Az Ómagyar Korpusz bemutatása
|
|
|
- Jakab Bognár
- 6 évvel ezelőtt
- Látták:
Átírás
1 Az Ómagyar Korpusz bemutatása Simon Eszter január Finnugor Szeminárium Simon Eszter Az Ómagyar Korpusz bemutatása
2 Az előadás vázlata 1 A projektek 2 A korpusz anyaga 3 A feldolgozás lépései 4 Korpuszlekérdező felületek
3 A projektek Magyar Generatív Történeti Szintaxis (MGTSz) 1&2 az OTKA támogatásával (OTKA No & OTKA No ) április március & január december projektvezető: É. Kiss Katalin
4 A projektek célja MGTSz 1&2 1 elméleti cél: szintaktikai változások rekonstrukciója és vizsgálata 2 számítógépes munka: egy olyan annotált történeti korpusz létrehozása, amely tartalmazza az összes egybefüggő ómagyar szöveget & a korpusz kibővítése középmagyar korból származó Újszövetség-fordításokkal
5 A korpusz anyaga 47 ómagyar kódex 24 kisebb egybefüggő szövegemlék az ómagyar korból (HB ME) 244 misszilis (Hegedűs Papp: Középkori leveleink (1541-ig)) Pesti Gábor (1536) Sylvester János (1541) Heltai Gáspár (1565) Károli Gáspár (1590) Káldi György (1626)

6 A korpusz mérete token, ebből normalizált, ebből morfológiailag elemzett és egyértelműsített
7 Szövegfeldolgozottsági szintek (1) kiadott kódex szkennelve OCR (2) nyers OCR-kimenet kézi javítás (3) betűhű elektronikus forma kézi normalizálás (4) normalizált forma automatikus morfológiai elemzés (5) szótövesített és morfológiailag elemzett forma félautomatikus egyértelműsítés (6) egyértelműsített korpusz
8 Az annotációs szintek az egyes szövegszavakhoz tartozó annotációs szintek párhuzamosan alakulnak a szövegfeldolgozottsági szintekkel: betűhű forma (3): adÿad normalizált alak (4): adjad szótő (6) alapján: ad morfológiai elemzés (6): V.Sub.S2.Def
9 A korpusz felépítése oldal sor betűhű norm lemma elemzés Mÿ mi mi Pro.Nom gen vronknac Urunknak Úr N:P.PxP1.Dat gen iesus Jézus Jézus N:P cristusnac Krisztusnak Krisztus N:P.Dat gen gyczeretÿre dicséretére dicséret N.PxS3=i.Sub es és és C gyczewsegere dicsőségére dicsőség N.PxS3.Sub

10 1. Kézzel írott kódexek, nyomtatott kiadások
11 2. Szkennelés, OCR
12 3. A betűhű szöveg előállítása 52 latin alapkarakter 42 diakritikus jel 10 szám 15 speciális karakter 34 szövegtagoló és egyéb jel 3 görög betű Összesen: 156 karakter + ezek kombinációi UTF-8 kódolású sztenderd Unicode karakterek
13 Unicode nemzetközi szabvány a világ összes nyelvének összes karakterét egy kódolási rendszerbe foglalja minden platformon elérhető lehetőséget nyújt az alapkarakterek és a diakritikus jelek kombinációjára, pl. e + + = è az egész korpuszra kiterjedő szigorúan egységes formátum, DE: van olyan régi karakter, amely a Unicode-ban nincsen reprezentálva helyettesítő karakter: l č
14 Hangjelölés-egységesítés
15 4. Normalizálás betűhű normalizált a varoſba a városba ahazi a házi annėphėz a néphez az arpak az árpák ānėp a nép a tew a tű a nyaar a nyár a mendenhato a Mindenható
16 A normalizálás első alapelve az összes ma már nem létező szót, toldalékot, morfológiai konstrukciót megtartjuk Példa ýsa pur es chomuv uogmuc isa, por és hamu vagyunk lata o napat fèkette látá ő napát fekette
17 A normalizálás második alapelve elhagyjuk az összes fonológiai és helyesírási esetlegességet, vagyis egységes, a mainak megfelelő helyesírásra törekszünk Példa meden menden mendun mendē mendė miden minden mynden my nden my ndē mýden mýnden mýndew mÿnden mÿndon mēden mēdèn mēdē mēdėn mėnden m ēden minden
18 Tokenizálás és mondatra bontás Példa de säbädicz== ==mk mikët a gonostwl de szabadíts meg minket a gonosztól harmal napon halottay bool felthamata harmad napon halottaiból feltámada egmen-@@denic o at t afiat nē zorongat t a egymindenik ő atyjafiát nem szorongatja
19 Automatikus előnormalizálás tokenizálás: egy sor egy token, a kötőjeles szavak összevonása, az írásjelek leválasztása mondatra bontás: minden írásjel után üres sor normalizálás: a már normalizált szövegekből készült lista alapján, amely tartalmazza az egy az egyhez megfeleltethető betűhű normalizált párokat ezzel a tokenek 63%-át lefedjük, és 49%-nyi időt spórolunk meg a teljesen kézi normalizáláshoz képest
20 5. Morfológiai elemzés és egyértelműsítés morfológiai elemzés: a Humor ó- és középmagyarra szabott változatával egyértelműsítés: kézzel egy webes interfészen keresztül a jó elemzés kiválasztható a lehetséges elemzések listájából a normalizált szóalak és az elemzés is szerkeszthető, ha szükséges az eredmény egy HTML fájl, amit visszakonvertálunk az általunk használt tsv formátumra
21 Univerzális Dependencia és Morfológia Humor saját formalizmus sztenderdizáció Univerzális Dependencia és Morfológia most: a morfológiai elemzés konverziója később: szintaktikai elemzés hozzáadása különbségek az ómagyar és a mai magyar között különbségek a szófaji és az inflexiós címkékben különbségek a két annotációs séma között bizonyos jelenségeket nem lehetett információvesztés nélkül konvertálni
22 Metaadatok lókuszjelölők az adott szó helye az eredeti kódexben bibliai könyv-, fejezet- és versszámozás értelmezés: a normalizált alak mai magyarra való fordítása megjegyzés: TITLE, LANG{nyelv}, ADD, RECO, STRIKE, FAIL, FRAG igekötő: az elvált igekötőt jelöljük az alapige mellett
23 Lekérdezés minden szinten a lekérdező lényege, hogy bármely szinten meg lehet fogalmazni a lekérdezésünket a lekérdezés eredménye független a lekérdezéstől, vagyis például kereshetünk a normalizált szinten, és megjeleníthetjük a betűhűt a lekérdezés eredménye: konkordancia vagy gyakorisági lista a kontextus ablaka állítható a szövegemlék specifikálható
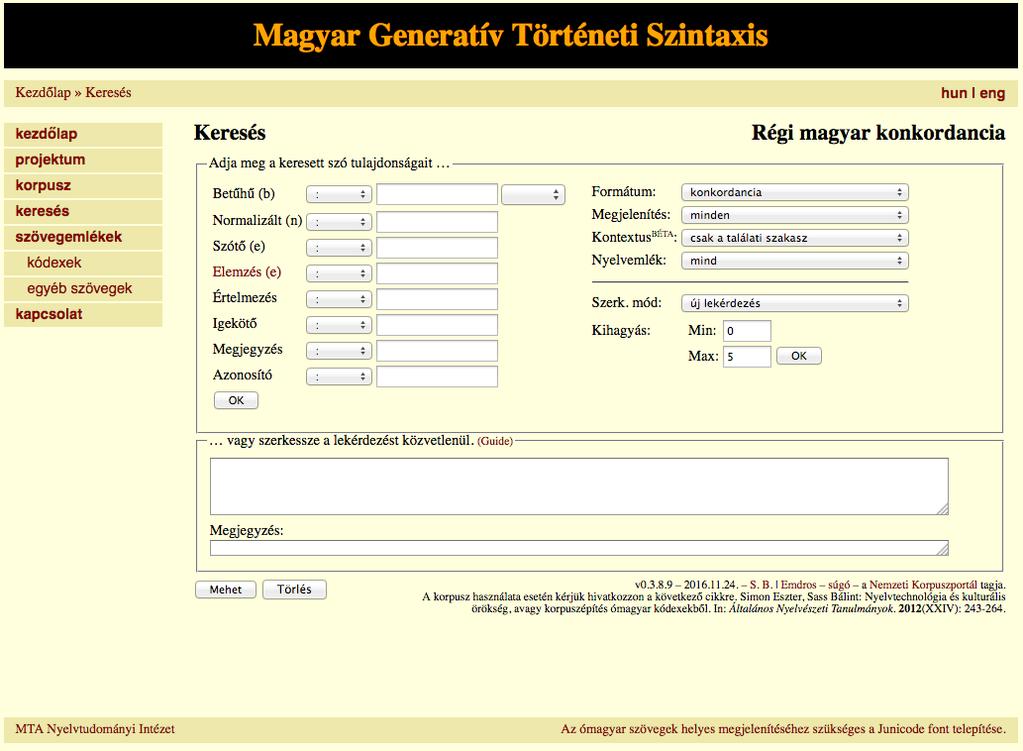
24 A felhasználói felület

25 A lekérdezés eredménye: konkordancia
26 A lekérdezés eredménye: gyakorisági lista
27 Párhuzamos Bibliaolvasó bibliai fejezet- vagy vers szinten párhuzamosan lehet megjeleníteni különböző bibliafordításokat tartalmaz ó-, közép- és mai magyar bibliafordításokat, plusz a King James Bible-t terv: bibliafordítások uráli nyelveken és oroszul is
28 Köszönöm a figyelmet! simon.eszter@nytud.mta.hu
Simon Eszter. 2012. április 19. MTA Nyelvtudományi Intézet. Korpuszépítés ómagyar kódexekből. Simon Eszter. Bemutatás. Anyaggyűjtés.
 MTA Nyelvtudományi Intézet 2012 április 19 Az előadás vázlata 1 A projekt bemutatása 2 A korpusz anyagának összegyűjtése 3 A korpusz anyagának feldolgozása A betűhű szöveg előállítása 4 5 6 i elemzés és
MTA Nyelvtudományi Intézet 2012 április 19 Az előadás vázlata 1 A projekt bemutatása 2 A korpusz anyagának összegyűjtése 3 A korpusz anyagának feldolgozása A betűhű szöveg előállítása 4 5 6 i elemzés és
Magyar nyelvű történeti korpuszok
 Magyar nyelvű történeti korpuszok Simon Eszter Debrecen, 2019. február 7. MTA Nyelvtudományi Intézet Az előadás vázlata 1. A történeti korpuszok jellemzői 2. A történeti szövegek feldolgozása 3. A korpuszok
Magyar nyelvű történeti korpuszok Simon Eszter Debrecen, 2019. február 7. MTA Nyelvtudományi Intézet Az előadás vázlata 1. A történeti korpuszok jellemzői 2. A történeti szövegek feldolgozása 3. A korpuszok
Blaho Sylvia, Sass Bálint & Simon Eszter. MTA Nyelvtudományi Intézet február 4.
 A készülő MGTSz adatbázis felépítése Blaho Sylvia, Sass Bálint & Simon Eszter MTA Nyelvtudományi Intézet 2010. február 4. Az előadás vázlata 1 A projekt bemutatása A szöveg feldolgozásának szintjei A korpusz
A készülő MGTSz adatbázis felépítése Blaho Sylvia, Sass Bálint & Simon Eszter MTA Nyelvtudományi Intézet 2010. február 4. Az előadás vázlata 1 A projekt bemutatása A szöveg feldolgozásának szintjei A korpusz
Az URaLUID adatbázis bemutatása
 Hatás alatt álló nyelvek Az URaLUID adatbázis bemutatása Simon Eszter MTA Nyelvtudományi Intézet 2017. január 13. 29. Finnugor Szeminárium Simon Eszter (MTA NyTI) Hatás alatt álló nyelvek 2017. január
Hatás alatt álló nyelvek Az URaLUID adatbázis bemutatása Simon Eszter MTA Nyelvtudományi Intézet 2017. január 13. 29. Finnugor Szeminárium Simon Eszter (MTA NyTI) Hatás alatt álló nyelvek 2017. január
KORPUSZOK, LEKÉRDEZŐK, NEMZETI KORPUSZPORTÁL
 KORPUSZOK, LEKÉRDEZŐK, NEMZETI KORPUSZPORTÁL Sass Bálint sass.balint@nytud.mta.hu MTA Nyelvtudományi Intézet Nyelvtechnológiai és Alkalmazott Nyelvészeti Osztály DHU2015 WS Számítógép az irodalomtudományban
KORPUSZOK, LEKÉRDEZŐK, NEMZETI KORPUSZPORTÁL Sass Bálint sass.balint@nytud.mta.hu MTA Nyelvtudományi Intézet Nyelvtechnológiai és Alkalmazott Nyelvészeti Osztály DHU2015 WS Számítógép az irodalomtudományban
Korpuszlekérdezők evolúciója
 Korpuszlekérdezők evolúciója Sass Bálint sass.balint@nytud.mta.hu MTA Nyelvtudományi Intézet Nyelvtechnológiai és Alkalmazott Nyelvészeti Osztály 2015. november 10. korpusz? lekérdező? 2 / 19 korpusz =
Korpuszlekérdezők evolúciója Sass Bálint sass.balint@nytud.mta.hu MTA Nyelvtudományi Intézet Nyelvtechnológiai és Alkalmazott Nyelvészeti Osztály 2015. november 10. korpusz? lekérdező? 2 / 19 korpusz =
A Magyar Nemzeti Szövegtár új változatáról Váradi Tamás
 A Magyar Nemzeti Szövegtár új változatáról Váradi Tamás varadi@nytud.mta.hu MTA Nyelvtudományi Intézet Nyelvtechnológiai és Alkalmazott Nyelvészeti Osztály Tartalom Előzmény Motiváció Cél Fejlesztés Eredmény
A Magyar Nemzeti Szövegtár új változatáról Váradi Tamás varadi@nytud.mta.hu MTA Nyelvtudományi Intézet Nyelvtechnológiai és Alkalmazott Nyelvészeti Osztály Tartalom Előzmény Motiváció Cél Fejlesztés Eredmény
avagy Simon Eszter, Sass Bálint MTA Nyelvtudományi Intézet, Budapest Kivonat
 Nyelvtechnológia és kulturális örökség, avagy korpuszépítés ómagyar kódexekből Simon Eszter, Sass Bálint MTA Nyelvtudományi Intézet, Budapest {simon.eszter,sass.balint}@nytud.mta.hu Kivonat A nyelvi kulturális
Nyelvtechnológia és kulturális örökség, avagy korpuszépítés ómagyar kódexekből Simon Eszter, Sass Bálint MTA Nyelvtudományi Intézet, Budapest {simon.eszter,sass.balint}@nytud.mta.hu Kivonat A nyelvi kulturális
Nyelvelemzés sajátkezűleg a magyar INTEX rendszer. Váradi Tamás varadi@nytud.hu
 Nyelvelemzés sajátkezűleg a magyar INTEX rendszer Váradi Tamás varadi@nytud.hu Vázlat A történet eddig Az INTEX rendszer A magyar modul Az INTEX korlátai premier előtt: NooJ konklúziók, további teendők
Nyelvelemzés sajátkezűleg a magyar INTEX rendszer Váradi Tamás varadi@nytud.hu Vázlat A történet eddig Az INTEX rendszer A magyar modul Az INTEX korlátai premier előtt: NooJ konklúziók, további teendők
VIII. Magyar Számítógépes. Nyelvészeti Konferencia MSZNY 2011. Szerkesztette: Tanács Attila. Vincze Veronika
 VIII. Magyar Számítógépes Nyelvészeti Konferencia MSZNY 2011 Szerkesztette: Tanács Attila Vincze Veronika Szeged, 2011. december 1-2. http://www.inf.u-szeged.hu/mszny2011 Tartalomjegyzék I. Többnyelvuség
VIII. Magyar Számítógépes Nyelvészeti Konferencia MSZNY 2011 Szerkesztette: Tanács Attila Vincze Veronika Szeged, 2011. december 1-2. http://www.inf.u-szeged.hu/mszny2011 Tartalomjegyzék I. Többnyelvuség
Motiváció Eszközök és eljárások Eredmények Távlat. Sass Bálint joker@nytud.hu
 VONZATKERETEK A MAGYAR NEMZETI SZÖVEGTÁRBAN Sass Bálint joker@nytud.hu Magyar Tudományos Akadémia Nyelvtudományi Intézet Korpusznyelvészeti Osztály MSZNY2005 Szeged, 2005. december 8-9. 1 MOTIVÁCIÓ 2 ESZKÖZÖK
VONZATKERETEK A MAGYAR NEMZETI SZÖVEGTÁRBAN Sass Bálint joker@nytud.hu Magyar Tudományos Akadémia Nyelvtudományi Intézet Korpusznyelvészeti Osztály MSZNY2005 Szeged, 2005. december 8-9. 1 MOTIVÁCIÓ 2 ESZKÖZÖK
SZÁMÍTÓGÉPES NYELVI ADATBÁZISOK
 SZÁMÍTÓGÉPES NYELVI ADATBÁZISOK A MAGYARÓRÁN Sass Bálint joker@nytud.hu Magyar Tudományos Akadémia Nyelvtudományi Intézet Korpusznyelvészeti Osztály XVI. MANYE kongresszus Gödöllő, 2006. április 10-12.
SZÁMÍTÓGÉPES NYELVI ADATBÁZISOK A MAGYARÓRÁN Sass Bálint joker@nytud.hu Magyar Tudományos Akadémia Nyelvtudományi Intézet Korpusznyelvészeti Osztály XVI. MANYE kongresszus Gödöllő, 2006. április 10-12.
Magyar generatív történeti mondattan Kutatási beszámoló
 Magyar generatív történeti mondattan Kutatási beszámoló 1. Az ómagyar korpusz A projektum két feladatot tűzött maga elé és oldott meg. Egyrészt létrehoztuk az ómagyar és korai középmagyar kéziratos szövegek
Magyar generatív történeti mondattan Kutatási beszámoló 1. Az ómagyar korpusz A projektum két feladatot tűzött maga elé és oldott meg. Egyrészt létrehoztuk az ómagyar és korai középmagyar kéziratos szövegek
Morfológia, szófaji egyértelműsítés. Nyelvészet az informatikában informatika a nyelvészetben október 9.
 Morfológia, szófaji egyértelműsítés Nyelvészet az informatikában informatika a nyelvészetben 2013. október 9. Előző órán Morfológiai alapfogalmak Szóelemzések Ismeretlen szavak elemzése Mai órán Szófajok
Morfológia, szófaji egyértelműsítés Nyelvészet az informatikában informatika a nyelvészetben 2013. október 9. Előző órán Morfológiai alapfogalmak Szóelemzések Ismeretlen szavak elemzése Mai órán Szófajok
A kibővített Magyar történeti szövegtár új keresőfelülete
 A kibővített Magyar történeti szövegtár új keresőfelülete Sass Bálint MTA Nyelvtudományi Intézet sass.balint@nytud.mta.hu A nyelvtörténeti kutatások újabb eredményei IX. 2016. április 27., Szeged Nszt
A kibővített Magyar történeti szövegtár új keresőfelülete Sass Bálint MTA Nyelvtudományi Intézet sass.balint@nytud.mta.hu A nyelvtörténeti kutatások újabb eredményei IX. 2016. április 27., Szeged Nszt
Hibrid előfeldolgozó algoritmusok morfológiailag komplex nyelvek és erőforrásszegény domainek hatékony feldolgozására Orosz György
 Hibrid előfeldolgozó algoritmusok morfológiailag komplex nyelvek és erőforrásszegény domainek hatékony feldolgozására Orosz György Témavezető: Prószéky Gábor Bevezetés Előfeldolgozó algoritmusok Napjaink
Hibrid előfeldolgozó algoritmusok morfológiailag komplex nyelvek és erőforrásszegény domainek hatékony feldolgozására Orosz György Témavezető: Prószéky Gábor Bevezetés Előfeldolgozó algoritmusok Napjaink
O & ko zèpmaǵar zoalactanÿ èlèmzo
 O & ko zèpmaǵar zoalactanÿ èlèmzo Novák Attila 1,2, Wenszky Nóra 2 1 MTA Nyelvtudományi Intézet 1068 Budapest, Benczúr utca 33. 2 MTA PPKE Nyelvtechnológiai Kutatócsoport 1083 Budapest, Práter utca 50/a
O & ko zèpmaǵar zoalactanÿ èlèmzo Novák Attila 1,2, Wenszky Nóra 2 1 MTA Nyelvtudományi Intézet 1068 Budapest, Benczúr utca 33. 2 MTA PPKE Nyelvtechnológiai Kutatócsoport 1083 Budapest, Práter utca 50/a
Petőfi Irodalmi Múzeum. megújuló rendszere technológiaváltás
 Petőfi Irodalmi Múzeum A Digitális Irodalmi Akadémia megújuló rendszere technológiaváltás II. Partnerek, feladatok Petőfi Irodalmi Múzeum Megrendelő, szakmai vezetés, kontroll Konzorcium MTA SZTAKI Internet
Petőfi Irodalmi Múzeum A Digitális Irodalmi Akadémia megújuló rendszere technológiaváltás II. Partnerek, feladatok Petőfi Irodalmi Múzeum Megrendelő, szakmai vezetés, kontroll Konzorcium MTA SZTAKI Internet
Bevezetés az e-magyar programcsomag használatába
 Bevezetés az e-magyar programcsomag használatába Vadász Noémi 2019. február 7. MTA Nyelvtudományi Intézet vadasz.noemi@nytud.mta.hu Az előadás felépítése 1. szövegelemzés számítógéppel elemzési lépések
Bevezetés az e-magyar programcsomag használatába Vadász Noémi 2019. február 7. MTA Nyelvtudományi Intézet vadasz.noemi@nytud.mta.hu Az előadás felépítése 1. szövegelemzés számítógéppel elemzési lépések
Az igekötők gépi annotálásának problémái Kalivoda Ágnes
 Az igekötők gépi annotálásának problémái Kalivoda Ágnes Budapest, 2017. február 3. PPKE BTK Bevezetés Mi a probléma? Homográf szóalakok hibás szófaji címkét kaphatnak Mi a megoldás? Szabály alapú javítás
Az igekötők gépi annotálásának problémái Kalivoda Ágnes Budapest, 2017. február 3. PPKE BTK Bevezetés Mi a probléma? Homográf szóalakok hibás szófaji címkét kaphatnak Mi a megoldás? Szabály alapú javítás
Beszéd- és nyelvelemző szoftverek a versenyképességért és az esélyegyenlőségért
 Szegedi Tudományegyetem Juhász Gyula Pedagógusképző Kar Magyar és Alkalmazott Nyelvészeti Tanszék Beszéd- és nyelvelemző szoftverek a versenyképességért és az esélyegyenlőségért HunCLARIN korpuszok és
Szegedi Tudományegyetem Juhász Gyula Pedagógusképző Kar Magyar és Alkalmazott Nyelvészeti Tanszék Beszéd- és nyelvelemző szoftverek a versenyképességért és az esélyegyenlőségért HunCLARIN korpuszok és
Főnévi csoportok azonosítása szabályalapú és hibrid módszerekkel
 Főnévi csoportok azonosítása szabályalapú és hibrid módszerekkel MTA SZTAKI Nyelvtechnológiai Kutatócsoport recski@sztaki.hu TLP20 2010. november 25. Tartalom Előzmények A feladat A hunchunk rendszer A
Főnévi csoportok azonosítása szabályalapú és hibrid módszerekkel MTA SZTAKI Nyelvtechnológiai Kutatócsoport recski@sztaki.hu TLP20 2010. november 25. Tartalom Előzmények A feladat A hunchunk rendszer A
Korpusznyelvészet április 18., ELTE. Sass Bálint MTA Nyelvtudományi Intézet 1/29
 Korpusznyelvészet 2016 április 18, ELTE Sass Bálint MTA Nyelvtudományi Intézet sassbalint@nytudmtahu 1/29 http://nsztnytudhu/nszthtml 2/29 Mi mindent kell csinálni ahhoz, hogy sima szövegből ilyen korpuszlekérdezőfelület
Korpusznyelvészet 2016 április 18, ELTE Sass Bálint MTA Nyelvtudományi Intézet sassbalint@nytudmtahu 1/29 http://nsztnytudhu/nszthtml 2/29 Mi mindent kell csinálni ahhoz, hogy sima szövegből ilyen korpuszlekérdezőfelület
LEADER. Helyi Fejlesztési Stratégiák. tervezését támogató alkalmazás
 TeIR LEADER Helyi Fejlesztési Stratégiák tervezését támogató alkalmazás Felhasználói útmutató Budapest, 2015. szeptember Tartalomjegyzék 1. BEVEZETŐ... 3 2. AZ ALKALMAZÁS BEMUTATÁSA... 3 2.1. HELYI AKCIÓCSOPORT/TELEPÜLÉS
TeIR LEADER Helyi Fejlesztési Stratégiák tervezését támogató alkalmazás Felhasználói útmutató Budapest, 2015. szeptember Tartalomjegyzék 1. BEVEZETŐ... 3 2. AZ ALKALMAZÁS BEMUTATÁSA... 3 2.1. HELYI AKCIÓCSOPORT/TELEPÜLÉS
A HG-1 Treebank és keresőfelület fejlesztői munkái, használata és felhasználhatósága
 A HG-1 Treebank és keresőfelület fejlesztői munkái, használata és felhasználhatósága Az elemzésektől a keresőfelületig DELITE Angol Nyelvészeti Tanszék 2014. 03. 12. Csernyi Gábor 1 Célok, előzmények Mit?
A HG-1 Treebank és keresőfelület fejlesztői munkái, használata és felhasználhatósága Az elemzésektől a keresőfelületig DELITE Angol Nyelvészeti Tanszék 2014. 03. 12. Csernyi Gábor 1 Célok, előzmények Mit?
Nemzeti LEADER Kézikönyv LEADER HELYI FEJLESZTÉSI STRATÉGIA FELHASZNÁLÓI KÉZIKÖNYV. 2015. szeptember
 Nemzeti LEADER Kézikönyv LEADER HELYI FEJLESZTÉSI STRATÉGIA 2014 2020 2015. szeptember Készült a Miniszterelnökség Agrár Vidékfejlesztési Programokért Felelős Helyettes Államtitkárság, mint a Magyarország
Nemzeti LEADER Kézikönyv LEADER HELYI FEJLESZTÉSI STRATÉGIA 2014 2020 2015. szeptember Készült a Miniszterelnökség Agrár Vidékfejlesztési Programokért Felelős Helyettes Államtitkárság, mint a Magyarország
Ó Ó É ü É ü ü
 É Ó É Ú ü ű ú ú ü ü ü Ó Ó É ü É ü ü Ó ü ü ü É ü ü Ó É É ü ü ü ü ü ü ü ü ü ü ü ü ü Ó Ó ü ü ü ü ü ü ü É ü ü É ü ü ü ü ü ü Ó ü ü ü ü ü ü ü ü É Ó ü ü É Ó Ó ü ü ü ü ü É ü ü ü É ü ü ü ü ü Ó Ó ú ü ü ü ü ü ü Ó
É Ó É Ú ü ű ú ú ü ü ü Ó Ó É ü É ü ü Ó ü ü ü É ü ü Ó É É ü ü ü ü ü ü ü ü ü ü ü ü ü Ó Ó ü ü ü ü ü ü ü É ü ü É ü ü ü ü ü ü Ó ü ü ü ü ü ü ü ü É Ó ü ü É Ó Ó ü ü ü ü ü É ü ü ü É ü ü ü ü ü Ó Ó ú ü ü ü ü ü ü Ó
Adatintegritás ellenőrzés Felhasználói dokumentáció verzió 2.0 Budapest, 2008.
 Adatintegritás ellenőrzés Felhasználói dokumentáció verzió 2.0 Budapest, 2008. Változáskezelés Verzió Dátum Változás Pont Cím Oldal Kiadás: 2008.10.30. Verzió: 2.0. Oldalszám: 2 / 11 Tartalomjegyzék 1.
Adatintegritás ellenőrzés Felhasználói dokumentáció verzió 2.0 Budapest, 2008. Változáskezelés Verzió Dátum Változás Pont Cím Oldal Kiadás: 2008.10.30. Verzió: 2.0. Oldalszám: 2 / 11 Tartalomjegyzék 1.




Fonetika és fonológia
 Fonetika és fonológia Előadás 2015. október Balogné Bérces Katalin PPKE BTK, Budapest/Piliscsaba 1: Bevezetés: Fonetika és fonológia Fonetika és fonológia fonetika: a beszédhangok fizikai tulajdonságai
Fonetika és fonológia Előadás 2015. október Balogné Bérces Katalin PPKE BTK, Budapest/Piliscsaba 1: Bevezetés: Fonetika és fonológia Fonetika és fonológia fonetika: a beszédhangok fizikai tulajdonságai
Nyelvészet. I. Témakör: Leíró nyelvtan
 Nyelvészet I. Témakör: Leíró nyelvtan 1. A magyar magánhangzó-harmónia és a hangtani hasonulások jellegzetességei KASSAI ILONA (1998): A beszédlánc fonetikai jelenségei. In: Kassai Ilona: Fonetika. Budapest:
Nyelvészet I. Témakör: Leíró nyelvtan 1. A magyar magánhangzó-harmónia és a hangtani hasonulások jellegzetességei KASSAI ILONA (1998): A beszédlánc fonetikai jelenségei. In: Kassai Ilona: Fonetika. Budapest:
ű ű ű Ö ű ű ű Ú ű ű ű Ö ű ű ű ű ű ű ű
 ű Ö É ű É Ö ű ű ű ű ű ű ű ű ű Ö ű ű ű Ú ű ű ű Ö ű ű ű ű ű ű ű Ú Ú Ú Ü É É É É ű É Ú É ű É Ó Ö É É ű ű ű É ű Ö Ö ű Ö Ú ű ű ű Ú ű ű ű Ö ű ű ű É ű ű ű Ó Ü É É Ú Ú Ü Ü Ö Ó ű Ü Ü ű ű É Ó Ó ű ű Ü Ö Ó Ö Ü Ü ű
ű Ö É ű É Ö ű ű ű ű ű ű ű ű ű Ö ű ű ű Ú ű ű ű Ö ű ű ű ű ű ű ű Ú Ú Ú Ü É É É É ű É Ú É ű É Ó Ö É É ű ű ű É ű Ö Ö ű Ö Ú ű ű ű Ú ű ű ű Ö ű ű ű É ű ű ű Ó Ü É É Ú Ú Ü Ü Ö Ó ű Ü Ü ű ű É Ó Ó ű ű Ü Ö Ó Ö Ü Ü ű

Ú Ú Ü Ü ű ű ű É Ú É ű
 É Ó ű ű Ö Ú Ú Ü Ü ű ű ű É Ú É ű É ű ű ű Ü ű É ű Ű Ö ű ű ű Ú Ú É É Ó Ó Ú ű ű É Ú É Ü Ü Ú ű Ú Ó É Ü ű É ű ű ű Ö ű ű ű Ö Ö Ú ű Ü Ú Ö ű Ü ű Ü ű ű Ü Ö ű ű ű Ú Ü Ú Ó ű ű É É ű ű ű ű ű Ö ű ű ű ű ű ű ű Ö ű ű ű
É Ó ű ű Ö Ú Ú Ü Ü ű ű ű É Ú É ű É ű ű ű Ü ű É ű Ű Ö ű ű ű Ú Ú É É Ó Ó Ú ű ű É Ú É Ü Ü Ú ű Ú Ó É Ü ű É ű ű ű Ö ű ű ű Ö Ö Ú ű Ü Ú Ö ű Ü ű Ü ű ű Ü Ö ű ű ű Ú Ü Ú Ó ű ű É É ű ű ű ű ű Ö ű ű ű ű ű ű ű Ö ű ű ű

Ó Ó ú ú ú ú ú É ú
 É Ö É ű ú É Ó É ú ú ú Ó Ó ú ú ú ú ú É ú Ó Ó ú É ú É ú Ó Ö É Ó Ó ú É ú Ö Ó Ó ú ú É É É ú Ó Ó É ú ú ú ú ú ú ú ú ú ú É Ú É Ó Ó ú ú Ó Ó Ö Ö É É É ú É É ú ú É É Ó Ó É Ű ú É Ó Ó Ű Ú ú ú É Ú Ú É Ú Ó Ó Ó É É É
É Ö É ű ú É Ó É ú ú ú Ó Ó ú ú ú ú ú É ú Ó Ó ú É ú É ú Ó Ö É Ó Ó ú É ú Ö Ó Ó ú ú É É É ú Ó Ó É ú ú ú ú ú ú ú ú ú ú É Ú É Ó Ó ú ú Ó Ó Ö Ö É É É ú É É ú ú É É Ó Ó É Ű ú É Ó Ó Ű Ú ú ú É Ú Ú É Ú Ó Ó Ó É É É

Ó ú É ú É É É Ő ú ú ű Ó Ö É É ú Ü ú É ú
 É Ó Ö É Ü ű ú Ü ÉÚ É ú ú ű ú Ó ú É ú É É É Ő ú ú ű Ó Ö É É ú Ü ú É ú Ó ú Ü Ü ú ű Ü Ö Ó ú ú ú ú É Ü ú ú Ü Ü Ó Ó É ú ú É É É É Ú Ü Ü ú Ü ú ú É Ő Ő ú É Ó Ó É Ő Ü Ó Ő ú Ó Ó É É ú Ü Ó Ó Ó É ú Ü Ú Ö Ü É ú Ó
É Ó Ö É Ü ű ú Ü ÉÚ É ú ú ű ú Ó ú É ú É É É Ő ú ú ű Ó Ö É É ú Ü ú É ú Ó ú Ü Ü ú ű Ü Ö Ó ú ú ú ú É Ü ú ú Ü Ü Ó Ó É ú ú É É É É Ú Ü Ü ú Ü ú ú É Ő Ő ú É Ó Ó É Ő Ü Ó Ő ú Ó Ó É É ú Ü Ó Ó Ó É ú Ü Ú Ö Ü É ú Ó

Kinek szól a könyv? A könyv témája A könyv felépítése Mire van szükség a könyv használatához? A könyvben használt jelölések. 1. Mi a programozás?
 Bevezetés Kinek szól a könyv? A könyv témája A könyv felépítése Mire van szükség a könyv használatához? A könyvben használt jelölések Forráskód Hibajegyzék p2p.wrox.com xiii xiii xiv xiv xvi xvii xviii
Bevezetés Kinek szól a könyv? A könyv témája A könyv felépítése Mire van szükség a könyv használatához? A könyvben használt jelölések Forráskód Hibajegyzék p2p.wrox.com xiii xiii xiv xiv xvi xvii xviii
ű ő ű ű ű ö ő ú ö ő ő ő ő ő ő ő ű ő ő ő ő ü ü ő ü ü ő ú ü ő ő ü ü ü ő ú ü
 Ö ü ö ő ú ö ü ű ö ö ö ö ő ő ö ő ü ö ö ő ö ö ü ú ö ü ő ő ö ú ő ü ü ü ű ű ű ő ű ű ű ö ő ú ö ő ő ő ő ő ő ő ű ő ő ő ő ü ü ő ü ü ő ú ü ő ő ü ü ü ő ú ü ő ü ü ő ő ü ü ő ő ú ő ú ő ü ü ő ü ő ú ü Ü ő ő ö ő ü ő ü
Ö ü ö ő ú ö ü ű ö ö ö ö ő ő ö ő ü ö ö ő ö ö ü ú ö ü ő ő ö ú ő ü ü ü ű ű ű ő ű ű ű ö ő ú ö ő ő ő ő ő ő ő ű ő ő ő ő ü ü ő ü ü ő ú ü ő ő ü ü ü ő ú ü ő ü ü ő ő ü ü ő ő ú ő ú ő ü ü ő ü ő ú ü Ü ő ő ö ő ü ő ü
PurePos: hatékony morfológiai egyértelműsítő modul
 PurePos: hatékony morfológiai egyértelműsítő modul Orosz György PPKE ITK Interdiszciplináris Műszaki Tudományok Doktori Iskola oroszgy@itk.ppke.hu Kivonat: A szófaji egyértelműsítés a számítógépes nyelvfeldolgozás
PurePos: hatékony morfológiai egyértelműsítő modul Orosz György PPKE ITK Interdiszciplináris Műszaki Tudományok Doktori Iskola oroszgy@itk.ppke.hu Kivonat: A szófaji egyértelműsítés a számítógépes nyelvfeldolgozás

BODROGKOZ.COM / HASZNÁLATI ÚTMUTATÓ
 BODROGKOZ.COM / HASZNÁLATI ÚTMUTATÓ 1. Adminisztrációs felület elérhetősége: http://www.bodrogkoz.com/wp-admin/ vagy http://www.bodrogkoz.com/wp-login.php A honlap tesztidőszak alatt az alábbi címen érhető
BODROGKOZ.COM / HASZNÁLATI ÚTMUTATÓ 1. Adminisztrációs felület elérhetősége: http://www.bodrogkoz.com/wp-admin/ vagy http://www.bodrogkoz.com/wp-login.php A honlap tesztidőszak alatt az alábbi címen érhető
Tájékoztató. Használható segédeszköz: -
 A 12/2013. (III. 29.) NFM rendelet szakmai és vizsgakövetelménye alapján. Szakképesítés, azonosítószáma és megnevezése 54 481 06 Informatikai rendszerüzemeltető Tájékoztató A vizsgázó az első lapra írja
A 12/2013. (III. 29.) NFM rendelet szakmai és vizsgakövetelménye alapján. Szakképesítés, azonosítószáma és megnevezése 54 481 06 Informatikai rendszerüzemeltető Tájékoztató A vizsgázó az első lapra írja
Egészítsük ki a Drupal-t. Drupal modul fejlesztés
 Egészítsük ki a Drupal-t Drupal modul fejlesztés Drupal 6.0 2008. február 13. Miért írjunk Drupal modult? Nincs az igényeinknek megfelelő modul Valamilyen közösségi igény kielégítése Valami nem úgy működik
Egészítsük ki a Drupal-t Drupal modul fejlesztés Drupal 6.0 2008. február 13. Miért írjunk Drupal modult? Nincs az igényeinknek megfelelő modul Valamilyen közösségi igény kielégítése Valami nem úgy működik
Ha megnyitottad az e Sword-öt, és a Biblia feliratra kattintasz a Menü soron, láthatod az elérhető opciók listáját:
 4. lecke A bibliafordítások ablak Az első leckében már érintettük a bibliafordítások ablakot, most részletesebben foglalkozunk vele. Evangéliumi összhang Ha megnyitottad az e Sword-öt, és a Biblia feliratra
4. lecke A bibliafordítások ablak Az első leckében már érintettük a bibliafordítások ablakot, most részletesebben foglalkozunk vele. Evangéliumi összhang Ha megnyitottad az e Sword-öt, és a Biblia feliratra
Új Nemzedék Központ. EFOP pályázatok online beszámoló felülete. Felhasználói útmutató
 Új Nemzedék Központ EFOP pályázatok online beszámoló felülete Felhasználói útmutató Tartalom 1. Bejelentkezés... 2 1.1. Első bejelentkezés... 2 1.2. Elfelejtett jelszó... 3 2. Saját adatok... 4 3. Dokumentumok...
Új Nemzedék Központ EFOP pályázatok online beszámoló felülete Felhasználói útmutató Tartalom 1. Bejelentkezés... 2 1.1. Első bejelentkezés... 2 1.2. Elfelejtett jelszó... 3 2. Saját adatok... 4 3. Dokumentumok...
Nyilvántartási Rendszer
 Nyilvántartási Rendszer Veszprém Megyei Levéltár 2011.04.14. Készítette: Juszt Miklós Honnan indultunk? Rövid történeti áttekintés 2003 2007 2008-2011 Access alapú raktári topográfia Adatbázis optimalizálás,
Nyilvántartási Rendszer Veszprém Megyei Levéltár 2011.04.14. Készítette: Juszt Miklós Honnan indultunk? Rövid történeti áttekintés 2003 2007 2008-2011 Access alapú raktári topográfia Adatbázis optimalizálás,
SZÖVEGES LEJEGYZÉSBŐL NYELVI ADATBÁZIS
 SZÖVEGES LEJEGYZÉSBŐL NYELVI ADATBÁZIS Oravecz Csaba és Sass Bálint {oravecz,joker}@nytud.hu MTA Nyelvtudományi Intézet BUSZI I. szimpózium 2008. december 9. 1 BEVEZETŐ (Beszélt) nyelvi adatbázis 2 KITEKINTÉS
SZÖVEGES LEJEGYZÉSBŐL NYELVI ADATBÁZIS Oravecz Csaba és Sass Bálint {oravecz,joker}@nytud.hu MTA Nyelvtudományi Intézet BUSZI I. szimpózium 2008. december 9. 1 BEVEZETŐ (Beszélt) nyelvi adatbázis 2 KITEKINTÉS
Különírás-egybeírás automatikusan
 Különírás-egybeírás automatikusan Ludányi Zsófia ludanyi.zsofia@nytud.mta.hu Magyar Tudományos Akadémia, Nyelvtudományi Intézet Nyelvtechnológiai Osztály VII. Alkalmazott Nyelvészeti Doktoranduszkonferencia
Különírás-egybeírás automatikusan Ludányi Zsófia ludanyi.zsofia@nytud.mta.hu Magyar Tudományos Akadémia, Nyelvtudományi Intézet Nyelvtechnológiai Osztály VII. Alkalmazott Nyelvészeti Doktoranduszkonferencia
Segédanyagok. Formális nyelvek a gyakorlatban. Szintaktikai helyesség. Fordítóprogramok. Formális nyelvek, 1. gyakorlat
 Formális nyelvek a gyakorlatban Formális nyelvek, 1 gyakorlat Segédanyagok Célja: A programozási nyelvek szintaxisának leírására használatos eszközök, módszerek bemutatása Fogalmak: BNF, szabály, levezethető,
Formális nyelvek a gyakorlatban Formális nyelvek, 1 gyakorlat Segédanyagok Célja: A programozási nyelvek szintaxisának leírására használatos eszközök, módszerek bemutatása Fogalmak: BNF, szabály, levezethető,
A Hunglish Korpusz és szótár
 A Hunglish Korpusz és szótár Halácsy Péter 1, Kornai András 1, Németh László 1, Sass Bálint 2 Varga Dániel 1, Váradi Tamás 1 BME Média Oktató és Kutató Központ 1111 Budapest, Stoczek u. 2 {hp,nemeth,daniel}@mokk.bme.hu
A Hunglish Korpusz és szótár Halácsy Péter 1, Kornai András 1, Németh László 1, Sass Bálint 2 Varga Dániel 1, Váradi Tamás 1 BME Média Oktató és Kutató Központ 1111 Budapest, Stoczek u. 2 {hp,nemeth,daniel}@mokk.bme.hu
HVK Adminisztrátori használati útmutató
 HVK Adminisztrátori használati útmutató Tartalom felöltés, Hírek karbantartása A www.mvfportal.hu oldalon a bejelentkezést követően a rendszer a felhasználó jogosultsági besorolásának megfelelő nyitó oldalra
HVK Adminisztrátori használati útmutató Tartalom felöltés, Hírek karbantartása A www.mvfportal.hu oldalon a bejelentkezést követően a rendszer a felhasználó jogosultsági besorolásának megfelelő nyitó oldalra
Felhasználói kézikönyv. ÜFT szolgáltatás. Magyar Nemzeti Bank
 Felhasználói kézikönyv ÜFT szolgáltatás Magyar Nemzeti Bank TARTALOMJEGYZÉK 1. BEVEZETÉS... 3 2. FOGALOMTÁR... 3 3. KÉSZPÉNZÁLLÁTÁSI ÜTF (KÜFT) MODUL... 3 3.1. A KÜFT MODUL FUNKCIÓI... 3 3.1.1. Pénzintézet
Felhasználói kézikönyv ÜFT szolgáltatás Magyar Nemzeti Bank TARTALOMJEGYZÉK 1. BEVEZETÉS... 3 2. FOGALOMTÁR... 3 3. KÉSZPÉNZÁLLÁTÁSI ÜTF (KÜFT) MODUL... 3 3.1. A KÜFT MODUL FUNKCIÓI... 3 3.1.1. Pénzintézet
ELO kliens funkciók összehasonlítása
 funkciók összehasonlítása összehasonlítás Java Web mobil Platform független Kliens telepítés szükséges (és Webstart) Unicode képes Vonalkód támogatása Dokumentumok egyenkénti vagy összefűzött szkennelése
funkciók összehasonlítása összehasonlítás Java Web mobil Platform független Kliens telepítés szükséges (és Webstart) Unicode képes Vonalkód támogatása Dokumentumok egyenkénti vagy összefűzött szkennelése
Szövegbányászati rendszer fejlesztése a Magyar Elektronikus Könyvtár számára
 Szövegbányászati rendszer fejlesztése a Magyar Elektronikus Könyvtár számára Vázsonyi Miklós VÁZSONYI Informatikai és Tanácsadó Kft. BME Információ- és Tudásmenedzsment Tanszék 1/23 Tartalom A MEK jelenlegi
Szövegbányászati rendszer fejlesztése a Magyar Elektronikus Könyvtár számára Vázsonyi Miklós VÁZSONYI Informatikai és Tanácsadó Kft. BME Információ- és Tudásmenedzsment Tanszék 1/23 Tartalom A MEK jelenlegi
PureToken: egy új tokenizáló eszköz
 Szeged, 2013. január 7 8. 305 PureToken: egy új tokenizáló eszköz Indig Balázs 1 1 Pázmány Péter Katolikus Egyetem, Információs Technológiai Kar, MTA-PPKE Magyar Nyelvtechnológiai Kutatócsoport 1083 Budapest,
Szeged, 2013. január 7 8. 305 PureToken: egy új tokenizáló eszköz Indig Balázs 1 1 Pázmány Péter Katolikus Egyetem, Információs Technológiai Kar, MTA-PPKE Magyar Nyelvtechnológiai Kutatócsoport 1083 Budapest,
Dokumentumformátumok Jelölő nyelvek XML XML. Sass Bálint sass@digitus.itk.ppke.hu. Bevezetés a nyelvtechnológiába 2. gyakorlat 2007. szeptember 20.
 XML Sass Bálint sass@digitus.itk.ppke.hu Bevezetés a nyelvtechnológiába 2. gyakorlat 2007. szeptember 20. 1 DOKUMENTUMFORMÁTUMOK 2 JELÖLŐ NYELVEK 3 XML 1 DOKUMENTUMFORMÁTUMOK 2 JELÖLŐ NYELVEK 3 XML DOKUMENTUMFORMÁTUMOK
XML Sass Bálint sass@digitus.itk.ppke.hu Bevezetés a nyelvtechnológiába 2. gyakorlat 2007. szeptember 20. 1 DOKUMENTUMFORMÁTUMOK 2 JELÖLŐ NYELVEK 3 XML 1 DOKUMENTUMFORMÁTUMOK 2 JELÖLŐ NYELVEK 3 XML DOKUMENTUMFORMÁTUMOK
Webes kurzus kezelés folyamata Oktatói felületek
 Webes kurzus kezelés folyamata Oktatói felületek A kurzusok kezelésével kapcsolatban számos paraméterezési lehetőség áll rendelkezésre az ETR rendszerében. Jelen dokumentumban igyekeztünk a kurzusok oktatói
Webes kurzus kezelés folyamata Oktatói felületek A kurzusok kezelésével kapcsolatban számos paraméterezési lehetőség áll rendelkezésre az ETR rendszerében. Jelen dokumentumban igyekeztünk a kurzusok oktatói
MSD-KR harmonizáció a Szeged Treebank 2.5-ben
 Szeged, 2010. december 2 3. 349 MSD-KR harmonizáció a Szeged Treebank 2.5-ben Farkas Richárd 1, Szeredi Dániel 2, Varga Dániel 2, Vincze Veronika 3 1 MTA-SZTE, Mesterséges Intelligencia Tanszéki Kutatócsoport
Szeged, 2010. december 2 3. 349 MSD-KR harmonizáció a Szeged Treebank 2.5-ben Farkas Richárd 1, Szeredi Dániel 2, Varga Dániel 2, Vincze Veronika 3 1 MTA-SZTE, Mesterséges Intelligencia Tanszéki Kutatócsoport
A Békés Megyei Könyvtár Elektronikus Könyvtárának kialakítása
 A Békés Megyei Könyvtár Elektronikus Könyvtárának kialakítása Előadók: Toldi Klára Vincze Andrea 1 Előzmények 1997-2002 A nemzetközi könyvtári trendek hatására a hazai könyvtárügyben is megjelenik az informatika
A Békés Megyei Könyvtár Elektronikus Könyvtárának kialakítása Előadók: Toldi Klára Vincze Andrea 1 Előzmények 1997-2002 A nemzetközi könyvtári trendek hatására a hazai könyvtárügyben is megjelenik az informatika
Dimag.hu médiaajánlat
 Dimag.hu médiaajánlat Tartalom 1 Infinety bemutatkozás - Új portfólió az élvonalban! 2 A Dimag.hu bemutatkozás 3 A Dimag.hu tartalmi elemei 4 A Dimag.hu strukturális felépítése 5 Látogatottsági és demográfiai
Dimag.hu médiaajánlat Tartalom 1 Infinety bemutatkozás - Új portfólió az élvonalban! 2 A Dimag.hu bemutatkozás 3 A Dimag.hu tartalmi elemei 4 A Dimag.hu strukturális felépítése 5 Látogatottsági és demográfiai
Magyar Biblia a reformáció korában
 Magyar Biblia a reformáció korában Komjáti Benedek Pozsonyi kanonok volt, s 1527 és 1529 között a bécsi egyetemen tanult. A török elől menekült, amint maga írja, Huszt várába. Perényiné Frangepán Katalin,
Magyar Biblia a reformáció korában Komjáti Benedek Pozsonyi kanonok volt, s 1527 és 1529 között a bécsi egyetemen tanult. A török elől menekült, amint maga írja, Huszt várába. Perényiné Frangepán Katalin,
ELŐTANULMÁNYI REND SOLA SCRIPTURA TEOLÓGIAI FŐISKOLA TEOLÓGIA SZAK (alapképzés) 2015/2016-os tanévtől kifutó
 2015/2016-os tanévtől kifutó") KÓD 1 TANEGYSÉG OKTATÓ KREDI T A FELVÉTEL FELTÉTELE 2 SZÁMONKÉRÉS MEGJEGYZÉS TKÓ1 Genezis Dr. Reisinger János _ TKÓ2 Az Ószövetség világa Nagy Viktória Izrael története TKÓ3 Nagy prófétai könyvek 1. (Dániel)
KÓD 1 TANEGYSÉG OKTATÓ KREDI T A FELVÉTEL FELTÉTELE 2 SZÁMONKÉRÉS MEGJEGYZÉS TKÓ1 Genezis Dr. Reisinger János _ TKÓ2 Az Ószövetség világa Nagy Viktória Izrael története TKÓ3 Nagy prófétai könyvek 1. (Dániel)
w w w. h a n s a g i i s k. h u
 Weblapkészítés weblap: hypertext kódolású dokumentumok, melyek szöveget képet linkeket, könyvjelzőket/horgonyokat táblázatokat / szövegdobozokat és más objektumokat tartalmaznak. Kódolásuk HTML (Hypertext
Weblapkészítés weblap: hypertext kódolású dokumentumok, melyek szöveget képet linkeket, könyvjelzőket/horgonyokat táblázatokat / szövegdobozokat és más objektumokat tartalmaznak. Kódolásuk HTML (Hypertext
Keresés korpuszban október 19., SZTE JGYPK Sass Bálint MTA Nyelvtudományi Intézet
 Keresés korpuszban Beszéd- és nyelvelemző szoftverek a versenyképességért és az esélyegyenlőségért 2018. október 19., SZTE JGYPK Sass Bálint MTA Nyelvtudományi Intézet sass.balint@nytud.mta.hu Témák NoSkE
Keresés korpuszban Beszéd- és nyelvelemző szoftverek a versenyképességért és az esélyegyenlőségért 2018. október 19., SZTE JGYPK Sass Bálint MTA Nyelvtudományi Intézet sass.balint@nytud.mta.hu Témák NoSkE
A tankönyvvé nyilvánítás folyamatát elektronikusan támogató rendszer az OKÉV számára
 AITIA International Zrt. 1039 Budapest, Czetz János u. 48-50. Tel.: +36 1 453 8080 Fax.: +36 1 453 8081 www.aitia.hu A tankönyvvé nyilvánítás folyamatát elektronikusan támogató rendszer az OKÉV számára
AITIA International Zrt. 1039 Budapest, Czetz János u. 48-50. Tel.: +36 1 453 8080 Fax.: +36 1 453 8081 www.aitia.hu A tankönyvvé nyilvánítás folyamatát elektronikusan támogató rendszer az OKÉV számára
Az alábbiakban a portál felépítéséről, illetve az egyes lekérdező funkciókról kaphat részletes információkat.
 Súgó Az alábbiakban a portál felépítéséről, illetve az egyes lekérdező funkciókról kaphat részletes információkat. A lekérdező rendszer a Hírközlési Szolgáltatások és Interfész bejelentések, valamint az
Súgó Az alábbiakban a portál felépítéséről, illetve az egyes lekérdező funkciókról kaphat részletes információkat. A lekérdező rendszer a Hírközlési Szolgáltatások és Interfész bejelentések, valamint az
AZ ÜGYFÉL KOMMUNIKÁCIÓ ÚJ FORMÁI POZITÍV ÜGYFÉLÉLMÉNY SZÖVEGBÁNYÁSZATI MEGOLDÁSOK
 AZ ÜGYFÉL KOMMUNIKÁCIÓ ÚJ FORMÁI POZITÍV ÜGYFÉLÉLMÉNY SZÖVEGBÁNYÁSZATI MEGOLDÁSOK HOFGESANG PÉTER ÜZLETI INTELLIGENCIA A JÖVŐ, AHOGY MI LÁTJUK Hagyományos és új kommunikációs formák Szöveges adatok Szöveganalitika
AZ ÜGYFÉL KOMMUNIKÁCIÓ ÚJ FORMÁI POZITÍV ÜGYFÉLÉLMÉNY SZÖVEGBÁNYÁSZATI MEGOLDÁSOK HOFGESANG PÉTER ÜZLETI INTELLIGENCIA A JÖVŐ, AHOGY MI LÁTJUK Hagyományos és új kommunikációs formák Szöveges adatok Szöveganalitika
Magyar nyelvű kódexek digitális alapú feldolgozása É. Kiss Katalin (MTA Nyelvtudományi Intézet és PPKE)
") Magyar nyelvű kódexek digitális alapú feldolgozása É. Kiss Katalin (MTA Nyelvtudományi Intézet és PPKE) 1. Bevezetés Írásomban röviden bemutatom az MTA Nyelvtudományi Intézetében 2009-2013 között készült
Magyar nyelvű kódexek digitális alapú feldolgozása É. Kiss Katalin (MTA Nyelvtudományi Intézet és PPKE) 1. Bevezetés Írásomban röviden bemutatom az MTA Nyelvtudományi Intézetében 2009-2013 között készült
E-Kataszteri rendszer ismertető
 E-Kataszteri rendszer ismertető Az E-Szoftverfejlesztő Kft. által fejlesztett KATAwin kataszteri és eszköznyilvántartó rendszert 2,600 db önkormányzat alkalmazza évek óta. Teljeskörű Certop minősítéssel
E-Kataszteri rendszer ismertető Az E-Szoftverfejlesztő Kft. által fejlesztett KATAwin kataszteri és eszköznyilvántartó rendszert 2,600 db önkormányzat alkalmazza évek óta. Teljeskörű Certop minősítéssel
Felhasználói segédlet a PubMed adatbázis használatához. Publikációk keresése, letöltése valamint importja
 Felhasználói segédlet a PubMed adatbázis használatához. Publikációk keresése, letöltése valamint importja A PubMed Medline adatbázis internet címe: http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=pubmed
Felhasználói segédlet a PubMed adatbázis használatához. Publikációk keresése, letöltése valamint importja A PubMed Medline adatbázis internet címe: http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=pubmed
Grafikus keretrendszer komponensalapú webalkalmazások fejlesztéséhez
 Grafikus keretrendszer komponensalapú webalkalmazások fejlesztéséhez Székely István Debreceni Egyetem, Informatikai Intézet A rendszer felépítése szerver a komponenseket szolgáltatja Java nyelvű implementáció
Grafikus keretrendszer komponensalapú webalkalmazások fejlesztéséhez Székely István Debreceni Egyetem, Informatikai Intézet A rendszer felépítése szerver a komponenseket szolgáltatja Java nyelvű implementáció
é ü ó ö é Ö é ü é é ó ö é ü ü é é ó ó ó é Á é é ü ó é ó ó é ö ö ö é é ü é ü é é ö ü ü é ó é é é é é é ö é é é é é é ö é ó ö ü é é é ü é é ó é ü ó ö é
 Ó Ö é ü ó ö é é ü é é ó ö é ü ü é é ó é é é é é é ö é é é é é é é ó ö ü é é é ü ó ö é Ö é ü é é ó ö é ü ü é é ó ó ó é Á é é ü ó é ó ó é ö ö ö é é ü é ü é é ö ü ü é ó é é é é é é ö é é é é é é ö é ó ö ü
Ó Ö é ü ó ö é é ü é é ó ö é ü ü é é ó é é é é é é ö é é é é é é é ó ö ü é é é ü ó ö é Ö é ü é é ó ö é ü ü é é ó ó ó é Á é é ü ó é ó ó é ö ö ö é é ü é ü é é ö ü ü é ó é é é é é é ö é é é é é é ö é ó ö ü
Ó Ó ó ö ó
 É ó ö É Á ó ó ü ó Ü ó ö ú ű ö ö ö ü ó Ó Ó ó ö ó Ó Ó ö ö ö ü Ó Ó ö ö ü ö ó ó ü ü Ó Ó Ó Ó ó ö ó ö ó ö ó ö ü ö ö ü ö ó ü ö ü ö ö ö ü ü ö ü É ü ö ü ü ö ó ü ü ü ü Ó Ó ü ö ö ü ö ó ö ö ü ó ü ó ö ü ö ü ö ü ö ó
É ó ö É Á ó ó ü ó Ü ó ö ú ű ö ö ö ü ó Ó Ó ó ö ó Ó Ó ö ö ö ü Ó Ó ö ö ü ö ó ó ü ü Ó Ó Ó Ó ó ö ó ö ó ö ó ö ü ö ö ü ö ó ü ö ü ö ö ö ü ü ö ü É ü ö ü ü ö ó ü ü ü ü Ó Ó ü ö ö ü ö ó ö ö ü ó ü ó ö ü ö ü ö ü ö ó
Magyar nyelvű kódexek digitális alapú feldolgozása
 MAGYAR NYELVJÁRÁSOK 52 (2014): 43 56. A DEBRECENI EGYETEM MAGYAR NYELVTUDOMÁNYI TANSZÉKÉNEK LEKTORÁLT FOLYÓIRATA Magyar nyelvű kódexek digitális alapú feldolgozása É. KISS KATALIN 1. Bevezetés Írásomban
MAGYAR NYELVJÁRÁSOK 52 (2014): 43 56. A DEBRECENI EGYETEM MAGYAR NYELVTUDOMÁNYI TANSZÉKÉNEK LEKTORÁLT FOLYÓIRATA Magyar nyelvű kódexek digitális alapú feldolgozása É. KISS KATALIN 1. Bevezetés Írásomban
Alkalmazásokban. Dezsényi Csaba Ovitas Magyarország kft.
 Tudásmodellezés Kereskedelmi Alkalmazásokban Dezsényi Csaba Ovitas Magyarország kft. Tudásmenedzsment Adat -> Információ -> Tudás Intézményi tudásvagyon hatékony kezelése az üzleti célok megvalósításának
Tudásmodellezés Kereskedelmi Alkalmazásokban Dezsényi Csaba Ovitas Magyarország kft. Tudásmenedzsment Adat -> Információ -> Tudás Intézményi tudásvagyon hatékony kezelése az üzleti célok megvalósításának
Kézikönyv. Szelekciós operátorok használata
 Kézikönyv Szelekciós operátorok használata Tartalomjegyzék 1 ABAS-ERP UTASÍTÁS ÁTTEKINTÉS... 7 2 ÁRUCIKK - ÜRES... 9 3 OBJEKTUM KIVÁLASZTÁS - ÁRUCIKK MEGJELENÍTÉS... 10 4 ABAS-ERP... 18 5 OBJEKTUM KIVÁLASZTÁS
Kézikönyv Szelekciós operátorok használata Tartalomjegyzék 1 ABAS-ERP UTASÍTÁS ÁTTEKINTÉS... 7 2 ÁRUCIKK - ÜRES... 9 3 OBJEKTUM KIVÁLASZTÁS - ÁRUCIKK MEGJELENÍTÉS... 10 4 ABAS-ERP... 18 5 OBJEKTUM KIVÁLASZTÁS
Remarketing 2.0 ÉLET AZ ADWORDS ÉS FACEBOOK-ON TÚL
 Remarketing 2.0 ÉLET AZ ADWORDS ÉS FACEBOOK-ON TÚL GEIGER TAMÁS @duracelltomi linkedin.com/in/duracelltomi jabjab.hu Miről lesz szó? Ahová sokan eljutnak RTB: mi is ez? "VS": AdWords/Facebook és AdRoll/Perfect
Remarketing 2.0 ÉLET AZ ADWORDS ÉS FACEBOOK-ON TÚL GEIGER TAMÁS @duracelltomi linkedin.com/in/duracelltomi jabjab.hu Miről lesz szó? Ahová sokan eljutnak RTB: mi is ez? "VS": AdWords/Facebook és AdRoll/Perfect
Adatbázis rendszerek. 4. előadás Redundancia, normalizálás
 Adatbázis rendszerek 4. előadás Redundancia, normalizálás Molnár Bence Szerkesztette: Koppányi Zoltán HF tapasztalatok HF tapasztalatok [ABR] az email címbe! Ne emailbe küldjük a házikat, töltsétek fel
Adatbázis rendszerek 4. előadás Redundancia, normalizálás Molnár Bence Szerkesztette: Koppányi Zoltán HF tapasztalatok HF tapasztalatok [ABR] az email címbe! Ne emailbe küldjük a házikat, töltsétek fel
Tartalomjegyzék. Bevezetés 5 1. Hálaadás 9 2. Dicsőítés 25 3. Imádás 43 IMÁK ÉS MEGVALLÁSOK
 Tartalomjegyzék Bevezetés 5 1. Hálaadás 9 2. Dicsőítés 25 3. Imádás 43 IMÁK ÉS MEGVALLÁSOK Bevezetés 59 Ruth Prince előszava 63 Az Úrnak félelme 65 Megigazulás és szentség 71 Erő, egészség 85 Vezetés,
Tartalomjegyzék Bevezetés 5 1. Hálaadás 9 2. Dicsőítés 25 3. Imádás 43 IMÁK ÉS MEGVALLÁSOK Bevezetés 59 Ruth Prince előszava 63 Az Úrnak félelme 65 Megigazulás és szentség 71 Erő, egészség 85 Vezetés,

GroupWise Naptár közzétételi gazda felhasználó
 GroupWise 8 Naptár közzétételi gazda felhasználó 8 2008. október 17. Áttekintés Novell GroupWise Naptár közzétételi gazda felhasználó Gyorskalauz www.novell.com The Novell GroupWise Naptár közzétételi
GroupWise 8 Naptár közzétételi gazda felhasználó 8 2008. október 17. Áttekintés Novell GroupWise Naptár közzétételi gazda felhasználó Gyorskalauz www.novell.com The Novell GroupWise Naptár közzétételi
Alapvető beállítások elvégzése Normál nézet
 Alapvető beállítások elvégzése Normál nézet A Normál nézet egy egyszerűsített oldalképet mutat. Ez a nézet a legalkalmasabb a szöveg beírására, szerkesztésére és az egyszerűbb formázásokra. Ebben a nézetben
Alapvető beállítások elvégzése Normál nézet A Normál nézet egy egyszerűsített oldalképet mutat. Ez a nézet a legalkalmasabb a szöveg beírására, szerkesztésére és az egyszerűbb formázásokra. Ebben a nézetben
Morfológiai újítások a Szeged Korpusz 2.5-ben
 332 X. Magyar Számítógépes Nyelvészeti Konferencia Morfológiai újítások a Szeged Korpusz 2.5-ben Vincze Veronika 1,2, Varga Viktor 2, Simkó Katalin Ilona 2, Zsibrita János 2, Nagy Ágoston 2, Farkas Richárd
332 X. Magyar Számítógépes Nyelvészeti Konferencia Morfológiai újítások a Szeged Korpusz 2.5-ben Vincze Veronika 1,2, Varga Viktor 2, Simkó Katalin Ilona 2, Zsibrita János 2, Nagy Ágoston 2, Farkas Richárd
Regionális forduló november 19.
 Regionális forduló 2016. november 19. 9-10. osztályosok feladata Feladat Írjatok Markdown HTML konvertert! A markdown egy nagyon népszerű, nyílt forráskódú projektekben gyakran használt, jól olvasható
Regionális forduló 2016. november 19. 9-10. osztályosok feladata Feladat Írjatok Markdown HTML konvertert! A markdown egy nagyon népszerű, nyílt forráskódú projektekben gyakran használt, jól olvasható
A Mazsola KORPUSZLEKÉRDEZŐ
 A Mazsola KORPUSZLEKÉRDEZŐ Sass Bálint sass.balint@nytud.mta.hu MTA Nyelvtudományi Intézet PPKE ITK Eötvös Collegium Budapest, 2012. április 27. 1 / 34 1 HÁTTÉR 2 HASZNÁLAT 3 MIRE JÓ? 4 PÉLDÁK 2 / 34 1
A Mazsola KORPUSZLEKÉRDEZŐ Sass Bálint sass.balint@nytud.mta.hu MTA Nyelvtudományi Intézet PPKE ITK Eötvös Collegium Budapest, 2012. április 27. 1 / 34 1 HÁTTÉR 2 HASZNÁLAT 3 MIRE JÓ? 4 PÉLDÁK 2 / 34 1
ó Ó ú ó ó ó Á ó ó ó Á ó ó ó ó Á ó ú ó ó ó
 É ó ú ó ú ó Á ó ó ú ó ó ó ú ó ó ó ó ú ó ó ó ó ó ó ú ó ó ú ó ó ó ó Ó ú ó ó ó Á ó ó ó Á ó ó ó ó Á ó ú ó ó ó Ö ó ó ó ó ó ó ó ó ó ó ó ó Ü ó ű ú ú ó ó ó ó ó ó ó É ó É ó É ó ó ó ó ó ó É ó ú ó ó É ó ó ó ó É ó
É ó ú ó ú ó Á ó ó ú ó ó ó ú ó ó ó ó ú ó ó ó ó ó ó ú ó ó ú ó ó ó ó Ó ú ó ó ó Á ó ó ó Á ó ó ó ó Á ó ú ó ó ó Ö ó ó ó ó ó ó ó ó ó ó ó ó Ü ó ű ú ú ó ó ó ó ó ó ó É ó É ó É ó ó ó ó ó ó É ó ú ó ó É ó ó ó ó É ó
Regionális forduló november 19.
 Regionális forduló 2016. november 19. 11-13. osztályosok feladata Feladat Írjatok Markdown HTML konvertert! A markdown egy nagyon népszerű, nyílt forráskódú projektekben gyakran használt, jól olvasható
Regionális forduló 2016. november 19. 11-13. osztályosok feladata Feladat Írjatok Markdown HTML konvertert! A markdown egy nagyon népszerű, nyílt forráskódú projektekben gyakran használt, jól olvasható

Fentrol.hu - Üzemeltetési tapasztalatok
 Fentrol.hu - Üzemeltetési tapasztalatok Takács Krisztián térinformatikus 6. Foszforgézu Nyílt forráskódú Térinformatikai Munkaértekezlet Budapest, Földmérési, Távérzékelési és Földhivatali Főosztály 1149
Fentrol.hu - Üzemeltetési tapasztalatok Takács Krisztián térinformatikus 6. Foszforgézu Nyílt forráskódú Térinformatikai Munkaértekezlet Budapest, Földmérési, Távérzékelési és Földhivatali Főosztály 1149
Ó é é Ó Ó ő ű Ó Ö ü Ó é Ó ő Ó Á Ö é Ö Ó Ó é Ó Ó Ó Ó ú Ó Ó Ó Ó ű Ö Ó Ó Ó é Ó Ó ö Ö Ó Ö Ö Ó Ó Ó é ö Ö é é Ü Ó Ö Ó é Ó é ö Ó Ú Ó ő Ö Ó é é Ö ú Ó Ö ö ű ő
 É Ó Ű Á Ó É Ó Á É Ó Á ő ű Ó ú Ö ú é Ö Ó Ö ú Ó Ö ú Ó Ó Ó Ó ű é ű ű Ó Ó ú ű ű é é Ö ö Ö Ö Ó ű Ó Ö ü ű Ö Ó ő Ó ő Ó ú Ó ő Ó é Ó ű Ó Ó Ó Ó ú Ó Ó Ó Ó Ö Ó Ó ö ő ü é ü Ö é é é Á é Ó Ó ú ú ű é Ö é é é Ó é é Ó Ó
É Ó Ű Á Ó É Ó Á É Ó Á ő ű Ó ú Ö ú é Ö Ó Ö ú Ó Ö ú Ó Ó Ó Ó ű é ű ű Ó Ó ú ű ű é é Ö ö Ö Ö Ó ű Ó Ö ü ű Ö Ó ő Ó ő Ó ú Ó ő Ó é Ó ű Ó Ó Ó Ó ú Ó Ó Ó Ó Ö Ó Ó ö ő ü é ü Ö é é é Á é Ó Ó ú ú ű é Ö é é é Ó é é Ó Ó
ó ő ő ó ő ö ő ő ó ó ó ö ő ó ó ó ö ő ó ő ő ö Ö ő ö ó ő ö ő ő ú ö ö ü ö ó ö ö ö ő ö ö Ö ú ü ó ü ő ő ő ő ó ő ü ó ü ö ő ö ó ő ö ő ö ü ö ü ő ö ö ó ö ő ő ö
 ü ö ő ö ő ó ö ő ü ü ö ő ó ó ü ő ö ő ö ő ö ü ö ő ö ő ó ö ü ü ö ő ő ő ö ő ö ü ö ő ó ő ö ü ö ő ő ű ő ö ö ő ű ő ü ö Ő ó ö ö ő ü ó ü ú ű ú ő ó ó ó ő ö ő ő ö ó ö ö ő ő ö ö ó ú ő ő ö ó ö ó ö ü ó ő ő ö ó ő ő ó
ü ö ő ö ő ó ö ő ü ü ö ő ó ó ü ő ö ő ö ő ö ü ö ő ö ő ó ö ü ü ö ő ő ő ö ő ö ü ö ő ó ő ö ü ö ő ő ű ő ö ö ő ű ő ü ö Ő ó ö ö ő ü ó ü ú ű ú ő ó ó ó ő ö ő ő ö ó ö ö ő ő ö ö ó ú ő ő ö ó ö ó ö ü ó ő ő ö ó ő ő ó
ű ű ű Ú Ú Á ű Ö ű ű Ú Ő É
 Ü ű ű ű Ú Ú Á ű Ö ű ű Ú Ő É É ű Ö Ö Á É ű Ö Ö Á Ü Á ű ű Ó Ó Á Á É Ü É ű Ó Á Ó Á ű Ö ű ű É Ü Ö ű É Ö ű ű Ó ű ű Ú ű ű ű ű ű É ű É Ú Ö Á É ű ű Ó ű ű ű ű ű ű Ó ű Ü ű ű ű É ű ű Ü Ü ű ű Ő Á Á Á ű ű ű Ó Ó Ó ű
Ü ű ű ű Ú Ú Á ű Ö ű ű Ú Ő É É ű Ö Ö Á É ű Ö Ö Á Ü Á ű ű Ó Ó Á Á É Ü É ű Ó Á Ó Á ű Ö ű ű É Ü Ö ű É Ö ű ű Ó ű ű Ú ű ű ű ű ű É ű É Ú Ö Á É ű ű Ó ű ű ű ű ű ű Ó ű Ü ű ű ű É ű ű Ü Ü ű ű Ő Á Á Á ű ű ű Ó Ó Ó ű