A Facebook adattárháza. Trencséni Márton info99
|
|
|
- Regina Dudás
- 5 évvel ezelőtt
- Látták:
Átírás
1 A Facebook adattárháza Trencséni Márton info99 1
2 Néhány szót rólam 1. BME-n végeztem 2004-ben műszaki informatikusként 2. Adatbázisok tárgy már akkor is volt :) Utána: ELTE, fizikus Graphisoft és kisebb magyar cégek (Budapest, ) Scalien (Budapest, ) (saját NoSQL startup, Prezi (Budapest, ) Facebook (London, ) - Data Engineer Fetchr (Dubai, ) 2
3 Tartalomjegyzék 1. Bevezető 2. Facebook számok, architektúra 3. Hadoop/Hive 4. Presto 5. Scuba 6. Konklúziók 3
4 Mi az a Data Engineer? Bevezető 4
5 Bevezető 5
6 Számok, metrikák 1. Daily Active User (DAU) - naponta aktív felhasználó 2. Monthly Active User (MAU) - utolsó 28 napban aktív felhasználó 3. Timespent / DAU - átlagosan hány percet tölt FB-on egy DAU Mennyi adat generálódik naponta? Legyen percenként 10KB 1B x 60 x 10KB = 600TB naponta De több termék van... FB, Messenger, Instagram, Whatsapp több PB naponta (kicsit segít: retention = letöröljük a régi, nem releváns DWH adatokat) De: kommersz adatbázis kezelők nem boldogulnak ennyi adattal, vagy nem elég flexibilisek Facebook számok, architektúra 6

7 Facebook számok, architektúra 7
8 A megoldás (2008-ban) = Hadoop Google-nél készültek hasonló rendszerek 2005 körül: Google Filesystem (GFS) Bigtable Chubby MapReduce Ezekről cikkeket írtak a Google mérnökei, ez alapján a Yahoo! mérnökei elkészítettek egy hasonló architektúrájú open-source rendszert, ez a Hadoop (Java alapú). Facebook-nál Hadoop 2008 óta van. Hadoop/Hive 8

9 Hadoop klaszter 1. Storage: Hadoop Filesystem (HDFS) a. Name node b. Data node 2. Compute: MapReduce a. Job tracker b. Task tracker 3. Hive: SQL a. HCatalog b. HiveServer Hadoop/Hive 9
10 HDFS tervezési elvek 1. Több ezer node, hardver failure mindig van. 2. Sok adat, PB-ok. 3. Write-once modell. 4. Nagy adatmennyiség miatt olcsóbb a számítást átmásolni mint az adatot. 5. Streaming jellegű adathozzáférés legyen gyors. Hadoop/Hive 10
11 Namenode A file rendszer metaadatot tárolja memóriában: 1. file-ok fába rendezése 2. egy file mely blokkokból áll (tipikusan egy blokk 128MB) 3. blokk {Datanode} táblát R=3 (default) replikációs faktor miatt több Datanode 4. Datanode {blokk} táblát Hibatűrésre rendelkezésre áll egy Secondary Namenode, ami pár percenként másolja a Namenode-ot. Hadoop/Hive 11
12 Datanode 1. 3 mp-enként heartbeat a Namenode-nak 2. A blokkjairól checksum-ot tart nyilván, ennek segítségével diszk korrupciót észleli, és jelenti a Namenode-nak 3. ha szükség van rá, a Namenode újra replikál blokkokat amelyeknek az R replikációs faktora R alá csökken. 4. Ennek hatására Datanode-ok egymás közt másolnak blokkokat. Hadoop/Hive 12
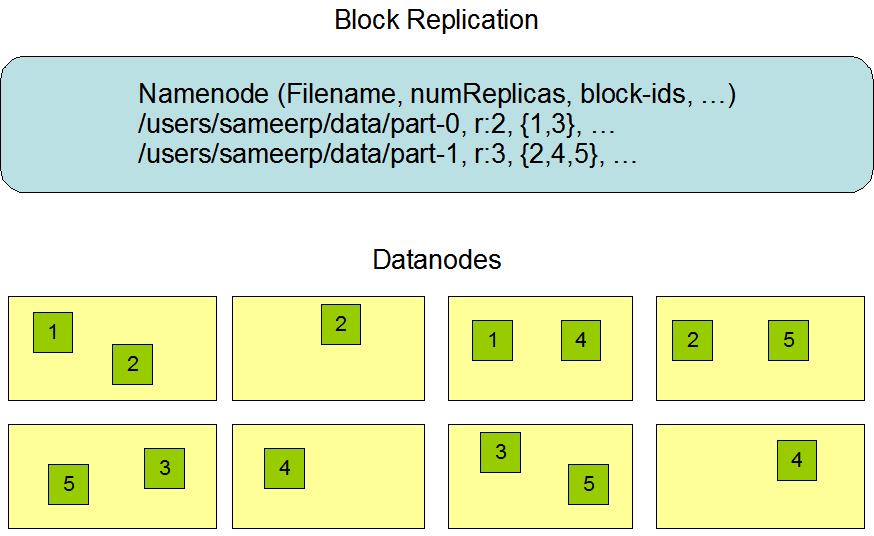
13 HDFS Hadoop/Hive 13
14 Facebook HDFS 1. Több klaszter (silver, gold, stb.) 2. Egy klaszter = 5-10,000 node 3. Egy klaszteren belül több Hive namespace (mint séma az adatbázisoknál) 4. Termékenként (FB, Messenger, IG, WP) egy namespace. 5. Klaszterek között nehéz mozgatni adatot, de lehet. Hadoop/Hive 14

15 Friends viewing posts Nagy HDFS klaszter = nagyon sok adat, elosztva Hogyan futtatunk rajta analitikai query-ket? Nem fér be memóriába Sokáig tart Hadoop/Hive 15
16 MapReduce segít map(list, func) es reduce(list, op, first) a funkcionális programozásból pl. map([1, 2, 3], sin) [sin(1), sin(2), sin(3)] pl. reduce([1, 2, 3], operator+, 0) = 6 MapReduce = elosztott programozási modell oldjuk meg a problémát egymás után következő map es reduce fázisokkal (map-reduce-reduce-map-map-reduce...) A fázisok közötti átmeneti eredményeket kiírja HDFS-re ( nem kell sok memória), itt shuffle és sort lépések vannak Hadoop/Hive 16
17 Példa Hadoop/Hive 17
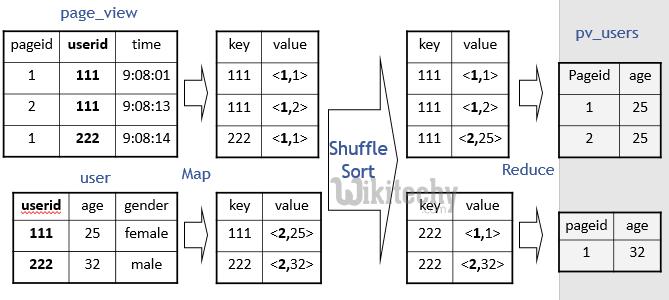
18 Hadoop/Hive 18
19 MapReduce 2 szerepből áll 1. JobTracker a. Átveszi a MR programot a klienstől b. Általában külön gépen fut, MR szempontből szűk keresztmetszet (single point of failure) c. NameNode-dal beszél, oda rakja az MR taskokat ahol az adat van (adatlokalitás) d. Figyeli az egyes TaskTrackerek-et, jelent a kliens-nek e. Ha lehal, MR nem megy, HDFS továbbra is megy 2. TaskTracker a. Map és Reduce végrehajtás b. DataNode-okon fut (adatlokalitás) c. JobTracker-nek állandóan jelent d. Ha lehal, nincs baj, a JobTracker újrafuttat egy másik TaskTracker-en Hadoop/Hive 19
20 Hive Lehetséges direktben MapReduce programot írni, tehat megadni a mapper (sin) és reducer (operator+) függvényeket egymás után, illetve a csomagoló (driver) programot. De ez még a FB-ban is ritka. Helyette = Hive, azaz Hive QL (HQL) SQL-szerű nyelv, amiből a Hive runtime legyártja a MapReduce programot HQL query HQL compiler.jar MapReduce job Két új szerep: HCatalog (séma, hol és hogyan), HiveServer (lekérdezések) Hadoop/Hive 20
21 Hadoop/Hive 21
 file.")
22 Hive táblák File-ok a HDFS elosztott filerendszeren hdfs://dwh/tablename/ds= /data.{csv,orc} Lehet akár CSV file is, vagy hatékonyabb formátumok, pl. FBnál Optimized Row Columnar (ORC) file. Hadoop/Hive 22
23 Hive plusz és minuszok Plusz: Sok adatra működik Hibatűrés, replikáció, nagy rendelkezésre állás (HDFS+MR) Viszonylag teljes SQL, UDF Moduláris, cserélhető komponensek (filerendszer, formátum, végrehajtás) Opensource Nem: (Nem ANSI SQL) Nem operatív adatbázis és... Hadoop/Hive 23
24 Probléma Hive-nál mindenképpen legyárt egy MapReduce programot, mindent elosztottan, batch-ben csinál, mindig ki kell várni egy nagy/hosszú soros folyamatot, ahol sok diszk írás is történik, nincs okos caching beleépítve. Pl. SELECT 1 vagy SELECT * FROM users LIMIT 10 is percekig tart :( Nem lehetne kisebb query-kre egy gyorsabb SQL motort használni? Hadoop/Hive 24
25 Presto FB-ban írták, opensource, 2013-tól fut. Ugyanazon HDFS elosztott klaszter felett ül, mint a Hive, de egy teljesen más, inmemory SQL execution engine (CSAK, DDL Hive-ban). Ha nem elég a memória, akkor ERROR, és át kell vinni a query-t Hive-ba. Nagyon gyors: csak memóriában workerek egymásnak streamelnek csak oszlop alapú nagyon gyors bytecode-ot generál kis query-k nagyobb prioritást kapnak nincs fault-tolerance Presto 25
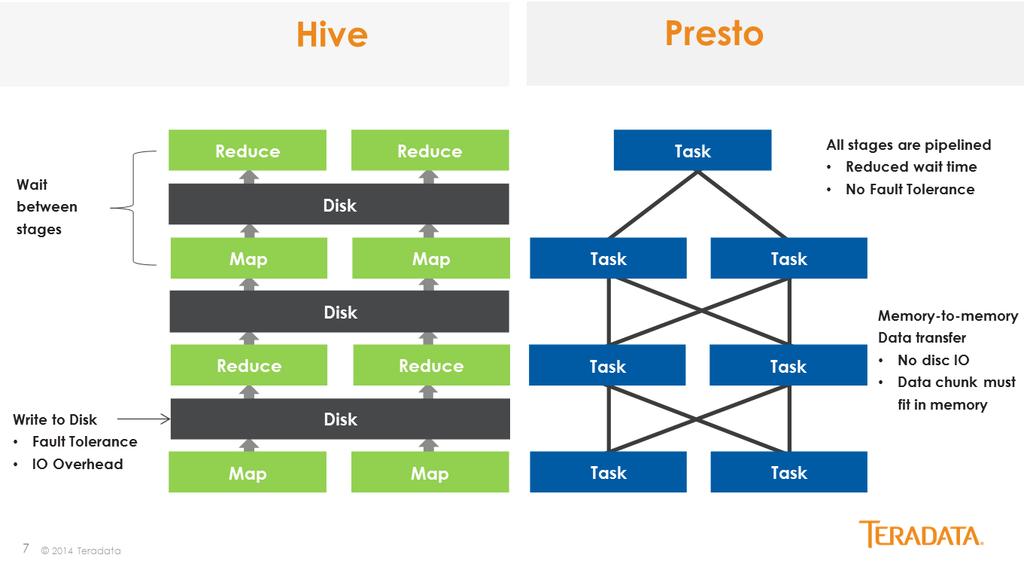
26 Presto 26
27 Tényleg :) Presto 27
28 Presto vs Hive Melyiket, mikor? 1. Facebook-ban eredetileg Hive volt, ezért a kb. 10,000+ ETL job nagy része HQL INSERT INTO... SELECT... FROM -ekből áll. 2. Új ETL jobokat már Presto-ban írnak, feltéve hogy lefut, egyébként visszaesnek Hive-ra. 3. A fontosabb jobokat migrálják Presto-ra (és Spark-ra). 4. Az analisták ( Data Scientist ) Presto lekérdezéseket írnak egész nap. a. Ha túl nagy Hive :( Presto 28
29 Event monitoring "Former Facebook employee and current Googler. I really really miss Scuba." 1. Nagy mennyiségű log adat, percenként milliárdos nagyságrendű eventszám. {ts: , post_id: , user_id: , length_msec: 600} 2. Monitoring, mind infra-ra, mind a termékre. Pl. kiraktunk egy új signup page-t, be tudnak jelentkezni az emberek? Magyarországon is, vagy elfelejtettük megcsinálni a lokalizációt? 3. 1 percen belül kell a válasz, különben több százmillió ember nem tud belépni. 4. Viszont, nem kellenek 100% pontosságú válaszok, elég ha látjuk h igen, be tudnak jelentkezni. Scuba 29
30 Scuba, 2011 Scuba 30
31 Adat betöltés 1. Nincsen definiált séma, a leaf node-ok direktben kapják az adatot a Scribe stream-ekből, egy Thrift API-n keresztül. 2. Minden blokk beérkező log sor esetén kiválaszt két véletlen Leaf Node-t, és az egyikre, amelyiken több szabad memória van, rakja az adatot. 3. Tehát az adatok, log kategória / táblától függetlenül minden Leaf Node-on szét vannak szórva. Replikáció nincs. 4. Minden adat log adat es az első mező a timestamp (index). 5. Nincs INSERT/UPDATE/DELETE, csak a fenti módon kerül be adat Scubaba. 6. Törlés: kor és tábla méret alapján (tipikus, 30 nap és 100GB ablak), ezen túl a legrégibb adatot ejti. Közben gzipelve diszken tárolja, de alapvetően memória alapú adatbázis (1 node 144GB), pár 1000 node. Scuba 31
32 Lekérdezés 1. Minden lekérdezés timestamp ablakra fut, nincs JOIN, nincs SUB-SELECT. 2. SELECT... WHERE... GROUP BY... ORDER BY... LIMIT. 3. Root Aggregator Node átveszi a query-t, leellenőrzi. AVG SUM+COUNT 4. Kiválaszt +4 Intermediate Aggregator Node-ot, és átadja nekik a lekérdezést. 5. Kiválaszt +4 Intermediate Aggregator Node-ot, és átadja nekik a lekérdezést Végül leérünk a Leaf Node-okhoz, azok kiszámolják a lokális adatokon. 8. Felfele progagál az eredmény, minden Aggregator kiszámolja az aggregátumokat. 9. Ha egy Lead Node nem válaszol 10 ms-on belül, kimarad. 10.Index csak timestamp-re van. 11.Minden szerveren futnak Leaf Node-ok és egy Aggregator Node. Scuba 32
33 Architektúra Scribe Thrift API 1 Leaf Node / CPU core Minden Lead Node-on van minden táblának adata! Scuba 33
34 Trükkök 1. Idő granularitás miatt (pl. óránként mutasd a görbét), majdnem mindig van GROUP BY. 2. Hogy lesz így AVG()? SUM() + COUNT() 3. Hogy lesz LIMIT? Best-effort: MAX(5 limit, 100) 4. Ha egy oszlop nincs ott mert megváltozott a loggolás NULL. 5. Legnagyobb trükk: a bejövő események mintavételezve vannak (még a Scuba előtt), minden sorban van egy speciális sample_rate=1...1,000,000 mező, ezt figyelembe veszi a SCUBA pl. COUNT() vagy SUM() számításnál! 6. Csak arra lehet szűrni, ami benne van a log sorban, pl. country, hiszen nincsen JOIN. Tehát kövér logsorokat kell beküldeni Scuba-ba! Scuba 34
35 Használat SLA UI: 1 másodpercen belül visszajön az eredmény az adatok >99% bele van számolva Monitoring Ha egy görbe beesik alert a megfelelő csapatnak Scuba 35
 Olcsóbb sok memóriát venni mint megoldani hogy kevesebb memóriával, diszken is működjön (ma egy 12 core + 192GB RAM Dell szerver ~$1000, ez kb.")
36 Tervezési elvek Iteratív, lehetőleg apró változások, kerüljük el az újraírást Építsünk a létező infrastruktúrára Jó mérnöki kompromisszumok (pl. csak in-memory) Olcsóbb sok memóriát venni mint megoldani hogy kevesebb memóriával, diszken is működjön (ma egy 12 core + 192GB RAM Dell szerver ~$1000, ez kb. 1-2 napi bére egy FB fejlesztőnek) Felhasználó kihasználása (Hive, Presto) Mi az ami elég? (Scuba) Bontsuk szét a problémát (Puma, Scuba) Csalás : ott dolgozik aki írta az adatbázis szoftvert... Konklúziók 36
 felett fut (zseniális, hasonló történt PHP/Hack téren is) Scuba nem kell precizitás, majdnem mindig az adat")
37 Záró gondolatok Hol érhető tetten a Facebook (user-adoption és üzleti) sikere a DWH architektúrában, annak környékén? Hive túl lassú, de ne migráljunk írjunk egy execution engine-t ami ugyanaz az adat (HDFS) felett fut (zseniális, hasonló történt PHP/Hack téren is) Scuba nem kell precizitás, majdnem mindig az adat 99% alapján is meg tudjuk hozni a döntéseinket Legnagyobb érték a termékfejlesztési sebesség (velocity) minél jobban változik a termék/csapatok, annál jobb nincs idő starschema-ra, minden tábla lapos, inkább megoldjuk sok hardverrel mi történt napnál régebben ritkán számít retention Konklúziók 37


38 Kérdések (és válaszok) Konklúziók 38
Hadoop és használata az LPDS cloud-on
 Hadoop és használata az LPDS cloud-on Bendig Loránd lbendig@ilab.sztaki.hu 2012.04.13 Miről lesz szó? Bevezetés Hadoop áttekintés OpenNebula Hadoop cluster az LPDS cloud-on Tapasztalatok, nyitott kérdések
Hadoop és használata az LPDS cloud-on Bendig Loránd lbendig@ilab.sztaki.hu 2012.04.13 Miről lesz szó? Bevezetés Hadoop áttekintés OpenNebula Hadoop cluster az LPDS cloud-on Tapasztalatok, nyitott kérdések
MMK-Informatikai projekt ellenőr képzés 4
 Miről lesz szó Big Data definíció Mi a Hadoop Hadoop működése, elemei Köré épülő technológiák Disztribúciók, Big Data a felhőben Miért, hol és hogyan használják Big Data definíció Miért Big a Data? 2017.
Miről lesz szó Big Data definíció Mi a Hadoop Hadoop működése, elemei Köré épülő technológiák Disztribúciók, Big Data a felhőben Miért, hol és hogyan használják Big Data definíció Miért Big a Data? 2017.
GENERÁCIÓS ADATBÁZISOK A BIG DATA KÜLÖNBÖZŐ TERÜLETEIN
 INFORMATIKAI PROJEKTELLENŐR 30 MB Szabó Csenger ÚJ GENERÁCIÓS ADATBÁZISOK A BIG DATA KÜLÖNBÖZŐ TERÜLETEIN 2016. 12. 31. MMK- Informatikai projektellenőr képzés Big Data definíció 2016. 12. 31. MMK-Informatikai
INFORMATIKAI PROJEKTELLENŐR 30 MB Szabó Csenger ÚJ GENERÁCIÓS ADATBÁZISOK A BIG DATA KÜLÖNBÖZŐ TERÜLETEIN 2016. 12. 31. MMK- Informatikai projektellenőr képzés Big Data definíció 2016. 12. 31. MMK-Informatikai
MapReduce paradigma a CAP-tétel kontextusában. Adatb haladóknak. Balassi Márton Adatbázisok haladóknak 2012.
 MapReduce paradigma a CAP-tétel kontextusában Balassi Márton balassi.marton@gmail.com 2012. október 30. Adatbázisok haladóknak 2012. 2012. október 30. Miről lesz szó? Elosztott adatfeldolgozásról általában
MapReduce paradigma a CAP-tétel kontextusában Balassi Márton balassi.marton@gmail.com 2012. október 30. Adatbázisok haladóknak 2012. 2012. október 30. Miről lesz szó? Elosztott adatfeldolgozásról általában
Weblog elemzés Hadoopon 1/39
 Weblog elemzés Hadoopon 1/39 Az előadás témái Egy Hadoop job életciklusa A Weblog-projekt 2/39 Mi a Hadoop? A Hadoop egy párhuzamos programozási séma egy implementációja. 3/39 A programozási séma: MapReduce
Weblog elemzés Hadoopon 1/39 Az előadás témái Egy Hadoop job életciklusa A Weblog-projekt 2/39 Mi a Hadoop? A Hadoop egy párhuzamos programozási séma egy implementációja. 3/39 A programozási séma: MapReduce
Élet az SQL-en túl: Az adatfeldolgozás legújabb trendjei. Földi Tamás
 Élet az SQL-en túl: Az adatfeldolgozás legújabb trendjei Földi Tamás tfoldi@starschema.net IBM Kutatóközpont San Jose, California, 1970 Negyven évvel később Gartner Report Elsősorban relációs adatbázisok
Élet az SQL-en túl: Az adatfeldolgozás legújabb trendjei Földi Tamás tfoldi@starschema.net IBM Kutatóközpont San Jose, California, 1970 Negyven évvel később Gartner Report Elsősorban relációs adatbázisok
Analitikai megoldások IBM Power és FlashSystem alapokon. Mosolygó Ferenc - Avnet
 Analitikai megoldások IBM Power és FlashSystem alapokon Mosolygó Ferenc - Avnet Bevezető Legfontosabb elvárásaink az adatbázisokkal szemben Teljesítmény Lekérdezések, riportok és válaszok gyors megjelenítése
Analitikai megoldások IBM Power és FlashSystem alapokon Mosolygó Ferenc - Avnet Bevezető Legfontosabb elvárásaink az adatbázisokkal szemben Teljesítmény Lekérdezések, riportok és válaszok gyors megjelenítése
Virtuális Obszervatórium. Gombos Gergő
 Virtuális Obszervatórium Gombos Gergő Áttekintés Motiváció, probléma felvetés Megoldások Virtuális obszervatóriumok NMVO Twitter VO Gombos Gergő Virtuális Obszervatórium 2 Motiváció Tudományos módszer
Virtuális Obszervatórium Gombos Gergő Áttekintés Motiváció, probléma felvetés Megoldások Virtuális obszervatóriumok NMVO Twitter VO Gombos Gergő Virtuális Obszervatórium 2 Motiváció Tudományos módszer
Valós idejű megoldások: Realtime ODS és Database In-Memory tapasztalatok
 Valós idejű megoldások: Realtime ODS és Database In-Memory tapasztalatok Pusztai Péter IT fejlesztési senior menedzser Magyar Telekom Sef Dániel Szenior IT tanácsadó T-Systems Magyarország 2016. április
Valós idejű megoldások: Realtime ODS és Database In-Memory tapasztalatok Pusztai Péter IT fejlesztési senior menedzser Magyar Telekom Sef Dániel Szenior IT tanácsadó T-Systems Magyarország 2016. április
Component Soft 1994-2013 és tovább
 Component Soft 1994-2013 és tovább IT szakemberek oktatása, tanácsadás Fő témáink: UNIX/Linux rendszerek, virtualizációs, fürtözési, tároló menedzsment és mentési technológiák Adatbázisok és middleware
Component Soft 1994-2013 és tovább IT szakemberek oktatása, tanácsadás Fő témáink: UNIX/Linux rendszerek, virtualizációs, fürtözési, tároló menedzsment és mentési technológiák Adatbázisok és middleware
Muppet: Gyors adatok MapReduce stílusú feldolgozása. Muppet: MapReduce-Style Processing of Fast Data
 Muppet: Gyors adatok MapReduce stílusú feldolgozása Muppet: MapReduce-Style Processing of Fast Data Tartalom Bevezető MapReduce MapUpdate Muppet 1.0 Muppet 2.0 Eredmények Jelenlegi tendenciák Nagy mennyiségű
Muppet: Gyors adatok MapReduce stílusú feldolgozása Muppet: MapReduce-Style Processing of Fast Data Tartalom Bevezető MapReduce MapUpdate Muppet 1.0 Muppet 2.0 Eredmények Jelenlegi tendenciák Nagy mennyiségű
Magic xpi 4.0 vadonatúj Architektúrája Gigaspaces alapokon
 Magic xpi 4.0 vadonatúj Architektúrája Gigaspaces alapokon Mi az IMDG? Nem memóriában futó relációs adatbázis NoSQL hagyományos relációs adatbázis Más fajta adat tárolás Az összes adat RAM-ban van, osztott
Magic xpi 4.0 vadonatúj Architektúrája Gigaspaces alapokon Mi az IMDG? Nem memóriában futó relációs adatbázis NoSQL hagyományos relációs adatbázis Más fajta adat tárolás Az összes adat RAM-ban van, osztott
Rendszermodernizációs lehetőségek a HANA-val Poszeidon. Groma István PhD SDA DMS Zrt.
 Rendszermodernizációs lehetőségek a HANA-val Poszeidon Groma István PhD SDA DMS Zrt. Poszeidon EKEIDR Tanúsított ügyviteli rendszer (3/2018. (II. 21.) BM rendelet). Munkafolyamat támogatás. Papírmentes
Rendszermodernizációs lehetőségek a HANA-val Poszeidon Groma István PhD SDA DMS Zrt. Poszeidon EKEIDR Tanúsított ügyviteli rendszer (3/2018. (II. 21.) BM rendelet). Munkafolyamat támogatás. Papírmentes
Riak. Pronounced REE-ahk. Elosztott adattároló eszköz. Molnár Péter molnarp@ilab.sztaki.hu
 Riak Pronounced REE-ahk Elosztott adattároló eszköz Molnár Péter molnarp@ilab.sztaki.hu Mi a Riak? A Database A Data Store A key/value store A NoSQL database Schemaless and data-type agnostic Written (primarily)
Riak Pronounced REE-ahk Elosztott adattároló eszköz Molnár Péter molnarp@ilab.sztaki.hu Mi a Riak? A Database A Data Store A key/value store A NoSQL database Schemaless and data-type agnostic Written (primarily)
Excel ODBC-ADO API. Tevékenységpontok: - DBMS telepítés. - ODBC driver telepítése. - DSN létrehozatala. -Excel-ben ADO bevonása
 DBMS spektrum Excel ODBC-ADO API Tevékenységpontok: - DBMS telepítés - ODBC driver telepítése - DSN létrehozatala -Excel-ben ADO bevonása - ADOConnection objektum létrehozatala - Open: kapcsolat felvétel
DBMS spektrum Excel ODBC-ADO API Tevékenységpontok: - DBMS telepítés - ODBC driver telepítése - DSN létrehozatala -Excel-ben ADO bevonása - ADOConnection objektum létrehozatala - Open: kapcsolat felvétel
Adatbázisok* tulajdonságai
 Gazdasági folyamatok térbeli elemzése 4. előadás 2010. 10. 05. Adatbázisok* tulajdonságai Rendezett, logikailag összefüggő és meghatározott szempont szerint tárolt adatok és/vagy információk halmaza Az
Gazdasági folyamatok térbeli elemzése 4. előadás 2010. 10. 05. Adatbázisok* tulajdonságai Rendezett, logikailag összefüggő és meghatározott szempont szerint tárolt adatok és/vagy információk halmaza Az
Adatbázisok elleni fenyegetések rendszerezése. Fleiner Rita BMF/NIK Robothadviselés 2009
 Adatbázisok elleni fenyegetések rendszerezése Fleiner Rita BMF/NIK Robothadviselés 2009 Előadás tartalma Adatbázis biztonsággal kapcsolatos fogalmak értelmezése Rendszertani alapok Rendszerezési kategóriák
Adatbázisok elleni fenyegetések rendszerezése Fleiner Rita BMF/NIK Robothadviselés 2009 Előadás tartalma Adatbázis biztonsággal kapcsolatos fogalmak értelmezése Rendszertani alapok Rendszerezési kategóriák
Adatbázis rendszerek 7. előadás State of the art
 Adatbázis rendszerek 7. előadás State of the art Molnár Bence Szerkesztette: Koppányi Zoltán Osztott adatbázisok Osztott rendszerek Mi is ez? Mi teszi lehetővé? Nagy sebességű hálózat Egyre olcsóbb, és
Adatbázis rendszerek 7. előadás State of the art Molnár Bence Szerkesztette: Koppányi Zoltán Osztott adatbázisok Osztott rendszerek Mi is ez? Mi teszi lehetővé? Nagy sebességű hálózat Egyre olcsóbb, és
Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása. Rákosi Péter és Lányi Árpád
 Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása Rákosi Péter és Lányi Árpád Adattárház korábbi üzemeltetési jellemzői Online szolgáltatásokat nem szolgált ki, klasszikus elemzésre
Vodafone ODI ETL eszközzel töltött adattárház Disaster Recovery megoldása Rákosi Péter és Lányi Árpád Adattárház korábbi üzemeltetési jellemzői Online szolgáltatásokat nem szolgált ki, klasszikus elemzésre
LOGISZTIKAI ADATBÁZIS RENDSZEREK JOIN, AGGREGÁCIÓ
 LOGISZTIKAI ADATBÁZIS RENDSZEREK JOIN, AGGREGÁCIÓ Lénárt Balázs tanársegéd TANTERV Hét Dátum Előadó Előadások Időpont: szerda 8:30-10:00, helye: LFSZÁMG Dátum Gyakvezető 1. 9. 11. Tokodi Adatbázis kezelés
LOGISZTIKAI ADATBÁZIS RENDSZEREK JOIN, AGGREGÁCIÓ Lénárt Balázs tanársegéd TANTERV Hét Dátum Előadó Előadások Időpont: szerda 8:30-10:00, helye: LFSZÁMG Dátum Gyakvezető 1. 9. 11. Tokodi Adatbázis kezelés
Adatbázisok. 9. gyakorlat SQL: SELECT október október 26. Adatbázisok 1 / 14
 Adatbázisok 9. gyakorlat SQL: SELECT 2015. október 26. 2015. október 26. Adatbázisok 1 / 14 SQL SELECT Lekérdezésre a SELECT utasítás szolgál, mely egy vagy több adattáblából egy eredménytáblát állít el
Adatbázisok 9. gyakorlat SQL: SELECT 2015. október 26. 2015. október 26. Adatbázisok 1 / 14 SQL SELECT Lekérdezésre a SELECT utasítás szolgál, mely egy vagy több adattáblából egy eredménytáblát állít el
Exadata hibrid oszlopos adattömörítés automatizálása; DB 12c partition merge
 Exadata hibrid oszlopos adattömörítés automatizálása; DB 12c partition merge HOUG Konferencia 2017. március 28. Németh Márk Principal Programmer Analyst National Instruments Tömörítési módok OLTP Exadata
Exadata hibrid oszlopos adattömörítés automatizálása; DB 12c partition merge HOUG Konferencia 2017. március 28. Németh Márk Principal Programmer Analyst National Instruments Tömörítési módok OLTP Exadata
Adatbázis-kezelés. Harmadik előadás
 Adatbázis-kezelés Harmadik előadás 39 Műveletek csoportosítása DDL adat definiálás Objektum létrehozás CREATE Objektum törlés DROP Objektum módosítás ALTER DML adat módosítás Rekord felvitel INSERT Rekord
Adatbázis-kezelés Harmadik előadás 39 Műveletek csoportosítása DDL adat definiálás Objektum létrehozás CREATE Objektum törlés DROP Objektum módosítás ALTER DML adat módosítás Rekord felvitel INSERT Rekord
SQL*Plus. Felhasználók: SYS: rendszergazda SCOTT: demonstrációs adatbázis, táblái: EMP (dolgozó), DEPT (osztály) "közönséges" felhasználók
, DEPT (osztály) közönséges felhasználók") SQL*Plus Felhasználók: SYS: rendszergazda SCOTT: demonstrációs adatbázis, táblái: EMP dolgozó), DEPT osztály) "közönséges" felhasználók Adatszótár: metaadatokat tartalmazó, csak olvasható táblák táblanév-prefixek:
SQL*Plus Felhasználók: SYS: rendszergazda SCOTT: demonstrációs adatbázis, táblái: EMP dolgozó), DEPT osztály) "közönséges" felhasználók Adatszótár: metaadatokat tartalmazó, csak olvasható táblák táblanév-prefixek:
Big Data tömeges adatelemzés gyorsan
 MEDIANET 2015 Big Data tömeges adatelemzés gyorsan STADLER GELLÉRT Oracle Hungary Kft. gellert.stadler@oracle.com Kulcsszavak: big data, döntéstámogatás, hadoop, üzleti intelligencia Az utóbbi években
MEDIANET 2015 Big Data tömeges adatelemzés gyorsan STADLER GELLÉRT Oracle Hungary Kft. gellert.stadler@oracle.com Kulcsszavak: big data, döntéstámogatás, hadoop, üzleti intelligencia Az utóbbi években
ADATBÁZISOK gyakorlat: SQL 2. rész SELECT
 ADATBÁZISOK 9-10. gyakorlat: SQL 2. rész SELECT SELECT utasítás általános alakja SELECT [DISTINCT] oszloplista FROM táblanévlista [WHERE feltétel] [GROUP BY oszloplista [HAVING feltétel] ] [ORDER BY oszloplista];
ADATBÁZISOK 9-10. gyakorlat: SQL 2. rész SELECT SELECT utasítás általános alakja SELECT [DISTINCT] oszloplista FROM táblanévlista [WHERE feltétel] [GROUP BY oszloplista [HAVING feltétel] ] [ORDER BY oszloplista];
Indexek és SQL hangolás
 Indexek és SQL hangolás Ableda Péter abledapeter@gmail.com Adatbázisok haladóknak 2012. 2012. november 20. Miről lesz szó? Történelem Oracle B*-fa Index Felépítése, karbantartása, típusai Bitmap index
Indexek és SQL hangolás Ableda Péter abledapeter@gmail.com Adatbázisok haladóknak 2012. 2012. november 20. Miről lesz szó? Történelem Oracle B*-fa Index Felépítése, karbantartása, típusai Bitmap index
Adatbázisok. 8. gyakorlat. SQL: CREATE TABLE, aktualizálás (INSERT, UPDATE, DELETE), SELECT október október 26. Adatbázisok 1 / 17
, SELECT október október 26. Adatbázisok 1 / 17") Adatbázisok 8. gyakorlat SQL: CREATE TABLE, aktualizálás (INSERT, UPDATE, DELETE), SELECT 2015. október 26. 2015. október 26. Adatbázisok 1 / 17 SQL nyelv Structured Query Language Struktúrált lekérdez
Adatbázisok 8. gyakorlat SQL: CREATE TABLE, aktualizálás (INSERT, UPDATE, DELETE), SELECT 2015. október 26. 2015. október 26. Adatbázisok 1 / 17 SQL nyelv Structured Query Language Struktúrált lekérdez
Tábla létrehozása: CREATE TABLE alma( ID INT( 3 ) NOT NULL PRIMARY KEY, Leiras VARCHAR( 100 ) );
 NOT NULL PRIMARY KEY, Leiras VARCHAR( 100 ) );") Tábla létrehozása: CREATE TABLE alma( ID INT( 3 ) NOT NULL PRIMARY KEY, Leiras VARCHAR( 100 ) ); CREATE TABLE `dihunor`.`csapat` ( `ID` INT( 4 ) NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT 'A csapat azonositoja',
Tábla létrehozása: CREATE TABLE alma( ID INT( 3 ) NOT NULL PRIMARY KEY, Leiras VARCHAR( 100 ) ); CREATE TABLE `dihunor`.`csapat` ( `ID` INT( 4 ) NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT 'A csapat azonositoja',
Nagy adathalmazok elosztott feldolgozása. Dr. Hajdu András, Debreceni Egyetem, Informatikai Kar
 Nagy adathalmazok elosztott feldolgozása Dr. Hajdu András, Debreceni Egyetem, Informatikai Kar Mi a Big Data? Nem létezik egzakt Big Data definíció. A big data kifejezést a mai értelemben először Cox és
Nagy adathalmazok elosztott feldolgozása Dr. Hajdu András, Debreceni Egyetem, Informatikai Kar Mi a Big Data? Nem létezik egzakt Big Data definíció. A big data kifejezést a mai értelemben először Cox és
Adatbázis kezelés Delphiben. SQL lekérdezések
 Adatbázis kezelés Delphiben. SQL lekérdezések Structured Query Language adatbázisok kezelésére szolgáló lekérdező nyelv Szabályok: Utasítások tetszés szerint tördelhetők Utasítások végét pontosvessző zárja
Adatbázis kezelés Delphiben. SQL lekérdezések Structured Query Language adatbázisok kezelésére szolgáló lekérdező nyelv Szabályok: Utasítások tetszés szerint tördelhetők Utasítások végét pontosvessző zárja
Nem klaszterezett index. Klaszterezett index. Beágyazott oszlopok. Index kitöltési faktor. Indexek tulajdonságai
 1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
RHadoop. Kocsis Imre Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék
 RHadoop Kocsis Imre ikocsis@mit.bme.hu Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Házi feladat Csapatépítés o 2 fő, tetszőleges kombinációkban http://goo.gl/m8yzwq
RHadoop Kocsis Imre ikocsis@mit.bme.hu Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Házi feladat Csapatépítés o 2 fő, tetszőleges kombinációkban http://goo.gl/m8yzwq
SQL DDL-2 (aktív elemek) triggerek
 triggerek") SQL DDL-2 (aktív elemek) triggerek Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 7.fej.: Megszorítások és triggerek 7.4. Önálló megszorítások 7.5. Triggerek
SQL DDL-2 (aktív elemek) triggerek Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 7.fej.: Megszorítások és triggerek 7.4. Önálló megszorítások 7.5. Triggerek
Kutatási fázis eredményei. Turi Péter turip@iig.elte.hu
 Kutatási fázis eredményei Turi Péter turip@iig.elte.hu Cloud szolgáltatások osztályozása Rendszergazda Programozó Felhasználó IaaS + + + PaaS + + SaaS + Alapvető karakterisztikák NIST Definition of Cloud
Kutatási fázis eredményei Turi Péter turip@iig.elte.hu Cloud szolgáltatások osztályozása Rendszergazda Programozó Felhasználó IaaS + + + PaaS + + SaaS + Alapvető karakterisztikák NIST Definition of Cloud
Data Integrátorok a gyakorlatban Oracle DI vs. Pentaho DI Fekszi Csaba Ügyvezető Vinnai Péter Adattárház fejlesztő 2013. február 20.
 Data Integrátorok a gyakorlatban Oracle DI vs. Pentaho DI Fekszi Csaba Ügyvezető Vinnai Péter Adattárház fejlesztő 2013. február 20. 1 2 3 4 5 6 7 8 Pentaho eszköztára Data Integrator Spoon felület Spoon
Data Integrátorok a gyakorlatban Oracle DI vs. Pentaho DI Fekszi Csaba Ügyvezető Vinnai Péter Adattárház fejlesztő 2013. február 20. 1 2 3 4 5 6 7 8 Pentaho eszköztára Data Integrator Spoon felület Spoon
B I T M A N B I v: T 2015.03.01 M A N
 Adatbázis Rendszerek MSc 2. Gy: MySQL Táblák, adatok B I v: T 2015.03.01 M A N 1/41 Témakörök SQL alapok DDL utasítások DML utasítások DQL utasítások DCL utasítások 2/41 Az SQL jellemzése Az SQL a relációs
Adatbázis Rendszerek MSc 2. Gy: MySQL Táblák, adatok B I v: T 2015.03.01 M A N 1/41 Témakörök SQL alapok DDL utasítások DML utasítások DQL utasítások DCL utasítások 2/41 Az SQL jellemzése Az SQL a relációs
A gyakorlat során MySQL adatbázis szerver és a böngészőben futó phpmyadmin használata javasolt. A gyakorlat során a következőket fogjuk gyakorolni:
 1 Adatbázis kezelés 3. gyakorlat A gyakorlat során MySQL adatbázis szerver és a böngészőben futó phpmyadmin használata javasolt. A gyakorlat során a következőket fogjuk gyakorolni: Tábla kapcsolatok létrehozása,
1 Adatbázis kezelés 3. gyakorlat A gyakorlat során MySQL adatbázis szerver és a böngészőben futó phpmyadmin használata javasolt. A gyakorlat során a következőket fogjuk gyakorolni: Tábla kapcsolatok létrehozása,
Nem klaszterezett index. Beágyazott oszlopok. Klaszterezett index. Indexek tulajdonságai. Index kitöltési faktor
 1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
1 2 Nem klaszterezett indexek Egy táblán csak egy klaszterezett index lehet Ha más oszlop szerint is keresni akarunk, nem klaszterezett indexeket használunk A tábla mellett megjelenő adatstruktúra Egy
Az indexelés újdonságai Oracle Database 12c R1 és 12c R2
 Az indexelés újdonságai Oracle Database 12c R1 és 12c R2 Szabó Rozalinda Oracle adattárház szakértő, oktató szabo.rozalinda@gmail.com Index tömörítés fejlődése 8.1.3-as verziótól: Basic (Prefixes) index
Az indexelés újdonságai Oracle Database 12c R1 és 12c R2 Szabó Rozalinda Oracle adattárház szakértő, oktató szabo.rozalinda@gmail.com Index tömörítés fejlődése 8.1.3-as verziótól: Basic (Prefixes) index
Felhő alapú hálózatok Konténerek orkesztrálása Simon Csaba. Budapesti Műszaki és Gazdaságtudományi Egyetem
 Felhő alapú hálózatok Konténerek orkesztrálása Simon Csaba Budapesti Műszaki és Gazdaságtudományi Egyetem 1 Motiváció multi host» Docker konténerek docker parancsokkal kezelhetők» Adott gazda gépen (on-host)»
Felhő alapú hálózatok Konténerek orkesztrálása Simon Csaba Budapesti Műszaki és Gazdaságtudományi Egyetem 1 Motiváció multi host» Docker konténerek docker parancsokkal kezelhetők» Adott gazda gépen (on-host)»
VvAaLlÓóSs IiıDdEeJjȷŰű OoDdSs goldengate alapokon a magyar telekomban
 VvAaLlÓóSs IiıDdEeJjȷŰű OoDdSs goldengate alapokon a magyar telekomban Pusztai Péter IT fejlesztési senior menedzser Magyar Telekom Medveczki György szenior IT architekt T-Systems Magyarország 2014. március
VvAaLlÓóSs IiıDdEeJjȷŰű OoDdSs goldengate alapokon a magyar telekomban Pusztai Péter IT fejlesztési senior menedzser Magyar Telekom Medveczki György szenior IT architekt T-Systems Magyarország 2014. március
MySQL kontra MongoDB programozás. SQL és NoSQL megközelítés egy konkrét példán keresztül
 MySQL kontra MongoDB programozás SQL és NoSQL megközelítés egy konkrét példán keresztül Kardos Sándor sandor@component.hu Miről lesz szó? Miért érdemes őket összehasonlítani? MySQL általános jellemzői
MySQL kontra MongoDB programozás SQL és NoSQL megközelítés egy konkrét példán keresztül Kardos Sándor sandor@component.hu Miről lesz szó? Miért érdemes őket összehasonlítani? MySQL általános jellemzői
A könyv tartalomjegyzéke
 A könyv tartalomjegyzéke Elıszó Bevezetés Adatbázis-kezelı rendszerek Adatmodellezés Alapfogalmak Egyedhalmaz, egyed Kapcsolat, kapcsolat-elıfordulás, kapcsolat típusa Tulajdonság, tulajdonságérték, értékhalmaz
A könyv tartalomjegyzéke Elıszó Bevezetés Adatbázis-kezelı rendszerek Adatmodellezés Alapfogalmak Egyedhalmaz, egyed Kapcsolat, kapcsolat-elıfordulás, kapcsolat típusa Tulajdonság, tulajdonságérték, értékhalmaz
SQL haladó. Külső összekapcsolások, Csoportosítás/Összesítés, Beszúrás/Törlés/Módosítás, Táblák létrehozása/kulcs megszorítások
 SQL haladó Külső összekapcsolások, Csoportosítás/Összesítés, Beszúrás/Törlés/Módosítás, Táblák létrehozása/kulcs megszorítások 1 Külső összekapcsolás Összekapcsoljuk R és S relációkat: R C S. R azon sorait,
SQL haladó Külső összekapcsolások, Csoportosítás/Összesítés, Beszúrás/Törlés/Módosítás, Táblák létrehozása/kulcs megszorítások 1 Külső összekapcsolás Összekapcsoljuk R és S relációkat: R C S. R azon sorait,
BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA CLOUD-ON KACSUK PÉTER, NAGY ENIKŐ, PINTYE ISTVÁN, HAJNAL ÁKOS, LOVAS RÓBERT
 BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA CLOUD-ON KACSUK PÉTER, NAGY ENIKŐ, PINTYE ISTVÁN, HAJNAL ÁKOS, LOVAS RÓBERT TARTALOM MTA Cloud Big Data és gépi tanulást támogató szoftver eszközök Apache Spark
BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA CLOUD-ON KACSUK PÉTER, NAGY ENIKŐ, PINTYE ISTVÁN, HAJNAL ÁKOS, LOVAS RÓBERT TARTALOM MTA Cloud Big Data és gépi tanulást támogató szoftver eszközök Apache Spark
Big Data adattárházas szemmel. Arató Bence ügyvezető, BI Consulting
 Big Data adattárházas szemmel Arató Bence ügyvezető, BI Consulting 1 Bemutatkozás 15 éves szakmai tapasztalat az üzleti intelligencia és adattárházak területén A BI Consulting szakmai igazgatója A BI.hu
Big Data adattárházas szemmel Arató Bence ügyvezető, BI Consulting 1 Bemutatkozás 15 éves szakmai tapasztalat az üzleti intelligencia és adattárházak területén A BI Consulting szakmai igazgatója A BI.hu
Adatbázis-lekérdezés. Az SQL nyelv. Makány György
 Adatbázis-lekérdezés Az SQL nyelv Makány György SQL (Structured Query Language=struktúrált lekérdező nyelv): relációs adatbázisok adatainak visszakeresésére, frissítésére, kezelésére szolgáló nyelv. Születési
Adatbázis-lekérdezés Az SQL nyelv Makány György SQL (Structured Query Language=struktúrált lekérdező nyelv): relációs adatbázisok adatainak visszakeresésére, frissítésére, kezelésére szolgáló nyelv. Születési
Tartalomjegyzék. Tartalomjegyzék 1. Az SQL nyelv 1 Az SQL DDL alapjai 2
 Tartalomjegyzék Tartalomjegyzék 1 Az SQL nyelv 1 Az SQL DDL alapjai 2 Adatbázis parancsok 2 Táblaparancsok 2 A táblázat létrehozása 2 A táblázat módosítása 3 A tábla törlése 3 Indextábla létrehozása 3
Tartalomjegyzék Tartalomjegyzék 1 Az SQL nyelv 1 Az SQL DDL alapjai 2 Adatbázis parancsok 2 Táblaparancsok 2 A táblázat létrehozása 2 A táblázat módosítása 3 A tábla törlése 3 Indextábla létrehozása 3
Az MTA Cloud a tudományos alkalmazások támogatására. Kacsuk Péter MTA SZTAKI
 Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Az MTA Cloud a tudományos alkalmazások támogatására Kacsuk Péter MTA SZTAKI Kacsuk.Peter@sztaki.mta.hu Tudományos alkalmazások és skálázhatóság Kétféle skálázhatóság: o Vertikális: dinamikusan változik
Elemi alkalmazások fejlesztése IV.
 Structured Query Language (Struktúrált lekérdez ı nyelv) Relációs adatbázisok kezelésére kifejlesztett szabvány né Nacsa Rozália nacsa@inf.elte.hu Fejlesztı : MySQLAB weboldal: www.mysql.com MySQL installálása.
Structured Query Language (Struktúrált lekérdez ı nyelv) Relációs adatbázisok kezelésére kifejlesztett szabvány né Nacsa Rozália nacsa@inf.elte.hu Fejlesztı : MySQLAB weboldal: www.mysql.com MySQL installálása.
Amazon Web Services. Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28.
 Amazon Web Services Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28. Ez nem egy könyváruház? 1994-ben alapította Jeff Bezos Túlélte a dot-com korszakot Eredetileg könyváruház majd az elérhető
Amazon Web Services Géhberger Dániel Szolgáltatások és alkalmazások 2013. március 28. Ez nem egy könyváruház? 1994-ben alapította Jeff Bezos Túlélte a dot-com korszakot Eredetileg könyváruház majd az elérhető
Oracle Big Data koncepció. Stadler Gellért Vezető tanácsadó Oracle ConsulKng HTE 2015 Konferencia
 Oracle Big Data koncepció Stadler Gellért Vezető tanácsadó Oracle ConsulKng HTE 2015 Konferencia Copyright 2015, Oracle and/or its affiliates. All rights reserved. Oracle ConfidenKal Internal/Restricted/Highly
Oracle Big Data koncepció Stadler Gellért Vezető tanácsadó Oracle ConsulKng HTE 2015 Konferencia Copyright 2015, Oracle and/or its affiliates. All rights reserved. Oracle ConfidenKal Internal/Restricted/Highly
Csima Judit szeptember 6.
 Adatbáziskezelés, bevezető Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2017. szeptember 6. Csima Judit Adatbáziskezelés, bevezető 1 / 20 Órák, emberek heti két óra: szerda 14.15-16.00
Adatbáziskezelés, bevezető Csima Judit BME, VIK, Számítástudományi és Információelméleti Tanszék 2017. szeptember 6. Csima Judit Adatbáziskezelés, bevezető 1 / 20 Órák, emberek heti két óra: szerda 14.15-16.00
Operációs rendszerek. UNIX fájlrendszer
 Operációs rendszerek UNIX fájlrendszer UNIX fájlrendszer Alapegység: a file, amelyet byte-folyamként kezel. Soros (szekvenciális) elérés. Transzparens (átlátszó) file-szerkezet. Link-ek (kapcsolatok) létrehozásának
Operációs rendszerek UNIX fájlrendszer UNIX fájlrendszer Alapegység: a file, amelyet byte-folyamként kezel. Soros (szekvenciális) elérés. Transzparens (átlátszó) file-szerkezet. Link-ek (kapcsolatok) létrehozásának
Készítette: Szabóné Nacsa Rozália
 Készítette: Szabóné Nacsa Rozália nacsa@inf.elte.hu 1 Structured Query Language (Struktúrált lekérdező nyelv) Relációs adatbázisok kezelésére kifejlesztett szabvány 2 DIAKOK dkód vnév knév 1001 Kiss János
Készítette: Szabóné Nacsa Rozália nacsa@inf.elte.hu 1 Structured Query Language (Struktúrált lekérdező nyelv) Relációs adatbázisok kezelésére kifejlesztett szabvány 2 DIAKOK dkód vnév knév 1001 Kiss János
Tipikus időbeli internetezői profilok nagyméretű webes naplóállományok alapján
 Tipikus időbeli internetezői profilok nagyméretű webes naplóállományok alapján Schrádi Tamás schraditamas@aut.bme.hu Automatizálási és Alkalmazott Informatikai Tanszék BME A feladat A webszerverek naplóállományainak
Tipikus időbeli internetezői profilok nagyméretű webes naplóállományok alapján Schrádi Tamás schraditamas@aut.bme.hu Automatizálási és Alkalmazott Informatikai Tanszék BME A feladat A webszerverek naplóállományainak
ADATBÁZIS-KEZELÉS - BEVEZETŐ - Tarcsi Ádám, ade@inf.elte.hu
 ADATBÁZIS-KEZELÉS - BEVEZETŐ - Tarcsi Ádám, ade@inf.elte.hu Számonkérés 2 Papíros (90 perces) zh az utolsó gyakorlaton. Segédanyag nem használható Tematika 1. félév 3 Óra Dátum Gyakorlat 1. 2010.09.28.
ADATBÁZIS-KEZELÉS - BEVEZETŐ - Tarcsi Ádám, ade@inf.elte.hu Számonkérés 2 Papíros (90 perces) zh az utolsó gyakorlaton. Segédanyag nem használható Tematika 1. félév 3 Óra Dátum Gyakorlat 1. 2010.09.28.
Tranzakciókezelés PL/SQL-ben
 Tranzakciókezelés PL/SQL-ben ACID tulajdonságok: Tranzakció Atomosság, Konzisztencia, Izoláció, Tartósság A tranzakció állhat: - Több DML utasításból - Egy DDL utasításból A tranzakció kezdete az első
Tranzakciókezelés PL/SQL-ben ACID tulajdonságok: Tranzakció Atomosság, Konzisztencia, Izoláció, Tartósság A tranzakció állhat: - Több DML utasításból - Egy DDL utasításból A tranzakció kezdete az első
Webes alkalmazások fejlesztése 11. előadás. Alkalmazások felhőben. Alkalmazások felhőben Számítástechnikai felhő
 Eötvös Loránd Tudományegyetem Informatikai Kar Webes alkalmazások fejlesztése 11. előadás Számítástechnikai felhő A számítástechnikai felhő (computational cloud) egy olyan szolgáltatás alapú rendszer,
Eötvös Loránd Tudományegyetem Informatikai Kar Webes alkalmazások fejlesztése 11. előadás Számítástechnikai felhő A számítástechnikai felhő (computational cloud) egy olyan szolgáltatás alapú rendszer,
Új komponens a Talend Palettán: Starschema SAP Connector. Csillag Péter, Földi Tamás Starschema Kft.
 Új komponens a Talend Palettán: Starschema SAP Connector Csillag Péter, Földi Tamás Starschema Kft. Kötelező marketing helye A Starschema Csapat Miért csináltuk? http://agustis-place.blogspot.com/2010/01/4th-eso-msc-computer-assisted-task-unit.html
Új komponens a Talend Palettán: Starschema SAP Connector Csillag Péter, Földi Tamás Starschema Kft. Kötelező marketing helye A Starschema Csapat Miért csináltuk? http://agustis-place.blogspot.com/2010/01/4th-eso-msc-computer-assisted-task-unit.html
Bevezetés: az SQL-be
 Bevezetés: az SQL-be Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 2.3. Relációsémák definiálása SQL-ben, adattípusok, kulcsok megadása 02B_BevSQLsemak
Bevezetés: az SQL-be Tankönyv: Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 2.3. Relációsémák definiálása SQL-ben, adattípusok, kulcsok megadása 02B_BevSQLsemak
Nézetek és indexek. AB1_06C_Nézetek_Indexek - Adatbázisok-1 EA (Hajas Csilla, ELTE IK) - J.D. Ullman elıadásai alapján
 - J.D. Ullman elıadásai alapján") Nézetek és indexek Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 8.1. Nézettáblák 8.2. Adatok módosítása nézettáblákon keresztül 8.3. Indexek az SQL-ben 8.4. Indexek
Nézetek és indexek Ullman-Widom: Adatbázisrendszerek Alapvetés Második, átdolgozott kiadás, Panem, 2009 8.1. Nézettáblák 8.2. Adatok módosítása nézettáblákon keresztül 8.3. Indexek az SQL-ben 8.4. Indexek
TELJESÍTÉNYMÉRÉS FELHŐ ALAPÚ KÖRNYEZETBEN AZURE CLOUD ANALÍZIS
 TELJESÍTÉNYMÉRÉS FELHŐ ALAPÚ KÖRNYEZETBEN AZURE CLOUD ANALÍZIS Hartung István BME Irányítástechnika és Informatika Tanszék TEMATIKA Cloud definíció, típusok, megvalósítási modellek Rövid Azure cloud bemutatás
TELJESÍTÉNYMÉRÉS FELHŐ ALAPÚ KÖRNYEZETBEN AZURE CLOUD ANALÍZIS Hartung István BME Irányítástechnika és Informatika Tanszék TEMATIKA Cloud definíció, típusok, megvalósítási modellek Rövid Azure cloud bemutatás
SQLServer. SQLServer konfigurációk
 SQLServer 2. téma DBMS installáció SQLServer konfigurációk 1 SQLServer konfigurációk SQLServer konfigurációk Enterprise Edition Standart Edition Workgroup Edition Developer Edition Express Edition 2 Enterprise
SQLServer 2. téma DBMS installáció SQLServer konfigurációk 1 SQLServer konfigurációk SQLServer konfigurációk Enterprise Edition Standart Edition Workgroup Edition Developer Edition Express Edition 2 Enterprise
Adatbázis használata PHP-ből
 Adatbázis használata PHP-ből Adatbázis használata PHP-ből...1 Nyílt forráskódú adatbázisok...1 A mysql függvények...2 A mysqli függvények...4 Bináris adatok adatbázisban való tárolása...8 Adatbázis csatoló
Adatbázis használata PHP-ből Adatbázis használata PHP-ből...1 Nyílt forráskódú adatbázisok...1 A mysql függvények...2 A mysqli függvények...4 Bináris adatok adatbázisban való tárolása...8 Adatbázis csatoló
Adatbányászat és Perszonalizáció architektúra
 Adatbányászat és Perszonalizáció architektúra Oracle9i Teljes e-üzleti intelligencia infrastruktúra Oracle9i Database Integrált üzleti intelligencia szerver Data Warehouse ETL OLAP Data Mining M e t a
Adatbányászat és Perszonalizáció architektúra Oracle9i Teljes e-üzleti intelligencia infrastruktúra Oracle9i Database Integrált üzleti intelligencia szerver Data Warehouse ETL OLAP Data Mining M e t a
8. Gyakorlat SQL. DDL (Data Definition Language) adatdefiníciós nyelv utasításai:
 adatdefiníciós nyelv utasításai:") 8. Gyakorlat SQL SQL: Structured Query Language; a relációs adatbáziskezelők szabványos, strukturált lekérdező nyelve SQL szabványok: SQL86, SQL89, SQL92, SQL99, SQL3 Az SQL utasításokat mindig pontosvessző
8. Gyakorlat SQL SQL: Structured Query Language; a relációs adatbáziskezelők szabványos, strukturált lekérdező nyelve SQL szabványok: SQL86, SQL89, SQL92, SQL99, SQL3 Az SQL utasításokat mindig pontosvessző
LBRA6i integrált rendszer
 LBRA6i integrált rendszer LIBRA 6i logolás és a log megtekintése Készítette: Libra Szoftver Zrt. Létrehozás dátuma: 2005.12.15. Utolsó módosítás: 2014.10.30. Referencia szám: LIBRA6i_UZEM_V_1.5 Verzió:
LBRA6i integrált rendszer LIBRA 6i logolás és a log megtekintése Készítette: Libra Szoftver Zrt. Létrehozás dátuma: 2005.12.15. Utolsó módosítás: 2014.10.30. Referencia szám: LIBRA6i_UZEM_V_1.5 Verzió:
Spatial a gyakorlatban
 Spatial a gyakorlatban A korábban összefoglalt elméleti ismeretanyagot mindenképpen szerettem volna kipróbálni a gyakorlatban is. Sajnos az időm rövidsége és beállítási problémák miatt nem tudtam megoldani,
Spatial a gyakorlatban A korábban összefoglalt elméleti ismeretanyagot mindenképpen szerettem volna kipróbálni a gyakorlatban is. Sajnos az időm rövidsége és beállítási problémák miatt nem tudtam megoldani,
Adatbázisok elmélete
 Adatbázisok elmélete Adatbáziskezelés, bevezető Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Katona Gyula Y. (BME SZIT) Adatbázisok elmélete
Adatbázisok elmélete Adatbáziskezelés, bevezető Katona Gyula Y. Számítástudományi és Információelméleti Tanszék Budapesti Műszaki és Gazdaságtudományi Egyetem Katona Gyula Y. (BME SZIT) Adatbázisok elmélete
Döbrönte Zoltán. Data Vault alapú adattárház - Fél óra alatt. DMS Consulting Kft.
 Data Vault alapú adattárház - Fél óra alatt Döbrönte Zoltán DMS Consulting Kft. 1 Miről lesz szó Adattárház automatizálás Hol alkalmazható a leghatékonyabban Célok, funkcionalitás, előnyök Data Vault modellezés
Data Vault alapú adattárház - Fél óra alatt Döbrönte Zoltán DMS Consulting Kft. 1 Miről lesz szó Adattárház automatizálás Hol alkalmazható a leghatékonyabban Célok, funkcionalitás, előnyök Data Vault modellezés
Kilencedik témakör: Lazarus-Firebird. Készítette: Dr. Kotsis Domokos
 PASzSz Kilencedik témakör: Lazarus-Firebird Készítette: Dr. Kotsis Domokos Az SQLdb fülön IBConnection Kapcsolat A Data Access fülön Az SQLdb fülön... Select 1. Az SQLQuery lezárása. (Active := false,
PASzSz Kilencedik témakör: Lazarus-Firebird Készítette: Dr. Kotsis Domokos Az SQLdb fülön IBConnection Kapcsolat A Data Access fülön Az SQLdb fülön... Select 1. Az SQLQuery lezárása. (Active := false,
2. lépés: openssh szerver telepítés sudo apt-get install openssh-server
 1. lépés: (master- és datanode esetén) Csoport készítés: sudo addgroup hadoop Felhasználók készítése: sudo adduser --ingroup hadoop yarn sudo adduser --ingroup hadoop hdfs sudo adduser --ingroup hadoop
1. lépés: (master- és datanode esetén) Csoport készítés: sudo addgroup hadoop Felhasználók készítése: sudo adduser --ingroup hadoop yarn sudo adduser --ingroup hadoop hdfs sudo adduser --ingroup hadoop
Java és web programozás
 Budapesti M szaki Egyetem 2013. november 20. 10. El adás SQLite SQLite: Adatbázis kezel rendszer SQL standardokat nagyrészt követi Nagyon elterjedt, pl böngész kben is használt Nehéz olyan programnyelvet
Budapesti M szaki Egyetem 2013. november 20. 10. El adás SQLite SQLite: Adatbázis kezel rendszer SQL standardokat nagyrészt követi Nagyon elterjedt, pl böngész kben is használt Nehéz olyan programnyelvet
Webes alkalmazások fejlesztése 11. előadás. Alkalmazások felhőben. 2015 Giachetta Roberto groberto@inf.elte.hu http://people.inf.elte.
 Eötvös Loránd Tudományegyetem Informatikai Kar Webes alkalmazások fejlesztése 11. előadás Alkalmazások felhőben 2015 Giachetta Roberto groberto@inf.elte.hu http://people.inf.elte.hu/groberto Számítástechnikai
Eötvös Loránd Tudományegyetem Informatikai Kar Webes alkalmazások fejlesztése 11. előadás Alkalmazások felhőben 2015 Giachetta Roberto groberto@inf.elte.hu http://people.inf.elte.hu/groberto Számítástechnikai
Adattárház és BigData Szimbiózisa. Baranyi Szabolcs IM Technical Sales
 Adattárház és BigData Szimbiózisa Baranyi Szabolcs IM Technical Sales Szabolcs.baranyi@hu.ibm.com BigData adatforrásai Adattárház kiterjesztés igénye BigData és adattárház integrációja a hatékonyság növelésére
Adattárház és BigData Szimbiózisa Baranyi Szabolcs IM Technical Sales Szabolcs.baranyi@hu.ibm.com BigData adatforrásai Adattárház kiterjesztés igénye BigData és adattárház integrációja a hatékonyság növelésére
KORSZERŰ BIG DATA FELDOLGOZÓ KERETRENDSZEREK. 2014.02.03. Hermann Gábor MTA-SZTAKI
 KORSZERŰ BIG DATA FELDOLGOZÓ KERETRENDSZEREK 2014.02.03. Hermann Gábor MTA-SZTAKI MI AZ A BIG DATA? MI AZ A BIG DATA? Sok adat! ENNYI? BIG DATA 4V Volume Velocity Variety Veracity +3V (7V) Variability
KORSZERŰ BIG DATA FELDOLGOZÓ KERETRENDSZEREK 2014.02.03. Hermann Gábor MTA-SZTAKI MI AZ A BIG DATA? MI AZ A BIG DATA? Sok adat! ENNYI? BIG DATA 4V Volume Velocity Variety Veracity +3V (7V) Variability
Oracle E-Business Suite üzemeltetés a Rába Járműipari Holding Nyrt.-nél
 Oracle E-Business Suite üzemeltetés a Rába Járműipari Holding Nyrt.-nél 1 Kósa György Szenior Rendszermérnök (Oracle OCP és MSSQL DBA, EBS DBA) T-Systems Magyarország Zrt. Kósa György - T-Systems Magyarország
Oracle E-Business Suite üzemeltetés a Rába Járműipari Holding Nyrt.-nél 1 Kósa György Szenior Rendszermérnök (Oracle OCP és MSSQL DBA, EBS DBA) T-Systems Magyarország Zrt. Kósa György - T-Systems Magyarország
Adatbáziskezelő-szerver. Relációs adatbázis-kezelők SQL. Házi feladat. Relációs adatszerkezet
 1 2 Adatbáziskezelő-szerver Általában dedikált szerver Optimalizált háttértár konfiguráció Csak OS + adatbázis-kezelő szoftver Teljes memória az adatbázisoké Fő funkciók: Adatok rendezett tárolása a háttértárolón
1 2 Adatbáziskezelő-szerver Általában dedikált szerver Optimalizált háttértár konfiguráció Csak OS + adatbázis-kezelő szoftver Teljes memória az adatbázisoké Fő funkciók: Adatok rendezett tárolása a háttértárolón
Webapp (in)security. Gyakori hibákról és azok kivédéséről fejlesztőknek és üzemeltetőknek egyaránt. Veres-Szentkirályi András
security. Gyakori hibákról és azok kivédéséről fejlesztőknek és üzemeltetőknek egyaránt. Veres-Szentkirályi András") Webapp (in)security Gyakori hibákról és azok kivédéséről fejlesztőknek és üzemeltetőknek egyaránt Veres-Szentkirályi András Rövid áttekintés Webalkalmazások fejlesztése során elkövetett leggyakoribb hibák
Webapp (in)security Gyakori hibákról és azok kivédéséről fejlesztőknek és üzemeltetőknek egyaránt Veres-Szentkirályi András Rövid áttekintés Webalkalmazások fejlesztése során elkövetett leggyakoribb hibák
Tematika. MongoDB koncepció JSON Schemaless logika Replicaset képzés Sharding Aggregate framework
 MONGODB Tematika MongoDB koncepció JSON Schemaless logika Replicaset képzés Sharding Aggregate framework Koncepció párhuzamosítás: hardver infrastruktúra adta lehetőségeket kihasználni (sok szerver, sok
MONGODB Tematika MongoDB koncepció JSON Schemaless logika Replicaset képzés Sharding Aggregate framework Koncepció párhuzamosítás: hardver infrastruktúra adta lehetőségeket kihasználni (sok szerver, sok
Táblakezelés: Open SQL Internal table. Tarcsi Ádám: Az SAP programozása 1.
 Táblakezelés: Open SQL Internal table Tarcsi Ádám: Az SAP programozása 1. OPEN SQL Tarcsi Ádám, ELTE SAP Excellence Center: SAP programozás oktatóanyag 2 Open SQL Az Open SQL kulcsszavai: SELECT INSERT
Táblakezelés: Open SQL Internal table Tarcsi Ádám: Az SAP programozása 1. OPEN SQL Tarcsi Ádám, ELTE SAP Excellence Center: SAP programozás oktatóanyag 2 Open SQL Az Open SQL kulcsszavai: SELECT INSERT
SELECT. SELECT(projekció) FROM(forrás) WHERE(szűrés) GROUPBY(csoportosítás) HAVING(csoportok szűrése) ORDERBY(rendezés)
 FROM(forrás) WHERE(szűrés) GROUPBY(csoportosítás) HAVING(csoportok szűrése) ORDERBY(rendezés)") Lekérdezések Tartalom Lekérdezések feldolgozási sorrendje Összekapcsolások Operátorok Szűrések Aggregátumok és csoportosítások Csoportos szűrések Rendezések Halmazműveletek Ranking függvények Pivotálás
Lekérdezések Tartalom Lekérdezések feldolgozási sorrendje Összekapcsolások Operátorok Szűrések Aggregátumok és csoportosítások Csoportos szűrések Rendezések Halmazműveletek Ranking függvények Pivotálás
Adattárház kialakítása a Szövetkezet Integrációban, UML eszközökkel. Németh Rajmund Vezető BI Szakértő március 28.
 Adattárház kialakítása a Szövetkezet Integrációban, UML eszközökkel Németh Rajmund Vezető BI Szakértő 2017. március 28. Szövetkezeti Integráció Központi Bank Takarékbank Zrt. Kereskedelmi Bank FHB Nyrt.
Adattárház kialakítása a Szövetkezet Integrációban, UML eszközökkel Németh Rajmund Vezető BI Szakértő 2017. március 28. Szövetkezeti Integráció Központi Bank Takarékbank Zrt. Kereskedelmi Bank FHB Nyrt.
Adatbázisok II. rész
 Adatbázisok II. rész Érettségi feladatok Új adatbázist készítünk A táblákat a külső adatok menüfül szövegfájl pontjánál importáljuk (nem pedig megnyitjuk!) Fontos: az első sor tartalmazza az oszlopneveket
Adatbázisok II. rész Érettségi feladatok Új adatbázist készítünk A táblákat a külső adatok menüfül szövegfájl pontjánál importáljuk (nem pedig megnyitjuk!) Fontos: az első sor tartalmazza az oszlopneveket
2011. November 8. Boscolo New York Palace Budapest. Extrém teljesítmény Oracle Exadata és Oracle Exalogic rendszerekkel
 2011. November 8. Boscolo New York Palace Budapest Extrém teljesítmény Oracle Exadata és Oracle Exalogic rendszerekkel Integrált rendszerek - Engineered Systems Együtt tervezett hardver és szoftver Egyedi
2011. November 8. Boscolo New York Palace Budapest Extrém teljesítmény Oracle Exadata és Oracle Exalogic rendszerekkel Integrált rendszerek - Engineered Systems Együtt tervezett hardver és szoftver Egyedi
RDBMS fejlesztési irányok. Ferris Wheel (óriáskerék) Jim Gray törvényei. Elosztott adatbázisok problémái. Elosztott adatbázisok
 Jim Gray törvényei. Elosztott adatbázisok problémái. Elosztott adatbázisok") 1 RDBMS fejlesztési irányok Column store Tömb adatmodell JIT fordító és vektorizált végrehajtás Ferris wheel (óriáskerék) Elosztott adatbázisok Ferris Wheel (óriáskerék) Optimalizált scan műveletek Table
1 RDBMS fejlesztési irányok Column store Tömb adatmodell JIT fordító és vektorizált végrehajtás Ferris wheel (óriáskerék) Elosztott adatbázisok Ferris Wheel (óriáskerék) Optimalizált scan műveletek Table
SQL gyakorló feladatok. 6. Adatbázis gyakorlat április 5.
 SQL gyakorló feladatok 6. Adatbázis gyakorlat 2011. április 5. SQL alapparancsai DDL: - create: táblák létrehozása - alter: táblák (séma) módosítása - drop: táblák törlése DML: - select: adatok lekérdezése
SQL gyakorló feladatok 6. Adatbázis gyakorlat 2011. április 5. SQL alapparancsai DDL: - create: táblák létrehozása - alter: táblák (séma) módosítása - drop: táblák törlése DML: - select: adatok lekérdezése
Adatbázisok elmélete 9. előadás
 Adatbázisok elmélete 9. előadás Katona Gyula Y. Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi Tsz. I. B. 137/b kiskat@cs.bme.hu http://www.cs.bme.hu/ kiskat 2005 ADATBÁZISOK ELMÉLETE
Adatbázisok elmélete 9. előadás Katona Gyula Y. Budapesti Műszaki és Gazdaságtudományi Egyetem Számítástudományi Tsz. I. B. 137/b kiskat@cs.bme.hu http://www.cs.bme.hu/ kiskat 2005 ADATBÁZISOK ELMÉLETE
Operációs Rendszerek II. Első verzió: 2009/2010. I. szemeszter Ez a verzió: 2009/2010. II. szemeszter
 Operációs Rendszerek II. Első verzió: 2009/2010. I. szemeszter Ez a verzió: 2009/2010. II. szemeszter 1 Mai témák ZFS NTFS 2 ZFS Új koncepció, nem továbbgondolás Pooled storage modell Minden művelet copy-on-write
Operációs Rendszerek II. Első verzió: 2009/2010. I. szemeszter Ez a verzió: 2009/2010. II. szemeszter 1 Mai témák ZFS NTFS 2 ZFS Új koncepció, nem továbbgondolás Pooled storage modell Minden művelet copy-on-write
CREATE TABLE student ( id int NOT NULL GENERATED ALWAYS AS IDENTITY PRIMARY KEY, name varchar(100) NOT NULL, address varchar(100) NOT NULL )
 NOT NULL, address varchar(100) NOT NULL )") Célok: a Java DB adatbázis-kezelő rendszer használatának ismertetése, adatbázisok használata Java alkalmazásokban - kétrétegű architektúra, egyszerű kliens-szerver architektúra használata hálózati alkalmazásokhoz.
Célok: a Java DB adatbázis-kezelő rendszer használatának ismertetése, adatbázisok használata Java alkalmazásokban - kétrétegű architektúra, egyszerű kliens-szerver architektúra használata hálózati alkalmazásokhoz.
SAP Business One. Áttekintés, gyakorlati ismertetı. Mosaic Business System Kft.; Support: +36 1 253-0526
 Mosaic Business System Kft.; Support: +36 1 253-0526 technológia Minimum hardver- és szoftverkövetelmények Technológia Technológia Az is kétszintő kliens/szerver architektúrán alapul. A szerver a Microsoft
Mosaic Business System Kft.; Support: +36 1 253-0526 technológia Minimum hardver- és szoftverkövetelmények Technológia Technológia Az is kétszintő kliens/szerver architektúrán alapul. A szerver a Microsoft
Google App Engine az Oktatásban 1.0. ügyvezető MattaKis Consulting http://www.mattakis.com
 Google App Engine az Oktatásban Kis 1.0 Gergely ügyvezető MattaKis Consulting http://www.mattakis.com Bemutatkozás 1998-2002 között LME aktivista 2004-2007 Siemens PSE mobiltelefon szoftverfejlesztés,
Google App Engine az Oktatásban Kis 1.0 Gergely ügyvezető MattaKis Consulting http://www.mattakis.com Bemutatkozás 1998-2002 között LME aktivista 2004-2007 Siemens PSE mobiltelefon szoftverfejlesztés,
Gráfok mindenhol. x $ SZENDI-VARGA JÁNOS IOT SOCIAL NETWORKS FRAUD DETECTION MASTER DATA MANAGEMENT RECOMMENDATION ENGINES. Internet of Things
 8 b $! [ IOT RECOMMENDATION ENGINES 5 K Internet of Things a " > Gráfok mindenhol Facebook, Twitter, Google+ x $ S SOCIAL NETWORKS 9 SZENDI-VARGA JÁNOS K K # MASTER DATA MANAGEMENT Z FRAUD DETECTION Graph
8 b $! [ IOT RECOMMENDATION ENGINES 5 K Internet of Things a " > Gráfok mindenhol Facebook, Twitter, Google+ x $ S SOCIAL NETWORKS 9 SZENDI-VARGA JÁNOS K K # MASTER DATA MANAGEMENT Z FRAUD DETECTION Graph
Big Data: a több adatnál is több
 Big Data: a több adatnál is több Sidló Csaba István MTA Számítástechnikai és Automatizálási Kutatóintézet Üzleti Intelligencia és Adattárházak Csoport sidlo@sztaki.mta.hu http://dms.sztaki.hu CIO Hungary
Big Data: a több adatnál is több Sidló Csaba István MTA Számítástechnikai és Automatizálási Kutatóintézet Üzleti Intelligencia és Adattárházak Csoport sidlo@sztaki.mta.hu http://dms.sztaki.hu CIO Hungary
SQL. Táblák összekapcsolása lekérdezéskor Aliasok Allekérdezések Nézettáblák
 SQL Táblák összekapcsolása lekérdezéskor Aliasok Allekérdezések Nézettáblák A SELECT UTASÍTÁS ÁLTALÁNOS ALAKJA (ISM.) SELECT [DISTINCT] megjelenítendő oszlopok FROM táblá(k direkt szorzata) [WHERE feltétel]
SQL Táblák összekapcsolása lekérdezéskor Aliasok Allekérdezések Nézettáblák A SELECT UTASÍTÁS ÁLTALÁNOS ALAKJA (ISM.) SELECT [DISTINCT] megjelenítendő oszlopok FROM táblá(k direkt szorzata) [WHERE feltétel]
NIIF Központi Elosztott Szolgáltatói Platform
 NIIF Központi Elosztott Szolgáltatói Platform Bajnok Kristóf kristof.bajnok@sztaki.hu MTA-SZTAKI ITAK 2004. április 7. MTA Sztaki / ITAK 1 A helyzet 2002-ben Az NIIF központi szolgáltatásait a helka.iif.hu
NIIF Központi Elosztott Szolgáltatói Platform Bajnok Kristóf kristof.bajnok@sztaki.hu MTA-SZTAKI ITAK 2004. április 7. MTA Sztaki / ITAK 1 A helyzet 2002-ben Az NIIF központi szolgáltatásait a helka.iif.hu
BEVEZETÉS Az objektum fogalma
 BEVEZETÉS Az objektum fogalma Program (1) Adat (2) Objektum Kiadványszerkesztés Word Táblázatkezelés Excel CAD AutoCad Adatbáziskezelés Access 1 Program (1) Adat (2) Objektum Adatmodell (2) A valós világ
BEVEZETÉS Az objektum fogalma Program (1) Adat (2) Objektum Kiadványszerkesztés Word Táblázatkezelés Excel CAD AutoCad Adatbáziskezelés Access 1 Program (1) Adat (2) Objektum Adatmodell (2) A valós világ
Adatbázis. AMP! (Apache + MySql + PHP) XAMPP, LAMP, MAMP, WAMP et cetera
 XAMPP, LAMP, MAMP, WAMP et cetera") Adatbázis PHP MySql AMP! (Apache + MySql + PHP) XAMPP, LAMP, MAMP, WAMP et cetera Adatbázis - nem html? Egyszerű blog { Bejegyzés Olvasó Komment MySql - miért pont az? The world's most popular open source
Adatbázis PHP MySql AMP! (Apache + MySql + PHP) XAMPP, LAMP, MAMP, WAMP et cetera Adatbázis - nem html? Egyszerű blog { Bejegyzés Olvasó Komment MySql - miért pont az? The world's most popular open source