Információ menedzsment eladások I. rész: Döntéstámogatás. Gajdos Sándor, TMIT sz
|
|
|
- Laura Deák
- 8 évvel ezelőtt
- Látták:
Átírás
1 Információ menedzsment eladások I. rész: Döntéstámogatás Gajdos Sándor, TMIT sz
2 Inmon adattárház definíciója
3 Üzleti intelligencia (BI) Új definíció (EPICOR, 2005): The art of science of knowing what the heck is going on with your business as it is happening, having the facts to understand it and support it, and having the ability to quickly do something about it.

4 A szükségletek hierarchiája Avagy: mi mködteti az embereket (Maslow) És mi mködteti a vállalatokat? A vállalatok rengeteg energiát ölnek abba, hogy fokozzák alkalmazottaik lelkesedését. Ez igazán szép tlük, de nézzünk szembe a tényekkel - dolgozni nem jó. Ha az emberek annyira szeretnének dolgozni, ingyen is csinálnák. Azért kell megfizetni az emberek munkáját, mert a munka messze nem tartozik az elképzelhet legkellemesebb idtöltések közé. Az ésszer vállalat tudja, hogy az alkalmazottak akkor lelkesednek a legjobban a munkájukért, ha segítünk nekik, hogy minél hamarabb abbahagyhassák azt. Scott Adams: Dilbert elv. SHL Hungary Kft. 2001
5 A DW üzleti életciklus Hadden-Kelly HP Open Warehouse Oracle Warehouse Methodology Ralph Kimball SAS Általános jellemz a fázisok definiálása és az iteratív szemlélet
6 Hadden-Kelly

7 Ralph Kimball módszertana
8 DW projekt definiálása érdekeltség vagy ellenérdekeltség? felkészültség értékelése
9 Gyakorlat Litmus teszt
10 Pénzügyi megfontolások A ROI (Return Of Investment) az Isten Amibe kerül: HW, SW, bels fejlesztési költségek, küls erforrások költsége, support, növekedés költségei. Mennyisége és eloszlása jól becsülhet Ami haszonként várható: bevételnövekedés: pl. gyorsabb piacrajutás vagy forgalomnövekedés a termékek jobb pozícionálása miatt,... költségcsökkenés: költséghatékonyabb marketing kampányok,...
11 DW projekt résztvevi heterogén csapatra van szükség PM üzleti analitikus architect (fmérnök) adatmodellez betöltés tervez front-end tervez biztonsági tervez data steward (adatgondnok) DBA Oktatók Betöltés programozó Front-end fejleszt üzemeltet (adat-)minségbiztosító, tesztel
12 Követelmények összegyjtése Alapelvek Elkészületek az interjúkhoz Interjúk lebonyolítása Sikerkritériumok meghatározása Konszolidálás, priorizálás, konszenzus kialakítása
13 DW architektúrák Rendszertervezési döntés, amely általában nem könnyen változtatható meg Fontosabb szempontok, amiket figyelembe kell venni. Mire jók a különböz architektúrák? Kommunikáció Tervezés Tanulás Hatékonyságnövelés és újrahasznosítás
14 Architektúrák Koncepcionális architektúra Adat(konzisztencia) architektúra Front-end architektúra és back-end architektúra Eszközarchitektúra (HW, SW) Üzemeltetési architektúra Biztonsági architektúra...
15 Koncepcionális architektúra fbb elemei forrásrendszerek adatkinyerés-integrálás állomásoztató terület (staging area, SA) elemi adattár (detailed storage, DS) szakterületi adattár (data mart) metaadattár üzemi adattár (operational data store, ODS) megjelenítés támogatás
16 ODS vs. DW Operatív adattár (ODS) Április 6.: Mike Jones a Market Street 14-be költözött Adattárház (DW) Ügyfél Mike Jones Cím 123 Main Street Hitel AA Utolsó módosítás jan. 12 Ügyfél Mike Jones Cím 123 Main Street Hitel AA Mettl: jan. 12. Meddig: jelen Ügyfél Mike Jones Cím 14 Market Street Hitel AA Utolsó módosítás ápr. 6 Ügyfél Mike Jones Cím 123 Main Street Hitel AA Mettl: jan. 12 Meddig: ápr. 5. Ügyfél Mike Jones Cím 14 Market Street Hitel AA Mettl: ápr. 6. Meddig: jelen
17 2 (! & ' ( " ) (! * + #,- * + # $ %.!,/! 3! # % %
18 !! " Szemantikai integrálási folyamat * /! ( # 6 - * + #,* + # ( ( %.!,/!!! - & 7#.89 : ; - $ * + 4! % %
19 #! = $! " * /!! M I D D L E W A R E ( # 6 - * + #,* + # ( ( %.!,/!! - & 7#.89 : ; $ 3! % % # < 8
20 Függ szakterületi adattár (hub-and-spoke architektúra)! 8! & (. /!! # 6 - * + #,* + # ( ( %.!,/!! - & 7#.89 : ; * ;! % ( 6 - # <
21 Adathozzáférési (front-end) architektúra Üzemeltetési architektúra
22 Relációs lekérdezések optimalizálása
23 Tartalom Heurisztikus, szabály alapú optimalizálás Költség alapú optimalizálás Katalógus költségbecslés Operációk, mveletek áttekintése Kifejezés-kiértékelés Az optimális végrehajtási terv kiválasztása Lekérdezés optimalizálás csillagsémákon
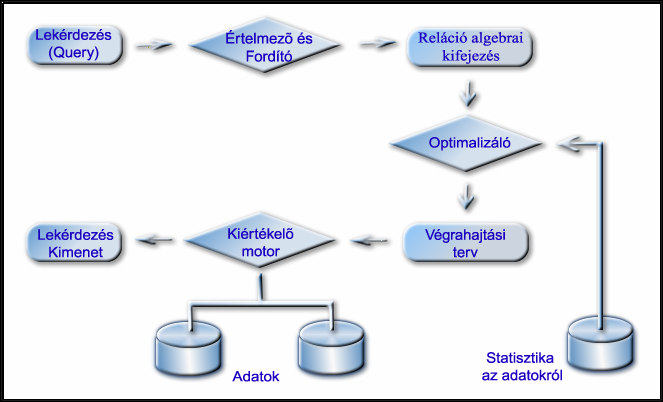
24 Áttekintés
25 I. Heurisztikus, szabály alapú optimalizálás Relációs algebrai fás optimalizálás Lekérdezési fa EMPLOYEE (EMPLOYEE_ID, LAST_NAME, FIRST_NAME, BIRTH_DATE, ) PROJECT (PROJECT_ID, PNAME, ) WORKS_ON (PROJECT_ID, EMPLOYEE_ID) select last_name from employee, works_on, project where employee.birth_date > and works_on.project_id = project.project_id and works_on.employee_id = employee.employee_id and project.pname = Aquarius
26 Egy lehetséges rel. algebrai megfelel: σ EMPLOYEE LAST _ NAME BIRTH _ DATE > ' ' EMPLOYEE _ ID= EMPLOYEE _ EMPLOYEE _ ID (( ( )) ( WORKS _ ON) σ ( ( PROJECT ))) PROJECT _ ID= PROJECT _ PROJECT _ ID PNAME = ' Aquarius ' π LAST _ NAME (3) PROJECT _ ID= PROJECT_ PROJECT _ ID (2) EMPLOYEE _ ID= EMPLOYEE _ EMPLOYEE _ ID σ PNAME =' Aquarius' σ (1) BIRTH _ DATE > ' ' WORKS_ON PROJECT EMPLOYEE
27 Cél: a leggyorsabb alak kiválasztása Kiindulás: kanonikus alakból (Descartes, szrés, projekció) π LAST _ NAME σ PNAME = ' Aquarius' AND PROJECT _ ID= PROJECT _ PROJECT _ ID AND EMPLOYEE _ ID= EMPLOYEE _ EMPLOYEE _ ID AND BIRTH _ DATE > ' ' X X PROJECT EMPLOYEE WORKS_ON
28 Második lépés: szelekciók süllyesztése π LAST _ NAME σ PROJECT _ ID= PROJECT _ PROJECT _ ID X σ EMPLOYEE _ ID= EMPLOYEE _ EMPLOYEE _ ID σ PNAME =' Aquarius' X PROJECT σ BIRTH _ DATE > ' ' WORKS_ON EMPLOYEE
29 Harmadik lépés: levelek átrendezése π LAST _ NAME σ EMPLOYEE _ ID= EMPLOYEE _ EMPLOYEE _ ID X σ PROJECT _ ID= PROJECT _ PROJECT _ ID σ BIRTH _ DATE > ' ' X EMPLOYEE σ PNAME =' Aquarius' WORKS_ON PROJECT
30 Negyedik lépés: join π LAST _ NAME EMPLOYEE _ ID= EMPLOYEE _ EMPLOYEE _ ID PROJECT _ ID= PROJECT _ PROJECT _ ID σ BIRTH _ DATE > ' ' σ PNAME =' Aquarius' WORKS_ON EMPLOYEE PROJECT
31 Ötödik lépés: projekció süllyesztése π LAST_ NAME EMPLOYEE _ ID = EMPLOYEE _ EMPLOYEE _ ID π EMPLOYEE_ EMPLOYEE_ ID π EMPLOYEE_ EMPLOYEE_ ID, LAST_ NAME PROJECT _ ID = PROJECT _ PROJECT _ ID σ BIRTH _ DATE > ' ' π PROJECT _ ID PROJECT _ ID, EMPLOYEE _ ID π EMPLOYEE σ PNAME=' Aquarius' WORKS_ON PROJECT
32 Mikor ekvivalens két fa? Relációs algebrai transzformációk I. σ c1andc2 ANDANDcn ( R) σ c1 ( σ c2 ( ( σ cn( R)) )) σ c1 ( σ c2( R)) σ c2 ( σ c1 ( R)) π List1 ( π List 2 ( ( π Listn( R)) )) = π List1( R) π A1, A2, An ( σ c ( R)) σ c ( π A1, A2,, An ( R))
33 Mikor ekvivalens két fa? Relációs algebrai transzformációk II. R c S S R σ (R S) ( ( R)) c σ c c S π L (R c S) ( π A1,, An ( R)) c ( π B1,, Bm ( S)) π (R L S) c π ( π ( )) L ( A1,, An, An+ 1,, An+ k R π B1,, Bm, Bm+ 1, Bm p ( S))) c (, + A halmazmveletek (unió, metszet) kommutativitása A join, Descartes-szorzat, unio és metszet asszociatív: ( Rθ S) θ T Rθ ( Sθ T )
34 Mikor ekvivalens két fa? Relációs algebrai transzformációk III. σ π c L ( Rθ S) ( σ ( R)) θ ( σ ( S)) c ( Rθ S) ( π ( R)) θ ( π ( S)) L c L Egyéb szabályok: c NOT ( c1 AND c2) ( NOT c1) OR ( NOT c2) c NOT ( c1 OR c2) ( NOT c1) AND ( NOT c2)
35 Összefoglaló szabályok: konjunktív szelekciós feltételeket szelekciós feltételek sorozatává bontjuk. szelekciós mveleteket felcseréljük a többi mvelettel átrendezzük a lekérdezési fa leveleit. A Descartes szorzatokat és a fölöttük lév szelekciós kapcsolási feltételt egy join mveletté vonjuk össze. a projekciós mveleteket felcseréljük a többi mvelettel
36 II. KöltsK ltség g alapú optimalizálás 1. Elemzés (szintaktikus), fordítás 2. Költség optimalizálás 3. Kiértékelés
37 Példa 1. Lekérdezés: select balance from account where balance < 2500 Algebrai forma: π ( σ 2500 ( account balance balance < σ balance < π balance 2500 ( ( account )) ))
38 Példa 1: A lekérdez rdezés s végrehajtv grehajtási terv π balance σ balance < 2500 account
39 II. KöltsK ltség g alapú optimalizálás Katalógusadatok alapján történ költségbecslés A katalógusban tárolt egyes relációkra vonatkozó információk Katalógus információk az indexekrl A lekérdezés költsége Oracle megoldás az adatok frissítésére
40 A katalógusban tárolt t egyes reláci ciókra vonatkozó informáci ciók: n r : az r relációban lev rekordok száma (number) b r : az r relációban lev rekordokat tartalmazó blokkok (blocks) száma s r : egy rekord nagysága (size) byte-okban f r : mennyi rekord fér egy blokkba (blocking factor)
41 - V (A, r): hány különböz értéke (values) fordul el az A attribútumnak az r relációban (kardinalitás): V (A, r) = π A (r) ; A kulcs, akkor V (A, r) = n r. - SC(A, r) : (Selection Cardinality) azon rekordok átlagos száma, amelyek egy kiválasztási feltételt kielégítenek. Az A kulcs, akkor SC(A, r) = 1. Általános esetben : SC(A, r) = n r / V (A, r). Ha a relációk rekordjai fizikailag együtt vannak tárolva, akkor: b r = n f r r
42 Katalógus informáci ciók k az indexekrl f i : pointer kimenetek átlagos száma a fa struktúrájú indexeknél, pl. a B* fáknál HT i : az index szintjeinek száma (Height of Tree) HT HT i i = [ log V ( A, r) ] = 1 f i (Hash) (B* fa) LB i : a levélszint indexblokkok száma (Lowest level index Block)
43 Költség g meghatároz rozása Meghatározása: -igényelt és felhasznált erforrások alapján? -válaszid alapján? -kommunikációra fordított id alapján? Definíció: -háttértár blokkolvasások és írások száma a válasz kiírásának költsége nélkül +További egyszersítések
44 Select Operáci ciók, mveletek m költsk ltsége szelekciós algoritmusok (alap, indexelt, összehasonlításos) komplex szelekció Join típusai join nagyságbecslés join algoritmusok komplex join Egyéb ismétldés kiszrése unió,metszet,különbség
45 Alap szelekciós s algoritmusok (=) A1: Lineáris keresés Költsége: E A1 = b r A2: Bináris keresés Feltétele: blokkok folyamatosan a diszken A attribútum szerint rendezettek szelekció feltétele az egyenlség az A attribútumon Költsége: E A SC ( A, r ) 2 = log 2 r f r [ b ] + 1
46 Indexelt szelekciós s algoritmusok A3: Elsdleges index használatával, egyenlségi feltételt a kulcson vizsgálva E A3 = HT i + 1 A4: Elsdleges index használatával, egyenlségi feltétel nem kulcson (a nemkulcs attribútumon van az elsdleges index) E A4 = HT + A5: Másodlagos index használatával. E A5 = HT i + SC(A, r) i EA5 = HT i + 1 (ha A kulcs) SC ( A, r ) f r
47 Összehasonlítás s alapú szelekció - σ A v (r) Az eredményrekordok számának becslése: Ha v-t nem ismerjük: n r /2 Ha v-t ismerjük, egyenletes eloszlás esetén: n átlagos = n r v min( A, r) ( ) max( A, r) min( A, r)
48 Összehasonlítás s alapú szelekció - σ A v (r) A6: Elsdleges index használatával. Ha v-t nem ismerjük: E A6 =HT i +b r /2 Ha v-t ismerjük: E A 6 = HT i + A7: Másodlagos index használatával c f r LBi E A7 = HTi nr 2 c jelöli azon rekordok számát, ahol A v
49 Komplex szelekció Konjukció: σ θ1 θ2.. θn (r) θ i kondíciónak eleget tev join nagysága: s i független feltételeket feltételezve Eredmény rekordok száma: Diszjunkció: σ θ1 θ2.. θn (r) Eredmény rekordok száma: Negáció: σ θ (r) Eredmény rekordok száma: size(r)-size(σ θ (r)) n r s * s 1 2 * *...* s n n r s 1 s 2 s n r * 1 1 * 1 *..* 1 nr nr n n n r
50 Komplex szelekció A8: Konjuktív szelekció indexek használatával. Legjobb feltétel mentén A9: Diszjunktív szelekció indexek mentén, minden feltétel-attribútumra van index lineáris keresés, ha nincs mindegyikre index A10: Szelekciók összekapcsolása diszjunkcióval pointereket készítünk az indexek alapján, majd unió a pointerekre Tanulság: A komplex szelekció kiértékelése semmivel sem bonyolultabb, mint egy szimpla szelekció.
51 Definíció: Típusai: Természetes join Join operáci ció Küls join (outer join) Bal oldali: T 1 (+)* T 2 Jobb oldali küls összekapcsolás: T 1 *(+) T 2. Teljes küls összekapcsolás: T 1 (+)*(+) T 2 T = σ feltétel (T 1 x T 2 ) ) Theta-join: R R ( R 2 ) θ σ 1 2 = θ 1 R T = π A U B (σ R1.X=R2.X (T 1 x T 2 ) )
52 Nested-loop join (egymásba ágyazott ciklikus illesztés) s) Adott két reláció r és s: FOR minden t r r rekordra DO BEGIN FOR minden t s s rekordra DO BEGIN teszteljük (t r, t s ) párt, hogy kielégíti-e a θ-join feltételt IF igen, THEN adjuk a t r. t s rekordot az eredményhez END END - worst case költség : n r *b s +b r -ha legalább az egyik befér a memóriába, akkor a költség: b r +b s
53 Block nested-loop join (blokkalapú egymásba ágyazott ciklikus illesztés) s) FOR minden b r r blokkra DO BEGIN FOR minden b s s blokkra DO BEGIN FOR minden t r b r rekordra DO BEGIN FOR minden t s b s rekordra DO BEGIN teszteljük le a (t r,t s ) párt END END END END - worst-case költsége: b r * b s + b r -sok memóriával: b r + b s
54 Indexed nested-loop join (indexalapú egymásba ágyazott ciklikus illesztés) s) - Az egyik relációhoz van indexünk (s) - Tegyük az els algoritmus bels ciklusába az indexelt relációt => A keresés index alapján kisebb költséggel is elvégezhet -Költsége: b r + n r *c, ahol c a szelekció költsége s-en.
55 További join implementáci ciók sorted merge-join a relációkat a join feltételben meghatározott attribútumok mentén rendezzük, majd összefésüljük hash-join az egyik relációt hash-táblán keresztül érjük el, miközben a másik reláció egy adott rekordjához illeszked rekordokat keressük egyéb pl. bitmap indexekkel (bitmap join)
56 Egyéb b operáci ciók Ismétldés kiszrése (rendezés, majd törlés) Projekció (projekció, majd ismétldés kiszrés) Unió (Mindkét relációt rendezzük, majd összefésülésnél kiszrjük a duplikációkat) Metszet (mindkét relációt rendezzük, fésülésnél csak a másodpéldányokat hagyjuk meg) Különbség (mindkét relációt rendezzük, fésülésnél csak els relációbeli rekordokat hagyunk) Aggregáció pl. márkanév G sum(egyenleg) (számla) számítása pl. rendezéssel márkanévre. Összegzés on-the-fly
57 Kifejezés s kiért rtékelés s módjaim Materializáció összetett kifejezésnek egyszerre egy mveletét értékeljük ki valamilyen rögzített sorrend szerint Pipelining egyszerre több elemi mvelet szimultán kiértékelése folyik egy operáció eredményét azonnal megkapja a sorban következ operáció operandusként
58 Materializáci ció Kanonikus alak: π customer _ name ( σ 2500 ( account) balance< customer) Mveleti fa: π customer_name σ balance < 2500 customer account Ered költség: a végrehajtott mveletek költsége + részeredmények tárolásának költsége Elnye: egyszer implementálhatóság Hátrány: sok háttértár-mvelet
59 Pipelining szimultán kiértékelés a részegységek az elttük álló elemtl kapott eredményekbl a sorban következ számára állítanak el részeredményeket nem számítja ki elre az egész relációt Elnye: -kiküszöböli az ideiglenes tárolás szükségességét -kicsi memóriaigény Hátránya: -szkíti a felhasználható algoritmusok körét

60 A kiért rtékelési terv kiválaszt lasztásasa milyen mveletek milyen sorrendben milyen algoritmus szerint milyen workflow-ban Egy konkrét kiértékelési terv
61 Költségalapú optimalizáci ció Mohó és egyben rossz stratégia: Minden ekvivalens kifejezés felsorolása Minden forma kiértékelése Az optimális kiválasztása Pl.: Tekintsük az alábbi kifejezést: r1 r2 r3, => 12 ekvivalens Általános esetben: n join-ra (2*(n-1))!/(n-1)! ekvivalens lehetség. Túl nagy terhelés a rendszer számára A megoldás: HEURISZTIKUS KÖLTSÉG ALAPÚ OPTIMALIZÁLÁS
62 Automatikus vs. manuális optimalizálás Az optimalizáló modul elnyei: Szélesebb ismeret a letárolt adatérétekekrl Gyorsabb numerikus kiértékelési mechanizmus Szisztematikus értékelés Algoritmusa több szakember együttes tudását hordozza Dinamikusan, minden mvelet eltt, az aktuális feltételeket figyelembe véve értékeldik ki. Az emberi optimalizálás elnyei: Szélesebb általános ismeret, a probléma szemantikai tartalmának megértése Nagyobb szabadság a felhasználható módszerek, eszközök tekintetében. Váratlan helyzetekre jobban felkészült.
63 III. Lekérdez rdezés optimalizálás csillagsémákon Lényegében egy illesztés a ténytábla és a dimenziós táblák között Dimenziós táblákat sohasem join-olunk A lehetség automatikus felismerése Hópihe séma: gyenge browsing teljesítmény, relációk növekv száma
64 Csillagséma optimális lekérdezése (feltételei, Oracle) Egyattribútumos bitmap index definiálása a tény valamennyi idegen kulcsára inicializáló paraméter beállítása (engedélyezés) költségalapú optimalizáló használata
65 Csillagtranszformáció Transzparens a felhasználónak Elve: 1. Dimenziós ID-k meghatározása 2. pontosan a szükséges tényrekordok kiolvasása bitmap segítségével 3. tényrekordok illesztése a dim. rekordokhoz.
66 Csillagtranszformáció példa SELECT ch.channel_class, c.cust_city, t.calendar_quarter_des FROM sales s, times t, customers c, channels ch WHERE s.time_id = t.time_id AND s.cust_id = c.cust_id AND s.channel_id = ch.channel_id AND c.cust_state_province = 'CA' AND ch.channel_desc IN ('Internet','Catalog') AND t.calendar_quarter_desc IN ( 2006-Q1', 2006-Q2') SELECT ch.channel_class, c.cust_city, t.calendar_quarter_desc FROM sales WHERE time_id IN (SELECT time_id FROM times WHERE calendar_quarter_desc IN( 2006-Q1', 2006-Q2')) AND cust_id IN (SELECT cust_id FROM customers WHERE cust_state_province='ca' AND channel_id IN (SELECT channel_id FROM channels WHERE channel_desc IN ('Internet','Catalog'));
67 Mködése a dimenziók általában kevés rekordot tartalmaznak dimenziók lekérdezése a dimenziós ID-kra time_id bitmap azonosítja a els negyedévi tényrekordokat time_id bitmap azonosítja a második negyedévi tényrekordokat hasonló bitmap-ek azonosítják a megfelel customer-hez és channel-hez tartozó tényrekordokat a bitmap-eket kombináljuk logikai mveletekkel tényrekordok elvétele a diszkrl dimenziós rekordok join-ja a tényrekordokhoz (módja reguláris optimalizálás során dl el)
68 Mikor jó? Ha a where predikátuma kellen szelektív a tényrekordokra Ha sok tényrekord érintett az eredmény elállításában, akkor full table scan jobb lehet...
69
70 Dimenziós modellezés Dimenziós modellezés elnyei: lekérdezése könnyen optimalizálható a modell bvítése egyszer, nem kell átstrukturálni az adatbázist, ha új adatot veszünk fel laikusok által is könnyen lekérdezhet a lekérdezést nem feltétlenül kell megváltoztatni, ha az adattárház bvül
71 Négylépéses dimenziós modellezés 1. Üzleti folyamat azonosítása 2. Tényadat granularitásának megválasztása 3. Dimenziók azonosítása 4. Tények azonosítása
72 1. Üzleti folyamat izolálása Példák: szolgáltatás használata, hitelek igénylése és felvétele, bevételek alakulása, kinnlevségek, rendelések személyzeti ügyek számlázás javítások és reklamációk, stb.
73 2. Tényadat granularitásának megválasztása milyen részletes adatok tárolását támogatjuk túl részletes: sok adat, nagy diszkigény, nagy CPU igény nem elég részletes: elemzéseket akadályozhat meg LE KELL ÍRNI A TÉNYREKORD PONTOS JELENTÉSÉT
74 3. Dimenziók azonosítása Mi alapján akarjuk rendezni, lekérdezni, csoportosítani a tényadatokat? Sok és részletes dimenzió változatosabb analízisek Dimenziók azonosítása szigorúan az adatok használata (ld. üzleti igények) alapján Dimenzió lesz minden, ami... Inkább szöveges attribútumok, de lehet numerikus is
75 4. Tények azonosítása A használandó mennyiségek konkrét meghatározása (pl. eladási ár Ft-ban, darabszám, átlagos kisker. ár, ) Általában folytonos értékkészletek és numerikusak.
76 Dimenziós tervezési elvek A pontosan ismerni és érteni az adatokat Dimenziós táblák: leíró attribútumuk, akár 50 is, a rekordok hossza kevéssé kritikus. Ténytáblák: a rekordok legyenek rövidek Konform dimenziókban gondolkodunk Minden dimenziónak legyen surrogate (anonym, kiegészít, jelentés nélküli, mesterséges) kulcsa.
77 Elnyei: Surrogate kulcs méretcsökkentés a ténytáblában forrásrendszeri kulcs változásaitól függetlenek leszünk az entitások idbeli változásait is le tudjuk így írni Hátránya: újra kell kulcsolni a tény és dimenziós rekordokat (jelents betöltési többletteher)
78 Dimenziós tábla tervezés A felesleges dimenziók teljesítményveszteséget eredményeznek. A dimenziós adatok nem feltétlenül nyerhetk ki valamely forrásrendszerbl. Az id, termék, hely, ügyfél a leggyakoribb dimenziók
79 Id dimenzió IDOSZAKOK_DIMENZIO IDOSZAK_ID <pk> NUMBER(4) NAPTARI_DATUM DATE NAP_MEGNEVEZESE CHAR(10) NAP_MEGNEVEZESE_ANGOL CHAR(9) NAP_ROVID_BETUJELE CHAR(3) NAP_ROVID_BETUJELE_ANGOL CHAR(3) HET_HANYADIK_NAPJA NUMBER(1) HONAP_HANYADIK_NAPJA NUMBER(2) EV_HANYADIK_NAPJA NUMBER(3) PENZUGYI_NEGYEDEV_NAPJA NUMBER(3) HONAP_HANYADIK_HETE NUMBER(2) EV_HANYADIK_HETE NUMBER(2) HONAP_ROVIDITESE CHAR(5) HONAP_ROVIDITESE_ANGOL CHAR(3) EV_HANYADIK_HONAPJA NUMBER(2) NAPTARI_NEGYEDEV NUMBER(1) NEGYEDEV_HONAPJA NUMBER(1) NEGYEDEV_HETE NUMBER(2) NEGYEDEV_NAPJA NUMBER(3) PENZUGYI_NEGYEDEV NUMBER(1) PENZUGYI_NEGYEDEV_HONAPJA NUMBER(1) PENZUGYI_NEGYEDEV_HETE NUMBER(3) HANYADIK_FELEV NUMBER(1) HONAP_MEGNEVEZESE CHAR(10) HONAP_MEGNEVEZESE_ANGOL CHAR(9) EVSZAM NUMBER(4) ROVID_EVSZAM NUMBER(2) PENZUGYI_EVSZAM NUMBER(4) PENZUGYI_ROVID_EVSZAM NUMBER(2) IDOSZAK_MEGNEVEZESE CHAR(40) IDOSZAK_MEGNEVEZESE_ANGOL CHAR(40) IDOSZAK_ROVID_NEVE CHAR(3) IDOSZAK_ROVID_NEVE_ANGOL CHAR(3) NAPOK_SZAMA_FIX_IDOPONTTOL NUMBER(4) KARACSONY_JELZO CHAR(1) HUSVET_JELZO CHAR(1) ALAPERTELMEZETT_IDOSZAK CHAR(1) NAPTIPUS NUMBER(1) NAPTIPUS_MEGNEVEZES CHAR(9)
80 Ténytábla tervezés Tényadatok a lehet legkisebb granularitásban (vö.: hiányzó "vásárlói kosár" analízis). Additív tényadatok Hacsak lehetséges, összegezhetnek kell választani. Nem additív tényadatok Egyáltalán nem összegezhetk, egyetlen dimenzió mentén sem. Szemi-additív tényadatok minden dimenzió szerint összegezhet, kivéve az idt. (általánosabban: bizonyos dimenziók szerint összegezhetk, mások szerint nem)
81 Tényadatok additivitásáról Áruház Nap Napi egyenleg Napi átlag Budapest Hétf 200 Budapest Kedd 100 Budapest Szerda 50 Budapest Csütörtök 20 Budapest Péntek 300 Budapest Szombat 200 Budapest Vasárnap Gyr Hétf 500 Gyr Kedd 600 Gyr Szerda 200 Gyr Csütörtök 100 Gyr Péntek 100 Gyr Szombat 500 Gyr Vasárnap Összesen 3570 Egyszer átlag (összesen/tételek száma) 255 Helyes átlag (összesen/periódusok száma)
82 Ténynélküli ténytáblák pl. diákok óralátogatási szokásai (id, tárgy, terem, diák, tanár függvényében) (kampány) lefedettségi táblák Pl. az eladás ténye termék, bolt, id, kampányjellemzk függvényében. Nem ad választ arra, hogy mit NEM adtak el abból, amirl a kampány szólt! Megoldás: egy másik ténytábla rekordja jelentse a kampányban való részvételt tényrekord jelentése: van olyan... Valójában klasszikus több-több kapcsolatok
83 Állapot- és esemény-tények Esemény-tény: egyetlen idpont Állapot-tény: két idpont Új tényrekord beszúrása egy másik lezárásával jár alacsonyabb hatékonyság valószínbb információvesztés (ld. késbb) Általában egymásba átalakíthatók Kik, mikor, hol, mit, stb. vásároltak Kik azok a vásárlók, akiknek van Melyek azok a termékek, amelyeket eladtak A lekérdezések hatékonysága ersen különböz!
84 Role-playing dimenziók pl. id, cím,... többféle jelentést is hordozhat a tényadathoz kapcsolódóan egyetlen fizikai dimenzió, amely több idegen kulccsal kapcsolódik a tényrekordhoz
85 Degenerált dimenziók Számla, tételekkel. A tételek lesznek a tényadatok. Mi legyen a számlaszámmal? Vannak olyan leíró (rövid, dimenziós jelleg) adatok, amelyeket a ténytáblában helyezünk el kapcsolódó dimenzió nélkül. Pl.: dokumentum egyedi azonosító száma A forrásrendszerben lehet könnyen azonosítani velük valamit Egyedi megfontolás. Normálisak, várhatók, hasznosak
86 Junk dimenziók Flag-ek és szöveges leírók nem mindig szervezhetk értelmes dimenziókba Ténytáblában nem célszer elhelyezni Egy vagy néhány jelentés nélküli dimenziót alkothatnak.
87 Ha a dimenzió is változik idvel ( slowly changing dimensions, SCD) Pl. az ügyfél elköltözik, címe megváltozik 1. régi rekord felülírása 2. old mez képzése a dim. táblában 3. új rekord a dim. táblában a surrogate kulcs új értékével
88 1. felülírás Pl.: az ügyfelek címei változhatnak, ha elköltözik. Ügyfél ID Ügyfél neve Ügyfél címe 123 Gipsz Jakab Budapest, Tó u felülírás Ügyfél ID Ügyfél neve Ügyfél címe 123 Gipsz Jakab Debrecen, F u. 3. Egyszer, de nincs history.
89 2. old mez létrehozása Ügyfél ID Ügyfél neve Ügyfél címe 123 Gipsz Jakab Budapest, Tó u A jelenlegi és az elz állapot jellemzésével Ügyfél ID Ügyfél neve Ügyfél elz címe Ügyfél jelenlegi címe 123 Gipsz Jakab Budapest, Tó u. 15. Debrecen, F u. 3. egyszer, de korlátozottak a lehetségei.
90 3. Új dim. rekord készítése Ügyfél ID Ügyfél neve Ügyfél címe 123 Gipsz Jakab Budapest, Tó u új dimenziós rekord minden változáshoz Ügyfél ID Ügyfél neve Ügyfél címe Tól Ig 123 Gipsz Jakab Budapest, Tó u júl szept Gipsz Jakab Debrecen, F u szept. 7.??????? particionálja a history-t, nehézkesebb a lekérdezés
91 Reklámkampány analízis 1. Mi a korreláció bizonyos oksági tényezk (engedmények, kiállítás módja, kuponok) és a pezsgsvödrök eladása között (darabban és Forintban) szupermarketenként, termékenként és 4 hetes eladási periódusonként? 2. Változik-e a pezsgsvödrök árérzékenysége üzletenként? Szükség van továbbá az alábbi standard riportokra: Piaci részesedés termékkategóriákként, szupermarketenként és idszakonként A legjobban fogyó márkák szupermarketenként és idszakonként Az adatforrások: a szupermarketek eladási adatai 4 hetes összesítésekben termékkódokként és szupermarketenként az így kapott file tartalmaz információt az alkalmazott kedvezményekrl, a kiállítás módjáról, a kuponokról, az eladott darabszámról, az eladási árról, az átlagos kiskereskedelmi árról és a kereskedelmi hierarchiáról. Attribútumlista: Kedvezmények, átlagos kiskereskedelmi ár, márka, kategória, kuponok, szín, kiállítás módja, eladási ár, íz, üzlet, csomagolás, költség, év, évszak, termékkód, darabszám, hét, cím (üzlet), dátum
92 FIZIKAI TERVEZÉS 1. ld. fizikai adatbázis tervezésrl eddig tanultak 2. összegzések tervezése 3. lekérdezés optimalizálás kérdései
93 Összegzések tervezése DEF.: elre kiszámított speciális lekérdezés, amikor a ténytábla tényadatait összegezzük bizonyos feltételek mentén. Másképpen: a dimenziókban lév hierarchiák "összenyomása" és a tényadatok ennek megfelel összeadása. (Ezért fontos a tényadatok additivitása.) Legfontosabb eszköz a teljesítmény kézbentartására Akár 1000 összegzés is létezhet egyidejleg!
94 Összegzések tárolása Új tényrekordokra van szükség, amelyhez új dimenziós táblák kellenek és új mesterséges kulcs. Az új rekordok kétféleképpen tárolhatók: új ténytáblában új szintjelz mezk segítségével (kevésbé jellemz)
95 Összegzés új ténytáblában Az összegzett tényrekordokat új táblában helyezzük el (Praktikusan a meglév ténytáblából is képezhetjük a szerkezetét). Hasonlóképpen az új dimenziós táblákat is képezhetjük a meglév dimenziósakból, a granularitás csökkentésével Példa: eredeti tény: termékek megrendelése, dimenzió: termék aggregátum tény: márkák megrendelése, dimenzió: márka A tényrekordokat összegeztük márkák szerint, új kulcsot definiáltunk a márka dimenzióhoz.
96 Összegzések méretezése 1. Elv: legalább 10:1 mérték rekordszámcsökkenés A választás szempontjai a (dimenzió) kompressziója és az együttes elfordulási gyakoriság (density). A kompresszió: ha egy márkához átlagosan (!) 50 termék tartozik, akkor a márkára definiált összegzés 50-szeres kompressziójú. Termék-bolt-nap elfordulási gyakorisága: ha egy boltban egy nap eladják a termékek 10%-át (átlagosan) Márka-bolt-nap elfordulási gyakorisága: ugyanakkor egy boltban egy nap eladják a márkáknak az 50%-át (átlagosan)
97 Összegzések méretezése 2. A várható rekordok száma az összegzés ténytáblájában = <sorok száma a dimenziókban> szorozva <elfordulási gyakoriság> Az együttes elfordulási gyakoriságok elre általában nem ismertek Megoldás: becslések, ill. tapasztalati méretezés (ha elég jó, akkor meghagyjuk )
98 Összegzések méretezése 3. way Termék dim. Üzlet dim. Idszak dim. Termék Üzlet Idszak Gyakoriság 0 SKU üzlet nap ,000,000 1 márka üzlet nap ,000, SKU kerület nap ,000, SKU üzlet hónap ,000, márka kerület nap ,400, márka üzlet hónap ,800, SKU kerület hónap ,400, márka kerület hónap , Rekordszám (millio) Összegzés kompresszió Dimenzió kompressziók: Termék-márka 5:1 Üzlet-kerület 10:1 Nap-hónap 30:1
99 Összegzés navigáció Új réteg. Nyilvántartja a létez összegzéseket és meghatározza, hogy melyik a legalkalmasabb a felhasználói lekérdezés kiszolgálására. Teljesítképesség és kényelmes használat Nagy a veszélye a túl sok összegzés definiálásának Nem mindegyik összegzés csökkenti jelentsen a sorok számát, ezeket futási idben kell kiszámolni. Számos adatbáziskezelnek része (pl. Oracle 8itl)
100 ÁLLOMÁSOZTATÓ TERÜLET TERVEZÉSE (Az ETL egyes fontosabb kérdései)
101 Back-room: data acquisition & staging Data acquisition (adat kinyerés) I. forrásrendszer minimális terhelése adat nem veszhet el és/vagy sérülhet teljes vs. inkrementális kezdeti ill. rendszeres flat file vs. adatbázis kapcsolat vs. hordozható táblatér metaadat gyjtés/vezérlés gyakoriság (ODS esetén sajátos megfontolások) tipikus források (pl. SAP) esetén dobozos interfész
102 Data acquisition (adat kinyerés) II. DW fejlesztési erfeszítések 60%-a adatelemek kiválasztása változások érzékelése (tranzakciós napló) full extract, ha: változás nem jól követhet szinkronizációhoz kis táblák esetén
103 Data acquisition (adat kinyerés) III. Adatkinyerés módja Adott idnként egyedi tábla másolatok (Full snapshot) Adott idnként egyedi tábla változásadatok Elnyök Egyszer Nem kell a forrásrendszert módosítani Forrásrendszer terhelése átidzíthet Forrásrendszer terhelése átidzíthet Információvesztés valószínsége kisebb Hátrányok Erforrásigényes mindkét oldalon Információvesztés lehetséges Nagy késleltetés A forrásrendszer módosításával járhat Nem mindig megvalósítható Nagy késleltetés Változásadatok eseményvezérelt kinyerése egyes táblákból Változásadatok kinyerése teljes tranzakció kontextusra, eseményvezérelten Kitüntetett adatokra kis késleltetés Információvesztés valószínsége még kisebb Információvesztés nincs Késleltetés nincs Viszonylag költséges Folyamatos többletterhelés a forrásnak Nem mindig megvalósítható Forrásrendszer módosításával jár együtt Költséges Bonyolult technológia Folyamatosan nagyobb többletterhelés a forrásnak Nem mindig megvalósítható Forrásrendszer módosításával jár együtt
104 Staging (állomásoztatás) I. Itt keletkezik a legtöbb hozzáadott érték Tervezése idigényes dimenziós és ténytáblák elállítása (bulk load!) flat file vs. relációs vs. egyedi struktúrák C, Cobol, utility-k, ill. adatbázis mveletek (sok overhead) archiválás adatmodell: teljesítmény és könny fejlesztés
105 Staging (állomásoztatás) II. metaadat vezérelt elv: a folyamatok a metaadattárból vezéreltek, mintsem beágyazottak az ETL programokba aktív-passzív metaadat (utasítás ill. dokumentál) változások a metaadattáron keresztül megvalósíthatók
106 Staging (állomásoztatás) III. adattípus konverziók adatforrások integrálása surrogátum kulcsok generálása referenciális integritás kezelése cleansing: (duplikátumok, hibás-hiányzó adatok) pontos specifikálás NULL: sok rendszerben nincs kódja
107 Adatminség javítása Minségi standard-ok definiálása (pontosság, teljesség, ellentmondás-mentesség, egységesség, frissesség) Javítás spec. karakterek ellentmondásos/változó használata (F N M F m f y n ) mez használat dokumentálatlan célra mez használat többféle célra adat fejldés - jelentésváltozás hiányzó - hibás - dupla értékek Javításuk a forrásrendszerben kívánatos, de nem mindig lehetséges A nevek és címek javítása külön tudomány
108 Staging (állomásoztatás) IV. Job vezérlés ütemezés: id és/vagy eseményvezérelt monitorozás naplózás (adatbázisba, segít optimalizálni is) kivételkezelés (visszautasított rekordok kezeléséhez hely, id, paraméterek kellenek) hibakezelés (crash recovery, stop, restart, állítható commit set jól jöhet) értesítés eseményrl (mail, SMS)
109 Staging (állomásoztatás) V. Mentések még UPS, mirroring, redundáns HW esetén is kell biztonsági mentés nagy teljesítmény egyszer adminisztráció nagyfokú automatizmus szoros kapcsolat a rendelkezésreállással
110 Staging (állomásoztatás) VI. Betöltés lépésenként Céltáblánként és célattribútumonként transzformációk leírása,végrehajtása Kivételkezelés megvalósítása Dimenzió betöltése (kis statikus, kis változó, nagyméret) Ténytáblák töltése Összegzések készítése Automatizmusok kialakítása
111 Prezentációs szerver Ahol az adatokat a végfelhasználók elérik Eleinte nem vált el a részletes adattártól Minél magasabb rendelkezésreállás
112 Közel valósidej adattárházak
113 Eddig: kötegelt (batch) feldolgozás Oka: a tipikus igényeket kielégíti és rel. olcsó Következmény: jelents késleltetés az eredményekben Cél: a késleltetés csökkentése
114 Valósidejség értelmezése I. felhasználói szempont: a lekérdezés eredménye álljon gyorsan el mszaki szempont: az adatok legyenek minél frissebbek Az igazi kihívás a kett együttes teljesítése. Eredmény: stratégiai, taktikai és operatív döntések támogatása
115 Valósidejség értelmezése II. Szigorú valós idej mködés akár folyamatirányításra Puha valós idej mködés döntéstámogatásra (near-time, soft realtime, right-time, on-time) Tipikusan mp-es, ill. nagyobb késleltetések Romlik a hatásfok, ha csökken a késleltetés
116 Hol lehet rá szükség? Általában: Ahol sok adat alapján gyors és automatizált döntésekre van szükség Ahol gyors döntéseket kell hozni példányokra vonatkozóan Ahol a jelenlegi mködést a historikus viselkedéssel kell összehasonlítani Tipikus területek: korai riasztások ( early warning ) KPI számítása kritikus folyamatok állandó követése vételi ajánlat készítés kártyás vásárlásnál CRM - gyors ügyfélinformáció hitelkártyacsalások felderítése
117 RTDW definíció Egy vállalatot átfogó (folytonos és többpontos) adatfolyam histórikus és analitikus része (Haisten, 1999.) Real Time is anything that is too fast for your current ETL (Kimball, 2005.)
118 Valósidejség a gyakorlatban (kompromisszumok) Nyers er helyett paradigmaváltás snapshot-ok helyett változásadatok frissítés gyakoriságának korlátozása statikus és dinamikus adatok szétválasztása lassan változó adatok kezelése továbbra is kötegelten
119 Komponensek Adatstruktúrák (tartalom) Megjelenítés Interfészek, adatmozgatás ETL helyett CTF (Capture, Transform, Flow)
120 CTF Adatkinyerés (Capture) folyamatosság ( kötegelt) teljes kontextus megragadása eseményvezérelt Transzformációk (Transform) konverziók, mezk szétválasztása, kódok feloldása összegzés, multidimenziós átalakítás Adattovábbítás (Flow)
121 Adatok kinyerése Full snapshot-ok: csak batch esetén Megváltozott adatok kinyerése Közvetlen támogatás nincs partícionálás idbélyegek triggerek Közvetlen támogatás a forrásrendszerben pl. CDC (Change Data Capture)
122 Oracle CDC (Change Data Capture) módosított adatok (U, I, D) azonnal elérhetk egy külön táblában publisher-subscriber(s) minden elfizetnek saját nézete van a megváltozott adatokra Az elfizet kezeli a nézet hosszát és törli belle az adatokat
123 Adatok mozgatása egyre szorosabb együttmködés az ETL és EAI eszközök között: Acta Works: Java JMS Informatica PowerCenterRT: IBM WebSphere MQ, TIBCO Rendezvous DataStage XE: IBM WebSphere MQ IBM Warehouse Manager: IBM WebSphere MQ
124 A valósidej adattár Hogyan töltsünk lekérdezés közben? Valós idej partíció kritikus mérszámok gyors korrekciójára IMDB Statikus partíciók hagyományos adattárház szakterületi adattárak ettl függenek valós idej partíció ürítése holtidben
125 Összegzések Ismert, hogy csökkenti a válaszidket helyet takarít meg elfedi a részletes adatokat szerepe átértékeldik trendek követése idérzékeny tevékenységeknél inkrementális összegzés
126 Egy lehetséges felépítés EAI Transzformációs motor Dinamikus partíció Statikus partíciók MDB L e k é r d e z é s e k Metaadatok MDB
127 Analógiák Tranzakciós rendszer: (digitális) fénykép a jelen állapotról Hagyományos adattárház: (digitális) fényképek sorozata - film Valósidej adattárház: (digitális) film, ahol csak a megváltozott képtartalmat rajzoljuk újra
128 Rövid történet 1998: els publikációk 1999: els fejlesztések 2001: els CTF eszközök megjelenése 2002: Oracle 9iR2 CDC 2003: HP Magyarország kísérleti RTDW v : Els Oracle alapú ipari implementáció (Euronext) 2006: Els Mo.-i ipari alkalmazás a MAVIRnál (BME-TMIT és HP)
129 Amikrl nem volt szó front-end kialakítása (ld. Inf. rendszerek fejlesztése ) teljesítmény méretezés teljesítmény mérés ( hardver...
130 Jó tanulást!
RELÁCIÓS LEKÉRDEZÉSEK OPTIMALIZÁLÁSA. Marton József november BME TMIT
 RELÁCIÓS LEKÉRDEZÉSEK OPTIMALIZÁLÁSA Marton József 2015. november BME TMIT ÁTTEKINTÉS lekérdezés (query) értelmező és fordító reláció algebrai kifejezés optimalizáló lekérdezés kimenet kiértékelő motor
RELÁCIÓS LEKÉRDEZÉSEK OPTIMALIZÁLÁSA Marton József 2015. november BME TMIT ÁTTEKINTÉS lekérdezés (query) értelmező és fordító reláció algebrai kifejezés optimalizáló lekérdezés kimenet kiértékelő motor
RELÁCIÓS LEKÉRDEZÉSEK OPTIMALIZÁLÁSA. Dr. Gajdos Sándor november BME TMIT
 RELÁCIÓS LEKÉRDEZÉSEK OPTIMALIZÁLÁSA Dr. Gajdos Sándor 2014. november BME TMIT TARTALOM Heurisztikus, szabály alapú optimalizálás Költség alapú optimalizálás Katalógus költségbecslés Operációk, műveletek
RELÁCIÓS LEKÉRDEZÉSEK OPTIMALIZÁLÁSA Dr. Gajdos Sándor 2014. november BME TMIT TARTALOM Heurisztikus, szabály alapú optimalizálás Költség alapú optimalizálás Katalógus költségbecslés Operációk, műveletek
Adatbázisok analitikus környezetben. Adatbázisok elmélete 4. előadás Gajdos Sándor
 Adatbázisok analitikus környezetben Adatbázisok elmélete 4. előadás Gajdos Sándor Tartalom Döntéstámogatás általában OSS vs. DSS Multidimenziós modellezés Hozzáférési módok, BI eszközök Lekérdezés optimalizálás
Adatbázisok analitikus környezetben Adatbázisok elmélete 4. előadás Gajdos Sándor Tartalom Döntéstámogatás általában OSS vs. DSS Multidimenziós modellezés Hozzáférési módok, BI eszközök Lekérdezés optimalizálás
Adattárházak. Gajdos Sándor, TMIT ősz
 Adattárházak Gajdos Sándor, TMIT 2015. ősz Döntéstámogató rendszerek (DSS: decision support systems) Kommunikáció-orientált Adat-orientált Dokumentáció-orientált Tudás-orientált Modell-orientált Kommunikáció-orientált
Adattárházak Gajdos Sándor, TMIT 2015. ősz Döntéstámogató rendszerek (DSS: decision support systems) Kommunikáció-orientált Adat-orientált Dokumentáció-orientált Tudás-orientált Modell-orientált Kommunikáció-orientált
Marton József BME-TMIT. Adatbázisok VITMAB november 11.
 Marton József BME-TMIT Gajdos Sándor diasorának felhasználásával Adatbázisok VITMAB00 2016. november 11. A lekérdezés-feldolgozás folyamata I. Cél: az adatok adatbázisból való kinyerése Mivel: egyértelmű,
Marton József BME-TMIT Gajdos Sándor diasorának felhasználásával Adatbázisok VITMAB00 2016. november 11. A lekérdezés-feldolgozás folyamata I. Cél: az adatok adatbázisból való kinyerése Mivel: egyértelmű,
Adattárház alapú vezetői információs rendszerek
 Adattárház alapú vezetői információs rendszerek Gajdos Sándor gajdos@tmit.bme.hu Adatbázisok haladóknak 2012. 2012. szeptember 11. Bevezető Fő kérdések: Mitől lesz egy adattárház projekt sikeres? Mik a
Adattárház alapú vezetői információs rendszerek Gajdos Sándor gajdos@tmit.bme.hu Adatbázisok haladóknak 2012. 2012. szeptember 11. Bevezető Fő kérdések: Mitől lesz egy adattárház projekt sikeres? Mik a
I. RÉSZ. Tartalom. Köszönetnyilvánítás...13 Bevezetés...15
 Tartalom 5 Tartalom Köszönetnyilvánítás...13 Bevezetés...15 I. RÉSZ AZ ALAPOK... 17 1. fejezet Egy kis történelem...19 A korai MIS rendszerektől az alapgondolatig...19 Operatív és analitikus rendszerek
Tartalom 5 Tartalom Köszönetnyilvánítás...13 Bevezetés...15 I. RÉSZ AZ ALAPOK... 17 1. fejezet Egy kis történelem...19 A korai MIS rendszerektől az alapgondolatig...19 Operatív és analitikus rendszerek
Ellenőrző kérdések. 36. Ha t szintű indexet használunk, mennyi a keresési költség blokkműveletek számában mérve? (1 pont) log 2 (B(I (t) )) + t
 log 2 (B(I (t) )) + t") Ellenőrző kérdések 2. Kis dolgozat kérdései 36. Ha t szintű indexet használunk, mennyi a keresési költség blokkműveletek számában mérve? (1 pont) log 2 (B(I (t) )) + t 37. Ha t szintű indexet használunk,
Ellenőrző kérdések 2. Kis dolgozat kérdései 36. Ha t szintű indexet használunk, mennyi a keresési költség blokkműveletek számában mérve? (1 pont) log 2 (B(I (t) )) + t 37. Ha t szintű indexet használunk,
Adattárház tiszta alapokon Oracle Day, Budapest, november 8.
 Adattárház tiszta alapokon Oracle Day, Budapest, 2011. november 8. WIT-SYS Consulting Zrt. Lévai Gábor gabor.levai@wit-sys.hu Tematika Az adattárházról általánosan Az adattárház definíciója Fő jellemzők
Adattárház tiszta alapokon Oracle Day, Budapest, 2011. november 8. WIT-SYS Consulting Zrt. Lévai Gábor gabor.levai@wit-sys.hu Tematika Az adattárházról általánosan Az adattárház definíciója Fő jellemzők
Adatmodellezés. 1. Fogalmi modell
 Adatmodellezés MODELL: a bonyolult (és időben változó) valóság leegyszerűsített mása, egy adott vizsgálat céljából. A modellben többnyire a vizsgálat szempontjából releváns jellemzőket (tulajdonságokat)
Adatmodellezés MODELL: a bonyolult (és időben változó) valóság leegyszerűsített mása, egy adott vizsgálat céljából. A modellben többnyire a vizsgálat szempontjából releváns jellemzőket (tulajdonságokat)
BEVEZETÉS AZ ADATTÁRHÁZ AUTOMATIZÁLÁSBA
 BEVEZETÉS AZ ADATTÁRHÁZ AUTOMATIZÁLÁSBA Gollnhofer Gábor JET-SOL Kft. Nyilvántartási szám: 503/1256-1177 JET-SOL KFT. Alapadatok 2003-ban alakultunk Több mint 120 magasan képzett munkatárs Ügyfélkör Nagyvállalati
BEVEZETÉS AZ ADATTÁRHÁZ AUTOMATIZÁLÁSBA Gollnhofer Gábor JET-SOL Kft. Nyilvántartási szám: 503/1256-1177 JET-SOL KFT. Alapadatok 2003-ban alakultunk Több mint 120 magasan képzett munkatárs Ügyfélkör Nagyvállalati
Sikerünk kulcsa: az információ De honnan lesz adatunk? Palaczk Péter
 Sikerünk kulcsa: az információ De honnan lesz adatunk? Palaczk Péter Bevezető az Oracle9i adattárházas újdonságaihoz Elemzési és vezetői információs igények 80:20 az adatgyűjtés javára! Adattárházak kínálta
Sikerünk kulcsa: az információ De honnan lesz adatunk? Palaczk Péter Bevezető az Oracle9i adattárházas újdonságaihoz Elemzési és vezetői információs igények 80:20 az adatgyűjtés javára! Adattárházak kínálta
Lekérdezés-feldolgozás és optimalizálás
 Lekérdezés-feldolgozás és optimalizálás Segédanyag az Adatbázisok c. tárgyhoz Gajdos S. 2008. Az anyag a relációs lekérdezések feldolgozása és optimalizálása gazdag témakörének csak egy viszonylag kis,
Lekérdezés-feldolgozás és optimalizálás Segédanyag az Adatbázisok c. tárgyhoz Gajdos S. 2008. Az anyag a relációs lekérdezések feldolgozása és optimalizálása gazdag témakörének csak egy viszonylag kis,
VvAaLlÓóSs IiıDdEeJjȷŰű OoDdSs goldengate alapokon a magyar telekomban
 VvAaLlÓóSs IiıDdEeJjȷŰű OoDdSs goldengate alapokon a magyar telekomban Pusztai Péter IT fejlesztési senior menedzser Magyar Telekom Medveczki György szenior IT architekt T-Systems Magyarország 2014. március
VvAaLlÓóSs IiıDdEeJjȷŰű OoDdSs goldengate alapokon a magyar telekomban Pusztai Péter IT fejlesztési senior menedzser Magyar Telekom Medveczki György szenior IT architekt T-Systems Magyarország 2014. március
Relációs algebra lekérdezések optimalizációja. Adatbázisok használata
 Relációs algebra lekérdezések optimalizációja Adatbázisok használata Mi a cél? Moore-törvénye: (Gordon Moore) szerint az integrált áramkörök sok jellemzőjének fejlődése exponenciális, ezek az értékek 18
Relációs algebra lekérdezések optimalizációja Adatbázisok használata Mi a cél? Moore-törvénye: (Gordon Moore) szerint az integrált áramkörök sok jellemzőjének fejlődése exponenciális, ezek az értékek 18
Adatbázisok. 8. gyakorlat. SQL: CREATE TABLE, aktualizálás (INSERT, UPDATE, DELETE), SELECT október október 26. Adatbázisok 1 / 17
, SELECT október október 26. Adatbázisok 1 / 17") Adatbázisok 8. gyakorlat SQL: CREATE TABLE, aktualizálás (INSERT, UPDATE, DELETE), SELECT 2015. október 26. 2015. október 26. Adatbázisok 1 / 17 SQL nyelv Structured Query Language Struktúrált lekérdez
Adatbázisok 8. gyakorlat SQL: CREATE TABLE, aktualizálás (INSERT, UPDATE, DELETE), SELECT 2015. október 26. 2015. október 26. Adatbázisok 1 / 17 SQL nyelv Structured Query Language Struktúrált lekérdez
ADATBÁZIS-KEZELÉS. Relációalgebra, 5NF
 ADATBÁZIS-KEZELÉS Relációalgebra, 5NF ABSZTRAKT LEKÉRDEZŐ NYELVEK relációalgebra relációkalkulus rekord alapú tartomány alapú Relációalgebra a matematikai halmazelméleten alapuló lekérdező nyelv a lekérdezés
ADATBÁZIS-KEZELÉS Relációalgebra, 5NF ABSZTRAKT LEKÉRDEZŐ NYELVEK relációalgebra relációkalkulus rekord alapú tartomány alapú Relációalgebra a matematikai halmazelméleten alapuló lekérdező nyelv a lekérdezés
Mveletek a relációs modellben. A felhasználónak szinte állandó jelleggel szüksége van az adatbázisban eltárolt adatok egy részére.
 Mveletek a relációs modellben A felhasználónak szinte állandó jelleggel szüksége van az adatbázisban eltárolt adatok egy részére. Megfogalmaz egy kérést, amelyben leírja, milyen adatokra van szüksége,
Mveletek a relációs modellben A felhasználónak szinte állandó jelleggel szüksége van az adatbázisban eltárolt adatok egy részére. Megfogalmaz egy kérést, amelyben leírja, milyen adatokra van szüksége,
ETL keretrendszer tervezése és implementálása. Gollnhofer Gábor Meta4Consulting Europe Kft.
 ETL keretrendszer tervezése és implementálása Gollnhofer Gábor Meta4Consulting Europe Kft. Tartalom Bevezetés ETL keretrendszer: elvárások és hogyan készítsük A mi keretrendszerünk Bevezetési tanulságok
ETL keretrendszer tervezése és implementálása Gollnhofer Gábor Meta4Consulting Europe Kft. Tartalom Bevezetés ETL keretrendszer: elvárások és hogyan készítsük A mi keretrendszerünk Bevezetési tanulságok
Adattárház kialakítása a Szövetkezet Integrációban, UML eszközökkel. Németh Rajmund Vezető BI Szakértő március 28.
 Adattárház kialakítása a Szövetkezet Integrációban, UML eszközökkel Németh Rajmund Vezető BI Szakértő 2017. március 28. Szövetkezeti Integráció Központi Bank Takarékbank Zrt. Kereskedelmi Bank FHB Nyrt.
Adattárház kialakítása a Szövetkezet Integrációban, UML eszközökkel Németh Rajmund Vezető BI Szakértő 2017. március 28. Szövetkezeti Integráció Központi Bank Takarékbank Zrt. Kereskedelmi Bank FHB Nyrt.
Szoftver újrafelhasználás
 Szoftver újrafelhasználás Szoftver újrafelhasználás Szoftver fejlesztésekor korábbi fejlesztésekkor létrehozott kód felhasználása architektúra felhasználása tudás felhasználása Nem azonos a portolással
Szoftver újrafelhasználás Szoftver újrafelhasználás Szoftver fejlesztésekor korábbi fejlesztésekkor létrehozott kód felhasználása architektúra felhasználása tudás felhasználása Nem azonos a portolással
Döbrönte Zoltán. Data Vault alapú adattárház - Fél óra alatt. DMS Consulting Kft.
 Data Vault alapú adattárház - Fél óra alatt Döbrönte Zoltán DMS Consulting Kft. 1 Miről lesz szó Adattárház automatizálás Hol alkalmazható a leghatékonyabban Célok, funkcionalitás, előnyök Data Vault modellezés
Data Vault alapú adattárház - Fél óra alatt Döbrönte Zoltán DMS Consulting Kft. 1 Miről lesz szó Adattárház automatizálás Hol alkalmazható a leghatékonyabban Célok, funkcionalitás, előnyök Data Vault modellezés
Infor PM10 Üzleti intelligencia megoldás
 Infor PM10 Üzleti intelligencia megoldás Infor Üzleti intelligencia (Teljesítmény menedzsment) Web Scorecard & Műszerfal Excel Email riasztás Riportok Irányít Összehangol Ellenőriz Stratégia Stratégia
Infor PM10 Üzleti intelligencia megoldás Infor Üzleti intelligencia (Teljesítmény menedzsment) Web Scorecard & Műszerfal Excel Email riasztás Riportok Irányít Összehangol Ellenőriz Stratégia Stratégia
Relációs algebra 1.rész alapok
 Relációs algebra 1.rész alapok Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 Lekérdezések a relációs modellben 2.4. Egy algebrai lekérdező nyelv, relációs
Relációs algebra 1.rész alapok Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 Lekérdezések a relációs modellben 2.4. Egy algebrai lekérdező nyelv, relációs
Adatbázis rendszerek. dr. Siki Zoltán
 Adatbázis rendszerek I. dr. Siki Zoltán Adatbázis fogalma adatok valamely célszerűen rendezett, szisztéma szerinti tárolása Az informatika elterjedése előtt is számos adatbázis létezett pl. Vállalati személyzeti
Adatbázis rendszerek I. dr. Siki Zoltán Adatbázis fogalma adatok valamely célszerűen rendezett, szisztéma szerinti tárolása Az informatika elterjedése előtt is számos adatbázis létezett pl. Vállalati személyzeti
TSIMMIS egy lekérdezés centrikus megközelítés. TSIMMIS célok, technikák, megoldások TSIMMIS korlátai További lehetségek
 TSIMMIS egy lekérdezés centrikus megközelítés TSIMMIS célok, technikák, megoldások TSIMMIS korlátai További lehetségek 1 Információk heterogén információs forrásokban érhetk el WWW Társalgás Jegyzet papírok
TSIMMIS egy lekérdezés centrikus megközelítés TSIMMIS célok, technikák, megoldások TSIMMIS korlátai További lehetségek 1 Információk heterogén információs forrásokban érhetk el WWW Társalgás Jegyzet papírok
Név- és tárgymutató A, Á
 313 Név- és tárgymutató A, Á Accumulating snapshot. Lásd Tényegyedek és táblák, gyűjtött pillanatfelvétel Adatbázis tervezése módszertani folyamat, 36 több fázison keresztül, 37 Adatgazda, 39 Adatkinyerés.
313 Név- és tárgymutató A, Á Accumulating snapshot. Lásd Tényegyedek és táblák, gyűjtött pillanatfelvétel Adatbázis tervezése módszertani folyamat, 36 több fázison keresztül, 37 Adatgazda, 39 Adatkinyerés.
Szoftver-mérés. Szoftver metrikák. Szoftver mérés
 Szoftver-mérés Szoftver metrikák Szoftver mérés Szoftver jellemz! megadása numerikus értékkel Technikák, termékek, folyamatok objektív összehasonlítása Mér! szoftverek, programok CASE eszközök Kevés szabványos
Szoftver-mérés Szoftver metrikák Szoftver mérés Szoftver jellemz! megadása numerikus értékkel Technikák, termékek, folyamatok objektív összehasonlítása Mér! szoftverek, programok CASE eszközök Kevés szabványos
Data Vault adatmodellezés.
 Data Vault adatmodellezés Nemeth.Zoltan@iqpp.hu Új adattárház adatmodellezési módszer Dan Linstedt nevéhez fűződik Ismérvei Részletes, tételes adatok Történetiség kezelése Data Vault Üzleti területek köré
Data Vault adatmodellezés Nemeth.Zoltan@iqpp.hu Új adattárház adatmodellezési módszer Dan Linstedt nevéhez fűződik Ismérvei Részletes, tételes adatok Történetiség kezelése Data Vault Üzleti területek köré
AB1 ZH mintafeladatok. 6. Minősítse az állításokat! I-igaz, H-hamis
 AB1 ZH mintafeladatok 1. Töltse ki, és egészítse ki! Matematikai formalizmus arra, hogy hogyan építhetünk új relációkat a régi relációkból. Az adatoknak egy jól strukturált halmaza, amelyből információ
AB1 ZH mintafeladatok 1. Töltse ki, és egészítse ki! Matematikai formalizmus arra, hogy hogyan építhetünk új relációkat a régi relációkból. Az adatoknak egy jól strukturált halmaza, amelyből információ
Oracle SQL Developer Data Modeler és a DW adatmodellezés. Gollnhofer Gábor Meta Consulting Kft.
 Oracle SQL Developer Data Modeler és a DW adatmodellezés Gollnhofer Gábor Meta Consulting Kft. Oracle Information Management & Big Data Reference Architecture 2 Mi a NoSQL modellezés célja? Forrás: Insights
Oracle SQL Developer Data Modeler és a DW adatmodellezés Gollnhofer Gábor Meta Consulting Kft. Oracle Information Management & Big Data Reference Architecture 2 Mi a NoSQL modellezés célja? Forrás: Insights
Lekérdezések feldolgozása és optimalizálása
 Lekérdezések feldolgozása és optimalizálása Definíciók Lekérdezés feldolgozása lekérdezés lefordítása alacsony szintű tevékenységekre lekérdezés kiértékelése adatok kinyerése Lekérdezés optimalizálása
Lekérdezések feldolgozása és optimalizálása Definíciók Lekérdezés feldolgozása lekérdezés lefordítása alacsony szintű tevékenységekre lekérdezés kiértékelése adatok kinyerése Lekérdezés optimalizálása
INFORMATIKA ÁGAZATI ALKALMAZÁSAI. Az Agrármérnöki MSc szak tananyagfejlesztése TÁMOP-4.1.2-08/1/A-2009-0010
 INFORMATIKA ÁGAZATI ALKALMAZÁSAI Az Agrármérnöki MSc szak tananyagfejlesztése TÁMOP-4.1.2-08/1/A-2009-0010 2. Adatbáziskezelés eszközei Adatbáziskezelés feladata Adatmodell típusai Relációs adatmodell
INFORMATIKA ÁGAZATI ALKALMAZÁSAI Az Agrármérnöki MSc szak tananyagfejlesztése TÁMOP-4.1.2-08/1/A-2009-0010 2. Adatbáziskezelés eszközei Adatbáziskezelés feladata Adatmodell típusai Relációs adatmodell
HATÉKONY ETL FOLYAMATOK WORKSHOP
 HATÉKONY ETL FOLYAMATOK WORKSHOP Gollnhofer Gábor JET-SOL Kft. Nyilvántartási szám: 503/1256-1177 JET-SOL KFT. Alapadatok 2003-ban alakultunk Több mint 120 magasan képzett munkatárs Ügyfélkör Nagyvállalati
HATÉKONY ETL FOLYAMATOK WORKSHOP Gollnhofer Gábor JET-SOL Kft. Nyilvántartási szám: 503/1256-1177 JET-SOL KFT. Alapadatok 2003-ban alakultunk Több mint 120 magasan képzett munkatárs Ügyfélkör Nagyvállalati
Component Soft 1994-2013 és tovább
 Component Soft 1994-2013 és tovább IT szakemberek oktatása, tanácsadás Fő témáink: UNIX/Linux rendszerek, virtualizációs, fürtözési, tároló menedzsment és mentési technológiák Adatbázisok és middleware
Component Soft 1994-2013 és tovább IT szakemberek oktatása, tanácsadás Fő témáink: UNIX/Linux rendszerek, virtualizációs, fürtözési, tároló menedzsment és mentési technológiák Adatbázisok és middleware
BGF. 4. Mi tartozik az adatmodellek szerkezeti elemei
 1. Mi az elsődleges következménye a gyenge logikai redundanciának? inkonzisztencia veszélye felesleges tárfoglalás feltételes függés 2. Az olyan tulajdonság az egyeden belül, amelynek bármely előfordulása
1. Mi az elsődleges következménye a gyenge logikai redundanciának? inkonzisztencia veszélye felesleges tárfoglalás feltételes függés 2. Az olyan tulajdonság az egyeden belül, amelynek bármely előfordulása
ADATTÁRHÁZ MENEDZSMENT ÉS METAADAT KEZELÉS
 ADATTÁRHÁZ MENEDZSMENT ÉS METAADAT KEZELÉS Gollnhofer Gábor JET-SOL Kft. Nyilvántartási szám: 503/1256-1177 TARTALOM Bemutatkozás Adattárház menedzsment szemszögből Mi kell a sikeres adattárházhoz? Kérdések
ADATTÁRHÁZ MENEDZSMENT ÉS METAADAT KEZELÉS Gollnhofer Gábor JET-SOL Kft. Nyilvántartási szám: 503/1256-1177 TARTALOM Bemutatkozás Adattárház menedzsment szemszögből Mi kell a sikeres adattárházhoz? Kérdések
Valós idejű megoldások: Realtime ODS és Database In-Memory tapasztalatok
 Valós idejű megoldások: Realtime ODS és Database In-Memory tapasztalatok Pusztai Péter IT fejlesztési senior menedzser Magyar Telekom Sef Dániel Szenior IT tanácsadó T-Systems Magyarország 2016. április
Valós idejű megoldások: Realtime ODS és Database In-Memory tapasztalatok Pusztai Péter IT fejlesztési senior menedzser Magyar Telekom Sef Dániel Szenior IT tanácsadó T-Systems Magyarország 2016. április
Adatbányászat és Perszonalizáció architektúra
 Adatbányászat és Perszonalizáció architektúra Oracle9i Teljes e-üzleti intelligencia infrastruktúra Oracle9i Database Integrált üzleti intelligencia szerver Data Warehouse ETL OLAP Data Mining M e t a
Adatbányászat és Perszonalizáció architektúra Oracle9i Teljes e-üzleti intelligencia infrastruktúra Oracle9i Database Integrált üzleti intelligencia szerver Data Warehouse ETL OLAP Data Mining M e t a
Adatszerkezetek Adatszerkezet fogalma. Az értékhalmaz struktúrája
 Adatszerkezetek Összetett adattípus Meghatározói: A felvehető értékek halmaza Az értékhalmaz struktúrája Az ábrázolás módja Műveletei Adatszerkezet fogalma Direkt szorzat Minden eleme a T i halmazokból
Adatszerkezetek Összetett adattípus Meghatározói: A felvehető értékek halmaza Az értékhalmaz struktúrája Az ábrázolás módja Műveletei Adatszerkezet fogalma Direkt szorzat Minden eleme a T i halmazokból
Multimédiás adatbázisok
 Multimédiás adatbázisok Multimédiás adatbázis kezelő Olyan adatbázis kezelő, mely támogatja multimédiás adatok (dokumentum, kép, hang, videó) tárolását, módosítását és visszakeresését Minimális elvárás
Multimédiás adatbázisok Multimédiás adatbázis kezelő Olyan adatbázis kezelő, mely támogatja multimédiás adatok (dokumentum, kép, hang, videó) tárolását, módosítását és visszakeresését Minimális elvárás
IRÁNYTŰ A SZABÁLYTENGERBEN
 IRÁNYTŰ A SZABÁLYTENGERBEN amikor Bábel tornya felépül BRM konferencia 2008 október 29 BCA Hungary A Csapat Cégalapítás: 2006 Tanácsadói létszám: 20 fő Tapasztalat: Átlagosan 5+ év tanácsadói tapasztalat
IRÁNYTŰ A SZABÁLYTENGERBEN amikor Bábel tornya felépül BRM konferencia 2008 október 29 BCA Hungary A Csapat Cégalapítás: 2006 Tanácsadói létszám: 20 fő Tapasztalat: Átlagosan 5+ év tanácsadói tapasztalat
Tartalom Keresés és rendezés. Vektoralgoritmusok. 1. fejezet. Keresés adatvektorban. A programozás alapjai I.
 Keresés Rendezés Feladat Keresés Rendezés Feladat Tartalom Keresés és rendezés A programozás alapjai I. Hálózati Rendszerek és Szolgáltatások Tanszék Farkas Balázs, Fiala Péter, Vitéz András, Zsóka Zoltán
Keresés Rendezés Feladat Keresés Rendezés Feladat Tartalom Keresés és rendezés A programozás alapjai I. Hálózati Rendszerek és Szolgáltatások Tanszék Farkas Balázs, Fiala Péter, Vitéz András, Zsóka Zoltán
Parametrikus tervezés
 2012.03.31. Statikus modell Dinamikus modell Parametrikus tervezés Módosítások a tervezés folyamán Konstrukciós variánsok (termékcsaládok) Parametrikus Modell Parametrikus tervezés Paraméterek (változók
2012.03.31. Statikus modell Dinamikus modell Parametrikus tervezés Módosítások a tervezés folyamán Konstrukciós variánsok (termékcsaládok) Parametrikus Modell Parametrikus tervezés Paraméterek (változók
Programozás alapjai II. (7. ea) C++ Speciális adatszerkezetek. Tömbök. Kiegészítő anyag: speciális adatszerkezetek
 C++ Speciális adatszerkezetek. Tömbök. Kiegészítő anyag: speciális adatszerkezetek") Programozás alapjai II. (7. ea) C++ Kiegészítő anyag: speciális adatszerkezetek Szeberényi Imre BME IIT M Ű E G Y E T E M 1 7 8 2 C++ programozási nyelv BME-IIT Sz.I. 2016.04.05. - 1
Programozás alapjai II. (7. ea) C++ Kiegészítő anyag: speciális adatszerkezetek Szeberényi Imre BME IIT M Ű E G Y E T E M 1 7 8 2 C++ programozási nyelv BME-IIT Sz.I. 2016.04.05. - 1
... S n. A párhuzamos programszerkezet két vagy több folyamatot tartalmaz, melyek egymással közös változó segítségével kommunikálnak.
 Párhuzamos programok Legyen S parbegin S 1... S n parend; program. A párhuzamos programszerkezet két vagy több folyamatot tartalmaz, melyek egymással közös változó segítségével kommunikálnak. Folyamat
Párhuzamos programok Legyen S parbegin S 1... S n parend; program. A párhuzamos programszerkezet két vagy több folyamatot tartalmaz, melyek egymással közös változó segítségével kommunikálnak. Folyamat
Tipikus időbeli internetezői profilok nagyméretű webes naplóállományok alapján
 Tipikus időbeli internetezői profilok nagyméretű webes naplóállományok alapján Schrádi Tamás schraditamas@aut.bme.hu Automatizálási és Alkalmazott Informatikai Tanszék BME A feladat A webszerverek naplóállományainak
Tipikus időbeli internetezői profilok nagyméretű webes naplóállományok alapján Schrádi Tamás schraditamas@aut.bme.hu Automatizálási és Alkalmazott Informatikai Tanszék BME A feladat A webszerverek naplóállományainak
Adatbázis, adatbázis-kezelő
 Adatbázisok I. rész Adatbázis, adatbázis-kezelő Adatbázis: Nagy adathalmaz Közvetlenül elérhető háttértárolón (pl. merevlemez) Jól szervezett Osztott Adatbázis-kezelő szoftver hozzáadás, lekérdezés, módosítás,
Adatbázisok I. rész Adatbázis, adatbázis-kezelő Adatbázis: Nagy adathalmaz Közvetlenül elérhető háttértárolón (pl. merevlemez) Jól szervezett Osztott Adatbázis-kezelő szoftver hozzáadás, lekérdezés, módosítás,
Keresés és rendezés. A programozás alapjai I. Hálózati Rendszerek és Szolgáltatások Tanszék Farkas Balázs, Fiala Péter, Vitéz András, Zsóka Zoltán
 Keresés Rendezés Feladat Keresés és rendezés A programozás alapjai I. Hálózati Rendszerek és Szolgáltatások Tanszék Farkas Balázs, Fiala Péter, Vitéz András, Zsóka Zoltán 2016. november 7. Farkas B., Fiala
Keresés Rendezés Feladat Keresés és rendezés A programozás alapjai I. Hálózati Rendszerek és Szolgáltatások Tanszék Farkas Balázs, Fiala Péter, Vitéz András, Zsóka Zoltán 2016. november 7. Farkas B., Fiala
Az indexelés újdonságai Oracle Database 12c R1 és 12c R2
 Az indexelés újdonságai Oracle Database 12c R1 és 12c R2 Szabó Rozalinda Oracle adattárház szakértő, oktató szabo.rozalinda@gmail.com Index tömörítés fejlődése 8.1.3-as verziótól: Basic (Prefixes) index
Az indexelés újdonságai Oracle Database 12c R1 és 12c R2 Szabó Rozalinda Oracle adattárház szakértő, oktató szabo.rozalinda@gmail.com Index tömörítés fejlődése 8.1.3-as verziótól: Basic (Prefixes) index
SQL*Plus. Felhasználók: SYS: rendszergazda SCOTT: demonstrációs adatbázis, táblái: EMP (dolgozó), DEPT (osztály) "közönséges" felhasználók
, DEPT (osztály) közönséges felhasználók") SQL*Plus Felhasználók: SYS: rendszergazda SCOTT: demonstrációs adatbázis, táblái: EMP dolgozó), DEPT osztály) "közönséges" felhasználók Adatszótár: metaadatokat tartalmazó, csak olvasható táblák táblanév-prefixek:
SQL*Plus Felhasználók: SYS: rendszergazda SCOTT: demonstrációs adatbázis, táblái: EMP dolgozó), DEPT osztály) "közönséges" felhasználók Adatszótár: metaadatokat tartalmazó, csak olvasható táblák táblanév-prefixek:
DW 9. előadás DW tervezése, DW-projekt
 DW 9. előadás DW tervezése, DW-projekt Követelmény felmérés DW séma tervezése Betöltési modul tervezése Fizikai DW tervezése OLAP felület tervezése Hardver kiépítése Implementáció Tesztelés, bevezetés
DW 9. előadás DW tervezése, DW-projekt Követelmény felmérés DW séma tervezése Betöltési modul tervezése Fizikai DW tervezése OLAP felület tervezése Hardver kiépítése Implementáció Tesztelés, bevezetés
Informatikai alapismeretek Földtudományi BSC számára
 Informatikai alapismeretek Földtudományi BSC számára 2010-2011 Őszi félév Heizlerné Bakonyi Viktória HBV@ludens.elte.hu Titkosítás,hitelesítés Szimmetrikus DES 56 bites kulcs (kb. 1000 év) felcserél, helyettesít
Informatikai alapismeretek Földtudományi BSC számára 2010-2011 Őszi félév Heizlerné Bakonyi Viktória HBV@ludens.elte.hu Titkosítás,hitelesítés Szimmetrikus DES 56 bites kulcs (kb. 1000 év) felcserél, helyettesít
Speciális adatszerkezetek. Programozás alapjai II. (8. ea) C++ Tömbök. Tömbök/2. N dimenziós tömb. Nagyméretű ritka tömbök
 C++ Tömbök. Tömbök/2. N dimenziós tömb. Nagyméretű ritka tömbök") Programozás alapjai II. (8. ea) C++ Kiegészítő anyag: speciális adatszerkezetek Szeberényi Imre BME IIT Speciális adatszerkezetek A helyes adatábrázolás választása, a helyes adatszerkezet
Programozás alapjai II. (8. ea) C++ Kiegészítő anyag: speciális adatszerkezetek Szeberényi Imre BME IIT Speciális adatszerkezetek A helyes adatábrázolás választása, a helyes adatszerkezet
Adatbázis-kezelő rendszerek. dr. Siki Zoltán
 Adatbázis-kezelő rendszerek I. dr. Siki Zoltán Adatbázis fogalma adatok valamely célszerűen rendezett, szisztéma szerinti tárolása Az informatika elterjedése előtt is számos adatbázis létezett pl. Vállalati
Adatbázis-kezelő rendszerek I. dr. Siki Zoltán Adatbázis fogalma adatok valamely célszerűen rendezett, szisztéma szerinti tárolása Az informatika elterjedése előtt is számos adatbázis létezett pl. Vállalati
Adatbázis-lekérdezés. Az SQL nyelv. Makány György
 Adatbázis-lekérdezés Az SQL nyelv Makány György SQL (Structured Query Language=struktúrált lekérdező nyelv): relációs adatbázisok adatainak visszakeresésére, frissítésére, kezelésére szolgáló nyelv. Születési
Adatbázis-lekérdezés Az SQL nyelv Makány György SQL (Structured Query Language=struktúrált lekérdező nyelv): relációs adatbázisok adatainak visszakeresésére, frissítésére, kezelésére szolgáló nyelv. Születési
Több mint BI (Adatból üzleti információ)
") Több mint BI (Adatból üzleti információ) Vállalati műszaki adattárház építés és üzleti elemzések az ELMŰ-ÉMÁSZ Társaságcsoportnál Papp Imre Geometria Kft MEE, Mátraháza, 2013. szeptember 12. Visszatekintés
Több mint BI (Adatból üzleti információ) Vállalati műszaki adattárház építés és üzleti elemzések az ELMŰ-ÉMÁSZ Társaságcsoportnál Papp Imre Geometria Kft MEE, Mátraháza, 2013. szeptember 12. Visszatekintés
Autóipari beágyazott rendszerek. Komponens és rendszer integráció
 Autóipari beágyazott rendszerek és rendszer integráció 1 Magas szintű fejlesztési folyamat SW architektúra modellezés Modell (VFB) Magas szintű modellezés komponensek portok interfészek adattípusok meghatározása
Autóipari beágyazott rendszerek és rendszer integráció 1 Magas szintű fejlesztési folyamat SW architektúra modellezés Modell (VFB) Magas szintű modellezés komponensek portok interfészek adattípusok meghatározása
Fájlszervezés. Adatbázisok tervezése, megvalósítása és menedzselése
 Fájlszervezés Adatbázisok tervezése, megvalósítása és menedzselése Célok: gyors lekérdezés, gyors adatmódosítás, minél kisebb tárolási terület. Kezdetek Nincs általánosan legjobb optimalizáció. Az egyik
Fájlszervezés Adatbázisok tervezése, megvalósítása és menedzselése Célok: gyors lekérdezés, gyors adatmódosítás, minél kisebb tárolási terület. Kezdetek Nincs általánosan legjobb optimalizáció. Az egyik
ADATBÁZISOK ELMÉLETE 5. ELŐADÁS 3/22. Az F formula: ahol A, B attribútumok, c érték (konstans), θ {<, >, =,,, } Példa:
, θ {<, >, =,,, } Példa:") Adatbázisok elmélete 5. előadás Katona Gyula Y. Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi Tsz. I. B. 137/b kiskat@cs.bme.hu http://www.cs.bme.hu/ kiskat 2005 ADATBÁZISOK ELMÉLETE
Adatbázisok elmélete 5. előadás Katona Gyula Y. Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi Tsz. I. B. 137/b kiskat@cs.bme.hu http://www.cs.bme.hu/ kiskat 2005 ADATBÁZISOK ELMÉLETE
Adatbázisműveletek és lekérdezésoptimalizálás
 és lekérdezésoptimalizálás Nagyméretű adathalmazok kezelése Kazi Sándor 2010. február 24. Kazi Sándor (kazi@cs.bme.hu) és lekérdezésoptimalizálás 1 / 39 1 Bevezetés 2 3 4 5 6 7 Kazi Sándor (kazi@cs.bme.hu)
és lekérdezésoptimalizálás Nagyméretű adathalmazok kezelése Kazi Sándor 2010. február 24. Kazi Sándor (kazi@cs.bme.hu) és lekérdezésoptimalizálás 1 / 39 1 Bevezetés 2 3 4 5 6 7 Kazi Sándor (kazi@cs.bme.hu)
A szoftver-folyamat. Szoftver életciklus modellek. Szoftver-technológia I. Irodalom
 A szoftver-folyamat Szoftver életciklus modellek Irodalom Ian Sommerville: Software Engineering, 7th e. chapter 4. Roger S. Pressman: Software Engineering, 5th e. chapter 2. 2 A szoftver-folyamat Szoftver
A szoftver-folyamat Szoftver életciklus modellek Irodalom Ian Sommerville: Software Engineering, 7th e. chapter 4. Roger S. Pressman: Software Engineering, 5th e. chapter 2. 2 A szoftver-folyamat Szoftver
Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása. Rákosi Péter és Lányi Árpád
 Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása Rákosi Péter és Lányi Árpád Adattárház korábbi üzemeltetési jellemzői Online szolgáltatásokat nem szolgált ki, klasszikus elemzésre
Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása Rákosi Péter és Lányi Árpád Adattárház korábbi üzemeltetési jellemzői Online szolgáltatásokat nem szolgált ki, klasszikus elemzésre
Segítség, összementem!
 Segítség, összementem! Előadók: Kránicz László Irimi János Budapest, 2013. április 10. ITFI - Adatintegrációs Kompetencia Központ ITFI - Adatintegrációs Kompetencia Központ Tartalomjegyzék 2 Az Adattárház
Segítség, összementem! Előadók: Kránicz László Irimi János Budapest, 2013. április 10. ITFI - Adatintegrációs Kompetencia Központ ITFI - Adatintegrációs Kompetencia Központ Tartalomjegyzék 2 Az Adattárház
Teljeskörű BI megoldás a gyakorlatban IBM eszközök használatával, Magyarországon
 Teljeskörű BI megoldás a gyakorlatban IBM eszközök használatával, Magyarországon esettanulmány csokor, mely megpróbálja összefoglalni az elmúlt 10 év tapasztalatait,tanulságait és bemutat egy élő, hazai
Teljeskörű BI megoldás a gyakorlatban IBM eszközök használatával, Magyarországon esettanulmány csokor, mely megpróbálja összefoglalni az elmúlt 10 év tapasztalatait,tanulságait és bemutat egy élő, hazai
Indexek és SQL hangolás
 Indexek és SQL hangolás Ableda Péter abledapeter@gmail.com Adatbázisok haladóknak 2012. 2012. november 20. Miről lesz szó? Történelem Oracle B*-fa Index Felépítése, karbantartása, típusai Bitmap index
Indexek és SQL hangolás Ableda Péter abledapeter@gmail.com Adatbázisok haladóknak 2012. 2012. november 20. Miről lesz szó? Történelem Oracle B*-fa Index Felépítése, karbantartása, típusai Bitmap index
SQLServer. Particionálás
 SQLServer 11. téma DBMS particiók, LOG shipping Particionálás Tábla, index adatinak szétosztása több FileGroup-ra 1 Particionálás Előnyök: Nagy méret hatékonyabb kezelése Részek önálló mentése, karbantartása
SQLServer 11. téma DBMS particiók, LOG shipping Particionálás Tábla, index adatinak szétosztása több FileGroup-ra 1 Particionálás Előnyök: Nagy méret hatékonyabb kezelése Részek önálló mentése, karbantartása
7. előadás. Karbantartási anomáliák, 1NF, 2NF, 3NF, BCNF. Adatbázisrendszerek előadás november 3.
 7. előadás,,,, Adatbázisrendszerek előadás 2008. november 3. és Debreceni Egyetem Informatikai Kar 7.1 relációs adatbázisokhoz Mit jelent a relációs adatbázis-tervezés? Az csoportosítását, hogy jó relációsémákat
7. előadás,,,, Adatbázisrendszerek előadás 2008. november 3. és Debreceni Egyetem Informatikai Kar 7.1 relációs adatbázisokhoz Mit jelent a relációs adatbázis-tervezés? Az csoportosítását, hogy jó relációsémákat
Történet John Little (1970) (Management Science cikk)
 (Management Science cikk)") Információ menedzsment Szendrői Etelka Rendszer- és Szoftvertechnológia Tanszék szendroi@witch.pmmf.hu Vezetői információs rendszerek Döntéstámogató rendszerek (Decision Support Systems) Döntések információn
Információ menedzsment Szendrői Etelka Rendszer- és Szoftvertechnológia Tanszék szendroi@witch.pmmf.hu Vezetői információs rendszerek Döntéstámogató rendszerek (Decision Support Systems) Döntések információn
Nézetek és indexek. AB1_06C_Nézetek_Indexek - Adatbázisok-1 EA (Hajas Csilla, ELTE IK) - J.D. Ullman elıadásai alapján
 - J.D. Ullman elıadásai alapján") Nézetek és indexek Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 8.1. Nézettáblák 8.2. Adatok módosítása nézettáblákon keresztül 8.3. Indexek az SQL-ben 8.4. Indexek
Nézetek és indexek Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 8.1. Nézettáblák 8.2. Adatok módosítása nézettáblákon keresztül 8.3. Indexek az SQL-ben 8.4. Indexek
Tartalom. Jó hogy jön Jucika, maga biztosan emlékszik még, hányadik oldalon van a Leszállás ködben.
 Tartalom Jó hogy jön Jucika, maga biztosan emlékszik még, hányadik oldalon van a Leszállás ködben. Előszó 1. Az adatbányászatról általában 19 1.1. Miért adatbányászat? 21 1.2. Technológia a rejtett információk
Tartalom Jó hogy jön Jucika, maga biztosan emlékszik még, hányadik oldalon van a Leszállás ködben. Előszó 1. Az adatbányászatról általában 19 1.1. Miért adatbányászat? 21 1.2. Technológia a rejtett információk
Tudásalapú információ integráció
 Tudásalapú információ integráció (A Szemantikus Web megközelítés és a másik irány) Tanszéki értekezlet, 2008. május 14. 1 Miért van szükségünk ilyesmire? WWW: (Alkalmazások) Keresés a weben (pl. összehasonlítás
Tudásalapú információ integráció (A Szemantikus Web megközelítés és a másik irány) Tanszéki értekezlet, 2008. május 14. 1 Miért van szükségünk ilyesmire? WWW: (Alkalmazások) Keresés a weben (pl. összehasonlítás
Szolgáltatás Orientált Architektúra a MAVIR-nál
 Szolgáltatás Orientált Architektúra a MAVIR-nál Sajner Zsuzsanna Accenture Sztráda Gyula MAVIR ZRt. FIO 2009. szeptember 10. Tartalomjegyzék 2 Mi a Szolgáltatás Orientált Architektúra? A SOA bevezetés
Szolgáltatás Orientált Architektúra a MAVIR-nál Sajner Zsuzsanna Accenture Sztráda Gyula MAVIR ZRt. FIO 2009. szeptember 10. Tartalomjegyzék 2 Mi a Szolgáltatás Orientált Architektúra? A SOA bevezetés
TABLE ACCESS FULL HASH CLUSTER BY INDEX ROWID BY USER ROWID BY GLOBAL INDEX ROWID BY LOCAL INDEX ROWID
 Az eddigi pédákban szereplo muveletek (operation és option együtt) (Az összes létezo lehetoséget lásd -> Performance Tuning Guide 19.9 fejezet, 19.3. táblázat) TABLE ACCESS FULL HASH CLUSTER BY INDEX ROWID
Az eddigi pédákban szereplo muveletek (operation és option együtt) (Az összes létezo lehetoséget lásd -> Performance Tuning Guide 19.9 fejezet, 19.3. táblázat) TABLE ACCESS FULL HASH CLUSTER BY INDEX ROWID
Adatbázis rendszerek 7. Matematikai rendszer amely foglal magában:
 Adatbázis Rendszerek Budapesti Műszaki és Gazdaságtudományi Egyetem Fotogrammetria és Térinformatika Tanszék 2011 Dr. Alhusain Othman oalhusain@gmail.com 7.1. Bevezetés 7.2. Klasszikus- és relációs- algebra
Adatbázis Rendszerek Budapesti Műszaki és Gazdaságtudományi Egyetem Fotogrammetria és Térinformatika Tanszék 2011 Dr. Alhusain Othman oalhusain@gmail.com 7.1. Bevezetés 7.2. Klasszikus- és relációs- algebra
Programozás alapjai II. (7. ea) C++
 C++") Programozás alapjai II. (7. ea) C++ Kiegészítő anyag: speciális adatszerkezetek Szeberényi Imre BME IIT M Ű E G Y E T E M 1 7 8 2 C++ programozási nyelv BME-IIT Sz.I. 2016.04.05. - 1
Programozás alapjai II. (7. ea) C++ Kiegészítő anyag: speciális adatszerkezetek Szeberényi Imre BME IIT M Ű E G Y E T E M 1 7 8 2 C++ programozási nyelv BME-IIT Sz.I. 2016.04.05. - 1
Nem klaszterezett index. Beágyazott oszlopok. Klaszterezett index. Indexek tulajdonságai. Index kitöltési faktor
 1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
Adatbáziskezelő-szerver. Relációs adatbázis-kezelők SQL. Házi feladat. Relációs adatszerkezet
 1 2 Adatbáziskezelő-szerver Általában dedikált szerver Optimalizált háttértár konfiguráció Csak OS + adatbázis-kezelő szoftver Teljes memória az adatbázisoké Fő funkciók: Adatok rendezett tárolása a háttértárolón
1 2 Adatbáziskezelő-szerver Általában dedikált szerver Optimalizált háttértár konfiguráció Csak OS + adatbázis-kezelő szoftver Teljes memória az adatbázisoké Fő funkciók: Adatok rendezett tárolása a háttértárolón
CMDB architektúra megjelenítése SAMU-val Rugalmas megoldás. ITSMF 2015. 10. 30. Bekk Nándor Magyar Telekom / IT szolgáltatás menedzsment központ
 CMDB architektúra megjelenítése SAMU-val Rugalmas megoldás ITSMF 2015. 10. 30. Bekk Nándor Magyar Telekom / IT szolgáltatás menedzsment központ Tartalom Nehézségeink CMDB adatok és függ ségek vizualizációja
CMDB architektúra megjelenítése SAMU-val Rugalmas megoldás ITSMF 2015. 10. 30. Bekk Nándor Magyar Telekom / IT szolgáltatás menedzsment központ Tartalom Nehézségeink CMDB adatok és függ ségek vizualizációja
Data Governance avagy adatvagyon kezelés Rövid bevezető. Gollnhofer Gábor DMS Consulting
 Data Governance avagy adatvagyon kezelés Rövid bevezető Gollnhofer Gábor DMS Consulting 1 Bemutatkozás DMS Consulting Kft. 2004-ben alakult, magyar tulajdonosok Data, Management, Systems, Consulting Főleg
Data Governance avagy adatvagyon kezelés Rövid bevezető Gollnhofer Gábor DMS Consulting 1 Bemutatkozás DMS Consulting Kft. 2004-ben alakult, magyar tulajdonosok Data, Management, Systems, Consulting Főleg
Szemléletmód váltás a banki BI projekteken
 Szemléletmód váltás a banki BI projekteken Data Governance módszertan Komáromi Gábor 2017.07.14. Fókuszpontok áthelyezése - Elérendő célok, elvárt eredmény 2 - Egységes adatforrásra épülő, szervezeti egységektől
Szemléletmód váltás a banki BI projekteken Data Governance módszertan Komáromi Gábor 2017.07.14. Fókuszpontok áthelyezése - Elérendő célok, elvárt eredmény 2 - Egységes adatforrásra épülő, szervezeti egységektől
Data Governance avagy adatvagyon kezelés Rövid bevezető. Gollnhofer Gábor DMS Consulting
 Data Governance avagy adatvagyon kezelés Rövid bevezető Gollnhofer Gábor DMS Consulting 1 Bemutatkozás DMS Consulting Kft. 2004-ben alakult, magyar tulajdonosok Data, Management, Systems, Consulting Főleg
Data Governance avagy adatvagyon kezelés Rövid bevezető Gollnhofer Gábor DMS Consulting 1 Bemutatkozás DMS Consulting Kft. 2004-ben alakult, magyar tulajdonosok Data, Management, Systems, Consulting Főleg
Data Integrátorok a gyakorlatban Oracle DI vs. Pentaho DI Fekszi Csaba Ügyvezető Vinnai Péter Adattárház fejlesztő 2013. február 20.
 Data Integrátorok a gyakorlatban Oracle DI vs. Pentaho DI Fekszi Csaba Ügyvezető Vinnai Péter Adattárház fejlesztő 2013. február 20. 1 2 3 4 5 6 7 8 Pentaho eszköztára Data Integrator Spoon felület Spoon
Data Integrátorok a gyakorlatban Oracle DI vs. Pentaho DI Fekszi Csaba Ügyvezető Vinnai Péter Adattárház fejlesztő 2013. február 20. 1 2 3 4 5 6 7 8 Pentaho eszköztára Data Integrator Spoon felület Spoon
Adaptív dinamikus szegmentálás idősorok indexeléséhez
 Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Adaptív dinamikus szegmentálás idősorok indexeléséhez IPM-08irAREAE kurzus cikkfeldolgozás Balassi Márton 1 Englert Péter 1 Tömösy Péter 1 1 Eötvös Loránd Tudományegyetem Informatikai Kar 2013. november
Átfogó megoldás a számlafolyamatok felgyorsításához ELO DocXtractor. Laczkó Kristóf ELO Digital Office Kft. Bálint András Prognax Kft.
 Átfogó megoldás a számlafolyamatok felgyorsításához ELO DocXtractor Laczkó Kristóf ELO Digital Office Kft. Bálint András Prognax Kft. Áttekintés Struktúrált és egyéb Információk bármely forrásból dokumentumok
Átfogó megoldás a számlafolyamatok felgyorsításához ELO DocXtractor Laczkó Kristóf ELO Digital Office Kft. Bálint András Prognax Kft. Áttekintés Struktúrált és egyéb Információk bármely forrásból dokumentumok
Rendszermodernizációs lehetőségek a HANA-val Poszeidon. Groma István PhD SDA DMS Zrt.
 Rendszermodernizációs lehetőségek a HANA-val Poszeidon Groma István PhD SDA DMS Zrt. Poszeidon EKEIDR Tanúsított ügyviteli rendszer (3/2018. (II. 21.) BM rendelet). Munkafolyamat támogatás. Papírmentes
Rendszermodernizációs lehetőségek a HANA-val Poszeidon Groma István PhD SDA DMS Zrt. Poszeidon EKEIDR Tanúsított ügyviteli rendszer (3/2018. (II. 21.) BM rendelet). Munkafolyamat támogatás. Papírmentes
Memóriagazdálkodás. Kódgenerálás. Kódoptimalizálás
 Kódgenerálás Memóriagazdálkodás Kódgenerálás program prológus és epilógus értékadások fordítása kifejezések fordítása vezérlési szerkezetek fordítása Kódoptimalizálás L ATG E > TE' E' > + @StPushAX T @StPopBX
Kódgenerálás Memóriagazdálkodás Kódgenerálás program prológus és epilógus értékadások fordítása kifejezések fordítása vezérlési szerkezetek fordítása Kódoptimalizálás L ATG E > TE' E' > + @StPushAX T @StPopBX
Szoftver architektúra, Architektúrális tervezés
 Szoftver architektúra, Architektúrális tervezés Irodalom Ian Sommerville: Software Engineering, 7th e. chapter 11. Roger S. Pressman: Software Engineering, 5th e. chapter 14. Bass, Clements, Kazman: Software
Szoftver architektúra, Architektúrális tervezés Irodalom Ian Sommerville: Software Engineering, 7th e. chapter 11. Roger S. Pressman: Software Engineering, 5th e. chapter 14. Bass, Clements, Kazman: Software
Fogalmak: Adatbázis Tábla Adatbázis sorai: Adatbázis oszlopai azonosító mező, egyedi kulcs Lekérdezések Jelentés Adattípusok: Szöveg Feljegyzés Szám
 Fogalmak: Adatbázis: logikailag összefüggő információ vagy adatgyőjtemény. Tábla: logikailag összetartozó adatok sorokból és oszlopokból álló elrendezése. Adatbázis sorai: (adat)rekord Adatbázis oszlopai:
Fogalmak: Adatbázis: logikailag összefüggő információ vagy adatgyőjtemény. Tábla: logikailag összetartozó adatok sorokból és oszlopokból álló elrendezése. Adatbázis sorai: (adat)rekord Adatbázis oszlopai:
Szoftver-technológia II. Modulok és OOP. Irodalom
 Modulok és OOP Irodalom Steven R. Schach: Object Oriented & Classical Software Engineering, McGRAW-HILL, 6th edition, 2005, chapter 7. 2 Modulok és objektumok Modulok Lexikálisan folytonos utasítás sorozatok,
Modulok és OOP Irodalom Steven R. Schach: Object Oriented & Classical Software Engineering, McGRAW-HILL, 6th edition, 2005, chapter 7. 2 Modulok és objektumok Modulok Lexikálisan folytonos utasítás sorozatok,
SELECT DISTINCT deptno FROM emp; (distinct) SELECT STATEMENT HASH UNIQUE TABLE ACCESS FULL EMP
 SELECT STATEMENT HASH UNIQUE TABLE ACCESS FULL EMP") SELECT * FROM emp; SELECT ename FROM emp; (projekció) SELECT ename FROM emp WHERE ename='jones'; (szelekció) ------------------------------------------ SELECT DISTINCT deptno FROM emp; (distinct) --------------------------------
SELECT * FROM emp; SELECT ename FROM emp; (projekció) SELECT ename FROM emp WHERE ename='jones'; (szelekció) ------------------------------------------ SELECT DISTINCT deptno FROM emp; (distinct) --------------------------------
Amit mindig is tudni akartál a Real Application Testing-ről. Földi Tamás Starschema Kft.
 Amit mindig is tudni akartál a Real Application Testing-ről Földi Tamás Starschema Kft. Környezet Adattárház Oracle 9i, HPUX 13ezer tábla ~1400 betöltő folyamat ~8000 töltési lépés (mapping) Riportok BusinessObjects
Amit mindig is tudni akartál a Real Application Testing-ről Földi Tamás Starschema Kft. Környezet Adattárház Oracle 9i, HPUX 13ezer tábla ~1400 betöltő folyamat ~8000 töltési lépés (mapping) Riportok BusinessObjects
MS ACCESS 2010 ADATBÁZIS-KEZELÉS ELMÉLET SZE INFORMATIKAI KÉPZÉS 1
 SZE INFORMATIKAI KÉPZÉS 1 ADATBÁZIS-KEZELÉS MS ACCESS 2010 A feladat megoldása során a Microsoft Office Access 2010 használata a javasolt. Ebben a feladatban a következőket fogjuk gyakorolni: Adatok importálása
SZE INFORMATIKAI KÉPZÉS 1 ADATBÁZIS-KEZELÉS MS ACCESS 2010 A feladat megoldása során a Microsoft Office Access 2010 használata a javasolt. Ebben a feladatban a következőket fogjuk gyakorolni: Adatok importálása
Nem klaszterezett index. Klaszterezett index. Beágyazott oszlopok. Index kitöltési faktor. Indexek tulajdonságai
 1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
Az adatbázisrendszerek világa
 Az adatbázisrendszerek világa Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 1.1. Az adatbázisrendszerek fejlődése 1.2. Az adatbázis-kezelő rendszerek áttekintése
Az adatbázisrendszerek világa Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 1.1. Az adatbázisrendszerek fejlődése 1.2. Az adatbázis-kezelő rendszerek áttekintése
Szolgáltatási szint és performancia menedzsment a PerformanceVisor alkalmazással. HOUG konferencia, 2007 április 19.
 Szolgáltatási szint és performancia menedzsment a PerformanceVisor alkalmazással Szabó Balázs HOUG konferencia, 2007 április 19. Mirıl lesz szó NETvisor Kft bemutatása Szolgáltatási szint alapjai Performancia
Szolgáltatási szint és performancia menedzsment a PerformanceVisor alkalmazással Szabó Balázs HOUG konferencia, 2007 április 19. Mirıl lesz szó NETvisor Kft bemutatása Szolgáltatási szint alapjai Performancia
Operációs rendszerek. Elvárások az NTFS-sel szemben
 Operációs rendszerek MS Windows NT (2000) NTFS Elvárások az NTFS-sel szemben Megbízható file-rendszer, visszaállíthatóság (recoverability). Állományok biztonságának garantálása, illetéktelen hozzáférés
Operációs rendszerek MS Windows NT (2000) NTFS Elvárások az NTFS-sel szemben Megbízható file-rendszer, visszaállíthatóság (recoverability). Állományok biztonságának garantálása, illetéktelen hozzáférés
Lekérdezések optimalizálása
 Lekérdezések optimalizálása CÉL: A lekérdezéseket gyorsabbá akarjuk tenni a táblákra vonatkozó paraméterek, statisztikák, indexek ismeretében és általános érvényő tulajdonságok, heurisztikák segítségével.
Lekérdezések optimalizálása CÉL: A lekérdezéseket gyorsabbá akarjuk tenni a táblákra vonatkozó paraméterek, statisztikák, indexek ismeretében és általános érvényő tulajdonságok, heurisztikák segítségével.
ADATBÁZIS-KEZELÉS FÉLÉVES FELADAT
 ÓBUDAI EGYETEM Neumann János Informatikai Kar Nappali Tagozat ADATBÁZIS-KEZELÉS FÉLÉVES FELADAT NÉV: MÁK VIRÁG NEPTUN KÓD: A DOLGOZAT CÍME: Jani bácsi székadatbázisa Beadási határidő: 14. oktatási hét
ÓBUDAI EGYETEM Neumann János Informatikai Kar Nappali Tagozat ADATBÁZIS-KEZELÉS FÉLÉVES FELADAT NÉV: MÁK VIRÁG NEPTUN KÓD: A DOLGOZAT CÍME: Jani bácsi székadatbázisa Beadási határidő: 14. oktatási hét
GPU Lab. 4. fejezet. Fordítók felépítése. Grafikus Processzorok Tudományos Célú Programozása. Berényi Dániel Nagy-Egri Máté Ferenc
 4. fejezet Fordítók felépítése Grafikus Processzorok Tudományos Célú Programozása Fordítók Kézzel assembly kódot írni nem érdemes, mert: Egyszerűen nem skálázik nagy problémákhoz arányosan sok kódot kell
4. fejezet Fordítók felépítése Grafikus Processzorok Tudományos Célú Programozása Fordítók Kézzel assembly kódot írni nem érdemes, mert: Egyszerűen nem skálázik nagy problémákhoz arányosan sok kódot kell