Adatok előfeldolgozása. Budapest, február 23.
|
|
|
- Ervin Sipos
- 10 évvel ezelőtt
- Látták:
Átírás
1 Adatok előfeldolgozása Kulcsár Géza Budapest, február 23.

2 Miért van szükség előfeldolgozásra? Az adatbányászat a nagy mennyiségű adatokban rejlő információk feltárása. Milyen formában áll az adat rendelkezésre? Általában:

3 Miért van szükség előfeldolgozásra? Az adatbányászat a nagy mennyiségű adatokban rejlő információk feltárása. Milyen formában áll az adat rendelkezésre? Általában: Hiányos

4 Miért van szükség előfeldolgozásra? Az adatbányászat a nagy mennyiségű adatokban rejlő információk feltárása. Milyen formában áll az adat rendelkezésre? Általában: Hiányos Zajos

5 Miért van szükség előfeldolgozásra? Az adatbányászat a nagy mennyiségű adatokban rejlő információk feltárása. Milyen formában áll az adat rendelkezésre? Általában: Hiányos Zajos Inkonzisztens

6 Hogyan előfeldolgozzunk? Milyen az adat? leírás, statisztika Hiányos, zajos, inkonzisztens adattisztítás Több adatforrás integráció Nagy adatmennyiség redukció

7 Az adat leírása, jellemzői Attribútum típusok I. Kategória típusú attribútumok: csak az egyenlőség vizsgálható II. Sorrend típusú attribútumok: >, <, = eldönthető, azaz van teljes rendezés III. Intervallum típusú attribútumok: az elemek csoportot alkotnak IV. Arány skálájú attribútum: van zérus elem is

8 Az adat leírása, jellemzői Attribútum típusok I. Kategória típusú attribútumok: csak az egyenlőség vizsgálható II. Sorrend típusú attribútumok: >, <, = eldönthető, azaz van teljes rendezés III. Intervallum típusú attribútumok: az elemek csoportot alkotnak IV. Arány skálájú attribútum: van zérus elem is

9 Az adat leírása, jellemzői Középértékek Átlag (súlyozott átlag) Medián Nehezen számolható (nem lehet darabolni a feladatot, holisztikus mérték.) De ismert intervallumszámosságoknál jól becsülhető! Hogyan? Módusz Lehet több is Ferdeség (skewness): γ 1 = E[(X m)3 ] (E[(X m) 2 ]) 3 2
: γ 1 = E[(X m)3 ] (E[(X m) 2")

10 Példa negatív ferdeségű adatra

11 Az adat leírása, jellemzői Az értékek eloszlása Többet tudhatunk meg az adathalmazról, ha nem csak a centralitásáról tájékozódunk. Negyedelőpontok (számosság szerint): Q 1 : 25%-hoz, Q 3 : 75%-hoz legközelebb eső adatpont a rendezett sorban IQR = Q 3 Q 1 Mit nem tudunk még?

12 Az adat leírása, jellemzői Az értékek eloszlása Többet tudhatunk meg az adathalmazról, ha nem csak a centralitásáról tájékozódunk. Negyedelőpontok (számosság szerint): Q 1 : 25%-hoz, Q 3 : 75%-hoz legközelebb eső adatpont a rendezett sorban IQR = Q 3 Q 1 Mit nem tudunk még? Ötszámos jellemzés: Minimum, Q 1, Medián, Q 3, Maximum Egyszerű lehetőség outlierek (különcök) azonosítására: d(x, Q) > 1, 5IQR

13 Az adat leírása, jellemzői Szórás σ 2 = 1 N N i=1 (x i x) 2 σ 2 : szórásnégyzet, variancia (tkp. második centrális momentum) σ: szórás Könnyen, elosztottan számítható, új adat érkezésekor felhasználhatjuk az eddigi értéket

14 Az adat leírása, jellemzői Hasonlósági mértékek Mennyire hasonĺıt egymásra két elem? Mekkora a távolságuk? Legegyszerűbben (ha azonos típusúak az attribútumaink): nemegyezések aránya az összes attribútum számához Intervallum típusú attribútumok esetén sokkal jobb: Minkowski-norma: L p (z) = ( z 1 p z m p ) 1 p

15 Az adat leírása, jellemzői Hasonlósági mértékek Mennyire hasonĺıt egymásra két elem? Mekkora a távolságuk? Legegyszerűbben (ha azonos típusúak az attribútumaink): nemegyezések aránya az összes attribútum számához Intervallum típusú attribútumok esetén sokkal jobb: Minkowski-norma: L p (z) = ( z 1 p z m p ) 1 p p = 2? p = 1?

16 Az adat leírása, jellemzői Hasonlósági mértékek Mennyire hasonĺıt egymásra két elem? Mekkora a távolságuk? Legegyszerűbben (ha azonos típusúak az attribútumaink): nemegyezések aránya az összes attribútum számához Intervallum típusú attribútumok esetén sokkal jobb: Minkowski-norma: L p (z) = ( z 1 p z m p ) 1 p p = 2? p = 1? p = 2: euklideszi norma, p = 1: Manhattan-norma

17 Az adat leírása, jellemzői Hasonlósági mértékek Mennyire hasonĺıt egymásra két elem? Mekkora a távolságuk? Legegyszerűbben (ha azonos típusúak az attribútumaink): nemegyezések aránya az összes attribútum számához Intervallum típusú attribútumok esetén sokkal jobb: Minkowski-norma: L p (z) = ( z 1 p z m p ) 1 p p = 2? p = 1? p = 2: euklideszi norma, p = 1: Manhattan-norma Vegyes attribútumok: csoportosítás, majd súlyozott távolságátlag Speciális esetek pl.: szerkesztési távolság, bezárt szög alapú hasonlóság


18 Különböző p értékek hatása a szomszédságokra
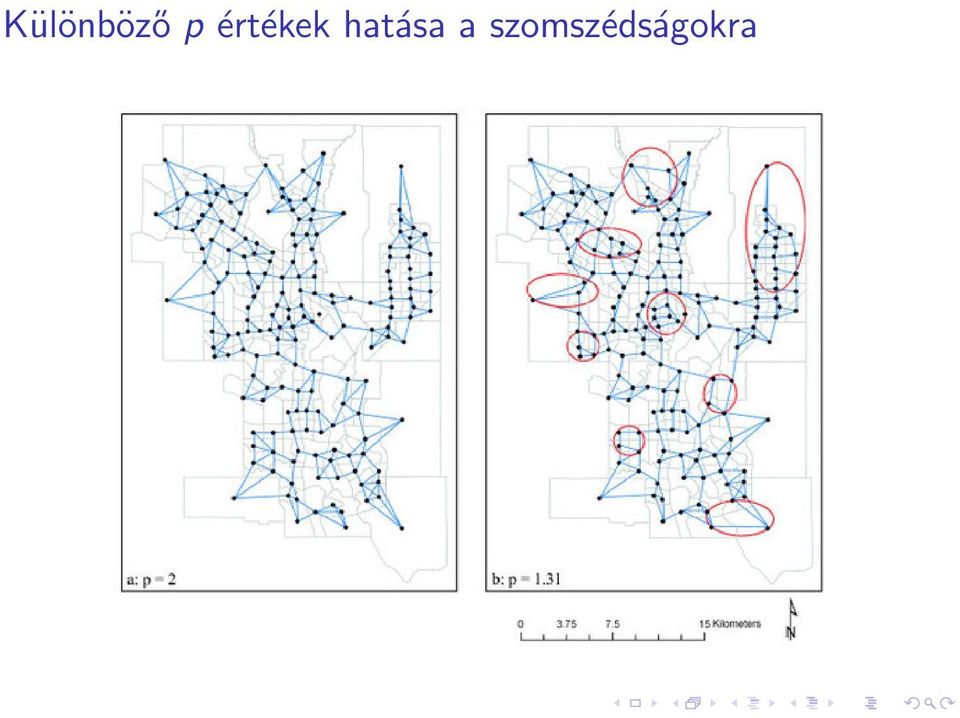
19 Adattisztítás Mit kezdjünk a hiányzó adattal? Elhagyjuk a rekordot, vagy kézzel tömjük be a lyukakat: nem túl hatékony Dedikált konstans a hiány jelzésére: félrevezetheti az adatbányász alkalmazást A teljes attribútum, vagy az adott osztály átlagának, móduszának behelyettesítése Következtetés a hiányzó értékre (regresszió, döntési fa...)

20 Adattisztítás Mit kezdjünk a zajos adattal? Egy értékhalmaz esetén zajon véletlenszerű hibából fakadó hibás értékeket értünk. Binning: rögzített számosságú vagy szélességű vödrök értékeit átlagukkal, mediánjukkal vagy a legközelebbi szélsőértékkel helyettesítjük Túl egyszerűnek látszik, de gyakorlatban is használható, pl. MS, NMR kísérletek Regresszió: az adat illesztése egy függvényhez Klaszterezés: hasonlóság alapú csoportosítás Ezek a technikák már több célra használhatók, egyben redukciós és diszkretizációs eljárások is


21 Toluol ionizációs tömegspektruma
22 Adatintegráció Különböző források egyesítése Azonosítási probléma, redundancia korrelációanaĺızis Pearson-féle korrelációs együttható: r A,B = Nem jelent implikációt Milyen értékeket vehet fel? N i=1 (a i A)(b i B) Nσ A σ B
23 Adatintegráció Különböző források egyesítése Azonosítási probléma, redundancia korrelációanaĺızis Pearson-féle korrelációs együttható: r A,B = Nem jelent implikációt Milyen értékeket vehet fel? N i=1 (a i A)(b i B) Nσ A σ B Kategória típusú attribútumokra: χ 2 statisztika (Pearson) A c-féle, B r-féle értéket vehet fel. Egy c x r-es táblázatot töltünk ki az eseménypárok együttes előfordulásával. χ 2 = c i=1 r j=1 várt együttes előfordulás e i j = #(A=a i )#(B=b i ) N (o ij e ij ) 2 e ij, ahol o ij a megfigyelt, e ij pedig a
24 Adattranszformáció Rengeteg diverz technikával készíthetjük elő az adatokat az adatbányászathoz. Zajszűrés (már láttuk) Aggregáció (pl. havi adatokból éves kimutatás) Általánosítás (fogalmi, numerikus hierarchiák) Normalizálás Új attribútum létrehozása
25 Adattranszformáció Normalizálás Min-max: v n = v min max min (max n min n ) + min n z-score: v n = v A σ A Decimális skálázás a céltartományhoz igazítva A min-max normalizálás és a decimális skálázás nem robusztus az érkező új értékekre
26 Adatredukció Ez tulajdonképpen a feldolgozandó adat méretének csökkentése érdekében végzett transzformáció. Aggregáció Attribútum-részhalmaz választása(inkrementálisan, dekrementálisan, döntési fákkal) Méretcsökkentés (alternatív ábrázolás, modellezés) Dimenziócsökkentés (ez is új reprezentáció, de valamilyen kódolás, leképezés, tömörítés ) Hasznos, ha nagyon nagy az attribútumhalmaz számossága (pl. szópárok gyakorisága az interneten: n 10 9 )
27 Adatredukció Dimenziócsökkentés: DWT (Discrete Wavelet Transform) Az adatrekordra vektorként tekintünk, a DWT ezt egy azonos hosszúságú vektorrá transzformálja. De akkor mire jó?
28 Adatredukció Dimenziócsökkentés: DWT (Discrete Wavelet Transform) Az adatrekordra vektorként tekintünk, a DWT ezt egy azonos hosszúságú vektorrá transzformálja. De akkor mire jó? Az új vektornak néhány együtthatójából is jól közeĺıthető az eredeti adat. A kiinduló vektor mérete 2 hatványa legyen (padding szükséges lehet). Egy transzformáció során két függvényt alkalmazunk szomszédos adatpárokra, iteratívan, minden ciklusban felezve ezzel az adathalmaz méretét. Az egyik függvény jellemzően simítja az adatot, a másik pedig a különbségeket erősíti. A futás során előálló, kijelölt értékek lesznek a transzformált vektor együtthatói. A transzformáció inverzét végrehajtva az adat visszaálĺıtható.
 A waveletek egy ortonormált bázisban történő leírást tesznek lehetové.")

29 De mi az a wavelet ( hullámocska )? A képen a legegyszerűbb diszkrét wavelet, a Haar-wavelet látható. (Haar Alfréd, 1909) A waveletek egy ortonormált bázisban történő leírást tesznek lehetové. (Két függvény: wavelet függvény az ortogonalitáshoz, és egy skálázó függvény az ortonormalitáshoz. A Haar-wavelet rekurzívan páronkénti különbségeket ad meg, illetve a teljes adatsor összegét. A DWT elonye a DFT-vel szemben, hogy nem csak a frekvenciát ábrázolja, hanem a lokalitást is.
")
30 Vannak összetettebb waveletek is! (Ingrid Daubechies, 1988)
")
31 Vannak összetettebb waveletek is! (Ingrid Daubechies, 1988)

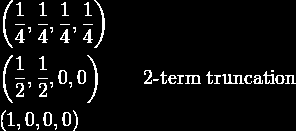
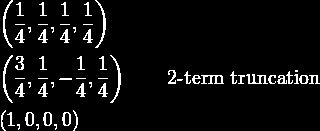
32 DWT vs. DFT az egységimpulzus példáján

33 DWT a gyakorlatban - JPEG2000

34 JPEG JFIF vs. JPEG2000
35 Adatredukció Dimenziócsökkentés: PCA (Principal Component Analysis - főkomponens-anaĺızis, szinguláris felbontás, Karhunen-Loeve módszer) Először: intuitíven A PCA-val egy új ortogonális bázist találhatunk az eredeti adathalmazhoz. Ezeket a vektorokat, amiket főkomponenseknek nevezünk, szignifikancia szerint sorba rendezhetjük, kezdve a legerősebb szórás irányába mutatóval. A leggyengébb komponensek elhagyásával is az eredeti adat jó közeĺıtését kapjuk. (Bizonyos értelemben a leheto legjobb közeĺıtést, mint azt látni fogjuk.)
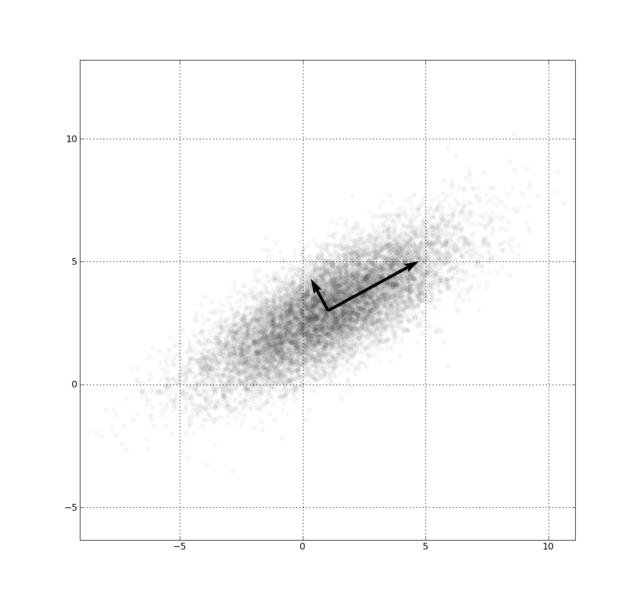

36 PCA Gauss-eloszlásra
37 Adatredukció Dimenziócsökkentés: PCA (Principal Component Analysis - főkomponens-anaĺızis, szinguláris felbontás, Karhunen-Loeve módszer) Másodszor: alapos(abb)an - PCA SVD használatával Definíció Ortogonális mátrix: Az U négyzetes mátrix ortogonális, ha létezik U 1 inverze és U 1 = U T
38 Adatredukció Dimenziócsökkentés: PCA (Principal Component Analysis - főkomponens-anaĺızis, szinguláris felbontás, Karhunen-Loeve módszer) Másodszor: alapos(abb)an - PCA SVD használatával Definíció Ortogonális mátrix: Az U négyzetes mátrix ortogonális, ha létezik U 1 inverze és U 1 = U T Ortogonális mátrix által reprezentált lineáris transzformáció nem változtatja a vektorok hosszát. Tétel Minden M R m n mátrixnak létezik szinguláris érték felbontása (SVD): M = UΣV T, ahol U R m m, V R n n, Σ R m n, és Σ bal felső részmátrixa egy r r diagonális mátrix, a főátlójában csökkenő sorrendben pozitív elemekkel, mindenhol máshol pedig 0 elemekkel.
39 Adatredukció Dimenziócsökkentés: PCA (Principal Component Analysis - főkomponens-anaĺızis, szinguláris felbontás, Karhunen-Loeve módszer) Miért jó ez nekünk a dimenziócsökkentésnél? M = UΣV T = r i=1 σ iu i v T i
40 Adatredukció Dimenziócsökkentés: PCA (Principal Component Analysis - főkomponens-anaĺızis, szinguláris felbontás, Karhunen-Loeve módszer) Miért jó ez nekünk a dimenziócsökkentésnél? M = UΣV T = r i=1 σ iu i v T i Vegyük csak a k legnagyobb súlyú diadikus szorzatot! M k = U k Σ k V T k, M k rangja k Tétel M M k F = min M N F = r i=k+1 σ2 i, ahol a minimumot a k rangú mátrixok N halmazán vesszük. Az M mátrix U k Σ k -val közeĺıtheto, ahol Vk T bázist. sorai alkotják a
41 Adatredukció Méretcsökkentés Parametrikus módszerek: nem kell eltárolni az adatot, csak néhány paramétert Példa: regresszió Nemparametrikus módszerek: klaszterezés, mintavételezés SRSWOR, SRSWR (Simple Random Sample WithOut/With Replacement): s rekordot húzunk, az utóbbinál ugyanaz többször is húzható Ha van klaszter- vagy osztályinformáció, azt felhasználhatjuk
42 Adatredukció Mintavételezés hibája a méret függvényében Első közeĺıtés: hiba(m) = P( Yx m p x ɛ), ahol m a minta mérete, Y x az x elem elofordulásainak száma a mintában, p x pedig x előfordulásának valószínűsége Csernov-korlátból: m 1 ln 2 2ɛ 2 σ, ahol σ a kívánt hibakorlát Pl. ha 0,01 vagy nagyobb eltérés esélyét 0,01 alá akarjuk csökkenteni, mintát kell vennünk Ez a megközeĺıtés nem szerencsés, mert kisebb p valószínuség mellett kisebb hibát ad Jobb: hiba(m) = P( Yx mp 1 + ɛ) + P( Yx mp 1 1+ɛ )
43 Diszkretizálás és hierarchiák Csökkenti, egyszerűsíti, ugyanakkor megfoghatóbbá teszi az adatot. Lehet top-down, illetve bottom-up megközeĺıtésű (splitting ill. merging), aszerint, hogy az osztópontok kezdeti halmazához továbbiakat veszünk, vagy kezdetben minden pont osztópont, és ezt csökkentjük Lehet felügyelt, ha a diszkretizáláshoz használunk osztályinformációt Létrehozhatunk több szintű hierarchiát is rekurzív diszkretizálással
44 Diszkretizálás és hierarchiák Módszerek numerikus adatokon Binning (már láttuk) Az 1R algoritmus diszkretizáló eljárása Entrópia alapú diszkretizálás ChiMerge Klaszterezés Intuitív feldarabolás (kívánatos lehet a természetesebb határok érdekében)
45 Diszkretizálás és hierarchiák Entrópia alapú diszkretizálás Felügyelt, top-down Entrópia: H(D) = C i C p i log 2 p i, ahol p i a C i osztályú elemek relatív gyakorisága D-ben Úgy választunk vágópontot, hogy D 1 D H(D 1) + D 2 D H(D 2) minimális legyen Ez annak az információnak a mértéke, amennyi hozzáadásával tökéletessé tehető lenne a vágás osztályozási képessége Rekurzívan, amíg el nem érünk valamilyen kívánt határt (hiányzó információban, intervallumok számosságában)
46 Diszkretizálás és hierarchiák ChiMerge Felügyelt, bottom-up diszkretizálás a már megismert χ 2 teszt használatával A táblázat oszlopai azok a szomszédos intervallumok, amiknek kíváncsi vagyunk az összevonhatóságára, sorai pedig az osztályok Alacsony χ 2 értékek esetén az intervallumok osztályfüggetlenek és összevonhatók Megállási kritériumok: χ 2, intervallumok száma
47 Diszkretizálás és hierarchiák Ökölszabály az intuitív diszkretizáláshoz szabály A decimális értékek MSD-je alapján határozzuk meg a következő szintű intervallumok számát 3, 6, 7 és 9 különbözo érték esetén: 3 részre 2, 4 és 8 különbözo érték esetén: 4 részre 1, 5 és 10 különözo érték esetén: 5 részre osztunk Előtte megfontolható az extrémumok kihagyása (pl. 5%-95%), de utána szükség lehet új intervallumokat létrehozni nekik
48 Köszönöm a figyelmet!
Huzsvai László - Balogh Péter LINEÁRIS MODELLEK AZ R-BEN
 Huzsvai László - Balogh Péter LINEÁRIS MODELLEK AZ R-BEN Seneca Books DEBRECEN 2015 Minden jog fenntartva. Jelen könyvet vagy annak részleteit a Kiadó engedélye nélkül bármilyen formában vagy eszközzel
Huzsvai László - Balogh Péter LINEÁRIS MODELLEK AZ R-BEN Seneca Books DEBRECEN 2015 Minden jog fenntartva. Jelen könyvet vagy annak részleteit a Kiadó engedélye nélkül bármilyen formában vagy eszközzel
Euler kör/út: olyan zárt/nem feltétlenül zárt élsorozat, amely a gráf minden élét pontosan egyszer tartalmazza
 1) Euler körök és utak, ezek létezésének szükséges és elégséges feltétele. Hamilton körök és utak. Szükséges feltétel Hamilton kör/út létezésére. Elégséges feltételek: Dirac, és Ore tétele. Euler kör/út:
1) Euler körök és utak, ezek létezésének szükséges és elégséges feltétele. Hamilton körök és utak. Szükséges feltétel Hamilton kör/út létezésére. Elégséges feltételek: Dirac, és Ore tétele. Euler kör/út:
LOGISZTIKUS REGRESSZIÓS EREDMÉNYEK ÉRTELMEZÉSE*
 A LOGISZTIKUS REGRESSZIÓS EREDMÉNYEK ÉRTELMEZÉSE* BARTUS TAMÁS A tanulmány azt vizsgálja, hogy logisztikus regressziós modellek értelmezésére jobban alkalmasak-e a marginális hatások (feltételes valószínűségek
A LOGISZTIKUS REGRESSZIÓS EREDMÉNYEK ÉRTELMEZÉSE* BARTUS TAMÁS A tanulmány azt vizsgálja, hogy logisztikus regressziós modellek értelmezésére jobban alkalmasak-e a marginális hatások (feltételes valószínűségek
Kockázati modellek (VaR és cvar)
") Kockázati modellek (VaR és cvar) BSc Szakdolgozat Írta: Kutas Éva Matematika BSc Alkalmazott matematikus szakirány Témavezet Mádi-Nagy Gergely egyetemi adjunktus Operációkutatási Tanszék Eötvös Loránd
Kockázati modellek (VaR és cvar) BSc Szakdolgozat Írta: Kutas Éva Matematika BSc Alkalmazott matematikus szakirány Témavezet Mádi-Nagy Gergely egyetemi adjunktus Operációkutatási Tanszék Eötvös Loránd
KOVÁCS BÉLA, MATEMATIKA I.
 KOVÁCS BÉLA MATEmATIkA I 6 VI KOmPLEX SZÁmOk 1 A komplex SZÁmOk HALmAZA A komplex számok olyan halmazt alkotnak amelyekben elvégezhető az összeadás és a szorzás azaz két komplex szám összege és szorzata
KOVÁCS BÉLA MATEmATIkA I 6 VI KOmPLEX SZÁmOk 1 A komplex SZÁmOk HALmAZA A komplex számok olyan halmazt alkotnak amelyekben elvégezhető az összeadás és a szorzás azaz két komplex szám összege és szorzata
4. Számelmélet, számrendszerek
 I. Elméleti összefoglaló A maradékos osztás tétele: 4. Számelmélet, számrendszerek Legyen a tetszőleges, b pedig nullától különböző egész szám. Ekkor léteznek olyan, egyértelműen meghatározott q és r egész
I. Elméleti összefoglaló A maradékos osztás tétele: 4. Számelmélet, számrendszerek Legyen a tetszőleges, b pedig nullától különböző egész szám. Ekkor léteznek olyan, egyértelműen meghatározott q és r egész
A defaultráta, a nemteljesítési valószínűség és a szabályozás egyéb követelményei
 2008. HETEDIK ÉVFOLYAM 1. SZÁM 1 MADAR LÁSZLÓ A defaultráta, a nemteljesítési valószínűség és a szabályozás egyéb követelményei Bár a defaultráta, illetve a nemteljesítési valószínűség fogalmai egy ideje
2008. HETEDIK ÉVFOLYAM 1. SZÁM 1 MADAR LÁSZLÓ A defaultráta, a nemteljesítési valószínűség és a szabályozás egyéb követelményei Bár a defaultráta, illetve a nemteljesítési valószínűség fogalmai egy ideje
A MEODIT több-felhasználós ontológia szerkesztő program tesztelése
 I. Bevezetés A MEODIT több-felhasználós ontológia szerkesztő program tesztelése A MEODIT ontológia szerkesztő programot az NKFP-2/042/04 számú Egységes Magyar Ontológia c. pályázat keretében készítették
I. Bevezetés A MEODIT több-felhasználós ontológia szerkesztő program tesztelése A MEODIT ontológia szerkesztő programot az NKFP-2/042/04 számú Egységes Magyar Ontológia c. pályázat keretében készítették
k=1 k=1 találhatjuk meg, hogy az adott feltétel mellett az empirikus eloszlás ennek az eloszlásnak
 Nagy eltérések elmélete. A Szanov tétel. Egy előző feladatsorban, a Nagy eltérések elmélete; Független valós értékű valószínűségi változók feladatsorban annak az eseménynek a valószínűségét vizsgáltuk,
Nagy eltérések elmélete. A Szanov tétel. Egy előző feladatsorban, a Nagy eltérések elmélete; Független valós értékű valószínűségi változók feladatsorban annak az eseménynek a valószínűségét vizsgáltuk,
feltételek esetén is definiálják, tehát olyan esetekben is, amikor a hagyományos, a
 A Valószínűségszámítás II. előadássorozat hatodik témája. ELTÉTELES VALÓSZÍNŰSÉG ÉS ELTÉTELES VÁRHATÓ ÉRTÉK A feltételes valószínűség és feltételes várható érték fogalmát nulla valószínűséggel bekövetkező
A Valószínűségszámítás II. előadássorozat hatodik témája. ELTÉTELES VALÓSZÍNŰSÉG ÉS ELTÉTELES VÁRHATÓ ÉRTÉK A feltételes valószínűség és feltételes várható érték fogalmát nulla valószínűséggel bekövetkező
1. fejezet HUMÁN EGÉSZSÉGKOCKÁZAT BECSLÉSE
 1. fejezet HUMÁN EGÉSZSÉGKOCKÁZAT BECSLÉSE 19 20 Tartalomjegyzék 1. Általános bevezetõ...25 1.1. Elõzmények...25 1.2. Általános alapelvek...27 2. Expozícióbecslés...29 2.1. Bevezetõ...29 2.1.1. A mért
1. fejezet HUMÁN EGÉSZSÉGKOCKÁZAT BECSLÉSE 19 20 Tartalomjegyzék 1. Általános bevezetõ...25 1.1. Elõzmények...25 1.2. Általános alapelvek...27 2. Expozícióbecslés...29 2.1. Bevezetõ...29 2.1.1. A mért
Országos kompetenciamérés 2013. Országos jelentés
 Országos kompetenciamérés 2013 Országos jelentés Szerzők Balázsi Ildikó, Lak Ágnes Rozina, Szabó Vilmos, Szabó Lívia Dóra, Vadász Csaba Tördelő Szabó Ágnes Balázsi Ildikó, Lak Ágnes Rozina, Szabó Vilmos,
Országos kompetenciamérés 2013 Országos jelentés Szerzők Balázsi Ildikó, Lak Ágnes Rozina, Szabó Vilmos, Szabó Lívia Dóra, Vadász Csaba Tördelő Szabó Ágnes Balázsi Ildikó, Lak Ágnes Rozina, Szabó Vilmos,
24. Valószínűség-számítás
 24. Valószínűség-számítás I. Elméleti összefoglaló Események, eseménytér A valószínűség-számítás a véletlen tömegjelenségek vizsgálatával foglalkozik. Azokat a jelenségeket, amelyeket a figyelembe vett
24. Valószínűség-számítás I. Elméleti összefoglaló Események, eseménytér A valószínűség-számítás a véletlen tömegjelenségek vizsgálatával foglalkozik. Azokat a jelenségeket, amelyeket a figyelembe vett
A parciális korrelációs együttható értelmezési problémái a többdimenziós normalitás feltételének sérülése esetén
 A parciális korrelációs együttható értelmezési problémái a többdimenziós normalitás feltételének sérülése esetén egyetemi tanár, az MTA doktora, Károli Gáspár Református Egyetem Pszichológiai Intézete,
A parciális korrelációs együttható értelmezési problémái a többdimenziós normalitás feltételének sérülése esetén egyetemi tanár, az MTA doktora, Károli Gáspár Református Egyetem Pszichológiai Intézete,
A HOZAMGÖRBE DINAMIKUS BECSLÉSE
 Budapesti CORVINUS Egyetem A HOZAMGÖRBE DINAMIKUS BECSLÉSE PH.D. ÉRTEKEZÉS Kopányi Szabolcs András Budapest, 2009 Kopányi Szabolcs András A HOZAMGÖRBE DINAMIKUS BECSLÉSE BEFEKTETÉSEK ÉS VÁLLALATI PÉNZÜGYEK
Budapesti CORVINUS Egyetem A HOZAMGÖRBE DINAMIKUS BECSLÉSE PH.D. ÉRTEKEZÉS Kopányi Szabolcs András Budapest, 2009 Kopányi Szabolcs András A HOZAMGÖRBE DINAMIKUS BECSLÉSE BEFEKTETÉSEK ÉS VÁLLALATI PÉNZÜGYEK
Berzsenyi Dániel Gimnázium. Matematika helyi tanterv Fizika tagozat 9-12. évfolyam
 Általános szerkezet Berzsenyi Dániel Gimnázium Matematika helyi tanterv Fizika tagozat 9-12. évfolyam Cél: az emelt szintű érettségi követelményekben szereplő tananyag megtanítása, néhány részen kiegészítve
Általános szerkezet Berzsenyi Dániel Gimnázium Matematika helyi tanterv Fizika tagozat 9-12. évfolyam Cél: az emelt szintű érettségi követelményekben szereplő tananyag megtanítása, néhány részen kiegészítve
RADIOKÉMIAI MÉRÉS. Laboratóriumi neutronforrásban aktivált-anyagok felezési idejének mérése. = felezési idő. ahol: A = a minta aktivitása.
 RADIOKÉMIAI MÉRÉS Laboratóriumi neutronforrásban aktivált-anyagok felezési idejének mérése A radioaktív bomlás valószínűségét kifejező bomlási állandó (λ) helyett gyakran a felezési időt alkalmazzuk (t
RADIOKÉMIAI MÉRÉS Laboratóriumi neutronforrásban aktivált-anyagok felezési idejének mérése A radioaktív bomlás valószínűségét kifejező bomlási állandó (λ) helyett gyakran a felezési időt alkalmazzuk (t
P, NP, NP-C, NP-hard, UP, RP, NC, RNC
 P, NP, NP-C, NP-hard, UP, RP, NC, RNC 1 Az eddig vizsgált algoritmusok csaknem valamennyien polinomiális idejuek, azaz n méretu bemeneten futási idejük a legrosszabb esetben is O(n k ), valamely k konstanssal.
P, NP, NP-C, NP-hard, UP, RP, NC, RNC 1 Az eddig vizsgált algoritmusok csaknem valamennyien polinomiális idejuek, azaz n méretu bemeneten futási idejük a legrosszabb esetben is O(n k ), valamely k konstanssal.
Malárics Viktor A szám fraktál
 Malárics Viktor A szám fraktál π e Tér és idő a mozgásból származnak. Tartalomjegyzék: 1. Bevezető a hetedik részhez 4 2. Számok, és a Pi szám 6 2. 1. Az osztály szintű szám fogalom...7 2. 2. Pi hasonmások
Malárics Viktor A szám fraktál π e Tér és idő a mozgásból származnak. Tartalomjegyzék: 1. Bevezető a hetedik részhez 4 2. Számok, és a Pi szám 6 2. 1. Az osztály szintű szám fogalom...7 2. 2. Pi hasonmások
SZENT ISTVÁN EGYETEM. DOKTORI (PhD) ÉRTEKEZÉS AZ ÜZEMI STRUKTÚRA FEJLŐDÉSÉNEK IRÁNYAI AZ EU TAGORSZÁGOKBAN ÉS ROMÁNIÁBAN
 ÉRTEKEZÉS AZ ÜZEMI STRUKTÚRA FEJLŐDÉSÉNEK IRÁNYAI AZ EU TAGORSZÁGOKBAN ÉS ROMÁNIÁBAN") SZENT ISTVÁN EGYETEM DOKTORI (PhD) ÉRTEKEZÉS AZ ÜZEMI STRUKTÚRA FEJLŐDÉSÉNEK IRÁNYAI AZ EU TAGORSZÁGOKBAN ÉS ROMÁNIÁBAN Bors Réka Gödöllő 2008. A doktori iskola megnevezése: tudományága: gazdálkodás- és
SZENT ISTVÁN EGYETEM DOKTORI (PhD) ÉRTEKEZÉS AZ ÜZEMI STRUKTÚRA FEJLŐDÉSÉNEK IRÁNYAI AZ EU TAGORSZÁGOKBAN ÉS ROMÁNIÁBAN Bors Réka Gödöllő 2008. A doktori iskola megnevezése: tudományága: gazdálkodás- és
Hogyan fogalmazzuk meg egyszerűen, egyértelműen a programozóknak, hogy milyen lekérdezésre, kimutatásra, jelentésre van szükségünk?
 Hogyan fogalmazzuk meg egyszerűen, egyértelműen a programozóknak, hogy milyen lekérdezésre, kimutatásra, jelentésre van szükségünk? Nem szükséges informatikusnak lennünk, vagy mélységében átlátnunk az
Hogyan fogalmazzuk meg egyszerűen, egyértelműen a programozóknak, hogy milyen lekérdezésre, kimutatásra, jelentésre van szükségünk? Nem szükséges informatikusnak lennünk, vagy mélységében átlátnunk az
BEVEZETÉS AZ INFORMATIKÁBA 1. rész TARTALOMJEGYZÉK
 BEVEZETÉS AZ INFORMATIKÁBA 1. rész TARTALOMJEGYZÉK BEVEZETÉS AZ INFORMATIKÁBA 1. RÉSZ... 1 TARTALOMJEGYZÉK... 1 AZ INFORMÁCIÓ... 2 Az információ fogalma... 2 Közlemény, hír, adat, információ... 3 Az információ
BEVEZETÉS AZ INFORMATIKÁBA 1. rész TARTALOMJEGYZÉK BEVEZETÉS AZ INFORMATIKÁBA 1. RÉSZ... 1 TARTALOMJEGYZÉK... 1 AZ INFORMÁCIÓ... 2 Az információ fogalma... 2 Közlemény, hír, adat, információ... 3 Az információ
Változások az Országos kompetenciamérés skáláiban
 Változások az Országos kompetenciamérés skáláiban A skála módosításának okai A kompetenciamérések bevezetésénél is megfogalmazott, ám akkor adatvédelmi szempontok miatt nem megvalósítható igény volt, hogy
Változások az Országos kompetenciamérés skáláiban A skála módosításának okai A kompetenciamérések bevezetésénél is megfogalmazott, ám akkor adatvédelmi szempontok miatt nem megvalósítható igény volt, hogy
Befektetések kockázatának mérése*
 Befektetések kockázatának mérése* Bugár Gyöngyi PhD, a Pécsi Tudományegyetem egyetemi docense E-mail: bugar@ktk.pte.hu Uzsoki Máté, a Budapesti Műszaki Egyetem hallgatója E-mail: uzsoki.mate@gmail.com
Befektetések kockázatának mérése* Bugár Gyöngyi PhD, a Pécsi Tudományegyetem egyetemi docense E-mail: bugar@ktk.pte.hu Uzsoki Máté, a Budapesti Műszaki Egyetem hallgatója E-mail: uzsoki.mate@gmail.com
Jelöljük az egyes területrészeket A-val, B-vel és C-vel, ahogy az ábrán látható.
 1. feladat. 013 pontosan egyféleképpen írható fel két prím összegeként. Mennyi ennek a két prímnek a szorzata? 40 Megoldás: Mivel az összeg páratlan, ezért az egyik prímnek párosnak kell lennie, tehát
1. feladat. 013 pontosan egyféleképpen írható fel két prím összegeként. Mennyi ennek a két prímnek a szorzata? 40 Megoldás: Mivel az összeg páratlan, ezért az egyik prímnek párosnak kell lennie, tehát
Diszkrét matematika II., 1. el adás. Lineáris leképezések
 1 Diszkrét matematika II., 1. el adás Lineáris leképezések Dr. Takách Géza NyME FMK Informatikai Intézet takach@inf.nyme.hu http://inf.nyme.hu/ takach/ 2005. február 6 Gyakorlati célok Ezen el adáson,
1 Diszkrét matematika II., 1. el adás Lineáris leképezések Dr. Takách Géza NyME FMK Informatikai Intézet takach@inf.nyme.hu http://inf.nyme.hu/ takach/ 2005. február 6 Gyakorlati célok Ezen el adáson,
Mágneses magrezonancia-spektroszkópia
 1 Mágneses magrezonancia-spektroszkópia Egy- és kétdimenziós módszerek a kémiai szerkezetkutatásban Metodikai útmutató Szalontai Gábor Veszprémi Egyetem NMR Laboratórium Verziószám: 2.0 2003. március 2
1 Mágneses magrezonancia-spektroszkópia Egy- és kétdimenziós módszerek a kémiai szerkezetkutatásban Metodikai útmutató Szalontai Gábor Veszprémi Egyetem NMR Laboratórium Verziószám: 2.0 2003. március 2
HARDVER- ÉS SZOFTVERRENDSZEREK VERIFIKÁCIÓJA
 Írta: ÉSIK ZOLTÁN GOMBÁS ÉVA NÉMETH L. ZOLTÁN HARDVER- ÉS SZOFTVERRENDSZEREK VERIFIKÁCIÓJA Egyetemi tananyag 2 COPYRIGHT: 2 26, Dr. Ésik Zoltán, Dr. Gombás Éva, Dr. Németh L. Zoltán, Szegedi Tudományegyetem
Írta: ÉSIK ZOLTÁN GOMBÁS ÉVA NÉMETH L. ZOLTÁN HARDVER- ÉS SZOFTVERRENDSZEREK VERIFIKÁCIÓJA Egyetemi tananyag 2 COPYRIGHT: 2 26, Dr. Ésik Zoltán, Dr. Gombás Éva, Dr. Németh L. Zoltán, Szegedi Tudományegyetem
MI ILYENNEK KÉPZELJÜK MATEMATIKA
 MI ILYENNEK KÉPZELJÜK Minta feladatsorok a középszintű MATEMATIKA érettségire való felkészüléshez II. RÉSZ Összeállították: a Fazekas Mihály Fővárosi Gyakorló Általános Iskola és Gimnázium vezetőtanárai
MI ILYENNEK KÉPZELJÜK Minta feladatsorok a középszintű MATEMATIKA érettségire való felkészüléshez II. RÉSZ Összeállították: a Fazekas Mihály Fővárosi Gyakorló Általános Iskola és Gimnázium vezetőtanárai
MAROSSY ZITA A SPOT VILLAMOSENERGIA-ÁRAK ELEMZÉSE STATISZTIKAI ÉS ÖKONOFIZIKAI ESZKÖZÖKKEL
 MAROSSY ZITA A SPOT VILLAMOSENERGIA-ÁRAK ELEMZÉSE STATISZTIKAI ÉS ÖKONOFIZIKAI ESZKÖZÖKKEL Befektetések és Vállalati Pénzügy Tanszék Matematikai Közgazdaságtan és Gazdaságelemzés Tanszék Témavezető: Csekő
MAROSSY ZITA A SPOT VILLAMOSENERGIA-ÁRAK ELEMZÉSE STATISZTIKAI ÉS ÖKONOFIZIKAI ESZKÖZÖKKEL Befektetések és Vállalati Pénzügy Tanszék Matematikai Közgazdaságtan és Gazdaságelemzés Tanszék Témavezető: Csekő