Dr. Sima Dezső. Architektúrák III. Készítette: Kappel Krisztián. komment by Krysz, Felix (2010, 2009 ősz)
|
|
|
- Alexandra Kozma
- 7 évvel ezelőtt
- Látták:
Átírás
1 Dr. Sima Dezső Architektúrák III. Készítette: Kappel Krisztián komment by Krysz, Felix (2010, 2009 ősz)

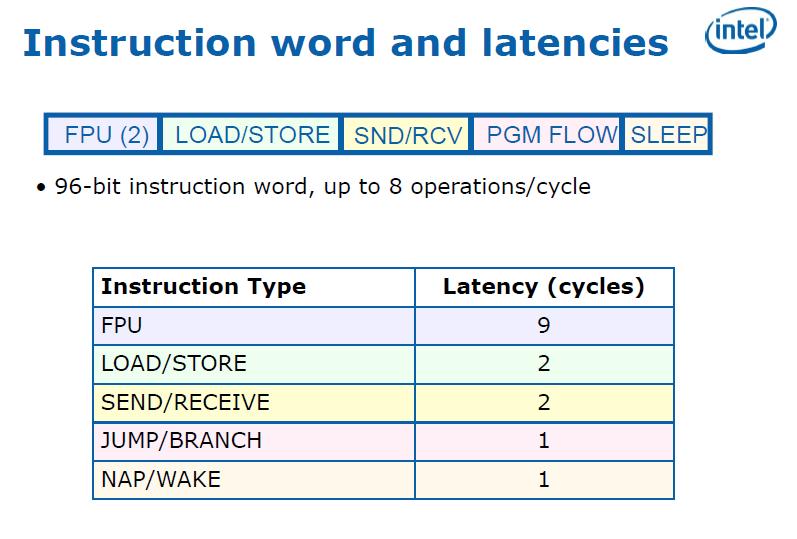
2 Az ILP feldolgozás fejlődése 2010 őszi félév Felépítés: - 2 -

3 Szaggatott nyíl: a fejlődési ív. Az ábrából kimaradt a mobil szegmens (hordozható számítógépek). Y tengely: ár. A valuepc-hez hasonló idővonalat kell elképzelni hozzá. Túlnyomórészt szerverek, desktopok, olcsó PC-k, mobil gépek. Manapság az eladásra jellemző arány: ~70% a mobil és ~30% a desktop. Szerverek fajtái: MP (multi processor), DP (dual processor), UP (uni processor). 1.számítógép 1946 ENIAC külső programvezérlésű gép volt. Ennek a fejlesztésébe Neumann nem szólhatott bele. Szuperszámítógép: Egy adott időben a legnagyobb fejlettségű gép. Mai szuperszámítógép: lebegőpontos művelet/sec (petaflops). A régi, híres gépeket tudni kell időben elhelyezni! Mainframe: középnagyságúak, első sorozatban gyártott gép UNIVAC fixpontos + decimális + karakteres, gazdasági célokra. Tárolás: ferritgyűrűs tár
 - szabványosított I/O rendszer Elsöpört mindent!")
4 1960 IBM 360-asa meghatározta a későbbi fejlődést. Mind az ötféle formátumot támogatta. - Univerzális gép - gépcsalád koncepciót valósít meg (egy egész sor CPU t mutattak be, különböző teljesítmény/ár arányban) - szabványosított I/O rendszer Elsöpört mindent! (Millió dolláros gépekről beszélünk) IBM 370: Virtuális memória (~tár) bevezetése (memória volt a szűk keresztmetszet). Minicomputer: Megjelenés 60-as évek közepe, kis teljesítményű gépek, ára egy éves jövedelemmel egyezett. Microcomputer: Intel 4004-es ~400 dolláros kit, forrasztgatás után működőképes es teljesítménynövekedés: 10 évenként százszoros!! Megjelenésének technológiai okai voltak (1960- tranzisztorgyártás, IC) Tranzisztor: Először évente duplázódik a száma, 1975-től 1,5 évente napjainkban 2 évente. Ez a Moore törvény alapja. Vonalvastagság -> Csíkszélesség 0,7x-s re csökken -> következő generációs csíkszélesség (kb. két évente). Ezzel csökkent a hőtermelés és fogyasztás is (ami dinamikus disszipációt csökkenti, ezáltal az nem növekszik *lásd később..+) 1974: Személyi számítógép Személyi ajándékként volt elképzelve, személyi használatra. UP szerverek: egy processzoros DP szerverek: két processzoros MP szerverek: 4 vagy több processzoros 81: IBM PC megjelenése (Apple, Commodore már korábban megjelentette a gépeit). Elterjedése: 1. A piac meghódítása 2. Mindent publikáltak => Klónok megjelenése, minden eszköz IBM kompatibilis lett. SOC -> System On Chip (kb. 50$) közepes szintű mikroprocesszor. Disszipáció csökkentése: Dinamikus feszültség és frekvencia skálázás DVFS 1. meghatározzák a szükséges teljesítményt 2. frekvencia hozzáillesztése a teljesítményhez 3. az órafrekvencia fenntartásához minimális feszültség kell Ez egészül ki az AVS-el (Adaptive Voltage Scaling) Worst Case jellegű meghatározás Process Voltage Temperature Gyártás után kell csinálni, minden IC-re. Beépítünk a processzorba egy sebességmérőt, ami minimális tápfeszültséget állít be. Csökkentjük a tápot, amíg az órajel engedi

5 Y tengely: teljesítmény érték. Logaritmus skála (1,10,100,1000, ) X tengely: idő skála (1,2,3,4,5, ). 10 év alatt ~100x teljesítménynövekedés ig. SPEC: teljesítménymérési módszer eljárásból fakadó számérték. Abszolút teljesítmény: hány utasítást dolgoz fel másodpercenként. Fc és IPC függő. 8088:Az Intel 8086-ból redukálták vissza (16 helyett 8 bites I/O adatbusz!, a 16 bites regiszterek megmaradtak! feldolgozás). Az IBM PC alap processzora. Az I/O határozza meg leginkább a számítógép árát. IBM PC azért 8 bites I/O-val rendelkezik, hogy olcsóbb legyen. (8086: már ehhez is lehetett csatolni co-processort - matematikai lebegőpontos társprocesszor) Növekedési ráta: 100x/ 10 év Végén megtorpanás P4-nél! 80286: protected mode megjelenése 386(1985): 32 bites architektúra. SX: 16 bites adatbusz és 32 bites regiszterek, DX: bit. Cache még nem a CPU-ban volt benne, 1. generációs futószalag. Virtuális mód megjelenése. 486(1988): DX: integrált, működőképes lebegőpontos co-processzor. SX: ugyanez le volt tiltva (később bele sem tették már) 2. Generációs futószalag (CPU-ban cache, + elágazásbecslés). (1.5 generációs: van cache, nincs elágazásbecslés. Intel nem gyártott ilyet). DX2, DX4: nem az Intel gyártotta, hanem a Cyrix és az AMD, nem referenciamodellek. EDORAM. On-die(CPU lapkára rákerült) L1. L2 külön, rendszerbuszon. Pentium(1993): 64 bit szélességű adatbusz. A feldolgozás 32 biten történik. SDRAM itt jelent meg ( MHz). Első generációs (keskeny) szuperskalár (2-3 RISC utasítás/óraciklus). A buszfrekvencia lassabban fejlődött, mint az órafrekvencia. Az AMD ekkoriban fejlesztette ki a DDR elvet: Double Data Rate. Mindkét élen adat: FSB: pl. 100 Mhz -> 400 megatranszfer, Intel a Pentium 4-ben már használta a DDR-t és a DDR2-t:
6 megatranszfer. A DDR technológia tehát nem csak a memóriához köthető Pentium 66 Mhz ig órajel = FSB. Utána: szorzók megjelenése. A 100 MHz-es Pentium esetében pl. még 66 MHz-es FSB volt. A PC-66MHz-es SDRAM óta Pentium 66 MHz-es processzorhoz hozzá lehetett illeszteni. L1 cache: külön Instruction és külön Data. Pentium MMX(1995): az első generációs szuperskalár processzor ISA kiterjesztése. 133->233 MHz L1 cache: külön Instruction és külön Data. Pentium Pro(1996): Széles szuperskalár (~4 RISC utasítás / óraciklus), általános célú alkalmazásban körülbelül ennyi utasítás párhuzamosítható pufferelt kibocsájtás esetén. Direkt kibocsátásnál: ~2). Eddig az IPC10x-növekedés, órajel szintén => 100xösszesen. Utána az IPC stagnált (elérték a 4 es szélességet), az órajelnek kellett 100x ra nőni. Dedikált buszon csatlakozik az L2 Pentium II(1997): 2,5. generációs szuperskalár processzor. Gyakorlatilag a Pentium Pro kiegészítése a MMX kiterjesztéssel, és néhány egyéb fejlesztés. 233 MHz en jött ki az első. Az FSB kezdetben 66, később 100 MHz => PC-66és PC-100SDRAM. Az Intel Celeron itt jelent meg kisebb cache-el (66 MHz) és a Celeron A (100 MHz) Dedikált buszon csatlakozik az L2, de volt olyan mag, ahol már a CPU lapkájára bekerült. Aktív hűtés megjelenése. Pentium III(1999):450 MHz-től 1.3 GHz. 2 féle tokozás: Slot-1és FCPGA. On-dieL2 cache (CPU lapkáján). Pentium IV: 3 különböző magja jelent meg. 1.Willamette 2. Northwood 3. Prescott Northwood: Behozta a többszálúságot. Prescott: behozta a 64 bitet, itt történt a torpanás! 90 nanométeres technológia A Pentium D 3,8 GHz (DualCore) kétféle magja a Prescott és a CedarMill volt. Kétmagos változatokban jelent meg az L3. Nőtt a szivárgási áram (nem lineárisan, exponenciálisan nő!!) -> statikus disszipáció Hőkatasztrófa következett be. Megjelent a Core 2 (2006), a P3 vonal ment tovább. 97-ben jelentette be az Intel, hogy a 32 bites processzort leváltja a 64 bites, de nem jött be (X86 - > IA 64) AMD: ISA-t 32-ről kibővítette 64 bitesre (nagyobb utasításkészlet kellett) 2000 Intel Tick-Tock modellt követ: Az egymást követő processzorok vagy architektúrális, vagy technológiai újításokon mennek keresztül, egyszerre a kettő túl kockázatos. A Tick jelenti a technológiaváltást architektúrához nyúlás nélkül, a Tock pedig az architektúrális váltást
 Eredményesen végrehajtott műveletek száma / sec (SIMD Single Instruction Multiple Data) P m = f c *IPC eff *OPI OPI: Műveletek száma / utasítás Mérésük a Performance Counter (pl.")
 -> nehezen mérhető Relatív teljesítmény: Egy benchmark programcsomag (banki tranzakciók pl.")
7 Abszolút teljesítmény: Eredményesen végrehajtott utasítások száma / sec P m = f c *IPC eff f c : ciklus órafrekvencia IPC eff : utasítás / ciklus effektív: hasznosult utasítás kibocsátás (elágazás miatt) Eredményesen végrehajtott műveletek száma / sec (SIMD Single Instruction Multiple Data) P m = f c *IPC eff *OPI OPI: Műveletek száma / utasítás Mérésük a Performance Counter (pl. lehívott, végrehajtott utasítások, elágazási utasítások) segítségével történik, minden CPU-nak ezen keresztül mérhető a teljesítménye. Egyszerű felhasználó nem tudja kezelni. Teljesítmény az alkalmazásfüggő (pl. lebegőpontos műveletek hosszabbak) -> nehezen mérhető Relatív teljesítmény: Egy benchmark programcsomag (banki tranzakciók pl.) valamely referenciarendszeren és a vizsgált rendszeren mért futási időnek összevetése az alábbi értelmezéssel (mértani közép). P r n t t 1 ref 1v t t nref nv Le kell mértani a tekintett rendszeren a futási időket. Azért van alul a vizsgált rendszer ideje, hogy a tört minél nagyobb lehessen (mert a rendszer valószínűleg gyorsabb a referenciánál. A tört így nagyobb lesz 1-nél. Segíti az eladást). Amit kapunk, az a gyorsítás mértani közepe. Spec benchmarkok a legismertebbek 1989-től kezdve (Pl. SPECint92, SPECint_base2000, SPEC_fp) 2 féle benchmark érték: - base (kisebb érték) : alapbeállítások, computer nincs rá optimalizálva - 7 -

8 - másik a szabadon továbbtuningolt Időben párhuzamos feldolgozás: Utasítás szempontjából minden órajelben képes utasítást végrehajtani. Itt a futószalag is behozott szűk keresztmetszetet, ezt feloldották. Párhuzamos utasításkibocsájtás: Előállnak függőségek!! Statikus függőségkezelés: architektúrát tekintve legegyszerűbb, ha a compiler-re bízzuk a függőségkezelést. VLIW esetén ez elvárás. Cache elérési idejétől függ L1: 2-3 ciklus L2: 10 ciklus L3: 30 ciklus. Amit a compiler egyszerre kibocsát, az legyen független. VLIW feldogozás elve: feldolgozó egység. Ez határozza meg a VLIW hosszát (az utasításszó mezőinek számát) -> bit hosszúak (32 bit * FE) is lehetnek. Annyi utasítás lehetséges a VLIW-ben, ahány feldolgozó egység található a processzorban. Emlékeztető: Ha van ~100 féle utasítás, akkor 8 bit hosszú a műveleti kód. Ha ~32 regiszterünk van, azt 5 biten lehet megcímezni. Amennyiben regiszter-regiszter architektúráról van szó, akkor 8 (MK) + 3(forrás,forrás,cél)*5 => 32 bit hosszú egy mező (utasítás) a VLIW ben - 8 -
9 Dinamikus függőség kezelés: Új technológia => szűk keresztmetszetek => ezek feloldása, majd a technológia határához elérkezünk => új technológia => A kibocsátott utasítások közt lehetnek olyanok, amelyek egymástól függenek, a függőségkezelés a CPU ra hárul. Compiler segítheti a párhuzamos feldolgozást, például utasítás sorrend megváltoztatásával (a legdurvább függőség a LOAD nál lép fel. A compiler minél előrébb helyezi el, hogy a kívánt adat megérkezzen, mikor szükség lesz rá. Az időigénye akár többszáz óraciklus is lehet). Továbbfejlesztési lehetőségek: Vektoros, azaz: több utasítás / művelet (SIMD). Multimédia, grafika, matematikai számítások esetén nyújt segítséget. Tehát csak dedikált alkalmazásokra tudunk hatékonyságot növelni, általános célúaknál már nem! Milyen szóhosszal kell számolnunk? 1 mező 1 feldolgozási egység 1 mező vezérléséhez 16 v 32 bit kell, ennyi kell egy utasításhoz (LOAD, STORE) jellemző szóhossz 32, ha van 6 feldolgozó egység, akkor 186! - 9 -

 => dedikált alkalmazások.")
10 Komplexitás determinálja a sorrendet. Futószalag => Szuperskalár => kiterjesztés. Az utasítások több műveletet kezdeményeznek. Csak akkor előny, ha azt az alkalmazás támogatja (pl. multimédia, grafika, matematika) => dedikált alkalmazások. CPI: Cycles per Instruction (IPC reciproka), EPIC: a VLIW új neve, Intel Itanium processzor
")
 -")
11 Teljesítmény: órajel (f c ) * hatékonyság (IPC eff )
12 A spekuláció alapvető az elágazás kezelésben és a LOAD oknál (sokáig tart az adatok beolvasása a memóriából). η: Spekulatívan végrehajtott utasítások hatékonysága = Jó utasítások száma / összes utasítás száma. ~ A lebegőpontos osztás n*10 ciklusig is eltarthat. Fénysebesség: 30 cm/ns; az elektronok a szilíciumlapkán: 20 cm/ns! Amíg a fény 6cm-t halad a gép összead két 64 bites számot. 1 GHz 1 ns óraciklus. Alapvető, hogy mennyi a csíkszélesség! A kisebb méretek (csíkszélesség) gyorsulást idéznek elő. Egy futószalag fokozata: puffer -> logika -> puffer. Logikai hossz: hány NAND kapun kell keresztülmenni. FO4: Fan-out: egy NAND kapu késleltetési ideje Növelték a fokozatok számát -> csökken a logikai hossza az egyes fokozatoknak. Korábban volt 100 FO4is, ma ~10-15 FO4. Prescottmag: 30 fokozatot is elérték. A spekulatív elágazásbecslés miatt a rossz irányba lehívott utasítások száma ilyen mértékben túlságosan nagy veszteséget okoz (túl nagy a buborék). Eredmény: napjainkban ~15 fokozat jellemző. Mikroarchitektúra: manapság ez a döntő, ettől függ az órafrekvencia sebessége. Napjainkban a hatékonyság növelése csak pár százalék különbséget okozhat
 => a feldolgozási szélesség növekedése - Teljesítmény = órafrekvencia * ciklusonkénti eredményesen végrehajtott utasítások száma Pai = Fc *")
13 Az utasítás-szintű párhuzamosság fejlődésének jellemzése: -100x növekedés 10 évenként (utóbbi időben stagnálás) - Oka: 3 különböző párhuzamosság megjelenés (időbeli, térbeli párhuzamos utasítás kibocsájtás, utasításon belüli - több művelet/utasítás) => a feldolgozási szélesség növekedése - Teljesítmény = órafrekvencia * ciklusonkénti eredményesen végrehajtott utasítások száma Pai = Fc * IPCeff Szuperskalár elvvel lezárult a fejlődés, ISA kiterjesztése SIMD fixpontos ábrázolás -> multimédia, 3 alapszín, 3x8 bit lebegőpontos ábrázolás -> grafika, ábrázolás alapja a háromszögek térbeli csúcspontok, 32 bites GPGPU Első időben szimpla pontos feldolgozás -> tudományos terület ILP processzorok teljesítménypotenciálja, soros futószalag, VLIW, SIMD, adatpárhuzamos utasítások. Az időben párhuzamos feldolgozás: 1. utasítás előrehívás 2. lebegőpontos műveletek 3. teljes utasítás párhuzamosítása
. Ilyen rövid időtartamnál erre nincs szükség.")
14 Pipelined EUs: A lebegőpontos utasítások végrehajtásánál az Execute fokozatok párhuzamosítása (a kitevők azonos alakra hozása, mantissza, ) Jellemzően tudományos célú gépeken alkalmazzák. 2 db bites fixpontos szám összeadása 0,5-1 óraciklust igényel. Ez ~ 0,3 ns idő (megj.: ez alatt a fény ~10 cm t halad). Ilyen rövid időtartamnál erre nincs szükség. Lebegőpontos osztás a legrosszabb műveletek egyike, ugyanis kivonásokra vezethető vissza. A lebegőpontos összeadás ~0.3 ns időt vesz igénybe. Pipelined processors: Futószalag. Minden óraciklusban be tud fogadni egy új utasítást. Az ábrán láthatóak a futószalag bevezetéseinek lépései, a futószalag tehát fokozatosan jelent meg 80-as évek közepétől a 80-as évek végéig minden gyártó áttért a futószalag technológiára (80386-tól). Intel/AMD: x86 (ez a domináns: az eladott processzorok 80-90%-a). Motorola: M68000 (CISC), MIPSR: RISC


15 Minden technológia magával hordozza a végzetét a szűk keresztmetszetet. Operatív tár sávszélessége: szekvenciális -> futószalagos feldolgozás. Szekvenciálisnál lehet közte 30 ciklus, míg újra kell, futószalagosnál minden órajelre új utasítás. Az operatív tár túlterhelődik, 100-szoros idő kell a válaszhoz, nagyobb sávszélesség igény -> cache bevezetését elősegítette motiválta. L1 szinten 32/64k a cache méret -> optimum az elérési idő és a cache hiány közt
 Volt olyan gyártó, amelyik előbb vezette be a cachet, mint a futószalagot (pl.")
16 Futószalag cache nélkül: (I. generációs futószalag processzor) Futószalag cache használatával: (II. generációs futószalag processzor) Volt olyan gyártó, amelyik előbb vezette be a cachet, mint a futószalagot (pl. Motorola, MIPS R) A zárójelek értelmezése: Ha egy változó van, akkor univerzális cache, ha kettő, akkor Instruction/Data cache (kilobyte). A cache a szekvenciális feldolgozást kifejezetten hátráltatja! Csak a ciklusokat támogatja, azokat is csak akkor, ha azok beleférnek a cache-be. Ebből következik, hogy minél nagyobb a cache, annál jobb, DE: ekkor az elérési idő is megnő - > optimumra van szükség. Ez kb.: 64K, 3 óraciklus. L1: jellemzően 64 Kb (3 óraciklus) megj.: AMD-nél 32 Kb is. L2: fél-2 Mb (10-15 ciklus) L3: 6-12 Mb (30 ciklus is akár)

17 Ha ugrani kell, akkor bázisregiszter címet kell számolni, 3 utasítás elvész -> ennyi buborék keletkezik a 4 fokozatú futószalagon (n fokozatú futószalagnál n-1 vész el). Ezért nagyon fontos az előrejelzés becslés. FDEW -> feltételezett futószalag működés, feltétlen elágazással is probléma van.. Az ugrás folyamata a következő: 1. Az ugrási irány becslése 2. Az utasításlehívást folytatjuk a becslés alapján ( ábrán piros nyíl irány, piros pontból) 3. Ellenőrizzük a becslés helyességét 4. A valós irányban folytatjuk (jóváhagyjuk vagy eldobjuk) a végrehajtást Feltétlen elágazásnál is fellép, de nem olyan jelentős. Execute fokozatnál vizsgálja a Flaget. Ciklusoknál nagyon jó a becslés (ha a ciklusváltozó n, a becslés n-1 szer jó lesz) Nem-szuperskalár processzoroknál a fix (rögzített, mindig ugrunk ) elágazásbecslés jellemző, az első generációs szuperskalároknál a statikus a jellemző. Statikus elágazásbecslés esetén a feltétel kiértékelésekor Displacement vizsgálat történik: Ha D<0, ugrik, ha nagyobb, akkor soros folytatás. Kód alapján történik a becslés, ezért primitív elágazásbecslési technika, a jobb rendszerek a múlt alapján becsültek. Dinamikus esetén elágazástörténetre alapoz, előzőekben ugrott, vagy nem

 Minden gyártó bevezette.")
18 Ismétlés: Az elágazási utasítások alapblokkokra osztják fel a kódot. Az alapblokkok általában 3-4 adatmanipuláló utasítást tartalmaznak tól jelenik meg az elágazásbecslés. (II. generációs futószalag processzor) Minden gyártó bevezette. 1989: futószalag technika kimerülése
.")

19 Cache megjelenése azért előzte meg az elágazásbecslést, mert azt egyszerűbb volt megvalósítani (komplexitás ~ tranzisztorok száma). A másfeledik generáció azokra a processzorokra vonatkozik, amelyeknek már volt cache-e, de még nem volt bennük elágazásbecslés
 regiszterből -> regiszterbe -> regiszterbe 32 bites számítást tesz lehetővé EPIC: a VLIW mai neve (Explicitly")
20 Független utasításoknak kell lennie egymástól valamint a félkész utasítástól, amit a rendszer épp feldolgoz. VLIW elv -> Ez a legegyszerűbb megoldása tárból -> regiszterbe -> tárba (LOAD/STORE elv) regiszterből -> regiszterbe -> regiszterbe 32 bites számítást tesz lehetővé EPIC: a VLIW mai neve (Explicitly Parallel Instruction Computer). Az ábrán például 6 utasítás található egy VLIW -ben. Gyakorlatilag: az utasítások továbbra is 32 bitesek, de maga a hosszú utasításszó (VLIW) akár 10-20x 32 bit hosszú is lehet


21 A compiler ma is kezel függőségeket, pl. az összes LOAD utasítást előrébb hozza, hogy a lassú, RAM-ból való betöltés eredménye már kéznél legyen, ha szükség van rá -> dinamikus függőségkezelésnél is van szerepe. Szuperskalárok esetén a szekvenciális konzisztenciát meg kell őrizni! ROB segítségével
, Multiflow (Trace - 1987), Commerse")
22 VLIW processzorok: Sok feldolgozó egység van a processzorban, ezek dedikáltak. Statikus függőségkezelés / párhuzamos optimalizálás -> komplex fordítót igényel. Nagyon compilerfüggő, technikafüggő, előkészítés fázis, szimulációs kísérletek, prototípusok, commerse rendszer -> kibocsájtható Cydrome (Cydra ), Multiflow (Trace ), Commerse implementációk Várt előnyök: - kevésbe komplex processzor - korábbi megjelenés - nagyobb pörgési sebesség, vagy LP Hátrányok: - gyökeresen új ISA, új fordítók - op. rendszerek, alkalmazások újraírása - kritikus tömeg elérése - VLIW utasítások részlegesen kitöltöttek (Például nincs mindig 30 utasítás, amivel ki lehetne tölteni => részlegesen lesz kitöltve, hézagos lesz. Ez vezet a rossz sávszél kihasználáshoz) - kevés a pénz - rossz tárhely és sávszélesség kihasználás - rendszer nem tudja fenntartani önmagát Mindkét cég csődöt jelentett, a fejlesztők két céghez mentek át -> HP, IBM (amik akkor gyengébbek voltak még) és az EPIC processzorok kezdeményezői lettek. HP nál kezdeményezték az VLIW processzorok továbbfejlesztését, mert ez a jövő. A partner az Intel lett

.")
23 HP lett a fősodrásban, az IBM mellékvágányra futott. Fontos: TRACE, CYDRA, és azok elődei (prototípusok). ELI-512: a szám a VLIW hosszát jelöli. 16*32 bit

. IBM Power maradt még egy ideig ami RISC-es.")
24 EPIC processzorok: Ma 80%-át uralják a piacnak! Intel nélkül esélytelenek -> együttműködési szerződést kötöttek 1994-ben, Explicity Paralell Instruction Computer 1997-ben egy konferencián már EPIC néven szerepel, a VLIW már el volt használva. X86-osok 32 bitesek voltak, meg fog halni a 32 bit, jövő a 64 biteseké, IA -> Intel Architecture között RISC-et felülmúlják a CISC-ek, ezek lettek a leggyorsabb processzorok. A RISC vállalatok sorra mentek tönkre ebben az időszakban, kiszorultak a piacról (Cisc vonalból is kettő maradt csak meg (Intel + AMD). IBM Power maradt még egy ideig ami RISC-es re ígérték az elsőt Merced néven (Mercedes). 2 évet késett. Átkeresztelték Itanium-ra. A Merced (2001) 600 MHz en működött, miközben a 2000-ben kijött Pentium 4 már 1.5 GHz-en, 400 (FSB: 100 Mhz, 4 transzfer/órajel) megatranszferrel, az Intel a saját konkurense lett. A Merced nagy csalódás volt, botrányos helyzet, ez volt az Intel fekete korszaka AMD más úton indult el -> RISC 86 architektúrát kiegészítették x86-64-el (kompatibilis volt a korábbi változattal) Direct Connection, RAM vezérlő a lapkán, soros buszok. -Opteron: Szerverre -Athlon64: DesktopraMicrosoft megtámogatta, az Intelnek muszáj volt utánoznia bites szerverek jöttek ki, memóriavezérlés került a chipre, FSB-t kidobták, É-híd, memória, VLIW csatlakozott. Tipikus processzor: 2001 Intel-64 Itanium Itanium 4c ennél tovább nem támogatja az Intel, ezzel vége lett Szuperskalár feldolgozás: újítás, dinamikus függőség, nem jelent változást az ISA-ban
 Utasítás cache-ből pufferbe tölti az utasításokat, 2-3 utasítást egyszerre lehív, paralel dekódolja, függőséget vizsgál,")


25 Kompatibilis ISA: A korábbi fejlesztésekkel kompatibilis! Nem igényel változtatást a korábban megírt programokban. A függőségeket a processzor kezeli. Működés: Sok EU (Executing Unit) Utasítás cache-ből pufferbe tölti az utasításokat, 2-3 utasítást egyszerre lehív, paralel dekódolja, függőséget vizsgál, direkt kibocsátás (soros az első függőig, az ablakot kiüríti, újratölti): a függetleneket bocsátja ki (nem pufferelt). Probléma: A függőségek -> átlagos kibocsátás utasítás alig haladja meg a 2db-ot, max ennyi az elvárható párhuzamosság, direkt kibocsátási korlátja, kibocsátási szűk keresztmetszet, szélesség = 2, általános célú programoknál. Processzor mag: Statikus elágazásbecslés, utasításkódot tekintjük gyorsítótár: Egyportos blokkolható L1, adat gyorsítótár, processzor buszon keresztül csatolt off chip L2 gyorsítótár (korábbi rendszerekben FSB-n keresztül). <- első generációsig második generációsig ->

26 Harmadik generációs szuperskalár: L2 a CPU-ban. Példák: Két nagy cég: IBM és DEC, az előbbi a piacvezető. Az IBM nyeresége megegyezett a DEC forgalmával!

27 RISC: A legelső szuperskalár processzor egy beágyazott rendszerben volt található az Intel által gyártva, nincs nagy jelentősége. M, HP, SPARC, MIPS, AM: meglévő rendszereket szuperskalárosítottak, fejlesztették tovább. IBM, DEC, PowerPC: új rendszerek, erre a célra készítve. IBM Power: az igazi kommersz, első szuperskalár Mindegyik kimúlt, kivéve: Power CISC: Eltolódás tapasztalható megjelenések tekintetében (~3 év). Intel a vezető gyártó, Motorola egy ideig vetélytárs, AMD kezd megjelenni a piacon. Cyrix-ből lett később a VIA. Az Intel és az AMD maradt meg a piacon. A családokat nem kell tudni, de kommentálni kell, ha a képet mutatják. CISC: a memóriában bitfolyamként látszódnak az utasítások, nincs eleje, sem vége. Ezek az utasítások komplexebbek is (megjelenik a memória, mint operandus). Az összes rendszer néhány év alatt ( 90-95) szuperskalárrá változott

28 Kibocsájtási szűk keresztmetszet: a kibocsájtás (Issue) az első függő utasításig történik. A függőségek miatt nem tudunk annyit kibocsátani, amekkora az utasítás-ablak mérete. Megoldás: pufferekbe tesszük a kibocsátott utasításokat, és ott vizsgáljuk meg a függőségeket


29 Alpha 21064: a legtisztább RISC, a Pentium mintapéldánya, 1. generáció Statikus utasításelosztás -> programban lévő utasítások előfordulási száma. Pentium: a legtisztább CISC Dinamikus utasításelosztás -> végrehajtott utasítások gyakorisága. Compilerek, általános alkalmazások: minden 5. utasítás jellemzően elágazás! FX utasítások a dominánsak! Memóriaműveletek: Load + Store = 30%+10% = 0,4. Direkt (nem pufferelt) kibocsájtás esetén kb. 2 utasítás / óraciklus => általános célú alkalmazásoknál 2-3-nál nagyobb szélességben nincs értelme gondolkodni
30 Adat-cache portok számolásához az előző dián található memóriaműveletekből vettük a 0.4 értéket (FX műveletek), ez tehát a memóriához nyúlást jelképezi. FX itt azért van duplázva, mert ezeket a végrehajtó egységeket terhelik a Load/Store címszámítások is. A címszámítást tehát rejtett, fixpontos regiszterek segítségével végezzük el. EU: Execution Unit (végrehajtó egység, VE). Összesen tehát 5-6 VE szükséges! Csak a függetleneket bocsátja ki a rendszer -> megoldás : pufferelés Pufferelés: Többféle puffer létezik: 1. végrehajtó egység elé helyezzük, egységenkénti puffer 2. Típusonkénti lebegő vagy fixpontos 3. köztes megoldás A kiküldés véges, a puffer nem végtelen méretű! Az adatok nem maximum szélességűek, vizsgálni kell, hogy ráér e az utasítás. Scoreboard -> regiszter 1-et flag tiltja, amíg számolnak vele, operandusok mellett elérhetőségi bitek jelennek meg kibocsátott utasításokban a célregiszterben. Egy bit jelzi, hogy számítás van

31 Shelvingbuffer: várakoztató állomás. A kibocsátási szűk keresztmetszet megszűnt. Ezzel nem biztos, hogy gyorsul a rendszer; amennyiben volt szűkebb keresztmetszet is, maradhat ugyanolyan sebességű, mint korábban. A kibocsátás 2 fázisú: 1.Pufferbe kerül - dispatch, kiküldés. 2.Pufferből VE-be kerül - Issue, kibocsátás. Komplikációk: ha a puffer megtelik, vagy az adatút szélessége kicsi (ha egy típusúak az utasítások), akkor nem lehet 4 utasítást egyszerre kibocsátani. Megoldási módok az adatutak szélességére: 1.Minden adatút worst case: legjobb teljesítmény (mert a legrosszabbra készülnek, 4 széles legyen minden) 2.Fixpontosnak pl. 2-szeres szélességű, lebegőpontok egyszeres (statisztikai közép: 2 vagy 3 (nem nagy a veszteség, és olcsó)) Második generációs (széles) szuperskalárok: Kibocsátási szűk keresztmetszet feloldása és egyes alrendszerek szélességének adekvát növelése. Átbocsátási képességet a legszűkebb keresztmetszet határozza meg. Azt a sínt, amely a processzort köti össze az északi híddal, Front Side Bus (FSB)-nek nevezzük (régebben: rendszerbusz)

32 Nagyobb felelősség hárul az elágazásbecslésre, 60% pontosság volt, váltottak dinamikus becslésre (történtektől függ a becslés). Sok utasítást kell kiküldeni egyszerre -> lassú -> elődekódolás! (pl. megállapítja az utasításcsoportot, kiszűri az elágazásokat, akár a címet is kiszámítja. L2 -> elődekódolás -> L1) 2-es kibocsátás függőségek miatt, ennek az arányát csökkenteni kell Regiszter átnevezés!!! - RAW: utasítás másik eredményére vár (Read After Write) - WAR: ne írja át csak olvasás után (Write After Read) - WAW: csak megfelelő sorrendben írja át (Write After Write) A WAR és a WAW függőségek oka regiszter átnevezéssel megszűntethető, átnevező bufferrel (archi II). ROB (ReOrder Buffer) szekvenciális konzisztencia Konzisztens a szekvenciális rendszerekkel. Működési elve: Utasításokat hajt végre és részben az operatív tárba részben a regiszterekbe ment. A beírásokat nem szabad a beírás sorrendjében tárolni (Neumann elvű rendszer szekvenciális feldolgozás), kell egy rendteremtő: ROB

33 ROB (ismétlés): Körpuffer, melynek van: - Kezdeti mutató: az első üres helyre mutat - Végmutató: a kiírandó bejegyzésre mutat Működése: - A kibocsátás sorrendben történik, így a kibocsátás sorrendjében folyamatosan töltjük fel a körpuffert, a kezdeti mutatónak megfelelően - A processzor követi a kiküldést - Végrehajtás alatt van-e - Befejeződött-e a végrehajtása - A kiírási feltétel - (Kiírás: az adott architekturális regiszterbe vagy a memóriába írjuk ki az eredményt) - Az adott utasítás végrehajtása befejeződött - Minden, ezt megelőző utasítás kiírásra került Megjegyzés: a RISC szerű utasítások eredményét nem lehet kiírni, csak az eredeti CISC utasítás eredményét A kiírt bejegyzés helyét a CPU felszabadítja Elérhető párhuzam: 4-6 utasítás / ciklus - Fixpontos: bármilyen széles a processzor 4-6 utasítás - lebegőpontos: több párhuzamosság van bennük, 10 vagy 20x-os is lehet, kibocsátási párhuzamosság kimerült
.")
34 Kétműveletes utasítások: 90-es években. Jellemzően lebegőpontos műveletek. Kicsi a hatékonysága. 3 operandus, két művelet. Ismétlés: SIMD: Single Instruction Multiple Data. Egy utasításban több művelet => vektorutasítások. MM: Multimédia, képfeldolgozás, jellemzően FX feldolgozás (2D, pixelek tárolási módja, stb.). FP: lebegőpontos (3Dgrafika: térpontok miatt) Első rendszerek: 64 bit, napjainkban: 128 bit hosszú lehet egy vektorutasítás. Nemsokára 256 bit hosszú lesz. 64 biten 2/4/8/16/32 db utasítás eltárolása lehetséges. LP: szimplapontos: 32, duplapontos: 64 bit. Pentium II: A lebegőpontos regisztertárba rakták be a multimédiát, MMX (Multi Media extension). Adatpárhuzamosság: Egy utasításban több művelet pl.: 2 operandusú művelet. FMA (Fused Multiple Add) SIMD utasításoknál 20-30% sebességnövekedés SIMT Thread, Többszálúság, mátrixutasítások (8x8 jellemzően), GPGPU, több dimenziós tömbök feldolgozása

35 A kiterjesztés fejlődése: I.Intel: MMX (FXSIMD) ben, PII II.AMD: 3DNow! (FX, FPis + extra SIMD regiszterblokk), 1999-ben, K6-2+ III.Intel: SSE(FX, FP, SIMD regiszter), 2000-ben, P4 IV.AMD: 3DNow! Professional (innentől rákényszerültek, hogy lemásolják az Intelt) Egy ritka alkalom, hogy az Intel az AMD t másolja: (Ismétlés) Előzmények: - RISC processzorok egyszerűek, de gyorsak, a CISC-ek pedig lassabbak, de hatékonyabbak (pl. Alpha: 300 MHz, Pentium: 166 MHz) - CISC elhúzott teljesítményben (a magas órajelen járó RISC et nehéz továbbgyorsítani észlelhető mértékben). 5 év alatt a RISC kiszorult ( ) - Intel és HP 1997ben bejelentik a Merced-et. Azt jósolták, az IA-32(CISC) t felváltja az IA- 64(EPIC) ben bemutatták, bukás. - AMD: bevezette a korábbi fejlesztésekkel kompatibilis, x86-64 et:2000: 64 bites ISAbejelentés2003: Opteron - Athlon 64 megjelenése. Direkt csatolt: a CPU tartalmazza a memóriavezérlőt, és vannak soros linkjei: hypertransport bus, 3 db van belőle, és I/O vagy CPU köthető mindegyikre => akár 4 CPU is összeköthető, MP rendszer kialakítható belőle. Az AMD elnyerte a Microsoft együttműködését (x86-64támogatású OS). Az Intel az IA-64 el szintén ezt akarta elérni, de a Microsoft nem tett eleget ennek, így rákényszerültek az AMD ISAjára

 Northwood (2002): HyperThreading, 55 millió tranzisztor Prescott (2004): már benne volt a 64 bit, de még nem")
36 Szaggatott vonal választja el a generációkat. Intel vonalat célszerű megtanulni! (melyik hányadik generáció). DEC Alpha 1. generáció és a DEC Alpha volt a leggyorsabb vonal. 1997: FX-SIMD megjelenése, az átállás éve. AGP busz megjelenése. Előtte: 2,5. generáció Utána: 3. generáció Amelyek nincsenek színezve, azok nem támogatják a SIMD et. Órán nem beszéltünk az SSE3-ról. Intel P4magok: Willamette (2000) Northwood (2002): HyperThreading, 55 millió tranzisztor Prescott (2004): már benne volt a 64 bit, de még nem publikálták. 110 millió tranzisztor (a 64 bit re való áttérés növelte meg ennyire)


37 Kiváltott szűk keresztmetszet: Rendszerarchitektúra On - chip L2: Lehet káros a cache, ha egy adatra egyszer van szükség, pl.: videó lejátszás, streaming adatfeldolgozás. Ilyenkor ki-be kell mozgatni az adatokat. Viszont ez sokszor kikapcsolható. AGP busz Futószalag hossz növekedése -> Igény jobb becslésre, egyre több hardver lesz, de a kihasználtság csökken. Branch prediction accuracy: Elágazásbecslés pontosságának javítása. ILP processzorok fejlődésének korszaka lezárult!
.")
38 Természetes fejlődési vonal: Bonyolultság lépésről lépésre növekszik, szuperskalár az több futószalag lényegében. Radikális fejlődési vonal: Új utasításszintű architektúra, gyökeresen új (eddigit el kell felejteni). Ez általában nem lesz sikeres, most se lett az


39 Az, hogy melyik újítás mikor lépett be, az a rendelkezésre álló hardver komplexitásától függött!

40 Nem blokkoló cache: olyan cache, amely cache miss esetén, az adat memóriából történő betöltése közben is ki tud elégíteni igényeket. FONTOS ábra!! Teljesítmény mit igényel? - lineárisan memória sávszélesség növekedése - hardver komplexitás
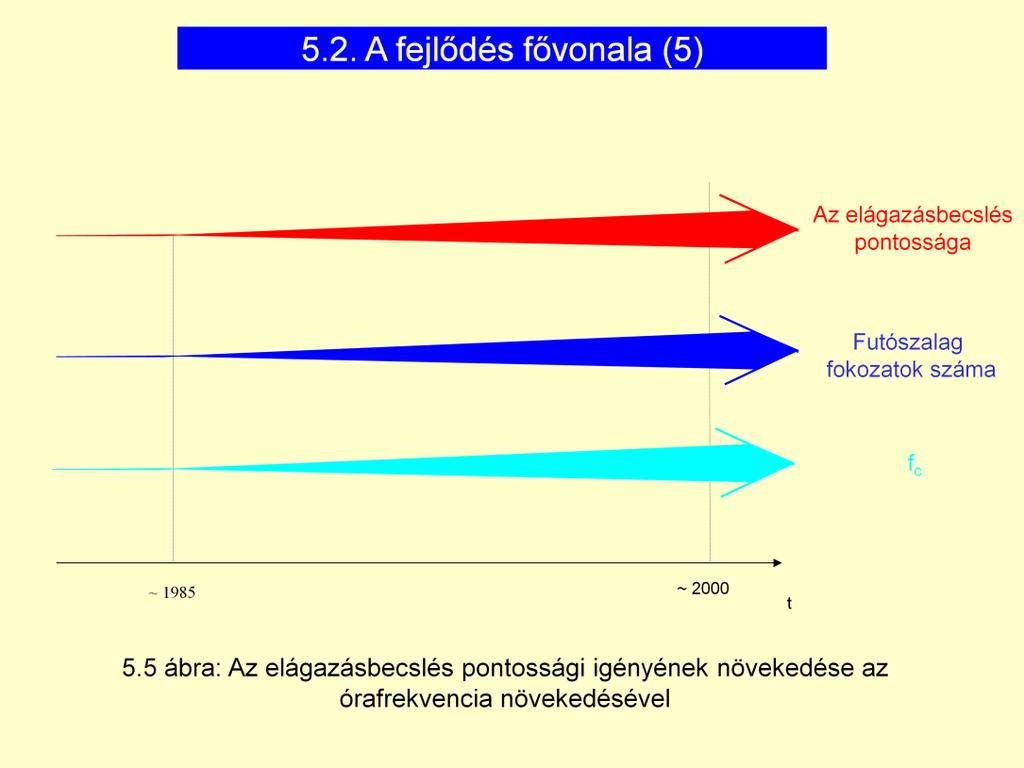
41 - 41 -


42 Egy szálban nincs párhuzamosság -> vegyünk többet. Ez egy magasabb párhuzamossági szint (szemcse)
 van.")
43 Többmagos processzor: BruteForce, nyers erő. Továbblépés. Szélesség növelése: 4 helyett 8- as kibocsátás. Többszálas processzor-mag: Ügyességen alapuló megoldás. Meg tudja különböztetni a szálakat. Több bemeneti tölcsér. Minden fájlnak külön adattere (regisztertere) van. Durván szemcsézett rendszer: Egy szál fut, amíg nem akad el Közepesen szemcsézett rendszer: Minden ciklusban egy szálat választ és azt futtatja Szimultán többszálú: Ciklusonként több szálból
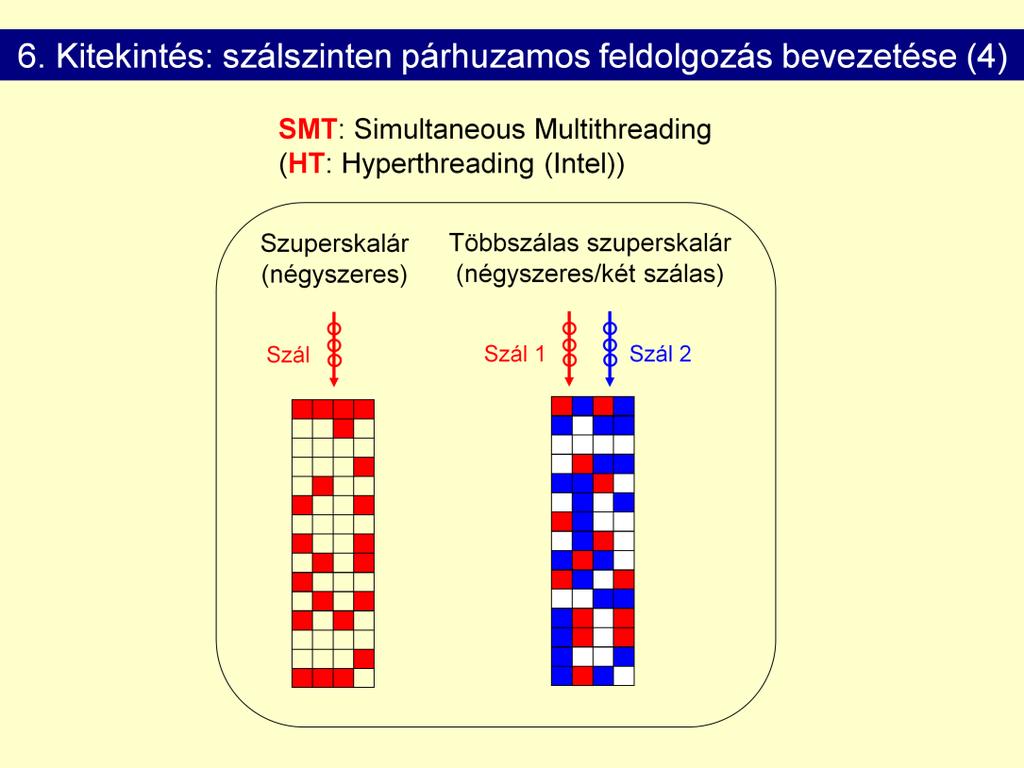
44 - 44 -


45 Korszakváltás a processzorok fejlődésében 2010 őszi félév Felépítés:

46 Korszakváltás: Egy év alatt lezárult, Intel átvált többmagosra. IBM-nél jelent meg először. Alapvető indíték: Teljesítmény növelés Több mint két évtizede - közel napjainkig - a processzorok teljesítménye megdöbbentően gyors ütemben folyamatosan emelkedett, amint ezt a világpiacon vezető piaci részesedésű Intel x86 család fixpontos teljesítményének változását bemutató 1. ábra illusztrálja. E szerint több mint két évtizeden át az Intel x86 processzorok fixpontos teljesítménye 10 évente mintegy megszázszorozódott. Ugyanakkor az elmúlt néhány évben jól kivehetővé vált egy új fejlődési szakasz, melyben a processzor teljesítmények növekedési üteme lényegesen lelassult és a növekedési görbe mindinkább egy telítődési görbéhez kezdett hasonlítani. De mi is játszódott le az elmúlt években, milyen okok idézték elő ezt a gyökeres változást? Az okok meghatározásához jó kiindulásul szolgál a processzorok abszolút műveleti teljesítményének vizsgálata. Általános célú alkalmazások esetében az OPI ~ 1! Nem beszélünk itt a SIMD-ről. A végrehajtott utasításokat külön kell nézni, mert a kibocsátott utasítások közül van, ami becsült; ha rossz a becslés, rollback kell (eldobás, visszavonás)

47 62000 es évek környékén az Intel processzorok teljesítménynövekedése megállt. Egészen addig kb. 100 szoros növekedés /10 év, ezt a meredekséget kell tudni!


48 Általános célú alkalmazás esetén: P a = f c * IPC eff -> hatékonyság: IPC eff = P a / f c (Adott frekvencián való teljesítmény) Kibocsátott utasításszám nagyobb lehet, mint a végrehajtott: pl. spekulatívan lehívott utasítások miatt
 elérték a technológia korlátait, az általános célú")
49 Intel 2. Generációs szuperskalároknál (-1995, Pentium Pro) elérték a technológia korlátait, az általános célú programoknál nem maradt több kimeríthető párhuzamosság. Y tengely: hatékonyság (teljesítmény / frekvencia)

")
50 Y tengely: teljesítmény A teljesítménynöveléshez az óra jel és a hatékonyság növelése milyen arányban fogja előidézni ig kb. ugyanakkora mértékben nő mindkettő, utána az órajel jobban, az IPC kevésbé. Pentium megjelenése. 1997:2 utasítás kibocsájtás / óraciklus hatékonyság. (A diát 97-ben vetítették, érdekes időpontban: ezen a napon volt az Intel és HP bejelentése: az IA- 64(x64) lesz az Új világ (Itanium, Merced))



51 1. Elsőgenerációs futószalag processzor: 386 Második generációs futószalag processzor: Elsőgenerációs szuperskalár processzor: Pentium Második generációs szuperskalár processzor: Pentium Pro Két-és feledik generációs szuperskalár processzor: Pentium II Harmadik generációs szuperskalár processzor: Pentium III A szélesség növekedés csak egy pontig volt kihasználható. Általános célú programoknál ~4-5xgyorsítás érhető el. DEC laborjában készült a mérés, 1990-ben
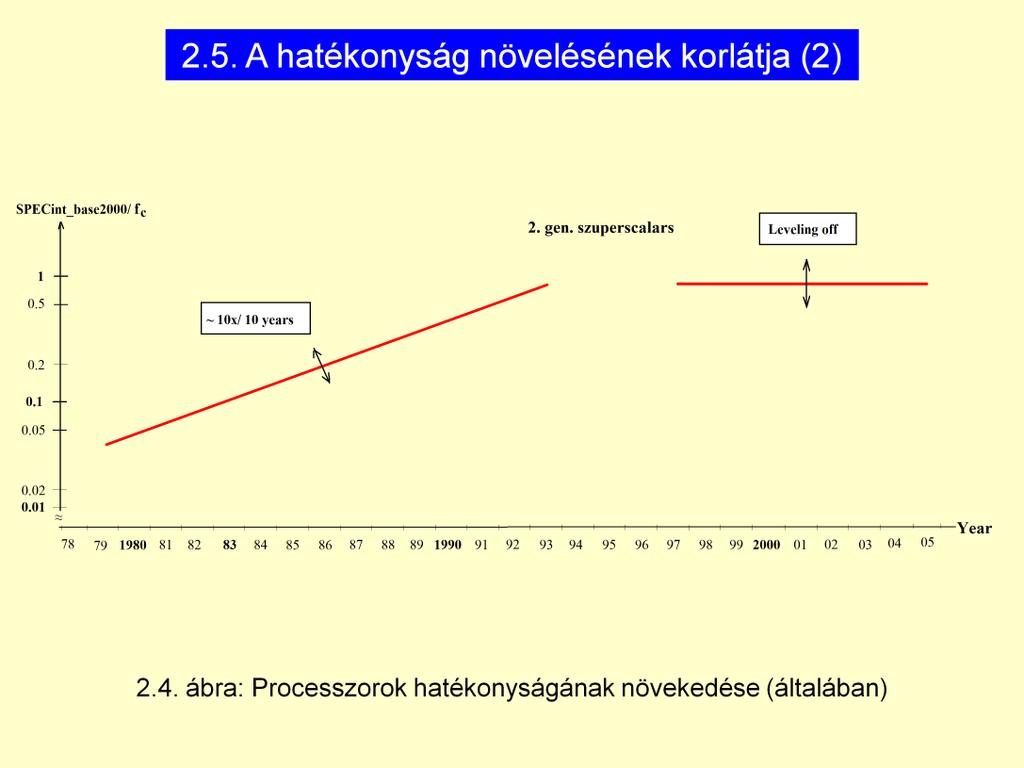


52 - 52 -
 Egy chip mérete kb.")

53 A teljesítménynövelést igényli a piac. Az órafrekvenciát kéne növelni ~100x-ra! 1.Csíkszélesség csökkentése (a jelnek kevesebb utat kell megtennie, kevesebb idő, nagyobb órajel, a jelek a lapkán 2/3ad fénysebességgel haladnak) Egy chip mérete kb. 1x1 cm, de felmegy 2x3-ig is akár ezért jelentős a vonalvastagság. 2.A leghosszabb futószalag logikai hosszának (egymás után lévő NAND kapuk száma) csökkentése. Ezt úgy tudjuk elérni, ha a fokozatokat kisebb egységekre. A futószalag fokozatainak logikai hosszát kell csökkenteni (F D E Wb -> F1 F2 F2D1 D2 E1 E2 ), nem pedig a futószalag hosszát! Így érhető el például a Northwood mag 20, és a Prescott mag 31 fokozata
 F04: Fen out of 4 Moore törvények a gyakorlatban.")

54 Futószalag rendszer felépítési elve: (FONTOS!!) F04: Fen out of 4 Moore törvények a gyakorlatban. váltószám: Egymás utáni technológia hányszoros váltószámú Hány évre van szükség, hogy ezt a technológiát produkálja? kb. 2 évente Két egymást követő technológia esetén a vonalvastagság ~0.7x re módosul. Ha egy négyzet oldalhossza 0.7, a négyzet területe 0.49~
55 Ebből következik, hogy a technológiaváltás esetén a tranzisztorok száma egységnyi területen megduplázódhat. A technológiák körülbelül kétévente váltják egymást (a rajz ~10 évet ölel fel, ebben 5 technológia van feltüntetve, így jön ki az érték). Intelnek hatalmas gyártási kapacitása és piaci volt, ezért is járhatott nagyon elől a fejlesztésekben is. Egy kézen meg lehetett számolni hány cégnek vannak gyártósorai. Zárójelben: a fokozatok száma. Emlékeztetőül: a fokozatok számának növelése a fokozatok logikai hosszának csökkentése. Intel célja a fokozatnöveléssel? Vásárlásnál alapvető szempont a sebesség volt és ennek akkor ez volt az alapja. Hátrány, hogy a disszipáció nőtt -> Korea -> lassabb tempó, de két mag. Összegzés: Hatékonyság 1-ben maradt, órafrekvenciát kellett növelni a sebesség növekedéséhez!


56 Y tengely: logikai hossz egy fokozaton belül. F1F2F3D1D2E1E2E3 15-nél stabilizálódott
 az fc növekedése 100x-ra nőtt / 10év (a csíkszélesség és a fokozatok logikai")


57 Fc korábban 10x-renőtt/ év (mert IPC is ugyanígy gyorsult). PII környékén (1997) az fc növekedése 100x-ra nőtt / 10év (a csíkszélesség és a fokozatok logikai hosszának csökkentése által). 10 év alatt ez a fejlesztési irány is bedugult. 1.Nagy válság: amikor a hatékonyságot nem tudták tovább növelni 2.Nagy válság: amikor az órajel frekvenciáját nem tudták tovább növelni. FONTOS! Y tengely: fc (MHz) DEC Alpha és Intel Pentium viszonya. 90 es évek vége felé a DEC processzorai voltak a legjobbak teljesítményben. A gyors frekvencianövelésnek köszönhetően Intel az élre tört (1999) -> RISC processzorok kiszorultak
 közti teljesítmény százalékos különbsége szinte folyamatosan csökken, a végén az Intel processzorának teljesítménye felülmúlja a DEC ét. 2.")

58 Y tengely: teljesítmény és relatív teljesítmény. A két gyártó (kék: DEC, piros: Intel) közti teljesítmény százalékos különbsége szinte folyamatosan csökken, a végén az Intel processzorának teljesítménye felülmúlja a DEC ét. 2. generációs szuperskalárok megjelenítésétől számítva 5 éven belül a CISC-ek kerültek előtérbe. Akkortájt 32 bites processzorok voltak, EPIC architektúra típus fog megjelenni, ez volt a jövő IA64 előtt, a RISC piac tönkrement egyszerűen. HP megszűnt a saját konkurens csatornáját (PA), IBM és a Sun túlélte, váltottak teljesen más koncepcióra, más piacra, mint eddig. RISC: Load-Store architektúra, CISC: Operandusként megjelenhet a memória is, komplexebb utasítások. IBM növelte az órajel frekvenciáját 5 GHz-ig
 Párhuzamos buszok: lecserélni sorosakra (Intel Nehalem, AMD K8mag: Opteron és Athlon XP). A párhuzamos busz ilyen magas frekvenciát nem bír el.")
 megnyilvánulásai: - memória késleltetési ideje (elérési ideje) - memória átviteli rátája - L2 cache tárak elérési ideje - processzor busz átviteli rátája Nagyobb frekvencián")
59 Hatékonysági korlát ~ visszaesés! Ábrák felrajzolása (a következőoldalon lévő rajzok+magyarázatok) Disszipációs korlát: STOP tábla a frekvencia növelésének (P4Prescott: 103 W leadás 1 cm^2 en.. Ez a maximum léghűtéssel) Párhuzamos buszok: lecserélni sorosakra (Intel Nehalem, AMD K8mag: Opteron és Athlon XP). A párhuzamos busz ilyen magas frekvenciát nem bír el. Skew: különböző hosszúságú vezetékeken a jelterjedési idő eltér. Ma minden busz soros. Lemarad a memória sebessége a CPU-hoz képest! Sebességolló (különbség) megnyilvánulásai: - memória késleltetési ideje (elérési ideje) - memória átviteli rátája - L2 cache tárak elérési ideje - processzor busz átviteli rátája Nagyobb frekvencián a kapacitás bekorlátozódik. Több csatorna: több DIMM. Memória két fő jellemzője: késleltetés (elérési idő) és sávszélesség
.")
 A memóriavezérlő a CPU lapkán található. Az Intel ezt a Nehalemmel (2008, pl. Corei7) vezette be.")
60 Beillesztett dia! (by Felix) FSB sávszélessége korlátozhatja a memóriát. Először 4 processzornak kellett osztoznia egy FSB-n. Direct Connect: nincs FSB, közvetlen kapcsolat a memóriával (3 db). A csatornákra egy-egy újabb processzort is rá lehet kötni (összesen 4 CPU köthető össze, ahol mindegyik processzor minden másikkal tud kommunikálni) A memóriavezérlő a CPU lapkán található. Az Intel ezt a Nehalemmel (2008, pl. Corei7) vezette be. AMD K8 (2003): Opteron és Athlon-64 Egyre nagyobb erőfeszítések, egyre kevesebb teljesítmény növekedés -> megoldás több magos processzorok

61 aszinkron rendszer jellemzői: Rendszer egy feladatot kap, ha kész akkor visszajelez. 2 jel kell hozzá megbízó és visszaigazoló (acknowledgement) szinkron rendszer: Megbízom, megbízom.. nem várok visszajelzést, olyan időtávon bízom meg, amelyen feltételezem, hogy végre tudja hajtani, worst case szemlélet! A második generációs szuperskalárok mellett jelentek meg a szinkron RAM- ok, nagyjából 4 évente duplázódott a sebesség 3 korszak: -DRAM: 1970 körül jelentek kb. a mikroprocesszorokkal egyidőben. FP( 74) FPM( 83) EDO( 95): aszinkron (93: Pentium, 66 MHz. RAM sebesség: 66 MHz) -SDRAM ( 96, 200Mhz) DDR( 00, 400 MHz) DDR2( 04, 800 MHz) DDR3( 07, 1600 MHz): szinkron (ez a kettő párhuzamos. 4 évente duplázódott a sebessége a RAM-oknak) 2. generációs szuperskalároknál jelenik meg. Szinkron: nem vár visszajelzést, tudja, hogy megkapják az adatot. -DRDRAM ( 99) : dupla sávszél az SDRAM-hoz képest Merre menjünk tovább? Intel Pentium 4 fejlesztése: 2000 Arra tettek, hogy a DRDRAM-ok fognak bejönni, hibáztak. Ez volt a rossz irány hiába a nagy sávszél, nagy az elérési idő is, 2 éven belül váltania kellett Párh. DIMM lábainak száma: ~240, sorosé: ~harmada. Fizikai korlátokat jelent a lábszám, csatornák száma max2 párhuzamos esetén, soros esetén ~ 4-6 -> kapacitás, a sávszélesség meg tud nőni. A soros kapcsolat biztosabb. Nagyobb frekvencián a kapacitás korlátozódik (DIMM-ek száma (2-3)). FBDIMM esetén akár 256 Gbyte is lehet egy alaplapon. DDR: kb. 240 lábbal rendelkezik. Soros kapcsolatú RAM-ok nem elterjedtek, nem a PC-kben használják
.")
 Mhz-el ment -> 200 ms.")
62 2 fajta elérési idő: chip (memóriakártyán) szintű és memória (rendszer)szintű elérési idők. A rendszerszintű elérési idő jóval nagyobb (chipek a kártyán -> BUS -> Északi híd FSB-> CPU). Rendszerszintű elérési idő: a memóriaegység elérési ideje. Az ábra a chip szintű elérési időt mutatja. Első IBM PC ~5 (4,7) Mhz-el ment -> 200 ms. 26 év alatt csak 1/10-ére csökkent az elérési idő
: Dupla hosszú elérési idejű, de nagy sávszélességű rendszerről van szó (ezt mutatja a csúcs, 120 és 210). Intelnél több millió dolláros befektetés.")
63 Rendszerszintű elérési idő lassan csökkent, kb. harmadára 25év alatt 1000xórajel frekvencianövekedés mellett, nagy probléma. RDRAM (Rambu sdram, DirectRambus DRAM, DRDRAM): Dupla hosszú elérési idejű, de nagy sávszélességű rendszerről van szó (ezt mutatja a csúcs, 120 és 210). Intelnél több millió dolláros befektetés. 28RAM lemaradását mutatja az ábra. RDRAM: Rambus DRAM (DRDRAM).Egyre több ciklust kell várni, hogy az adatok megérkezzenek (akár 1000 t is). Vízszintes vonal: a CPU és a RAM azonos frekvencián működtek. Az Intel a P4 et először RDRAM-mal hozta be (2000). Ezt a világ nem fogadta jól, mert ezek hosszú elérési idejűek; 2002 környékén SDRAM-okra tértek át

64 Relatív sávszélesség: RAM Olvasási sebesség / frekvencia. Először 66/66=1. Utána: 0.5, PC-100esetén 100/500=0.2 stb. FPM: Fast Page Mode RAM PC-800D: RDRAM, Rambus A relatív sávszélesség nál beállt, jobbat nem tudtak elérni. Manapság feljebb lehetne húzni vonalakat, y=0.5 fölé és x=2.5 körül 3.0 GHz-nél óra frekvencia leállt, de a RAM fejlődése nem
 rendelkeznek. 0.2 környékén stabilizálódott ez is. Ma már nem korlát az FSB. 2003-ban AMD-nél eltűnt az FSB mert a RAM vezérlő bekerült a CPU-ba, 2008banaz Intel Nehalembe is bekerült.")
65 Pentium: 66 MHz (FSB) FSB növekedése körülbelül megfelelt a memória sebességnövekedésével, mert azonos fizikai korlátokkal (átviteli vezetékek fizikai jellemzői áthallások, zajok, lezárások..) rendelkeznek. 0.2 környékén stabilizálódott ez is. Ma már nem korlát az FSB ban AMD-nél eltűnt az FSB mert a RAM vezérlő bekerült a CPU-ba, 2008banaz Intel Nehalembe is bekerült
 Prescott: 125 millió tranzisztor 64 bit megjelenése (Eleinte titkos) A cache igényli a legtöbb tranzisztort. L1 cache jellemző mérete: 32-64 K,elérési idő: jellemzően 2-3 ciklus.")
66 Willamette: 42millió tranzisztor Northwood: 55 millió tranzisztor - Hyper Threading megjelenése (DEC Alphától vették át, a fejlesztőikkel együtt. Eleinte titkos) Prescott: 125 millió tranzisztor 64 bit megjelenése (Eleinte titkos) A cache igényli a legtöbb tranzisztort. L1 cache jellemző mérete: K,elérési idő: jellemzően 2-3 ciklus. Ha nagyobb lenne a cache, lassabban lehetne elérni. L2: 1 Mb környékén. Prescott: 64 bit. Ezt sem jelentették be, csak aktiválták a későbbiekben. Gyanús volt: 55 millió tranzisztor helyett 125 millió tranzisztor, ebből jöttek rá, hogy valamit eltitkolhatnak. Prescott esetén 7-ből 23 lett az L2 elérési ideje (kapacitás miatt), L3: az L2 két-háromszorosa (40-60 ciklus) => A memória lassúságának kompenzálására bevezetett cache sebességével is gondok vannak!

67 Hatékonyság mérése SPECint_base2000/f c. X tengely: frekvenciaskála! A hatékonyságot az L2 cache növeli, viszont a frekvencia miatt csökken. INTEL Dir: Directconnected, saját busz, nem FSB-rekötött L2. On-die: chipre integrált L2. PC-133 : RAM sebesség ATA-100, SCSI-U2W : háttértár típusa, sebessége Pentium II nagy újdonsága: fixpontos SIMD Pentium III nagy újdonsága: 1999-ben jött ki multimédia támogatással: lebegőpontos SIMD (3Dgrafika, 3. generációs szuperskalár) Coppermine ugrása az on-die miatt, de rögtön csökken, ha nő a frekvencia. Pentium 4: 1,4-1,5 GHz en jött ki, 400 Megatranszfer / s. FSB: 100, 4 egység / ciklus Northwood: ugrás a cache duplázódása (256 -> 512) miatt. Prescottmag: 1ML2. HT= HyperThreading. Northwood-ban jelent meg. Irwindale: L3cache megjelenése, ezzel 0.6 lett a hatékonyság. Összegzés: A hatékonyság meredeken zuhan, ha növeljük az órajel frekvenciáját. A Pentium 4 hatékonysága minden újdonság ellenére elmaradt a PIII tól, a HyperThreading általános célú alkalmazásokban alig hoz valamit
.")
68 AMD Athlon: ~ Pentium 3-nak felel meg Athlon XP: P4 környékén vezették be, az elnevezés megváltoztatása is itt jelenik meg: konkurenciához viszonyítva(pl. AMD Athlon XP1500+). Palomino mag, 2001-ben jelent meg. Athlon64: 2003-ban behozták a 64 bitet, az on-chip memória vezérlést és a CPU-k összekapcsolását lehetővé tevő buszokat (DirectConnection..). Athlon 64: desktop neve, Opteron: szerver változat. Korábban vezették be a DDR-t (200 MHz FSB).On-dieL2 esetén a hatékonyság drasztikusan esett. Oka: rossz tervezés: L2 sávszélessége túl kicsi volt (Itt nem a sávszélességet ölték meg (Rambus DRAM), hanem pont fordítva). Ezt helyre tették, ezután ugyanolyan vonalak az ábrán, mint az Intelnél. Hatékonyságban az Athlon 64 megkétszerezte az akkori Intel P4 ét.(teljesítmény megegyezett, de az AMD feleakkora órajelen tudta hozni ezt az eredményt.( IPCeff = Pa/fc ) Barton vitte fel 0.5 környékére 32 biten a hatékonyságot, 64 bites Opteronnal felvitték 0.6ra. ->2 világ: Intel: nagy frekvencián megy, de alacsony teljesítmény AMD: alacsony frekvencián megy, de nagy teljesítmény
 nő.")

69 Azonos rendszer esetén a hatékonyság a frekvencia emelésével leesik. Az architektúra fejlesztésével (L2 méret, FSB, sávszélesség növelés, ) nő. => A hatékonyság fűrészfogas mintázatot mutat Intel: Növeljük a frekvenciát, hatékonyság mindegy AMD: Hatékonyság is növekedett, de ekkor nem ez volt a vásárlási szempont Intelnek bejött, de Prescottal koppantak, mert nagy frekvencia magával hozta a disszipációt ( disszipációs fal). A2.2 GHz-es AMD teljesítménye körülbelül megegyezik az Intel 3.4 GHz-es modelljével

70 Intel Core2 (2006):Pentium M-re alapozott, amit a PIII-ból fejlesztettek ki (disszipáció csökkentési politika, mobil szegmens)
71 Ez a kedvenc témám Sima Szóval FONTOS!!! Chip - aktív tranzisztorok -> dinamikus disszipáció - passzív tranzisztorok -> statikus disszipáció Kapacitást fel kell tölteni, ezt órajelnél lehet, és ki is kell sütni (ellenálláson). Van egy tápfeszültség, U (órán: V ). Van egy szórt kapacitás, C. Q töltés jelenik meg a kapacitáson. Levezetés: Q= C*U = I*Δt. Δt =Δt/2 (1óraciklusalatt történik meg a feltöltés és a kisülés is -> fél-fél órajel). Δt = 1/fc Q = C*U = I* (deltat / 2)C*U = I/(fc*2)C*U*fc*2 = ID = P = U*I = C*U^2*fc*2 A feszültséget csökkenteni kell, hisz ettől négyzetesen függ! Pentiumban 5 V a feszültség, később 3.3V. Manapság 1V. A korlát az órafrekvencia, mert kisebb feszültség kisebbet pumpál, lassabban tölti fel a tranzisztort, a felfutó görbe túlságosan elnyúlna, ezért nem lehet a végtelenségig csökkenteni a feszültséget. Statikus disszipáció csak zárt kapuk esetén. Szivárgási áram * feszültség. Dinamikus: feltölt-kisüt. Csak a nyitott tranzisztoroknál jelenik meg. FONTOS: a kettő összege a disszipáció. Észre kell venni a terhelést, meghatározni mekkora frekvencia kell ehhez, kell egy hardver amit be lehet állítani teljesítményre, frekvenciára. Vizsgálják, hogy adott U feszültségen mennyit tud a chip, folyamatosan csökkentik, amíg az éppen elvárt f c -t tudja


72 Fajlagos disszipáció: négyzetcentiméterenként hány Wattot kell disszipálni. Intelnél ténylegesen kb. 1 cm^2 a terület, ezeket az adatokat így könnyebb értelmezni. 20Wfelett már kell hűtés. Prescott: 103 Wattot kell eldisszipálni 1 négyzetcentiméteren, a léghűtésnek ez a fizikai hatása. Y tengely logaritmus-skála! P5: Pentium, P6: Pentium Pro, Klamath: Pentium II, Katmai, Coppermine: Pentium III
 visszavonták, a disszipáció miatt.")

73 2004 májusában a P4család 2000-ben bejelentett 2 tagját (4 GHz) visszavonták, a disszipáció miatt. A P4 családot 2010-ig tervezték előre, 10 GHz es frekvenciát jósoltak akkoriban neki, de ezt is vissza kellett vonni
 logaritmikus skála (1:100) Vörös: dinamikus, 1-estől picit nő (Oka: tápfeszültség csökkent a háttérben) Zöld és narancs: szivárgási áram Kék: csíkszélesség,")
74 Statikus és dinamikus disszipáció aránya. Y tengely a disszipáció (din + statikus) logaritmikus skála (1:100) Vörös: dinamikus, 1-estől picit nő (Oka: tápfeszültség csökkent a háttérben) Zöld és narancs: szivárgási áram Kék: csíkszélesség, csökkent nagyban, ez az oka a szivárgási áram. Kb táján hőfal!! Arányok: 1995:2. generációs szuperskalároknál: 1:10000, elhanyagolható méretű volt a 90es évek végéig. DE! nagymértékben nőtt a statikus disszipáció, 2005 körül azonos értéket vett fel dinamikussal (Prescottnál). Dinamikus szinte ugyanakkora maradt, mert a tápfeszültséget folyamatosan csökkentették -> nem emelkedett meg drasztikusan.. Statikus: szigetelőréteg egyre vékonyabb -> I leak egyre nagyobb. Megoldás: jobb szigetelés kell, High-k dielektikum. Erről ad képet a következő dia. Órafrekvenciát lekorlátozza a disszipáció, más módot kell találni a teljesítménynövelésre



75 Fémkapu szerepe: növeli a térerőt, gyorsítja az elektronok áramlását. Fontos a két számadat! SiO2: szilícium-dioxid Jelenlegi technológia. Magas k alapú szigetelő alkalmazása csökkentette a disszipációt, szivárgási áram kezelése fémkapukkal kiegészítve gyorsította a tranzisztort
 Egyik ok: Késleltetési időkülönbség: skew. Fellép adott távolság megtétele után egy vezetéken.")

76 Két út van: 1.Aktív állapot teljesítmény kezelése 2.Passzív állapot elősegítése Ábrán a távolság ~10 cm. 8 bájtos átvitel (64 bites busz szélesség, 64 vezeték) Egyik ok: Késleltetési időkülönbség: skew. Fellép adott távolság megtétele után egy vezetéken. Mivel kapuzott szinkron áramkörök, ez problémát okozhat. Ha eléri az órafrekvencia ütemét, nem kezelhető. Ez okozza a frekvenciakorlátot. Másik ok: Buszok terhelése nem azonos, kapacitáskülönbség. Nagyobb kapacitású lassabban töltődik fel. Harmadik ok: zaj és áthallás jelenhet meg, ez feszültségként jelenik meg, félreérthetővé válik. A vezetékek hossza NEM azonos. Prescott alapú alaplap, ami érdekes: a vezetékek hosszainak mesterséges és szándékos meghosszabbítása (kompenzálás a tervezés során). Nem az igazi megoldás, ami az igazi: soros buszok

 Példa a párhuzamos-soros technológiabeli különbségre (pl.")
77 Jelek megvalósítása lehet: - Egyik módszer: 0 és +5 V például (szennyezés problémát okozhat) - Másik módszer: pl. 2.5 és 7.5 V (itt 5Va viszonyítási érték). Jobb megoldás, de lehetne még jobb is. - Harmadik módszer: Nem a földhöz mért feszültségről beszélünk.2 darab vezeték kell hozzá. Szimmetrikus jelátalakítás. Nagyon gyors (Néhányszáz ma amplítúdó miatt), zavarérzéketlen (mert mindkét vezetékre hat, és ez kiesik). Lassú busz pl: USB (sokkal kevesebb vezeték kell hozzá, mintha párhuzamos lenne => olcsó) Példa a párhuzamos-soros technológiabeli különbségre (pl. merevlemez csatlakozó): Párhuzamos: ATA nagyobb helyet foglal, lassabb Soros busz: SATA kisebb helyet igényel, gyorsabb. Növekvő frekvenciákon csökkenő teljesítménynövekedés

87-88: VLIW")

78 Első ágat lezártuk. Esetleges mellékút a második ág. (83-)87-88: VLIW processzorok. Bukás oka: gyökeresen új ISA kell(új alkalmazásokkal), nem volt támogatása

79 :Elbocsátott fejlesztők az IBM-hez és a HP-hoz vándoroltak.32 bites x86-> 64 bites IA- 64volt a terv. EPIC: ugyanaz, mint a VLIW + szuperskalárok előnyei (elágazásbecslés, cache kezelés, stb..). 99-re ígérték be Merced névvel. Két évet késett, csőd volt, rá egy évre föltupírozták, majd növelték a frekvenciát ban Monte Chito 2 magos 2010-ben Tuqvilla 4 magos Itanium Itanium: teljes bukás, megdöbbentően gyenge hatékonyságú, alacsony teljesítményű
, P4: 1.5 Ghz.")

80 Fajlagos teljesítmény. MT: megatranszfer. Itanium frekvenciája~800 Mhz (FSB: 133 MHz), P4: 1.5 Ghz. Fajlagos teljesítménye a P4-nek: 0,4. Itanium2 későn jött ki, keveset tudott -> csőd volt. Többprocesszoros rendszer, megbízhatóság. IA-64helyett az x8664 bites kiterjesztésére lett igaz a korábbi előrejelzés


81 Először azt hitték, 1 év alatt 10 milliárd dollár lesz a bevétel. Később két évet adtak a 10 milliárdnak, és ahogy telt az idő, egyre többet. Lila görbe: amikor behozták. 3 évet adtak. A valóság még rosszabb lett. 8 processzoros, speciális rendszerekbe szorult ki. Semmi esélye nem volt, mert az általános célú alkalmazásoknál az elérhető maximális párhuzamosság ~4-5. Nem bukott meg, csak a piacon feljebb szorult. Bezárult a fejlődés: 1 magos gépek vége




82 Eleinte nem így volt, 3 különböző piac: - futószalag szélesítése, többlet tranzisztorok - Core Enhancements, elágazásbecslés - cache, Lvl2, Lvl3 cache megjelenése Osztályai: - homogén rendszerek a, konvencionális homogének:felépítésben megfelelnek a korábbi rendszerekhez b, 8 mag felett a régi technikák nem használhatók. Chipen implementált kapcsolóhálónak másnak kell lennie, gyűrűs rendszer, sokmagos rendszereknek hívjuk (ez több mint a többmagos rendszer ) - heterogén rendszerek: master/slave: van mester processzor és szolga processzorok, a mester processzor vezényel, ő osztja ki a feladatokat, utasítás feldolgozás a feladata, ő ütemez, szinkronizálja a végrehajtást. Vannak gyorsítók, CPU-processzor, GPU-gyorsító (gyorsító lehet többféle a GPU az a grafikus). A CPU kapja meg az utasításfolyamot, ha oylan feladat van amit nála valamelyik gyorsitó gyorsabban old meg, akkor azt arra küldi
.")
83 Rendszerek státusza: szerverekben már elértük a 8 magot, váltás lesz, az ennél több magos rendszerek csak kísérleti rendszerek, még nem tudunk vele mit kezdeni, még kutatás folyik. Gyorsítóval csatolt rendszerek: 2-6 processzortól használatosak a GPU-k, elsőként nem csatolt processzorként, hanem kártyákon jelentek meg (NVIDIA, AMD-Ati). Összegezve: Általános célú alkalmazásokban az utasításszinten rendelkezésre álló párhuzamosság a második generációs szuperskalárok megjelenésével már a 90-es évek derekán kimerült. Az ezt követő közel egy évtizedben a processzor teljesítmények fokozásának színtere az órafrekvenciák intenzív növelése lett, de az elmúlt néhány évben bizonyossá vált hogy ez az út az órafrekvenciák növekedésével egyre világosabban kirajzolódó három korlát miatt tovább már nem járható. A hatékonyság növelését célzó hardver többletráfordítások egyre csökkenő mértékben térülnek meg, a fokozódó disszipáció mértéke túllépi a léghűtéssel kezelhető tartományt és a párhuzamos buszok egyes bitvezetékei között fellépő futási idő különbségek (skew) egyre inkább megközelítik a ciklusidőt és így bekorlátozzák a buszfrekvenciát. Más megfogalmazásban: a processzorteljesítményeknek az órafrekvenciák intenzív növelésére alapozott stratégiája az elmúlt években hatékonysági, disszipációs és buszfrekvencia növelési korlátokba ütközött. E változások hatására a fejlesztések színtere az utasítás szintről a szálszintre tevődött át, az órafrekvenciák növelése érdekében alkalmazott hosszú futószalagokra (20-30 fokozat) alapozó processzorokat szükségszerűen felváltják a közepes (10-15) fokozatszámú, alacsonyabb órafrekvenciájú, lassabb de hatékonyabb mikroarchitektúrájú többmagos processzorok, míg a párhuzamos processzorbuszokat a sebességkorlátok elérése miatt, ill. a párhuzamos periféria buszokat a ráfordítás csökkentése érdekében kiszorítják a gyors, egyszerűen skálázható soros buszok

84 Többmagos/sokmagos processzorok 2010 őszi félév Felépítés:


85 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd
86 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva a törvény (1975 Projection vs. Microprocessor)


87 Csak egyféle értelmes felhasználása van a többlet-tranzisztoroknak: több CPU mag! Három ok van, amiért nincs más megoldás: 1.Szélesség növelés: általános célú alkalmazásoknál max. 4-5x a kihasználható párhuzamosság 2.Magok okosítása: 1-2%-os gyorsítás elérhető csak el vele 3.Cache fejlesztés: csak ciklusoknál segít (ráadásul minél nagyobb a mérete, annál nagyobb az elérési idő is)
88 Kérdés: Kell-e ez a sok mag? Minek kell, melyik alkalmazásnak? 2 mag van most általába, minek stb.? Ha nem kéne több az Intel meghalna -> ki kell találniuk alkalmazásokat, amelyekhez szükség van sokmagos processzorra
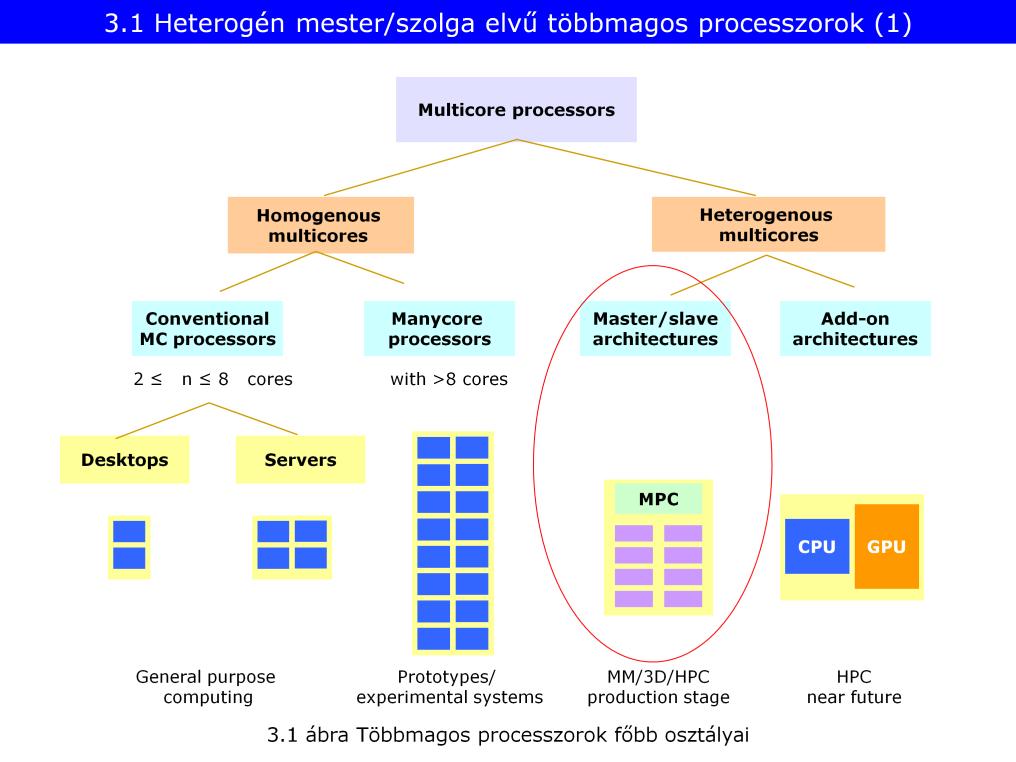
89 Homogén: általános célú magok többszörözése, heterogén: speciális, dedikált magok. A hagyományos többmagos és a sokmagos CPU k közti határvonal: ~8 mag. Ennek oka: a kapcsolódó hálózatok; az elvi működését 8 mag felett meg kell változtatni (mennyiségi változásból minőségi változásba vált át) - Conventional MC processors: korábban megismert egymagos világ továbbépítése - Manycore: Másik logika, itt lehet experimentálni, publikálni, egyetemeknek jó Heterogén: - Master/slave: 1 master, n slave. (végét járja) - Add-on(csatolt, más néven co-processor): általános célú CPU + speciális mag (pl: GPU, kriptográfia, lebegőpontos műveletvégző, stb). Régebben ilyen volt a 386, lebegőpontos co-processor ral. Van egy főfolyam (utasítás feldolgozó) és van egy sereg specialista, ha valaki gyorsabban meg tudja oldani a feladatot akkor oda megy a feladat. Nem kell teljesen szinkronizálni csak régiónként -> hatékonyabb Sokmagos CPU: kísérleti világban jellemző (később lesznek példák). HPC (High Performance Computing): számításigényes feladatok. Fontos rövidítés! Desktopok-szerverek: adatközpontokban Sokmagosak: kísérleti világban Master-Slave: működő rendszerek, speciális célokra Add-on: a jövő a csatolt processzoroké (speciális alkalmazásokra)
")

90 Ismétlés: Szerverek esetén beszélünk UP, DP, UP (Uni-, Dual-, Multiprocessor) típusokról. A hagyományos CPU k előfordulása: Mobil gépek (laptopok), desktopok, szerverek



: L2-t emelik 24 MB-ra")
91 Intel többmagos MP szerver processzorai: P4-től kezdődően 2 évente 2 családot publikálnak. P4 teljesen más fejlesztés, kitűnik a sorból. 3.oszlopban 1. rész: Hány magot tartalmaznak. p4: 2X1 magos: olcsóbb, de kevésbé hatékony. 3.oszlopban 2. rész: cache architektúra Penryn: 2 magonként közös L2 cache Nehalem (ejtsd: Nehálem): L2-t emelik 24 MB-ra Következő processzornak 7600-asnak kell lennie eszerint a logika szerint
92 Core2 szélessége: 4 (AMD: 3 => 1/3 al több). További előnye: behoztak több feldolgozó egységet (főleg MM) -> P4 hez képest nagy fejlődés. A dián a Core a processzort jelenti!!! Platform = CPU + chipset (processzor + lapkakészlet)

93 NB: North Bridge A fejlődés során a mennyiségi változás minőségi változásba alakult át. 2005: FSB-re rácsatolták a 4 darab egymagos CPU t. NB: NorthBridge. 2006: magszám növelés; sávszél növelés, már az előzőnél is szűk keresztmetszet volt az FSB, most kvázi 8 CPU lenne rajta => 2 FSB kell hozzá, de a RAM is igényelte ehhez a változtatást. A transzferrátának van egy maximális értéke, a fő oka ennek: a jelterjedés. 66 MHz => 100 MHz (400 megatranszfer). Nehéz a jelek dekódolása (kevés az erre fordítható idő). További probléma: ha nem zárják le a vezetéket a hullám impedanciájával, reflexió is megjelenhet, a vételt lehetetlenné teszi. DIMM-ek növelik az impedenciát. => a sebesség bekorlátozza a transzferrátát. A DIMM-ek száma is bekorlátozódik. Régebben volt 8-6-4, de re csökkent! Megoldás: Párhuzamos buszok helyett soros buszok használata. Az átalakító, amit ehhez használnak: XMB. (ennek a neve nem fontos. Ismétlés: lábszámok: DDR: 240 pin, északi híd (3*4 cm): 480 pin a RAM hoz (+ FSB-hez, VGA hoz, déli hídhoz). Soros busz: ~80 pin, 4 csatorna is ráfér.) 2007: minden CPU hoz külön FSB (eddigi 2 db => 4 db). FBDIMM (Fully Buffered DIMM) : szabványos (ipari jellegű) megvalósítása a párhuzamos-soros átalakításnak! Az FBDIMM2 előnye: a lábszám csökkentése (=> csatornák számának növekedése) és a DIMM ek(foglalatok) számának növekedése (1-2 => 6) a soros-párhuzamos átalakítás miatt. Kapacitásnövekedés figyelhető meg a DIMM-ek száma miatt. Következő lépés: felejtsük el a párhuzamos FSB-ket
. PCI-E kimenet. MCH: északi híd. http://en.")
94 Esettanulmány, elméleti ábra (rendszerarchitektúra). A következő dián a valós példa. 4 CPU külön FSB n keresztül kapcsolódik, 4 memória csatorna (8-8 DIMM: 512 Gb, 16 Gb/ DIMM). PCI-E kimenet. MCH: északi híd. -

 Nehalem újra behozta.")
95 A különbség: 8-8 helyett a valóságban 6-6 DIMM(összesen 24) van beépítve, maximum 8 Gb/ DIMM. 4 csatorna * 6 DIMM* 8 Gb= 192 Gb. P4: első magnak nem volt SMT-je, többinek igen Core 2 elhagyta az SMT-t (mert siettek vele) Nehalem újra behozta. Integrált memóriavezérlés, QPI
 = busz sebessége * adatút szélessége.")
 Egy processzornak van 4 linkje, ezen keresztül tudnak")
96 - Kétirányú a kapcsolat, - Bitenként két vezeték kell (gyors sebességnél), - Differenciál átvitel történik (néhány száz mv váltás), - Összes vonalszám: 80. Magyarázat: A sávszélesség (a processzor teljesítménye miatt) = busz sebessége * adatút szélessége. A sebesség elérte a maximumot, a busz szélességét kell növelni, az optimum: 20. => *2 az átvitel miatt, *2 a két irány miatt => 80 vonal szükséges (+4 az órajelnek) Egy processzornak van 4 linkje, ezen keresztül tudnak kapcsolódni egymással. Külön memóriavezérlőt tartalmaz -> könnyen skálázható a memóriakezelés



97 8 magos kialakítás, 16 szálat képesek kezelni, 2 integrált memóriacsatorna

98 3 dolgot szükséges kiemelni: - AVX - Tartalmaz egy grafikai motort - kapcsolóhálózat gyűrűs ( csille sorok, ebből vesszük ki az adatokat Turbo Boost: Ha van 4 magom, akkor van annak egy maximum disszipációja ami belefér adott teljesítményhez, ha viszont csak egy mag aktív akkor annak lehet emelni a frekvenciáját, anélkül h a disszipáció túl nagy lenne. Ez a végállomás ma!

99 2003-ban indult el az ág. HT: Hyper Transport cht: coherent Hyper Transport



100 AMD platform AMD késlekedett, infrastruktúra késleltetve követte a processzorokat. Opteron: K8mag (2003). 64 bit és memóriavezérlő a CPU lapkán, soros buszok
. Skálázódik a memóriacsatornák száma a CPU k számával (2 csatorna / CPU => 4 CPU esetén 8 csatorna). RAM vezérlő a lapkán.")
101 - Direct Connected Architecture: Közvetlen kapcsolódás másik processzorhoz vagy memóriához. Például egy CPU 2 másikhoz kapcsolódik, plusz az I/O hoz. - Két csatornás RAM kapcsolat (vastagabb fekete vonal). Skálázódik a memóriacsatornák száma a CPU k számával (2 csatorna / CPU => 4 CPU esetén 8 csatorna). RAM vezérlő a lapkán. - Soros busz megjelenése. Intel: Nehalem architektúra (Corei3, i5, i7): ugyanez, csak 3 helyett 4 link (AMD: K10). Jellemzően 3 memóriacsatorna. 64 bites architektúra. QPI (Quick Path Interconnect): a kapcsolóhálózat elnevezése

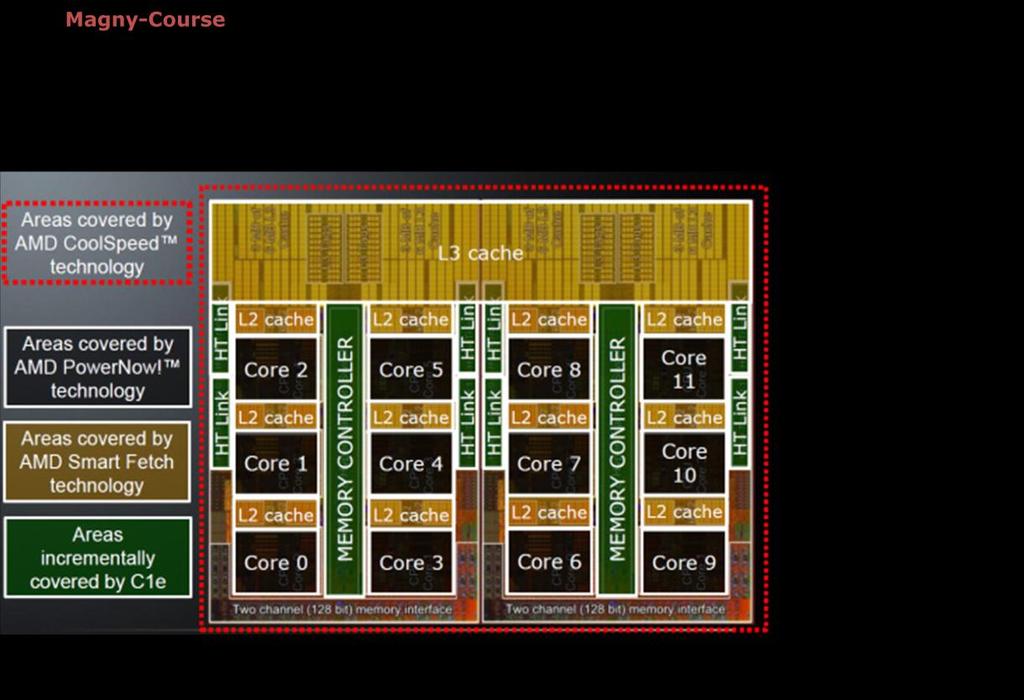

102
103 Nagyon gyorsan változik a világ, nem tudni meddig halad a magszám



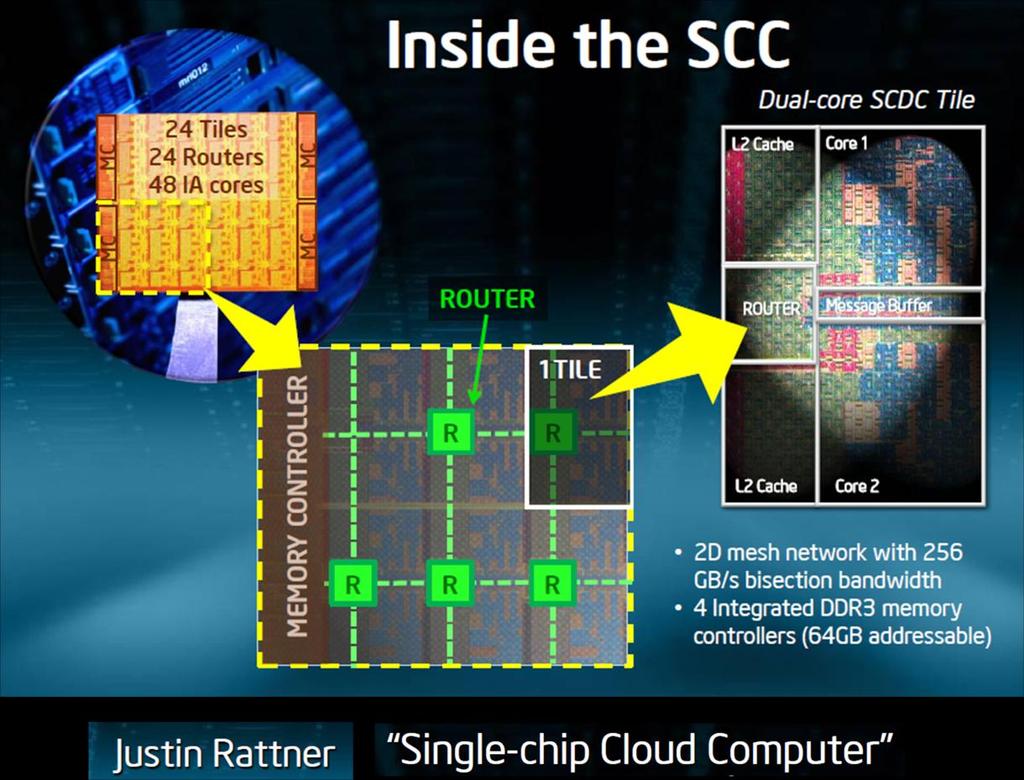
104 + Single Chip Cloud Computing 2009 decemberében visszavonták 2009-ben visszavonták. Oka: 1-2 Tera teljesítményű volt, de kijöttek új processzorok, amik ennél nagyobbal jöttek ki

105 - x86 alapúak bites SIMD kiterjesztés (512 bitet tudnak egyidőben összeadni) - 4 szál, Multi Threading. - Koherens L2 cache: odafigyelnek rá, hogy mindig a legutolsó beírt értéket kapja meg, aki kéri. 512 Kb. Ringbus: a kapcsolóhálózat. 2 db bus, mindkét irányba 1-1 kommunikál. Minden mag forrás vagy nyelő, rendelkeznek egy-egy elosztó áramkörrel. 2 feladata: kiveszi, ami neki kell, és gondoskodik arról, hogy a másnak küldött csomagok a megfelelő helyre kerüljenek bele. RAM vezérlő is ezen keresztül kommunikál, és ha van speciális-dedikált egység, akkor azok is ezen keresztül kommunikálnak egymással
 8 csatorna, hogy ezt a sávszélességet produkálni tudják. DIMM: 64 bitesek egyéb, hagyományos (nagyobb, de lassabb). - HPC célú.")
106 Kialakítási alternatívák: - GPU orientált Larrabee alaplapja (publikálták, de nem lehet tudni, megjelenik-e) GPU-k adattal való ellátása nehéz dolog: sávszélesség bites. GDDR: 32 bitesek grafikai memóriák (kisebb, de gyorsabb) 8 csatorna, hogy ezt a sávszélességet produkálni tudják. DIMM: 64 bitesek egyéb, hagyományos (nagyobb, de lassabb). - HPC célú. Kiérlelődött, kiforrott, működő rendszer. Minden mag mindenkivel kommunikálhat, memóriavezérlő on-die. CSI: soros busz (AMD: HyperTransport), a QPI elődje (csak máshogy nevezték). ICH (I/O ControllerHUB): Déli híd


107 Csempézett, 80 magos processzor 8*10 es kialakítás, csempénként 5 link (router)
 -> NINCS memória controller, memória kicsi, disztributált.")

108 3 Kbyte utasításmemória (hol a nagy memória??) -> NINCS memória controller, memória kicsi, disztributált. 2 lebegőpontos egység 32 bites, és ez minden, nagyon egyszerű rendszer. A feldolgozó egység nem annyira fejlett (kapcsolóhálózatokkal játszanak.)
, kis utasításkészlet. Csak egy néhány speciális feladatra használható, semmi szoftvertámogatás.")
109 256 utasítás áll rendelkezésre Semmi osztás, korlátozott elágaztatás, semmi compiler ( Itt a hardver, nesze játssz vele ), kis utasításkészlet. Csak egy néhány speciális feladatra használható, semmi szoftvertámogatás

110

, gyors kell -")
111 Tanulság: Talán érdemes sok tranzisztor egy részét On-die memóriaként alkalmazni, ezzel kiküszöbölhető sok holt idő - Vigyázni kell a kommunikációra (message passing), gyors kell



112 2009 decemberében jelentették be, feltételezve mert a Larabee-t akkor vonták vissza. Felkínálták egyetemeknek, hogy használják. Fejlesztés Németországban és Indiában. 48 mag, üzenet közvetítések Ha shared memory akkor cache tartalmának koherensnek kell lennie egymással! 24 csempe, van memória controller, 1,3 milliárd tranzisztor


113 6 oszlop, 4 sor rács, rácsok közt routerek Csempében két magot találunk: P54C Pentium mag (mint Larabee-ben) 16 Kb adat és utasítás cache CC : Cache Controller 8Kb üzenet puffer

114 Ez már egy használható rendszer

115 Nem használnak cache koherenciát, helyette más van
 - 116 -")
116 Ki kell emelni itt a disszipációt: Külön kell frekvencia sziget és feszültség sziget, hogy tudjuk szabályozni őket külön, el tudjanak válni a többitől. Ennél a rendszernél 8 feszültség sziget van és csempénként más frekvencia. (FONTOS)


117 Működéséről: van egy közösen használt off-chip memória magonként L1, L2, van saját üzenet buffer Kommunikáció: Berakja saját pufferébe amit küldeni szeretne, átviszi a másik pufferébe, az kicsomagolja és elolvassa
118
, blade-be néhány tízezret => QS20-21-22: sokat nem hozott a PS3 hoz")
119 Eredetileg a PS3 gépekhez készült (2000), később kiépítették, mint egy blade-et. PS3-ba rengeteget adtak el (tízmilliós nagyságrend), blade-be néhány tízezret => QS : sokat nem hozott a PS3 hoz képest.5-7 év fejlesztői munka nagyon sok!
: csak ebből képesek programot végrehajtani/adatot lehozni -> saját kis memóriájuk van, a mesternek kell felprogramoznia őket (beletenni a")
120 VMX: az IBM-nél így hívják a SIMD et. Power architektúra. EIB az egy ringbus. Kétcsatornás memóriavezérlő. 64 bit. 512 k cache 8 db SPE(szolga) bonyolult felépítéssel. Szolgák felépítése: - Önműködésűek LS (Local Store): csak ebből képesek programot végrehajtani/adatot lehozni -> saját kis memóriájuk van, a mesternek kell felprogramoznia őket (beletenni a memóriájukba) - Működés: 1. Be kell tenni az adatot és a programot a lokális tárba 2. meg kell szólítani, induljon el 3. szolga szól, hogyha kész (signal, olyasmi, mint a megszakítás az I/O nál) vagy pedig beteszi egy postafiókba (nem a lokális tárba!), és a mester kiveszi belőle (adott idöközönként vizsgálja) - Mindent a mester szervez - Rambus XDRAM (QS21-ben már DDR) Mester: Teljesen közönséges CPU. DMA kapcsolat a szolga és a mester között. Nehéz programozni

121 QS20: Rambus memória: a grafika miatt (sávszélesség), hiszen eredetileg PS3 hoz csinálták. QS21-nél ezt felváltotta a DDR. Minden műveletet szinkronizálni, menedzselni kell => nehéz programozás Felépítésen látszik: 512 L2, mester, szolga, RAM és I/O kapcsolat, kapcsolóhálózat

.")
122 EIB: 2-2 darab ringbus. 96 byte/ciklus (~0.1 kb) sávszélesség (16 byte / ringbus). Az ábrán látható még a kétcsatornás memória és az IO vezérlő



123 Egyidejűleg több paralell kapcsolat lehet. SP: SinglePrecision, szimplapontos. Lényeg: 0.4 TF sebesség. Roadrunner: Peta flops teljesítmény. Ennek volt a Cell egy alkotóeleme ben hódította el a címet a Jaguar: 1.75 Teraflop sebességgel. A Roadrunner a második
. ~4 MW teljesítményfelvétel - 124 -")
124 7000 Dual-core Opteron (LS21Blade) Cell (QS22Blade). ~4 MW teljesítményfelvétel
: univerzális, egységes shader modell.")

125 Shadereken keresztül történik a grafika megvalósítása. Shadermodellek: szabványok. Fontos: Shadermodell 4 (2006): univerzális, egységes shader modell. Azonos adattípusok, azonos utasításkezelési rendszer -> azonos hardver használata különböző shadermodellekhez. Ettől kezdve jelentek meg olyan processzorok, amiben rengeteg lebegőpontos műveletvégző van. ATI a vezető, AMD felvásárolta. Intel fel akarta vásárolni az nvidiát, de az nem hódolt be. => AMD és nvidiaa két nagy cég
126 Az ábra csalóka: grafikus kártya 1 TFLOPS-ot tud, de ez szimplapontos lebegőpontos művelet! A GPGPU k 32 bitesre vannak kialakítva: Az SP elegendő a térbeli pontok megadásához. Tehát tudják a 32 bites FP t és a bites FX et (3*8 bites RGB komponensek). Intel: 64 bitre van kialakítva tól kezdve nagyon sok ALU került a processzorokba. (lásd később)
 Cache több, mint a felét elfoglalta a CPU-nak. GPU-ban a cache szerepe kisebb, ha a memória nem érhető el, akkor többszálúsággal oldja meg.")
127 Sávszélesség: 10 és 100 Gb/s (CPU nála felületet döntően a cache viszi el, míg a GPGPU ban lényegében az egészet a számítási teljesítményt támogató processzorok töltik ki (következő ábrák). Nem egészen jó ábra, de jól néz ki ( Móricka ábra ) Cache több, mint a felét elfoglalta a CPU-nak. GPU-ban a cache szerepe kisebb, ha a memória nem érhető el, akkor többszálúsággal oldja meg


128 Most kezd elterjedni, mert a szoftverháttere most kezd kirajzolódni. 16 magja van, magonként 32 ALU-ja. Mindegyik ALU 32 bites, támogatja a duplapontos lebegőpontos műveletet, és az ezzel való számolás a szimplapontos fele!
129


130 Közösen használt L2 cache. Grafikai memória, gyors, 32 bites. Jövő: rá kell tenni a lapkára a GPU t (mindkét cég belátta)
 csatornás ram.")
131 Intel Nehalem: nm, 3 (DP) vagy 4 (DP-MP) csatornás ram
, Westmere Kiemeltük: Havendale: Kétmagos CPU")

132 Pentium 4, Core2, Nehalem (pl. az ábrán: Havendale és Lynnfield), Westmere Kiemeltük: Havendale: Kétmagos CPU (Dual-Channel, PCIe, GraphicsCore): bejelentették, majd vissza is vonták. 45 nm helyett 32 n hozták ki, Clarkdale lett az új neve. A négymagos Lynnfield kijött 45 nm en, ahogy eredetileg bejelentették

133 Arra várunk, hogy a grafikus kártya rákerüljön a procira
134 Az irány, amerre halad a fejlődés: Sok master és sok slave (példa: CellQS sorozat. Roadrunner Cell Blade is van benne) Sok CPU és sok dedikált mag (példa: nvidia: G200sorozat. ATI/AMD 9250) 1 CPU 1 csatolt => több CPU -1 csatolt => több CPU - több csatolt Jövő tehát: több mester több dedikált processzor


135 GPGPU - Data Paralell Accelerators 2010 őszi félév


136 GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Az ábrázolás háromszögekre épül (n millió), van felülete és élei. Ha le akarjuk íni, akkor mind a 3 rendszerben le kell írni plusz kiegészítő információkat kell hozzáadni. 3D képponthoz szimplapontos lebegőpontos ábrázolás kell. Vertex shaders: Pixel shaderre lett egyszerűsítve, a képpontokat keverik, így leképeződik 2D-re. Fixpontos ábrázolás: 3*8 bit elég (3 szín, 100 árnyalat *8bit elég ábrázolni+, ember ennyit észlel)




137 A 11-es DirectX verzió mára már valósággá vált! 2-es modellben: Háromszög csúcsaihoz lebegőpontos formátum Árnyalatok: Fixpontos formátum Külön formátum, ezekhez külön regiszer készlet és utasítások kellettek: nem túl hatékony. 3-as modellben : Egységesítették a kettőt (FP32 mindkettő) 4-es modellben: Egységes pontosság, egységes utasítás, egységes regiszterek, két ISA egybeolvad - > hardverben azonos eszközöket lehetett használni -> új lehetőség
! Sok ALU miatt nagy számítási sebesség, ehhez nagy sávszél kell.")
138 GPGPU-t használják HPC számításra. Csúcs feldolgozó teljesítmény: Gigaflops. Szimplapontos teljesítményre vonatkozik az ábra. Intel rendszerek és NVIDIA GPGPU-k összehasonlítása környékén SM4 nek köszönhetően begyorsult, a csúcsteljesítmény ban1 TF. Manapság 2,7 Tflops (Fermi)! Sok ALU miatt nagy számítási sebesség, ehhez nagy sávszél kell. Ami hátrány az az adatlapátolás a memória és a GPGPU között
 Támogatni kell a RAM oldaláról is: memória sávszélesség: 100-150 Gbyte / s (Intel processzoroknál: 10-20")
139 Lebegőpontos teljesítmény. Mindre jellemző a szeres szorzó (szimplapontos és duplapontos között). Fermi felviszi ezt 0.5 re, tehát 1.3 TFLOPS duplapontos teljesítményre képes. Csak adatpárhuzamosságra vonatkozik ez a teljesítmény (mátrixokkal való műveletvégzésnél) Támogatni kell a RAM oldaláról is: memória sávszélesség: Gbyte / s (Intel processzoroknál: Gb/s). Nagyon széles adatutakkal érik ezt el: pl. 32 bites csatornából 6-8 db (a szokásos 1*64 bittel szemben). Nagy teljesítmény indoka: a cache-eket igyekeznek mellőzni (masszívan többszálú működésűek). A hagyományos architektúrában a cache-ek segítségével csökkentik a hatékony átlagos elérési időt. Itt nagyon sok szállal működnek, és ha egy szál a RAMhoz fordul, elveszem az erőforrásokat, azt átadom egy másik szálnak, stb, és így meg tudom várni, amíg előáll az adat
.")
: Egy utasítás többszálú, SIMT nem szabvány elnevezés,")

140 SIMD: Egy utasítással több művelet, egy dimenziós adatpárhuzam. Először fixpontos műveletek, majd lebegőpontos (2.gen szuperskalár 1995). Ehhez kell ISA kiterjesztés és egy hardver. SIMT (T Thread): Egy utasítás többszálú, SIMT nem szabvány elnevezés, találkozhatunk vele másképp is. Két vagy több dimenziós tömbökbe adatpárhuzam kiterjesztése. Kell tudni szinkronizálni a szálakat -> barrier( sorompó szinkron), a szálak megvárják egymást. Ehhez kell ISA kiterjesztés és API-k
 hajtunk végre egy feladatot, fizikai háttérrel.")

141 Adatpárhuzamos végrehajtás, legalább kétdimenziós végrehajtási lehetőséggel. Logikailag Pl8*4 vagy 8*8 adatelemen (tömb) hajtunk végre egy feladatot, fizikai háttérrel. SIMT magok: GPGPU alapvető építőelemei, végrehajtás közben ezekre kell leképezni a (jellemzően 2D) mátrixokat. Alapjául szolgálnak az ALU-k, ezek szimplapontos lebegőpontosak ALU is lehet benne, ezek lineáris elrendezésűek -> a mátrixokat végrehajtás szintjén le kell képezni. SIMT mag gyártófüggő elnevezései


.")
142 Minden mag 1-1 regiszterfájlt kap a működéshez, és abból hozza az adatokat, és abba viszi az adatokat. 3 nyíl oka, hogy ha 3 operandusú művelet van azt is át tudja vinni (Fused Multiply Add). A*B+C nagyon jellemző mátrixoknál




143 Futószalag jellegű végrehajtás (Azt várom el tőle, hogy minden órajelre új utasítást dolgozzon fel). ~2-4 óraciklus után megvan az adat (Fermi: 2, régebbieknél 4) Fényforrások kiszámolásához kell sin, cos, tg műveleteket, ezeket támogatják. Masszív többszálúság: Célja, hogy a cache-ket a többszálúság kiváltsa, alapvetően a megállított szálak esetén a vezérlést új szálak kapják





144 A szálváltásnak null ciklusúnak kell lennie (nem veszíthetünk időt). Kontextus váltásnál mikor nem kell mentés? Ha másik regisztertérben dolgoznak! Van egy sereg ALU, mindnek van regisztere. Minden szálhoz rendelődik egy regiszter tér

145 Induljunk el egy vektorból. Van egy programunk, nézzük meg az alapelemeket. Ha az adatelem 0 akkor ref1 = Ka különben felső ág. Sok adatelem esetén szükségszerűen mindkét ágat végig kell járni! Vagyis amelyre nem teljesül a feltétel azok pihennek, egy ponton viszont bevárják egymást. Első 3 ciklusban azoké akiknél a feltétel teljesül, a többi NOP, utána fordítva

 ->")
146 Az összes többi utasítást csak ezután hajtja végre (minden ALU-ban) -> szinkronizáció
 végrehajtja, és amikor adatpárhuzamos részhez érünk ( Kernel ), ami blokkokból épül fel (pl.")
147 Bal oldalt utasításfolyam, ezt két kódszegmensre bontjuk. Van egy CPU és van egy GPGPU. A CPU az az eszköz, amelyik az utasításfolyamot elvben (valószínűszeg sorosan, egy maggal) végrehajtja, és amikor adatpárhuzamos részhez érünk ( Kernel ), ami blokkokból épül fel (pl. 1 blokk szál), akkor megszólítja a GPGPU-t, adattranszfert végrehajt, és a GPGPU végzi el a műveletet, esetleg adatokat visszaad a CPU-nak. Ezután megy tovább a soros végrehajtás. Hátrány: adattranszferek lassítják. Töltési idő a szűk keresztmetszet


148 Alapvető megvalósítás: GPGPU szintű, gyorsító szintű GPGPU: öszvér, a grafika és a HPC között. Programozható, API-kat kell tudni, tesztelni kell tudni. AMD megvásárolta az ATI-t. NVIDIA nem ment bele abba, hogy az Intel része legyen. Data paralell acc.: kijelző nélküli nagyobb memóriával rendelkező célhardver. Tesla és FireStream családok
 és G92 közt nincs nagy különbség, G200 már van architektúrális változás, utána Fermi (zsugorítás és architektúrális változtatás is történt).")
149 Nvidia élete nehéz a piacon, de megkapaszkodik. NVIDIA: G80 volt az első használható GPGPU. G80 (az első igazán használható GPGPU) és G92 közt nincs nagy különbség, G200 már van architektúrális változás, utána Fermi (zsugorítás és architektúrális változtatás is történt). AMD: technológiában előrehaladottabb (triviális, mivel jóval nagyobb cég). RV870: 2009 ősszel
150 Kiemelendő 3 dolog: - Komplexitás (tranzisztorszám): G80 700millió, GT200: duplázódik, Fermi: szintén. ~ tranzisztor! - ALU-k száma: G80 ~100, GT200 ~200, Fermi ~500 - Memória adat sávszélessége: bit (32 bit széles, n db csatorna) AMD R500: beépített rendszer, XBOX-ba készült. Nem tekinthető GPGPU-nak (~50 ALU), de egy állomás afelé. R600: ALU-k száma Szoftvertámogatás: CUDA v1, v2 (egymástól lényegesen eltér a kettő! ) NVidia sajátja. Brook+: saját programozási rendszere az AMD-nek. OpenCL szabvány: AMD, NVIDIA, Intel is támogatja, elmúlt 1-1,5 évben érett meg. Mivel szabvány rendszer ezért bonyolult, nehezen programozható, CUDA-t könnyebb
 Elvben : 2 FX, plusz 1: minden 8. ciklusban FP.GDDR5 kicsit gyorsabb, mint a GDDR3.")
151 2 dolgot kell kiemelni: - Chip felület: 576 mm^2 (~2*3 centi.. Intel CPU: ~1 cm^2) - Frekvencia ~1 Ghz hatékonyan (tényleges számítási frekvencia: 1 GHz felett: 100 ALU 1.2 GHz, elvben 3 utasítás => 346 GFLOPS. Ugyanígy kapjuk meg az ~1 TFLOPS ot is) Elvben : 2 FX, plusz 1: minden 8. ciklusban FP.GDDR5 kicsit gyorsabb, mint a GDDR3. Jellemzően PCI expressen keresztül csatlakoznak Teljesítmény kiszámolható: művelet*frekvencia*alu szám pl GTS: 3*1,2*96 Ringbus <-> Crossbar - Most Crossbar tűnik jövőnek Alap frekvencia Nvidiánál magasabb, de kevesebb ALU, AMD fordítva!
 Itt is megvan a több kártya használati")

152 Nagyon hasonló az előzőhöz, több mag van, kisebb frekvenciával (1 Ghz helyett 700 Mhz körül) Itt is megvan a több kártya használati lehetősége, csak máshogy hívják. Árak: AMD nagyobb, megengedheti az olcsóbb árat, uralja is a piacot. Intel a nagy teljesítményre törekszik
. Mindkettő visszamondta, azt mondják, hogy a 32 nanos technológiával hozzák ki (a nagy tranzisztorszám miatt). Következő évben (2011) fog kijönni.")
153 Adatpárhuzamos gyorsítók Két féle implementáció: - kártyás (jelen) - szilicium lapra integrált (jövő) Mindkét gyártó bejelentette, hogy 1 lapkán lesz CPU és GPU (Intel: Nehalem). Mindkettő visszamondta, azt mondják, hogy a 32 nanos technológiával hozzák ki (a nagy tranzisztorszám miatt). Következő évben (2011) fog kijönni


: 4 kártyás, 2")

154 Kártya alapú megvalósítás: Kártya, desktop, szerver. (NVIDIA: C-D-S) Kártya (C): PCI-e x16 oson keresztül. Desktop (D): 2 kártya, adapteren keresztül Szerver (S): 4 kártyás, 2 adapter, 2 slot, 2 kábel kell Tesla 1 kártyás rendszer, nagyon egyszerű. 1 processzor, 1 Frame Buffer, 1 host interface



155 2 GPU kell hozzá, PCI Express kapcsoló, adapterkártyán keresztüli csatlakozás a CPU-hoz


156


157 Server: 2 * 2 kártya Az előző kétkártyás megoldást tükrözték, kizárólag mennyiségi változás. nvidia: S sorozat AMD: 9200-as sorozat Kétkábeles csatlakoztatás

158 memória, kapacitás, teljesítmény : kártya -> D -> S 2-szeres különbség! A GFlops, szerintem itt TFlops akar lenni Card: fél Tflops teljesítmény, tranzisztorszám kb. egymásnak megfelelnek az Nvidiával


159 teljesítményfelvétel elég nagy -> erős táp kell A kártyák néhány 100$-ba kerültek, ezek pedig több ezer $!! Céljuk: Nagy számításigényű feladatok, állami intézetekben, bankokban, biztosítóknál pl


160 2,7 TFLOPS a szimplapontos! 20%-a a duplapontos, de így is fél TFLOPS. 544 GFLOPS duplapontos viszont elmarad a Fermitől. ECC: Fermi tudja, ATI nemtudja

161 Egyszerű felépítés. 16 ALU / mag, 5 feldolgozó egység / ALU -> 1600 feldolgozó egység! Felül van egy command processzor, követi egy szál-diszpécser. Alul egy 8 csatornás memória, ezek 32 bitesek. Összesen 256 bit

162 Stream Processor = ALU Újdonság: Idle Board Power: disszipáció csökkentéssel elkezdtek foglalkozni, disszipáció csökkentési technika, így a fogyasztás is csökken ban fele minden paraméter kb

163 Ez a jelen!


164 Jövő: Financial Analysis Date-n mutatják be, hogy mi várható, ebből tudunk következtetni. Y tengely: árszint, X tengely: idő október 12.: kis árszintes, alacsonyabb teljesítményű kártyát harangoztak be november 18.: magasabb árú, nagyobb teljesítményűt Igyekeznek egy olyan családot kialakítani, ahol pénztárcától függően választhat az ember, hogy melyiket szeretné. 2 GPU-ja van (paraméterek * 2), de ennek ára van -> nagyobb lesz, be kell férnie a gépbe


165

166 5800-ast követni fogják alcsaládok > 6990 pl. Iszonyú nagy a verseny, igen gyakran hozzák ki az újakat. 1-2 éven belül új családsorok

167 Teljesítményben sorban egymást követik a családok. Középső oszloptól DX11-et támogatják!

168 1 hét különbséggel jelenti be



169 16 mag, minden magban 32 ALU, 384 bit memória. Itt: core = ALU!!!

170 Egy ALU: - két végrehajtó egység - egy lebegőpontos, egy szimpla 32 bites - 2 órára van ehhez szükség -> fele a duplapontos teljesítmény Előző rendszerbe 3 magra jutott egy cache, most 1-re. L2 cache háromszorosára nőtt, L1-et is növelték. Egyre több tranzisztor, ezért nagyobb a cache


171 Kernel hívja meg a GPU-t. CPU memóriájából be kell tölteni GPU-ba az adatokat és vissza


172 Hiba: 2001 az 2010! GF : GeForce kártya családneve GF110 : Úgy tűnik átveszi a teljesítmény koronát. ATI - Nvidia versenyben a 480-as még alulmarad, 580-tól várják el a fordítást


173


174 Integrált CPU / GPU : Ez jelenthet diszkrétet is: tokon belül de lehet sziliciumlapkára integrált is 2010 november 9.-én jelentik be. Liano: legjobb teljesítmény (DX11) Stars: Régi mag Két új mag: - Bobcat: Új mag, kisebb teljesítmény - Bulldozer : nagyobb teljesítmény


175 Régi mag, de kész. (paramétereket nem kell tudni) Ami érdekes itt az a Mainstream


176 4 magos, alul GPU. Nem lehet tudni, hogy Bulldozer, vagy Stars Opteron 6-12 maggal nő magra. Bulldozer architektúra


177 Lehív Dekódol Integer scheduler: ütemezők FP ütemező 2 db FX mag, megosztott L2 cache


178 Ez az előző ábra részletesebben. BTB : Branch Target Buffer az elágazás-kezeléshez. Icache : Utasítás cache Két szálú processzor, a szálak alig zavarják egymást (erős szálak)

179 Kék: Start Sárga: Prototípus Piros: Kijövetel Kb. 2 év telik el közte


180 Integrált CPU és GPU. i5: Diszkrét integráció: egy tokban vannak, de két Si lapka. 45 nm-es a GPU

181 1-2,5 Ghz Támogatják a Turbo Boost Technológiát: ha nem használunk egy magot, növeli a frekvenciát. Tervezési disszipációs értéket 2 magra határozzák meg erős meghajtás mellett. Ha egyik mag nincs meghajtva, akkor fel lehet növelni a másik frekvenciáját, túlzott disszipáció nélkül. i3-as többet fogyaszt, mint a jobb i7 -> fejlettebb disszipáció kezelés

182 1 év múlva jön ki Full integráció, 1 Si tartalmazza a magokat. Sandy Bridge -> Gyűrűs kapcsolóhálózat (amely először Cellbe jelent meg, majd Larabee-be is betették)
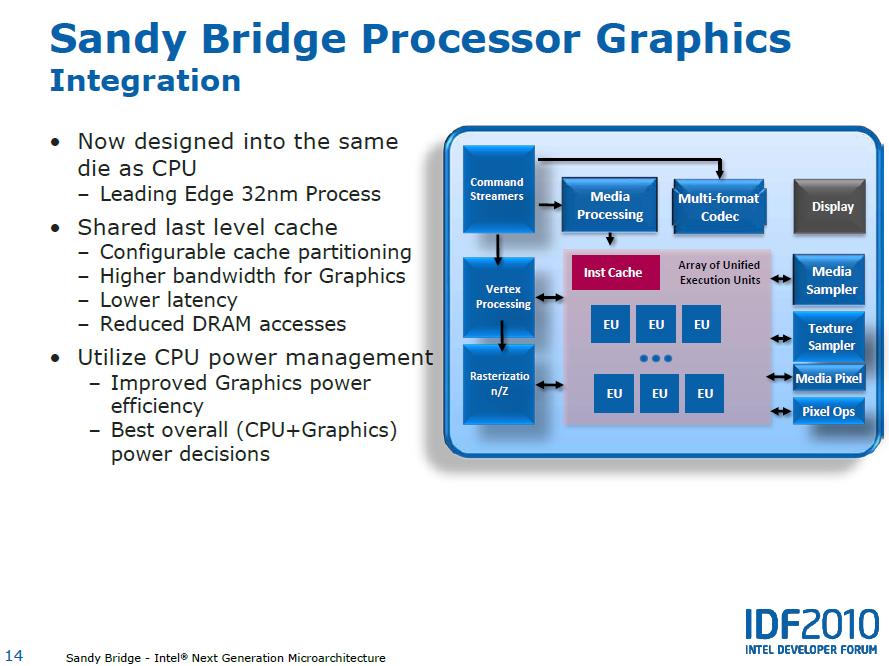
183


184 Alaplapok 2010 őszi félév Felépítés:



185 Első megjelent IBM PC-k, 71-ben jelent meg az első PC, 10 év kellett, hogy megjelenjen az IBM PC. Alap IBM PC: 1981, processzora 8088, 4,77 Mhz, 16 Kb memória, ami be volt forrasztva az alaplapra. Két évet kellett várni míg megjelent az XT 10 MB-os merevlemezzel (1985-ben 1,5M Ft-ért adták el az intézetnek ez mai viszonyításban olyan 30 MFt). ROM: Basic nyelvet tartalmaz
.")

186 Első Compaq: 1982, hasonló volt mint az IBM PC (lemásolták, nem volt nehéz, mivel bárki megszerezhette az IBM dokumentációját). Klónozás jellemző a korszakra, ez az IBM piaci árát leszorította, viszont az alkalmazói programok erre íródtak, ez nagy előny volt nekik. Compaq 286 behozta a lapkakészletet -> alaplap méretének csökkenése -> Baby AT Ezt az IBM vette át tőlük


187 y tengely : méret AT, LPX, Baby AT : ez a 3 típus a kezdeti alaplaptípusok Majd bejön az ATX (gazdaságosság, célirányosság), ezzel egy időben jelentek meg a 2. generációs szuperskalárok, de nincs köztük logikai kapcsolat. NLX, ATX, micro ATX : 2. nagy alaplapcsalád BTX, micro BTX, pico BTX: alaplapcsalád kezdeményezés. Oka: Prescott, ezt készítette elő, disszipáció javítása, hűtési rendszer fejlezstése. De mivel jöttek a többmagos processzorok, ahol nem volt nagy disszipáció ezért feleslegessé vált


188 AT: ISA 92- PCI busz EISA : Extended ISA 32 bit, de működést nem módosította PCI: Intelnek volt szerepe benne 90-es évek végén HUB architektúra

189 PCI: két vezérlő közt helyezkedik el ISA: kompatibilitás miatt van meg PIII környékén: HUB, egészen amíg északi híd integrálódik 1 bájtos memória -> 4 bájtos memória Pentium után jelent meg a 21 bájtos


")
190 ISA -> PCI -> ATA PII multimédia támogatású -> AGP II. generációs szuperskalár, ATX busz -> ATA, USB, AGP, LPC, AC 97 soros buszok világa: SATA, PCI-E (nem kell tudni az adatokat, csak áttekintés) form factor : alaplap


191 A memória még egy felület, nem kártya. Jellemző CPU: 286 KBD: Keyboard csatlakozó, PC: tápkapcsolat Nagy felület van a vezérlőnek, mert nincs lapkakészlet



192 - CPU: 386 L2 cache 1 bájt széles SIMMek -> memória kártyák


193 . Későbbi Baby AT Megjelent a PCI buszrendszer 8 bites ISA-ra már nem volt szükség memória: 4 bájtos kártyák CPU: 486, Pentium

194 Itt még rendszer és periféria-vezérlő volt, nem É, D híd. Jellemző : Riser Card: lap közepén, ezáltal kisebb lesz az alaplap mérete


195 . gazdaságos, célirányos!! IO szabványosítva : emeletes kialakítású rendszer (következő dia) 1 hűtő rendszer (ventillátoros) Egymás mellé kell tenni a processzort és a tápot és együtt hűteni. Legalább 6 slot legyen (ISA, PCI)
196
197 Méretek összehasonlítva. ATX sokat élt. Kezdeti PCI alapú rendszerek, késői PCI alapú rendszerek AGP megjelenése (MM támogatás PII-höz) Port alapú rendszerek PIII-tól (ÉH, DH) Soros rendszerek
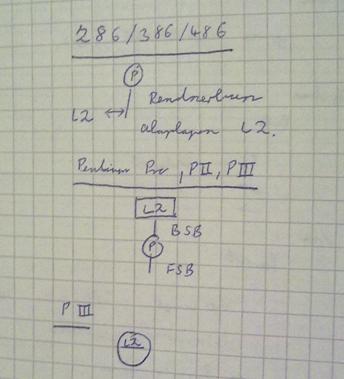
198 L2 elrendezés


199 Késői PCI alapú PII, PIII Slot1-es rendszerek SDRAMok megjelenése MM támogatás -> AGP
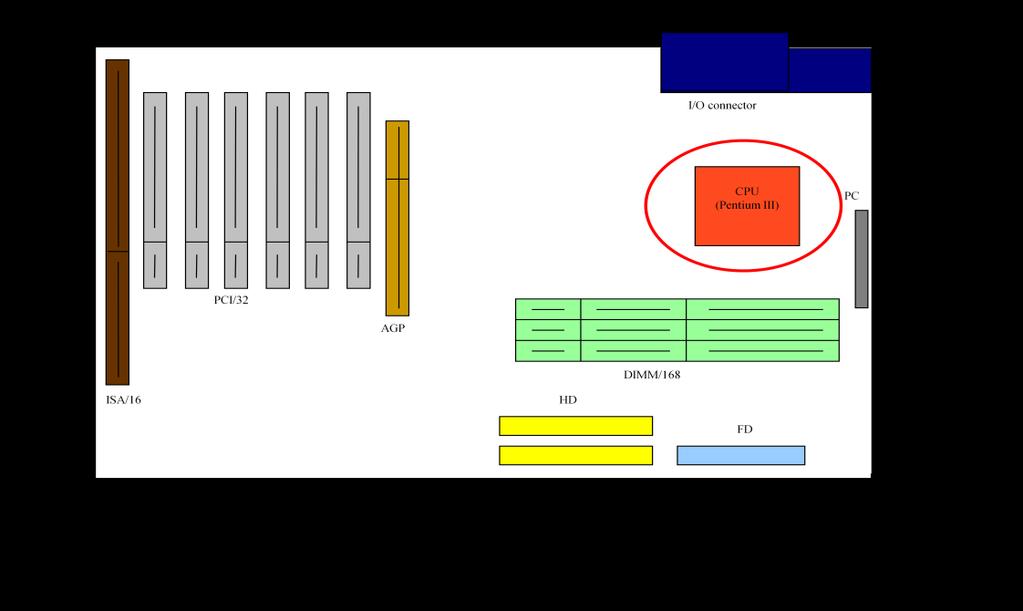

200 Processzor visszaköltözött egy tokba


201 late: P4-es rendszerek Prescott soros buszok: PCI-E, SATA, disszipációs problémák -> komoly hűtés kell!!

202


203 Riser kártya lap szélére kerül


204 1 légcsatornára helyezik a kritikus eszközöket: ICH: IO Control, D híd MCH: Memory Control, É híd Processzor

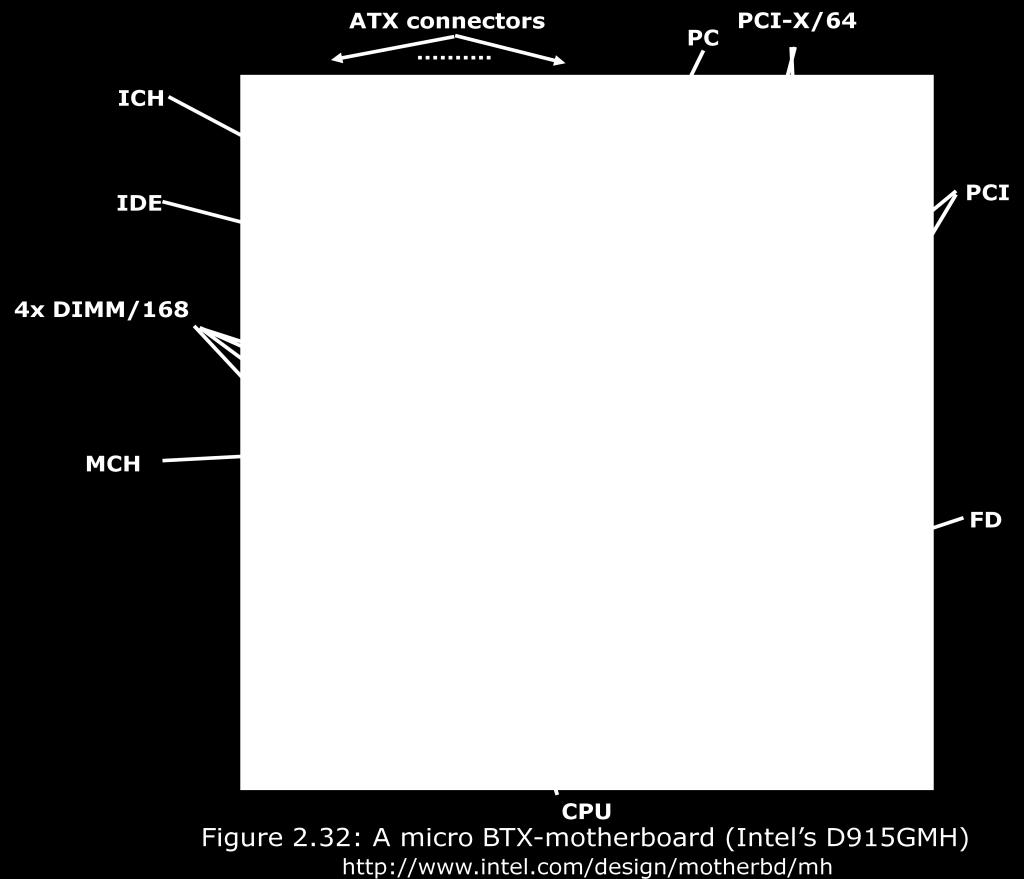
205 Hatékony hűtés
206 Soros port alapú szerver alaplap DH kapcsolat: lassú


207 MCH: Északi híd ICH: Déli híd
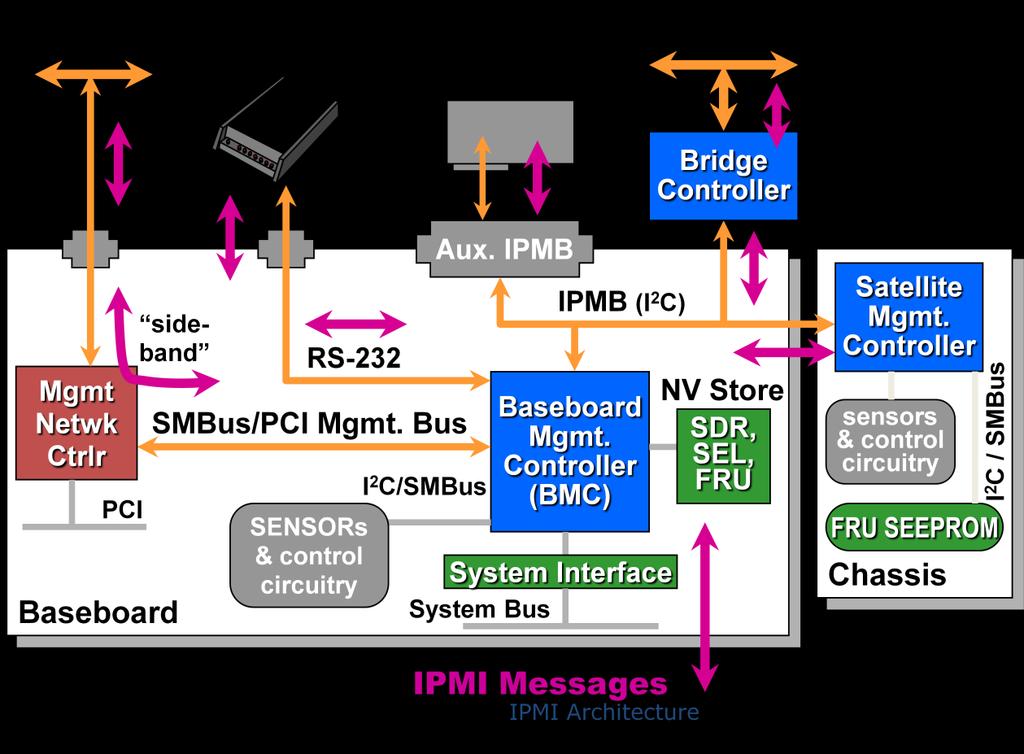
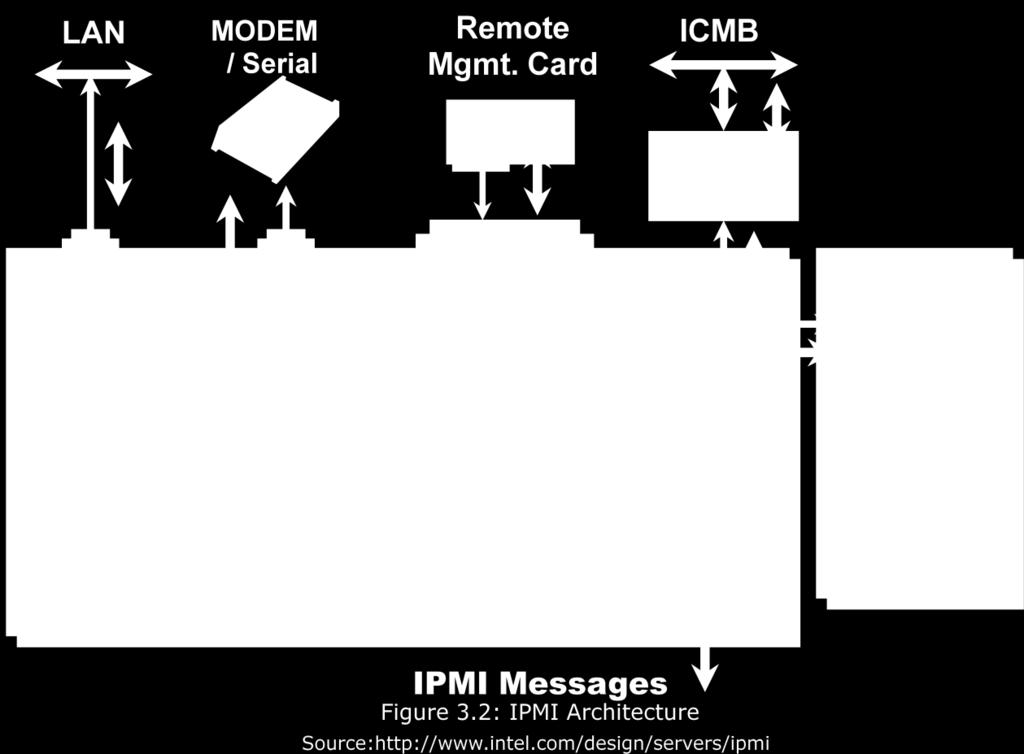
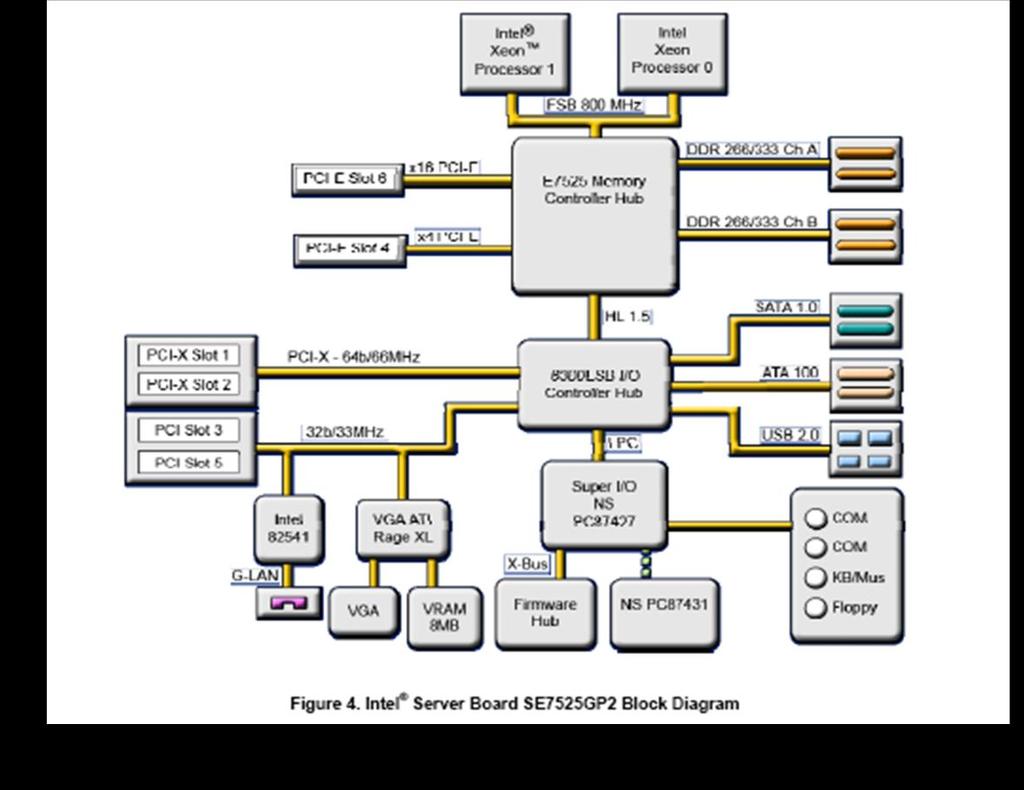
208 Két processzoros szerver

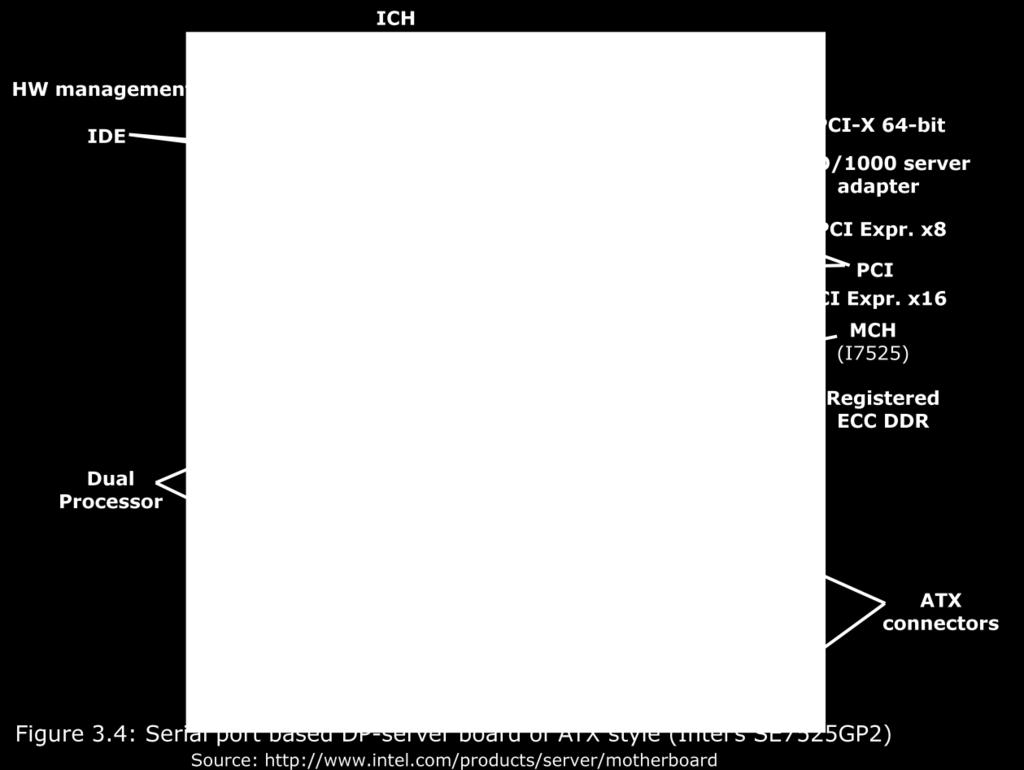
209 Registered ECC DDR HW management: tápmenedzsment

210 IO-k fejlődése csíkok: mettől meddig volt jellemző a használatuk
Teljesítmény: időegység alatt végrehajtott utasítások száma. Egységek: MIPS, GIPS, MFLOPS, GFLOPS, TFLOPS, PFLOPS. Mai nagyteljesítményű GPGPU k: 1-2
 2009. 10. 21. 1 2 Teljesítmény: időegység alatt végrehajtott utasítások száma. Egységek: MIPS, GIPS, MFLOPS, GFLOPS, TFLOPS, PFLOPS. Mai nagyteljesítményű GPGPU k: 1-2 PFLOPS. (Los Alamosban 1 PFLOPS os
2009. 10. 21. 1 2 Teljesítmény: időegység alatt végrehajtott utasítások száma. Egységek: MIPS, GIPS, MFLOPS, GFLOPS, TFLOPS, PFLOPS. Mai nagyteljesítményű GPGPU k: 1-2 PFLOPS. (Los Alamosban 1 PFLOPS os
VLIW processzorok (Működési elvük, jellemzőik, előnyeik, hátrányaik, kereskedelmi rendszerek)
") SzA35. VLIW processzorok (Működési elvük, jellemzőik, előnyeik, hátrányaik, kereskedelmi rendszerek) Működési elvük: Jellemzőik: -függőségek kezelése statikusan, compiler által -hátránya: a compiler erősen
SzA35. VLIW processzorok (Működési elvük, jellemzőik, előnyeik, hátrányaik, kereskedelmi rendszerek) Működési elvük: Jellemzőik: -függőségek kezelése statikusan, compiler által -hátránya: a compiler erősen
Módosított ábra: szaggatott nyíl: a fejlődési ív Az ábrából kimaradt a mobil szegmens (hordozható számítógépek). Y tengely: ár.
. Y tengely: ár.") 2009. 09. 23. 1 2 3 Módosított ábra: szaggatott nyíl: a fejlődési ív Az ábrából kimaradt a mobil szegmens (hordozható számítógépek). Y tengely: ár. A value PC hez hasonló idővonalat kell elképzelni hozzá.
2009. 09. 23. 1 2 3 Módosított ábra: szaggatott nyíl: a fejlődési ív Az ábrából kimaradt a mobil szegmens (hordozható számítógépek). Y tengely: ár. A value PC hez hasonló idővonalat kell elképzelni hozzá.
Számítógép architektúrák záróvizsga-kérdések február
 Számítógép architektúrák záróvizsga-kérdések 2007. február 1. Az ILP feldolgozás fejlődése 1.1 ILP feldolgozási paradigmák (Releváns paradigmák áttekintése, teljesítmény potenciáljuk, megjelenési sorrendjük
Számítógép architektúrák záróvizsga-kérdések 2007. február 1. Az ILP feldolgozás fejlődése 1.1 ILP feldolgozási paradigmák (Releváns paradigmák áttekintése, teljesítmény potenciáljuk, megjelenési sorrendjük
Első sor az érdekes, IBM PC. 8088 ra alapul: 16 bites feldolgozás, 8 bites I/O (olcsóbb megoldás). 16 kbyte RAM. Nem volt háttértár, 5 db ISA foglalat
. 16 kbyte RAM. Nem volt háttértár, 5 db ISA foglalat") 1 2 3 Első sor az érdekes, IBM PC. 8088 ra alapul: 16 bites feldolgozás, 8 bites I/O (olcsóbb megoldás). 16 kbyte RAM. Nem volt háttértár, 5 db ISA foglalat XT: 83. CPU ugyanaz, nagyobb RAM, elsőként jelent
1 2 3 Első sor az érdekes, IBM PC. 8088 ra alapul: 16 bites feldolgozás, 8 bites I/O (olcsóbb megoldás). 16 kbyte RAM. Nem volt háttértár, 5 db ISA foglalat XT: 83. CPU ugyanaz, nagyobb RAM, elsőként jelent
* 800 MHz/PC-3200/ATA-100. SPECint_base2000/f c Pentium III. Pentium * 800 MHz/PC-2667/ATA-100 * * * * *
 SzA42. A processzorok fejlődésének hatékonysági határa (ennek alapvető oka és megnyilvánulási formái, hogyan változik az Intel és az AMD x86 családok hatékonysága az órafrekvencia növelésekor, a két család
SzA42. A processzorok fejlődésének hatékonysági határa (ennek alapvető oka és megnyilvánulási formái, hogyan változik az Intel és az AMD x86 családok hatékonysága az órafrekvencia növelésekor, a két család
SZÁMÍTÓGÉP ARCHITEKTÚRÁK
 SZÁMÍTÓGÉP ARCHITEKTÚRÁK Az utasítás-pipeline szélesítése Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-05-19 1 UTASÍTÁSFELDOLGOZÁS
SZÁMÍTÓGÉP ARCHITEKTÚRÁK Az utasítás-pipeline szélesítése Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-05-19 1 UTASÍTÁSFELDOLGOZÁS
SzA19. Az elágazások vizsgálata
 SzA19. Az elágazások vizsgálata (Az elágazások csoportosítása, a feltételes utasítások használata, a műveletek eredményének vizsgálata az állapottér módszerrel és közvetlen adatvizsgálattal, az elágazási
SzA19. Az elágazások vizsgálata (Az elágazások csoportosítása, a feltételes utasítások használata, a műveletek eredményének vizsgálata az állapottér módszerrel és közvetlen adatvizsgálattal, az elágazási
Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd.
 1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
1 2 3 Ismétlés: Moore törvény. Tranzisztorok mérőszáma: n*százmillió, n*milliárd. 4 5 Moore törvényhez érdekesség: a várakozásokhoz képest folyamatosan alulteljesített, ezért többször is újra lett fogalmazva
Számítógépek felépítése
 Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
Számítógépek felépítése Emil Vatai 2014-2015 Emil Vatai Számítógépek felépítése 2014-2015 1 / 14 Outline 1 Alap fogalmak Bit, Byte, Word 2 Számítógép részei A processzor részei Processzor architektúrák
5-6. ea Created by mrjrm & Pogácsa, frissítette: Félix
 2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
2. Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra. Szorzás esetén karakterisztika összeadódik, mantissza összeszorzódik.
Számítógépek felépítése, alapfogalmak
 2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd, Krankovits Melinda SZE MTK MSZT kmelinda@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? 2 Nem reprezentatív felmérés
2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd, Krankovits Melinda SZE MTK MSZT kmelinda@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? 2 Nem reprezentatív felmérés
Architektúra, cache. Mirıl lesz szó? Mi a probléma? Teljesítmény. Cache elve. Megoldás. Egy rövid idıintervallum alatt a memóriahivatkozások a teljes
 Architektúra, cache irıl lesz szó? Alapfogalmak Adat cache tervezési terének alapkomponensei Koschek Vilmos Fejlıdés vkoschek@vonalkodhu Teljesítmény Teljesítmény növelése Technológia Architektúra (mem)
Architektúra, cache irıl lesz szó? Alapfogalmak Adat cache tervezési terének alapkomponensei Koschek Vilmos Fejlıdés vkoschek@vonalkodhu Teljesítmény Teljesítmény növelése Technológia Architektúra (mem)
Memóriák - tárak. Memória. Kapacitás Ár. Sebesség. Háttértár. (felejtő) (nem felejtő)
 (nem felejtő)") Memóriák (felejtő) Memória Kapacitás Ár Sebesség Memóriák - tárak Háttértár (nem felejtő) Memória Vezérlő egység Központi memória Aritmetikai Logikai Egység (ALU) Regiszterek Programok Adatok Ez nélkül
Memóriák (felejtő) Memória Kapacitás Ár Sebesség Memóriák - tárak Háttértár (nem felejtő) Memória Vezérlő egység Központi memória Aritmetikai Logikai Egység (ALU) Regiszterek Programok Adatok Ez nélkül
Hardver Ismeretek IA32 -> IA64
 Hardver Ismeretek IA32 -> IA64 Problémák az IA-32-vel Bonyolult architektúra CISC ISA (RISC jobb a párhuzamos feldolgozás szempontjából) Változó utasításhossz és forma nehéz dekódolni és párhuzamosítani
Hardver Ismeretek IA32 -> IA64 Problémák az IA-32-vel Bonyolult architektúra CISC ISA (RISC jobb a párhuzamos feldolgozás szempontjából) Változó utasításhossz és forma nehéz dekódolni és párhuzamosítani
Hibrid előadás: az ea másik felében a Morgen Stanley munkatársa kiegészítéseket fog hozzáfűzni a témához. Hagyományos és szerverrendszerek.
 Hibrid előadás: az ea másik felében a Morgen Stanley munkatársa kiegészítéseket fog hozzáfűzni a témához. Hagyományos és szerverrendszerek. 1 2 3 2000 őszén bejelentés: Netburst architektúra meghírdetése:
Hibrid előadás: az ea másik felében a Morgen Stanley munkatársa kiegészítéseket fog hozzáfűzni a témához. Hagyományos és szerverrendszerek. 1 2 3 2000 őszén bejelentés: Netburst architektúra meghírdetése:
Számítógép architektúrák. A mai témák. A teljesítmény fokozás. A processzor teljesítmény növelése
 Számítógép architektúrák A processzor teljesítmény növelése A mai témák CISC és RISC Párhuzamosságok Utasítás szintű párhuzamosságok Futószalag feldolgozás Többszörözés (szuperskalaritás) A függőségek
Számítógép architektúrák A processzor teljesítmény növelése A mai témák CISC és RISC Párhuzamosságok Utasítás szintű párhuzamosságok Futószalag feldolgozás Többszörözés (szuperskalaritás) A függőségek
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre
 GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
GPGPU: Általános célú grafikus processzorok cgpu: computational GPU GPGPU = cgpu Adatpárhuzamos gyorsító: dedikált eszköz, ami eleve csak erre szolgál. Nagyobb memória+grafika nélkül (nincs kijelzőre kimenet)
A mai témák. Számítógép architektúrák. CISC és RISC. A teljesítmény fokozás. További előnyök. A RISC gondolat
 A mai témák Számítógép architektúrák A processzor teljesítmény növelése CISC és RISC Párhuzamosságok Utasítás szintű párhuzamosságok Futószalag feldolgozás Többszörözés (szuperskalaritás) A függőségek
A mai témák Számítógép architektúrák A processzor teljesítmény növelése CISC és RISC Párhuzamosságok Utasítás szintű párhuzamosságok Futószalag feldolgozás Többszörözés (szuperskalaritás) A függőségek
Digitális rendszerek. Digitális logika szintje
 Digitális rendszerek Digitális logika szintje CPU lapkák Mai modern CPU-k egy lapkán helyezkednek el Kapcsolat a külvilággal: kivezetéseken (lábak) keresztül Cím, adat és vezérlőjelek, ill. sínek (buszok)
Digitális rendszerek Digitális logika szintje CPU lapkák Mai modern CPU-k egy lapkán helyezkednek el Kapcsolat a külvilággal: kivezetéseken (lábak) keresztül Cím, adat és vezérlőjelek, ill. sínek (buszok)
elektronikus adattárolást memóriacím
 MEMÓRIA Feladata A memória elektronikus adattárolást valósít meg. A számítógép csak olyan műveletek elvégzésére és csak olyan adatok feldolgozására képes, melyek a memóriájában vannak. Az információ tárolása
MEMÓRIA Feladata A memória elektronikus adattárolást valósít meg. A számítógép csak olyan műveletek elvégzésére és csak olyan adatok feldolgozására képes, melyek a memóriájában vannak. Az információ tárolása
Processzor (CPU - Central Processing Unit)
") Készíts saját kódolású WEBOLDALT az alábbi ismeretanyag felhasználásával! A lap alján lábjegyzetben hivatkozz a fenti oldalra! Processzor (CPU - Central Processing Unit) A központi feldolgozó egység a
Készíts saját kódolású WEBOLDALT az alábbi ismeretanyag felhasználásával! A lap alján lábjegyzetben hivatkozz a fenti oldalra! Processzor (CPU - Central Processing Unit) A központi feldolgozó egység a
Bepillantás a gépházba
 Bepillantás a gépházba Neumann-elvű számítógépek főbb egységei A részek feladatai: Központi egység: Feladata a számítógép vezérlése, és a számítások elvégzése. Operatív memória: A számítógép bekapcsolt
Bepillantás a gépházba Neumann-elvű számítógépek főbb egységei A részek feladatai: Központi egység: Feladata a számítógép vezérlése, és a számítások elvégzése. Operatív memória: A számítógép bekapcsolt
Operandus típusok Bevezetés: Az utasítás-feldolgozás menete
 Operandus típusok Bevezetés: Az utasítás-feldolgozás menete Egy gépi kódú utasítás általános formája: MK Címrész MK = műveleti kód Mit? Mivel? Az utasítás-feldolgozás általános folyamatábrája: Megszakítás?
Operandus típusok Bevezetés: Az utasítás-feldolgozás menete Egy gépi kódú utasítás általános formája: MK Címrész MK = műveleti kód Mit? Mivel? Az utasítás-feldolgozás általános folyamatábrája: Megszakítás?
3. Az elektronikus számítógépek fejlődése napjainkig 1
 2. Az elektronikus számítógépek fejlődése napjainkig Vázold fel az elektronikus eszközök fejlődését napjainkig! Részletesen ismertesd az egyes a számítógép generációk technikai újdonságait és jellemző
2. Az elektronikus számítógépek fejlődése napjainkig Vázold fel az elektronikus eszközök fejlődését napjainkig! Részletesen ismertesd az egyes a számítógép generációk technikai újdonságait és jellemző
Számítógép Architektúrák
 Az utasítás-pipeline szélesítése Horváth Gábor 2015. április 23. Budapest docens BME Hálózati Rendszerek és Szolgáltatások Tsz. ghorvath@hit.bme.hu Aktuális 2. ZH jövő csütörtök Memória technológiák, virtuális
Az utasítás-pipeline szélesítése Horváth Gábor 2015. április 23. Budapest docens BME Hálózati Rendszerek és Szolgáltatások Tsz. ghorvath@hit.bme.hu Aktuális 2. ZH jövő csütörtök Memória technológiák, virtuális
Számítógép felépítése
 Alaplap, processzor Számítógép felépítése Az alaplap A számítógép teljesítményét alapvetően a CPU és belső busz sebessége (a belső kommunikáció sebessége), a memória mérete és típusa, a merevlemez sebessége
Alaplap, processzor Számítógép felépítése Az alaplap A számítógép teljesítményét alapvetően a CPU és belső busz sebessége (a belső kommunikáció sebessége), a memória mérete és típusa, a merevlemez sebessége
8. Fejezet Processzor (CPU) és memória: tervezés, implementáció, modern megoldások
 és memória: tervezés, implementáció, modern megoldások") 8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
Alaplap. Az alaplapról. Néhány processzorfoglalat. Slot. < Hardver
 1/11 < Hardver Szerző: Sallai András Copyright Sallai András, 2014, 2015, 2017 Licenc: GNU Free Documentation License 1.3 Web: http://szit.hu Az alaplapról A számítógép alapja, ez fogja össze az egyes
1/11 < Hardver Szerző: Sallai András Copyright Sallai András, 2014, 2015, 2017 Licenc: GNU Free Documentation License 1.3 Web: http://szit.hu Az alaplapról A számítógép alapja, ez fogja össze az egyes
Összeadás BCD számokkal
 Összeadás BCD számokkal Ugyanúgy adjuk össze a BCD számokat is, mint a binárisakat, csak - fel kell ismernünk az érvénytelen tetrádokat és - ezeknél korrekciót kell végrehajtani. A, Az érvénytelen tetrádok
Összeadás BCD számokkal Ugyanúgy adjuk össze a BCD számokat is, mint a binárisakat, csak - fel kell ismernünk az érvénytelen tetrádokat és - ezeknél korrekciót kell végrehajtani. A, Az érvénytelen tetrádok
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely
 Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
Készítette: Trosztel Mátyás Konzulens: Hajós Gergely Monte Carlo Markov Chain MCMC során egy megfelelően konstruált Markov-lánc segítségével mintákat generálunk. Ezek eloszlása követi a céleloszlást. A
Az informatika fejlõdéstörténete
 Az informatika fejlõdéstörténete Elektronikus gépek A háború alatt a haditechnika fejlõdésével felmerült az igény a számítások precizitásának növelésére. Több gépet is kifejlesztettek, de ezek egyike sem
Az informatika fejlõdéstörténete Elektronikus gépek A háború alatt a haditechnika fejlõdésével felmerült az igény a számítások precizitásának növelésére. Több gépet is kifejlesztettek, de ezek egyike sem
2. Számítógépek működési elve. Bevezetés az informatikába. Vezérlés elve. Külső programvezérlés... Memória. Belső programvezérlés
 . Számítógépek működési elve Bevezetés az informatikába. előadás Dudásné Nagy Marianna Az általánosan használt számítógépek a belső programvezérlés elvén működnek Külső programvezérlés... Vezérlés elve
. Számítógépek működési elve Bevezetés az informatikába. előadás Dudásné Nagy Marianna Az általánosan használt számítógépek a belső programvezérlés elvén működnek Külső programvezérlés... Vezérlés elve
Számítógépek felépítése, alapfogalmak
 2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd SZE MTK MSZT lovas.szilard@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? Nem reprezentatív felmérés kinek van
2. előadás Számítógépek felépítése, alapfogalmak Lovas Szilárd SZE MTK MSZT lovas.szilard@sze.hu B607 szoba Nem reprezentatív felmérés kinek van ilyen számítógépe? Nem reprezentatív felmérés kinek van
8. Fejezet Processzor (CPU) és memória: tervezés, implementáció, modern megoldások
 és memória: tervezés, implementáció, modern megoldások") 8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
8. Fejezet Processzor (CPU) és memória: The Architecture of Computer Hardware and Systems Software: An Information Technology Approach 3rd Edition, Irv Englander John Wiley and Sons 2003 Wilson Wong, Bentley
Ismerkedjünk tovább a számítógéppel. Alaplap és a processzeor
 Ismerkedjünk tovább a számítógéppel Alaplap és a processzeor Neumann-elvű számítógépek főbb egységei A részek feladatai: Központi egység: Feladata a számítógép vezérlése, és a számítások elvégzése. Operatív
Ismerkedjünk tovább a számítógéppel Alaplap és a processzeor Neumann-elvű számítógépek főbb egységei A részek feladatai: Központi egység: Feladata a számítógép vezérlése, és a számítások elvégzése. Operatív
A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem)
") 65-67 A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem) Két fő része: a vezérlőegység, ami a memóriában tárolt program dekódolását és végrehajtását végzi, az
65-67 A processzor hajtja végre a műveleteket. összeadás, szorzás, logikai műveletek (és, vagy, nem) Két fő része: a vezérlőegység, ami a memóriában tárolt program dekódolását és végrehajtását végzi, az
Számítógép Architektúrák
 Számítógép Architektúrák Utasításkészlet architektúrák 2015. április 11. Budapest Horváth Gábor docens BME Hálózati Rendszerek és Szolgáltatások Tsz. ghorvath@hit.bme.hu Számítógép Architektúrák Horváth
Számítógép Architektúrák Utasításkészlet architektúrák 2015. április 11. Budapest Horváth Gábor docens BME Hálózati Rendszerek és Szolgáltatások Tsz. ghorvath@hit.bme.hu Számítógép Architektúrák Horváth
ELŐADÁS 2016-01-05 SZÁMÍTÓGÉP MŰKÖDÉSE FIZIKA ÉS INFORMATIKA
 ELŐADÁS 2016-01-05 SZÁMÍTÓGÉP MŰKÖDÉSE FIZIKA ÉS INFORMATIKA A PC FIZIKAI KIÉPÍTÉSÉNEK ALAPELEMEI Chip (lapka) Mikroprocesszor (CPU) Integrált áramköri lapok: alaplap, bővítőkártyák SZÁMÍTÓGÉP FELÉPÍTÉSE
ELŐADÁS 2016-01-05 SZÁMÍTÓGÉP MŰKÖDÉSE FIZIKA ÉS INFORMATIKA A PC FIZIKAI KIÉPÍTÉSÉNEK ALAPELEMEI Chip (lapka) Mikroprocesszor (CPU) Integrált áramköri lapok: alaplap, bővítőkártyák SZÁMÍTÓGÉP FELÉPÍTÉSE
MEMÓRIA TECHNOLÓGIÁK. Számítógép-architektúrák 4. gyakorlat. Dr. Lencse Gábor. tudományos főmunkatárs BME Híradástechnikai Tanszék lencse@hit.bme.
 MEMÓRIA TECHNOLÓGIÁK Számítógép-architektúrák 4. gyakorlat Dr. Lencse Gábor 2011. október 3., Budapest tudományos főmunkatárs BME Híradástechnikai Tanszék lencse@hit.bme.hu Tartalom Emlékeztető: mit kell
MEMÓRIA TECHNOLÓGIÁK Számítógép-architektúrák 4. gyakorlat Dr. Lencse Gábor 2011. október 3., Budapest tudományos főmunkatárs BME Híradástechnikai Tanszék lencse@hit.bme.hu Tartalom Emlékeztető: mit kell
Számítógépes alapismeretek
 Számítógépes alapismeretek 1. előadás Dr. Istenes Zoltán Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék Programtervező Informatikus BSc 2008 / Budapest
Számítógépes alapismeretek 1. előadás Dr. Istenes Zoltán Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék Programtervező Informatikus BSc 2008 / Budapest
Magas szintű optimalizálás
 Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
Magas szintű optimalizálás Soros kód párhuzamosítása Mennyi a várható teljesítmény növekedés? Erős skálázódás (Amdahl törvény) Mennyire lineáris a skálázódás a párhuzamosítás növelésével? S 1 P 1 P N GPGPU
A számítógép felépítése A processzor és csatlakoztatása
 Máté István A számítógép felépítése A processzor és csatlakoztatása A követelménymodul megnevezése: Számítógép összeszerelése A követelménymodul száma: 1173-06 A tartalomelem azonosító száma és célcsoportja:
Máté István A számítógép felépítése A processzor és csatlakoztatása A követelménymodul megnevezése: Számítógép összeszerelése A követelménymodul száma: 1173-06 A tartalomelem azonosító száma és célcsoportja:
Dr. Illés Zoltán zoltan.illes@elte.hu
 Dr. Illés Zoltán zoltan.illes@elte.hu Operációs rendszerek kialakulása Op. Rendszer fogalmak, struktúrák Fájlok, könyvtárak, fájlrendszerek Folyamatok Folyamatok kommunikációja Kritikus szekciók, szemaforok.
Dr. Illés Zoltán zoltan.illes@elte.hu Operációs rendszerek kialakulása Op. Rendszer fogalmak, struktúrák Fájlok, könyvtárak, fájlrendszerek Folyamatok Folyamatok kommunikációja Kritikus szekciók, szemaforok.
SZÁMÍTÓGÉP ARCHITEKTÚRÁK
 SZÁMÍTÓGÉP ARCHITEKTÚRÁK Soron kívüli utasítás-végrehajtás Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-04-24 1 KÜLÖNBÖZŐ
SZÁMÍTÓGÉP ARCHITEKTÚRÁK Soron kívüli utasítás-végrehajtás Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-04-24 1 KÜLÖNBÖZŐ
Csoportos üzenetszórás optimalizálása klaszter rendszerekben
 Csoportos üzenetszórás optimalizálása klaszter rendszerekben Készítette: Juhász Sándor Csikvári András Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Automatizálási
Csoportos üzenetszórás optimalizálása klaszter rendszerekben Készítette: Juhász Sándor Csikvári András Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Automatizálási
Mikroprocesszorok (Microprocessors, CPU-s)
") Mikroprocesszorok (Microprocessors, CPU-s) 1971-2011 Források: CHIP magazin index.hu wikipedia internetes források 1 Intel Adatbusz 4 bit 16 bit 16 bit 32 bit 32 bit 32 bit 32 bit 32 bit 32 bit 32 bit
Mikroprocesszorok (Microprocessors, CPU-s) 1971-2011 Források: CHIP magazin index.hu wikipedia internetes források 1 Intel Adatbusz 4 bit 16 bit 16 bit 32 bit 32 bit 32 bit 32 bit 32 bit 32 bit 32 bit
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Számítógép architektúra
 Budapesti Műszaki Főiskola Regionális Oktatási és Innovációs Központ Székesfehérvár Számítógép architektúra Dr. Seebauer Márta főiskolai tanár seebauer.marta@roik.bmf.hu Irodalmi források Cserny L.: Számítógépek
Budapesti Műszaki Főiskola Regionális Oktatási és Innovációs Központ Székesfehérvár Számítógép architektúra Dr. Seebauer Márta főiskolai tanár seebauer.marta@roik.bmf.hu Irodalmi források Cserny L.: Számítógépek
Multimédia hardver szabványok
 Multimédia hardver szabványok HEFOP 3.5.1 Korszerű felnőttképzési módszerek kifejlesztése és alkalmazása EMIR azonosító: HEFOP-3.5.1-K-2004-10-0001/2.0 Tananyagfejlesztő: Máté István Lektorálta: Brückler
Multimédia hardver szabványok HEFOP 3.5.1 Korszerű felnőttképzési módszerek kifejlesztése és alkalmazása EMIR azonosító: HEFOP-3.5.1-K-2004-10-0001/2.0 Tananyagfejlesztő: Máté István Lektorálta: Brückler
1. Generáció( ):
:") Generációk: 1. Generáció(1943-1958): Az elektroncsövet 1904-ben találták fel. Felfedezték azt is, hogy nemcsak erősítőként, hanem kapcsolóként is alkalmazható. A csövek drágák, megbízhatatlanok és rövid
Generációk: 1. Generáció(1943-1958): Az elektroncsövet 1904-ben találták fel. Felfedezték azt is, hogy nemcsak erősítőként, hanem kapcsolóként is alkalmazható. A csövek drágák, megbízhatatlanok és rövid
Dr. Oniga István DIGITÁLIS TECHNIKA 8
 Dr. Oniga István DIGITÁLIS TECHNIA 8 Szekvenciális (sorrendi) hálózatok Szekvenciális hálózatok fogalma Tárolók RS tárolók tárolók T és D típusú tárolók Számlálók Szinkron számlálók Aszinkron számlálók
Dr. Oniga István DIGITÁLIS TECHNIA 8 Szekvenciális (sorrendi) hálózatok Szekvenciális hálózatok fogalma Tárolók RS tárolók tárolók T és D típusú tárolók Számlálók Szinkron számlálók Aszinkron számlálók
Számítógép architektúrák. A processzor teljesítmény növelése
 Számítógép architektúrák A processzor teljesítmény növelése A mai témák CISC és RISC Párhuzamosságok Utasítás szintű párhuzamosságok Futószalag feldolgozás Többszörözés (szuperskalaritás) A függőségek
Számítógép architektúrák A processzor teljesítmény növelése A mai témák CISC és RISC Párhuzamosságok Utasítás szintű párhuzamosságok Futószalag feldolgozás Többszörözés (szuperskalaritás) A függőségek
6. óra Mi van a számítógépházban? A számítógép: elektronikus berendezés. Tárolja az adatokat, feldolgozza és az adatok ki és bevitelére is képes.
 6. óra Mi van a számítógépházban? A számítógép: elektronikus berendezés. Tárolja az adatokat, feldolgozza és az adatok ki és bevitelére is képes. Neumann elv: Külön vezérlő és végrehajtó egység van Kettes
6. óra Mi van a számítógépházban? A számítógép: elektronikus berendezés. Tárolja az adatokat, feldolgozza és az adatok ki és bevitelére is képes. Neumann elv: Külön vezérlő és végrehajtó egység van Kettes
Alaplap. Slot. Bővítőkártyák. Csatolható tárolók. Portok. < Hardver
 2016/07/02 07:26 < Hardver Szerző: Sallai András Copyright Sallai András, 2014, 2015 Licenc: GNU Free Documentation License 1.3 Web: http://szit.hu Slot Az alaplap bővítőhelyei. ISA VESA-LB PCI AGP PCIE
2016/07/02 07:26 < Hardver Szerző: Sallai András Copyright Sallai András, 2014, 2015 Licenc: GNU Free Documentation License 1.3 Web: http://szit.hu Slot Az alaplap bővítőhelyei. ISA VESA-LB PCI AGP PCIE
Párhuzamos programozási platformok
 Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Párhuzamos programozási platformok Parallel számítógép részei Hardver Több processzor Több memória Kapcsolatot biztosító hálózat Rendszer szoftver Párhuzamos operációs rendszer Konkurenciát biztosító programozási
Bevezetés. Többszálú, többmagos architektúrák és programozásuk Óbudai Egyetem, Neumann János Informatikai Kar
 Többszálú, többmagos architektúrák és programozásuk Óbudai Egyetem, Neumann János Informatikai Kar Bevezetés Motiváció Soros és párhuzamos végrehajtás, soros és párhuzamos programozás Miért? Alapfogalmak
Többszálú, többmagos architektúrák és programozásuk Óbudai Egyetem, Neumann János Informatikai Kar Bevezetés Motiváció Soros és párhuzamos végrehajtás, soros és párhuzamos programozás Miért? Alapfogalmak
Nagy adattömbökkel végzett FORRÓ TI BOR tudományos számítások lehetőségei. kisszámítógépes rendszerekben. Kutató Intézet
 Nagy adattömbökkel végzett FORRÓ TI BOR tudományos számítások lehetőségei Kutató Intézet kisszámítógépes rendszerekben Tudományos számításokban gyakran nagy mennyiségű aritmetikai művelet elvégzésére van
Nagy adattömbökkel végzett FORRÓ TI BOR tudományos számítások lehetőségei Kutató Intézet kisszámítógépes rendszerekben Tudományos számításokban gyakran nagy mennyiségű aritmetikai művelet elvégzésére van
Négyprocesszoros közvetlen csatolású szerverek architektúrája:
 SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
SzA49. AMD többmagos 2 és 4 processzoros szerverarchitektúrái (a közvetlenül csatolt architektúra főbb jegyei, négyprocesszoros közvetlen csatolású szerverek architektúrája, többmagos szerverprocesszorok
Számítógép architektúrák. Bevezetés
 Számítógép architektúrák Bevezetés Mechanikus számológépek Blaise Pascal (1642) Gottfried Willhelm von Leibniz báró (~1676) Összeadás, kivonás Mai négyműveletes zsebszámológépek mechanikus őse Charles
Számítógép architektúrák Bevezetés Mechanikus számológépek Blaise Pascal (1642) Gottfried Willhelm von Leibniz báró (~1676) Összeadás, kivonás Mai négyműveletes zsebszámológépek mechanikus őse Charles
AMD PROCESSZOROK KÉSZÍTETTE: NAGY ZOLTÁN MÁRK EHA KÓD: NAZKABF.SZE I. ÉVES PROGRAMTERVEZŐ-INFORMATIKUS,BSC
 AMD PROCESSZOROK KÉSZÍTETTE: NAGY ZOLTÁN MÁRK EHA KÓD: NAZKABF.SZE I. ÉVES PROGRAMTERVEZŐ-INFORMATIKUS,BSC Az Advanced Micro Devices, Inc. (AMD) egy félvezetőgyártó vállalat, központja a kaliforniai Sunnyvale-ben
AMD PROCESSZOROK KÉSZÍTETTE: NAGY ZOLTÁN MÁRK EHA KÓD: NAZKABF.SZE I. ÉVES PROGRAMTERVEZŐ-INFORMATIKUS,BSC Az Advanced Micro Devices, Inc. (AMD) egy félvezetőgyártó vállalat, központja a kaliforniai Sunnyvale-ben
statikus RAM ( tároló eleme: flip-flop ),
,") 1 Írható/olvasható memóriák (RAM) Az írható/olvasható memóriák angol rövidítése ( RAM Random Acces Memories közvetlen hozzáférésű memóriák) csak a cím szerinti elérés módjára utal, de ma már ehhez az elnevezéshez
1 Írható/olvasható memóriák (RAM) Az írható/olvasható memóriák angol rövidítése ( RAM Random Acces Memories közvetlen hozzáférésű memóriák) csak a cím szerinti elérés módjára utal, de ma már ehhez az elnevezéshez
Máté: Számítógép architektúrák
 Az GOTO offset utasítás. P relatív: P értékéhez hozzá kell adni a két bájtos, előjeles offset értékét. Mic 1 program: Main1 P = P + 1; fetch; goto() goto1 OP=P 1 // Main1 nél : P=P+1 1. bájt goto P=P+1;
Az GOTO offset utasítás. P relatív: P értékéhez hozzá kell adni a két bájtos, előjeles offset értékét. Mic 1 program: Main1 P = P + 1; fetch; goto() goto1 OP=P 1 // Main1 nél : P=P+1 1. bájt goto P=P+1;
Számítógép fajtái. 1) személyi számítógép ( PC, Apple Macintosh) - asztali (desktop) - hordozható (laptop, notebook, palmtop)
 személyi számítógép ( PC, Apple Macintosh) - asztali (desktop) - hordozható (laptop, notebook, palmtop)") Számítógép Számítógépnek nevezzük azt a műszakilag megalkotott rendszert, amely adatok bevitelére, azok tárolására, feldolgozására, a gépen tárolt programok működtetésére alkalmas emberi beavatkozás nélkül.
Számítógép Számítógépnek nevezzük azt a műszakilag megalkotott rendszert, amely adatok bevitelére, azok tárolására, feldolgozására, a gépen tárolt programok működtetésére alkalmas emberi beavatkozás nélkül.
Alaplap: közös kapcsolódási felület a számítógép részegységei számára
 Alaplap: közös kapcsolódási felület a számítógép részegységei számára AGP-csatlakozó alaplapi vezérlő chip PCI-csatlakozók rögzítőkeret a hűtőhöz FDD-csatlakozó tápegységcsatlakozó S.ATAcsatlakozók P.ATAcsatlakozók
Alaplap: közös kapcsolódási felület a számítógép részegységei számára AGP-csatlakozó alaplapi vezérlő chip PCI-csatlakozók rögzítőkeret a hűtőhöz FDD-csatlakozó tápegységcsatlakozó S.ATAcsatlakozók P.ATAcsatlakozók
Digitális rendszerek. Mikroarchitektúra szintje
 Digitális rendszerek Mikroarchitektúra szintje Mikroarchitektúra Jellemzők A digitális logika feletti szint Feladata az utasításrendszer-architektúra szint megalapozása, illetve megvalósítása Példa Egy
Digitális rendszerek Mikroarchitektúra szintje Mikroarchitektúra Jellemzők A digitális logika feletti szint Feladata az utasításrendszer-architektúra szint megalapozása, illetve megvalósítása Példa Egy
Számítógép architektúrák Korszerű architektúrák Mai program Pentium P6 processzor (esettanulmány) Párhuzamosítások a CPU-n kívül
 Párhuzamosítások a CPU-n kívül") Számítógép architektúrák Korszerű architektúrák Mai program Pentium P6 processzor (esettanulmány) Párhuzamosítások a CPU-n kívül Vadász, 2005. 2 Az Intel P6 család IA instrukciókat feldolgozó (x86 és Katmai
Számítógép architektúrák Korszerű architektúrák Mai program Pentium P6 processzor (esettanulmány) Párhuzamosítások a CPU-n kívül Vadász, 2005. 2 Az Intel P6 család IA instrukciókat feldolgozó (x86 és Katmai
Máté: Számítógép architektúrák
 Elágazás jövendölés ok gép megjövendöli, hogy egy ugrást végre kell hajtani vagy sem. Egy triviális jóslás: a visszafelé irányulót végre kell hajtani (ilyen van a ciklusok végén), az előre irányulót nem
Elágazás jövendölés ok gép megjövendöli, hogy egy ugrást végre kell hajtani vagy sem. Egy triviális jóslás: a visszafelé irányulót végre kell hajtani (ilyen van a ciklusok végén), az előre irányulót nem
Bevezetés az informatikába
 Bevezetés az informatikába 3. előadás Dr. Istenes Zoltán Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék Matematikus BSc - I. félév / 2008 / Budapest Dr.
Bevezetés az informatikába 3. előadás Dr. Istenes Zoltán Eötvös Loránd Tudományegyetem Informatikai Kar Programozáselmélet és Szoftvertechnológiai Tanszék Matematikus BSc - I. félév / 2008 / Budapest Dr.
11.3.7 Feladatlap: Számítógép összetevők keresése
 11.3.7 Feladatlap: Számítógép összetevők keresése Bevezetés Nyomtasd ki a feladatlapot és old meg a feladatokat. Ezen feladatlap megoldásához szükséged lesz az Internetre, katalógusokra vagy egy helyi
11.3.7 Feladatlap: Számítógép összetevők keresése Bevezetés Nyomtasd ki a feladatlapot és old meg a feladatokat. Ezen feladatlap megoldásához szükséged lesz az Internetre, katalógusokra vagy egy helyi
Számítógép Architektúrák
 Soron kívüli utasítás-végrehajtás Horváth Gábor 2016. április 27. Budapest docens BME Hálózati Rendszerek és Szolgáltatások Tsz. ghorvath@hit.bme.hu Különböző késleltetésű műveletek Láttuk, hogy a lebegőpontos
Soron kívüli utasítás-végrehajtás Horváth Gábor 2016. április 27. Budapest docens BME Hálózati Rendszerek és Szolgáltatások Tsz. ghorvath@hit.bme.hu Különböző késleltetésű műveletek Láttuk, hogy a lebegőpontos
Mikrorendszerek tervezése
 BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Mikrorendszerek tervezése Beágyazott rendszerek Fehér Béla Raikovich Tamás
BUDAPESTI MŰSZAKI ÉS GAZDASÁGTUDOMÁNYI EGYETEM VILLAMOSMÉRNÖKI ÉS INFORMATIKAI KAR MÉRÉSTECHNIKA ÉS INFORMÁCIÓS RENDSZEREK TANSZÉK Mikrorendszerek tervezése Beágyazott rendszerek Fehér Béla Raikovich Tamás
Számítógép Architektúrák
 Multiprocesszoros rendszerek Horváth Gábor 2015. május 19. Budapest docens BME Híradástechnikai Tanszék ghorvath@hit.bme.hu Párhuzamosság formái A párhuzamosság milyen formáit ismerjük? Bit szintű párhuzamosság
Multiprocesszoros rendszerek Horváth Gábor 2015. május 19. Budapest docens BME Híradástechnikai Tanszék ghorvath@hit.bme.hu Párhuzamosság formái A párhuzamosság milyen formáit ismerjük? Bit szintű párhuzamosság
Számítógép Architektúrák I-II-III.
 Kidolgozott államvizsgatételek Számítógép Architektúrák I-II-III. tárgyakhoz 2010. június A sikeres államvizsgához kizárólag ennek a dokumentumnak az ismerete nem elégséges, a témaköröket a Számítógép
Kidolgozott államvizsgatételek Számítógép Architektúrák I-II-III. tárgyakhoz 2010. június A sikeres államvizsgához kizárólag ennek a dokumentumnak az ismerete nem elégséges, a témaköröket a Számítógép
Nyíregyházi Egyetem Matematika és Informatika Intézete. Input/Output
 1 Input/Output 1. I/O műveletek hardveres háttere 2. I/O műveletek szoftveres háttere 3. Diszkek (lemezek) ------------------------------------------------ 4. Órák, Szöveges terminálok 5. GUI - Graphical
1 Input/Output 1. I/O műveletek hardveres háttere 2. I/O műveletek szoftveres háttere 3. Diszkek (lemezek) ------------------------------------------------ 4. Órák, Szöveges terminálok 5. GUI - Graphical
SZORGALMI FELADAT. 17. Oktober
 SZORGALMI FELADAT F2. Tervezzen egy statikus aszinkron SRAM memóriainterfész áramkört a kártyán található 128Ki*8 bites memóriához! Az áramkör legyen képes az írási és olvasási műveletek végrehajtására
SZORGALMI FELADAT F2. Tervezzen egy statikus aszinkron SRAM memóriainterfész áramkört a kártyán található 128Ki*8 bites memóriához! Az áramkör legyen képes az írási és olvasási műveletek végrehajtására
3DMark 06 CPU. Magok / Szálak 8MB / MB /
 1 / 21 2016.04.01. 14:48 13 nov. Processzor Modellszám L3 Cache TDP (Watt) MHz - Turbo Magok / Szálak 3DMark 06 CPU Cinebench R15 SingleCPU 64bit Cinebench R15 MultiCPU 64bit x264 Pass 1 x264 Pass 2 i7-4940mx
1 / 21 2016.04.01. 14:48 13 nov. Processzor Modellszám L3 Cache TDP (Watt) MHz - Turbo Magok / Szálak 3DMark 06 CPU Cinebench R15 SingleCPU 64bit Cinebench R15 MultiCPU 64bit x264 Pass 1 x264 Pass 2 i7-4940mx
Nagy Gergely április 4.
 Mikrovezérlők Nagy Gergely BME EET 2012. április 4. ebook ready 1 Bevezetés Áttekintés Az elektronikai tervezés eszközei Mikroprocesszorok 2 A mikrovezérlők 3 Főbb gyártók Áttekintés A mikrovezérlők az
Mikrovezérlők Nagy Gergely BME EET 2012. április 4. ebook ready 1 Bevezetés Áttekintés Az elektronikai tervezés eszközei Mikroprocesszorok 2 A mikrovezérlők 3 Főbb gyártók Áttekintés A mikrovezérlők az
SZÁMÍTÓGÉPES ARCHITEKTÚRÁK
 Misák Sándor SZÁMÍTÓGÉPES ARCHITEKTÚRÁK Nanoelektronikai és Nanotechnológiai Részleg DE TTK v.0.1 (2007.02.13.) 2. előadás A STRUKTURÁLT SZÁMÍTÓGÉP-FELÉPÍTÉS 2. előadás 1. Nyelvek, szintek és virtuális
Misák Sándor SZÁMÍTÓGÉPES ARCHITEKTÚRÁK Nanoelektronikai és Nanotechnológiai Részleg DE TTK v.0.1 (2007.02.13.) 2. előadás A STRUKTURÁLT SZÁMÍTÓGÉP-FELÉPÍTÉS 2. előadás 1. Nyelvek, szintek és virtuális
Mi van a számítógépben? Hardver
 Mi van a számítógépben? Hardver A Hardver (angol nyelven: hardware) a számítógép azon alkatrészeit / részeit jelenti, amiket kézzel meg tudunk fogni. Ezen alkatrészek közül 5 fontos alkatésszel kell megismerkedni.
Mi van a számítógépben? Hardver A Hardver (angol nyelven: hardware) a számítógép azon alkatrészeit / részeit jelenti, amiket kézzel meg tudunk fogni. Ezen alkatrészek közül 5 fontos alkatésszel kell megismerkedni.
Grafikus csővezeték 1 / 44
 Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
Grafikus csővezeték 1 / 44 Grafikus csővezeték Vertex feldolgozás A vertexek egyenként a képernyő térbe vannak transzformálva Primitív feldolgozás A vertexek primitívekbe vannak szervezve Raszterizálás
A számítógép egységei
 A számítógép egységei A számítógépes rendszer két alapvető részből áll: Hardver (a fizikai eszközök összessége) Szoftver (a fizikai eszközöket működtető programok összessége) 1.) Hardver a) Alaplap: Kommunikációt
A számítógép egységei A számítógépes rendszer két alapvető részből áll: Hardver (a fizikai eszközök összessége) Szoftver (a fizikai eszközöket működtető programok összessége) 1.) Hardver a) Alaplap: Kommunikációt
Számítógép architektúrák. Korszerű architektúrák
 Számítógép architektúrák Korszerű architektúrák Mai program Pentium P6 processzor (esettanulmány) Párhuzamosítások a CPU-n kívül 2 Az Intel P6 család IA instrukciókat feldolgozó (x86, MMX, Katmai Iset),
Számítógép architektúrák Korszerű architektúrák Mai program Pentium P6 processzor (esettanulmány) Párhuzamosítások a CPU-n kívül 2 Az Intel P6 család IA instrukciókat feldolgozó (x86, MMX, Katmai Iset),
Ez egy program. De ki tudja végrehajtani?
 Császármorzsa Keverj össze 25 dkg grízt 1 mokkás kanál sóval, 4 evőkanál cukorral és egy csomag vaníliás cukorral! Adj hozzá két evőkanál olajat és két tojást, jól dolgozd el! Folyamatos keverés közben
Császármorzsa Keverj össze 25 dkg grízt 1 mokkás kanál sóval, 4 evőkanál cukorral és egy csomag vaníliás cukorral! Adj hozzá két evőkanál olajat és két tojást, jól dolgozd el! Folyamatos keverés közben
Hordozható számítógép, noteszgép szó szerint: ölbevehető. Síkkijelzős, telepes, hordozható számítógép. (Informatikai fogalomtár)
") Hordozható számítógép, noteszgép szó szerint: ölbevehető. Síkkijelzős, telepes, hordozható számítógép. (Informatikai fogalomtár) Az emberek mindig is késztetést éreztek arra, hogy az otthoni kikapcsolódás,
Hordozható számítógép, noteszgép szó szerint: ölbevehető. Síkkijelzős, telepes, hordozható számítógép. (Informatikai fogalomtár) Az emberek mindig is késztetést éreztek arra, hogy az otthoni kikapcsolódás,
SZÁMÍTÓGÉP ARCHITEKTÚRÁK
 SZÁMÍTÓGÉP ARCHITEKTÚRÁK Pipeline utasításfeldolgozás Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-04-24 1 UTASÍTÁSOK
SZÁMÍTÓGÉP ARCHITEKTÚRÁK Pipeline utasításfeldolgozás Horváth Gábor, Belső Zoltán BME Hálózati Rendszerek és Szolgáltatások Tanszék ghorvath@hit.bme.hu, belso@hit.bme.hu Budapest, 2018-04-24 1 UTASÍTÁSOK
Számítógép-rendszerek fontos jellemzői (Hardver és Szoftver):
:") B Motiváció B Motiváció Számítógép-rendszerek fontos jellemzői (Hardver és Szoftver): Helyesség Felhasználóbarátság Hatékonyság Modern számítógép-rendszerek: Egyértelmű hatékonyság (például hálózati hatékonyság)
B Motiváció B Motiváció Számítógép-rendszerek fontos jellemzői (Hardver és Szoftver): Helyesség Felhasználóbarátság Hatékonyság Modern számítógép-rendszerek: Egyértelmű hatékonyság (például hálózati hatékonyság)
Számítógép architektúrák II.
 Számítógép architektúrák II. 2009 Órai jegyzet (Dr. Broczkó Péter anyagához) AnNo és Broadcast jegyzeteinek frissített változata A jegyzet készítői az esetleges hibákért semmilyen felelősséget nem vállalnak,
Számítógép architektúrák II. 2009 Órai jegyzet (Dr. Broczkó Péter anyagához) AnNo és Broadcast jegyzeteinek frissített változata A jegyzet készítői az esetleges hibákért semmilyen felelősséget nem vállalnak,
Elvonatkoztatási szintek a digitális rendszertervezésben
 Budapest Műszaki és Gazdaságtudományi Egyetem Elvonatkoztatási szintek a digitális rendszertervezésben Elektronikus Eszközök Tanszéke eet.bme.hu Rendszerszintű tervezés BMEVIEEM314 Horváth Péter 2013 Rendszerszint
Budapest Műszaki és Gazdaságtudományi Egyetem Elvonatkoztatási szintek a digitális rendszertervezésben Elektronikus Eszközök Tanszéke eet.bme.hu Rendszerszintű tervezés BMEVIEEM314 Horváth Péter 2013 Rendszerszint
A tervfeladat sorszáma: 1 A tervfeladat címe: ALU egység 8 regiszterrel és 8 utasítással
 .. A tervfeladat sorszáma: 1 A ALU egység 8 regiszterrel és 8 utasítással Minimálisan az alábbi képességekkel rendelkezzen az ALU 8-bites operandusok Aritmetikai funkciók: összeadás, kivonás, shift, komparálás
.. A tervfeladat sorszáma: 1 A ALU egység 8 regiszterrel és 8 utasítással Minimálisan az alábbi képességekkel rendelkezzen az ALU 8-bites operandusok Aritmetikai funkciók: összeadás, kivonás, shift, komparálás
5. tétel. A számítógép sematikus felépítése. (Ábra, buszok, CPU, Memória, IT, DMA, Periféria vezérlő)
") 5. tétel 12a.05. A számítógép sematikus felépítése (Ábra, buszok, CPU, Memória, IT, DMA, Periféria vezérlő) Készítette: Bandur Ádám és Antal Dominik Tartalomjegyzék I. Neumann János ajánlása II. A számítógép
5. tétel 12a.05. A számítógép sematikus felépítése (Ábra, buszok, CPU, Memória, IT, DMA, Periféria vezérlő) Készítette: Bandur Ádám és Antal Dominik Tartalomjegyzék I. Neumann János ajánlása II. A számítógép
A számítógép fő részei
 Hardver ismeretek 1 A számítógép fő részei 1. A számítógéppel végzett munka folyamata: bevitel ==> tárolás ==> feldolgozás ==> kivitel 2. A számítógépet 3 fő részre bonthatjuk: központi egységre; perifériákra;
Hardver ismeretek 1 A számítógép fő részei 1. A számítógéppel végzett munka folyamata: bevitel ==> tárolás ==> feldolgozás ==> kivitel 2. A számítógépet 3 fő részre bonthatjuk: központi egységre; perifériákra;
A PC története. Informatika alapjai-9 Személyi számítógép (PC) 1/12. (Personal computer - From Wikipedia, the free encyclopedia)
 1/12. (Personal computer - From Wikipedia, the free encyclopedia)") Informatika alapjai-9 Személyi számítógép (PC) 1/12 (Personal computer - From Wikipedia, the free encyclopedia) A személyi számítógépet ára, mérete és képességei és a használatában kialakult kultúra teszik
Informatika alapjai-9 Személyi számítógép (PC) 1/12 (Personal computer - From Wikipedia, the free encyclopedia) A személyi számítógépet ára, mérete és képességei és a használatában kialakult kultúra teszik
Digitális rendszerek. Utasításarchitektúra szintje
 Digitális rendszerek Utasításarchitektúra szintje Utasításarchitektúra Jellemzők Mikroarchitektúra és az operációs rendszer közötti réteg Eredetileg ez jelent meg először Sokszor az assembly nyelvvel keverik
Digitális rendszerek Utasításarchitektúra szintje Utasításarchitektúra Jellemzők Mikroarchitektúra és az operációs rendszer közötti réteg Eredetileg ez jelent meg először Sokszor az assembly nyelvvel keverik
2017/12/16 21:33 1/7 Hardver alapok
 2017/12/16 21:33 1/7 Hardver alapok < Hardver Hardver alapok Szerző: Sallai András Copyright Sallai András, 2011, 2013, 2014 Licenc: GNU Free Documentation License 1.3 Web: http://szit.hu Bevezetés A számítógépet
2017/12/16 21:33 1/7 Hardver alapok < Hardver Hardver alapok Szerző: Sallai András Copyright Sallai András, 2011, 2013, 2014 Licenc: GNU Free Documentation License 1.3 Web: http://szit.hu Bevezetés A számítógépet
1. Milyen eszközöket használt az ősember a számoláshoz? ujjait, fadarabokat, kavicsokat
 1. Milyen eszközöket használt az ősember a számoláshoz? ujjait, fadarabokat, kavicsokat 2. Mit tudsz Blaise Pascalról? Ő készítette el az első szériában gyártott számológépet. 7 példányban készült el.
1. Milyen eszközöket használt az ősember a számoláshoz? ujjait, fadarabokat, kavicsokat 2. Mit tudsz Blaise Pascalról? Ő készítette el az első szériában gyártott számológépet. 7 példányban készült el.
Ikermaggal bıvített kimutatások
 Ikermaggal bıvített kimutatások Ideje egy új CPU összehasonlításnak, felhasználva az újonnan kidolgozott tesztrendszerünket. A leginkább említésre méltó kiegészítés természetesen az ikermagos processzorok
Ikermaggal bıvített kimutatások Ideje egy új CPU összehasonlításnak, felhasználva az újonnan kidolgozott tesztrendszerünket. A leginkább említésre méltó kiegészítés természetesen az ikermagos processzorok
11.2. A FESZÜLTSÉGLOGIKA
 11.2. A FESZÜLTSÉGLOGIKA Ma a feszültséglogika számít az uralkodó megoldásnak. Itt a logikai változó két lehetséges állapotát két feszültségérték képviseli. Elvileg a két érték minél távolabb kell, hogy
11.2. A FESZÜLTSÉGLOGIKA Ma a feszültséglogika számít az uralkodó megoldásnak. Itt a logikai változó két lehetséges állapotát két feszültségérték képviseli. Elvileg a két érték minél távolabb kell, hogy
Assembly. Iványi Péter
 Assembly Iványi Péter További Op. rsz. funkcionalitások PSP címének lekérdezése mov ah, 62h int 21h Eredmény: BX = PSP szegmens címe További Op. rsz. funkcionalitások Paraméterek kimásolása mov di, parameter
Assembly Iványi Péter További Op. rsz. funkcionalitások PSP címének lekérdezése mov ah, 62h int 21h Eredmény: BX = PSP szegmens címe További Op. rsz. funkcionalitások Paraméterek kimásolása mov di, parameter
SZÁMÍTÓGÉPES ARCHITEKTÚRÁK
 Misák Sándor SZÁMÍTÓGÉPES ARCHITEKTÚRÁK Nanoelektronikai és Nanotechnológiai Részleg DE TTK v.0.1 (2007.02.20.) 3. előadás A SZÁMÍTÓGÉP- RENDSZEREK FELÉPÍTÉSE 1. Processzorok: 3. előadás CPU felépítése,
Misák Sándor SZÁMÍTÓGÉPES ARCHITEKTÚRÁK Nanoelektronikai és Nanotechnológiai Részleg DE TTK v.0.1 (2007.02.20.) 3. előadás A SZÁMÍTÓGÉP- RENDSZEREK FELÉPÍTÉSE 1. Processzorok: 3. előadás CPU felépítése,