 Bisnode Minősítés A Bisnode Minősítést a lehető legkorszerűbb, szofisztikált matematikai-statisztikai módszertannal, hazai és nemzetközi szakértők bevonásával fejlesztettük. A Minősítés a múltra vonatkozó
Bisnode Minősítés A Bisnode Minősítést a lehető legkorszerűbb, szofisztikált matematikai-statisztikai módszertannal, hazai és nemzetközi szakértők bevonásával fejlesztettük. A Minősítés a múltra vonatkozó
4. LECKE: DÖNTÉSI FÁK - OSZTÁLYOZÁS II. -- Előadás. 4.1. Döntési fák [Concepts Chapter 11]
![4. LECKE: DÖNTÉSI FÁK - OSZTÁLYOZÁS II. -- Előadás. 4.1. Döntési fák [Concepts Chapter 11]](/thumbs/34/17147027.jpg "4. LECKE: DÖNTÉSI FÁK - OSZTÁLYOZÁS II. -- Előadás. 4.1. Döntési fák [Concepts Chapter 11]") 1 4. LECKE: DÖNTÉSI FÁK - OSZTÁLYOZÁS II. -- Előadás 4.1. Döntési fák [Concepts Chapter 11] A döntési fákon alapuló klasszifikációs eljárás nagy előnye, hogy az alkalmazása révén nemcsak egyedenkénti előrejelzést
1 4. LECKE: DÖNTÉSI FÁK - OSZTÁLYOZÁS II. -- Előadás 4.1. Döntési fák [Concepts Chapter 11] A döntési fákon alapuló klasszifikációs eljárás nagy előnye, hogy az alkalmazása révén nemcsak egyedenkénti előrejelzést
Csima Judit február 19.
 Osztályozás Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2018. február 19. Csima Judit Osztályozás 1 / 53 Osztályozás általában Osztályozás, classification adott egy rekordokból
Osztályozás Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2018. február 19. Csima Judit Osztályozás 1 / 53 Osztályozás általában Osztályozás, classification adott egy rekordokból
Gyors sikerek adatbányászati módszerekkel
 Gyors sikerek adatbányászati módszerekkel Kezdő adatbányászati workshop Petrócziné Huczman Zsuzsanna 2015.10.13. Bemutatkozás BME, műszaki informatika szak, adatbányászati szakirány Citibank Data Explorer
Gyors sikerek adatbányászati módszerekkel Kezdő adatbányászati workshop Petrócziné Huczman Zsuzsanna 2015.10.13. Bemutatkozás BME, műszaki informatika szak, adatbányászati szakirány Citibank Data Explorer
Így kampányolunk mi. Hans Zoltán. Szolgáltatás Fejlesztés és Online Irányítás vezető. IBM-SPSS üzleti reggeli (Budapest) 2010.09.22.
 2010.09.22.") Így kampányolunk mi Hans Zoltán Szolgáltatás Fejlesztés és Online Irányítás vezető IBM-SPSS üzleti reggeli (Budapest) 2010.09.22. LIFE INSURANCE PENSION INVESTMENT Tartalom AEGON Útkeresések Esettanulmány
Így kampányolunk mi Hans Zoltán Szolgáltatás Fejlesztés és Online Irányítás vezető IBM-SPSS üzleti reggeli (Budapest) 2010.09.22. LIFE INSURANCE PENSION INVESTMENT Tartalom AEGON Útkeresések Esettanulmány
ADATBÁNYÁSZAT AZ AUTÓIPARI TERMÉKEK FEJLESZTÉSÉBEN
 ADATBÁNYÁSZAT AZ AUTÓIPARI TERMÉKEK FEJLESZTÉSÉBEN Zámborszky Judit 2019.05.14. Adatbányászat az autóipari termékek fejlesztésében Industry 4.0 Ipar 4.0 Ipari forradalmak: 1.: Gépek használata (gőzgép)
ADATBÁNYÁSZAT AZ AUTÓIPARI TERMÉKEK FEJLESZTÉSÉBEN Zámborszky Judit 2019.05.14. Adatbányászat az autóipari termékek fejlesztésében Industry 4.0 Ipar 4.0 Ipari forradalmak: 1.: Gépek használata (gőzgép)
Nagy adathalmazok labor
 1 Nagy adathalmazok labor 2015-2015 őszi félév 2015.09.09 1. Bevezetés, adminisztráció 2. Osztályozás és klaszterezés feladata 2 Elérhetőségek Daróczy Bálint daroczyb@ilab.sztaki.hu Személyesen: MTA SZTAKI,
1 Nagy adathalmazok labor 2015-2015 őszi félév 2015.09.09 1. Bevezetés, adminisztráció 2. Osztályozás és klaszterezés feladata 2 Elérhetőségek Daróczy Bálint daroczyb@ilab.sztaki.hu Személyesen: MTA SZTAKI,
Diagnosztikus tesztek értékelése
 n e c n b c szegregancia relevancia Diagnosztikus tesztek értékelése c Átlapoló eloszlások feltételezés: egy mérhető mennyiség (pl. koncentráció) megnövekszik a populációban (a megváltozás a lényeges és
n e c n b c szegregancia relevancia Diagnosztikus tesztek értékelése c Átlapoló eloszlások feltételezés: egy mérhető mennyiség (pl. koncentráció) megnövekszik a populációban (a megváltozás a lényeges és
Gyors sikerek adatbányászati módszerekkel
 Gyors sikerek adatbányászati módszerekkel Kezdő adatbányászati workshop Petrócziné Huczman Zsuzsanna Tajti András 2016.10.25. Petrócziné Huczman Zsuzsanna Andego Tanácsadó Kft. PBA, KÖBE, Fókusz Takarék,
Gyors sikerek adatbányászati módszerekkel Kezdő adatbányászati workshop Petrócziné Huczman Zsuzsanna Tajti András 2016.10.25. Petrócziné Huczman Zsuzsanna Andego Tanácsadó Kft. PBA, KÖBE, Fókusz Takarék,
Retro adatbányászat. Kovács Gyula Andego Tanácsadó Kft.
 Retro adatbányászat Kovács Gyula Andego Tanácsadó Kft. Adattárház Fórum 2012 Magunkról 2010-ben alapították magánszemélyek (az alapítók több mint egy évtizedes BI tapasztalatokkal rendelkeznek) Andego
Retro adatbányászat Kovács Gyula Andego Tanácsadó Kft. Adattárház Fórum 2012 Magunkról 2010-ben alapították magánszemélyek (az alapítók több mint egy évtizedes BI tapasztalatokkal rendelkeznek) Andego
Regresszió. Csorba János. Nagyméretű adathalmazok kezelése március 31.
 Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Regresszió Csorba János Nagyméretű adathalmazok kezelése 2010. március 31. A feladat X magyarázó attribútumok halmaza Y magyarázandó attribútumok) Kérdés: f : X -> Y a kapcsolat pár tanítópontban ismert
Deep Learning a gyakorlatban Python és LUA alapon Felhasználói viselkedés modellezés
 Gyires-Tóth Bálint Deep Learning a gyakorlatban Python és LUA alapon Felhasználói viselkedés modellezés http://smartlab.tmit.bme.hu Modellezés célja A telefon szenzoradatai alapján egy általános viselkedési
Gyires-Tóth Bálint Deep Learning a gyakorlatban Python és LUA alapon Felhasználói viselkedés modellezés http://smartlab.tmit.bme.hu Modellezés célja A telefon szenzoradatai alapján egy általános viselkedési
LOGIT-REGRESSZIÓ a függő változó: névleges vagy sorrendi skála
 LOGIT-REGRESSZIÓ a függő változó: névleges vagy sorrendi skála a független változó: névleges vagy sorrendi vagy folytonos skála BIOMETRIA2_NEMPARAMÉTERES_5 1 Y: visszafizeti-e a hitelt x: fizetés (életkor)
LOGIT-REGRESSZIÓ a függő változó: névleges vagy sorrendi skála a független változó: névleges vagy sorrendi vagy folytonos skála BIOMETRIA2_NEMPARAMÉTERES_5 1 Y: visszafizeti-e a hitelt x: fizetés (életkor)
Modellezési Kockázat. Kereskedelmi Banki Kockázatmodellezés. Molnár Márton Modellezési Vezető (Kockázatkezelés)
") Modellezési Kockázat Kereskedelmi Banki Kockázatmodellezés Molnár Márton Modellezési Vezető (Kockázatkezelés) Modellek Kockázata Adathibák Szabályozói elvárások figyelmen kívül hagyása Becslési Bizonytalanság
Modellezési Kockázat Kereskedelmi Banki Kockázatmodellezés Molnár Márton Modellezési Vezető (Kockázatkezelés) Modellek Kockázata Adathibák Szabályozói elvárások figyelmen kívül hagyása Becslési Bizonytalanság
Gépi tanulás a gyakorlatban. Kiértékelés és Klaszterezés
 Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Gépi tanulás a gyakorlatban Kiértékelés és Klaszterezés Hogyan alkalmazzuk sikeresen a gépi tanuló módszereket? Hogyan válasszuk az algoritmusokat? Hogyan hangoljuk a paramétereiket? Precízebben: Tegyük
Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl sok szelet se legyen.
 KEMOMETRIA VIII-1/27 /2013 ősz CART Classification and Regression Trees Osztályozó fák Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl
KEMOMETRIA VIII-1/27 /2013 ősz CART Classification and Regression Trees Osztályozó fák Szeleteljük fel úgy a tulajdonságteret, hogy az egyes szeletekbe lehetőleg egyfajta objektumok kerüljenek, de túl
Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására
 VÉGZŐS KONFERENCIA 2009 2009. május 20, Budapest Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására Hidasi Balázs hidasi@tmit.bme.hu Konzulens: Gáspár-Papanek Csaba Budapesti
VÉGZŐS KONFERENCIA 2009 2009. május 20, Budapest Újfajta, automatikus, döntési fa alapú adatbányászati módszer idősorok osztályozására Hidasi Balázs hidasi@tmit.bme.hu Konzulens: Gáspár-Papanek Csaba Budapesti
Adatbányászat az Oracle9i-ben. Fekete Zoltán vezető termékmenedzser Zoltan.Fekete@oracle.com
 Agenda Az Oracle9i adattárház tulajdonságai Adatbányászat az Oracle9i-ben DM, Personalization az Oracle9i-ben, architektúra Integrált adatbányászat az Oracle CRM-ben Szünet Perszonalizációs felhasználási
Agenda Az Oracle9i adattárház tulajdonságai Adatbányászat az Oracle9i-ben DM, Personalization az Oracle9i-ben, architektúra Integrált adatbányászat az Oracle CRM-ben Szünet Perszonalizációs felhasználási
Szomszédság alapú ajánló rendszerek
 Nagyméretű adathalmazok kezelése Szomszédság alapú ajánló rendszerek Készítette: Szabó Máté A rendelkezésre álló adatmennyiség növelésével egyre nehezebb kiválogatni a hasznos információkat Megoldás: ajánló
Nagyméretű adathalmazok kezelése Szomszédság alapú ajánló rendszerek Készítette: Szabó Máté A rendelkezésre álló adatmennyiség növelésével egyre nehezebb kiválogatni a hasznos információkat Megoldás: ajánló
Közösségi kezdeményezéseket megalapozó szükségletfeltárás módszertana. Domokos Tamás, módszertani igazgató
 Közösségi kezdeményezéseket megalapozó szükségletfeltárás módszertana Domokos Tamás, módszertani igazgató A helyzetfeltárás célja A közösségi kezdeményezéshez kapcsolódó kutatások célja elsősorban felderítés,
Közösségi kezdeményezéseket megalapozó szükségletfeltárás módszertana Domokos Tamás, módszertani igazgató A helyzetfeltárás célja A közösségi kezdeményezéshez kapcsolódó kutatások célja elsősorban felderítés,
MÓDSZERTANI ESETTANULMÁNY. isk_4kat végzettségek négy katban. Frequency Percent Valid Percent. Valid 1 legfeljebb 8 osztály ,2 43,7 43,7
 MÓDSZERTANI ESETTANULMÁNY 1. Az elemzés kérdésfeltevése Egy 2009-es kutatásban (pszichiátriai ellátásban szociális lévők körében) attitűdöket vizsgáltunk, melyből a foglalkoztatás egyes modelljeinek egészségmegóvó
MÓDSZERTANI ESETTANULMÁNY 1. Az elemzés kérdésfeltevése Egy 2009-es kutatásban (pszichiátriai ellátásban szociális lévők körében) attitűdöket vizsgáltunk, melyből a foglalkoztatás egyes modelljeinek egészségmegóvó
5. LECKE: TÁMASZVEKTOROK (SVM, Support Vector Machines)
") 5. LECKE: TÁMASZVEKTOROK (SVM, Support Vector Machines) -- Előadás 5.1. Támaszvektor osztályozásra [C18] Ez a témakör a klasszifikációhoz áll legközelebb, bár alkalmazható más területeken is (regresszió,
5. LECKE: TÁMASZVEKTOROK (SVM, Support Vector Machines) -- Előadás 5.1. Támaszvektor osztályozásra [C18] Ez a témakör a klasszifikációhoz áll legközelebb, bár alkalmazható más területeken is (regresszió,
Logisztikus regresszió
 Logisztikus regresszió 9. előadás Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó () Nem metrikus Metrikus Kereszttábla
Logisztikus regresszió 9. előadás Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó () Nem metrikus Metrikus Kereszttábla
IBM SPSS Modeler 18.2 Újdonságok
 IBM SPSS Modeler 18.2 Újdonságok 1 2 Új, modern megjelenés Vizualizáció fejlesztése Újabb algoritmusok (Python, Spark alapú) View Data, t-sne, e-plot GMM, HDBSCAN, KDE, Isotonic-Regression 3 Új, modern
IBM SPSS Modeler 18.2 Újdonságok 1 2 Új, modern megjelenés Vizualizáció fejlesztése Újabb algoritmusok (Python, Spark alapú) View Data, t-sne, e-plot GMM, HDBSCAN, KDE, Isotonic-Regression 3 Új, modern
A gép az ember tükre, avagy hogyan (ne) adjuk át saját előítéleteinket a mesterséges értelemnek
 adjuk át saját előítéleteinket a mesterséges értelemnek") A gép az ember tükre, avagy hogyan (ne) adjuk át saját előítéleteinket a mesterséges értelemnek Varjú Zoltán 2018.05.22. HWSW Meetup ML Engineering Rules of Machine Learning #1 Don t be afraid to launch
A gép az ember tükre, avagy hogyan (ne) adjuk át saját előítéleteinket a mesterséges értelemnek Varjú Zoltán 2018.05.22. HWSW Meetup ML Engineering Rules of Machine Learning #1 Don t be afraid to launch
Csima Judit február 26.
 Osztályozás Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2014. február 26. Csima Judit Osztályozás 1 / 60 Osztályozás általában Osztályozás, classification adott egy rekordokból
Osztályozás Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2014. február 26. Csima Judit Osztályozás 1 / 60 Osztályozás általában Osztályozás, classification adott egy rekordokból
Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés
 Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés 4. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Logók és támogatás A tananyag a TÁMOP-4.1.2-08/1/A-2009-0046
Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés 4. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Logók és támogatás A tananyag a TÁMOP-4.1.2-08/1/A-2009-0046
Copyright 2012, Oracle and/or its affiliates. All rights reserved.
 1 Oracle Felhő Alkalmazások: Gyorsabb eredmények alacsonyabb kockázattal Biber Attila Igazgató Alkalmazások Divízió 2 M I L L I Á RD 4 1 PERC MINDEN 5 PERCBŐL 5 6 Ember használ mobilt 7 FELHŐ SZOLGÁLTATÁS
1 Oracle Felhő Alkalmazások: Gyorsabb eredmények alacsonyabb kockázattal Biber Attila Igazgató Alkalmazások Divízió 2 M I L L I Á RD 4 1 PERC MINDEN 5 PERCBŐL 5 6 Ember használ mobilt 7 FELHŐ SZOLGÁLTATÁS
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 10 X. SZIMULÁCIÓ 1. VÉLETLEN számok A véletlen számok fontos szerepet játszanak a véletlen helyzetek generálásában (pénzérme, dobókocka,
MagyarBrands kutatás 2017
 MagyarBrands kutatás 2017 A kutatási program leírása GfK, 2017. 1 A kutatás módszertana Lakossági Magyarbrands márkák mérése Módszertan: Online önkitöltős (CAWI) megkérdezés GfK Hungária online paneltagjainak
MagyarBrands kutatás 2017 A kutatási program leírása GfK, 2017. 1 A kutatás módszertana Lakossági Magyarbrands márkák mérése Módszertan: Online önkitöltős (CAWI) megkérdezés GfK Hungária online paneltagjainak
Módszertani áttekintés
 Módszertani áttekintés 1. A CSŐDMODELLEKNÉL ALKALMAZOTT STATISZTIKAI MÓDSZEREK... 1 1.1. DISZKRIMINANCIA ANALÍZIS... 1 1.2. REGRESSZIÓS MODELLEK... 3 1.2.1. Logisztikus (logit) regresszió... 4 1.2.2. Probit
Módszertani áttekintés 1. A CSŐDMODELLEKNÉL ALKALMAZOTT STATISZTIKAI MÓDSZEREK... 1 1.1. DISZKRIMINANCIA ANALÍZIS... 1 1.2. REGRESSZIÓS MODELLEK... 3 1.2.1. Logisztikus (logit) regresszió... 4 1.2.2. Probit
Fehér Tamás, Hofgesang Péter T-Systems Magyarország. Adócsalók a RADAR képernyőjén
 Fehér Tamás, Hofgesang Péter T-Systems Magyarország Adócsalók a RADAR képernyőjén Adatbányászat A sör és pelenka elhelyezésétől a twitterezők hangulatának elemzéséig NAV-előzmények Igény Egy olyan rendszer
Fehér Tamás, Hofgesang Péter T-Systems Magyarország Adócsalók a RADAR képernyőjén Adatbányászat A sör és pelenka elhelyezésétől a twitterezők hangulatának elemzéséig NAV-előzmények Igény Egy olyan rendszer
Megerősítéses tanulás
 Megerősítéses tanulás elméleti kognitív neurális Introduction Knowledge representation Probabilistic models Bayesian behaviour Approximate inference I (computer lab) Vision I Approximate inference II:
Megerősítéses tanulás elméleti kognitív neurális Introduction Knowledge representation Probabilistic models Bayesian behaviour Approximate inference I (computer lab) Vision I Approximate inference II:
II. rész: a rendszer felülvizsgálati stratégia kidolgozását támogató funkciói. Tóth László, Lenkeyné Biró Gyöngyvér, Kuczogi László
 A kockázat alapú felülvizsgálati és karbantartási stratégia alkalmazása a MOL Rt.-nél megvalósuló Statikus Készülékek Állapot-felügyeleti Rendszerének kialakításában II. rész: a rendszer felülvizsgálati
A kockázat alapú felülvizsgálati és karbantartási stratégia alkalmazása a MOL Rt.-nél megvalósuló Statikus Készülékek Állapot-felügyeleti Rendszerének kialakításában II. rész: a rendszer felülvizsgálati
Matematikai statisztika c. tárgy oktatásának célja és tematikája
 Matematikai statisztika c. tárgy oktatásának célja és tematikája 2015 Tematika Matematikai statisztika 1. Időkeret: 12 héten keresztül heti 3x50 perc (előadás és szeminárium) 2. Szükséges előismeretek:
Matematikai statisztika c. tárgy oktatásának célja és tematikája 2015 Tematika Matematikai statisztika 1. Időkeret: 12 héten keresztül heti 3x50 perc (előadás és szeminárium) 2. Szükséges előismeretek:
Statisztika I. 4. előadás Mintavétel. Kóczy Á. László KGK-VMI. Minta Mintavétel Feladatok. http://uni-obuda.hu/users/koczyl/statisztika1.
 Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
IV.7 MÓDSZER KIDOLGOZÁSA FELHASZNÁLÓI ADATOK VÉDELMÉRE MOBIL ALKALMAZÁSOK ESETÉN
 infokommunikációs technológiák IV.7 MÓDSZER KIDOLGOZÁSA FELHASZNÁLÓI ADATOK VÉDELMÉRE MOBIL ALKALMAZÁSOK ESETÉN ANTAL Margit, SZABÓ László Zsolt 2015, január 8. BEVEZETÉS A KUTATÁS CÉLJA A felhasználó
infokommunikációs technológiák IV.7 MÓDSZER KIDOLGOZÁSA FELHASZNÁLÓI ADATOK VÉDELMÉRE MOBIL ALKALMAZÁSOK ESETÉN ANTAL Margit, SZABÓ László Zsolt 2015, január 8. BEVEZETÉS A KUTATÁS CÉLJA A felhasználó
Nagy adathalmazok labor
 1 Nagy adathalmazok labor 2018-2019 őszi félév 2018.09.12-13 1. Kiértékelés 2. Döntési fák 3. Ipython notebook notebook 2 Féléves terv o Kiértékelés: cross-validation, bias-variance trade-off o Supervised
1 Nagy adathalmazok labor 2018-2019 őszi félév 2018.09.12-13 1. Kiértékelés 2. Döntési fák 3. Ipython notebook notebook 2 Féléves terv o Kiértékelés: cross-validation, bias-variance trade-off o Supervised
Az adatelemző felelőssége tapasztalatok a biztosítási analitikában
 Az adatelemző felelőssége tapasztalatok a biztosítási analitikában Szabó Dániel Advanced Analytics team vezető Budapest, 2018. június 14. Segítünk az embereknek anyagi biztonságot teremteni egy életen
Az adatelemző felelőssége tapasztalatok a biztosítási analitikában Szabó Dániel Advanced Analytics team vezető Budapest, 2018. június 14. Segítünk az embereknek anyagi biztonságot teremteni egy életen
Csalásfelderítés hálózatokon keresztül. Innovatív BI konferencia, Budapest, 2011. 11. 22.
 Csalásfelderítés hálózatokon keresztül Innovatív BI konferencia, Budapest, 2011. 11. 22. Hans Zoltán AEGON Magyarország Szolgáltatás Fejlesztés és Online Irányítás Vezető Benczúr András MTA SZTAKI Informatika
Csalásfelderítés hálózatokon keresztül Innovatív BI konferencia, Budapest, 2011. 11. 22. Hans Zoltán AEGON Magyarország Szolgáltatás Fejlesztés és Online Irányítás Vezető Benczúr András MTA SZTAKI Informatika
Statisztika I. 4. előadás Mintavétel. Kóczy Á. László KGK-VMI. Minta Mintavétel Feladatok. http://uni-obuda.hu/users/koczyl/statisztika1.
 Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
Statisztika I. 4. előadás Mintavétel http://uni-obuda.hu/users/koczyl/statisztika1.htm Kóczy Á. László KGK-VMI koczy.laszlo@kgk.uni-obuda.hu Sokaság és minta Alap- és mintasokaság A mintasokaság az a részsokaság,
Hipotézis, sejtés STATISZTIKA. Kétmintás hipotézisek. Tudományos hipotézis. Munkahipotézis (H a ) Nullhipotézis (H 0 ) 11. Előadás
 Nullhipotézis (H 0 ) 11. Előadás") STATISZTIKA Hipotézis, sejtés 11. Előadás Hipotézisvizsgálatok, nem paraméteres próbák Tudományos hipotézis Nullhipotézis felállítása (H 0 ): Kétmintás hipotézisek Munkahipotézis (H a ) Nullhipotézis (H
STATISZTIKA Hipotézis, sejtés 11. Előadás Hipotézisvizsgálatok, nem paraméteres próbák Tudományos hipotézis Nullhipotézis felállítása (H 0 ): Kétmintás hipotézisek Munkahipotézis (H a ) Nullhipotézis (H
 MKKV ügyfelek adósminősítő modelljének fejlesztése RapidMiner a TakarékBankban Frindt Anna Magyar Takarékszövetkezeti Bank Zrt. 1 Budapest, 2011.10.06. A Takarékbank és a Takarékszövetkezetek/Bankok 1989
MKKV ügyfelek adósminősítő modelljének fejlesztése RapidMiner a TakarékBankban Frindt Anna Magyar Takarékszövetkezeti Bank Zrt. 1 Budapest, 2011.10.06. A Takarékbank és a Takarékszövetkezetek/Bankok 1989
Mi a big data? ML? AI? DS? Az adatelemzés szintjei CRISP-DM módszertan. GUI Enterprise eszközök Programozási nyelvek
 Mi a big data? ML? AI? DS? Az adatelemzés szintjei CRISP-DM módszertan GUI Enterprise eszközök Programozási nyelvek 800-1300 800-2000 McKinsey Global Institute, 2011 Egy magyar fejvadászcég tapasztalatai
Mi a big data? ML? AI? DS? Az adatelemzés szintjei CRISP-DM módszertan GUI Enterprise eszközök Programozási nyelvek 800-1300 800-2000 McKinsey Global Institute, 2011 Egy magyar fejvadászcég tapasztalatai
Hipotézis STATISZTIKA. Kétmintás hipotézisek. Munkahipotézis (H a ) Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok
 Tematika. Tudományos hipotézis. 1. Előadás. Hipotézisvizsgálatok") STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
STATISZTIKA 1. Előadás Hipotézisvizsgálatok Tematika 1. Hipotézis vizsgálatok 2. t-próbák 3. Variancia-analízis 4. A variancia-analízis validálása, erőfüggvény 5. Korreláció számítás 6. Kétváltozós lineáris
Neurális hálózatok bemutató
 Neurális hálózatok bemutató Füvesi Viktor Miskolci Egyetem Alkalmazott Földtudományi Kutatóintézet Miért? Vannak feladatok amelyeket az agy gyorsabban hajt végre mint a konvencionális számítógépek. Pl.:
Neurális hálózatok bemutató Füvesi Viktor Miskolci Egyetem Alkalmazott Földtudományi Kutatóintézet Miért? Vannak feladatok amelyeket az agy gyorsabban hajt végre mint a konvencionális számítógépek. Pl.:
Adatelemzés őszi félév ,26,27 1. Bevezetés 2. Osztályozás és klaszterezés feladata 3. Numpy és Ipython 4. Logisztikus regresszió
 1 Adatelemzés 2017-2018 őszi félév 2018.03.19,26,27 1. Bevezetés 2. Osztályozás és klaszterezés feladata 3. Numpy és Ipython 4. Logisztikus regresszió 2 Elérhetőségek Daróczy Bálint daroczyb@ilab.sztaki.hu
1 Adatelemzés 2017-2018 őszi félév 2018.03.19,26,27 1. Bevezetés 2. Osztályozás és klaszterezés feladata 3. Numpy és Ipython 4. Logisztikus regresszió 2 Elérhetőségek Daróczy Bálint daroczyb@ilab.sztaki.hu
Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés
 Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés 4. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Tan,Steinbach, Kumar Bevezetés az
Adatbányászat: Osztályozás Alapfogalmak, döntési fák, kiértékelés 4. fejezet Tan, Steinbach, Kumar Bevezetés az adatbányászatba előadás-fóliák fordította Ispány Márton Tan,Steinbach, Kumar Bevezetés az
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI
 FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
FEGYVERNEKI SÁNDOR, Valószínűség-sZÁMÍTÁs És MATEMATIKAI statisztika 4 IV. MINTA, ALAPsTATIsZTIKÁK 1. MATEMATIKAI statisztika A matematikai statisztika alapfeladatát nagy általánosságban a következőképpen
Loss Distribution Approach
 Modeling operational risk using the Loss Distribution Approach Tartalom»Szabályozói környezet»modellezési struktúra»eseményszám eloszlás»káreloszlás»aggregált veszteségek»további problémák 2 Szabályozói
Modeling operational risk using the Loss Distribution Approach Tartalom»Szabályozói környezet»modellezési struktúra»eseményszám eloszlás»káreloszlás»aggregált veszteségek»további problémák 2 Szabályozói
A tudás handrendbe állítása, azaz SPSS PES
 A tudás handrendbe állítása, azaz SPSS PES...és hogyan történt mindez a Vodafone Hungary Zrt-nél Cseh Zoltán, PhD konzultációs igazgató SPSS Hungary Hagyományos hadászati egységek Légi elhárítás Gyalogság
A tudás handrendbe állítása, azaz SPSS PES...és hogyan történt mindez a Vodafone Hungary Zrt-nél Cseh Zoltán, PhD konzultációs igazgató SPSS Hungary Hagyományos hadászati egységek Légi elhárítás Gyalogság
Véletlenszám generátorok és tesztelésük. Tossenberger Tamás
 Véletlenszám generátorok és tesztelésük Tossenberger Tamás Érdekességek Pénzérme feldobó gép: $0,25-os érme 1/6000 valószínűséggel esik az élére 51% eséllyel érkezik a felfelé mutató oldalára Pörgetésnél
Véletlenszám generátorok és tesztelésük Tossenberger Tamás Érdekességek Pénzérme feldobó gép: $0,25-os érme 1/6000 valószínűséggel esik az élére 51% eséllyel érkezik a felfelé mutató oldalára Pörgetésnél
Adatbányászat és Perszonalizáció architektúra
 Adatbányászat és Perszonalizáció architektúra Oracle9i Teljes e-üzleti intelligencia infrastruktúra Oracle9i Database Integrált üzleti intelligencia szerver Data Warehouse ETL OLAP Data Mining M e t a
Adatbányászat és Perszonalizáció architektúra Oracle9i Teljes e-üzleti intelligencia infrastruktúra Oracle9i Database Integrált üzleti intelligencia szerver Data Warehouse ETL OLAP Data Mining M e t a
A 9001:2015 a kockázatközpontú megközelítést követi
 A 9001:2015 a kockázatközpontú megközelítést követi Tartalom n Kockázat vs. megelőzés n A kockázat fogalma n Hol található a kockázat az új szabványban? n Kritikus megjegyzések n Körlevél n Megvalósítás
A 9001:2015 a kockázatközpontú megközelítést követi Tartalom n Kockázat vs. megelőzés n A kockázat fogalma n Hol található a kockázat az új szabványban? n Kritikus megjegyzések n Körlevél n Megvalósítás
Soltész Gábor. Önéletrajz Budapest, Lechner Ödön fasor em 26. a.
 Soltész Gábor Önéletrajz SZEMÉLYI ADATOK Születési dátum: 1983.07.09 Születési hely: Lakcím: Dunaújváros 1095 Budapest, Lechner Ödön fasor 1. 2. em 26. a Telefonszám: +36/20-466-7553 Email: Weboldal: solteszgabor@solteszgabor.com
Soltész Gábor Önéletrajz SZEMÉLYI ADATOK Születési dátum: 1983.07.09 Születési hely: Lakcím: Dunaújváros 1095 Budapest, Lechner Ödön fasor 1. 2. em 26. a Telefonszám: +36/20-466-7553 Email: Weboldal: solteszgabor@solteszgabor.com
Véletlenszám generátorok és tesztelésük HORVÁTH BÁLINT
 Véletlenszám generátorok és tesztelésük HORVÁTH BÁLINT Mi a véletlen? Determinisztikus vs. Véletlen esemény? Véletlenszám: számok sorozata, ahol véletlenszerűen követik egymást az elemek Pszeudo-véletlenszám
Véletlenszám generátorok és tesztelésük HORVÁTH BÁLINT Mi a véletlen? Determinisztikus vs. Véletlen esemény? Véletlenszám: számok sorozata, ahol véletlenszerűen követik egymást az elemek Pszeudo-véletlenszám
AZ IGAZI BIG DATA hogyan használják a világban és egyáltalán használják-e hazánkban?
 AZ IGAZI BIG DATA hogyan használják a világban és egyáltalán használják-e hazánkban? Médiapiac 2015 Eger, 2015.03.18 Dévényi Edit Dunai Albert K&H Bank és Biztosító 1 Nem értek hozzá! Mi tart vissza? Túl
AZ IGAZI BIG DATA hogyan használják a világban és egyáltalán használják-e hazánkban? Médiapiac 2015 Eger, 2015.03.18 Dévényi Edit Dunai Albert K&H Bank és Biztosító 1 Nem értek hozzá! Mi tart vissza? Túl
CEBS Consultative Paper 10 (folytatás) Krekó Béla PSZÁF, 2005. szeptember 15.
 Krekó Béla PSZÁF, 2005. szeptember 15.") CEBS Consultative Paper 10 (folytatás) Krekó Béla PSZÁF, 2005. szeptember 15. 1 3.3.3 Minősítési rendszerek és a kockázatok számszerűsítése Minősítések hozzárendelése PD, LGD, CF meghatározása Közös vizsgálati
CEBS Consultative Paper 10 (folytatás) Krekó Béla PSZÁF, 2005. szeptember 15. 1 3.3.3 Minősítési rendszerek és a kockázatok számszerűsítése Minősítések hozzárendelése PD, LGD, CF meghatározása Közös vizsgálati
Adatbányászat a felhőben
 Adatbányászat a felhőben Kovács Gyula Andego Tanácsadó Kft. 2012 II. Innovatív BI Konferencia Magunkról 2010-ben alapították magánszemélyek (az alapítók több mint egy évtizedes BI tapasztalatokkal rendelkeznek)
Adatbányászat a felhőben Kovács Gyula Andego Tanácsadó Kft. 2012 II. Innovatív BI Konferencia Magunkról 2010-ben alapították magánszemélyek (az alapítók több mint egy évtizedes BI tapasztalatokkal rendelkeznek)
Vajda Éva. Bevezetés a keresőmarketingbe
 Vajda Éva Bevezetés a keresőmarketingbe Alapfogalmak Fizetett hivatkozások - hirdetés Organikus találatok - ki kell "érdemelni" jó honlappal Organikus vs fizetett hivatkozás Organikus - keresőoptimalizálás
Vajda Éva Bevezetés a keresőmarketingbe Alapfogalmak Fizetett hivatkozások - hirdetés Organikus találatok - ki kell "érdemelni" jó honlappal Organikus vs fizetett hivatkozás Organikus - keresőoptimalizálás
E x μ x μ K I. és 1. osztály. pontokként), valamint a bayesi döntést megvalósító szeparáló görbét (kék egyenes)
, valamint a bayesi döntést megvalósító szeparáló görbét (kék egyenes)") 6-7 ősz. gyakorlat Feladatok.) Adjon meg azt a perceptronon implementált Bayes-i klasszifikátort, amely kétdimenziós a bemeneti tér felett szeparálja a Gauss eloszlású mintákat! Rajzolja le a bemeneti
6-7 ősz. gyakorlat Feladatok.) Adjon meg azt a perceptronon implementált Bayes-i klasszifikátort, amely kétdimenziós a bemeneti tér felett szeparálja a Gauss eloszlású mintákat! Rajzolja le a bemeneti
Modellkiválasztás és struktúrák tanulása
 Modellkiválasztás és struktúrák tanulása Szervezőelvek keresése Az unsupervised learning egyik fő célja Optimális reprezentációk Magyarázatok Predikciók Az emberi tanulás alapja Általános strukturális
Modellkiválasztás és struktúrák tanulása Szervezőelvek keresése Az unsupervised learning egyik fő célja Optimális reprezentációk Magyarázatok Predikciók Az emberi tanulás alapja Általános strukturális
Algoritmusok Tervezése. 6. Előadás Algoritmusok 101 Dr. Bécsi Tamás
 Algoritmusok Tervezése 6. Előadás Algoritmusok 101 Dr. Bécsi Tamás Mi az algoritmus? Lépések sorozata egy feladat elvégzéséhez (legáltalánosabban) Informálisan algoritmusnak nevezünk bármilyen jól definiált
Algoritmusok Tervezése 6. Előadás Algoritmusok 101 Dr. Bécsi Tamás Mi az algoritmus? Lépések sorozata egy feladat elvégzéséhez (legáltalánosabban) Informálisan algoritmusnak nevezünk bármilyen jól definiált
biometria II. foglalkozás előadó: Prof. Dr. Rajkó Róbert Matematikai-statisztikai adatfeldolgozás
 Kísérlettervezés - biometria II. foglalkozás előadó: Prof. Dr. Rajkó Róbert Matematikai-statisztikai adatfeldolgozás A matematikai-statisztika feladata tapasztalati adatok feldolgozásával segítséget nyújtani
Kísérlettervezés - biometria II. foglalkozás előadó: Prof. Dr. Rajkó Róbert Matematikai-statisztikai adatfeldolgozás A matematikai-statisztika feladata tapasztalati adatok feldolgozásával segítséget nyújtani
A szak specializációi
 A szak specializációi Specializációk A specializációválasztás során a hallgatónak preferenciasorrendet kell megjelölnie, legalább két specializáció megadásával. A specializációkra történő besorolás a hallgatók
A szak specializációi Specializációk A specializációválasztás során a hallgatónak preferenciasorrendet kell megjelölnie, legalább két specializáció megadásával. A specializációkra történő besorolás a hallgatók
Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok
 Zrínyi Miklós Gimnázium Művészet és tudomány napja Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok 10/9/2009 Dr. Viharos Zsolt János Elsősorban volt Zrínyis diák Tudományos főmunkatárs
Zrínyi Miklós Gimnázium Művészet és tudomány napja Tanulás tanuló gépek tanuló algoritmusok mesterséges neurális hálózatok 10/9/2009 Dr. Viharos Zsolt János Elsősorban volt Zrínyis diák Tudományos főmunkatárs
Döntési fák. (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART ))
)") Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
Döntési fák (Klasszifikációs és regressziós fák: (Classification And Regression Trees: CART )) Rekurzív osztályozó módszer, Klasszifikációs és regressziós fák folytonos, kategóriás, illetve túlélés adatok
OKM ISKOLAI EREDMÉNYEK
 OKM ISKOLAI EREDMÉNYEK Statisztikai alapfogalmak Item Statisztikai alapfogalmak Átlag Leggyakrabban: számtani átlag Egyetlen számadat jól jellemzi az eredményeket Óvatosan: elfed Statisztikai alapfogalmak
OKM ISKOLAI EREDMÉNYEK Statisztikai alapfogalmak Item Statisztikai alapfogalmak Átlag Leggyakrabban: számtani átlag Egyetlen számadat jól jellemzi az eredményeket Óvatosan: elfed Statisztikai alapfogalmak
Az értékelés során következtetést fogalmazhatunk meg a
 Az értékelés során következtetést fogalmazhatunk meg a a tanuló teljesítményére, a tanulási folyamatra, a célokra és követelményekre a szülők teljesítményére, a tanulási folyamatra, a célokra és követelményekre
Az értékelés során következtetést fogalmazhatunk meg a a tanuló teljesítményére, a tanulási folyamatra, a célokra és követelményekre a szülők teljesítményére, a tanulási folyamatra, a célokra és követelményekre
Logisztikus regresszió
 Logisztikus regresszió Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó (x) Nem metrikus Metrikus Kereszttábla elemzés
Logisztikus regresszió Kvantitatív statisztikai módszerek Dr. Szilágyi Roland Függő változó (y) Nem metrikus Metri kus Gazdaságtudományi Kar Független változó (x) Nem metrikus Metrikus Kereszttábla elemzés
Nyílt forráskód, mint üzleti előny. Szücs Imre VTMSZ - CMC Minősítési előadás 2013.03.05. Ha valamit érdemes csinálni, akkor azt megéri jól csinálni
 Nyílt forráskód, mint üzleti előny Szücs Imre VTMSZ - CMC Minősítési előadás 2013.03.05 Ha valamit érdemes csinálni, akkor azt megéri jól csinálni 1 Open source Első kérdések Forráskóddal kell dolgoznom?
Nyílt forráskód, mint üzleti előny Szücs Imre VTMSZ - CMC Minősítési előadás 2013.03.05 Ha valamit érdemes csinálni, akkor azt megéri jól csinálni 1 Open source Első kérdések Forráskóddal kell dolgoznom?
Intelligens adatelemzés
 Antal Péter, Antos András, Horváth Gábor, Hullám Gábor, Kocsis Imre, Marx Péter, Millinghoffer András, Pataricza András, Salánki Ágnes Intelligens adatelemzés Szerkesztette: Antal Péter A jegyzetben az
Antal Péter, Antos András, Horváth Gábor, Hullám Gábor, Kocsis Imre, Marx Péter, Millinghoffer András, Pataricza András, Salánki Ágnes Intelligens adatelemzés Szerkesztette: Antal Péter A jegyzetben az
Önértékelés IAIS alapon *
 Dr. ASZTALOS László György a PSZÁF Felügyeleti Tanácsának tagja Budapest 1013 Krisztina krt.39. T: 36/1/489-9350 Fax: 36/1/489-9352 E-mail: asztalos.laszlo@pszaf.hu 047/ALGY/2006 Önértékelés IAIS alapon
Dr. ASZTALOS László György a PSZÁF Felügyeleti Tanácsának tagja Budapest 1013 Krisztina krt.39. T: 36/1/489-9350 Fax: 36/1/489-9352 E-mail: asztalos.laszlo@pszaf.hu 047/ALGY/2006 Önértékelés IAIS alapon
Intelligens Rendszerek Elmélete. Versengéses és önszervező tanulás neurális hálózatokban
 Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Intelligens Rendszerek Elmélete : dr. Kutor László Versengéses és önszervező tanulás neurális hálózatokban http://mobil.nik.bmf.hu/tantargyak/ire.html Login név: ire jelszó: IRE07 IRE 9/1 Processzor Versengéses
Nemzetközi díjas fejlesztés: hatékonyság- és ügyfélelégedettség-növelés az Oktatási Hivatal hatósági eljárásaiban
 Fulfilling your vision is our mission Fulfilling your vision Nemzetközi díjas fejlesztés: hatékonyság- és ügyfélelégedettség-növelés az Oktatási Hivatal hatósági eljárásaiban Barackmagból atommag Lengyel
Fulfilling your vision is our mission Fulfilling your vision Nemzetközi díjas fejlesztés: hatékonyság- és ügyfélelégedettség-növelés az Oktatási Hivatal hatósági eljárásaiban Barackmagból atommag Lengyel
A hierarchikus adatbázis struktúra jellemzői
 A hierarchikus adatbázis struktúra jellemzői Az első adatbázis-kezelő rendszerek a hierarchikus modellen alapultak. Ennek az volt a magyarázata, hogy az élet sok területén első közelítésben elég jól lehet
A hierarchikus adatbázis struktúra jellemzői Az első adatbázis-kezelő rendszerek a hierarchikus modellen alapultak. Ennek az volt a magyarázata, hogy az élet sok területén első közelítésben elég jól lehet
Statisztika - bevezetés Méréselmélet PE MIK MI_BSc VI_BSc 1
 Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
Statisztika - bevezetés 00.04.05. Méréselmélet PE MIK MI_BSc VI_BSc Bevezetés Véletlen jelenség fogalma jelenséget okok bizonyos rendszere hozza létre ha mindegyik figyelembe vehető egyértelmű leírás általában
AZ INNOVÁCIÓS POTENCIÁL MÉRÉSE KIS- ÉS KÖZÉPVÁLLALKOZÁSOK SZÁMÁRA
 A Nyugat-dunántúli technológiai régió jövőképe és operatív programja workshop 2003. Június 4. AZ INNOVÁCIÓS POTENCIÁL MÉRÉSE KIS- ÉS KÖZÉPVÁLLALKOZÁSOK SZÁMÁRA BEMUTATKOZÁS 1991. Nemzetközi Technológiai
A Nyugat-dunántúli technológiai régió jövőképe és operatív programja workshop 2003. Június 4. AZ INNOVÁCIÓS POTENCIÁL MÉRÉSE KIS- ÉS KÖZÉPVÁLLALKOZÁSOK SZÁMÁRA BEMUTATKOZÁS 1991. Nemzetközi Technológiai
Adatbányászati technikák (VISZM185) 2015 tavasz
 2015 tavasz") Adatbányászati technikák (VISZM185) 2015 tavasz Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2015. február 11. Csima Judit Adatbányászati technikák (VISZM185) 2015 tavasz 1 / 27
Adatbányászati technikák (VISZM185) 2015 tavasz Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2015. február 11. Csima Judit Adatbányászati technikák (VISZM185) 2015 tavasz 1 / 27
Hatékony iteratív fejlesztési módszertan a gyakorlatban a RUP fejlesztési módszertanra építve
 Hatékony iteratív fejlesztési módszertan a gyakorlatban a RUP fejlesztési módszertanra építve Kérdő Attila, ügyvezető, INSERO Kft. EOQ MNB, Informatikai Szakosztály, HTE, ISACA 2012. május 17. Módszertanok
Hatékony iteratív fejlesztési módszertan a gyakorlatban a RUP fejlesztési módszertanra építve Kérdő Attila, ügyvezető, INSERO Kft. EOQ MNB, Informatikai Szakosztály, HTE, ISACA 2012. május 17. Módszertanok
Ökonometria. Logisztikus regresszió. Ferenci Tamás 1 Nyolcadik fejezet. Budapesti Corvinus Egyetem. 1 Statisztika Tanszék
 Ferenci Tamás 1 tamas.ferenci@medstat.hu 1 Statisztika Tanszék Budapesti Corvinus Egyetem Nyolcadik fejezet Tartalom V. esettanulmány 1 V. esettanulmány Csődelőrejelzés 2 Általános gondolatok 3 becslése
Ferenci Tamás 1 tamas.ferenci@medstat.hu 1 Statisztika Tanszék Budapesti Corvinus Egyetem Nyolcadik fejezet Tartalom V. esettanulmány 1 V. esettanulmány Csődelőrejelzés 2 Általános gondolatok 3 becslése
Módszertani Intézeti Tanszéki Osztály. A megoldás részletes mellékszámítások hiányában nem értékelhető!
 BGF KKK Módszertani Intézeti Tanszéki Osztály Budapest, 2012.. Név:... Neptun kód:... Érdemjegy:..... STATISZTIKA II. VIZSGADOLGOZAT Feladatok 1. 2. 3. 4. 5. 6. Összesen Szerezhető pontszám 21 20 7 22
BGF KKK Módszertani Intézeti Tanszéki Osztály Budapest, 2012.. Név:... Neptun kód:... Érdemjegy:..... STATISZTIKA II. VIZSGADOLGOZAT Feladatok 1. 2. 3. 4. 5. 6. Összesen Szerezhető pontszám 21 20 7 22
TANULÁSI GÖRBÉK AZ ÉPÍTŐIPARBAN
 TANULÁSI GÖRBÉK AZ ÉPÍTŐIPARBAN Mályusz Levente ELŐZMÉNYEK 1 A tanulási görbét először egy 19 századi pszichológus Hermann Ebbinghaus írta le. Azt vizsgálta, hogy milyen gyorsan memorizál valaki különböző
TANULÁSI GÖRBÉK AZ ÉPÍTŐIPARBAN Mályusz Levente ELŐZMÉNYEK 1 A tanulási görbét először egy 19 századi pszichológus Hermann Ebbinghaus írta le. Azt vizsgálta, hogy milyen gyorsan memorizál valaki különböző
Témaválasztás, kutatási kérdések, kutatásmódszertan
 Témaválasztás, kutatási kérdések, kutatásmódszertan Dr. Dernóczy-Polyák Adrienn PhD egyetemi adjunktus, MMT dernoczy@sze.hu A projekt címe: Széchenyi István Egyetem minőségi kutatói utánpótlás nevelésének
Témaválasztás, kutatási kérdések, kutatásmódszertan Dr. Dernóczy-Polyák Adrienn PhD egyetemi adjunktus, MMT dernoczy@sze.hu A projekt címe: Széchenyi István Egyetem minőségi kutatói utánpótlás nevelésének
S atisztika 2. előadás
 Statisztika 2. előadás 4. lépés Terepmunka vagy adatgyűjtés Kutatási módszerek osztályozása Kutatási módszer Feltáró kutatás Következtető kutatás Leíró kutatás Ok-okozati kutatás Keresztmetszeti kutatás
Statisztika 2. előadás 4. lépés Terepmunka vagy adatgyűjtés Kutatási módszerek osztályozása Kutatási módszer Feltáró kutatás Következtető kutatás Leíró kutatás Ok-okozati kutatás Keresztmetszeti kutatás
STATISZTIKA ELŐADÁS ÁTTEKINTÉSE. Matematikai statisztika. Mi a modell? Binomiális eloszlás sűrűségfüggvény. Binomiális eloszlás
 ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 9. Előadás Binomiális eloszlás Egyenletes eloszlás Háromszög eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell 2/62 Matematikai statisztika
ELŐADÁS ÁTTEKINTÉSE STATISZTIKA 9. Előadás Binomiális eloszlás Egyenletes eloszlás Háromszög eloszlás Normális eloszlás Standard normális eloszlás Normális eloszlás mint modell 2/62 Matematikai statisztika
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017.
 Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Mit látnak a robotok? Bányai Mihály Matemorfózis, 2017. Vizuális feldolgozórendszerek feladatai Mesterséges intelligencia és idegtudomány Mesterséges intelligencia és idegtudomány Párhuzamos problémák
Projekt siker és felelősség
 Projekt siker és felelősség dr. Prónay Gábor 10. Távközlési és Informatikai Projekt Menedzsment Fórum 2007. április 5. AZ ELŐADÁS CÉLJA figyelem felhívás a siker kritériumok összetettségére, az elmúlt
Projekt siker és felelősség dr. Prónay Gábor 10. Távközlési és Informatikai Projekt Menedzsment Fórum 2007. április 5. AZ ELŐADÁS CÉLJA figyelem felhívás a siker kritériumok összetettségére, az elmúlt
Üzleti folyamatok rugalmasabb IT támogatása. Nick Gábor András 2009. szeptember 10.
 Üzleti folyamatok rugalmasabb IT támogatása Nick Gábor András 2009. szeptember 10. A Generali-Providencia Magyarországon 1831: A Generali Magyarország első biztosítója 1946: Vállalatok államosítása 1989:
Üzleti folyamatok rugalmasabb IT támogatása Nick Gábor András 2009. szeptember 10. A Generali-Providencia Magyarországon 1831: A Generali Magyarország első biztosítója 1946: Vállalatok államosítása 1989:
társadalomtudományokban
 Gépi tanulás, predikció és okság a társadalomtudományokban Muraközy Balázs (MTA KRTK) Bemutatkozik a Számítógépes Társadalomtudomány témacsoport, MTA, 2017 2/20 Empirikus közgazdasági kérdések Felváltja-e
Gépi tanulás, predikció és okság a társadalomtudományokban Muraközy Balázs (MTA KRTK) Bemutatkozik a Számítógépes Társadalomtudomány témacsoport, MTA, 2017 2/20 Empirikus közgazdasági kérdések Felváltja-e
TÁJÉKOZTATÓ PSIDIUM AKKREDITÁCIÓS KÉPZÉS PSIDIUM RENDSZERISMERETI KÉPZÉS DÖNTÉSTÁMOGATÓ MÓDSZEREK A HUMÁNERŐFORRÁS MENEDZSMENTBEN
 PSIDIUM AKKREDITÁCIÓS KÉPZÉS TÁJÉKOZTATÓ PSIDIUM RENDSZERISMERETI KÉPZÉS DÖNTÉSTÁMOGATÓ MÓDSZEREK A HUMÁNERŐFORRÁS MENEDZSMENTBEN OBJEKTIVITÁS ÉS MÉRHETŐSÉG BEVEZETÉSE PAK TÁJÉKOZTATÓ Programjaink célja,
PSIDIUM AKKREDITÁCIÓS KÉPZÉS TÁJÉKOZTATÓ PSIDIUM RENDSZERISMERETI KÉPZÉS DÖNTÉSTÁMOGATÓ MÓDSZEREK A HUMÁNERŐFORRÁS MENEDZSMENTBEN OBJEKTIVITÁS ÉS MÉRHETŐSÉG BEVEZETÉSE PAK TÁJÉKOZTATÓ Programjaink célja,
IT Factory. Kiss László
 IT Factory Kiss László Mit jelent az IT Factory Együttműködő építőelemekből áll, amelyek jól definiált céllal, feladattal rendelkeznek. A tervezés és megvalósítás világosan elkülönül. A folyamatok és teljesítmény
IT Factory Kiss László Mit jelent az IT Factory Együttműködő építőelemekből áll, amelyek jól definiált céllal, feladattal rendelkeznek. A tervezés és megvalósítás világosan elkülönül. A folyamatok és teljesítmény